Hadoop Essentials (2015)
Chapter 2. Hadoop Ecosystem
Now that we have discussed and understood big data and Hadoop, we can move on to understanding the Hadoop ecosystem. A Hadoop cluster may have hundreds or thousands of nodes which are difficult to design, configure, and manage manually. Due to this, there arises a need for tools and utilities to manage systems and data easily and effectively. Along with Hadoop, we have separate sub-projects which are contributed by some organizations and contributors, and are managed mostly by Apache. The sub-projects integrate very well with Hadoop and can help us concentrate more on design and development rather than maintenance and monitoring, and can also help in the development and data management.
Before we understand different tools and technologies, let's understand a use case and how it differs from traditional systems.
Traditional systems
Traditional systems are good for OLTP (online transaction processing) and some basic Data Analysis and BI use cases. Within the scope, the traditional systems are best in performance and management. The following figure shows a traditional system on a high-level overview:
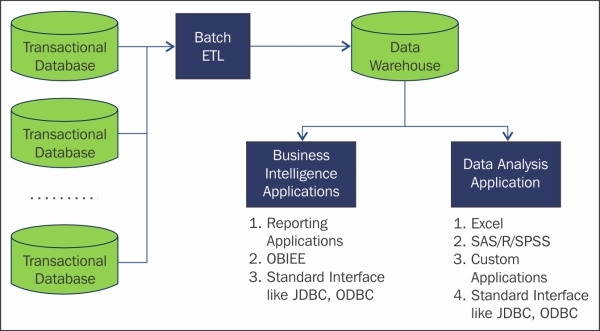
Traditional systems with BIA
The steps for typical traditional systems are as follows:
1. Data resides in a database
2. ETL (Extract Transform Load) processes
3. Data moved into a data warehouse
4. Business Intelligence Applications can have some BI reporting
5. Data can be used by Data Analysis Application as well
When the data grows, traditional systems fail to process, or even store, the data; and even if they do, it comes at a very high cost and effort because of the limitations in the architecture, issue with scalability and resource constraints, incapability or difficulty to scale horizontally.
Database trend
Database technologies have evolved over a period of time. We have RDBMS (relational database), EDW (Enterprise data warehouse), and now Hadoop and NoSQL-based database have emerged. Hadoop and NoSQL-based database are now the preferred technology used for the big data problems, and some traditional systems are gradually moving towards Hadoop and NoSQL, along with their existing systems. Some systems have different technologies to process the data such as, Hadoop with RDBMS, Hadoop with EDW, NoSQL with EDW, and NoSQL with Hadoop. The following figure depicts the database trend according to Forrester Research:
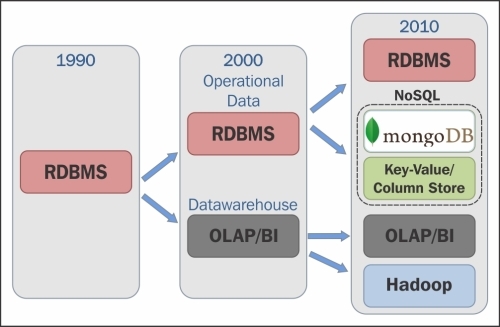
Database trends
The figure depicts the design trends and the technology which was available and adapted in a particular decade.
The 1990's decade was the RDBMS era which was designed for OLTP processing and data processing was not so complex.
The emergence and adaptation of data warehouse was in the 2000's, which is used for OLAP processing and BI.
From 2010 big data systems, especially Hadoop, have been adapted by many organizations to solve Big Data problems.
All these technologies can practically co-exist for a solution as each technology has its pros and cons because not all problems can be solved by any one technology.
