Hadoop Essentials (2015)
Chapter 3. Pillars of Hadoop – HDFS, MapReduce, and YARN
We discussed in the last two chapters about big data, Hadoop, and the Hadoop ecosystem. Now, let's discuss more technical aspects about Hadoop Architecture. Hadoop Architecture is extremely flexible, scalable, and fault tolerant. The key to the success of Hadoop is its architecture that allows the data to be loaded as it is and stored in a distributed way, which has no data loss and no preprocessing is required.
We know that Hadoop is distributed computing and a parallel processing environment. Hadoop architecture can be divided in two parts: storage and processing. Storage in Hadoop is handled by Hadoop Distributed File System(HDFS), and processing is handled by MapReduce, as shown in the following image:
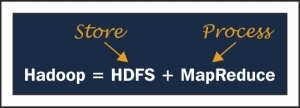
In this chapter, we will cover the basics of HDFS concept, Architecture, some key features, how Read and Write process happens, and some examples. MapReduce is the heart of Hadoop, and we will cover the Architecture, Serialization Data Types, MapReduce Steps or process, various file formats, and an example to write MapReduce programs. After this, we will come to YARN, which is most promising in Hadoop, and many applications have already adopted YARN, which has elevated Hadoop's capability.
HDFS
HDFS is the default storage filesystem in Hadoop, which is distributed, considerably simple in design and extremely scalable, flexible, and with high fault tolerance capability. HDFS architecture has a master-slave pattern due to which the slave nodes can be better managed and utilized. HDFS can even run on commodity hardware, and the architecture accepts that some nodes can be down and still data has to be recovered and processed. HDFS has self-healing processes and speculative execution, which make the system fault tolerant, and is flexible to add/remove nodes and increases the scalability with reliability. HDFS is designed to be best suited for MapReduce programming. One key assumption in HDFS is Moving Computation is Cheaper than Moving Data.
Features of HDFS
The important features of HDFS are as follows:
· Scalability: HDFS is scalable to petabytes or even more. HDFS is flexible enough to add or remove nodes, which can achieve scalability.
· Reliability and fault tolerance: HDFS replicates the data to a configurable parameter, which gives flexibility of getting high reliability and increases the fault tolerance of a system, as data will be stored in multiple nodes, and even if a few nodes are down, data can be accessed from other available nodes.
· Data Coherency: HDFS has the WORM (write once, read many) model, which simplifies the data coherency and gives high throughput.
· Hardware failure recovery: HDFS assumes some nodes in the cluster can fail and has a good failure recovery processes which allows HDFS to run even in commodity hardwares. HDFS has failover processes which can recover the data and handle hardware failure recovery.
· Portability: HDFS is portable on different hardwares and softwares.
· Computation closer to data: HDFS moves the computation process toward data instead of pulling data out for computation, which is much faster, as data is distributed and ideal for the MapReduce process.
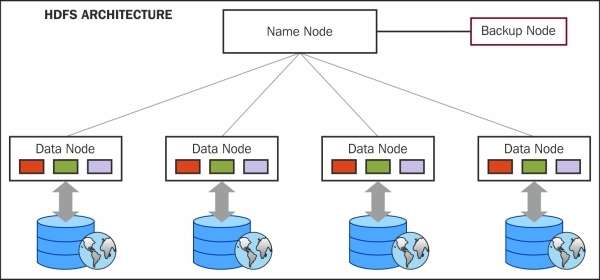
HDFS architecture
HDFS is managed by the daemon processes which are as follows:
· NameNode: Master process
· DataNode: Slave process
· Checkpoint NameNode or Secondary NameNode: Checkpoint process
· BackupNode: Backup NameNode
The HDFS architecture is shown in the following screenshot:
NameNode
NameNode is the master process daemon server in HDFS that coordinates all the operations related to storage in Hadoop, including the read and writes in HDFS. NameNode manages the filesystem namespace. NameNode holds the metadata above all the file blocks, and in which all nodes of data blocks are present in the cluster. NameNode doesn't store any data. NameNode caches the data and stores metadata in RAM for faster access, hence it requires a system with high RAM, otherwise NameNode can become a bottleneck in the cluster processing.
NameNode is a very critical process in HDFS and is a single point of failure, but HDFS can be configured as HDFS HA (high availability), which allows two NameNodes, only one of them can be active at a point of time and the other will be in standby. Standby NameNode will be getting the updates and the DataNode status, which makes Standby NameNode ready to take over and recover, if the active node of NameNode fails.
NameNode maintains the following two metadata files:
· Fsimage file: This holds the entire filesystem namespace, including the mapping of blocks to files and filesystem properties
· Editlog file: This holds every change that occurs to the filesystem metadata
When NameNode starts up, it reads FsImage and EditLog files from disk, merges all the transactions present in the EditLog to the FsImage, and flushes out this new version into a new FsImage on disk. It can then truncate the old EditLog because its transactions have been applied to the persistent FsImage.
DataNode
DataNode holds the actual data in HDFS and is also responsible for creating, deleting, and replicating data blocks, as assigned by NameNode. DataNode sends messages to NameNode, which are called as heartbeat in a periodic interval. If a DataNode fails to send the heartbeat message, then NameNode will mark it as a dead node. If the file data present in the DataNode becomes less than the replication factor, then NameNode replicates the file data to other DataNodes.
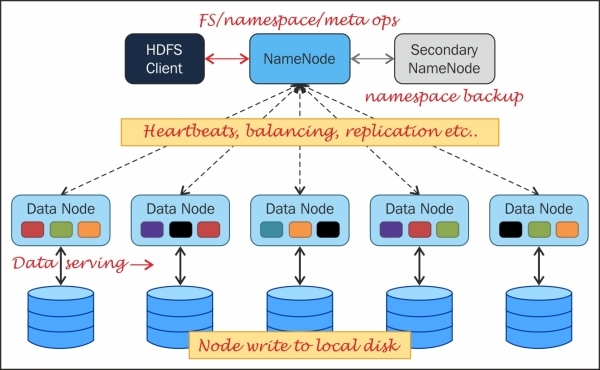
Image source: http://yoyoclouds.files.wordpress.com/2011/12/hadoop_arch.png.
