eXist: A NoSQL Document Database and Application Platform (2015)
Chapter 11. Basic Indexing
This chapter will take you into the mysterious and sometimes puzzling world of database indexes. As soon as your dataset starts growing and performance starts degrading as a result, indexes become a necessity.
Just for a moment let’s imagine that there are no indexes. This would mean that every XPath request must be resolved by brute force. So, for a query like //line[@author eq "erik"], the full document(s) node tree(s) must be traversed to try to find line elements with anauthor attribute that matches the value erik. You can probably see that on a large dataset this could be an intensive, and ultimately a slow, operation. If you further imagine running many of these queries on demand by your users in parallel, things can only get worse!
Of course, indexes come with a cost of their own: when XML documents are created or updated, the corresponding indexes must be updated too. However, this is generally not a problem. For most (but not all) applications, updating is a much rarer event than querying, and the short time lags created by updating the indexes go unnoticed.
Large databases, XML or otherwise, rarely scale well without indexes. Performance degradation as the dataset grows could be linear, or often worse. Therefore, defining and tuning indexes is well worth the effort, and often a necessity.
NOTE
Besides the indexes mentioned here and in Chapter 12, there is also an index that supports explicit ordering, known as the sort index. Since this works differently to the indexes described here, it is handled separately in sort.
Indexing Example
For an introduction to the world of indexing, examine the code that accompanies the book (see “Accompanying Source Code”)in the folder chapters/indexing, or in the /db/apps/exist-book/indexing collection if you have installed the XAR package. The data subcollection contains two XML data files with some old Encyclopedia Britannica entries. The contents of these files are exactly the same, with the exception that one is in the tei namespace and the other is not.
For a look at the index definitions for these files, open /db/system/config/db/apps/exist-book/indexing/data/collection.xconf:
<collection xmlns="http://exist-db.org/collection-config/1.0">
<index xmlns:tei="http://www.tei-c.org/ns/1.0">
<create qname="tei:name" type="xs:string"/>
<ngram qname="tei:p"/>
<lucene>
<text qname="tei:p"/>
</lucene>
</index>
</collection>
This file defines three indexes on data in the /db/apps/exist-book/indexing/data collection:
§ A range index on all tei:name elements in this collection. A range index optimizes searches on the content of elements and attributes.
§ An NGram index on all tei:p elements in this collection. An NGram index optimizes searches on substrings within the contents of elements and attributes.
§ A full-text index on all tei:p elements in this collection. Full-text indexes optimize searches on words and phrases within the contents of elements and attributes.
How this works exactly and what index type to use when are handled in this and the next chapter. The effect, however, of these definitions is that the data in the tei-namespaced file is indexed, but the (same) data without a namespace is not. This allows us to easily run the same query over the indexed and nonindexed data and compare the results.
The test-indexes.xq script does exactly this. It runs a number of queries over the contents of the two files and outputs the results as an XML fragment.
NOTE
To show the differences between indexed and nonindexed searches more clearly (on modern, fast hardware), all searches are repeated multiple times. If your system is slower or faster than our test system, then it could be that the search is too slow or too fast for you. You can change the number of iterations performed at the top of the script.
Here is the code fragment that performs the test of the range index:
{
let $starttime as xs:time := util:system-time()
let $result := for $i in1 to $repeats-range
return
for $n indoc($doc-with-indexes)//tei:name[. eq$phrase-range] return $n
let $endtime as xs:time := util:system-time()
return
<Result type="indexed"
time="{seconds-from-duration($endtime - $starttime)}s"/>
}
{
let $starttime as xs:time := util:system-time()
let $result := for $i in1 to $repeats-range
return
for $n indoc($doc-without-indexes)//name[. eq$phrase-range] return $n
let $endtime as xs:time := util:system-time()
return
<Result type="non-indexed"
time="{seconds-from-duration($endtime - $starttime)}s"/>
}
NOTE
Notice that we use util:system-time, not fn:current-time, to get the start and end time of a piece of code. The XQuery specification states that the value of current-time is deterministic throughout the execution of an XQuery. This means that it will not change during execution. As we want to measure the difference between two times to determine how long the query took, we instead use util:system-time, which is nondeterministic and will always return the point in time. It is worth noting that all of the date/time functions within the XPath and XQuery Functions and Operators specification are deterministic.
