Learning Nagios 4 (2014)
Chapter 2. Installing Nagios 4
The previous chapter has described what Nagios is, the basic concepts of monitoring, and types of objects in Nagios. This chapter describes how to install Nagios and the standard Nagios plugins. The process described here does not take advantage of any packaging systems that are currently available on the majority of operating systems.
In this chapter, we will cover the following points:
· How to upgrade Nagios from a previous version
· Installing Nagios prerequisites (software, users, and groups)
· Obtaining and compiling Nagios from source
· Installing Nagios and setting up a system service
· Configuring Nagios with a basic set of objects
· Setting up basic notifications
· Using templates and object inheritance
Installation
Nagios can be installed in two ways. The first one is to install Nagios from your Linux distribution's binary packages, which has the upside that the packages are updated in terms of security issues by your Linux distribution automatically or by running updates manually. The downside is that for many distributions, Nagios 4 may not be available for some time, such as long term support distributions that may be providing the Nagios 3.x version.
Another option is to compile and install Nagios manually. Manual installation is recommended for system administrators who want more power where their software is installed, and want to manage software upgrades and configuration on their own. It also allows updating to latest version of Nagios faster; binary distributions may not always have the latest versions.
This section discusses the installation of Nagios 4. It focuses on Ubuntu Linux distribution, but the commands for Ubuntu are also valid for Debian Linux distribution. This chapter also has guides for RedHat and CentOS Linux distributions. If you are using a different Linux distribution, the commands may be slightly different.
Upgrading from previous versions
If you already have Nagios setup, it is worth upgrading to Nagios 4, either to take advantage of the new features or performance improvements that the latest version offers. While upgrading, you should proceed with the same steps as when performing a fresh installation. You need to use the same username, groups, and directories that you have used for the previous Nagios installation. It is also needed to stop all Nagios processes before performing an upgrade. This can usually be done by invoking the following command:
service nagios stop
The preceding command works on all modern Linux distributions and supports services installed as SysVinit (in /etc/init.d or /etc/rc.d/init.d) and Upstart services (added in /etc/init and using a different format of the service file definition).
If the preceding command did not work properly, running the init.d script directly should work:
service nagios stop
It is recommended to stop Nagios while compiling and installing a new version. You should then proceed with the installation steps described in the next sections. Almost all of Nagios 4 configuration parameters are backward compatible, so your current configuration will work fine after upgrading. Backward incompatibilities between Nagios 4 and 3 are mentioned in Chapter 1, Introducing Nagios. Once the new version of Nagios is installed, it is recommended to check the Nagios configuration with the new version to ensure there are no incompatibilities:
/opt/nagios/bin/nagios -v /etc/nagios/nagios.cfg
We can now simply run the command:
service nagios start
If the preceding command did not work properly, run the following init.d script, and the upgrade process should be complete:
/etc/init.d/nagios start
Installing prerequisites
This section applies for people compiling Nagios from sources and manually installing them. Almost all modern Linux distributions include Nagios in their packages. Nagios website also offers instructions for automated installation on several operating systems. In such cases, all related packages will be installed by the underlying system (such as APT in Debian and Ubuntu systems and Yum for RedHat and CentOS systems). Usually, a system with a set of development packages installed already contains all the packages needed to build Nagios.
Building Nagios from sources requires having a C compiler, standard C library development files, and the make/imake command. Additionally, development files for OpenSSL should be installed so that network-based plugins will be able to communicate over an SSL layer. MySQL and PostgreSQL development packages should also be installed so that database checks can be run.
First of all, if we're planning to build the Nagios system, a compiler along with several build tools will be required. These are gcc, make, cpp, and binutils. It also needs standard C library development files. All those packages are often already installed, but make sure they are present, as they are needed before any compilation.
Nagios by itself does not have a large number of packages that need to be installed on your system in order for it to offer the basic functionality. However, if we want to use all functionalities that Nagios can offer, it is required to install an additional software.
If we want to use the Nagios web interface, a web server capable of serving CGI scripts is required. Apache web is the recommended and also the most popular web server on a Linux installation. Even though Nagios should work with any web server supporting CGI and PHP, the book covers configuring Apache.
Additionally, several plugins from the Nagios standard distribution are written in Perl and will not work if Perl is not installed. Some plugins also need Perl's Net::Snmp package to communicate with devices over the SNMP protocol.
Also, the GD graphics library is needed for the Nagios web interface to create status map and trends images. We will also install libraries for JPEG and PNG images so that GD can create images in these formats.
All of the packages mentioned earlier are usually installed with many operating systems and most of them are already available for almost any Unix-based platform.
Throughout this chapter, we will use the Ubuntu Linux 12.04 Precise distribution as it is very popular. All newer Ubuntu platforms use the same package names, so the following commands will work without any problem.
We will also install Apache 2 and Perl from Ubuntu packages. For different operating systems, the package names might be different but should be similar. A command to install all the packages for our chosen distribution is as follows:
apt-get install gcc make binutils cpp \
libpq-dev libmysqlclient-dev \
libssl1.0.0 libssl-dev pkg-config \
libgd2-xpm libgd2-xpm-dev libgd-tools \
perl libperl-dev libnet-snmp-perl snmp \
apache2 libapache2-mod-php5
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account from http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Package names might be different for other operating systems and distributions. The command to install corresponding packages might also be different. For RPM packages, the naming convention is a bit different development; packages have devel suffix. Libraries themselves are also named slightly differently.
For Red Hat Enterprise Linux, CentOS and Fedora Core operating systems with yum installed, the command to install all prerequisites would be as follows:
yum install gcc make imake binutils cpp \
postgresql-devel mysql-libs mysql-devel \
openssl openssl-devel pkgconfig \
gd gd-devel gd-progs libpng libpng-devel \
libjpeg libjpeg-devel perl perl-devel \net-snmp net-snmp-devel net-snmp-perl net-snmp-utils \
httpd php
The preceding command is for the CentOS 6 Linux distribution. Package names may vary slightly depending on your system's distribution and version. The packages include tools for compiling applications, various libraries, and their development packages. Apache and PHP5 are needed for the web interface, which is described in more detail in Chapter 3, Using the Nagios Web Interface. Usually a system with a set of development packages installed already contains all of the packages needed to build Nagios.
Obtaining Nagios
Nagios is an open source application, which means that source code of all Nagios components is freely available from the Nagios home page. Nagios is distributed under GNU GPL (General Public License) Version 2 (visit http://www.gnu.org/licenses/old-licenses/gpl-2.0.html for more details), which means that the Nagios source code can be redistributed and modified almost freely under the condition that all changes are also distributed as source code. Nagios also has a standard set of plugins, named Nagios plugins, which are developed independently as SourceForge project available at http://sourceforge.net/projects/nagiosplug/ and are distributed under the GPL Version 3 license, which can be found at http://www.gnu.org/licenses/gpl.html.
First of all, many operating systems already have binary distributions of Nagios. If you are not an IT expert and just want to try out or learn Nagios in your environment, it is best to use binary distributions instead of compiling Nagios by yourself. Therefore, it is recommended to check if your distribution does not contain a compiled version of Nagios 4. For RedHat and Fedora Linux systems, Nagios download page (available at http://www.nagios.org/download/) contains RPMs that can be simply installed onto your system. For other distributions, their package repository might contain binary Nagios packages. The NagiosExchange website (http://exchange.nagios.org/) also hosts Nagios builds for various platforms, such as AIX or SUSE Linux. All binary distributions of Nagios are split into packages (the rpm, dpkg, pkg, or bin file) that contain the Nagios daemon. It is usually called Nagios, and the standard set of plugins is usually named Nagios plugins.
If you are an experienced user and want to control software installed on your machines, it's recommended to install Nagios from sources. In that case, you should also download sources of both Nagios and its plugins. In order to download the Nagios source packages, please go to the Nagios download page, available at http://www.nagios.org/download/. All Nagios downloads are hosted on SourceForge, so the download links will redirect you to the SourceForge download page. The download process should begin automatically.
You should start by downloading the source tarball of the latest Nagios 4.x branch. It is available under the Get Nagios Core section. When asked about Nagios software editions, please choose the free version of Nagios. The filename of the source tarball should be similar to nagios-4.0.tar.gz, depending on what is the exact version of latest stable release.
You should also download the source tarball of the latest Nagios plugins from the same download page. It is available under the Get Nagios Plugins page. The filename for the plugins should be similar to nagios-plugins-1.4.16.tar.gz, also depending on which the exact version of latest stable release is.
To unpack both the files, we first need to create a source directory; we will use /usr/src/nagios4 throughout the chapter, but the path can be any location. To create it and unpack both files, we should execute the following commands:
mkdir /usr/src/nagios4
cd /usr/src/nagios4
tar –xzf /path/to/nagios-4.0.tar.gz
tar –xzf /path/to/nagios-plugins-1.4.16.tar.gz
Setting up users and groups
This section describes how to do a compilation and installation of Nagios and standard Nagios plugins from source tarballs. If you plan on installing Nagios from binary distributions, you should skip this section and proceed to the next section that describes the exact Nagios configurations. You might also need to adjust parameters mentioned in the book to use directories that your Nagios installation uses. If you are upgrading from a previous Nagios version, then you already have all users and groups properly set up. In such cases, you should proceed to the next section.
