Hadoop Essentials (2015)
Chapter 7. Streaming and Real-time Analysis – Storm and Spark
As we have already discussed about Hadoop being a Batch processing system and some data source types that varies in their velocity or rate, volume of data. Many system especially machines generates a lot of data consistently, they need to process such high volume data to maintain quality and avoid heavy loss and thus the need for Stream processing has emerged. To design systems that are built as Lambda implementation, which are Batch as well as Stream processing systems, We should have combination of different environment that can integrate with each other to process the data and quite obviously which increases the complexity of designing the system. Streaming data is complex to store, analyze, process, and maintain. Prior to version 2.x, Hadoop was only a Batch processing system, and after the emergence of YARN and other frameworks and the integration of those frameworks with YARN, Hadoop can be designed for streaming and real-time analysis with better performance. Various initiatives and contributions have elevated the capability of Hadoop with its integration with systems such as Storm and Spark.
In this chapter, we will cover the paradigms of Storm and Spark frameworks, in order to process streaming and conduct real-time analysis efficiently.
An introduction to Storm
Storm can process streaming data really fast (clocked at over one million messages per second per node); it is scalable (thousands of worker nodes of cluster), fault tolerant, and reliable (message processing is guaranteed). Storm is easy to use and deploy, which also eases its maintainability. Hadoop is primarily designed for batch processing and for Lambda Architecture systems. Storm is well-integrated with Hadoop, in order to provide distributed real-time streaming analysis reliably with good fault tolerance for big data.
Storm was developed by Twitter and later contributed to Apache. Storm's benchmark results are quite outstanding at over a million sets of data called tuples processed per second per node. Storm utilizes a Thrift interface; hence, the client can be written in any language and even non-JVM language communicates over JSON-based protocol. Considering the complexity of Storm, it is a fairly easy-to-use API.
Features of Storm
Some important features of Storm are as follows:
· Simple programming model
· Free and open source
· Can be used with any language
· Fault-tolerant
· Distributed and horizontally scalable—runs across a cluster of machines in parallel
· Reliable—guaranteed message processing
· Fast—processes streaming data in real time
· Easy to deploy and operate
Physical architecture of Storm
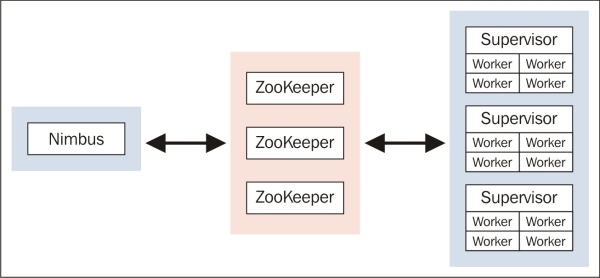
Storm architecture is based on the master-slave model and utilizes Zookeeper for coordination between the master and slaves. It is composed of four components:
· Nimbus: Master process that distributes processing across clusters
· Supervisor: Manages worker nodes
· Worker: Executes tasks assigned by Nimbus
· Zookeeper: Coordinates between Nimbus and Supervisors
Workers send heartbeats to Supervisors and Nimbus via Zookeeper. If a Worker or Supervisor is not able to respond, then Nimbus reassigns the work to another node in the cluster, which is shown in the following figure:
Data architecture of Storm
Storm data architecture has the following terminologies:
· Spout: Produces Stream or data source
· Bolt: Ingests the Spout tuples then processes it and produces output stream; it can be used to filter, aggregate, or join data, or talk to databases
· Topology: A network graph between Spouts and Bolts
The following figure explains the preceding points:
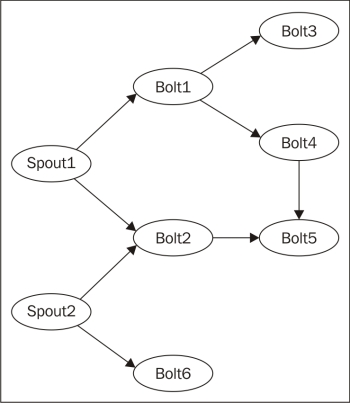
The data level abstractions in Storm are:
· Tuple: The basic unit of Storm data—a named list of values
· Stream: An unbounded sequence of tuples
The following figure shows the spouts producing streams and bolts processing the tuples or streams to produce different streams:
Storm topology
Streams can be partitioned among bolts by using stream grouping, which allows the streams to be routed towards a bolt. Storm provides the following built-in stream groupings, and you can implement a custom stream grouping by implementing the interface:
· Shuffle grouping: Each bolt is configured uniformly to get an almost equal number of tuples
· Fields grouping: Grouping on a particular field is possible to consolidate the tuples of the same field value and different value tuples to different bolts
· All grouping: Each tuple can be sent to all the bolts but can increase the overhead
· Global grouping: All the tuples go to a single bolt
· Direct grouping: The producer can decide which tuples to be sent to which bolt
Storm on YARN
Storm integration on YARN was done in Yahoo and released as an open source. Storm can be integrated with YARN to provide batch and real-time analysis on the same cluster as Lambda architecture. Storm on YARN couples Storm's event-processing framework with Hadoop to provide low latency processing. Storm resources can be managed by YARN to provide all the benefits of stream processing by Storm on Hadoop. Storm on YARN provides high availability, optimization, and elasticity in resource utilization.