If you look at the output from one of our systems for this fragment, the differences between the indexed and nonindexed versions are rather dramatic:
<Result type="indexed" time="0.011s"/>
<Result type="non-indexed" time="0.782s"/>
Performance with an index is a factor of 71 times faster, and the difference will likely only increase as more data is added to the system!
Index Types
Out of the box, eXist has a number of predefined index types available. This section will tell you what they are and what they are used for. This is important, because you have to choose the right tool for the job to get the best results. Configuring and using these indexes is handled in the sections to come.
You can change the available index types (on the Java level), and even add your own. However, that’s an advanced subject and not discussed here. Please refer to the online documentation if you want to know more about this.
Structural Index
eXist’s structural index keeps track of the tree structure of nodes in all XML documents stored in the database. It indexes all elements and attributes, so that when you do a query like //title, it can quickly find all of the appropriate title elements. Indexing is done with thequalified name (or QName) of a node: both the namespace and the local name are used.
The structural index also automatically indexes identifier attributes. These are attributes called xml:id or attributes explicitly marked as of type ID in an attached DTD.
The structural index is used for resolving nearly all XPath and XQuery expressions. You can’t configure or disable it, it is an integral part of eXist.
Range Indexes
Although the structural index allows eXist to find nodes by name quickly, it doesn’t do anything with the actual values of the nodes (except @xml:id). So, a query like //author[@name='erik'] will be able to find author elements that have a name attribute quickly, but after that will still have to use brute force to compare the value of the name attribute with 'erik'. When the database becomes large and the queries more complex, performance will degrade rapidly.
Range indexes come to the rescue here: these indexes work on the values of nodes, not their names. The optimizer will use them when you do a =, >, <, etc., comparison in your XPath expression. They are also used for string comparisons within functions like contains and even for regular expression lookups with the matches function.
Range indexes are also useful for nonstring comparisons. You can define the index to treat the indexed value as, for instance, xs:double, xs:integer, or xs:dateTime (values that cannot be cast as the specified type are ignored when the index is being created). This makes a query like //article[@price gt 100.0] with an xs:double range index on the price attribute very efficient.
NOTE
Without an index on the price attribute, the syntax for this XPath has to be //article[xs:double(@price) gt 100.0]. However, for the index to work, do not add type conversions like xs:double. Because of the index, type conversions are implicit. Adding one will actually prevent the index from working.
NGram Indexes
NGram indexes are used to make exact substring searches efficient. For example, if you often do things like searching for 'def' in 'abcdefghij', an NGram index can help make this perform faster. NGram indexes retain whitespace and punctuation and are case-insensitive (index=INDEX=Index). To use an NGram index, you need the functions from the ngram extension module. Read more about this in “Using the NGram Indexes”.
NGram indexes are called “NGram” because values are split into tokens of n characters, the so-called n-grams (for background information, see the Wikipedia "n-gram” article). For eXist n is 3 by default, which, in our experience, provides the best compromise between index size and performance. If needed, you can change the value of n in $EXIST_HOME/conf.xml (search for n="3”).
NOTE
If all your substring searches are looking for words (whitespace-separated), you’re better off using a full-text index, as described next. However, some non-European languages don’t separate their words with whitespace; this is where the NGram index comes in handy.
Full-Text Indexes
eXist’s full-text indexing capabilities allow you to search the text in your documents for words and phrases using a query language with features like wildcards, fuzzy matches, and Boolean expressions. When they are used in combination with eXist’s “keywords in context” (KWIC) capabilities, results can be displayed in an attractive manner, highlighting the found words within a fragment of surrounding text.
Full-text indexes in eXist are implemented via Lucene, a fast, efficient, and customizable full-text indexer.
Since full-text indexing is a detailed subject, it is handled separately in Chapter 12.
Configuring Indexes
Configurable indexes (i.e., all but the structural index) are defined at the collection level. This means that specific indexes can be defined for all XML documents in a certain collection (and any subcollections).
To define indexes for a specific collection (and its subcollections), you need to do the following:
1. The database has a system collection /db/system/config. Under here, you create a collection path that reflects the path from the database root (/db) to the collection that holds the data you wish to index. For instance, if you wanted to create indexes for /db/myapp/data, you would create the collection /db/system/config/db/myapp/data.