Checkpoint NameNode or Secondary NameNode
Checkpoint NameNode , earlier known as Secondary NameNode, is a node that has frequent data check points of FsImage and EditLog files merged and available for NameNode in case of any NameNode failure. Checkpoint NameNode collects and stores the latest checkpoint. After storing, it merges the changes in the metadata to make it available for NameNode. Checkpoint NameNode usually has to be a separate node, and it requires a similar configuration machine as for NameNode, as memory requirement is the same as NameNode.
BackupNode
BackupNode is similar to Checkpoint NameNode, but it keeps the updated copy of FsImage in RAM memory and is always synchronized with NameNode. BackupNode has the same RAM requirement as NameNode. In high availability, BackupNode can be configured as Hot standby Node, and Zookeeper coordinates to make BackupNode as a failover NameNode.
Data storage in HDFS
In HDFS, files are divided in blocks, are stored in multiple DataNodes, and their metadata is stored in NameNode. For understanding how HDFS works, we need to understand some parameters and why it is used. The parameters are as follows:
· Block: Files are divided in multiple blocks. Blocks are configurable parameters in HDFS, where we can set the value, and files will be divided in block size: the default block size is 64 MB in the version prior to 2.2.0 and 128 MB since Hadoop 2.2.0 version. Block size is high to minimize the cost of disk seek time (which is slower), leverage transfer rate (which can be high), and reduce the metadata size in NameNode for a file.
· Replication: Each block of files divided earlier is stored in multiple DataNodes, and we can configure the number of replication factors. The default value is 3. The replication factor is the key to achieve fault tolerance. The higher the number of the replication factor, the system will be highly fault tolerant and will occupy that many numbers of time the file is saved, and also increase the metadata in NameNode. We have to balance the replication factor, not too high and not too low.
Read pipeline
The HDFS read process can be depicted in the following image:
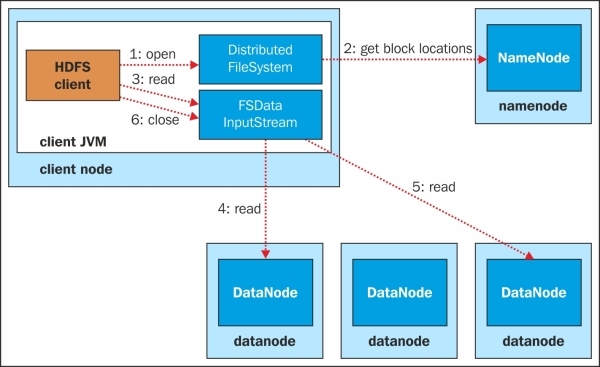
The HDFS read process involves the following six steps:
1. The client using a Distributed FileSystem object of Hadoop client API calls open() which initiate the read request.
2. Distributed FileSystem connects with NameNode. NameNode identifies the block locations of the file to be read and in which DataNodes the block is located. NameNode then sends the list of DataNodes in order of nearest DataNodes from the client.
3. Distributed FileSystem then creates FSDataInputStream objects, which, in turn, wrap a DFSInputStream, which can connect to the DataNodes selected and get the block, and return to the client. The client initiates the transfer by calling the read() of FSDataInputStream.
4. FSDataInputStream repeatedly calls the read() method to get the block data.
5. When the end of the block is reached, DFSInputStream closes the connection from the DataNode and identifies the best DataNode for the next block.
6. When the client has finished reading, it will call close() on FSDataInputStream to close the connection.
Write pipeline
The HDFS write pipeline process flow is summarized in the following image:
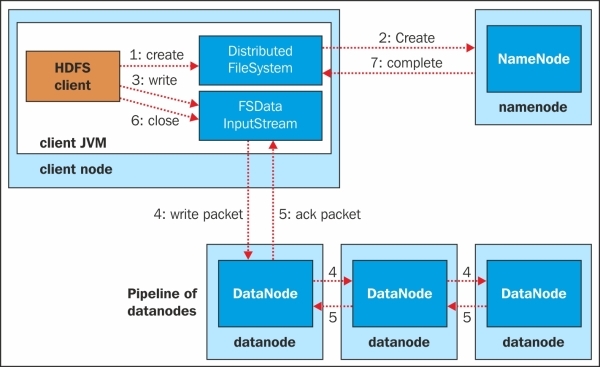
The HDFS write pipeline process flow is described in the following seven steps:
1. The client, using a Distributed FileSystem object of Hadoop client API, calls create(), which initiates the write request.
2. Distributed FileSystem connects with NameNode. NameNode initiates a new file creation, and creates a new record in metadata and initiates an output stream of type FSDataOutputStream, which wraps DFSOutputStream and returns it to the client. Before initiating the file creation, NameNode checks if a file already exists and whether the client has permissions to create a new file and if any of the condition is true then an IOException is thrown to the client.
3. The client uses the FSDataOutputStream object to write the data and calls the write() method. The FSDataOutputStream object, which is DFSOutputStream, handles the communication with the DataNodes and NameNode.
4. DFSOutputStream splits files to blocks and coordinates with NameNode to identify the DataNode and the replica DataNodes. The number of the replication factor will be the number of DataNodes identified. Data will be sent to a DataNode in packets, and that DataNode will send the same packet to the second DataNode, the second DataNode will send it to the third, and so on, until the number of DataNodes is identified.
5. When all the packets are received and written, DataNodes send an acknowledgement packet to the sender DataNode, to the client. DFSOutputStream maintains a queue internally to check if the packets are successfully written by DataNode. DFSOutputStream also handles if the acknowledgment is not received or DataNode fails while writing.
