Hadoop Essentials (2015)
Chapter 6. Data Ingestion in Hadoop – Sqoop and Flume
Data ingestion is critical and should be emphasized for any big data project, as the volume of data is usually in terabytes or petabytes, maybe exabytes. Handling huge amounts of data is always a challenge and critical. As big data systems are popular to process unstructured or semi-structured data, this brings in complex and many data sources that have huge amount of data. With each data source, the complexity of system increases. Many domains or data types such as social media, marketing, genes in healthcare, video and audio systems, telecom CDR, and so on have diverse sources of data. Many of these produce or send data consistently on a large scale. The key issue is to manage the data consistency and how to leverage the resource available. Data ingestion, in particular, is complex in Hadoop or generally big data as data sources and processing are now in batch, stream, real-time. This also increases the complexity and management.
In this chapter, we will look at some of the challenges in data ingestion in Hadoop and possible solutions of using tools like Sqoop and Flume. We will cover Sqoop and Flume in detail.
Data sources
Due to the capability of processing variety of data and volume of data, data sources for Hadoop has increased and along with that the complexity has increased enormously. We now see huge amount of batch and streaming and real-time analysis processed in Hadoop, for which data ingestion can become a bottleneck or can break a system, if not designed according to the requirement.
Let's look at some of the data sources, which can produce enormous volume of data or consistent data continuously:
· Data sensors: These are thousands of sensors, producing data continuously.
· Machine Data: Produces data which should be processed in near real time for avoiding huge loss.
· Telco Data: CDR data and other telecom data generates high volume of data.
· Healthcare system data: Genes, images, ECR records are unstructured and complex to process.
· Social Media: Facebook, Twitter, Google Plus, YouTube, and others get a huge volume of data.
· Geological Data: Semiconductors and other geological data produce huge volumes of data.
· Maps: Maps have a huge volume of data, and processing data is also a challenge in Maps.
· Aerospace: Flight details and runway management systems produce high-volume data and processing in real time.
· Astronomy: Planets and other objects produce heavy images, which have to be processed at a faster rate.
· Mobile Data: Mobile generates many events and a huge volume of data at a high velocity rate.
These are just some domains or data sources that produce data in Terabytes or Exabytes. Data ingestion is critical and can make or break a system.
Challenges in data ingestion
The following are the challenges in data source ingestion:
· Multiple source ingestion
· Streaming / real-time ingestion
· Scalability
· Parallel processing
· Data quality
· Machine data can be on a high scale in GB per minute
Sqoop
Sqoop can process data transfer between traditional databases, Hadoop, and NoSQL database like HBase and Cassandra efficiently. Sqoop helps by providing a utility to import and export data in Hadoop from these data sources. Sqoop helps in executing the process in parallel and therefore in much faster speed. Sqoop utilizes connectors and drivers to connect with the underlying database source, and executes the import and export in multiple Mapper process, in order to execute the data in parallel and faster. Sqoop can process bulk data transfers on HDFS, Hive, or HBase.
Connectors and drivers
Sqoop utility needs drivers and connectors for data transfer between a database and Hadoop. One of the important step in configuring Sqoop is to get the driver and configure it with Sqoop. Drivers are required by Sqoop to connect with them and should be the JDBC drivers for Sqoop 1 that are provided by the database vendor for the respective database. Drivers are not shipped with Sqoop as some drivers are licensed, hence we have to get the JDBC driver of the database and keep it in the Sqoop library. Connectors are required to optimize the data transfer by getting metadata information of the database. All RDBMS Databases use SQL, but some commands and syntax vary with other databases. This makes it difficult to get the metadata and optimize the data. Sqoop provides generic connectors that will work with databases such as MySQL, Oracle, PostgreSQL, DB2, and SQL Server, but are not optimal. For optimal performance, some vendors have released their connectors that can be plugged with Sqoop, which is shown in the following figure:
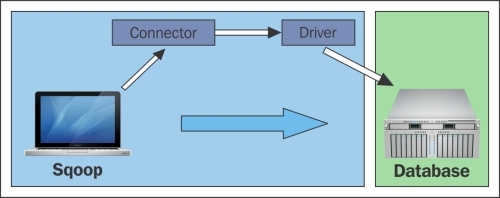
Sqoop 1 architecture
Sqoop1 architecture is a client-side tool, which is tightly coupled with the Hadoop cluster. A Sqoop command initiated by the client fetches the metadata of the tables, columns, and data types, according to the connectors and drivers interfaces. The import or export is translated to a Map-only Job program to load the data in parallel between the databases and Hadoop. Clients should have the appropriate connector and driver for the execution of the process.
