Learning Heroku Postgres (2015)
Chapter 8. Extensions, PostGIS, Full Text Search Dictionaries, Data Caching, and Tuning
In the previous chapters, you've learned the main concepts about Heroku Postgres, which usually cover most of the functions that you will need.
You have reached the last chapter and this is a very special chapter because it covers a collection of advanced features that I preferred to cover just in one chapter as an excellent reference for you.
In this chapter, you will learn about the main extensions of the Postgres database, and understand how to enable PostGIS to work with spatial data, text search tools, and data cache. You will also gauge how you can perform optimizations and performance analysis in your database.
This chapter covers the following topics:
· Heroku Postgres extensions
· Full text search dictionaries
· Data caching
· Setting up PostGIS
· Database tuning
· Performance analysis
Heroku Postgres extensions
PostgreSQL allows its functionality to be extended with additional modules called extensions. Many of these extensions aren't installed by default in PostgreSQL, because they aren't part of its core and mainly because they are specific to a limited audience. In addition, some extensions are experimental, but nothing prevents their use.
Heroku Postgres provides some interesting extensions for data types, functions, statistics, index types, languages, searches, and many others. In the next sections, you will learn about each of these extensions, with simple samples, and you will understand how they work.
The first step to get started is to discover the list of available extensions in your database; it may vary according your database plan. You should do it using the following command:
$ echo 'show extwlist.extensions' | heroku pg:psql --app your-app-name
---> Connecting to HEROKU_POSTGRESQL_CHARCOAL_URL (DATABASE_URL)
extwlist.extensions
-------------------------------------------------------------------btree_gist,chkpass,citext,cube,dblink,dict_int,dict_xsyn,earthdistance,fuzzystrmatch,hstore,isn,ltree,pg_stat_statements,pg_trgm,pgcrypto,pgrowlocks,pgstattuple,plpgsql,plv8,postgis,postgis_topology,postgres_fdw,tablefunc,unaccent,uuid-ossp
These extensions are available in the database, but they aren't installed. To install and start using its features, you need to run the appropriate SQL query in the database. First you need to connect in psql and then run the SQL query to install the extension that you want:
$ heroku pg:psql --app your-app-name
---> Connecting to HEROKU_POSTGRESQL_GOLD_URL (DATABASE_URL)
psql (9.3.4, server 9.3.3)
SSL connection (cipher: DHE-RSA-AES256-SHA, bits: 256)
Type "help" for help.
app-name::GOLD=> CREATE EXTENSION extension_name_to_install;
Data types
In computer science, data type is a combination of values and operations that one variable can perform. There are a large number of data types available such as integer, float, Boolean, Array, Hash, and many others. PostgreSQL is no different; you have a collection of data types available by default, such as numeric, monetary, character, binary, date/time, Boolean, enumerated, and many others.
In some cases, other kinds of data types are necessary and they aren't installed by default on PostgreSQL. In this section, you will discover the power of some important extensions for data types.
Case-insensitive text – citext
This data type is very useful for working with queries where the data is case insensitive. You can use this feature with an implementation to facilitate your searches, such as searching for products on an e-commerce website.
For you to understand, the data type text is generally used, but it is case sensitive. For example, suppose you have a table with the column username and an index to avoid duplicate usernames:
$ heroku pg:psql –app your-app-name
CREATE TABLE students (username text NOT NULL);
CREATE UNIQUE INDEX unique_username_on_students ON students (username);
Next, you'll insert some student names:
INSERT INTO students (username) VALUES ('patrick');
INSERT INTO students (username) VALUES ('PATRICK');
In the preceding example, two records were created; as the data type text is case sensitive, so the values 'patrick' and 'PATRICK' are different. This is the problem that extension citext resolves, it allows you to define case insensitive data.
After that, you'll switch to use the citext extension:
CREATE EXTENSION citext;
TRUNCATE TABLE students;
ALTER TABLE students ALTER COLUMN username TYPE citext;
DROP INDEX unique_username_on_students;
CREATE UNIQUE INDEX unique_username_on_students ON students (username);
Finally, if you try to repeat the inserts, you'll have an error:
INSERT INTO students (username) VALUES ('patrick');
INSERT INTO students (username) VALUES ('PATRICK');
# ERROR: duplicate key value violates unique constraint "unique_username_on_students"
# DETAIL: Key (username)=(PATRICK) already exists.
You can find more information at http://www.postgresql.org/docs/current/static/citext.html.
