Data Manipulation with R, Second Edition (2015)
Chapter 6. Text Manipulation
Text data is one of the most important areas in the field of data analytics. Every day, we are producing a huge amount of text data through various media. For example, Twitter posts, blog writing, and Facebook posts are major sources of text data. Text data can be used to retrieve information in sentiment analysis and even entity recognition. In this chapter, we will discuss how R can be used to process text data, which we can utilize in any text analytics areas. These types of data can also be used in text categorization, predictive analytics, lexical analysis, document summarization, and even in natural language processing. First, we will discuss the default functions of R for processing text data. Then, we will introduce a stringr library to work with text data. We will cover the following topics in this chapter:
· What is text data?
· Sources of text data
· Obtaining text data
· Text processing using default functions
· Text processing using stringr
· Structuring text data for text mining
Text data and its source
Text data is any type of text on any topic. Here is a list of text data and its sources:
· Tweets from any individual, or from any company
· Facebook status updates
· RSS feeds from any news site
· Blog articles
· Journal articles
· Newspapers
· Verbatim transcripts of an in-depth interview
These are the most common sources of text data. In the area of text analytics, Twitter data has been used frequently to find topic trends through topic modeling. Text data has also been used to predict certain diseases from tweets. The HTML web file are also a great source of text data.
Getting text data
Text data can be embedded into any dataset as a string variable. Also, text data can be stored as plain text files even in the HTML file format. In this section, we will see how we can read or import text data into the R environment for further processing.
The easiest way to get text data is to import from a .csv file where some of the variables contain character data. For example, the tweets.csv file contains 50 Twitter statuses on a certain topic. Since this is a .csv file, we can import it using the read.csv() function, but we have to protect automatic factor conversion by specifying the stringsAsFactors=FALSE argument. An example of importing text data from the tweets.csv file is as follows:
textData <- read.csv("tweets.csv",stringsAsFactors=FALSE)
str(textData)
''data.frame'': 50 obs. of 2 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10 ...
$ TWEETS: chr "Sohum Spa at Movenpick HotelSpa Bangalore reveals Indian traditions for relaxation" "Sohum Spa at Movenpick HotelSpa Bangalore reveals Indian traditions for relaxation" "SalesMarketing Manager at Prestige Leisure Resorts Pvt Ltd" "Assistant Front Office Manager at The LEELA PalaceBangalore" ...
So, this is just as simple as importing any other data in R. Now, let's look at an example of obtaining text data from a plain text file. The tweets.txt file is the plain text file. We will import this file using the generic readLines() function:
textData1<-readLines("tweets.txt")"")
str(textData1)
chr [1:51] "ID\tTWEETS " "1\tSohum Spa at Movenpick HotelSpa Bangalore reveals Indian traditions for relaxation" ...
If we see the structure of the textData and textData1 objects, there is a difference. The textData object, which is imported by read.csv(), is a data frame, whereas the textData1 object imported by readLines() is just a vector of characters. To convert the character vector into a data frame, we need some basic processing. We will talk about this in a later section. Importing text data from an HTML page, which is technically known as web scraping, is one of the widely used sources of text data. In this example, we will see how we can import data from the web. Interestingly, the readLines()generic function can be used to read an HTML file too, but later on, we need to process it to have a structured database. Here is an example to importing a Wikipedia article:
# Creating object with the URL
conURL <- "http://en.wikipedia.org/wiki/R_%28programming_language%29"
# Establish the connection with the URL
link2URL <- url(conURL)
# Reading html code
htmlCode <- readLines(link2URL)
# Closing the connection
close(link2URL)
# Printing the result
htmlCode
Like the previous textData1 object. This is also a character string, but this time it contains the HTML code. From this HTML code, we are able to generate structured data for further use.
To obtain text data from social networking sites such as Twitter and Facebook, there are designated R libraries. To extract Twitter data, we can use tweetR and, to extract data from Facebook, we could use facebookR. In the section Working with Twitter data, we will discuss this in detail.
The tm text mining library has some other functions to import text data from various files such as PDF files, plain text files, and even from doc files. Readers are advised to look into the tm library for further information. Discussing the tm library in detail is beyond the scope of this chapter.
