Anonymizing Health Data: Case Studies and Methods to Get You Started (2013)
Chapter 12. Secure Linking
A lot of useful health data is linked health data. This means that the data set consists of multiple data sets that have been linked together. But anonymization, by design, makes linking difficult. How do you accurately link records together between two data sets when they have next to nothing in common after anonymization? This is a challenge we see a lot with anonymization. Data sets are collected at different points in time, or by different organizations, and they need to be linked together to run the desired analytics.
To be useful for analysis, data sets must be linked before anonymization. This means that the different organizations holding the constituent data sets need to share information to allow this linking to happen. The best fields to use for linking data sets are almost always identifiers, which means that the organizations have to share personally identifying information in order to link their data. We’re back to the original problem now—how can these organizations share personal identifiers if they do not have appropriate authority or consent?
Only once they’re linked can the data sets be de-identified and used and disclosed for secondary purposes. We’ve seen many useful projects die because it wasn’t possible to link the needed data sets together. But this problem can be solved: this chapter describes a way to securely link data sets together without disclosing personal information. The mechanism is an equi-join process for two tables that have one or more common fields that act as unique identifiers.
Let’s Link Up
There are many situations where linking health data sets is necessary or can help facilitate powerful analytics. For instance, clinical data from electronic medical records at a family practice could be linked to hospital discharge data and retail pharmacy data. This linked data would show how treatment by a primary care physician after patients have been discharged from the hospital can affect complications from their hospital procedures. It provides a more complete picture of the continuum of care that patients experience.
Emergency department visits can be mapped to prescription or dispensation of drugs to evaluate drug side effects or interactions. Data on vital statistics could also be added to include deaths, to evaluate survival rates for different paths through the health care system, or to compare treatments. These are straightforward data linking cases, but they require a way to uniquely identify individuals between the data sets.
The data sets that need to be linked do not necessarily have to come from the providers. Researchers may have survey data on the sexual behaviors of youths, and it may be valuable to link that data with HPV vaccination information to determine whether the highest-risk individuals are being vaccinated. That means matching records from a research data set with a vaccination registry. Securing such sensitive health information is obviously a high priority.
Figuring out when patients have died for a survival analysis could also use the National Death Index (NDI). The way this usually works is that researchers submit their records to the NDI, which then performs the matching for them and sends back information about the matching records. The data being sent to the NDI could be just about anything, such as a list of patients diagnosed with cancer, or those on some specific diet, or nothing whatsoever (for a baseline).
Health data can also be linked with nonhealth data. Immigration data can be linked to health insurance claims data to examine how new immigrants’ health evolves when they settle in their adoptive countries. Correctional services data can be linked with health data to examine the health of inmates after they return to the community. And educational data can be linked with health data to determine the impact of infant health on school performance.
NOTE
As the previous examples illustrate, often different parties will own the individual databases that we need to link together. Some of them will be health care providers, and some will have nothing to do with health care but still hold valuable data. Anonymization methods could be applied before the data is shared among all of these different parties. The anonymization would ensure that the risk of re-identifying the data subjects is very small, and would eliminate some key barriers to these organizations sharing their data. But it would also make it very challenging for them to link their data together!
Secure methods for linking two databases can also address two other very common use cases: secure lookup and de-duplication.
Secure lookup is the use case where we want to find whether a record in one table exists in the other table without revealing identifying information about the record. For instance, imagine two parties, the Carolers and the Tailgaters, that each have a table. The Tailgaters have a record about “Billy” in their table, and they want to find out whether Billy is in the table that the Carolers are holding. However, they do not want to reveal the identity of Billy to the Carolers, and they do not even want the Carolers to know whether the record was found in the Tailgaters’ table. Nor do the Carolers want to share their table with the Tailgaters, because they don’t want the Tailgaters to learn the identities of the other individuals in the Carolers’ table. At the end of the secure lookup, the only information revealed to the Tailgaters is whether Billy is in the Carolers’ table. This scenario is exactly the same as secure linking, except that the linking is performed on a single record.
Secure lookups are useful in fraud detection. For example, let’s say an insurance company has received a claim for some procedure that Billy has undergone, but they are suspicious and want to see whether the same claim was also submitted to one of their competitors. Billy and his provider may be completely innocent, so it would be inappropriate to reveal their identities until there is evidence to warrant further investigation. Also, the competing insurance company does not want to reveal its client database. A secure lookup would allow the first insurance company to do a lookup in the second company’s database without revealing the identity of the individual being sought, and without knowing who else is in that second company’s database.