Cube
The cube extension is used to create multidimensional data. It is useful for datasets that require more than one dimension. Through this extension, you can perform many operations with multidimensional data such as discovering the number of dimensions, creating union between cubes, finding the intersection of two cubes, generating subsets, and other functions. In the following example, you will see how to create a cube and how to perform some queries.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION cube;
CREATE TABLE sets (element cube);
INSERT INTO sets (element) VALUES ('(1, 2, 3)');
First, you'll check whether the cube contains a specific subset:
SELECT * FROM sets WHERE cube_contains(element, '(1, 2)');
element
-----------
(1, 2, 3)
After that, you'll create a cube union with another cube:
SELECT cube_union(element, '(4, 5, 6)') FROM sets;
cube_union
---------------------
(1, 2, 3),(4, 5, 6)
Finally, you will find the cube intersection with another cube:
SELECT cube_inter(element, '(1, 2)') FROM sets;
cube_inter
---------------------
(1, 2, 3),(1, 2, 0)
There are other functions that you can explore. For more information, visit the website http://www.postgresql.org/docs/current/static/cube.html.
HStore
The HStore extension stores data in key and value format. It is a data structure consisting of a non-ordered set of items formed by a key-value pair, in which each key has an associated value. The HStore data type is useful because it allows their use in queries.
In the following example, you will create a new table called profiles and store a data key / value in the configs column.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION hstore;
CREATE TABLE profiles (configs hstore);
INSERT INTO profiles (configs) VALUES ('resolution => "1024x768", brightness => 45');
This data type has a limitation where all their data is stored in string format. You can see that if you perform a SELECT query:
SELECT * FROM profiles;
configs
----------------------------------------------
"brightness"=>"45", "resolution"=>"1024x768"
Finally, you are able to find records using the configs key-value data:
SELECT * FROM profiles WHERE configs->'resolution' = '1024x768';
configs
----------------------------------------------
"brightness"=>"45", "resolution"=>"1024x768"
There are numerous possibilities of using the HStore extension and you can find more information in the PostgreSQL documentation http://www.postgresql.org/docs/current/static/hstore.html.
Label tree – ltree
It provides a way to organize data with labels stored in a hierarchical tree structure. The main advantage of this extension is the speed for searching data, since a recursive search is not necessary.
For you to understand this extension better, you can build an example of continents and countries in a hierarchical tree as shown in the following diagram:
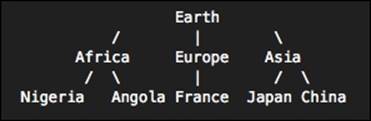
Hierarchical tree of countries.
First, you will install the ltree extension, then create the table of countries and add the tree structure as shown in the preceding diagram. The commands for creating the country table are as follows:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION ltree;
CREATE TABLE countries (path ltree);
INSERT INTO countries VALUES ('Earth');
INSERT INTO countries VALUES ('Earth.Africa');
INSERT INTO countries VALUES ('Earth.Africa.Nigeria');
INSERT INTO countries VALUES ('Earth.Africa.Angola');
INSERT INTO countries VALUES ('Earth.Europe');
INSERT INTO countries VALUES ('Earth.Europe.France');
INSERT INTO countries VALUES ('Earth.Asia');
INSERT INTO countries VALUES ('Earth.Asia.Japan');
INSERT INTO countries VALUES ('Earth.Asia.China');
Finally, you are able to perform queries to discover the countries on each continent. For example if you want to view countries of Africa use the following query:
SELECT path FROM countries WHERE path ~ 'Earth.Africa.*{1}';
path
----------------------
Earth.Africa.Nigeria
Earth.Africa.Angola
If you want to view countries in Europe use the following query:
SELECT path FROM countries WHERE path ~ 'Earth.Europe.*{1}';
path
---------------------
Earth.Europe.France
If you want to view countries in Asia use the following query:
SELECT path FROM countries WHERE path ~ 'Earth.Asia.*{1}';
path
------------------
Earth.Asia.Japan
Earth.Asia.China
This extension can be used in many situations, and has many functions for searching. You can find more information in its documentation at http://www.postgresql.org/docs/current/static/ltree.html.