The Sqoop architecture is shown in the following figure:
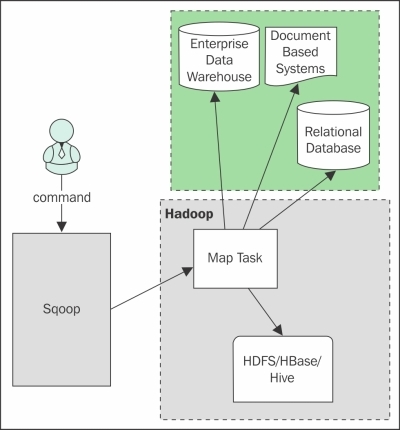
Limitation of Sqoop 1
Few limitations that were realized after a wide adaptation of Sqoop 1 for data ingestion led to Sqoop 2, which were:
· Connectors have to support the serialization format, otherwise Sqoop cannot transfer data in that format and connectors have to be JDBC drivers. Some database vendors do not provide it.
· Not easy to configure and install.
· Monitoring and debugging is difficult.
· Security concerns as Sqoop 1 requires root access to install and configure it.
· Only the command line argument is supported.
· Connectors are only JDBC-based.
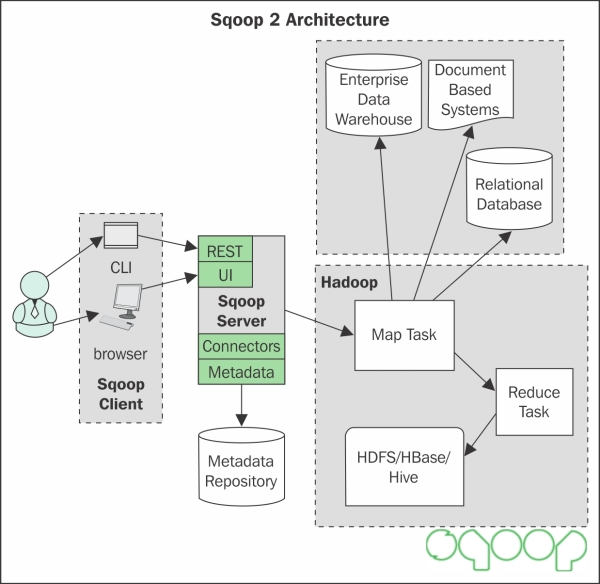
Sqoop 2 architecture
Sqoop 2 architecture overcomes the limitations of Sqoop 1, which we discussed earlier. The features of Sqoop 2 are:
· Sqoop 2 exposes REST API as a web service, which can be easily integrated with other systems.
· The connectors and drivers are managed centrally in one place.
· Sqoop 2 is well configured and integrated with HBase, Hive, and Oozie for interoperability and management.
· Connectors can be non-JDBC based.
· As a service-oriented design, Sqoop 2 can have role-based authentication and audit trail logging to increase the security.