Also consider a government department that provides health insurance to low-income individuals, and that wants to confirm that insurance recipients indeed have a low income. The tax department has all of the data on income. However, the health department is not allowed to share information with the tax department, and vice versa. A secure lookup would allow the health department to know whether Billy, who is receiving insurance, is indeed claiming a low income, without revealing Billy’s identity to the tax department and without getting access to the tax information of the rest of the population.
The second use case pertains to de-duplication. Here, two complete tables are linked, but just for the purpose of de-duplicating records. De-duplication is a critical step in producing data sets that are clean and ready for analytical use. For example, all states collect uniform data for cancer surveillance on people diagnosed and treated while living in their jurisdiction. They count those cases to calculate statewide cancer incidence rates. The state of residence at the time of diagnosis and treatment is a crucial piece of information to determine population-based cancer incidence. Each state works independently to identify cases. What they don’t want is to count patients that reside in multiple jurisdictions more than once, perhaps because they have a summer home or cottage (like those lucky “snowbirds”). So, they need to de-duplicate their registries, but without sharing the identities of individuals who reside in only a single state. A secure linking protocol would allow this to be accomplished.
Doing It Securely
The tables held by the Carolers and the Tailgaters have some fields in common. The tables also have the same or overlapping patients. We need to join these two tables using a unique identifier for individuals. The unique identifier might be a Social Security number, a health card insurance number, a medical record number, or a credit card number. It can also be a combination of variables that are uniquely identifying, such as county of birth, date of birth, gender, first initial, and last name.
But these unique identifiers are sensitive pieces of information, and it’s often quite challenging to share them among organizations. In Ontario, if a researcher wants to collect the health insurance number for the purpose of linking the records of research subjects, he will need to get approval from his ethics board. Most ethics boards would be reluctant to grant that approval, which means that if a researcher needs to link two databases the health insurance number may not be used, even though it’s the best unique identifier for all citizens.
WARNING
Although we’re just looking to link records in the data, sometimes these unique identifiers can themselves be used to identify an individual. For example, you might think Social Security numbers are simply random numbers assigned to people for the purpose of managing information about them. But it’s possible to figure out a person’s identity from this number,[82] making its use equivalent to sharing personal identifiable information. That’s not to mention that Social Security numbers are so widely collected that they can be used to identify people from other data sources.
It would be nice if one party could just give its data to the other one and have that party join the two tables together. The linked data set could then be de-identified and used or disclosed for secondary purposes. But in a lot of cases that’s just not going to happen, and rightly so, because of privacy concerns for those patients who aren’t in both tables. Parties often don’t even have the authority to share identifying information about their patients. What we need is a way to allow this linking without sharing identifying fields. For this we turn to encryption, which means protecting data inside of an encoding scheme that doesn’t allow anyone to understand what it is without a key.
Don’t Try This at Home
A number of methods have been used in the past to link data sets together, but they’re either not very secure or quite expensive. We’ll describe these here so you know what not to do. Assume that the Carolers want to de-duplicate their data against the data from the Tailgaters by matching on the health card number (HCN). Here are some of the possibilities:
Matching on hashed values
A simple scheme is for the Carolers and Tailgaters to hash their HCNs (basically creating a map from a key to a value, to mask the information and speed up comparisons). The Carolers would send their hashed values to the Tailgaters. The Tailgaters would then match the hashed values to figure out how many and which ones are duplicates. The problem with this approach is that the Tailgaters can hash all possible HCNs and compare these with what they get from the Carolers. If the HCN consists of nine digits, the Tailgaters would need to generate only one billion hashed values, and use these as a dictionary (from hash to HCN). The Tailgaters could then reverse engineer the HCNs for all of the data they received. Not so secure. Don’t do this.
Matching on hashed values with a third party
The Carolers and the Tailgaters could each send their hashed values to a trusted third party, the Easter Bunnies (and who doesn’t trust the Easter Bunnies?). The Easter Bunnies would then match the hashed values and return the result to the Carolers. This would allow them to de-duplicate their database, yay! Oh, wait, the Easter Bunnies could easily launch the same dictionary attack on both sets of hashed values to reverse engineer the original values. We’re willing to trust the Easter Bunnies, but not that much. (Otherwise, what was the point of using hashed values in the first place?)