The first thing that needs to be done is to decide where to install Nagios. In this section, we'll install Nagios binaries into the /opt/nagios directory and all configuration files will be based on these locations. This is a location for all Nagios binaries, plugins, and additional files. The Nagios data will be stored in the /var/nagios directory. This is where the status of everything is kept. It can be a part of the Nagios binaries installation directory or a separate directory, as in our case. The Nagios configuration will be put into/etc/nagios. These directories will be created as part of the Nagios installation process.
After we have decided on our directory structure, we need to set up the users and groups for Nagios data. We'll also create a system user and a group named nagios, which will be used by the daemon. We'll also set up the nagioscmd group that can communicate with the daemon. The Nagios user will be a member of the nagios and nagioscmd groups. The following commands will create the groups and users:
groupadd nagios
groupadd nagioscmd
useradd -g nagios -G nagioscmd -d /opt/nagios nagios
The reason for creating additional users in the system is that Nagios uses a separate user. This increases security and allows a more flexible setup. Nagios also communicates with external components over a Unix socket. This is a socket that works similar to a file on your file system. All commands are passed to Nagios via the pipe, and therefore, if you want your processes to be able to send reports or changes to Nagios, you need to make sure they have access to the socket. One of typical uses for this is that the Nagios web interface needs to be able to send commands to the monitoring process.
If you want to use the web interface, it is necessary to add the user that your web server runs at to the nagioscmd group. This will allow the web interface to send commands to Nagios. The user that the web server is working as is usually www-data, apache, or httpd. It can be checked with a simple grep command:
root@ubuntu:~# grep -r ^User /etc/apache* /etc/httpd*
/etc/apache2/apache2.conf:User www-data
For our preceding example, we now know the user name is www-data.
Sometimes on Ubuntu, the setting is slightly different, as shown in the following command:
root@ubuntu:~# grep -r ^User /etc/apache* /etc/httpd*
/etc/apache2/apache2.conf:User ${APACHE_RUN_USER}
In that case, the value is defined in the /etc/apache2/envvars file:
# grep APACHE_RUN_USER /etc/apache2/envvars
/etc/apache2/envvars:export APACHE_RUN_USER=www-data
In this case, the user name is also www-data.
Now we will add this user to the nagioscmd group. This requires a simple command to be run:
usermod -G nagioscmd www-data
Compiling and installing Nagios
The next step is to set up the Nagios destination directories and change their owners accordingly. The following commands will create the directories and change their owner user and group to nagios.
mkdir -p /opt/nagios /etc/nagios /var/nagios
chown nagios:nagios /opt/nagios /etc/nagios /var/nagios
We will now create a source directory, where all of our builds will take place. For the purpose of this book, it will be /usr/src/nagios4. We need to extract our Nagios and standard plugins into that directory. The extraction will create nagios-4.0 and nagios-plugins-1.4.16 subdirectories (or similar ones, depending on your source versions).
Now lets go to the directory where Nagios sources are located; in our case it is /usr/src/nagios4/nagios-4.0. We'll configure Nagios parameters for the directories, we plan to install it by running the configure script. Some of the options that the script accepts are described in the following table:
|
Option |
Description |
|
--prefix=<dir> |
Specifies the main directory in which all Nagios binaries are installed; this defaults to /usr/local/nagios |
|
--sysconfdir=<dir> |
Specifies the directory where all Nagios configurations will be stored; this defaults to [PREFIX]/etc |
|
--localstatedir=<dir> |
Specifies the directory where all Nagios status and other information will be kept; this defaults to [PREFIX]/var |
|
--with-nagios-user=<user> |
Specifies the Unix user to be used by the Nagios daemon; this defaults to nagios |
|
--with-nagios-group=<grp> |
Specifies the Unix group to use for the Nagios daemon; this defaults to nagios |
|
--with-mail=<path> |
Specifies the path to the mail program used for sending e-mails |
|
--with-httpd-conf=<path> |
Specifies the path to the Apache configuration directory; this can be used to generate Apache configuration files |
|
--with-init-dir=<path> |
Specifies the directory where all scripts required for setting up a system service should be installed; this defaults to /etc/rc.d/init.d |
For the directory structure that was described earlier in this section, the following configure script should be used:
sh configure \
--prefix=/opt/nagios \
--sysconfdir=/etc/nagios \
--localstatedir=/var/nagios \
--libexecdir=/opt/nagios/plugins \
--with-command-group=nagioscmd
The script might take time to complete as it will try to guess the configuration of your machine and verify how to build Nagios. If the configure script fails, the most probable reason is that one or more prerequisites are missing. At that point, you will need to analyze which test failed and install or configure additional packages. Most of the times, the output is quite clear, and it is easy to understand what went wrong.
Assuming the configure command worked, we now need to build Nagios. The build process uses the make command, similar to almost all Unix programs. The following commands can be used to build or install Nagios:
|
Command |
Description |
|
make all |
Compiles Nagios; this is the first thing you should be doing |
|
make install |
Installs the main program, CGI, and HTML files |
|
make install-commandmode |
Installs and configures the external command file |
|
make install-config |
Installs the sample Nagios configuration; this target should only be used for fresh installations |
|
make install-init |
Installs scripts to set up Nagios as a system service |
First, we'll need to build every module within Nagios. To do this, simply run the following command:
make all
If an error occurs, it is probably due to some header files missing or a development package not installed. The following is a sample output from a successful Nagios build. It finishes with a friendly message saying that it has completed successfully.
cd ./base && make
make[1]: Entering directory '/usr/src/nagios4/base'
[…]
*** Compile finished ***
[…]
*************************************************************
Enjoy.
If an error occurs during the build, information about it is also shown. For example, the following is a sample output from the build:
[…]
In file included from checks.c:40:
../include/config.h:163:18: error: ssl.h: No such file or directory
[…]
make[1]: *** [checks.o] Error 1
make[1]: Leaving directory '/usr/src/nagios4/base'
make: *** [all] Error 2
If this or a similar error occurs, please make sure that you have all the prerequisites mentioned earlier installed. Also, please make sure that you have enough memory and storage space during compilation as this might also cause unexpected crashes during builds.
On Ubuntu systems, it is possible to look for development packages using the apt-cache search command; for example, apt-cache search ssl will find all packages related to OpenSSL. Development packages always have the -dev suffix in their package name—in this case, it would be the libssl-dev package. Combined with the grep command to filter only development packages, for SSL it would be the following command:
apt-cache search ssl | grep -- -dev
On RedHat Enterprise Linux, CentOS and Fedora Core, it is possible to look for development packages using the yum search command:
yum search ssl | grep -- -devel
Now, we need to install Nagios by running the following commands:
make install
make install-commandmode
For a fresh install, it is recommended to also install sample configuration files that will be used later for configuring Nagios:
make install-config
At this point Nagios is installed. It is recommended to keep all of your Nagios sources, as well as prepare dedicated scripts that install Nagios. This is just in case you decide to enable/disable specific options and don't want to guess how exactly Nagios was configured to build the last time it was installed.
Compiling and installing Nagios plugins
The next step that should be carried out is compile Nagios Plugins package. Similar to Nagios, we can both install packages from binary distributions or compile the standard plugins from source code. To install the plugins on an Ubuntu Linux distribution, we can run the following command:
apt-get install nagios-plugins-basic nagios-plugins-standard
And for RedHat Enterprise Linux and CentOS, we need to run the following command:
yum -y install nagios-plugins-all
If you choose to install the Nagios plugins manually you may continue to the next section and skip the manual installation process. In order to compile Nagios plugins manually, first let's go to the directory where Nagios plugins source code is located, in our case it is/usr/src/nagios4/nagios-plugins-1.4.16. We'll configure Nagios plugins parameters for the directories, we plan to install it by running the configure script. Some of the options that the script accepts are described in the following table:
|
Option |
Description |
|
--prefix=<dir> |
Specifies the main directory in which all Nagios binaries are installed; defaults to /usr/local/nagios |
|
--sysconfdir=<dir> |
Specifies the directory where all Nagios configurations will be stored; defaults to [PREFIX]/etc |
|
--libexecdir=<dir> |
Specifies the directory where all Nagios plugins will be installed; defaults to [PREFIX]/libexec |
|
--localstatedir=<dir> |
Specifies the directory where all Nagios status and other information will be kept; defaults to [PREFIX]/var |
|
--enable-perl-modules |
Installs the Nagios::Plugin package along with all dependant packages |
|
--with-nagios-user=<user> |
Specifies the Unix user used by the Nagios daemon; defaults to nagios |
|
--with-nagios-group=<grp> |
Specifies the Unix group to use for the Nagios daemon; defaults to nagios |
|
--with-pgsql=<path> |
Specifies path to PostgreSQL installation; required for building of PostgreSQL testing plugins |
|
--with-mysql=<path> |
Specifies the path to the MySQL installation; required for building of MySQL testing plugins |
|
--with-openssl=<path> |
Specifies the path to the OpenSSL installation; can be specified if OpenSSL is installed in a non-standard location (such as /opt/nagios/openssl) |
|
--with-perl=<path> |
Specifies the path to Perl installation; can be specified if Perl is installed in a non-standard location (such as /opt/nagios/perl) |
The --enable-perl-modules option enables installing additional Perl modules (Nagios::Plugin and its dependencies) that aid in developing your own Nagios plugins in Perl. It is useful to enable this option if you are familiar with Perl.