The following is an architecture of Sqoop 2:
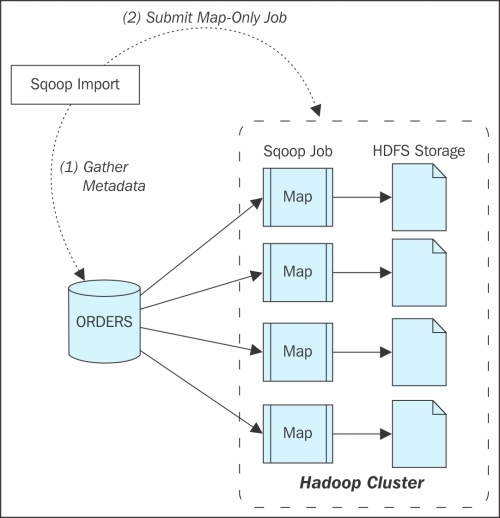
Imports
Sqoop import is executed in two steps:
1. Gather metadata
2. Submit map only job
The following figure explains the import in to Sqoop:
Sqoop import provides the following options:
· Import an entire table:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
--table cities
· Import a subset of data:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
--where "country = 'USA'"
· Change file format, by default the data will be saved in tab separated csv format but Sqoop provides option for saving the data in Hadoop SequenceFile, Avro binary format and Parquet file:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
· --as-sequencefile
·
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
--as-avrodatafile
· Compressing imported data:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --table cities \
· --compress \
--compression-codec org.apache.hadoop.io.compress.BZip2Codec
· Bulk import:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --table cities \
--direct
· Importing all your table:
· sqoop import-all-tables \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
--password sqoop
· Incremental import:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table visits \
· --incremental append \
· --check-column id \
--last-value 1
· Free form query import:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --query 'SELECT normcities.id, \
· countries.country, \
· normcities.city \
· FROM normcities \
· JOIN countries USING(country_id) \
· WHERE $CONDITIONS' \
· --split-by id \
--target-dir cities
· Custom boundary query import:
· sqoop import \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --query 'SELECT normcities.id, \
· countries.country, \
· normcities.city \
· FROM normcities \
· JOIN countries USING(country_id) \
· WHERE $CONDITIONS' \
· --split-by id \
· --target-dir cities \
--boundary-query "select min(id), max(id) from normcities"
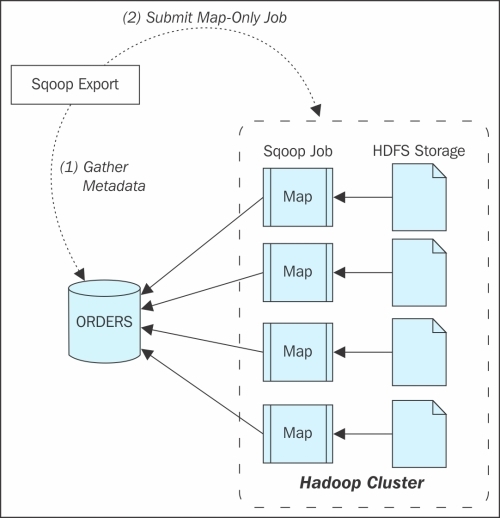
Exports
Sqoop Export is also in a similar process, only the source will be HDFS. Export is performed in two steps;
· Gather metadata
· Submit map-only job
The following figure explains the export into Sqoop:
Sqoop Export has following options:
· Exporting files from under the HDFS directory to a table:
· sqoop export \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
--export-dir cities
· Batch inserts export:
· sqoop export \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
· --export-dir cities \
--batch
· Updating existing dataset:
· sqoop export \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
--update-key id
· Upsert export:
· sqoop export \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
· --update-key id \
--update-mode allowinsert
· Column export:
· sqoop export \
· --connect jdbc:mysql://mysql.example.com/sqoop \
· --username sqoop \
· --password sqoop \
· --table cities \
--columns country,city
Apache Flume
Flume is extremely popular data ingestion system, which can be used to ingest data from different multiple sources and can put it in multiple destinations. Flume provides a framework to handle and process data on a larger scale, and it is very reliable.
Flume is usually described as distributed, reliable, scalable, manageable, and customizable to ingest and process data from different multiple data sources to multiple destinations.
As we already discussed about the different type of data sources. One thing which makes the design more difficult is that data formats changes frequently in some cases especially social media data in JSON, and usually a Big Data systems has multiple data sources. Flume is extremely efficient in handling such scenarios and provides a greater control over each data source and the processing layer. Flume can be configured in three modes: single node, pseudo-distributed, and fully-distributed mode.
Flume is adapted due to its capability to be highly reliable, flexible, customizable, extensible, and can work in a distributed manner in parallel to process big data.
Reliability
Reliability in distributed environment is difficult to design and achieve. Flume excels in the reliability aspect. Flume handles the logical component dynamically to achieve load balancing and reliability. It can guarantee the delivery of the message if the agent node is active. As we mentioned, reliability is difficult to achieve, although Flume can achieve it with some cost and can be resource intensive. According to the requirement and need, Flume provides three levels of reliability, which are:
· End-to-end: The end-to-end level is the most reliable level and guarantees the delivery of an event as long as the agent is alive. The durability is achieved by writing the event in a Write Ahead Log (WAL) file that can be used to recover the events, even in case of crash.