Product numbering – isn
Data types are used to store product data following the international standard and serial numbers such as ISSN (serial), UPC, ISBN (books), EAN13, ISMN (music). The numbers are validated.
In this example, you will create a table of books, with the data type ISBN for the id field, and you will insert a book:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION isn;
CREATE TABLE books (id isbn, name text);
INSERT INTO books (id, name) VALUES ('9780307465351', 'The 4-Hour Workweek');
This extension is very simple and you can find all data types supported in the documentation at http://www.postgresql.org/docs/current/static/isn.html.
Functions
In computer science, functions are subprograms identified by a name. They can receive a list of parameters and one of the great benefits is the reuse of code. In addition, they make the code reading more intuitive.
All the function extensions on PostgreSQL provide a set of methods that increase the power and features of your database. They provide algorithms to solve common problems. In the upcoming sections, you will learn the available function extensions in Heroku Postgres.
Earth distance
The earthdistance extension offers two different ways to calculate distances in a circle on the earth's surface. For this extension, the earth is assumed to be perfectly spherical. If the calculations are inaccurate for you, it's recommended to use the PostGIS extension. You will see more about it in this chapter.
In this example, you will create a table of attractions in Brazil and you will insert their latitude/longitude. After using this information, you will find the distance between the two attractions. You can create the following table:
id | name | latitude | longitude
----+------------------------------+-------------+------------
1 | Christ the Redeemer (statue) | -22.9518769 | -43.2104991
2 | Maracana Stadium | -22.9121089 | -43.2301558
First, you will install the earthdistance extension and then insert the two attractions:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION earthdistance;
CREATE TABLE attractions (id integer, name text, latitude float, longitude float);
INSERT INTO attractions (id, name, latitude, longitude) VALUES (1, 'Christ the Redeemer (statue)', -22.951876900000000000, -43.210499099999990000);
INSERT INTO attractions (id, name, latitude, longitude) VALUES (2, 'Maracana Stadium', -22.912108900000000000, -43.230155800000034000);
Finally, you are able to calculate the distance between the Christ the Redeemer (statue) and Maracana Stadium. In this example, you will use two functions, the first one is the ll_to_earth function, which transforms the latitude/longitude data on a point on the surface of the Earth. The second function is earth_distance that calculates the distance.
SELECT earth_distance(
(SELECT ll_to_earth(latitude, longitude) FROM attractions WHERE name = 'Christ the Redeemer (statue)'),
(SELECT ll_to_earth(latitude, longitude) FROM attractions WHERE name = 'Maracana Stadium')
);
earth_distance
------------------
4864.08588226038
There are other possibilities for this extension; visit the documentation at http://www.postgresql.org/docs/current/static/earthdistance.html.
Intarray
This extension provides a set of functions and operators for working with integer arrays. It also provides support for indexed search using operators. The operations provided by this extension are used for one-dimensional arrays.
In this example, you will create a table of contents and add a disordered array. Then you will use two functions, the first to sort the array and the second to display the number of elements.
To start, you will install the intarray extension, create the table contents, and insert a record:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION intarray;
CREATE TABLE contents (elements INT[]);
INSERT INTO contents (elements) VALUES (ARRAY[2, 4, 3, 1]);
Next, you will sort the array of elements:
SELECT sort_asc(elements) FROM contents;
sort_asc
-----------
{1,2,3,4}
Finally, you will discover the number of elements in the array.
SELECT icount(elements) FROM contents;
icount
--------
4
For other useful functions, check the documentation at http://www.postgresql.org/docs/current/static/intarray.html.
Fuzzy match – fuzzystrmatch
This extension provides a set of functions for determining the distance and similarity between strings. Search engines such as Google search for similar words; through the extension fuzzystrmatch you are able to use this feature in your queries.