Text processing using default functions
Some of you might not be interested in text mining, but you still need to process text data in your day-to-day activities. In this section, we will try to give some examples that will be helpful for your daily needs. The following are the general tasks that we need to perform frequently:
· Removing certain characters or words from a string
· Splitting the character string to get structured information
· Matching certain parts of the characters to find out some patterns
· Changing lowercase to uppercase, and vice versa
· Calculating the number of characters in a string
· Extracting a certain part from a string
· Extracting only digits from a string
We will see an example for each case listed previously. First, we will remove a certain word from a string. To do so, we will use the textData object. This object has two variables, and one of them contains text data. We will use the first observation from that text variable:
# Extracting first observation
text2process <- textData$TWEET[1]
text2process
[1] "Sohum Spa at Movenpick HotelSpa Bangalore reveals Indian traditions for relaxation"
Now, we are interested in removing the prepositions, such as for and at, from the text. To do so, we will use the gsub function, which replaces certain text based on pattern matching. The important arguments of the gsub function are pattern, replacement, and the string is as follows:
prepRemovedText <- gsub(pattern="for",replacement="",x=text2process)
prepRemovedText
[1] "Sohum Spa at Movenpick HotelSpa Bangalore reveals Indian traditions relaxation"
This example shows that the word for has been removed from the original string.
We can also split the string so that it has a different data structure. For example, if we split the text2process object using the splitting character as a blank space, then it will be a vector of the character, with each word separated. Here is an example:
splittedText <- strsplit(text2process,split=" ")
splittedText
[[1]]
[1] "Sohum" "Spa" "at" "Movenpick" "HotelSpa" "Bangalore" "reveals" "Indian" "traditions" "for" "relaxation"
The strsplit function takes a character string as input and the character in split argument specifies the location of split. The output is initially stored in a list object, but to get the output as a vector, we can remove the object from the list in the following way:
unlist(splittedText)
[1] "Sohum" "Spa" "at" "Movenpick" "HotelSpa" "Bangalore" "reveals" "Indian" "traditions" "for" "relaxation"
Converting lowercase and uppercase strings is another important function when we work with text data. Since R is case-sensitive, the words Spa and spa are different, though, in fact, they are the same word. So, to remove ambiguity, we can convert either all the words to lowercase or change them all to uppercase.
To convert into lowercase and then to uppercase, let's take a look at the following example:
tolower(text2process)
[1] "sohum spa at movenpick hotelspa bangalore reveals indian traditions for relaxation"
toupper(text2process)
[1] "SOHUM SPA AT MOVENPICK HOTELSPA BANGALORE REVEALS INDIAN TRADITIONS FOR RELAXATION"
During data analysis and in text processing, we need to know the number of characters in a character string. For example, in some databases, the id variable could be text, and it should contain a certain number of characters. In this case, we need to count whether the required number of characters is present or not. In this example, we will see how to calculate the number of characters from a string. The total number of characters in the text2process string can be found using the nchar() function. This function counts each character, including a blank space:
nchar(text2process)
[1] 82
Now, we will pass the same function, but this time the input will be the unlisted split character vector:
nchar(unlist(splittedText))
[1] 5 3 2 9 8 9 7 6 10 3 10
This time, we have a vector of an integer because the input of the nchar() function, here, is a vector of the character object. So, it returns the number of characters for each component of that input vector.
In some cases, the text variable contains both date and time information. For example, 02Feb2015:11:15PM is a character string. We need to extract only the date part for further processing. To do the task, take a look at this example:
# Creating the character string with date and time information
dateTimeobject <- "02Feb2015:11:15PM"
# Extracting only the character between 1 to 9
# including 1st and 9th
substr(dateTimeobject,1,9)
[1] "02Feb2015"
So, the substr function can be used to extract a portion of text from a character string.
During text processing, sometimes, we need to extract only the digits from a character string. In the example, we will see how we can do this task. In R, we have default color names that can be accessed through the color() function. Some of the color names contains digits such as red1, red2, and so on. In this example, we will extract only the digits from color names:
# to see the color names
colors()
# Now to extract the digit from the color names
as.integer(gsub("\\D", "", colors()))
This table gives us an idea about the facilities in the stringr library and its link with the default R functions:
|
Base R functions |
stringr functions |
|
paste(): This function is used to concatenate a vector of characters, with a default separator as a space. |
str_c(): This has a functionality similar to paste(), but it uses empty as the default separator. It also silently removes zero-length arguments. |
|
nchar(): This returns the number of characters in a character string. For NA, it returns 2, which is not expected. Here is an example: nchar(c("x","y",NA)) [1] 1 1 2 |
str_length(): This is the same as nchar(), but it preserves NA. Here is an example: str_length(c("x","y",NA)) [1] 1 1 NA |
|
substr(): This extracts or replaces substrings in a character vector. |
str_sub(): This is the equivalent of substr(), but it returns a zero-length vector if any of its inputs are of zero length. It also accepts negative positions, which are calculated from the left-hand side of the last character. The end position defaults to -1, which corresponds to the last character. |
|
Unavailable |
str_dup(): This is used to duplicate the characters within a string. |
|
Unavailable |
str_trim(): This is used to remove the leading and trailing white spaces. |
|
Unavailable |
str_pad(): This is used to pad a string with extra white spaces on the left-hand side, right-hand side, or both sides. |
Other than the functions listed in the preceding table, there are some other user-friendly functions for pattern matching. These functions are str_detect, str_locate, str_extract, str_match, str_replace, and so on. To get more details about these functions, you should refer to the stringr: . It is a modern, consistent string-processing paper by Hadley Wickham, which can be found at http://journal.r-project.org/archive/2010-2/RJournal_2010-2_Wickham.pdf.