6. If all the packets have been successfully written, then the client closes the stream.
7. If the process is completed, then the Distributed FileSystem object notifies the NameNode of the status.
HDFS has some important concepts which make the architecture fault tolerant and highly available.
Rack awareness
HDFS is fault tolerant, which can be enhanced by configuring rack awareness across the nodes. In a large Hadoop cluster system, DataNodes will be spanned across multiple racks, which can be configured in HDFS to identify rack information of a DataNode. In a simplest form, HDFS can be made rack aware by using a script that can return a rack address for an IP address of nodes. To set the rack mapping script, specify the key topology.script.file.name in conf/hadoop-site.xml, it must be an executable script or program, which should provide a command to run to return a rack ID.
Rack IDs in Hadoop are hierarchical and look like path names. By default, every node has a rack ID of/default-rack. You can set rack IDs for nodes to any arbitrary path, for example, /foo/bar-rack. Path elements further to the left are higher up the tree. Thus, a reasonable structure for a large installation may be /top-switch-name/rack-name. The Hadoop rack IDs will be used to find near and far nodes for replica placement.
Advantages of rack awareness in HDFS
Rack awareness can be used to prevent losing data when an entire rack fails and to identify a nearest node where a block is present when reading a file. For efficient rack awareness, a node cannot have two copies of the same block, and in a rack, a block can be present in a maximum of two nodes. The number of racks used for block replication should be always less than the total number of block replicas.
Consider the following scenarios:
· Writing a block: When a new block is created, the first replica is placed on the local node, the second one is placed at a different rack, and the third one is placed on a different node at the local rack
· Reading a block: For a read request, as in the case of a normal read process, NameNode sends the list of DataNodes in order of DataNodes that are closer from the client and hence gives preference to the DataNodes of the same rack
To verify if a data block is corrupt, HDFS does block scanning. Every DataNode checks the block present in it and verifies with the stored checksum, which is generated during the block creation. Checksum is also verified after an HDFS client reads a block and DataNode gets intimated with the result. Block Scanner is scheduled for three weeks and can also be configured.
In case block corruption is identified, NameNode is informed, and NameNode marks the block in the DataNode as corrupt and initiates a replication of the block, and once a good copy is created and verified with checksum, the block from that DataNode is deleted.
HDFS federation
We have already discussed that NameNode is tightly coupled with DataNodes and is a SPOF (Single Point of Failure) in Hadoop 1.x. Let's try to understand the limitations of HDFS 1.0 to understand the necessity of HDFS Federation.
Limitations of HDFS 1.0
The following are the limitations:
· Limitation to number of files: Even though HDFS can have hundreds and thousands of nodes, as NameNode keeps the metadata in memory, the number of files that can be stored gets limited, depending upon the map heap memory allocated to the NameNode. The limitation arises because of a single NameNode.
· Single namespace: Due to a single namespace, the NameNode cannot delegate any workload and can be a bottleneck.
· SPOF: NameNode is a single point of failure as it is critical, and too much workload can be there with NameNode.
· Cannot run non MapReduce applications: HDFS is only designed to run applications that are MapReduce process or applications that are based on the MapReduce framework.
NameNode has single namespace and is tightly coupled with DataNodes, as all the requests have to coordinate with NameNode to get the blocks' location, and due to which it can become a bottleneck. NameNode has to be highly available or else the request will not be serviced. HDFS Federation is a feature that enables Hadoop to have independent multiple namespaces that overcome the limitations that we discussed. Lets have a look at the following image:
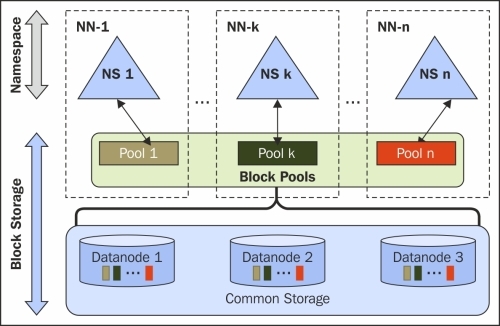
With multiple independent namespace hierarchy, the responsibility of NameNode is shared across multiple namespaces, which are federated but share the DataNodes of the cluster. Due to the Federation of NameNode, some requests can get load balanced among the NameNodes. Federated NameNodes work in multi-tenant architecture to provide isolation.
The benefit of HDFS federation
Read and write process is faster due to multiple NameNodes by avoiding bottleneck in case of a single NameNode process.
Horizontal scalability is achieved by HDFS Federation, which has a huge advantage of being a highly available process and can also act as a load balancer.
HDFS ports
In the Hadoop ecosystem, components have different ports and communication happens by their respective ports. Usually, the port number will be hard to remember.
The default HDFS web UI ports are as summarized in Hortonworks docs at http://docs.hortonworks.com/HDPDocuments/HDP1/HDP-1.2.0/bk_reference/content/reference_chap2_1.html.
|
Service |
Servers |
Default Ports Used |
Protocol |
Description |
Need End User Access? |
Configuration Parameters |
|
NameNode WebUI |
Master Nodes (NameNode and any back-up NameNodes) |
50070 |
http |
Web UI to look at current status of HDFS, explore filesystem |
Yes (Typically admins, Dev/Support teams) |
dfs.http.address |
|
50470 |
https |
Secure http service |
dfs.https.address |
|||
|
NameNode metadata service |
Master Nodes (NameNode and any back-up NameNodes) |
8020/9000 |
IPC |
Filesystem metadata operations |
Yes (All clients who directly need to interact with HDFS) |
Embedded in URI specified by fs.default.name |
|
DataNode |
All Slave Nodes |
50075 |
http |
DataNode WebUI to access the status, logs etc. |
Yes (Typically admins, Dev/Support teams) |
dfs.datanode.http.address |
|
50475 |
https |
Secure http service |
dfs.datanode.https.address |
|||
|
50010 |
Data transfer |
dfs.datanode.address |
||||
|
50020 |
IPC |
Metadata operations |
No |
dfs.datanode.ipc.address |
||
|
Checkpoint NameNode or Secondary NameNode |
Secondary NameNode and any backup Secondary NameNode |
50090 |
http |
Checkpoint for NameNode metadata |
No |
dfs.secondary.http.address |
HDFS commands
The Hadoop command line environment is Linux-like. The Hadoop filesystem (fs) provides various shell commands to perform file operations such as copying file, viewing the contents of the file, changing ownership of files, changing permissions, creating directories, and so on.