Salting the hash
It’s possible for the Tailgaters and the Carolers to add a random value to the HCNs before hashing them. Such salting of the hash is often attempted as a way to protect against the flaws already noted. But because the salt value needs to be shared with both parties, either one can still launch a dictionary attack on the data. We’re back to square one, with the same basic problem as before.
Salting the hash with a third party
Now, if both the Carolers and the Tailgaters salt their hashes with the same random value independently of one another, and send the results to the Easter Bunnies, the Easter Bunnies can do the matching and we avoid the dictionary attack problem. The Easter Bunnies don’t know the salt value—right? Well, not quite. This approach requires the Carolers and the Tailgaters to share a secret, their salt value, with each other. Sharing secrets is generally not recommended because if either of them loses or discloses the salt, they essentially compromise the security of the other’s data.
Those of you working in the security space will be thinking, “No way, this doesn’t happen.” Oh, but it does. We’ve seen it. Security protocols are detailed and nuanced. Not everyone will appreciate, and therefore follow, all the steps down to the letter, or understand their limitations. They’ll do what they think is secure, but it often isn’t. We call this practicing security without a license.
The Third-Party Problem
You might think that there can’t possibly be too many parties (birthday parties, tailgate parties, Easter parties). But, alas, that simply isn’t the case here. A general challenge with approaches that require a trusted third party is that when the Carolers and Tailgaters are in different jurisdictions, they may not agree on who that third party will be. Each one of them will want the third party to be in their jurisdiction because they don’t quite trust parties in other jurisdictions. This makes protocols using a trusted third party difficult to implement.
Creating a trusted third party is also expensive, because a lot of security and privacy practices and protocols need to be in place. The third party also needs to be audited on a regular basis to ensure compliance with the stipulated practices and protocols. The Carolers and Tailgaters may agree to trust the Easter Bunnies as their secure third party, but it’s also a lot of overhead for the Easter Bunnies to take on.
THE THREE SHADES OF PARTIES
There are generally three kinds of parties that participate in security protocols:
Fully trusted parties
We let these parties go their own way. We trust them not to get out of hand. They get access to personal information, and we know full well they would be able to easily attack the information they get to recover personal information, but we trust them not to do so. But as we’ve noted already, this assumption has some inherent disadvantages.
Semi-trusted parties
OK, so we can’t all be that trusting. Instead, we trust with caveats. We assume that each party will follow the protocol as specified, but recognize that they could use the information they receive and the output of their computations to recover personal information. For example, if you give the Birthdaygoers a piece of software to run, they’ll execute it as expected, but they might intercept the inputs and outputs to the software and then use that information in some way.
Malicious parties
These are the ones we have to watch out for. Let’s call them the Ravers. They may not follow the protocol, and they may deliberately deviate from the protocol to recover personal information. They could, as a deliberate deviation, be injecting fake values into the output.
In protocols developed in the context of health care, we assume that we’re dealing with semi-trusted parties.
Some protocols that are used quite extensively in practice for linking health data use a fourth trusted party. The fourth party generates the salt value and embeds it within a software program. In our example, the Carolers and Tailgaters then execute that software program to hash the values, and then send the hashed values to their trusted third party, the Easter Bunnies, to link them. This approach would be secure if we assumed that the Carolers and Tailgaters would not, or cannot, reverse engineer the software program to attempt to recover the salt value.
The challenge with using a fourth trusted party is that it amplifies the complexity of the linking protocol and amplifies the disadvantages of having a trusted third party. Plus, what are we going to call this fourth party? We’re running out of amusing names!
Basic Layout for Linking Up
We start with our two parties, the Carolers and the Tailgaters, that want to join their databases together. The Carolers have a database with a bunch of records; the Tailgaters have a database with another bunch of records. Of course, they need a set of fields in common on which to match the databases together.
We need to consider a few points in devising this kind of equi-join protocol:
§ One of the two parties, probably the Carolers, might not have much in the way of computing power. They have data, and they’re willing to provide it, but they don’t want to invest in anything other than what they already have to help with the secure equi-join. This is just a practical requirement because often one entity wants to link or de-duplicate against another larger entity’s database. The former will not have much computing capacity and does not want to invest in developing that capacity because it does not need to do the linking very often. This requirement necessitates that we have some kind of third party involved in the protocol.