In the following example, you will add some names and use the function called difference to discover their similarity. This function returns a value from 0 to 4, where 0 (zero) is the exact match and 4 (four) is the distant correspondence:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION fuzzystrmatch;
CREATE TABLE doctors (name text);
INSERT INTO doctors (name) VALUES ('Patrick');
INSERT INTO doctors (name) VALUES ('Padrig');
SELECT difference(
(SELECT name FROM doctors WHERE name = 'Patrick'),
(SELECT name FROM doctors WHERE name = 'Padrig')
);
difference
------------
4
There are other functions such as soundex, levenshtein, metaphone, and dmetaphone. You can find more information about them on the extension documentation at http://www.postgresql.org/docs/current/static/fuzzystrmatch.html.
PGCrypto
This extension provides encryption functions that allow you to store encrypted data in your database. The pgcrypto extension is often used to manage user authentication in web applications.
In the following example, you will create a user table with two columns: username and password. Now you will insert a user with an encrypted password. Then, through the appropriate SQL, you will search the user with the access credentials.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION pgcrypto;
CREATE TABLE users (username text, password bytea);
In the following insert statement, you will encrypt the user password via the digest function. This function accepts two parameters: the first one is the string to be encrypted and the second one is the type of algorithm that is used. The algorithm can be md5, sha1,sha224, sha256, sha384, or sha512.
INSERT INTO users (username, password) VALUES ('patrickespake', digest('pass123', 'md5'));
Finally, you are able to search users via the username and password.
SELECT * FROM users WHERE username = 'patrickespake' AND password = digest('pass123', 'md5') LIMIT 1;
username | password
---------------+------------------------------------------
patrickespake | 2%\001p\240\334\251-S\354\226$\3636\312$
In the documentation at http://www.postgresql.org/docs/current/static/pgcrypto.html, you can find many other interesting functions.
Table functions and pivot tables – tablefunc
This is an extension that allows you to return tables with multiple lines. It provides useful functions for working with pivot tables. It is used to cross-refer values of two variables.
In the following example, you will create a sales table with the columns year, month, and value. Then you will use this data to make a crosstab by monthly sales.
First, you will install the tablefunc extension and insert some sales:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION tablefunc;
CREATE TABLE sales (year integer, month integer, value float);
INSERT INTO sales (year, month, value) VALUES (2013, 1, 34.56);
INSERT INTO sales (year, month, value) VALUES (2014, 3, 99.50);
INSERT INTO sales (year, month, value) VALUES (2014, 4, 45.99);
INSERT INTO sales (year, month, value) VALUES (2015, 2, 78.99);
Finally, you will use the functions crosstab and generate_series to create a pivot table between month and the sales value in each year:
SELECT * FROM crosstab(
'SELECT year, month, value FROM sales',
'SELECT month FROM generate_series(1, 4) month'
)
AS (
year integer,
"Jan" float,
"Feb" float,
"Mar" float,
"Apr" float
);
year | Jan | Feb | Mar | Apr
------+-------+-------+------+-------
2013 | 34.56 | | |
2014 | | | 99.5 | 45.99
2015 | | 78.99 | |
For more information visit the documentation at http://www.postgresql.org/docs/current/static/tablefunc.html.
Trigram – pg_trgm
The pg_trgm extension provides operators and functions to calculate the similarity of alphanumeric ASCII text with a trigram base match. A trigram is defined with a set of three consecutive characters, made from a string; it is very effective for measuring the similarity of words in natural languages.
The following example is very simple; you will use the similarity function to discover the similarity between two strings. The return of this function can be between 0 and 1, where 0 (zero) indicates that the strings are dissimilar and 1 (one) being similar.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION pg_trgm;
SELECT similarity('PostgreSQL', 'Postgres');
similarity
------------
0.666667
You can find more information at http://www.postgresql.org/docs/current/static/pgtrgm.html.
UUID generation
It provides functions to generate universal unique identifiers (UUID). It is a special type of identifier used in software applications to provide a reference number that is unique in any context.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION "uuid-ossp";
SELECT uuid_generate_v1();
uuid_generate_v1
--------------------------------------
d976c6de-af2e-11e4-b1fb-22000ae18ca6
For more information, visit the documentation at http://www.postgresql.org/docs/current/static/uuid-ossp.html.
Statistics
By definition, statistics is the science that uses probabilistic theories to explain the frequency of the occurrence of events. The Heroku Postgres provides some extensions for database statistics and tables. In upcoming sections, you will learn about them.
Row locking – pgrowlocks
This extension provides a function called pgrowlocks to display locked rows in a specific table.