The syntax of Hadoop fs shell command is as follows:
hadoop fs <args>
1. Create a directory in HDFS at the given path(s):
o Usage:
o hadoop fs -mkdir <paths>
o Example:
o hadoop fs -mkdir /user/shiva/dir1 /user/shiva/dir2
2. List the contents of a directory:
o Usage:
o hadoop fs -ls <args>
o Example:
o hadoop fs -ls /user/shiva
3. Put and Get a file in HDFS:
o Usage(Put):
o hadoop fs -put <localsrc> ... <HDFS_dest_Path>
o Example:
o hadoop fs -put /home/shiva/Samplefile.txt /user/shiva/dir3/
o Usage(Get):
o hadoop fs -get <hdfs_src> <localdst>
o Example:
o hadoop fs -get /user/shiva/dir3/Samplefile.txt /home/
4. See contents of a file:
o Usage:
o hadoop fs -cat <path[filename]>
o Example:
o hadoop fs -cat /user/shiva/dir1/abc.txt
5. Copy a file from source to destination:
o Usage:
o hadoop fs -cp <source> <dest>
o Example:
o hadoop fs -cp /user/shiva/dir1/abc.txt /user/shiva/dir2
6. Copy a file from/To Local filesystem to HDFS:
o Usage of copyFromLocal:
o hadoop fs -copyFromLocal <localsrc> URI
o Example:
o hadoop fs -copyFromLocal /home/shiva/abc.txt /user/shiva/abc.txt
o Usage of copyToLocal
o hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
7. Move file from source to destination:
o Usage:
o hadoop fs -mv <src> <dest>
o Example:
o hadoop fs -mv /user/shiva/dir1/abc.txt /user/shiva/dir2
8. Remove a file or directory in HDFS:
o Usage:
o hadoop fs -rm <arg>
o Example:
o hadoop fs -rm /user/shiva/dir1/abc.txt
o Usage of the recursive version of delete:
o hadoop fs -rmr <arg>
o Example:
o hadoop fs -rmr /user/shiva/
9. Display the last few lines of a file:
o Usage:
o hadoop fs -tail <path[filename]>
o Example:
o hadoop fs -tail /user/shiva/dir1/abc.txt
MapReduce
MapReduce is a massive parallel processing framework that processes faster, scalable, and fault tolerant data of a distributed environment. Similar to HDFS, Hadoop MapReduce can also be executed even in commodity hardware, and assumes that nodes can fail anytime and still process the job. MapReduce can process a large volume of data in parallel, by dividing a task into independent sub-tasks. MapReduce also has a master-slave architecture.
The input and output, even the intermediary output in a MapReduce job, are in the form of <Key, Value> pair. Key and Value have to be serializable and do not use the Java serialization package, but have an interface, which has to be implemented, and which can be efficiently serialized, as the data process has to move from one node to another. Key has to be a class that implements a WritableComparable interface, which is necessary for sorting the key, and Value has to be a class that implements a Writable interface.
The MapReduce architecture
MapReduce architecture has the following two daemon processes:
· JobTracker: Master process
· TaskTracker: Slave process
JobTracker
JobTracker is the master coordinator daemon process that is responsible for coordinating and completing a MapReduce job in Hadoop. The primary functions of JobTracker are resource management, tracking resource availability, and task process cycle. JobTracker identifies the TaskTracker to perform certain tasks and monitors the progress and status of a task. JobTracker is a single point of failure for the MapReduce process.
TaskTracker
TaskTracker is the slave daemon process that performs a task assigned by JobTracker. TaskTracker sends heartbeat messages to JobTracker periodically to notify about the free slots and sends the status to JobTracker about the task and checks if any task has to be performed.
Serialization data types
Serialization in MapReduce is extremely important as the data and intermediate data have to move from one TaskTracker to another on a very large scale. Java serialization is not optimized, as even for a smaller value, the object serializer will have higher size, which could be a bottleneck in Hadoop's performance as Hadoop processing requires a lot of data transfer. Hence, Hadoop doesn't use the Java serialization package and uses the Writable interface.
For serialization, Hadoop uses the following two interfaces:
· Writable interface (for values)
· WritableComparable interface (for key)
The Writable interface
The Writable interface is used for values for serialization and deserialization. Some of the classes that implement the Writable interface are ArrayWritable, BooleanWritable, ByteWritable, DoubleWritable, FloatWritable, IntWritable, LongWritable, MapWritable, NullWritable, ObjectWritable, ShortWritable, TupleWritable, VIntWritable, and VLongWritable.
We can create our own custom Writable class that can be used in MapReduce. For creating a class, we have to implement the Writable class and implement the following two methods:
· void write (DataOutput out): This serializes the object
· void readFields (DataInput in): This reads the input stream and converts it to an object
WritableComparable interface
WritableComparable is used for keys, which is inherited from the Writable interface and implements a comparable interface to provide comparison of value Objects. Some of the implementations are BooleanWritable, BytesWritable, ByteWritable, DoubleWritable, FloatWritable, IntWritable, LongWritable, NullWritable, ShortWritable, Text, VIntWritable, and VLongWritable.