· Store on failure: The store on failure level relies on the confirmation acknowledgement of sending events to sink. In case of acknowledgment not received by the node, the data is stored in the local disk and waits till the node recovers of another node is identified. This level is reliable, but can have data loss in case of silent failure.
· Best effort: The best effort level is the lowest in reliability and can have data loss, but data processing will be faster. In best effort, no attempt will be made to retry or confirm, hence data can be lost.
Flume architecture
Flume architecture is a very flexible and customizable composed agent that can be configured as multitiered for a data flow process. The data flow design allows the source or data to be transferred or processed from the source to the destination. The components are wired together in chains and in different tiers called the logical node's configuration. The logical nodes are configured in three tiers, namely, Client, Collector, and Storage. The first tier is the Client that captures the data from data source and forwards the it to the Collector, which consolidates the data after processing and sends it to the Storage tier.
The Flume process and the logical components are controlled by the Flume Master. The logical nodes are very flexible and can be added or deleted dynamically by the Master.
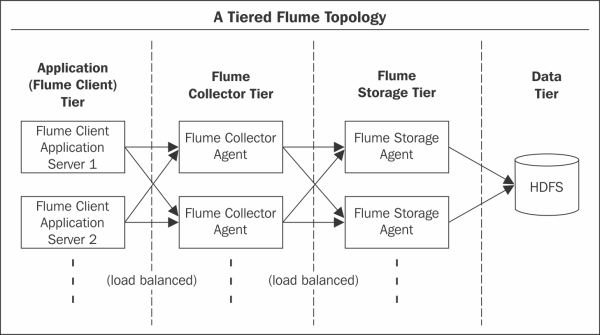
Multitier topology
In Flume, Agents can be configured to be a Client, Collector, or Storage. A Client Agent ingests the data from a data source and pushes it to another Agent, using an Avro/Thrift or intermediatory storage area. A Collector Agent takes an input from another Agent and acts as a source for the Storage Agent. A Storage Agent takes an input from a collector Agent or another Agent and saves the data at the end storage location. Each tier can have multiple independent Agents, which can act as a load balancer. Tier Sink can forward the events to any of the available next hop destination. The flume topology is shown in the following figure:
Flume physical has two components: Flume Master and Flume Nodes.
Flume master
Flume Master, as we mentioned earlier, assigns and coordinates the physical and dynamic logical layer, hence, Master is important in achieving the flexibility and reliability. The logical nodes also check with Master for any updates in configuration. For achieving high availability of Master, we can configure multiple Masters or use Zookeeper to manage Master and Nodes.
Flume nodes
Flume Nodes are physical JVM processes, which run in each nodes. In Flume, each machine has a single JVM process as a physical node that acts as a container for multiple logical processes. Even though Agents and the Collectors are logically separate processes, they can run in the same machine.
Logical components in Flume have two components, namely, Event and Agent. We will discuss the following components:
· Events: Flume has a data flow model, where a unit of data in the flow is called an Event. Events carry payload and an optional set of headers. Events can be customized by implementing Event Interface or overriding existing Event in Flume. Events flow through one or more Agents specifically from Source to the Channel to the Sink component of Agent.
· Agent: An Agent in Flume provides the flexibility to Flume architecture, as it runs on a separate JVM process. An Agent in Flume has three components: Source, Channel, and Sink. Agent works on hop-by-hop flow. It receives events from the Source and puts it in a Channel. It then stores or processes the events and forwards them via Sink to the next hop destination. An Agent can have multiple Sink to forward the events to multiple Agents. The following figure explains the Agent's role:
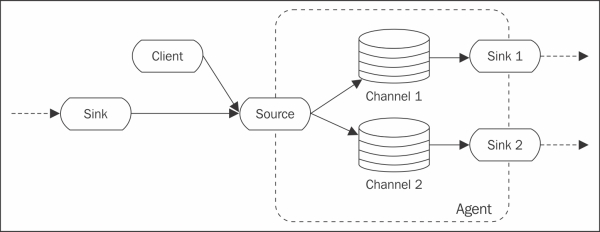
Components in Agent
Let's look at the components of Agent, that is, Source and Sink in the upcoming sections.