The --with-pgsql and --with-mysql options allow us to specify locations for the installations of PostgreSQL and/or MySQL databases. It is used to create plugins for monitoring PostgreSQL and/or MySQL. If not specified, the build process will look for the development files for these databases in their default locations. Installing development files for these databases is described in the Prerequisites section. For the directory structure that was described earlier in this section, the following configure script should be used:
sh configure \
--prefix=/opt/nagios \
--sysconfdir=/etc/nagios \
--localstatedir=/var/nagios \
--libexecdir=/opt/nagios/plugins
The script should run for some time and succeed, assuming that all prerequisites are installed. If not, the script should indicate what the missing component is. The build process also uses the make command similar to how Nagios is compiled. In this case, only alland install targets will be used. Therefore, the next step is to run the make commands as shown here:
make all
make install
If any of these steps fail, an investigation on what exactly has failed is needed, and if it is due to a missing library or a development package, please install those and try again. If all of the preceding commands succeeded, then you now have a fully installed Nagios setup. Congratulations!
The next step is to make sure that Nagios is working properly after being set up. To do this, we can simply run Nagios with the sample configuration that was created by install-config.
We should run it as a nagios user, since the process will be run as normally only as a nagios user. We will use the su command to switch the user and run the specified command:
# su -c '/opt/nagios/bin/nagios /etc/nagios/nagios.cfg' nagios
Nagios Core 4.0.0
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 05-24-2013
License: GPL
Website: http://www.nagios.org
Nagios 4.0.0 starting... (PID=1302)
Local time is Fri Aug 30 21:01:59 CEST 2013
nerd: Channel hostchecks registered successfully
nerd: Channel servicechecks registered successfully
nerd: Channel opathchecks registered successfully
nerd: Fully initialized and ready to rock!
wproc: Successfully registered manager as @wproc with query handler
wproc: Registry request: name=Core Worker 1304;pid=1304
wproc: Registry request: name=Core Worker 1303;pid=1303
wproc: Registry request: name=Core Worker 1306;pid=1306
wproc: Registry request: name=Core Worker 1305;pid=1305
Successfully launched command file worker with pid 1307
This message indicates that the process was successfully started. After we have verified that Nagios has started successfully, we now need to press Ctrl + C to stop the Nagios process.
Setting up Nagios as a system service
After installing Nagios, it is worth making sure the daemon will be running as a system service, and will properly start up during system boot. In order to do this, go to the sources directory; in our case it is /usr/src/nagios4/ nagios-4.0. Then, run the following command:
make install-init
This will install a script in our init.d directory (this usually is /etc/init.d or /etc/rc.d/init.d). The script is automatically created, and will contain usernames and paths that were put when the configure script was run. To check it, simply run the following command:
# /etc/init.d/nagios start
In Nagios 4.0.0, the /etc/init.d/nagios script shipped with the source code does not work properly on Ubuntu Linux. If running the preceding command failed, a solution can be found in the next section. The next step is to set up a system to stop and start this service automatically. For Ubuntu Linux distributions, the command is:
update-rc.d nagios defaults
For RedHat Enterprise Linux and CentOS, the command is:
chkconfig --add nagios ; chkconfig nagios on
After Nagios has been set up as a system service, it is recommended to reboot to verify that it is actually starting. After your system has been fully restarted, make sure that Nagios is running. This can be done by checking the process list as follows:
root@ubuntu:~# ps –ef|grep ^nagios
nagios 796 1 0 00:00:00 /opt/nagios/bin/nagios –d /etc/nagios/nagios.cfg
If at least one process is found, it means that Nagios has been properly started. If not, please read the Nagios log file (which has the name /var/nagios/nagios.log assuming the Nagios installed using the method described earlier) and see why exactly it was failing. This usually relates to incorrect permissions. In such case, you should perform all steps mentioned in previous sections and reinstall Nagios from the beginning.
The result of the startup is mentioned at the end of the log file and an error indication should also be present of what the issue might be. For example, a part of the log for an error related to incorrect permissions is as follows:
[1377937468] Nagios 4.0.0 starting... (PID=1403)
[1377937468] Local time is Sat Aug 31 10:24:28 CEST 2013
[1377937468] LOG VERSION: 2.0
[1377937468] qh: Socket '/var/nagios/rw/nagios.qh' successfully initialized
[1377937468] qh: core query handler registered
[1377937468] nerd: Channel hostchecks registered successfully
[1377937468] nerd: Channel servicechecks registered successfully
[1377937468] nerd: Channel opathchecks registered successfully
[1377937468] nerd: Fully initialized and ready to rock!
[1377937468] wproc: Successfully registered manager as @wproc with query handler
[1377937468] wproc: Registry request: name=Core Worker 1407;pid=1407
[1377937468] wproc: Registry request: name=Core Worker 1405;pid=1405
[1377937468] wproc: Registry request: name=Core Worker 1404;pid=1404
[1377937468] wproc: Registry request: name=Core Worker 1406;pid=1406
[1377937468] Successfully launched command file worker with pid 1408
[1377937468] Error: Could not open external command file for reading via open(): (13) -> Permission denied
By default, Nagios also sends its logs to syslog daemon. So if the Nagios log file does not exist, looking into system log (usually /var/log/messages or /var/log/syslog) might provide some information on the problem. If you wish to start or stop Nagios manually, please run the nagios script from the init.d directory with one of the parameters:
/etc/init.d/nagios stop|start|restart
Please note that path to the init.d directory might be different for your operating system.
Resolving errors with script for Nagios system service
This section is mainly meant to provide a solution if the /etc/init.d/nagios script that was installed in the previous section does not work. If creating the service worked for you and Nagios has started properly, you should skip this section and continue on to the next one.
If the /etc/init.d/nagios script installed by the Nagios make install-init command is working properly, the following is a minimal version of the script that works on all modern Linux systems. Before starting, we should first create a backup of the original file by executing the following command:
cp /etc/init.d/nagios /etc/init.d/nagios.bak
Next, we can create a new /etc/init.d/nagios file using the following code:
#!/bin/sh
BINARY=/opt/nagios/bin/nagios
CONFIG=/etc/nagios/nagios.cfg
is_running ()
{
pgrep -U nagios nagios >/dev/null 2>&1
}
case "$1" in
start)
if is_running ; then
echo "Nagios is already running"
else
echo "StartingStartingStartingStartingt Nagios"
su -c "$BINARY -d $CONFIG" nagios
fi
;;
stop)
if is_running ; then
echo "Stopping Nagios"
pkill -U nagios nagios >/dev/null 2>&1
else
echo "Nagios is not running"
fi
;;
restart|force-reload|reload)
$0 stop
Sleep 5
$0 start
;;
*)
echo "Usage: $0 start|stop|restart"
;;
esac
Next, make sure that the file can be run as a script by changing the permissions to 0755 and restart the Nagios service:
chmod 0755 /etc/init.d/nagios
service nagios restart
The command does not make use of distribution-specific commands (such as daemon or start-stop-daemon tools) and only uses the pgrep and pkill commands available on all recent Linux distributions.
Note
This script does not make use of all Nagios features (such as pre-cached objects) and should only be used in case of running into errors with the script bundled with the Nagios source code.
Configuring Nagios
Nagios stores it's configuration in a separate directory. Usually it's either in /etc/nagios or /usr/local/etc/nagios. If you followed the steps for manual installation, it's in /etc/nagios. We will now configure Nagios so that it is ready for use. While it will not be easy to check the results right away, we will verify that the configuration itself is valid. Chapter 3, Using the Nagios Web Interface, talks about setting up the Nagios web interface, which will allow us to check the status of the host and services that we will create in this section.