We can create our own custom WritableComparable class that can be used in MapReduce. For creating a class, we have to implement WritableComparable class and implement the following three methods:
· void write (DataPutput out): This serializes the object
· void readFields (DataInput in): This reads the input stream and converts it to an object
· Int compareTo (Object obj): Compare the values required to sort the key
The MapReduce example
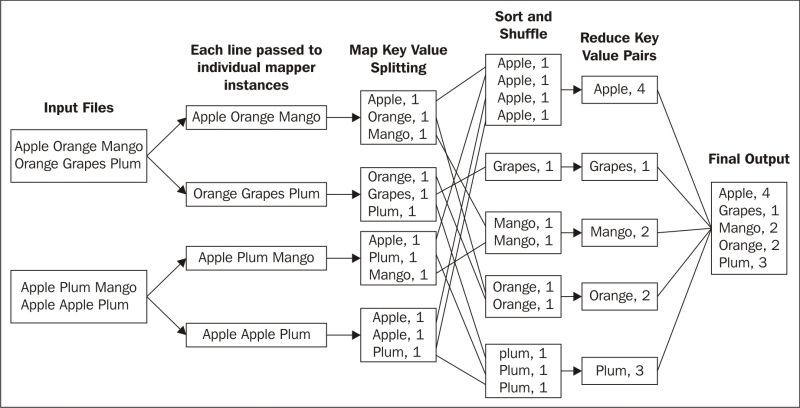
MapReduce is tricky to understand initially, so we will try to understand it with a simple example. Let's assume we have a file that has some words and the file is divided into blocks in HDFS, and we have to count the number of occurrences of a word in the file. We will go step by step to achieve the result using MapReduce functionality. The whole process is illustrated in the following diagram:
Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/supportand register to have the files e-mailed directly to you.
The following is the description of the preceding image:
1. Each block will be processed. Each line in the block will be sent as an input to the process. This process is called as Mapper.
Mapper parses the line, gets a word and sets <<word>, 1> for each word. In this example, the output of Mapper for a line Apple Orange Mango will be <Apple, 1>, <Orange, 1>, and <Mango, 1>. All Mappers will have key as word and value as 1.
2. The next phase is where the output of Mapper, which has the same key will be consolidated. So key with Apple, Orange, Mango, and others will be consolidated, and values will be appended as a list, in this case
<Apple, List<1, 1, 1, 1>>, <Grapes, List<1>>, <Mango, List<1, 1>>, and so on.
The key produced by Mappers will be compared and sorted. This step is called shuffle and sort. The key and list of values will be sent to the next step in the sorted sequence of the key.
3. The next phase will get <key, List<>> as input, and will just count the number of 1s in the list and will set the count value as output. This step is called as Reducer, for example, the output for the certain steps are given as follows:
o <Apple, List<1, 1, 1, 1>> will be <Apple, 4>
o <Grapes, List<1>> will be < Grapes, 1>
o <Mango, List<1, 1>> will be <Mango, 2>
4. The Reducer output will be consolidated to a file and will be saved in HDFS as the final output.
The MapReduce process
MapReduce frameworks have multiple steps and processes or tasks. For programmers, MapReduce abstracts most of them and, in many of the cases, only have to care about two processes; Map and Reduce and to coordinate the process, a Driver class program has to be written. In the Driver class, we can set various parameters to run a MapReduce job from input, Mapper class, Reducer class, output, and other parameters required for a MapReduce job to execute.
MapReduce jobs are complex and involve multiple steps; some steps are performed by Hadoop with default behavior and can be overridden if needed. The following are the mandatory steps performed in MapReduce in sequence:
1. Mapper
2. Shuffle and sorting
3. Reducer
The preceding process is explained in the following figure:
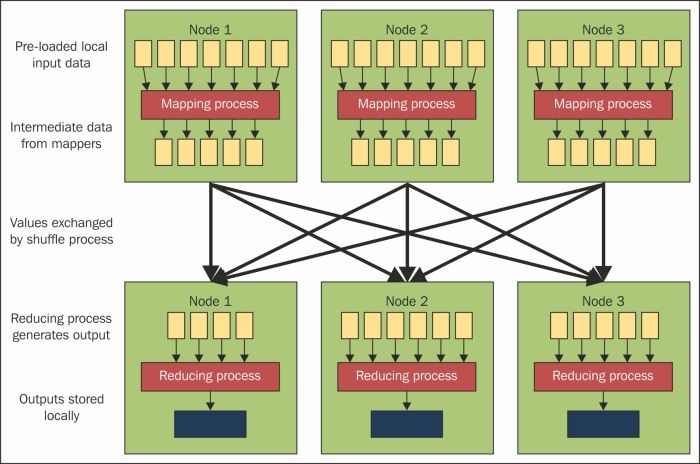
Image source: Hadoop Tutorial from Yahoo!
Mapper
In MapReduce, the parallelism will be achieved by Mapper, where the Mapper function will be present in TaskTracker, which will process a Mapper. Mapper code should have a logic, which can be independent of other block data. Mapper logic should leverage all the parallel steps possible in the algorithm. Input to Mapper is set in the Driver program of a particular InputFormat type and file(s) on which the Mapper process has to run. The output of Mapper will be a map <key, value>, key and value set in Mapper output is not saved in HDFS, but an intermediate file is created in the OS space path and that file is read and shuffle and sorting takes place.
Shuffle and sorting
Shuffle and sort are intermediate steps in MapReduce between Mapper and Reducer, which is handled by Hadoop and can be overridden if required. The Shuffle process aggregates all the Mapper output by grouping key values of the Mapper output and the value will be appended in a list of values. So, the Shuffle output format will be a map <key, List<list of values>>. The key from the Mapper output will be consolidated and sorted. The Mapper output will be sent to Reducer using the sorted key sequence by default a HashPartitioner, which will send the Mapper result in a round robin style of the sequence of number of reducers with the sorted sequence.