The Hadoop use cases
Hadoop can help in solving the big data problems that we discussed in Chapter 1, Introduction to Big Data and Hadoop. Based on Data Velocity (Batch and Real time) and Data Variety (Structured, Semi-structured and Unstructured), we have different sets of use cases across different domains and industries. All these use cases are big data use cases and Hadoop can effectively help in solving them. Some use cases are depicted in the following figure:
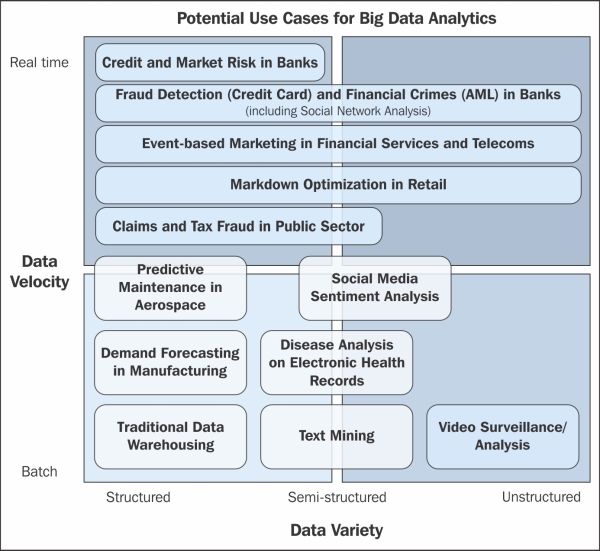
Potential use case for Big Data Analytics
Hadoop's basic data flow
A basic data flow of the Hadoop system can be divided into four phases:
1. Capture Big Data : The sources can be extensive lists that are structured, semi-structured, and unstructured, some streaming, real-time data sources, sensors, devices, machine-captured data, and many other sources. For data capturing and storage, we have different data integrators such as, Flume, Sqoop, Storm, and so on in the Hadoop ecosystem, depending on the type of data.
2. Process and Structure: We will be cleansing, filtering, and transforming the data by using a MapReduce-based framework or some other frameworks which can perform distributed programming in the Hadoop ecosystem. The frameworks available currently are MapReduce, Hive, Pig, Spark and so on.
3. Distribute Results: The processed data can be used by the BI and analytics system or the big data analytics system for performing analysis or visualization.
4. Feedback and Retain: The data analyzed can be fed back to Hadoop and used for improvements and audits.
The following figure shows the data captured and then processed in a Hadoop platform, and the results used in a Business Transactions and Interactions system, and a Business Intelligence and Analytics system:
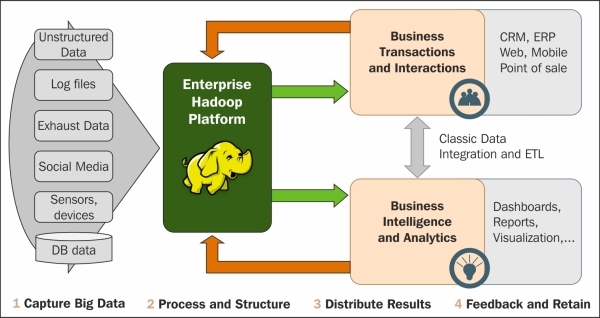
Hadoop basic data flow
Hadoop integration
Hadoop architecture is designed to be easily integrated with other systems. Integration is very important because although we can process the data efficiently in Hadoop, but we should also be able to send that result to another system to move the data to another level. Data has to be integrated with other systems to achieve interoperability and flexibility.