First, you must install the extension:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION pgrowlocks;
The pgrowlocks function accepts a parameter that is the table name. For example:
SELECT * FROM pgrowlocks('users');
locked_row| lock_type | locker | multi | xids | pids
----------+-----------+--------+-------+-----------+---------
(0,1) | Shared | 22 | t | {378,809} | {23457}
(0,2) | Exclusive | 345 | f | {780} | {12869}
For details, visit the documentation at http://www.postgresql.org/docs/current/static/pgrowlocks.html.
Tuple statistics – pgstattuple
A tuple is a set of objects that share the same characteristics or have the same property. The pgstattuple extension provides a set of functions for statistics on the tuple level.
In the official Heroku documentation, it is informed that this extension is available for use, but many developers fail to use it. This extension needs a superuser level and Heroku does not provide it. For example:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION pgstattuple;
CREATE TABLE jobs (id integer, name text);
INSERT INTO jobs (id, name) VALUES (1, 'Load users');
INSERT INTO jobs (id, name) VALUES (2, 'Send emails');
SELECT * FROM pgstattuple('jobs');
ERROR: must be superuser to use pgstattuple functions
You can find more information about using this extension in your local environment at http://www.postgresql.org/docs/current/static/pgstattuple.html.
Index types
An index, in the database context, is a related reference to a key, which is used for optimization purposes and and to allow records to be located more rapidly in a query. Heroku Postgres provides an extension to work with index types Btree GiST.
Btree GiST – btree_gist
In computing, Generalized Search Tree (GiST) is a data structure that can be used to build search tree in many types of data. The btree_gist extension provides the GiST index operator that implements the equivalent B-tree behavior for these data types: int2,int4, int8, float4, float8, numeric, timestamp, time, date, interval, oid, money, char, varchar, text, bytea, bit, varbit, macaddr, inet, and cidr.
Most of the time, these operator classes will not exceed B-tree index methods and don't have the ability to enforce uniqueness.
These operator classes are useful when a multicolumn GiST index is required.
For example:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION btree_gist;
CREATE TABLE drinks (quantity int4);
CREATE INDEX drinks_quantity_index ON drinks USING gist (quantity);
For more details visit the documentation at http://www.postgresql.org/docs/current/static/btree-gist.html.
Languages
PostgreSQL allows user-defined functions. They are written in other programming languages. These languages are generically called procedural languages (PLs). Heroku only supports one extra extension: PLV8.
PLV8 – V8 Engine JavaScript Procedural Language
This extension is very interesting because it provides a procedural language created by the JavaScript V8 engine. It allows you to write functions in JavaScript and use them with SQL.
In the following example, you will create a function in JavaScript that makes a join between two JSON objects.
First, you will install the PLV8 extension and then the join_json function. This function accepts two JSON objects as parameters:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION plv8;
CREATE OR REPLACE FUNCTION join_json(first JSON, second JSON)
RETURNS JSON AS $$
for (var json_key in second)
{
first[json_key] = second[json_key];
}
return first;
$$ LANGUAGE plv8;
Finally, you will run SQL to make a union between the two JSON objects.
WITH my_join AS (
SELECT
'{"config":"true"}'::JSON f,
'{"user":23}'::JSON s
)
SELECT
f,
s,
join_json(f, s)
FROM my_join;
f | s | join_json
-----------------+--------------+-------------------------
{"config":"true"}|{"user":23}|{"config":"true","user":23}
Tip
The PLV8 extension is not available on the Hobby-tier database plans.
For more information visit the project page at https://code.google.com/p/plv8js/.
Full text search dictionaries
Full text search dictionaries are a mechanism that allows the identification of documents in natural language corresponding to a query and optionally sorts them by relevance. In the upcoming sections, you will use two of these extensions.
Dict int
This is a full-text search dictionary extension used for indexing integers (signed and unsigned), preventing the growth of the unique word number, which greatly affects the search performance.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION dict_int;
For more details, visit the documentation at http://www.postgresql.org/docs/current/static/dict-int.html.
Unaccent
Basically, this consists of a text searching and filtering dictionary, which means that its output is always passed to the next dictionary, which is different from the normal behavior of dictionaries. This extension removes accents from lexemes. It is the minimum unit of distinctive semantic system of a language.