Topology configuration example
Storm topology can be configured by the TopologyBuilder class by creating spouts and bolts, and then by submitting the topology.
Spouts
Some implementations of spouts are available in Storm, such as BaseRichSpout, ClojureSpout, DRPCSpout, FeederSpout, FixedTupleSpout, MasterBatchCoordinator, RichShellSpout, RichSpoutBatchTriggerer, ShellSpout, SpoutTracker, TestPlannerSpout, TestWordSpout, and TransactionalSpoutCoordinator.
We can write a custom bolts by extending any of the aforementioned classes or implementing the ISpout interface:
public class NumberSpout extends BaseRichSpout
{
private SpoutOutputCollector collector;
private static int currentNumber = 1;
@Override
public void open( Map conf, TopologyContext context, SpoutOutputCollector collector )
{
this.collector = collector;
}
@Override
public void nextTuple()
{
// Emit the next number
collector.emit( new Values( new Integer( currentNumber++ ) ) );
}
@Override
public void ack(Object id)
{
}
@Override
public void fail(Object id)
{
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare( new Fields( "number" ) );
}
}
Bolts
Some implementations of bolts are available in Storm, such as BaseBasicBolt, BatchProcessWord, BatchRepeatA, IdentityBolt, PrepareBatchBolt, PrepareRequest, TestConfBolt, TestWordCounter, and TridentSpoutCoordinator.
We can write a custom bolt by extending any of the aforementioned classes or implementing the IBasicBolt interface:
public class PrimeNumberBolt extends BaseRichBolt
{
private OutputCollector collector;
public void prepare( Map conf, TopologyContext context, OutputCollector collector )
{
this.collector = collector;
}
public void execute( Tuple tuple )
{
int number = tuple.getInteger( 0 );
if( isPrime( number) )
{
System.out.println( number );
}
collector.ack( tuple );
}
public void declareOutputFields( OutputFieldsDeclarer declarer )
{
declarer.declare( new Fields( "number" ) );
}
private boolean isPrime( int n )
{
if( n == 1 || n == 2 || n == 3 )
{
return true;
}
// Is n an even number?
if( n % 2 == 0 )
{
return false;
}
//if not, then just check the odds
for( int i=3; i*i<=n; i+=2 )
{
if( n % i == 0)
{
return false;
}
}
return true;
}
}
Topology
The TopologyBuilder class can be used to configure the spouts and bolts and to submit the topology, as shown in this example:
public class PrimeNumberTopology
{
public static void main(String[] args)
{
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout( "spout", new NumberSpout() );
builder.setBolt( "prime", new PrimeNumberBolt() )
.shuffleGrouping("spout");
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
An introduction to Spark
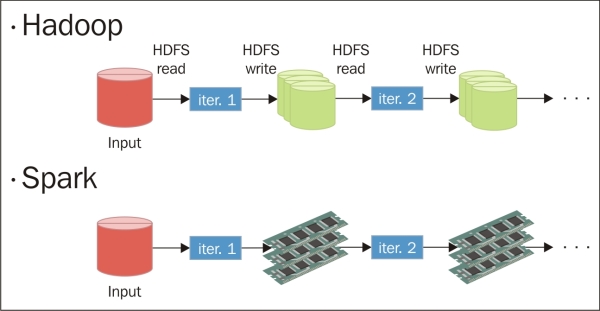
Spark is a cluster computing framework, which was developed in AMPLab at UC Berkley and contributed as an open source project to Apache. Spark is an in-memory based data processing framework, which makes it much faster in processing than MapReduce. In MapReduce, intermediate data is stored in the disk and data access and transfer makes it slower, whereas in Spark it is stored in-memory. Spark can be thought of as an alternative to MapReduce due to the limitations and overheads of the latter, but not as a replacement. Spark is widely used for streaming data analytics, graph analytics, fast interactive queries, and machine learning. It has attracted the attention of many contributors due to its in-memory nature and actually was one of the top-level Apache projects in 2014 with over 200 contributors and 50+ organizations. Spark utilizes multiple threads instead of multiple processes to achieve parallelism on a single node.