Creating the main configuration file
The main configuration file is called nagios.cfg, and it is the main file that is loaded during Nagios startup. Its syntax is simple, a line beginning with # is a comment, and all lines in the form of <parameter>=<value> set a value. In some cases, a value might be repeated (like specifying additional files/directories to read). The following is a sample of the Nagios main configuration file:
# log file to use
log_file=/var/nagios/nagios.log
# object configuration directory
cfg_dir=/etc/nagios/objects
# storage information
resource_file=/etc/nagios/resource.cfg
status_file=/var/nagios/status.dat
status_update_interval=10
(…)
The main configuration file needs to define a log file to use, and that has to be passed as the first option in the file. It also configures various Nagios parameters that allow tuning its behavior and performance. The following are some of the commonly changed options:
|
Option |
Description |
|
log_file |
Specifies the log file to use; defaults to [localstatedir]/nagios.log |
|
cfg_file |
Specifies the configuration file to read for object definitions; might be specified multiple times |
|
cfg_dir |
Specifies the configuration directory where all files in it should be read for object definitions; might be specified multiple times |
|
resource_file |
File that stores additional macro definitions; [sysconfdir]/resource.cfg |
|
temp_file |
Path to a temporary file that is used for temporary data; defaults to [localstatedir]/nagios.tmp |
|
lock_file |
Path to a file that is used for synchronization; defaults to [localstatedir]/nagios.lock |
|
temp_path |
Path to where Nagios can create temporary files; defaults to /tmp |
|
status_file |
Path to a file that stores the current status of all hosts and services; defaults to [localstatedir]/status.dat |
|
status_update_interval |
Specifies how often (in seconds) the status file should be updated; defaults to 10 (seconds) |
|
nagios_user |
User to run the daemon |
|
nagios_group |
Group to run the daemon |
|
command_file |
It specifies the path to the external command line that is used by other processes to control the Nagios daemon; defaults to [localstatedir]/rw/nagios.cmd |
|
use_syslog |
Whether Nagios should log messages to syslog as well as to the Nagios log file; defaults to 1 (enabled) |
|
state_retention_file |
Path to a file that stores state information across shutdowns; defaults to [localstatedir]/retention.dat |
|
retention_update_interval |
How often (in seconds) the retention file should be updated; defaults to 60 (seconds) |
|
service_check_timeout |
After how many seconds should a service check be assumed that it has failed; defaults to 60 (seconds) |
|
host_check_timeout |
After how many seconds should a host check be assumed that it has failed; defaults to 30 (seconds) |
|
event_handler_timeout |
After how many seconds should an event handler be terminated; defaults to 30 (seconds) |
|
notification_timeout |
After how many seconds should a notification attempt be assumed that it has failed; defaults to 30 (seconds) |
|
enable_environment_macros |
Whether Nagios should pass all macros to plugins as environment variables; defaults to 1 (enabled) |
|
interval_length |
Specifies the number of seconds a "unit interval" is; this defaults to 60, which means that an interval is one minute; it is not recommended to change the option in any way, as it might end with undesirable behavior |
For a complete list of accepted parameters, please consult with the Nagios documentation available at http://library.nagios.com/library/products/nagioscore/manuals/.
The Nagios option resource_file defines a file to store user variables. This file can be used to store additional information that can be accessed in all object definitions. These usually contain sensitive data as they can only be used in object definitions and it is not possible to read their values from the web interface. This makes it possible to hide passwords to various sensitive services from Nagios administrators without proper privileges. There can be up to 32 macros, named $USER1$, $USER2$ … $USER32$. The Macro definition$USER1$ defines the path to Nagios plugins and is commonly used in check command definitions.
The cfg_file and cfg_dir options are used to specify files that should be read for object definitions. The first option specifies a single file to read and second specifies the directory to read all files with the .cfg extension in the directory and all child directories. Each file may contain different types of objects. The next section describes each type of definitions that Nagios uses.
One of the first things that needs to be planned is how your Nagios configuration should be stored. In order to create a configuration that will be maintainable as your IT infrastructure changes, it is worth investing some time to plan out how you want your host definitions set up and how that could be easily placed in a configuration file structure. Throughout this book, various approaches on how to make your configuration maintainable are discussed. It's also recommended to set up a small Nagios system to get a better understanding of the Nagios configuration before proceeding to larger setups.
Sometimes, it is best to have the configuration grouped into directories by locations in which hosts and/or services are. In other cases, it might be best to keep definitions of all servers with a similar functionality in one directory.
A good directory layout makes it much easier to control the Nagios configuration; for example, massively disable all objects related to a particular part of the IT infrastructure Even though it is recommended to use downtimes, it is sometimes useful to just remove all entries from the Nagios configuration.
Throughout all configuration examples in this book, we will use the directory structure. A separate directory is used for each object type and similar objects are grouped within a single file. For example, all command definitions are to be stored in the commands/subdirectory. All host definitions are stored in the hosts/<hostname>.cfg file.
For Nagios to read the configuration from these directories, edit your main Nagios configuration file (/etc/nagios/nagios.cfg), remove all the cfg_file and cfg_dir entries, and add the following ones:
cfg_dir=/etc/nagios/commands
cfg_dir=/etc/nagios/timeperiods
cfg_dir=/etc/nagios/contacts
cfg_dir=/etc/nagios/contactgroups
cfg_dir=/etc/nagios/hosts
cfg_dir=/etc/nagios/hostgroups
cfg_dir=/etc/nagios/services
cfg_dir=/etc/nagios/servicegroups
The next step is to create the directories by executing the following commands:
root@ubuntu:~# cd /etc/nagios
root@ubuntu:/etc/nagios# mkdir commands timeperiods \
contacts contactgroups hosts hostgroups services servicegroups
In order to use default Nagios plugins, copy the default Nagios command definition file /etc/nagios/objects/commands.cfg to /etc/nagios/commands/default.cfg. Also, make sure that the following options are set as follows in your nagios.cfg file:
check_external_commands=1
interval_length=60
accept_passive_service_checks=1
accept_passive_host_checks=1
If any of the options is set to a different value, please change it and add it at the end of the file if they are not currently present. After such changes in the Nagios setup, you can now move on to next sections and prepare a working configuration for your Nagios installation.
Understanding macro definitions
The ability to use macro definitions is one of the key features of Nagios. They offer a lot of flexibility in object and command definitions. Nagios also provides custom macro definitions, which give you greater possibility to use object templates for specifying parameters common to a group of similar objects.
All command definitions can use macros. Macro definitions allow parameters from other objects, such as hosts, services, and contacts to be referenced so that a command does not need to have everything passed as an argument. Each macro invocation begins and ends with a $ sign.
A typical example is a HOSTADDRESS macro, which references the address field from the host object. All host definitions provide the value of the address parameter. The following is a host and command definition:
define host{
host_name somemachine
address 10.0.0.1
check_command check-host-alive
}
define command{
command_name check-host-alive
command_line $USER1$/check_ping -H $HOSTADDRESS$
-w 3000.0,80% -c 5000.0,100% -p 5
}
The following command will be invoked:
/opt/nagios/plugins/check_ping -H 10.0.0.1 -w 3000.0,80% -c 5000.0,100% -p 5
Also, please note that the USER1 macro was also used and expanded as a path to the Nagios plugins directory. This is a macro definition that references the data contained in a file that is passed as the resource_file configuration directive. Even though it is not required for the USER1 macro to point to the plugins directory, all standard command definitions that come with Nagios use this macro, so it is not recommended to change it. Some of the macro definitions are listed in the following table:
|
Macro |
Description |
|
HOSTNAME |
Short, unique name of the host; maps to the host_name directive in the host object |
|
HOSTADDRESS |
The IP or hostname of the host; maps to the address directive in the host object |
|
HOSTDISPLAYNAME |
Description of the host; maps to the alias directive in the host object |
|
HOSTSTATE |
The current state of the host (one of UP, DOWN, UNREACHABLE) |
|
HOSTGROUPNAMES |
Short names of all host groups a host belongs, separated by a comma |
|
LASTHOSTCHECK |
The date and time of last check of the host, in Unix timestamp (number of seconds since 1970-01-01) |
|
LASTHOSTSTATE |
The last known state of the host (one of UP, DOWN, UNREACHABLE) |
|
SERVICEDESC |
Description of the service; maps to the description directive in the service object |
|
SERVICESTATE |
The current state of the service (one of OK, WARNING, UNKNOWN, CRITICAL) |
|
SERVICEGROUPNAMES |
Short names of all service groups a service belongs, separated by a comma |
|
CONTACTNAME |
Short, unique name of the contact; maps to the contact_name directive in the contact object |
|
CONTACTALIAS |
Description of the contact; maps to the alias directive in the contact object |
|
CONTACTEMAIL |
The e-mail address of the contact; maps to the email directive in the contact object |
|
CONTACTGROUPNAMES |
Short names of all contact groups a contact belongs, separated by a comma |
This table is not complete and only covers commonly used macro definitions. A complete list of available macros can be found in the Nagios documentation available at http://library.nagios.com/library/products/nagioscore/manuals/. Also, please remember that all macro definitions need to be prefixed and suffixed with a $ sign, for example, $HOSTADDRESS$ maps to the HOSTADDRESS macro definition.
An additional functionality is on-demand macro definitions. These are macros that are not defined, not exported as environment variables, but if found in a command definition, will be parsed and substituted accordingly. These macros accept one or more arguments inside the macro definition name, each passed after a colon. This is mainly used to read specific values, not related to the current object. In order to read the contact e-mail for the user jdoe, regardless of who the current contact person is, the macro would be as follows: $CONTACTEMAIL:jdoe$ which means getting a CONTACTEMAIL macro definition in the context of the jdoe contact.