$ heroku pg:psql --app your-app-name
CREATE EXTENSION unaccent;
For more details, visit the documentation at http://www.postgresql.org/docs/current/static/unaccent.html.
Data caching
Generally, for most applications, only one piece of data is frequently accessed. Postgres monitors the accessed data and places it in a cache to improve the performance of your queries. If your application is well designed, it is possible that 99 percent of the queries are cached.
You can find the cache rate of your database with the following SQL query:
$ heroku pg:psql --app your-app-name
SELECT sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as percentage, sum(heap_blks_hit) as quantity_hit, sum(heap_blks_read) as quantity_read FROM pg_statio_user_tables;
percentage | quantity_hit | quantity_read
-----------------------+-----------------+---------------
0.99999826000612665185 | 4024719812 | 7003
(1 row)
In this example, the application and the database are optimized with 99.99 percent of cache. If your percentage is below that, you should consider optimizing your application or change your database plan to a higher one that offers more RAM memory.
For example, if you are using the Premium 2 plan that offers 3.5 GB of RAM memory, a small portion will be used by the operating system kernel, another part will be used for other programs, including Postgres, and the rest between 80 percent and 95 percent of RAM memory is used to cache data by the operating system. Postgres manages a Shared Buffer Cache, which is allocated and used to hold data and indexes in memory. Usually, it is allocated 25 percent of the total operating system memory.
Some operations in the database can affect the amount of cache memory temporarily. If, for example, you are running VACUUM, DDL operations, or creating indexes, these operations tend to consume the available cache memory.
If there is an interruption of database services, you may receive a message saying that you have a "cold cache". This happens for a period until the database comes back online after a service failure.
As a result, it will drop the quality of your application during cache recreation. One way to solve this is using a follower of your primary database so that, when the failure occurs, you can promote the follower database as the main database and reduce the time for the cache. This way you can ensure greater stability in failure events.
Setting up PostGIS
PostGIS is an extension for creating spatial databases in PostgreSQL. This extension adds support for geographic objects; it allows location queries through SQL.
This is the most popular open source extension offering many features that are rarely found in competing spatial databases such as Oracle Locator/Spatial and SQL Server.
PostGIS is supported on Heroku Postgres in beta mode. For using this extension, you must be using a database in the production tier and it isn't available for plans in the Hobby tier. Besides that, it is only available in the 2.0 version with Postgres v9.2 or in the 2.1 version with Postgres v9.3.
Provisioning
You can install PostGIS as any other extension. First you must connect to psql and then run the statement for installation:
$ heroku pg:psql --app your-app-name
CREATE EXTENSION postgis;
In order to confirm that the installation was successful, you can run the SQL query to check the PostGIS version available:
=> SELECT postgis_version();
postgis_version
--------------------------------------------------
2.1 USE_GEOS=1 USE_PROJ=1 USE_STATS=1
(1 row)
Database tuning
Over time, it is very common that your database starts to generate some dead rows. This is a side effect generated by the Multiversion Concurrency Control (MVCC) mechanism of Postgres that tracks the changes in your database. The UPDATE and DELETEoperations also contribute to generate these lines.
For example, when you DELETE lines, PostgreSQL doesn't remove them physically, instead it just marks them as useless. This process consumes less resources and time. The same happens when you UPDATE rows; internally Postgres performs an insert command by running the command for a new line with the same original data and marks the other one as useless.
Thus, from time to time, it is necessary to carry out some procedures for collecting the database garbage. The same will be discussed in the upcoming sections.
Database VACUUM
The VACUUM procedure is responsible for cleaning this set of useless lines in your database, thus ensuring increased performance.
Usually, the default setting of Heroku Postgres automates this procedure, but eventually you may need to perform this action manually.
The VACUUM command searches for useless lines in your database and removes them physically; this decreases the size of your database accordingly. VACUUM also organizes the records that were not deleted and, so it's guaranteed that there won't be any gaps between records.
Determining the bloat factor
You are able to determine whether your database needs a VACUUM by performing the table and index bloat query, which tells you in case there are any dead rows. Heroku offers a plugin called pg-extras to Heroku Toolbelt that allows this query to be performed.