§ It should be possible for only one party, the Carolers, to know the results of the match. The Carolers might be checking the data in the NDI for their cancer survival analysis. But they don’t want the Tailgaters, who work at the NDI, to know which patients they’re looking for.
§ Because of the disadvantages of having trusted third parties, discussed in The Third-Party Problem, it’s best to avoid using them if possible. Where they do exist, such as in the case of national statistical agencies, they probably don’t have the mandate to act as third parties anyway.
§ A semi-trusted third party, the Birthdaygoers, would work, though. They’re trusted to follow the protocol, but nothing more. They might be a little too eager to try and discover PHI, which is why they aren’t fully trusted. But that’s OK, because they won’t be given any info that would allow them to discover PHI, so strong security measures don’t need to be put in place for what they handle.
§ Neither the Carolers nor Tailgaters needs to share secrets. They keep to themselves, so that no one party needs to trust the other. Otherwise, if the Tailgaters lost the shared key, the encrypted or hashed data of the Carolers would also be jeopardized, and they would be singing a new tune.
§ The matching between individuals in the two databases needs to be unique for the equi-join to work. The matching variables could include unique individual identifiers, or combinations of identifiers that together are unique, such as names and dates of birth.
§ The Tailgaters are assumed to have significant computing power. They will do much of the heavy lifting. This makes sense because the Tailgaters are the ones with the valuable data resource that everyone wants to link to. This makes it economical for them to invest in some computing capacity.
Ultimately, the architecture of the equi-join protocol requires a semi-trusted third party, the Birthdaygoers. The Birthdaygoers act as the key holder. The key holder needs to have decent computing resources, but it won’t learn the identities of the patients or learn anything new about them during the process of the equi-join. The only thing that the Birthdaygoers will learn within this protocol is how many patients matched between the two data sets.
The Nitty-Gritty Protocol for Linking Up
Unfortunately, we need to get our hands dirty and dig into some technical details to make linked data work. The basic idea is that we’ll use encryption to hide the inner workings of the equi-join.
Bringing Paillier to the Parties
Let’s look at the additive homomorphic encryption system proposed by Paillier.[83], [84] Wow, that’s already a mouthful. Additive means exactly what you think, except that we’re adding encrypted data, which is kind of cool when you think about it. Take two encrypted pieces of information, add them together, and you get their sum. Except it’s still encrypted, so you have no idea what that sum is! Homomorphism is basically a map that preserves the structure between two sets that have some predefined operations performed on them—operations that take in a finite number of elements to produce an output. OK, so what we have, more or less, is an encryption system that allows addition with operators that can take a finite set of elements to produce an output. So far, so good.
With the Paillier cryptosystem it’s possible to perform mathematical operations on the encrypted values themselves, notably addition and limited forms of multiplication. We start by picking two really big prime numbers at random, then we multiply them to give us a value p. Let’s consider two data elements, m1 and m2, and their encrypted values, E(m1) and E(m2):
Paillier addition
E(m1) × E(m2) = E(m1 + m2), where multiplication of cyphertext is mod p2 and addition of plaintext is mod p in this algebraic system
Decrypting this information gives us D(E(m1 + m2)) = m1 + m2. So, this cryptosystem is mapping multiplication of cyphertext (the encrypted values) to addition of plaintext (the unencrypted values). Pretty cool, but let’s not forget that the encryption and decryption require a key:
Paillier multiplication
(E(m1))m2 = E(m1 × m2), where exponentiation of cyphertext is mod p2 and multiplication of plaintext is mod p
Decrypting this information gives us D(E(m1 × m2)) = m1 × m2. This time the value m2 is plaintext only, not encrypted. The value m1 is encrypted, and the product of m1 and m2 is encrypted, but not m2 itself. That’s what makes this a limited form of multiplication. Unfortunately, there isn’t a way to do multiplication of cyphertext in this system.
An important property of Paillier encryption is that it’s probabilistic: it uses randomness in its encryption algorithm so that encrypting the same message several times will generally give different cyphertexts. This ensures that an adversary won’t be able to compare encrypted messages to figure out the underlying information.
Matching on the Unknown
First things first. The Birthdaygoers need to generate a key pair—a public encryption key and a private decryption key—and send the public key to the Tailgaters and the Carolers, as shown in Figure 12-1. What we want to do is match on the unknown, i.e., the encrypted values.