Spark's main motive was to develop a processing system that would be faster and easier to use and could be used for analytics. Its programming follows more of the Directed Acyclic Graph (DAG) pattern, in which multi-step data flows and is complex, which is explained in the following figure:
Features of Spark
Spark has numerous features and capabilities worth mentioning, as follows:
· Runs 100 times faster than MapReduce when running in-memory and 10 times faster when running on disk
· Can process iterative and interactive analytics
· Many functions and operators available for data analysis
· DAG framework to design functions easily
· In-memory based intermediate storage
· Easy to use and maintain
· Written in Scala and runs in JVM environment; applications using Spark can be written in Scala, Java, Python, R, Clojure
· Runs in environments such as Hadoop and Mesos, or standalone, or in cloud
Spark framework
Spark contributors have utilized the core Spark framework and have developed different libraries on top of Spark to enhance its capabilities. These libraries can be plugged in to Spark as per the requirement:
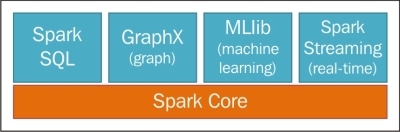
Spark SQL
Spark SQL is a wrapper of SQL on top of Spark. It transforms SQL queries into Spark jobs to produce results. Spark SQL can work with a variety of data sources, such as Hive tables, Parquet files, and JSON files.
GraphX
GraphX, as the name suggests, enables working with graph-based algorithms. It has a wide variety of graph-based algorithms already implemented and is still growing. Some examples are PageRank, Connected components, Label propagation, SVD++, strongly connected components, Triangle count, and so on.
MLib
MLib is a scalable machine learning library that works on top of Spark. It is considerably easier to use and deploy, and its performance can be optimized to be 100 times faster than MapReduce.
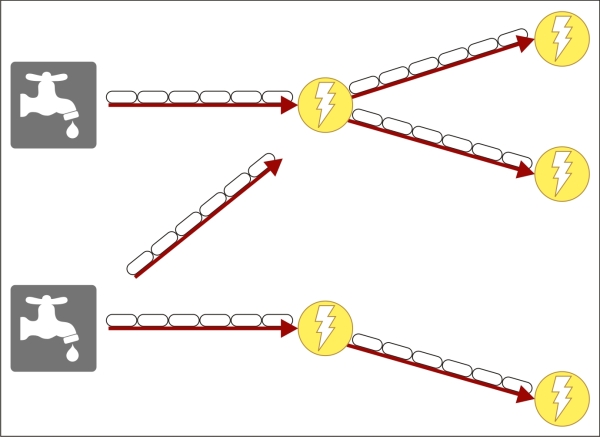
Spark streaming
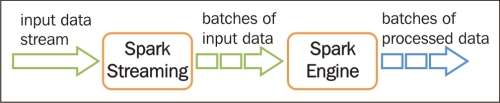
Spark streaming is a library that enables Spark to perform scalable, fault-tolerant, high throughput system to process streaming data in real time. Spark Streaming is well integrated with many sources, such as Kinesis, HDFS, S3, Flume, Kafka, Twitter, and so on, which is shown in the following figure:

Spark streaming can be integrated with MLib and GraphX to process their algorithms or libraries in streaming data. Spark streaming ingests the input data from a source and breaks it into batches. The batch is stored as an internal dataset (RDD—we will look at it in detail) for processing, which is explained in the following figure:
Spark architecture
Spark architecture is based on a DAG engine and its data model works on Resilient Distributed Dataset (RDD), which is its USP with a large number of benefits in terms of performance. In Spark the computations are performed lazily, which allows the DAG engine to identify the step or computation that is not needed for the end result and is not performed at all, thus improving performance.