2. Create an XML file there called collection.xconf with the following basic contents:
3. <collection xmlns="http://exist-db.org/collection-config/1.0">
4. <index>
5. <!-- Index definitions here -->
6. </index>
</collection>
All elements in the collection.xconf file must be in the http://exist-db.org/collection-config/1.0 namespace.
7. Add the index definitions as children of the index element (details covered shortly, and for full text in Chapter 12).
8. If there’s already data in the collection, don’t forget to reindex! See “Maintaining Indexes” for details.
Configuring Range Indexes
You may define range indexes by adding create elements to the index configuration in collection.xconf. For instance:
<collection xmlns="http://exist-db.org/collection-config/1.0">
<index xmlns:ns1="http://mynamespace">
<create qname="ns1:article" type="xs:string"/>
<create qname="@price" type="xs:double"/>
</index>
</collection>
This creates a string-type range index on every article element (in the http://mynamespace namespace) and a double-precision floating-point range index on every price attribute, for every document in the collection (and subcollections).
The create element must be a direct child of the index element. It takes the form:
<create qname = xs:QName
type = xs:QName />
where:
§ qname holds the qualified name (local name with an optional namespace prefix) of the element or attribute to index. An attribute must be prefixed with an at sign (@).
§ type contains the data type of the element/attribute to index, expressed as an XML schema data type. The supported types are xs:string , xs:integer, xs:decimal, xs:boolean, xs:dateTime, and all their subtypes.
WARNING
If the value of the type attribute is invalid, the index configuration is silently ignored! However, a warning indicating the problem is written to the $EXIST_HOME/webapp/WEB-INF/logs/exist.log logfile.
INDEXING SPECIFIC NODES
There is a second format for defining range indexes: using a path instead of a qname attribute (e.g., <create path="//ns1:article/@price" type="xs:double"/>). The path attribute can contain a limited form of XPath expression to specify the nodes to index; only element and attribute (with @) names, the // and / axes, and the wildcard * operator are allowed. Predicates are not allowed.
At first sight, this looks like it’s leading to more efficient indexes as you provide the indexer with a more targeted set of elements/attributes to index, which should in turn lead to smaller and therefore faster indexes.
Unfortunately, these kinds of indexes make life extremely hard for the query optimizer. An index like this is only valid in certain contexts, and since optimization is done at compile time, when the context is frequently not yet known, most optimization techniques cannot be applied.
Therefore, our strong advice is to stick to range indexes based on qualified names and not use context-dependent indexing. In most cases, the indexes will be larger but the queries will still be faster!
Range indexing is done on the text values of the defined nodes. For example, assume you have a range index defined on title elements and the XML contains:
<title>Books written by <author>Joe Dumb</author></title>
The title range index will be on the concatenated text nodes of title, "Books written by Joe Dumb".
Range indexes are on the defined node only, though, not on their children. This means that in the preceding example there is no index on the author element. Expressions like //title[author='Joe Dumb'] are evaluated without using any index. Luckily, nothing stops you from defining an index on both title and author.
Configuring NGram Indexes
You can define NGram indexes by adding ngram elements to the index configuration in collection.xconf. For instance:
<collection xmlns="http://exist-db.org/collection-config/1.0">
<index xmlns:ns1="http://mynamespace">
<ngram qname="ns1:article"/>
<ngram qname="@price"/>
</index>
</collection>
This creates an NGram index on every article element (in the http://mynamespace namespace) and on every price attribute, for every document in the collection (and subcollections).
The ngram element must be a direct child of the index element. It takes the following form:
<ngram qname = QName />
where qname holds the qualified name (local name with an optional namespace prefix) of the element or attribute to index. An attribute must be prefixed with an @.
Maintaining Indexes
Once they are defined, eXist automatically keeps all indexes up to date. Adding or updating documents will automagically update all relevant indexes.
The only time you explicitly have to reindex is when you add or change an index definition for an existing collection. Luckily, this is easy. There are several ways to do this:
From the eXist client
Start eXist’s Java Admin Client, select the right collection, and choose the menu command File→“Reindex collection.”
From the dashboard’s collection browser
Open the dashboard, start the collection browser, select the right collection, and click the toolbar command “Reindex collection.”
From XQuery code
Use the extension function xmldb:reindex, passing it the URI of the collection to reindex. Upon completion, it will return true or false.