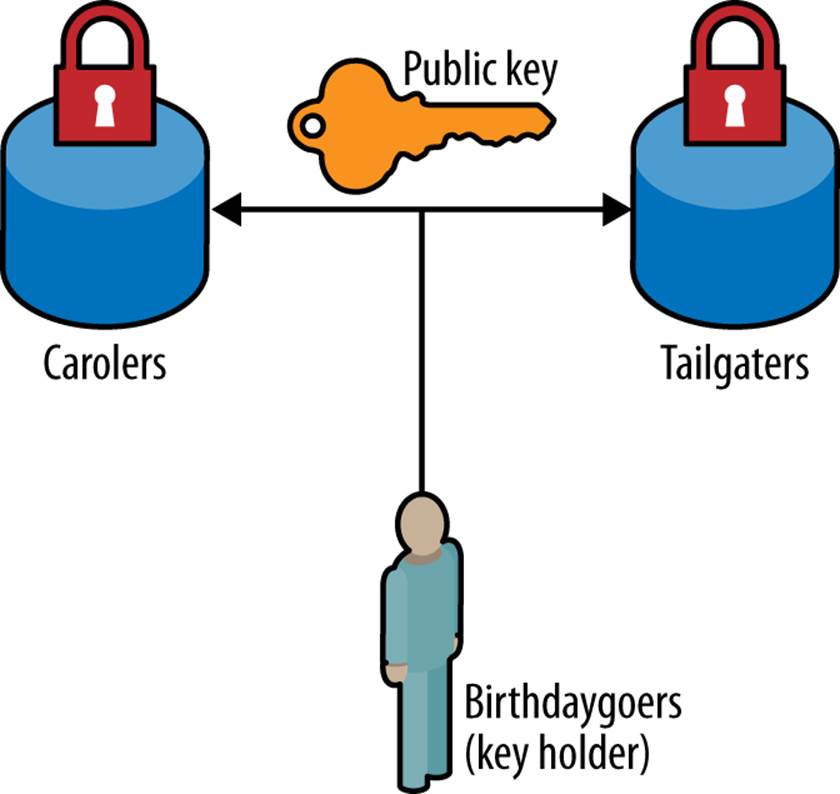
Figure 12-1. The first step in any relationship is to share (in this case, the public encryption key).
The Carolers initiate the matching (they’re very responsible that way, going door to door bringing cheer). For nonstring fields (e.g., SSN or HCN), we use a secure comparison to find matches between records in the data set sent by the Carolers and what the Tailgaters already have. This works as shown in Figure 12-2, and is described in more detail in the following list:
1. The Carolers send their encrypted records to the Tailgaters (which will be used in a couple of steps). Let E(x) be one of their encrypted HCNs. Obviously they need to send all of them, but we want to use minimal notation for simplicity.
2. For each encrypted record the Tailgaters have, E(y), they generate a random number r to accompany it. Each record gets a new random number (no double dipping!).
3. For every pair of records between the Carolers and the Tailgaters, and over every matching variable, they compute the funky comparison variable c = ((E(x) × E(y))-1)r. So, it’s one funky comparison variable for each pair of records, and each matching variable. Recall that every matching variable, which is then sent to the Birthdaygoers, has its own encryption.
4. The Birthdaygoers use their private key to decrypt the c values, and blow party horns when these values equal zero! Because a zero means a match, which sounds like a good enough reason to blow a party horn when you’re a Birthdaygoer. Nonzero values mean that there isn’t a match, so no party horns.
5. The Birthdaygoers are left with a binary table of matches and nonmatches, basically a bingo card, for all of the compared pairs of records and matching variables. The final bingo card of matches can be sent back to whoever it is that’s planning to link the two data sets together.