First, install the plugin:
$ heroku plugins:install git://github.com/heroku/heroku-pg-extras.git
Installing heroku-pg-extras... done
Now you can run the pg:bloat command in order to get statistics about your database:
$ heroku pg:bloat DATABASE_URL --app your-app-name
type | schemaname | object_name | bloat | waste
------+------------+--------------------------+-------+-------
table | public | invitations | 11.5 | 210 MB
table | public | selected_flight_options | 2.6 | 360 kB
As a result of this command, you have the bloat factor. If this is greater than 10, it indicates that this table may be experiencing degraded performance, and corrective action is recommended, especially indicated for tables larger than 100 MB.
Manual vacuuming
Before running VACUUM, it is important for you to understand that there are two main differences between the VACUUM command (without parameters) and VACUUM FULL.
The VACUUM command (without parameters) only removes tuples marked as useless in UPDATE or DELETE processes, so it is unnecessary to lock the database for operations. On the other hand, the VACUUM FULL command also removes the tuples marked as useless and it organizes the tables, removing empty gaps. To perform this process, it is necessary to lock the database in order to guarantee that no other action will be taken.
To run the VACUUM command, open the psql connection through the heroku pg:psql command:
$ heroku pg:psql --app your-app-name
=> VACUUM;
You should also run the VACUUM command in a specific table:
$ heroku pg:psql --app your-app-name
=> VACUUM invitations;
If you want to see information during the VACUUM process, you can add the VERBOSE parameter:
$ heroku pg:psql --app your-app-name
=> VACUUM VERBOSE;
Although you have the freedom to perform the VACUUM command on Heroku Postgres, it is rarely necessary to do it manually. All this can be done automatically if you configure your database properly, as it will be discussed in the upcoming section.
Automatic vacuuming
The automatic way is the most effective way to ensure the performance of your database. It allows you to configure each table or database so you are informed about when the autovacuum should be performed. For example:
$ heroku pg:psql --app your-app-name
=> ALTER TABLE invitations SET (autovacuum_vacuum_threshold = 60);
=> ALTER TABLE invitations SET (autovacuum_vacuum_scale_factor = 0.4);
The preceding setting sets the time that the autovacuum should run in your table. The threshold value defines the raw number of necessary dead lines and the scale factor defines the bloat factor to run the autovacuum process. The default values for these settings are 50 and 0.2 respectively.
With these two settings you get the real limit through the following formula:
vacuum threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * number of rows
You can also impose these settings at the database level, through the following settings:
$ heroku pg:psql --app your-app-name
=> SELECT current_database();
current_database
------------------
d6ufnl4ugp8sq1
(1 row)
=> ALTER DATABASE d6ufnl4ugp8sq1 SET vacuum_cost_page_miss = 10;
=> ALTER DATABASE d6ufnl4ugp8sq1 SET vacuum_cost_limit = 200;
=> ALTER DATABASE d6ufnl4ugp8sq1 SET vacuum_cost_page_hit = 1;
=> ALTER DATABASE d6ufnl4ugp8sq1 SET vacuum_cost_page_dirty = 20;
You can find more details about each of these configuration variables in the documentation at http://www.postgresql.org/docs/current/static/runtime-config-resource.html.
Performance analysis
Heroku Postgres offers, through its dashboard, a graphical interface for analyzing the performance of your database.
It displays the queries through four criteria:
· Most time consuming
· Slowest execution time
· Highest throughput
· Slowest I/O
To view this information, visit https://postgres.heroku.com, select your database, and then go to the Expensive queries section.