Directed Acyclic Graph engine
Spark has an advanced DAG engine that manages the data flow. A job in Spark is transformed in a DAG with task stages and the graph is then optimized. The tasks identified are then analyzed to check if they can be processed in one stage or multiple stages. Task locality is also analyzed to optimize the process.
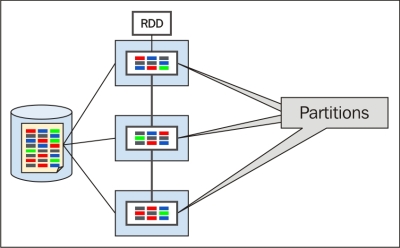
Resilient Distributed Dataset
As per the white paper "Resilient Distributed Datasets, a Fault-Tolerant Abstraction for In-Memory Cluster Computing." Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica on April 2012. This paper has also received Best Paper Award and Honorable Mention for Community Award. An RDD is a read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (a) data in stable storage or (b) other RDDs.
RDDs are an 'immutable resilient distributed collection of records, which can be stored in the volatile memory or in a persistent storage (HDFS, HBase, and so on) and can be converted into another RDD through some transformations. An RDD stores the data in-memory as long as possible. If the data grows larger than the threshold, it spills into the disk. Due to this, the computation becomes faster. On the other hand, if some node holding the data in memory fails, then that part of computations has to be processed again. To avoid this, check pointing is performed after some stages, which is shown in the following figure:
RDDs are of two types:
· Parallelized collections: Created by invoking SparkContext's parallelize method
· Hadoop datasets: Created from HDFS files
An RDD can perform either transformation or actions. Transformations can be used for some filters or map functions. Actions can return a value after some executions, such as reduce or count.
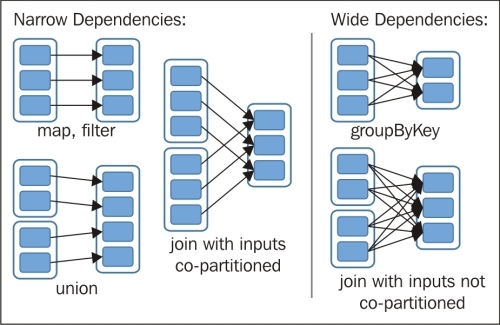
An RDD can have two types of dependencies: narrow and wide. Narrow dependencies occur when a partition of an RDD is used by only one partition of the next RDD. Wide dependencies occur when a partition of an RDD is used by multiple partitions in the next RDD usually in groups and joins. The following figure shows the two types of dependencies:
The features of RDDs are as follows:
· Resilient and fault tolerant; in case of any failure they can be rebuilt according to the data stored
· Distributed
· Datasets partitioned across cluster nodes
· Immutable
· Memory-intensive
· Caching levels configurable according to the environment
Physical architecture
Spark's physical architecture components are composed of Spark Master and Spark Worker, where as Hadoop Spark Worker sits on the data nodes. Spark Master controls the workflow and it is highly available on top of YARN. We can configure a backup Spark Master for easy failover. Spark Worker launches appropriate executors for each task, which is shown in the following figure:
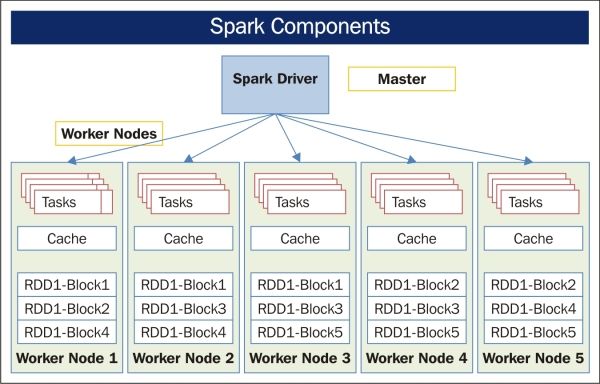
In deployment, one analytics node runs the Spark Master, and Spark Workers run on each of the nodes.
Operations in Spark
RDDs support two types of operations:
· Transformations
· Actions
Transformations
The transformation operation performs some functions and creates another dataset. Transformations are processed in the lazy mode and only those transformations that are needed in the end result are processed. If any transformation is found unnecessary, then Spark ignores it, and this improves the efficiency.