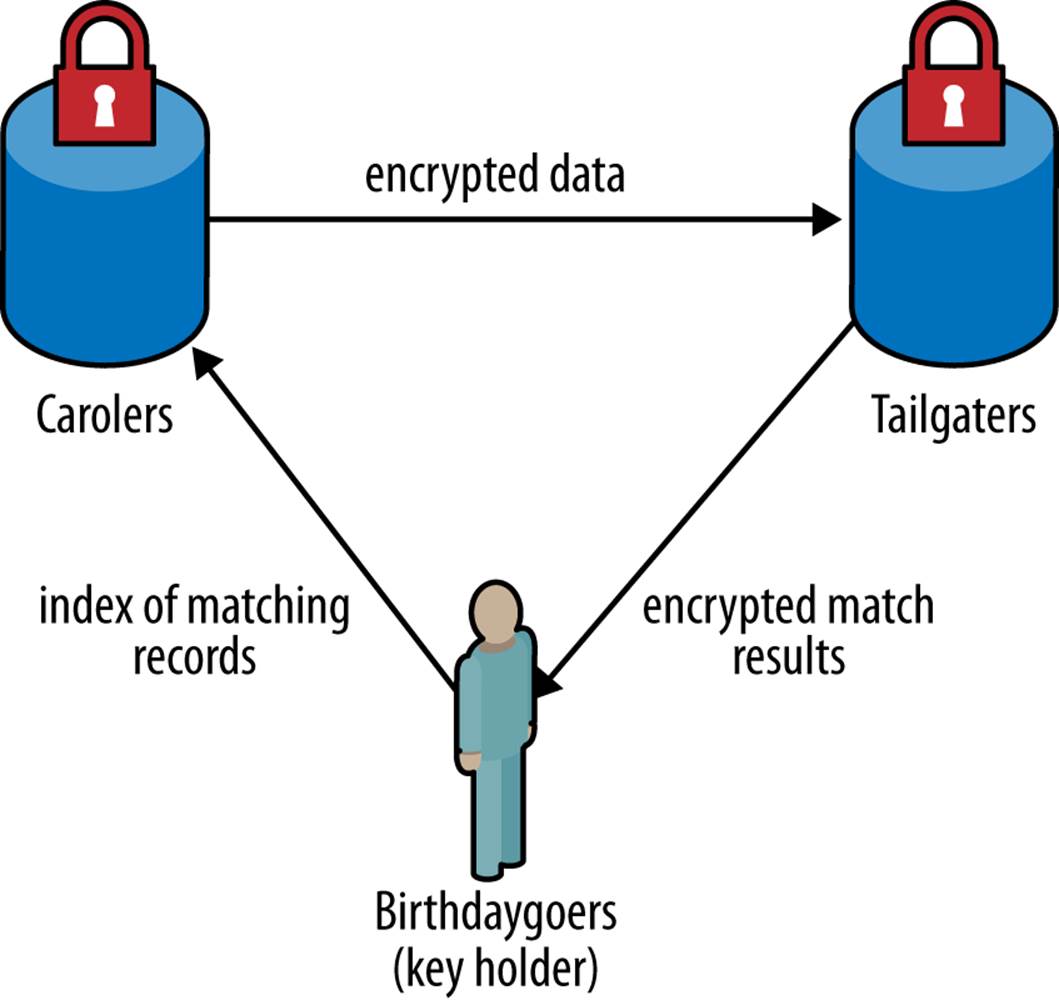
Figure 12-2. Now we share data for the matching of records.
Although that description was for nonstring fields, the basic idea works equally well for string fields. The major difference is that you need to consider the approximate matching of strings, in case there are first or last names that have typos or some other difference. Phonetic encoding functions, like Soundex and NYSIIS, can be used to perform exact comparisons in the same way we showed before.
We can even match records on approximate birth dates, following the guidelines used by the NDI. We consider records matched on dates of birth when any of the following are found in the two records:
§ Exact same month and same year of birth
§ Exact same month and same day of birth
§ Exact same month and year of birth to within one year
For the matching protocol this means we would need to share the encrypted values for the day, month, year – 1, year, and year + 1 of the date of birth (i.e., five different encrypted values). And be careful of differences in the order of day, month, and year when comparing dates! One database might use day/month/year, and another month/day/year.
Scaling Up
The protocol we just described will, sadly, not scale very well. If the Carolers have a database with n records, and the Tailgaters have a database with m records, we will need to do n × m comparisons. This can be a pretty big number for large databases, and all of these comparisons can take a long time—computations on encrypted values are slower than computations on raw (unencrypted) values. We need to make the protocol run more efficiently than that.