Source
Source only listens and receives events from the data source. It then translates it into events and puts it in the Channels Queue. Flume is very well integrated with various source types such as Avro, Thrift, HTTP, and others. For defining a source, we have to set the values of property type. Some frequently used source types are:
|
Source Type |
value of property Type |
Mandatory property to set for the source type |
|
Avro |
avro |
bind: hostname or IP address port: Port # to bind to |
|
Thrift |
thrift |
bind: hostname or IP address port: Port # to bind to |
|
Unix command |
exec |
command: unix command to execute like tail or cat |
|
JMS source |
jms |
initialContextFactory: Example: org.apache.activemq.jndi.ActiveMQInitialContextFactory connectionFactory: The JNDI name the connection factory should appear as: providerURL: The JMS provider URL destinationName; Destination name destinationType: Destination type (queue or topic) |
|
Spooling directory source |
spooldir |
spoolDir: The directory from which to read files from |
|
|
org.apache.flume.source.twitter.TwitterSource |
P.S.: This source is highly experimental and may change between minor versions of Flume. Use at your own risk: consumerKey: OAuth consumer key consumerSecret: OAuth consumer secret accessToken: OAuth access token accessTokenSecret: OAuth token secret |
|
NetCat source |
netcat |
bind: hostname or IP address port: Port # to bind to |
|
Sequence generator source |
seq |
Sequence generator starts with 0 and incremental by 1 index. |
|
HTTP source |
http |
port: Port # to bind to |
For more details, we can check the Apache Flume user guide page https://flume.apache.org/FlumeUserGuide.html#flume-sources.
Example: For creating a source of Agent that should get the updated data of a log file, the mandatory parameter and value should be:
· type: exec
· command: tail –f log_file
· channels: <channel_name>
The preceding points are explained in the following command:
agent.sources.source_log-tail.type = exec
agent.sources.source_log-tail.command = tail -F /log/system.log
agent.sources.source_log-tail.channels = channel1
Sink
Sink collects the events from channels and forwards it to next hop destination as an output of the Agent.
For defining a sink, we have to set values of property type. Some frequently used sink types are:
|
Sink type |
value of property type |
Mandatory property to set for the sink type |
|
HDFS sink |
hdfs |
hdfs.path – HDFS directory path |
|
Logger sink |
logger |
|
|
Avro |
avro |
bind: hostname or IP address port: Port # to bind to |
|
Thrift |
thrift |
bind: hostname or IP address port: Port # to bind to |
|
IRC sink |
irc |
hostname: hostname or IP address nick: Nick name chan: channel |
|
File Roll Sink |
file_roll |
sink.directory: The directory where files will be stored |
|
Null Sink |
null |
|
|
HBaseSinks |
hbase |
table: The name of the table in HBase to write to. columnFamily: The column family in HBase to write to. |
|
AsyncHBaseSink |
asynchbase |
table: The name of the table in Hbase to write to. columnFamily: The column family in HBase to write to. |
|
MorphlineSolrSink |
org.apache.flume.sink.solr.morphline.MorphlineSolrSink |
morphlineFile: The relative or absolute path on the local file system to the morphline configuration file. Example: /etc/flume-ng/conf/morphline.conf |
|
ElasticSearchSink |
org.apache.flume.sink.elasticsearch.ElasticSearchSink |
hostNames: Comma separated list of hostname:port, if the port is not present the default port 9300 will be used |
Example: For a sink that outputs to hdfs:
agent.sinks.log-hdfs.channel = channel1
agent.sinks.log-hdfs.type = hdfs
agent.sinks.log-hdfs.hdfs.path = hdfs://<server> /log/system.log/
Channels
Channels are temporary stores in an Agent, which can be used to hold the events received from the source and transfer the events to sink. Channels are typically of two forms:
· In-Memory Queues: These channels provides high throughput as data is not persisted due to which if an Agent fails, events are not recovered.