Working with Twitter data
Twitter is one of the best sources of text data. In this section, we will extract text data from Twitter using the #rstats hashtag. After extracting the text, we will clean it and then produce a wordcloud. The required libraries for this particular section are as follows:
· tm
· wordcloud
To extract data from Twitter, first, we need to connect with the Twitter account through a valid authentication process. The code to authenticate the R session with Twitter to extract data, is as follows:
library(twitteR)
# need to provide actual string for each key by replacing xxxx
setup_twitter_oauth(consumer_key="xxxx",
consumer_secret="xxxx",
access_token="xxxx", access_secret="xxxx")
Once the authentication process is complete, we can extract text data. In the following code, we extracted data for 500 tweets with a #rstats hashtag. We restricted the tweets to English only. The results of this section will be changed over time.
# Extracting 500 recent tweets with #rstats hashtag
# and language of the tweets is English
tweets<-searchTwitter("#rstats", n=500,lang='en')
The object will be listed in nature with lots of information related to tweets. We can easily check the structure of the newly created objects using the following str() function:
str(tweets)
To prepare a word cloud, we will use only the status text from the extracted tweets. To do so, we need to convert the list object into a data frame and then take only the text column. The code chunk to get only the text column is as follows:
datTweet<-plyr::ldply(tweets,as.data.frame)
vecStatus <- datTweet$text
The next step is to clean the text by removing HTML tags, retweets tags (RT), and punctuation symbols:
#Clean Text
vecStatus = gsub("(RT|via)((?:\\b\\W*@\\w+)+)","",vecStatus)
vecStatus = gsub("http[^[:blank:]]+", "", vecStatus)
vecStatus = gsub("@\\w+", "", vecStatus)
vecStatus = gsub("[ \t]{2,}", "", vecStatus)
vecStatus = gsub("^\\s+|\\s+$", "", vecStatus)
vecStatus <- gsub('\\d+', '', vecStatus)
vecStatus = gsub("[[:punct:]]", " ", vecStatus)
# additional cleaning by tm library
library(tm)
corpus = Corpus(VectorSource(vecStatus))
corpus = tm_map(corpus,removePunctuation)
corpus = tm_map(corpus,stripWhitespace)
corpus = tm_map(corpus,tolower)
corpus = tm_map(corpus,removeWords,stopwords("english"))
Once we clean the text, it is now ready to produce a word cloud of the texts. To make a word cloud, we will call the wordclund library and then use the wordcloud()function, as shown in the following example:
library(wordcloud)
wordcloud(corpus)
The following screenshot shows the wordcloud corresponding to the 500 extracted tweets using rstats hashtag:
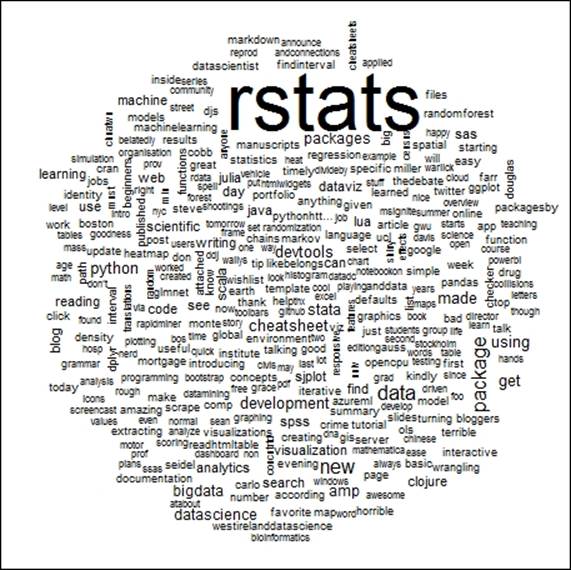
Summary
In this chapter, we tried to discuss the source of text data and how plain text can be handled using R. We also compared functions from the stringr library with the default R functions to process text data. In the final section, we showed you how to extract text data from Twitter posts and then clean the data to produce a word cloud. The processed text data can be used in other text-mining applications, such as topic modeling and sentiment analysis.