One approach is to use blocking, where we do some data partitioning up front. Let’s take our example of matching on the HCNs. The Carolers send along the year of birth as well as the encrypted HCN. (For it to be safe for them to send this information, the year of birth for the data held by the Carolers would have to have a low risk of re-identification, as measured using the techniques described earlier in this book.) If there are 50 unique years of birth in the data set and they are uniformly distributed, we have essentially split the data set into 50 mini data sets. No HCN can match any HCN associated with a different year of birth, so the number of comparisons required could be 50 times fewer in this case.
If this is not enough, we can add another variable to block on; let’s say the state. If there are 50 states in the data set, the combination of state and year of birth could result in as many as 2,500 unique values. Then we would end up with 2,500 fewer comparisons. Now we’re cookin‘!
Of course, we would have to be sure that the combination of year of birth and state has a low risk of re-identification for the Carolers’ data set.
These are nontrivial performance improvements, but we can still do better.
Cuckoo Hashing
Cuckoo hashing is a well-developed hashing scheme about which you can find many technical articles. This isn’t necessarily an easy concept to grasp, but we’ll try to explain without going into too much detail. To describe it in the context of our linking problem, the Carolers would create a hash table to store their encrypted HCN values. The hash table would have a “bin” for each encrypted value. This hash table would allow the Tailgaters to find the right bins when doing their comparisons.
For each HCN, the Carolers would compute the index for its bin and store its value in that bin. When all of the HCNs have been inserted in the hash table, any empty bins are filled up with fake encrypted values. That way, the frequency of the HCNs is not disclosed. This meets one of the goals of cryptography, which is to share as little information as possible. It’s crazy what can be used to attack encrypted data if there’s any leakage of information—even the time it takes to execute a protocol can be used to attack the system. Better to not have any leakage.
This padded hash table is sent to the Tailgaters. They take each one of their own HCN numbers and compute its bin index. Then they pull the value in that bin from the hash table they received from the Carolers, and compare the values. An interesting feature of a cuckoo hash table is that the Tailgaters need to look in only two bins to know with a high probability whether there’s a match or not. This means that the total number of comparisons will be 2 × m, irrespective of how large the Carolers’ table is (which has n records). That is cuckoo, but good cuckoo.
How Fast Does a Cuckoo Run?
To illustrate how fast this can run in practice, we did a few evaluations on a series of HCNs of various sizes The results are shown in Table 12-1. Here, the tables for the Carolers and Tailgaters were of the same size. We used a 64-bit Windows 2008 server machine with eight cores.
Table 12-1. Cuckoo hashing performance
|
No. of records (each) |
Encryption (secs) |
Compare (secs) |
Match (secs) |
Total time |
|
10,000 |
16 |
29 |
9 |
0.9 min |
|
100,000 |
175 |
342 |
44 |
9.35 min |
|
1,000,000 |
1,441 |
3,278 |
443 |
1 hr 26 min |
|
10,000,000 |
13,785 |
31,216 |
5,017 |
13 hr 53 min |
The original approach would have taken us a few years to complete on the 10 million record data set. But the whole computation time for a 10 million by 10 million record run—with encryption, secure comparisons, and matching—takes approximately 14 hours. Now that’s a roadrunner!
Final Thoughts
Secure linking solves one of the major challenges in getting access to data from multiple sources. It has a number of common use cases, from de-duplication of databases to linking databases across jurisdictional or organizational boundaries without sharing any personal information. The challenge with such secure protocols is their performance, but with the schemes we’ve presented here for linking tables, scaling the implementation to larger data sets is feasible on current hardware and doesn’t require the use of blocking techniques.
At the end of the secure linking protocol, the only information that’s revealed is the identities of the matching records. This is inevitable, and in fact the whole point of the exercise. Therefore, it’s important for the Carolers to have the authority or consent to learn the new information they gain from having matched records. Even this requirement can be eliminated by using secure anonymization, whereby the linked data is securely anonymized before it’s revealed to the Carolers, but we’ll leave that protocol for another book.
[82] A. Acquisti and R. Gross, “Predicting Social Security Numbers from Public Data,” Proceedings of the National Academy of Science 106:27 (2009): 10975–10980.
[83] P. Paillier, “Public-Key Cryptosystems Based on Composite Degree Residuosity Classes,” Advances in Cryptography—EUROCRYPT ’99 (New York: Springer-Verlag, 1999) 223-238.
[84] P. Paillier, “Composite-Residuosity Based Cryptography: An Overview,” Cryptobytes 5:1 (2002): 20–26.