· Disk-based Queues: These channels provide full recovery even in case of event failure, but are a little slower than In-Memory due to the persistence of events.
Memory Channel, File Channel, and JDBC Channel are the three frequently used Flume Channels. We'll discuss them in the upcoming sections.
Memory channel
Memory channel stores events in an In-memory heap space. Memory channels are faster because of In-memory and as it won't persist the data to the disk. Memory channel should not be used if data loss is a concern because data will not be recovered if there is any crash in the process or machine. The properties that can be configured for defining Memory channel are:
· type: The value of the property should be org.apache.flume.channel.MemoryChannel.
· capacity: This is the maximum number of events the channel can hold. The default value is 100.
· transactionCapacity: This is the maximum number of events that the source can send the events to the channel per transaction. The default value is 100.
· keep-alive: This is the timeout period for adding and removing an event. The default value is 3.
· byteCapacity: This is the maximum size of space allowed for the channel. The default value is 80 percent of the total heap memory allocated to the JVM.
· byteCapacityBufferPercentage: This is the percent age of buffer between the byte capacity of the channel and the total size of the bodies of all events currently in the channel. The default value is 20.
File Channel
File channel persists the events on the disk and thus doesn't lose event data in case of a crash. File channels are used where data loss is not acceptable and to achieve reliability for processing. The configuration properties that can be set are:
· type: The value of the property should be file.
· capacity: The maximum number of events the channel can hold. The default value is 1000000.
· transactionCapacity: The maximum number of events the source can send the events to the channel per transaction. The default value is 10000.
· checkpointDir: The directory path where the checkpoint data should be saved.
· dataDirs: The directory where the data should be saved. The directories can be multiple and it can improve file channel performance.
· useDualCheckpoints: By default, the value of this property is false, which means checkpoint directory will not be backed up. If true, the checkpoint directory will be backed up.
· backupCheckpointDir: If useDualCheckpoints is true, the directory where the checkpoint should be saved.
· checkpointInterval: The time between the checkpoints.
· maxFileSize: The maximum size of a single log file. The default value is 2146435071.
· minimumRequiredSpace: The minimum size below which the channel will stop operation to avoid data corruption. The default value is 524288000.
· keep-alive: The timeout period for adding and removing an event. The default value is 3.
JDBC Channel
JDBC channel persists the events in a database, and currently only derby database is supported. This channel can be used where the events should be recovered and all event processing is of utmost importance. The configuration properties to be set for JDBC channel are:
· type: The value of type should be jdbc.
· db.type: The type of database default to and currently only DERBY value that can be set.
· driver.class: The class for vendor JDBC driver. The default value is org.apache.derby.jdbc.EmbeddedDriver.
· driver.url: The connection url.
· db.username: The user ID of the database to connect.
Example:
db.password: password of the user id for database to connect.Example of a Channel:agent.channels = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10000
agent.channels.c1.transactionCapacity = 10000
agent.channels.c1.byteCapacityBufferPercentage = 20
agent.channels.c1.byteCapacity = 800000
A simple Flume configuration can be represented by the following figure:
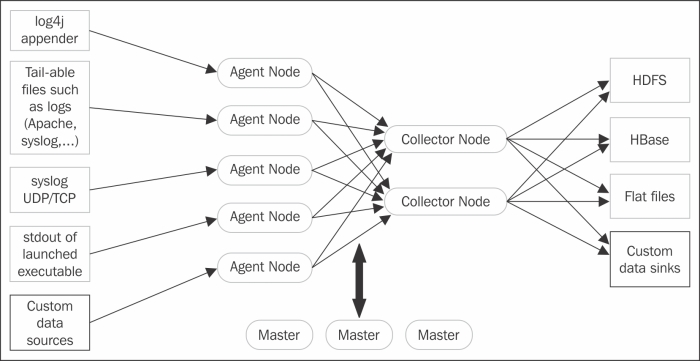
Examples of configuring Flume
Flume can be configured as a Single Agent or Multi Agent; we will see the respective examples in the upcoming sections.