Using Indexes
Once they are defined, eXist tries to use the indexes as efficiently as possible, often by silently optimizing XPath expressions. You can also use them by explicitly calling certain extension functions. This section will tell you how to get the most out of your indexes.
Using the Structural Index
The structural index is a core part of eXist and cannot be avoided, even if you want to. However, the way it is implemented, as an index of qualified names, leads to some surprising effects. Being aware of this can help you write more efficient code.
When eXist evaluates a query like //title/author, it performs two lookups in the structural index: all title elements and all author elements (in the full database!). It then performs a structural join between these sets to determine which author elements are children of titleelements. Because of the way internal node identifiers are built up (see “Dynamic Level Numbering of Nodes”), this is extremely efficient.
As a consequence, some of the common wisdom about XPath may not hold true for eXist. For instance, more specific queries like /a/b/c/d/e are often presented in textbooks as being more efficient than //e, but since every step in an XQuery expression would cause eXist to perform a join, the fewer steps the better. In eXist, //e or /a//e is more efficient than /a/b/c/d/e.
The structural index is also used for looking up identifiers with the id function (finding nodes with a matching xml:id attribute or with a matching attribute that is explicitly marked as of type ID in an attached DTD).
Using the Range Indexes
Range indexes are used automatically to optimize queries. For this to work, the following conditions must be met:
§ The data type of the range index must match the data type used in the query.
For instance, assume you have a range index of data type xs:integer defined on attribute customerid. A query //Customer[@customerid eq '3456'] will not use this index because your query uses string comparison. To make use of the index, you need to rewrite this as //Customer[@customerid eq 3456].
WARNING
When you have an index of the xs:double data type, make sure your queries actually use doubles. Don’t write //Article[@price gt 100], but //Article[@price gt 100.0].
§ The query must not depend on the current context item.
For instance, a range index on id attributes will not be used in queries like //Article[@id eq ../@refid].
Indexes of the xs:string type are also used for queries that include the XPath functions contains, starts-with, and ends-with. However, substring searches like this are not very efficient with a range index. If you do this frequently, use an NGram index instead (and don’t forget to use the special ngram extension functions discussed in the next section to exploit those indexes).
WARNING
When you’re using range indexes, if you perform a query over multiple collections and not all collections are indexed, or they are in different indexes, eXist takes the first available index and only uses this. Matches outside this index are ignored.
For instance, assume you have a range index defined on collection /db/myapp/a but not on /db/myapp/b. Performing a query over collection('/db/myapp') will return matches from /db/myapp/a only!
Using the NGram Indexes
NGram indexes are not applied automatically in general comparisons; instead, you need to use the functions from the ngram extension module to exploit them.
For instance, assume there is an NGram index on Text elements. An NGram query for 'eXist indexes' might look like this:
//Text[ngram:contains(., 'eXist indexes')]
NOTE
Remember that NGram indexes are case-insensitive. This means that all ngram extension functions are case-insensitive too, in contrast to their XPath counterparts!
The ngram extension module includes the following functions:
ngram:contains, ngram:ends-with, ngram:starts-with
These work the same way as their XPath counterparts (albeit case-insensitive).
ngram:wildcard-contains
This allows searching for substrings using a limited regular expression syntax. Please refer to the function documentation for details.
General Optimization Tips
To round off this section, here are some general tips to help you make the most of eXist’s optimization techniques and indexes:
Prefer short paths
Because of the way the structural index works, queries like /a/b/c/d are slower than //d.
Prefer XPath filters over FLWOR where clauses
Don’t use for $n in //e where @id eq 1. Rewrite this as for $n in //e[@id eq 1]. eXist is much better at rewriting and optimizing predicates than where clauses.
Reduce the search space as early as possible
If you have an XPath query with multiple predicates, like //Text[contains(., 'eXist')][@id eq 1], you should put the most restrictive one first. So in this case (assuming identifiers are unique), //Text[@id eq 1][contains(., 'eXist')] will most likely perform better.
Use multiple XPath predicates instead of the and operator
Writing //Text[@id eq 1][contains(., 'eXist')] is better than //Text[@id eq 1 and contains(., 'eXist')]. The XQuery optimizer will try to do this rewriting trick for you, but helping it by explicitly using multiple predicates won’t hurt.