Reducer
In MapReduce, Reducer is the aggregator process where data after shuffle and sort, is sent to Reducer where we have <key, List<list of values >>, and Reducer will process on the list of values. Each key could be sent to a different Reducer. Reducer can set the value, and that will be consolidated in the final output of a MapReduce job and the value will be saved in HDFS as the final output.
Speculative execution
As we discussed, MapReduce jobs are broken into multiple Mapper and Reducer processes, and some intermediate tasks, so that a job can produce hundreds or thousands of tasks, and some tasks or nodes can take a long time to complete a task. Hadoop monitors and detects when a task is running slower than expectation, and if the node has a history of performing the task slower, then it starts the same task in another node as a backup, and this is called as speculative execution of tasks. Hadoop doesn't try to fix or diagnose the node or process, since the process is not giving an error, but it is slow, and slowness can occur because of hardware degradation, software misconfiguration, network congestion, and so on. For speculative execution, JobTracker monitors the tasks after all the tasks have been initiated and identifies slow performing tasks monitoring other running tasks. Once the slow performing task has been marked, JobTracker initiates the task in a different node and takes the result of the task that completes first and kills the other tasks and makes a note of the situation. If a node is consistently lagging behind, then JobTracker gives less preference to that node.
Speculative execution can be enabled or disabled, and by default it is turned on, as it is a useful process. Speculative execution has to monitor every task in some cases can affect the performance and resources. Speculation Execution is not advised in jobs where a task especially reducer can get millions of values due to skewness in data on a specific reducer which will take longer time than other tasks and starting another task will not help. Another case could be of a Sqoop process where a task imports the data and if it takes more than the usual time it can start same task in another node and will import the same data which will result in duplicate records.
FileFormats
FileFormats controls the input and output in MapReduce programs. Some FileFormats can be considered as data structures. Hadoop provides some implemented FileFormats, and we can write our own custom FileFormats too. We will have a look at them in the upcoming section.
InputFormats
The Mapper process steps provide the parallelism, and for faster processing, Mapper has to be designed optimally. For performing the data independently, Input data to Mapper is split into chunks called as InputSplit. InputSplit can be considered as a part of input data, where data can be processed independently. A Mapper processes on an InputSplit of data. Input to a MapReduce job has to be defined as a class implementing the InputFormat interface and RecordReader is sometimes necessary to read data between splits to identify independent chunks of data from the input data file.
Hadoop already has different types of InputFormat for the interpretation of various types of input data and reading the data from the input file. InputFormat splits the input file in fragments that are input to the map task. Examples of InputFormat classes implemented are as follows:
· TextInputFormat is used to read text files line by line
· SequenceFileInputFormat is used to read binary file formats
· DBInputFormat subclass is a class that can be used to read data from a SQL database
· CombineFileInputFormat is the abstract subclass of the FileInputFormat class that can be used to combine multiple files into a single split
We can create our own custom InputFormat classes by implementing the InputFormat interface or extending any class that implements InputFormats. Extending the class is preferred as many of the functions written are reusable, which helps in maintainability and reusability of a code. The class would have to override the following two functions:
· public RecordReader createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException
· protected boolean isSplitable(JobContext context, Path file)
RecordReader
InputFormat splits the data, but splits do not always end neatly at the end of a line. The RecordReader can allow data even if the line crosses the end of the split or else chances are of missing records that might have crossed the InputSplit boundaries.
The following figure explains the concept of RecordReader where the block size is 128 MB and the split size is 50 MB:
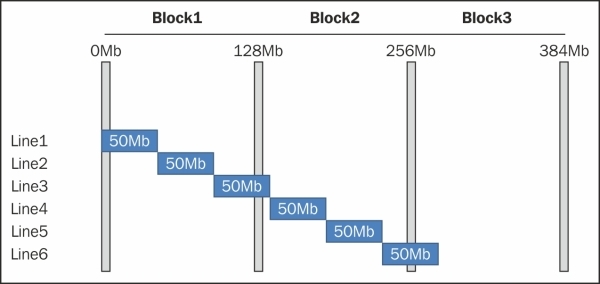
We can see that there are overlaps of data split between different blocks. Splits 1 and 2 can be read from Block1, but for split 3, RecordReader has to read locally from 101 MB to 128 MB and from 129 MB to 150 MB has to be read remotely from Block 2 and the merged data will be sent as an input to Mapper.
OutputFormats
OutputFormat implementation classes are responsible for writing the output and results of a MapReduce job, it gives control of how you want to write the record efficiently to optimize the result, and can be used to write the format of the data for inter-operability with other systems. The default OutputFormat is TextOutputFormat (we used this as an output to our WordCount example), which is key–value pair line separated and tab delimited. TextOutputFormat can be used in many use cases, but not in an optimized or efficient way, as it can waste space and can make the output size larger and increase the resource utilization. Hence, we can reuse some OutputFormats provided by Hadoop or can even write custom OutputFormats.
Some available OutputFormats that are widely used, are as follows:
1. FileOutputFormat (implements the interface OutputFormat) base class for all OutputFormats
o MapFileOutputFormat
o SequenceFileOutputFormat
SequenceFileAsBinaryOutputFormat
o TextOutputFormat
o MultipleOutputFormat
MultipleTextOutputFormat
MultipleSequenceFileOutputFormat
2. SequenceOutputFormat can be used for binary representation of the object, which it compresses and writes as an output. OutputFormats use the implementation of RecordWriter to actually write the data.
RecordWriter
RecordWriter interface provides more control to write the data as we want. RecordWriter takes the input as key-value pair and can translate the format of the data to write.
RecordWriter is an abstract class, which has two methods to be implemented, as shown in the following:
abstract void write(K key, V value) Writes a key/value pair.
abstract void close(TaskAttemptContext context) Close this RecordWriter to future operations.