Nagios also offers custom macro definitions. This works in a way that administrators can define additional attributes in each type of an object and that macro can then be used inside a command. This is used to store additional parameters related to an object; for example, you can store a MAC address in a host definition and use it in certain types of host checks.
It works in such a way that an object has a directive that starts with an underscore and is written in uppercase. It is referenced in one of the following ways, based on the object type it is defined in:
$_HOST<variable>$ – for directives defined within a host object
$_SERVICE<variable>$ – for directives defined within a service object
$_CONTACT<variable>$ – for directives defined within a contact object
A sample host definition that includes an additional directive with a MAC address would be as follows:
define host{
host_name somemachine
address 10.0.0.1
_MAC 12:12:12:12:12:12
check_command check-host-by-mac
}
A corresponding check command that uses this attribute inside a check is as follows:
define command{
command_name check-host-by-mac
command_line $USER1$/check_hostmac -H $HOSTADDRESS$ -m $_HOSTMAC$
}
A majority of standard macro definitions are exported to check commands as environment variables. The environment variable names are the same as macros, but are prefixed with NAGIOS_; for example, HOSTADDRESS is passed as the NAGIOS_HOSTADDRESS variable. Variables are not made available on demand. For security reasons, the $USERn$ variables are also not passed to commands as environment variables.
Configuring hosts
Hosts are objects that describe machines that should be monitored—either physical hardware or virtual machines. A host consists of a short name, descriptive name, and an IP address or host name. It also tells Nagios when and how the system should be monitored as well as who shall be contacted with regards to any problems related to this host. It also specifies how often the host should be checked, how retrying the checks should be handled, and how often should a notification about problems be sent out. A sample definition of a host is as follows:
define host{
host_name linuxbox01
hostgroups linuxservers
alias Linux Server 01
address 10.0.2.15
check_command check-host-alive
check_interval 5
retry_interval 1
max_check_attempts 5
check_period 24x7
contact_groups linux-admins
notification_interval 30
notification_period 24x7
notification_options d,u,r
}
It defines a Linux box that will use the check-host-alive command to make sure it is up and running. The test will be performed every 5 minutes, and after 5 failed tests, it will assume the host is down. If it is down, a notification will be sent out every 30 minutes. The following is a table of common directives that can be used to describe hosts. Items in bold are required when specifying a host.
|
Option |
Description |
|
host_name |
The Short, unique name of the host |
|
alias |
The descriptive name of the host |
|
address |
An IP address or fully qualified domain name of the host; It is recommended to use an IP address as all tests will fail if DNS servers are down |
|
parents |
The list of all parent hosts on which this host depends, separated by a comma; this is usually one or more switch and router to which this host is directly connected |
|
hostgroups |
The list of all hostgroups this host should be a member of; separated by a comma |
|
check_command |
The short name of the command that should be used to test if the host is alive; if a command returns an OK state, the host is assumed to be up. is assumed to be down otherwise |
|
check_interval |
Specifies how often a check should be performed; the value is in minutes |
|
retry_interval |
Specifies how many minutes to wait before retesting if the host is up |
|
max_check_attempts |
Specifies how many times a test needs to report that a host is down before it is assumed to be down by Nagios |
|
check_period |
Specifies the name of the time period that should be used to determine times during which tests if the host is up should be performed |
|
contacts |
The list of all contacts to which should receive notifications related to host state changes be sent; separated by a comma; at least one contact or contact group needs to be specified for each host |
|
contact_groups |
List of all contacts groups that should receive notifications related to host state changes be sent to; separated by a comma; at least one contact or contact group needs to be specified for each host |
|
first_notification_delay |
Specifies the number of minutes before the first notification related to a host being down is sent out |
|
notification_interval |
Specifies the number of minutes before each next notification related to a host being down is sent out |
|
notification_period |
Specifies time periods during which notifications related to host states should be sent out |
|
notification_options |
Specifies which notification types for host states should be sent, separated by a comma; should be one or more of the following: d: the host DOWN state u: the host UNREACHABLE state r: host recovery (UP state) f: the host starts and stops flapping s: notify when scheduled downtime starts or ends |
For a complete list of accepted parameters, please consult with the Nagios documentation. By default, Nagios assumes all host states to be up. If the check_command option is not specified for a host, then its state will always be set to up. When the command to perform host checks is specified, then regularly scheduled checks will take place, and the host state will be monitored using the value of check_interval as number of minutes between checks.
Nagios uses a soft and hard state logic to handle host states. Therefore, if a host state has changed from UP to DOWN since last hard state, then Nagios assumes that the host is soft DOWN state and performs retries of the test, waiting retry_interval minutes between each test. Once the result is the same after max_check_attempts number of times, Nagios assumes that the DOWN state is a hard state. The same mechanisms apply for DOWN to UP transitions. Notifications are also only sent if a host is in a hard state. This means that a temporary failure that only occurred for a single test will not cause a notification to be sent if max_check_attempts was set to a number higher than 1.
The host object parents directive is used to define the topology of the network. Usually, this directive points to a switch, router, or any other device that is responsible for forwarding network packets. The host is assumed to be unreachable if the parent host is currently in hard DOWN state. For example, if a router is down, then all machines accessed via it are considered unreachable and no tests will be performed on these hosts.
If your network consists of servers connected via switches and routers to a different network, then the parent for all servers in the local network as well as the router would be the switch. The parent of the router on the other side of the link would be the local router. The following diagram shows the actual network infrastructure and how Nagios hosts should be configured in terms of parents for each element of the network:
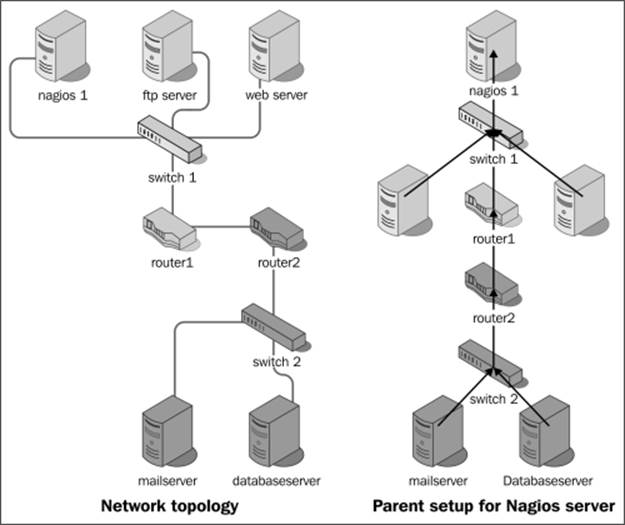
The actual network topology is shown on the left, and parent hosts setup for each of the machine are shown on the right. Each arrow represents mapping from a host to a parent host. There is no need to define a parent for hosts that are directly on the network with your Nagios server. So in this case, switch1 should not have a parent host set.
Even though some devices such as switches cannot be easily checked if they are down, it is still a good idea to describe them as part of your topology. In that case, you might use functionality, such as scheduled downtime, to keep track of when the device is going to be offline or mark it as down manually. This helps in determining other problems—Nagios will not scan any hosts that have the router somewhere along the path that is currently scheduled for downtime. This way you won't be flooded with notifications on actually unreachable hosts being down.
Check and notification periods specify the time periods during which checks for host state and notifications are to be performed. These can be specified so that different hosts can be monitored at different times.
It is also possible to set up where information that a host is down is kept, but nobody should be notified about it. This can be done by specifying notification_period that will tell Nagios when a notification should be sent out. No notifications will be sent out outside this time period.
A typical example is a server that is only required during business hours and has a daily maintenance window between 10PM and 4AM. You can set up Nagios so as to not monitor host availability outside of business hours, or you can make Nagios monitor it but without notifying that it is actually down. If monitoring is not done at all, then Nagios will perform fewer operations during this period. In second case, it is possible to gather statistics on how much of the maintenance window is used, which can be used if changes to the window need to be made.
Configuring host groups
Nagios allows grouping multiple hosts in order to manage them effectively. In order to do that, Nagios offers the hostgroup objects that are a group of one or more machines. A host might be a member of more than one host group. Usually, grouping is done by type of machines, location they are in, and the role of the machine. Each host group has a unique short name that it is identified, a descriptive name, and one or more hosts that are members of this group.
The following are the examples of host group definitions that define groups of hosts and a group that combines both groups:
define hostgroup{
hostgroup_name linux-servers
alias Linux servers
members linuxbox01,linuxbox02
}
define hostgroup{
hostgroup_name aix-servers
alias AIX servers
members aixbox1,aixbox2
}
define hostgroup{
hostgroup_name unix-servers
alias UNIX servers servers
hostgroup_members linux-servers,aix-servers
}
The following table is of directives that can be used to describe host groups. Items in bold are required when specifying a host group.
|
Option |
Description |
|
hostgroup_name |
The short, unique name of the host group |
|
alias |
The descriptive name of the host group |
|
members |
The list of all hosts that should be a member of this group; separated by a comma |
|
hostgroup_members |
The list of all other host groups whose all members should also be members of this group; separated by a comma |
Host groups can also be used when defining services or dependencies. For example, it is possible to tell Nagios that all Linux servers should have their SSH service monitored, and all AIX servers should have a telnet accepting connections.