The Single agent example
We will look at an example of the logger example and save it in HDFS and a memory channel, using the following code:
# Source of an Agent with tail
agent.source = source_log-tail
agent.sources.source_log-tail.type = exec
agent.sources.source_log-tail.command = tail -F /log/logger.log
agent.sources.source_log-tail.channels = memoryChannel
# Sink of an Agent to save in HDFS
agent.sinks = log-hdfs
agent.sinks.log-hdfs.channel = memoryChannel
agent.sinks.log-hdfs.type = hdfs
agent.sinks.log-hdfs.hdfs.path = /log/logger.log
# Channel of an Agent to store in memory
agent.channels = memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 10000
agent.channels.memoryChannel.transactionCapacity = 10000
agent.channels.memoryChannel.byteCapacityBufferPercentage = 20
agent.channels.memoryChannel.byteCapacity = 800000
Start the flume process, using the following command:
$ flume-ng agent -n agent -c conf -f conf/flume-conf.properties -Dflume.root.logger=INFO,console
Multiple flows in an agent
We can have multiple source, channel, and sink in an Agent configuration, using the following command:
<Agent>.sources = <Source1> <Source2>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
We can define the corresponding sources, sinks, and channels in the upcoming sections.
Configuring a multiagent setup
To configure a multi-agent setup, we have to link up the agents via an Avro/Thrift where an Avro sink type of one Agent acts as an Avro source type of another Agent. We should have two Agents. The first one will have a logger source and an Avro sink, which is shown in the following code:
# Source of an Agent with tail
agent1.source = source_log-tail
agent1.sources.source_log-tail.type = exec
agent1.sources.source_log-tail.command = tail -F /log/logger.log
agent1.sources.source_log-tail.channels = memoryChannel
agent1.sinks.avro-sink.type = avro
agent1.sinks.avro-sink.hostname = 192.168.0.1 #<hostname>
agent1.sinks.avro-sink.port = 1111
agent1.channels = memoryChannel
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 10000
agent1.channels.memoryChannel.transactionCapacity = 10000
agent1.channels.memoryChannel.byteCapacityBufferPercentage = 20
agent1.channels.memoryChannel.byteCapacity = 800000
The second Agent will have the Avro source of the first Agent sink:
# Source of an Agent with Avro source listening to sink of first Agent
agent2.source = avro-sink
agent2.sources.avro-sink.type = avro
agent2.sources.avro-sink.hostname = 192.168.0.1 #<hostname>
agent2.sources.avro-sink.port = 1111
agent2.sources.avro-sink.channels = memoryChannel
# Sink of an Agent to save in HDFS
agent2.sinks = log-hdfs
agent2.sinks.log-hdfs.channel = memoryChannel
agent2.sinks.log-hdfs.type = hdfs
agent2.sinks.log-hdfs.hdfs.path = /log/logger.log
agent2.channels = memoryChannel
agent2.channels.memoryChannel.type = memory
agent2.channels.memoryChannel.capacity = 10000
agent2.channels.memoryChannel.transactionCapacity = 10000
agent2.channels.memoryChannel.byteCapacityBufferPercentage = 20
agent2.channels.memoryChannel.byteCapacity = 800000
Start the flume agents in different nodes.
Start Agent2 in node 1, using the following command:
$ flume-ng agent -n agent2 -c conf -f conf/flume-conf.properties -Dflume.root.logger=INFO,console
Start Agent1 in node 2, using the following command:
$ flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties -Dflume.root.logger=INFO,console
Summary
One of the critical phases of big data project is Data Ingestion, which we discussed. It is challenging and complex to develop and manage. Nowadays, data sources are in different formats and produce data in high velocity. We explored Sqoop and Flume architecture and its applications, in a nut shell.
We also learned how Sqoop provides a utility to import and export data between Hadoop and databases using connectors and drivers. Sqoop 1 is only JDBC based, and client-side responsibility and interoperability is limited code. Sqoop 2 is not only JDBC based, but also exposes restful API web-based architecture which is easily integrable.
Apache Flume is a reliable, flexible, customizable, and extensible framework to ingest data from fan in and fan out process. Flume has multitier topology, in which Agents can be configured to be used as Client, Collector, or Storage layer.
Hadoop was primarily a batch system, which has limited use cases and many big data use cases required for streaming data analysis and real-time capability. For processing real-time analysis, we will discuss Storm and Spark in the next chapter to process data effectively.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.