The default RecordWriter is LineRecordWriter.
Writing a MapReduce program
A MapReduce job class will have the following three mandatory classes or tasks:
· Mapper: In the Mapper class, the actual independent steps are written, which are parallelized to run in independent sub-tasks
· Reducer: In the Reducer class, the aggregation of the Mapper output takes place and the output is written in HDFS
· Driver: In the Driver class, we can set various parameters to run a MapReduce job from input, Mapper class, Reducer class, output, and other parameters required for a MapReduce job to execute
We have already seen the logic of a simple WordCount example to illustrate how MapReduce works. Now, we will see how to code it in the Java MapReduce program.
Mapper code
A Mapper class has to extend
org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>.
The following is the snippet of the Mapper class code:
// And override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer token = new StringTokenizer(value.toString());
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
In a map function, the input value (Apple, Orange, Mango) has to be tokenized, and the tokenized word will be written as Mapper key and value as 1. Note that value 1 is IntWritable.
Reducer code
A Reducer class has to extend
org.apache.hadoop.mapreduce.Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>.
The following is the code for WordCountReducer:
// and override reduce function
protected void reduce(KEYIN key, Iterable<VALUEIN> values,
org.apache.hadoop.mapreduce.Reducer.Context context)
throws IOException, InterruptedException
public static class WordCountReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable count = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
count.set(sum);
context.write(key, count);
}
}
Reducer input will be <word, List<1,1,…>> for WordCount Reducer has to sum the list of values and write the value. Reducer output will be the key as word and value as count.
Driver code
Driver code in MapReduce will be mostly boiler plate code with just changes in the parameters, and may need to set some Auxiliary class, as shown in the following:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
Driver code has to create an instance of the Configuration object, which is used to get an instance of Job class. In Job class, we can set the following:
· MapperClass
· ReducerClass
· OutputKeyClass
· OutputValueClass
· InputFormat
· OutputFormat
· JarByClass
The whole program of WordCount is as follows:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class WordCountMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer token = new StringTokenizer(value.toString());
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable count = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
count.set(sum);
context.write(key, count);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Compile WordCount.java and create a jar.
Run the application:
$ bin/hadoop jar wc.jar WordCount /input /user/shiva/wordcount/output
Output:
$ bin/hdfs dfs -cat /user/shiva/wordcount/output/part-r-00000
Auxiliary steps
Along with Mapper, shuffle and sort, and Reducer, there are other auxiliary steps in MapReduce that can be set, or a default implementation can be overridden to process the MapReduce job. The following are some processes which we will discuss:
· Combiner
· Partitioner
The preceding points are discussed in the following figure:
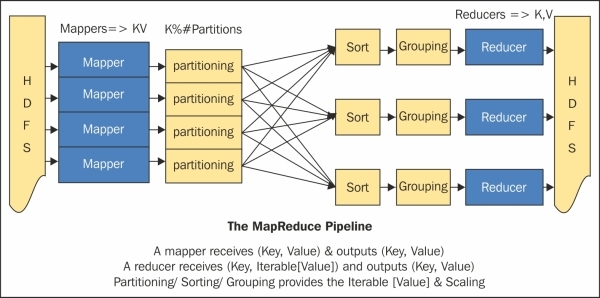
Combiner
Combiners are node-local reducers. Combiners are used to reduce the number of key values set by Mapper, and we can reduce the number of data sent for shuffling. Many programs would have Reducer as the Combiner class and can have a different implementation from Reducer if needed, The combiner is specified for a job using job.setCombinerClass(CombinerClassName).
Combiner should have the same input/output key and value types as the output types of your Mapper. Combiners can only be used on the functions that are commutative (a.b = b.a) and associative {a. (b.c) = (a.b).c}.
In the WordCount example, we can use a combiner, which can be the same as the Reducer class and will improve the performance of the job.
Combiner will not always be processed by JobTracker. If the data in Mapper spills out then Combiner will surely be called.
Partitioner
Partitioner is responsible for sending specific key-value pairs to specific reducers. HashPartitioner is the default Partitioner, which hashes a record's key to determine which partition the record belongs to, in a round robin fashion, according to the number of Reducers, if specified, or the number of partitions is then equal to the number of reduce tasks for the job. Partitioning is sometimes required to control the key-value pairs from Mapper to move to particular Reducers. Partitioning has a direct impact on the overall performance of the job we want to run.
Custom partitioner
Suppose we want to sort the output of the WordCount on the basis of the number of occurrences of tokens. Assume that our job will be handled by two reducers, as shown in the following:
Setting Number of Reducer: We can specify that by using job.setNumReduceTasks(#NoOfReducucer).
If we run our job without using any user defined Partitioner, we will get output like the following:
|
Count |
Word |
Count |
Word |
|
1 |
The |
2 |
a |
|
3 |
Is |
4 |
because |
|
6 |
As |
5 |
of |
|
Reducer 1 |
Reducer 2 |
||
This is a partial sort, which is the default behavior of HashPartitioner. If we use the correct partitioning function, we can send a count less than, or equal to, 3 to a reducer and higher to another, and we have to set setNumReduceTasksas 2. We will get the total order on the number of occurrences.
The output would look like the following:
|
Count |
Word |
Count |
Word |
|
1 |
The |
4 |
because |
|
2 |
A |
5 |
as |
|
3 |
Is |
6 |
of |
|
Reducer 1 |
Reducer 2 |
||
Let's look at how can we write a custom Partitioner class, as shown in the following:
public static class MyPartitioner extends org.apache.hadoop.mapreduce.Partitioner<Text,Text>
{
@Override
public int getPartition(Text key, Text value, int numPartitions)
{
int count =Integer.parseInt(line[1]);
if(count<=3)
return 0;
else
return 1;
}
}
And in Driver class
job.setPartitionerClass(MyPartitioner.class);
YARN
YARN is Yet Another Resource Negotiator, the next generation compute and cluster management technology. YARN provides a platform to build/run multiple distributed applications in Hadoop. YARN was released in the Hadoop 2.0 version in 2012, marking a major change in Hadoop architecture. YARN took around 5 years to develop in an open community.