It is also possible to define dependencies between hosts. They are, in a way, similar to the parent-host relationship, but dependencies offer more complex configuration options. Nagios will only issue host and service checks if all dependent hosts are currently up. More details on dependencies can be found in Chapter 5, Advanced Configuration.
For the purpose of this book, we will define at least one host in our Nagios configuration directory structure. To be able to monitor a local server that the Nagios installation is running, we will need to add its definition into the /etc/nagios/hosts/localhost.cfg file:
define host{
host_name localhost
alias Localhost
address 127.0.0.1
check_command check-host-alive
check_interval 5
retry_interval 1
max_check_attempts 5
check_period 24x7
contact_groups admins
notification_interval 60
notification_period 24x7
notification_options d,u,r
}
Although Nagios does not require a naming convention, it is a good practice to use the hostname as name of the file. To make sure Nagios monitoring works, it is also a good idea to set the address to a valid IP address of local machine, such as 127.0.0.1, as stated in the preceding code or the IP address in your network if it is static.
If you are planning on monitoring other servers as well, you will want to add them—the recommended approach is to define a single object definition in a single file.
Configuring services
Services are objects that describe a functionality that a particular host is offering. This can be virtually anything—network servers such as FTP, resources such as storage space, or CPU load.
A service is always tied to a host that it is running. It is also identified by its description, which needs to be unique within a particular host. A service also defines when and how Nagios should check if it is running properly and how to notify people responsible for this service. A short example of a web server that is defined on the localhost machine created earlier is as follows:
define service{
host_name localhost
service_description www
check_command check_http
check_interval 10
check_period 24x7
retry_interval 3
max_check_attempts 3
notification_interval 30
notification_period 24x7
notification_options w,c,u,r
contact_groups admins
}
This definition tells Nagios to monitor that the web server is working correctly every 10 minutes. The recommended file for this definition is /etc/nagios/services/localhost-www.cfg—with services, a good approach is to use <host>-<servicename> as the name of the file if a single host or host group is being set up for monitoring. The following table is about the common directives that can be used to describe service. Items in bold are required when specifying a service:
|
Option |
Description |
|
host_name |
The short name of the host on which the service is running; separated by a comma |
|
hostgroup_name |
The short name of the host groups that the service is running on; separated by a comma |
|
service_description |
The description of the service that is used to uniquely identify services running on a host |
|
servicegroups |
The list of all service groups of which this service should be a member; separated by a comma |
|
check_command |
The short name of the command that should be used to test if the service is running |
|
check_interval |
Specifies how often a check should be performed; the value is in minutes |
|
retry_interval |
Specifies how many minutes to wait before retesting whether the service is working |
|
max_check_attempts |
Specifies how many times a test needs to report that a service is down before it is assumed to be down by Nagios |
|
check_period |
Specifies the name of the time period that should be used to determine the time during which tests should be performed if the service is working |
|
contacts |
The list of all contacts that should receive notifications related to service state changes; separated by a comma; at least one contact or contact group needs to be specified for each service |
|
contact_groups |
The list of all contacts groups that should receive notifications related to service state changes, separated by a comma. At least one contact or contact group needs to be specified for each service |
|
first_notification_delay |
Specifies the number of minutes before the first notification related to a service state change is sent out |
|
notification_interval |
Specifies the number of minutes before each next notification related to a service not working correctly is sent out |
|
notification_period |
Specifies time periods during which notifications related to service states should be sent out |
|
notification_options |
Specifies which notification types for service states should be sent, separated by a comma; should be one or more of the following: w: the service WARNING state u: the service UNKNOWN state c: the service CRITICAL state r: the service recovery (back to OK) state f: the host starts and stops flapping s: notify when the scheduled downtime starts or ends |
For a complete list of accepted parameters, please consult with the Nagios documentation. Nagios requires that at least one service should be defined for every host, and requires that at least one service is defined for it to run. That is why we will now create a sample service in our configuration directory structure. For this purpose, we'll monitor the secure shell protocol.
In order to monitor whether SSH server is running on the Nagios installation, we will need to add its definition into the /etc/nagios/services/localhost-ssh.cfg file:
define service{
host_name localhost
service_description ssh
check_command check_ssh
check_interval 5
retry_interval 1
max_check_attempts 3
check_period 24x7
contact_groups admins
notification_interval 60
notification_period 24x7
notification_options w,c,u,r
}
If you are planning on monitoring other services as well, you will want to add a definition as well.
Very often, the same service is being offered by more than one host. In such cases, it is possible to specify a service that will be used by multiple machines or even specify host groups for which all hosts will be checked. It is also possible to specify hosts for which checks will not be performed; for example, if a service is present on all hosts in a group except for a specific box. To do that, exclamation needs to be added before a host name or host group name. To tell Nagios that SSH should be checked on all Linux servers except for linux01 and the aix01 machine, a service definition similar to the following has to be created:
define service{
hostgroup_name linux-servers
host_name !linuxbox01,aix01
service_description SSH
check_command check_ssh
check_interval 10
check_period 24x7
retry_interval 2
max_check_attempts 3
notification_interval 30
notification_period 24x7
notification_options w,c,r
contact_groups linux-admins
}
Services may be configured to be dependent on one another similar to hosts. In this case, Nagios will only perform checks on a service if all dependent services are working correctly. More details on dependencies can be found in Chapter 5, Advanced Configuration.
Configuring service groups
Services can be grouped similar to host objects. This can be used to manage services more conveniently. It also aids in viewing service reports on the Nagios web interface. Service groups are also used to configure dependencies in a more convenient way. The following table describes attributes that can be used to define a group. Items in bold are required when specifying a service group.
|
Option |
Description |
|
servicegroup_name |
The short, unique name of the service group |
|
alias |
The descriptive name of the service group |
|
members |
The list of all hosts and services that should be a member of this group; separated by a comma |
|
servicegroup_members |
The list of all other service groups whose all members should also be members of this group; separated by a comma |
The format of the members directive of service group object is one or more <host>,<service> pair.
An example of a service group is shown:
define servicegroup{
servicegroup_name databaseservices
alias All services related to databases
members linuxbox01,mysql,linuxbox01,pgsql,aix01,db2
}
This service group consists of the mysql and pgsql services on a linuxbox01 host and db2 on the aix01 machine. It is uniquely identified by its name databaseservices. It is also possible to specify groups that a service should be member of inside the service definition itself. To do this, add groups so that it will be a member of in servicegroups directive in the service definition. It is also possible to define an empty service group and have the service definitions specify to which groups they belong, for example:
define servicegroup{
servicegroup_name databaseservices
alias All services related to databases
}
define service{
host_name linuxbox01
service_description mysql
check_command check_ssh
servicegroups databaseservices
}
Configuring commands
Command definitions describe how host/service checks should be done. They can also define how notifications about problems or event handlers should work. Commands defined in Nagios tell how it can perform checks, such as what commands to run to check if a database is working properly; how to check if SSH, SMTP, or FTP server is properly working, or if DHCP server is assigning IP addresses correctly. Commands are also run to let users know of issues, or try to recover a problem automatically.
Nagios makes no distinction between commands provided by Nagios plugins project and custom commands, either created by a third party or written by you, and since its interface is very straight forward, it is very easy to create your own checks. Chapter 11,Programming Nagios, talks about writing custom commands to perform things such as monitoring custom protocols or communicating with installed applications.
Commands are defined in a manner similar to other objects in Nagios. A command definition has two parameters: name and command line. The first parameter is a name that is then used for defining checks and notifications. The second parameter is an actual command that will be run along with all parameters.
Commands are used by hosts and services. They define which system command to execute when making sure a host or service is working properly. A check command is identified by its unique name.
When used with other object definitions, it can also have additional arguments and uses exclamation mark as a delimiter. Commands with parameters have the following syntax: command_name[!arg1][!arg2][!arg3][...].
A command name is often the same as the plugin that it runs, but it can be different. The command line includes macro definitions (such as $HOSTADDRESS$). Check commands also use macros $ARG1$, $ARG2$ … $ARG32$ if a check command for a host or service passed additional arguments. The following is an example that defines a command to ping a host to make sure it is working properly. It does not use any arguments.
define command{
command_name check-host-alive
command_line $USER1$/check_ping -H $HOSTADDRESS$
-w 3000.0,80% -c 5000.0,100% -p 5
}
A very short host definition that would use this check command could be similar to the one shown here:
define host{
host_name somemachine
address 10.0.0.1
check_command check-host-alive
}
Such a check is usually done as part of the host checks. This allows Nagios to make sure that a machine is working properly if it responds to ICMP requests. Commands allow passing arguments as it offers a more flexible way of defining checks. So, a definition accepting parameters would be as follows:
define command{
command_name check-host-alive-limits
command_line $USER1$/check_ping -H $HOSTADDRESS$
-w $ARG1$ -c $ARG2$ -p 5
}
The corresponding host definition is as follows:
define host{
host_name othermachine
address 10.0.0.2
check_command check-host-alive-limits!3000.0,80%!5000.0,100%
}
The following is another example that sets up a check command for a previously-defined service:
define command{
command_name check_http
command_line $USER1$/check_http -H $HOSTADDRESS$
}
This check can be used when defining a service to be monitored by Nagios. Our Nagios configuration includes the default Nagios plugins definitions that we have previously copied as /etc/nagios/commands/default.cfg. Chapter 4, Using the Nagios Plugins, covers standard Nagios plugins along with sample command definitions.