The following figure depicts the Hadoop system integrated with different systems and with some implemented tools for reference:
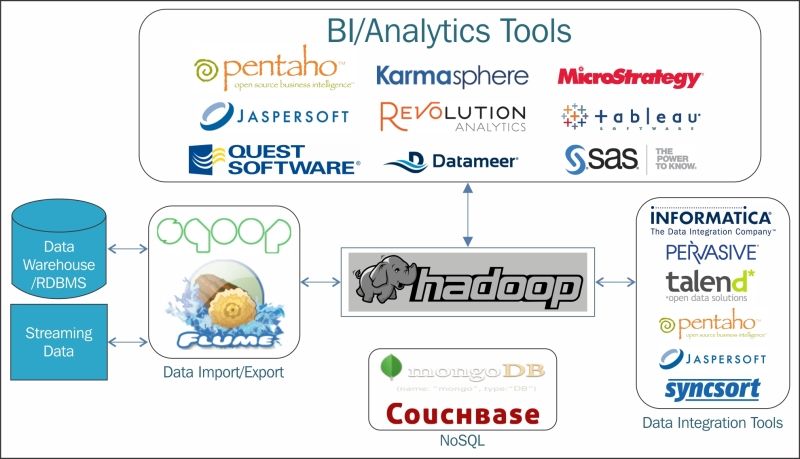
Hadoop Integration with other systems
Systems that are usually integrated with Hadoop are:
· Data Integration tools such as, Sqoop, Flume, and others
· NoSQL tools such as, Cassandra, MongoDB, Couchbase, and others
· ETL tools such as, Pentaho, Informatica, Talend, and others
· Visualization tools such as, Tableau, Sas, R, and others
The Hadoop ecosystem
The Hadoop ecosystem comprises of a lot of sub-projects and we can configure these projects as we need in a Hadoop cluster. As Hadoop is an open source software and has become popular, we see a lot of contributions and improvements supporting Hadoop by different organizations. All the utilities are absolutely useful and help in managing the Hadoop system efficiently. For simplicity, we will understand different tools by categorizing them.
The following figure depicts the layer, and the tools and utilities within that layer, in the Hadoop ecosystem:
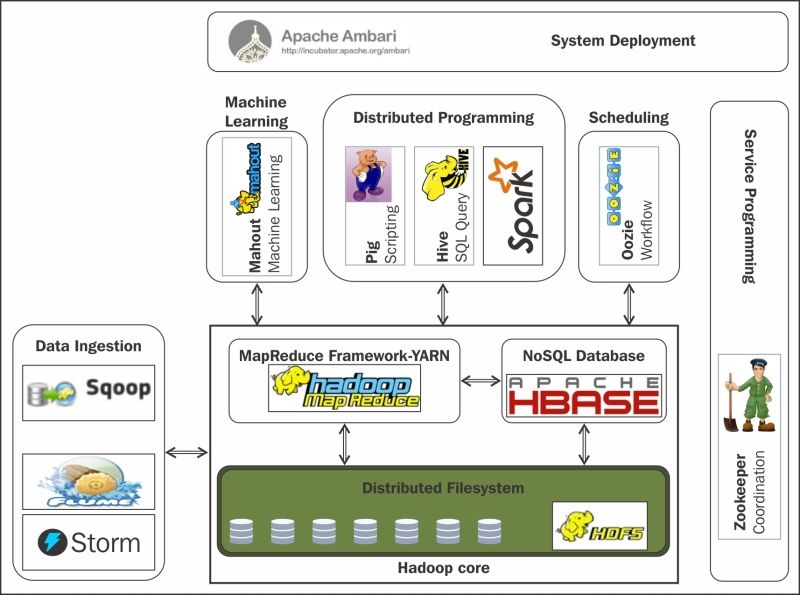
Hadoop ecosystem
Distributed filesystem
In Hadoop, we know that data is stored in a distributed computing environment, so the files are scattered across the cluster. We should have an efficient filesystem to manage the files in Hadoop. The filesystem used in Hadoop is HDFS, elaborated as Hadoop Distributed File System.
HDFS
HDFS is extremely scalable and fault tolerant. It is designed to efficiently process parallel processing in a distributed environment in even commodity hardware. HDFS has daemon processes in Hadoop, which manage the data. The processes are NameNode, DataNode, BackupNode, and Checkpoint NameNode.
We will discuss HDFS elaborately in the next chapter.
Distributed programming
To leverage the power of a distributed storage filesystem, Hadoop performs distributed programming which can do massive parallel programming. Distributed programming is the heart of any big data system, so it is extremely critical. The following are the different frameworks that can be used for distributed programming:
· MapReduce
· Hive
· Pig
· Spark
The basic layer in Hadoop for distributed programming is MapReduce. Let's introduce MapReduce:
· Hadoop MapReduce: MapReduce is the heart of the Hadoop system distributed programming. MapReduce is a framework model designed as parallel processing on a distributed environment. Hadoop MapReduce was inspired by Google MapReduce whitepaper. Hadoop MapReduce is scalable and massively parallel processing framework, which can work on huge data and is designed to run, even in commodity hardware. Before Hadoop 2.x, MapReduce was the only processing framework that could be performed, and then some utility extended and created a wrapper to program easily for faster development. We will discuss about Hadoop MapReduce in detail in Chapter 3, Pillars of Hadoop – HDFS, MapReduce, and YARN.