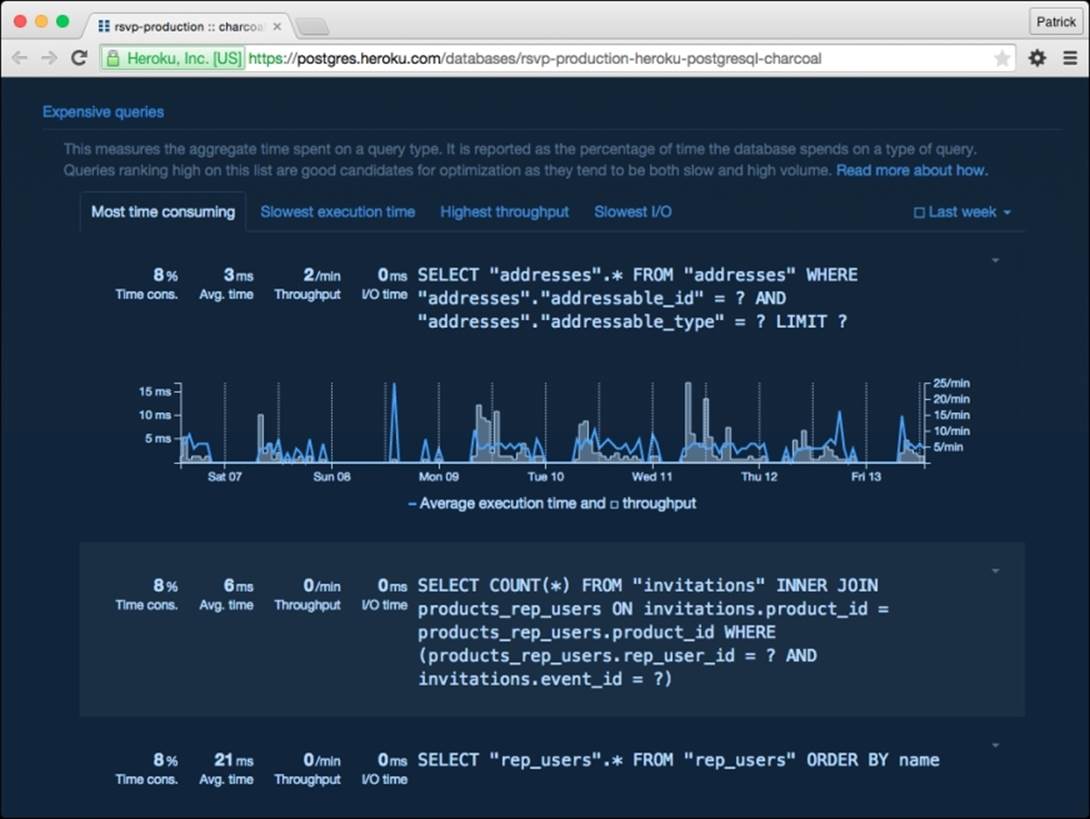
Heroku Postgres expensive queries
Self-test Questions
Answer the following questions as true or false:
1. Are the extensions functionalities that add new features in your database?
2. Is the cube extension used to remove accents?
3. Is the HStore extension useful to work with key value data?
4. Can you store book numbers (ISBN) in your database through the product numbering extension?
5. Does the PLV8 extension allow you to fire queries directly from inside your JavaScript code application?
6. Is the full-text extension useful for text searches across dictionaries?
7. Is it rarely possible to achieve 99% of data cache in your database on Heroku Postgres?
8. Does Heroku Postgres support PostGIS?
9. Should you always run the command VACUUM to improve the performance of your database?
10. Is Heroku Postgres able to do automatic VACUUM in your database?
Summary
In this chapter, you've learned how to use advanced features available in the Heroku Postgres platform.
These features allow you to increase the power of your database by installing extensions that add functionalities to work with data types, indexes, functions, statistics, languages, and full-text searching in your Postgres database.
You have also understood how the Heroku Postgres cache system works. It is also possible to achieve a 99.99% of data caching if your application database and application are well developed.
PostGIS was another interesting feature that you've learned in this chapter. Through this, you are able to work with geographic objects in your SQL queries. You've also noted that PostGIS is available in beta mode on Heroku Postgres.
Finally, you've understood how the tuning process works in your database. You've seen that, from time to time, useless lines are generated. In the vast majority of cases, you don't need to worry about cleaning these lines, because Heroku Postgres does it automatically for you; but, if necessary, you can perform VACUUM manually.
You have reached the end of this book and I hope your learning journey about Heroku Postgres has been very fruitful and that you have acquired all necessary knowledge to improve your work routine in this amazing platform built by Heroku. It was a great honor to help you in this learning process and I hope to see you in future books.
I say goodbye to you with a message from the great Leonardo da Vinci:
"A little knowledge puffs up; great knowledge makes humble. Blasted ears raise proud heads; those full of grain bow down."
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.