Configuring time periods
Time periods are definitions of dates and times during which an action should be performed or specified people should be notified. They describe ranges of days and times and can be reused across various operations. A time period definition consists of a name that uniquely identifies it in Nagios. It also contains a description. It contains one or more days or dates, along with time spans as well.
A typical example of a time period would be working hours, which defines that a valid time to perform an action is from Monday to Friday during business hours. Another definition of a time period can be weekends which mean Saturday and Sunday, all day long. The following is a sample time period for working hours:
define timeperiod{
timeperiod_name workinghours
alias Working Hours, from Monday to Friday
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}
This particular example tells Nagios that a good time to perform something is from Monday to Friday between 9 AM and 5 PM. Each entry in a time period contains information on date or weekday. It also contains a range of hours. Nagios first checks if current date matches any of the dates specified. If it does, then it compares whether current time matches time ranges specified for particular date.
There are multiple ways a date can be specified. Depending on what type of date it is, one definition might take precedence over another. For example, a definition for December 24th is more important than a generic definition that every weekday an action should be performed between 9AM to 5PM.
Possible date types are mentioned here:
· Calendar date: For example, 2009-11-01 which means November 1st, year 2009; Nagios accepts dates in the YYYY-MM-DD format
· Date recurring every year: For example, July 4 which means 4th of July
· Specific day within a month: For example, day 14 which means 14th of every month
· Specific weekday along with offset in a month: For example, Monday 1 September which means the first Monday in September; Monday -1 would mean last Monday in May
· Specific weekday in all months: For example, Monday 1, which means every 1st Monday in a month
· Weekday: For example, Monday which means all Mondays
It lists all types by order in which Nagios uses different date types. This means that a date recurring every year will always be used prior to an entry describing what should be done every Monday.
In order to be able to correctly configure all objects, we will now create some standard time periods that will be used in the configuration. The following example periods will be used by the remaining sections of this chapter, and it is recommended to put them in the/etc/nagios/timeperiods/default.cfg file:
define timeperiod{
timeperiod_name workinghours
alias Working Hours, from Monday to Friday
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}
define timeperiod{
timeperiod_name weekends
alias Weekends all day long
saturday 00:00-24:00
sunday 00:00-24:00
}
define timeperiod{
timeperiod_name 24x7
alias 24 hours a day 7 days a week
monday 00:00-24:00
tuesday 00:00-24:00
wednesday 00:00-24:00
thursday 00:00-24:00
friday 00:00-24:00
saturday 00:00-24:00
sunday 00:00-24:00
}
The last time period is also used by the SSH service defined earlier. This way, monitoring the SSH server will be done all the time.
Configuring contacts
Contacts define people who can be either owners of specific machines, or people who should be contacted in case of problems. Depending on how your organization might contact people in case of problems, a definition of a contact may vary a lot. A contact consists of a unique name, a descriptive name, one or more e-mail addresses, and pager numbers. Contact definitions can also contain additional data specific to how a person can be contacted.
A basic contact definition is shown here, and specifies the unique contact name, an alias, and the contact information. It also specifies event types that the person should receive and time periods during which notifications should be sent.
define contact{
contact_name jdoe
alias John Doe
email john.doe@yourcompany.com
contactgroups admins,nagiosadmin
host_notification_period workinghours
service_notification_period workinghours
host_notification_options d,u,r
service_notification_options w,u,c,r
host_notification_commands notify-host-by-email
service_notification_commands notify-service-by-email
}
The contactgroups line defines that this user is a member of groups admins, which is defined later in this chapter. We will now create a similar file in /etc/nagios/contacts, setting values for contact_name, alias, and email based on your username, full name, and e-mail address. The recommended name for the file is based on contact_name.
The following table describes all available directives when defining a contact. Items in bold are required when specifying a contact.
|
Option |
Description |
|
contact_name |
The short, unique name of the contact |
|
alias |
The descriptive name of the contact; usually this is the full name of the person |
|
contactgroups |
The list of all contact groups of which this user should be a member; separated by a comma |
|
host_notifications_enabled |
This specifies whether this person should receive notifications regarding host state |
|
host_notification_period |
This specifies the name of the time period that should be used to determine time during which a person should receive notifications regarding the host state |
|
host_notification_commands |
Specifies one or more commands that should be used to notify the person of a host state; separated by a comma |
|
host_notification_options |
Specifies host states about which the user should be notified, separated by a comma; should be one or more of the following: d: the host DOWN state u: the host UNREACHABLE state r: the host recovery (UP state) f: the host starts and stops flapping s: notify when scheduled downtime starts or ends n: the person will not receive any service notifications |
|
service_notifications_enabled |
Specifies whether this person should receive notifications regarding the service state |
|
service_notification_period |
Specifies name of the time period that should be used to determine time during which a person should receive notifications regarding the service state |
|
service_notification_commands |
Specifies one or more commands that should be used to notify the person of a service state; separated by a comma |
|
service_notification_options |
Specifies service states about which that the user should be notified, separated by a comma; should be one or more of the following: w: the service WARNING state u: the service UNKNOWN state c: the service CRITICAL state r: the service recovery (OK state) f: the service starts and stops flapping n: the person will not receive any service notifications |
|
|
Specifies the e-mail address of the contact |
|
pager |
Specifies the pager number for the contact. It can also be an e-mail to the pager gateway |
|
address1 … address6 |
Additional six addresses that can be specified for the contact; these can be anything, based on how the notification commands will use these fields |
|
can_submit_commands |
Specifies whether the user is allowed to execute commands from Nagios web interface |
|
retain_status_information |
Specifies whether the status-related information about this person is retained across restarts |
|
retain_nonstatus_information |
Specifies whether the non-status information about this person should be retained across restarts |
Contacts are also mapped to users that log into the Nagios web interface. This means that all operations done via the interface will be logged as that particular user and that the web interface will use the access granted to particular contact objects when evaluating if an operation should be allowed. The contact_name field from a contact object maps to user names in the Nagios web interface.
Configuring contact groups
Contacts can be grouped. Usually, grouping is used to keep a list of which users are responsible for which tasks, and maps to job responsibilities for particular people. It also makes it possible to define people that should be responsible for handling problems at specific time periods, and Nagios will automatically contact the right people for a particular time a problem has occurred. A sample definition of a contact group is as follows:
define contactgroup{
contactgroup_name linux-admins
alias Linux Administrators
members jdoe,asmith
}
This group is also used when defining the linuxbox01 and WWW service contacts. This means that both the jdoe and asmith contacts will receive information on status of this host and service.
The following table is a complete list of directives that can be used to describe contact groups. Items in bold are required when specifying a contact group.
|
Option |
Description |
|
contactgroup_name |
The short, unique name of the contact group |
|
alias |
The descriptive name of the contact group |
|
members |
The list of all contacts that should be a member of this group; separated by a comma |
|
contactgroup_members |
The list of all other contact groups whose all members should also be members of this group; separated by a comma |
Members of a contact group can either be specified in the contact group definition or using the contactgroups directive in a contact definition. It is also possible to combine both methods—some of the members can be specified in the contact group definition and others can be specified in their contact object definition.
Contacts are used to specify who shall be contacted if a status changes for one or more hosts or services. Nagios accepts both contacts and contact groups in their object definitions. This allows making either specific people or entire groups responsible for particular machines or services.
It is also possible to specify different people or groups for handling host-related problems and service related problems—for example, hardware administrators for handling host problems and system administrators for handling service issues.
In order for our previously created user jdoe to work properly, we need to define the admins and nagiosadmin groups in the /etc/nagios/contactgroups/admins.cfg file:
define contactgroup{
contactgroup_name admins
alias System administrators
}
define contactgroup{
contactgroup_name nagiosadmin
alias Nagios administrators
}
Verifying the configuration
At this point, our configuration file should be ready for use. We can now verify that all of the configuration statements are correct and that Nagios would start correctly with our configuration. We can do this by running the nagios command with the -v option. For example:
root@ubuntu:~# /opt/nagios/bin/nagios -v /etc/nagios/nagios.cfg
Nagios Core 4.0.0
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 05-24-2013
License: GPL
Website: http://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking services...
Checked 1 services.
Checking hosts...
Checked 1 hosts.
Checking host groups...