Transformations, which are available and mentioned in Spark Apache docs at https://spark.apache.org/docs/latest/programming-guide.html#transformations, are as follows:
|
Transformation |
Meaning |
|
map (func) |
Return a new distributed dataset formed by passing each element of the source through a function func. |
|
filter (func) |
Return a new dataset formed by selecting those elements of the source on which func returns true. |
|
flatMap (func) |
Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
|
mapPartitions (func) |
Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator[T] => Iterator[U] when running on an RDD of type T. |
|
mapPartitionsWithSplit (func) |
Similar to mapPartitions, but also provides func with an integer value representing the index of the split, so func must be of type (Int, Iterator[T]) => Iterator[U] when running on an RDD of type T. |
|
Sample (withReplacement,fraction, seed) |
Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
|
Union (otherDataset) |
Return a new dataset that contains the union of the elements in the source dataset and the argument. |
|
Distinct ([numTasks])) |
Return a new dataset that contains the distinct elements of the source dataset. |
|
groupByKey ([numTasks]) |
When called on a dataset of (K, V) pairs, returns a dataset of (K, Seq[V]) pairs. Note: By default, this uses only eight parallel tasks to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
|
reduceByKey (func, [numTasks]) |
When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values of each key are aggregated using the given reduce function. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
|
sortByKey ([ascending], [numTasks]) |
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs, sorted by keys in ascending or descending order, as specified in the Boolean ascending argument. |
|
Join (otherDataset, [numTasks]) |
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. |
|
Cogroup (otherDataset, [numTasks]) |
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, Seq[V], Seq[W]) tuples. This operation is also called groupWith. |
|
Cartesian (otherDataset) |
When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
Actions
Action operations produce and return a result. An action's result is actually written to an external storage system. Actions available and mentioned in Spark Apache docs, mentioned at https://spark.apache.org/docs/latest/programming-guide.html#actions are as follows:
|
Action |
Meaning |
|
Reduce (func) |
Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative, so that it can be computed correctly in parallel. |
|
Collect () |
Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
|
Count () |
Return the number of elements in the dataset. |
|
First () |
Return the first element of the dataset (similar to take(1)). |
|
Take (n) |
Return an array with the first n elements of the dataset. Note that this is currently not executed in parallel. Instead, the driver program computes all the elements. |
|
takeSample (withReplacement,num, seed) |
Return an array with a random sample of num elements of the dataset, with or without replacement, using the given random number generator seed. |
|
saveAsTextFile (path) |
Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS, or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
|
saveAsSequenceFile (path) |
Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS, or any other Hadoop-supported file system. This is only available on RDDs of key-value pairs that either implement Hadoop's Writable interface or are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, and so on). |
|
countByKey () |
Only available on RDDs of type (K, V). Returns a Map of (K, Int) pairs with the count of each key. |
|
Foreach (func) |
Run a function func on each element of the dataset. This is usually done for side effects such as updating an accumulator variable (see below) or interacting with external storage systems. |
Spark example
For simplicity, let's take Word count as an example in Spark.
In Scala:
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
In Java:
JavaRDD<String> file = spark.textFile("hdfs://...");JavaRDD<String> words = file.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" ")); }
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1); }});
JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer>() {
public Integer call(Integer a, Integer b) {
return a + b; }});
counts.saveAsTextFile("hdfs://...");
Summary
Streaming and real-time analysis are required in many systems in big data. Batch processing is very well handled by Hadoop and integration of frameworks like Storm and Spark elevates their streaming and real-time capability.
We discussed that Storm is an open source, fast, stream processing, scalable, fault-tolerant, and reliable system that is easy to use and deploy. Storm's physical architecture comprises Nimbus, Supervisor, Worker, and Zookeeper processes. The data architecture of Storm comprises a spouts, bolts, and topology-based data flow system.
Spark is an extremely popular framework which provides in-memory data handling capability and makes it much faster than the MapReduce framework. Spark frameworks have some libraries such as Spark SQL, GraphX, MLib, Spark Streaming, and others to process specialized data and requirements. Spark Architecture is based on RDDs and the DAG engine, which provides capability of in-memory data processing and optimizes the processing, according to the data flow effectively and efficiently. Spark RDD can perform numerous transformations and actions.
Finally, we have come to the last chapter and have covered different sets of tools and utilities within the Hadoop Ecosystem. I hope that the book will be useful to you and give you a quick heads-up about the components and essential details, as well as how to use them.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.