· Apache Hive: Hive provides a data warehouse infrastructure system for Hadoop, which creates a SQL-like wrapper interface called HiveQL, on top of MapReduce. Hive can be used to run some ad hoc querying and basic aggregation and summarization processing on the Hadoop data. HiveQL is not SQL92 compliant. Hive was developed by Facebook and contributed to Apache. Hive is designed on top of MapReduce, which means a HiveQL query will run the MapReduce jobs for processing the query. We can even extend HiveQL by using User Defined Functions (UDF).
· Apache Pig: Pig provides a scripting-like wrapper written in the Pig Latin language to process the data with script-like syntax. Pig was developed by Yahoo and contributed to Apache. Pig also translates the Pig Latin script code to MapReduce and executes the job. Pig is usually used for analyzing semi-structured and large data sets.
· Apache Spark: Spark provides a powerful alternative to Hadoop's MapReduce. Apache Spark is a parallel data processing framework that can run programs up to 100 times faster than Hadoop MapReduce in memory, or 10 times faster on disk. Spark is used for real-time stream processing and analysis of the data.
NoSQL databases
We have already discussed about NoSQL as one of the emerging and adopted systems. Within Hadoop ecosystem, we have a NoSQL database called HBase. HBase is one of the key component that provides a very flexible design and high volume simultaneous reads and write in low latency hence it is widely adopted.
Apache HBase
HBase is inspired from Google's Big Table. HBase is a sorted map, which is sparse, consistent, distributed, and multidimensional. HBase is a NoSQL, column oriented database and a key/value store, which works on top of HDFS. HBase provides faster lookup and also high volume inserts/updates of a random access request on a high scale. The HBase schema is very flexible and actually variable, where the columns can be added or removed at runtime. HBase supports low-latency and strongly consistent read and write operations. It is suitable for high-speed counter aggregation.
Many organizations or companies use HBase, such as Yahoo, Adobe, Facebook, Twitter, Stumbleupon, NGData, Infolinks, Trend Micro, and many more.
Data ingestion
Data management in big data is an important and critical aspect. We have to import and export large scale data to do processing, which becomes unmanageable in the production environment. In Hadoop, we deal with different set of sources such as batch, streaming, real time, and also sources that are complex in data formats, as some are semi-structured and unstructured too. Managing such data is very difficult, therefore we have some tools for data management such as Flume, Sqoop, and Storm, which are mentioned as follows:
· Apache Flume: Apache Flume is a widely used tool for efficiently collecting, aggregating, and moving large amounts of log data from many different sources to a centralized data store. Flume is a distributed, reliable, and available system. It performs well if a source is streaming, for example, log files.
· Apache Sqoop: Sqoop can be used to manage data between Hadoop and relational databases, enterprise data warehouses, and NoSQL systems. Sqoop has different connectors with respective data stores and using these connectors, Sqoop can import and export data in MapReduce, and can import and export data in parallel mode. Sqoop is also fault tolerant.
· Apache Storm: Apache Storm provides a real-time, scalable, and distributed solution for streaming data. Storm enables data-driven and automated activities. Apache Storm can be used with any programming language and it guarantees that data streams are processed without data loss. Storm is datatype-agnostic, it processes data streams of any data type.