Checked 1 host groups.
Checking service groups...
Checked 1 service groups.
Checking contacts...
Checked 1 contacts.
Checking contact groups...
Checked 1 contact groups.
Checking commands...
Checked 24 commands.
Checking time periods...
Checked 3 time periods.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 3 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
The preceding command indicates a correct configuration file. If there are errors, the message will indicate the problem, as shown in the following command:
root@ubuntu:~# /opt/nagios/bin/nagios -v /etc/nagios/nagios.cfg
Nagios Core 4.0.0
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 05-24-2013
License: GPL
Website: http://www.nagios.org
Reading configuration data...
Read main config file okay...
Error: Contactgroup 'admin' is not defined anywhere
Error: Could not add contactgroup 'admin' to service (config file '/etc/nagios/services/localhost-www.cfg', starting on line 1)
Error processing object config files!
***> One or more problems was encountered while processing the config files...
Check your configuration file(s) to ensure that they contain valid
directives and data defintions. If you are upgrading from a previous
version of Nagios, you should be aware that some variables/definitions
may have been removed or modified in this version. Make sure to read
the HTML documentation regarding the config files, as well as the
'Whats New' section to find out what has changed.
The preceding example indicates the contactgroup value admin is not valid for a service defined in /etc/nagios/services/localhost-www.cfg file.
Note
It is always recommended to verify the Nagios configuration file after making changes to ensure it does not prevent Nagios from functioning properly.
Even if the /etc/init.d/nagios script prevents restarting when the configuration is incorrect, this would cause Nagios not to start after a system restart.
Understanding notifications
Notifications is Nagios' way of letting people know that something is either wrong or has returned to the normal way of functioning. This is a very important functionality in Nagios, and configuring notifications correctly might seem a bit tricky in the beginning.
When and how notifications are sent out is configured as part of the contact configuration. Each contact has configuration directives for when notifications can be sent out and how he/she wants to be contacted. Contacts also contain information about contact details, such as telephone number, e-mail address, and Jabber/MSN address. Each host and service is configured with when information about it should be sent, and who should be contacted. Nagios then combines all this information in order to notify people of changes in the status.
Notifications may be sent out in one of the following situations:
· The host has changed its state to the DOWN or UNREACHABLE state; a notification is sent out after first_notification_delay number of minutes specified in the corresponding host object
· The host remains in the DOWN or UNREACHABLE state; a notification is sent out every notification_interval number of minutes specified in the corresponding host object
· The host recovers to an UP state; a notification is sent out immediately and only once
· The host starts or stops flapping; a notification is sent out immediately
· The host remains flapping; a notification is sent out every notification_interval number of minutes specified in the corresponding host object
· The service has changed its state to the WARNING, CRITICAL or UNKNOWN state; a notification is sent out after first_notification_delay number of minutes specified in the corresponding service object
· The service remains in the WARNING, CRITICAL or UNKNOWN state; a notification is sent out every notification_interval number of minutes specified in the corresponding service object
· The service recovers to an OK state; a notification is sent out immediately and only once
· The service starts or stops flapping; a notification is sent out immediately
· The service remains flapping; a notification is sent out every notification_interval number of minutes specified in the corresponding service object
If one of these conditions occurs, Nagios starts evaluating whether information about it should be sent out and to whom.
First of all, the current date and time is checked against the notification time period. The time period is taken from the notification_timeperiod field from the current host or the service definition. Only if the time period includes the current time will a notification be sent out.
Next, a list of users based on the contacts and contact_groups fields is created. Based on all members of all groups and included groups, as well as all contacts directly bound with the current host or service, a complete list of users is made.
Each of matched users is checked whether they should be notified about the current event. In this case, each user's time period is also checked whether it includes the current date and time. The host_notification_period or service_notification_period directive is used, depending on whether the notification is for the host or the service.
For host notifications, the host_notification_options directive for each contact is also used to determine whether that particular person should be contacted; for example, different users might be contacted about an unreachable host if the host is actually down. For service notifications, the service_notification_options parameter is used to check every user if they should be notified about this issue. The section on hosts and services configuration described what values these directives take.
If all of these criteria have been met, then Nagios will send a notification to this user. It will now use commands specified in the host_notification_commands and service_notification_commands directives.
It is possible to specify multiple commands that will be used for notifications, so it is possible to set up Nagios so that it sends both e-mail as well as a message on an instant messaging system.
Nagios also offers escalations which allow sending e-mails to other people when a problem has not been resolved for too long. This can be used to propagate problems to the higher management or teams that might be affected by unresolved problems. It is a very powerful mechanism and is split between the host and service-based escalations. This functionality is described in more detail in Chapter 6, Notifications and Events.
Templates and object inheritance
In order to allow flexible configuration of machines, Nagios offers a powerful inheritance engine. The main concept is that administrators can set up templates that define common parameters and re-use them in actual host or service definitions. The mechanism even offers the possibility to create templates that inherit parameters from other templates.
This mechanisms works in a way that templates are plain Nagios objects that specify the register directive and set it to 0. This means that they will not be registered as an actual host or service that need to be monitored. Objects that inherit parameters from a template or another host should have a use directive pointing to the short name of the template object they are using.
When defining a template, its name is always specified using the name directive. This is slightly different from how typical hosts and services are registered, as they require the host_name and/or service_description parameters.
Inheritance can be used to define a template for basic host checks with only basic parameters such as IP address being defined for each particular host, and the following code is an example of this:
define host{
name generic-server
check_command check-host-alive
check_interval 5
retry_interval 1
max_check_attempts 5
check_period 24x7
notification_interval 30
notification_period 24x7
notification_options d,u,r
register 0
}
define host{
use generic-server
name linuxbox01
alias Linux Server 01
address 10.0.2.1
contact_groups linux-admins
}
It is possible to inherit from multiple templates. To do this, simply put multiple names in the use directive, separated by a comma. This allows an object to use several templates which define a part or all directives that it will use. If multiple templates specify the same parameters, the value from the first template specifying it will be used. The following is an example code:
define service{
name generic-service
check_interval 10
retry_interval 2
max_check_attempts 3
check_period 24x7
register 0
}
define service{
host_name workinghours-service
check_period workinghours
notification_interval 30
notification_period workinghours
notification_options w,c,u,r
register 0
}
define service{
use workinghours-service,generic-service
contact_groups linux-admins
host_name linuxbox01
service_description SSH
check_command check_ssh
}
In this case, values from both templates will be used. The value of workinghours will be used for the check_period directive as it was first specified in the workinghours-service template. Changing the order in use directive to generic-service,workinghours-service would cause value of the check_period parameter to be 24x7.
Nagios also accepts creating multiple levels of templates. For example, you can set up a generic service template, and inherit it to create templates for various types of checks, such as local services, resource sensitive checks, and template for passive-only checks. Let's consider the following object and template structure:
define host{
host_name linuxserver1
use generic-linux,template-chicago
.....
}
define host{
register 0
name generic-linux
use generic-server
.....
}
define host{
register 0
name generic-server
use generic-host
.....
}
define host{
register 0
name template-chicago
use contacts-chicago,misc-chicago
.....
}
The following diagram shows how Nagios will look for values for all directives:
When looking for parameters, Nagios will first look for the value in the linuxserver1 object definition. Next, it will use the following templates, in this order: generic-linux, generic-server, generic-host, template-chicago, contacts-chicago, and misc-chicago in the end.
It is also possible to set up host or service dependencies that will be inherited from a template. In that case, the dependent hosts or services can't be templates themselves, and need to be registered as an object that will be monitored by the Nagios daemon.
Summary
Our Nagios setup is now complete and ready to be started! We took the road from source code into a working application. We have also configured it so that it monitors the machine it is running on from scratch, and it took very little time and effort to do this.
Our Nagios installation now uses three directories:/opt/nagios for binaries, /etc/nagios for the configuration, and /var/nagios for storing the data. All object definitions are stored in a categorized way as subdirectories /etc/nagios. This allows a much easier management of Nagios objects.
We have configured the server on which Nagios is running to be monitored. You might want to add more servers just to see how it all works. We told Nagios to monitor the SSH server, but most probably you'll also want to monitor other things such as a web server or an e-mail.
Chapter 4, Using the Nagios Plugins will help when it comes to setting up various types of checks. Make sure to also read the /etc/nagios/commands/default.cfg file to see with which commands Nagios was already configured. Sometimes, it will also be needed to set up your own check commands—either custom scripts or using Nagios plugins in a different way than the default command set.
You'll also want to set up other users if you are working as part of a larger team. It'll definitely help everyone in your team if you tell Nagios who is taking care of which parts of the infrastructure!
All that should be a good start for making sure everything works fine in your company. Of course, configuring Nagios for your needs might take a lot of time, but starting with monitoring just the essentials is a good thing. You'll learn how it works and increase the number of objects that are monitored over time.
The next step is to set up the web interface so that you'll be able to see things from your favorite browser or even put them on your desktop. The next chapter provides essential information on how to install, configure, and use the web interface.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.