We discussed JobTracker being a single point of failure for MapReduce, and considering Hadoop is designed to run even in commodity servers, there is a good probability that the JobTracker can fail. JobTracker has two important functions: resource management, and job scheduling and monitoring.
YARN delegates and splits up the responsibility into separate daemons and achieves better performance and fault tolerance. Because of YARN, Hadoop, which could work only as a batch process, can now be designed to process interactive and real-time processing systems. This is a huge advantage as many systems, machines, sensors, and other sources generate huge data continuously streaming and YARN can process this data, as depicted in the following figure:
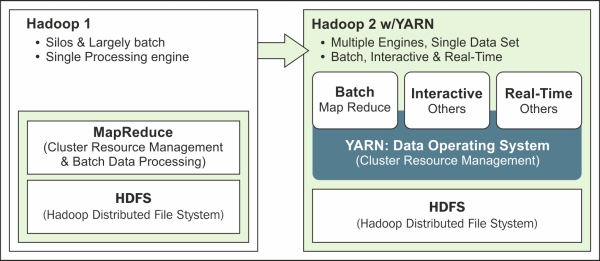
Image source: http://hortonworks.com/wp-content/uploads/2013/05/yarn.png
YARN architecture
YARN architecture is extremely scalable, fault tolerant, and processes data faster as compared to MapReduce 1.x. YARN focuses on high availability and utilization of resources in the cluster. YARN architecture has the following three components:
· ResourceManager (RM)
· NodeManager (NM)
· ApplicationMaster (AM)
YARN architecture is illustrated in the following image:
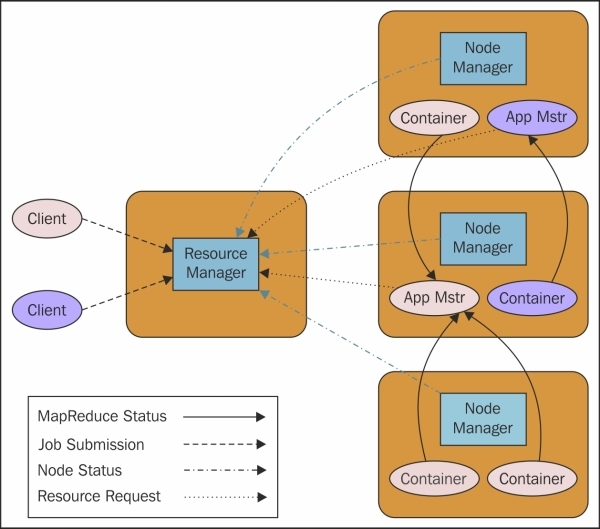
Image source: http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html.
ResourceManager
In YARN, ResourceManager is the master process manager responsible for resource management among the applications in the system. ResourceManager has a scheduler, which only allocates the resources to the applications and resource availability which ResourceManager gets from containers that provide information such as memory, disk, CPU, network, and so on.
NodeManager
In YARN, NodeManager is present in all the nodes, which is responsible for containers, authentication, monitoring resource usage, and reports the information to ResourceManager. Similar to TaskTracker, NodeManager sends heartbeats to ResourceManager.
ApplicationMaster
ApplicationMaster is present for each application, responsible for managing each and every instance of applications that run within YARN. ApplicationMaster coordinates with ResourceManager for the negotiation of the resources and coordinates with the NodeManager to monitor the execution and resource consumption of containers, such as resource allocations of CPU, memory, and so on.
Applications powered by YARN
Below are some of the applications that have adapted YARN to leverage its features and achieve high availability:
· Apache Giraph: Graph processing
· Apache Hama: Advanced Analytics
· Apache Hadoop MapReduce: Batch processing
· Apache Tez: Interactive/Batch on top of Hive
· Apache S4: Stream processing
· Apache Samza: Stream processing
· Apache Storm: Stream processing
· Apache Spark: Realtime Iterative processing
· Hoya: Hbase on YARN
Summary
In this chapter, we have discussed HDFS, MapReduce, and YARN in detail.
HDFS is highly scalable, fault tolerant, reliable, and portable, and is designed to work even on commodity hardwares. HDFS architecture has four daemon processes, which are NameNode, DataNode, Checkpoint NameNode, and Backup Node. HDFS has a lot of complex design challenges, which are managed by different techniques such as Replication, Heartbeat, Block concept, Rack Awareness, and Block Scanner, and HDFS Federation makes HDFS highly available and fault tolerant.
Hadoop MapReduce is also highly scalable, fault tolerant, and designed to work even in commodity hardwares. MapReduce architecture has a master JobTracker and multiple worker TaskTracker processes in the Nodes. MapReduce jobs are broken into multistep processes, which are Mapper, Shuffle, Sort, Reducer, and auxiliary Combiner and Partitioner. MapReduce jobs needs a lot of data transfer, for which Hadoop uses Writable and WritableComparable interfaces. MapReduce FileFormats has an InputFormat interface, RecordReader, OutputFormat, and RecordWriter to improve the processing and efficiency.
YARN is a distributed resource manager to manage and run different applications on top of Hadoop, and provides much needed enhancements to the MapReduce framework, that can make Hadoop much more available, scalable, and integrable. YARN Architecture has the following components: ResourceManager, NodeManager, and ApplicationMaster. Many applications are built on top of YARN, which has made Hadoop much more stable and integrable with other applications.
In the next chapter, we will cover Data Access component technologies, which are used in the Hadoop ecosystem, such as Hive and Pig, as it helps to ease the programming model and makes it faster and more maintainable.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.