Service programming
Programming in a distributed environment is complex and care has to be taken, otherwise it can become inefficient. To develop properly distributed applications in Hadoop, we have some service programming tools which provide utilities that take care of the distribution and resource management aspect. The tools that we will be discussing are as follows:
· Apache YARN
· Apache Zookeeper
Apache YARN
Yet another Resource Negotiator (YARN) has been a revolution in the major release of Hadoop 2.x version. YARN provides resource management and should be utilized as a common platform for integrating different tools and utilities in a Hadoop cluster and managing them. YARN is a resource manager that was created by separating the processing engine and resource management capabilities of MapReduce. It also provides the platform for processing frameworks other than MapReduce such as, Storm, Spark, and so on. YARN has built-in support for multi-tenancy to share cluster resource. YARN is responsible for managing and monitoring workloads and managing high-availability features of Hadoop.
YARN has improved capabilities, so that it can also be tuned for streaming and real-time analysis, which is a huge benefit and need in some scenarios. YARN is also backward compatible for existing MapReduce apps.
Some applications powered by YARN are as follows:
· Apache Hadoop MapReduce
· Apache Spark
· Apache Storm
· Apache Tez
· Apache S4
Apache Zookeeper
ZooKeeper is a distributed, open source coordination service for distributed applications. ZooKeeper exposes a simple set of primitives that distributed applications can use for synchronization, configuration, maintenance, grouping and naming resources for achieving co-ordination, high availability, and synchronization. ZooKeeper runs in Java and has bindings for both Java and C.
HBase, Solr, Kata, Neo4j, and so on, are some tools which use Zookeeper to coordinate activities.
Scheduling
The Hadoop system can have multiple jobs and these have to be scheduled many times. Hadoop jobs' scheduling is complex and difficult to create, manage, and monitor. We can use a system such as Oozie to coordinate and monitor Hadoop jobs efficiently, as mentioned next:
· Apache Oozie: Oozie is a workflow and coordination service processing system that lets the users manage multiple jobs as well as chain of jobs written in MapReduce, Pig, and Hive, also java programs and shell sripts too, and can link them to one another. Oozie is an extensible, scalable, and data-aware service. Oozie can be used to set rules for beginning and ending a workflow and it can also detect the completion of tasks.
Data analytics and machine learning
In Hadoop, and for general big data, analytics is the key interest area, as Hadoop is a powerful tool to process complex programs and algorithms to improve the process and business. Data analytics can identify deep insights and can help to optimize the process and stay ahead in the competition. Due to the powerful processing nature of Hadoop, machine learning has been in focus and a lot of development in the algorithms and techniques have been adapted for Hadoop. Machine learning techniques are also used in predictive analytics. Data analytics and machine learning is needed by competitive organizations to stay ahead in the competition and by some researchers, especially in life sciences, to process genes and medical records' patterns to generate much important and useful insights and details that are quite necessary in the medical field. This is also needed by researchers in the field of robotics to provide intelligence to machines for performing and optimizing a task. RHadoop is a data analytics statistical language integrated with Hadoop. Mahout is an open source machine learning API used in Hadoop.
· Apache Mahout: Mahout is a scalable machine learning API, which has a lot of implemented machine learning libraries. Mahout is an isolated project which can be used as a pure machine learning library, but the power of Mahout enhances when it is integrated with Hadoop. Some of the algorithms which are popularly used in Mahout are as follows:
o Recommendation
o Clustering
o Classification
System management
Deploying, provisioning, managing, and monitoring a Hadoop cluster requires expert scripting knowledge and usually takes a good amount of effort and time manually, but is repetitive. For performing such activities in Hadoop, we can use tools such as Ambari.
Apache Ambari
Ambari can be used by application developers and system integrators for managing most of the administration activities in a Hadoop cluster. Ambari is an open source framework in the Hadoop ecosystem, which can be used for installing, provisioning, deployment, managing, and monitoring a Hadoop cluster. Ambari's main motive is to hide the complexity of the Hadoop cluster management and to provide a very easy and intuitive web UI. One key feature of Ambari is that it provides RESTful APIs, which can be used to integrate with other external tools for better management.
Summary
In this chapter, we explored the different layers, and some components which can perform the layer functionality in the Hadoop ecosystem, and their usage.
We discussed the Hadoop system on a very high level, and we will be discussing the Hadoop architecture in depth in Chapter 3, Pillars of Hadoop – HDFS, MapReduce, and YARN.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.