Use a union operator instead of an or operator
An expression like //Text[@id eq 1 or contains(., 'eXist')] performs better when rewritten as //Text[@id eq 1] | //Text[contains(., 'eXist')].
In all cases, of course, watch out for overdoing it. It’s no use rewriting simple queries that are already fast and/or work on small datasets. Also, try to remember the old software engineering gem: maintaining code is usually more expensive than creating it. Manually rewriting a query to squeeze out every last millisecond of performance can easily obfuscate its meaning.
Debugging Indexes
Applying indexes can feel a bit unnerving: you’ve defined them and all seems to be working, but is this really the case? Are your queries as efficient as you would like them to be? This can be a hard thing to test, because during development you may not have enough data at hand to really see if an index makes any difference at all. To help you with this, eXist has several ways to ascertain that your indexes are correctly defined and applied.
NOTE
When operations designed to exploit indexes don’t seem to be working as you would expect them to, you can of course always look in the eXist logfiles for any messages regarding the indexes.
Checking Index Definitions
An index definition is set up in the appropriate collection.xconf file (see “Configuring Indexes”). To find out if the index is correctly defined (and you didn’t, for instance, make any syntactical mistakes), open the dashboard’s Admin Web Application and select the Browse - Indexes page. There you’ll find an overview of all the defined indexes per collection. Find your collection in this list and check if the intended indexes are shown.
For instance, the indexes in the collection for our indexing example (see “Indexing Example”) look like Figure 11-1.
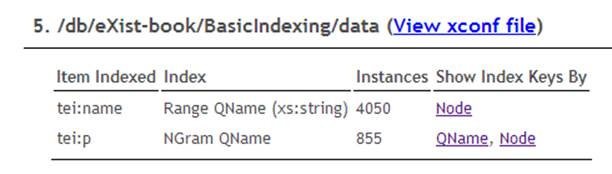
Figure 11-1. Viewing the index definitions in the Admin Web Application
The links underneath Show Index Keys By provide you with an overview of all the keys in the index. If you want a fast but database-wide list of index keys for a given QName, choose “QName.” If you want a collection-specific list of index keys, choose “Node.”
NOTE
You might want to check the number of instances in the index. If this is less than you expect, did you perhaps forget to reindex the collection after defining the index?
Checking Index Usage
You can check whether an index is used in query optimizations by using the Tooling – Query Profiling page of the Admin Web Application. Click Enable Tracing and then run your queries that you expect to benefit from the defined indexes. Finally, come back to the admin interface, click Disable Tracing, and go to the Indexes tab. You should see something like Figure 11-2.
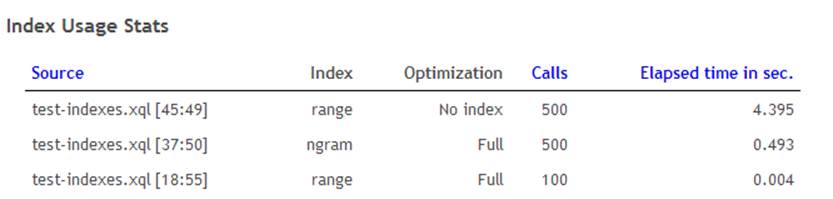
Figure 11-2. Index usage output
The most interesting entries here are probably the ones marked “No index.” Double-check these to make sure this value is indeed what you expect, and if not, try to fix them using the information in “Using Indexes”.
There is an option on the Query Profiling page called “Write additional info to log.” If you select this, additional tracing information regarding indexes is written to $EXIST_HOME/webapp/WEB-INF/logs/profile.log.
Tracing the Optimizer
If you need to investigate the details of what the optimizer is doing, you can enable tracing log output. This will give you a detailed list of all the (normally invisible) decisions and optimizations made.
To enable tracing, change eXist’s root logging level to trace by opening $EXIST_HOME/log4j.xml and searching for the root element (probably at the bottom of the file). You should see something like this:
<root>
<priority value="info"/>
<appender-ref ref="exist.core"/>
</root>
Change the priority to <priority value="trace"/>, restart eXist, and rerun the scripts you want to examine. The $EXIST_HOME/webapp/WEB-INF/logs/exist.log file should now contain lots of detailed information regarding your queries and their optimizations.
Don’t forget to reset the priority to <priority value="info"/> (and restart) after you’re done; otherwise, the logfile will quickly fill up your disk!