Learning Nagios 4 (2014)
Chapter 5. Advanced Configuration
In the previous chapter, we walked through the standard Nagios plugins, which can be used to monitor a large variety of hosts and services. We learned how the plugins can be used to perform specific and generic checking of the IT resources. This chapter describes some guidelines that will help you migrate from small (and increasing) Nagios setups to a flexible model by using templates and grouping effectively. Any experienced administrator knows that there is a huge difference between a working system and a properly configured system. Using this advice will help you and your team survive the switch from monitoring only critical services to checking the health of the majority of your IT infrastructure.
This chapter focuses on how to set up templates, groupings, and the naming structure. However, creating a robust monitoring system involves much more—be sure to read the following chapters that talk about monitoring other servers, setting up multiple hosts that use Nagios to monitor your network and report to a single central machine, as well as how to monitor hosts running the Microsoft Windows operating system.
In this chapter, we will learn the following:
· Setting up and maintaining the configuration files that can grow along with your IT monitoring system
· Configuring the dependencies for easier root cause analysis of IT problems
· Creating the templates for easier management of similar hosts and services
· Using the custom variables for easier customization of objects
· What flapping is and how it works
Creating maintainable configurations
Enormous effort is required to deploy, configure, and maintain a system that monitors your company's IT infrastructure. The configuration for several hundred machines can take months. The effort required will also depend upon the scope of hosts and services that should be tracked—the more precise the checks need to be, the more the time needed to set these up.
If your company plans to monitor a wide range of hosts and services, you should consider setting up a machine dedicated to Nagios that will only take care of this single job. Even though a small Nagios installation consumes little resources, as it grows, Nagios will start using more resources. If you set it to run on the same machine as business-critical applications, it can lead to problems. Therefore, it is always best to set up a dedicated Nagios box, even if this is on a slower machine, right from the beginning.
Very often, a good approach is to start with monitoring only critical parts of your network, such as routers and main servers. You can also start off with only making sure that essential services are working—DHCP, DNS, file sharing, and databases are good examples of what is critical. Of course, if your company does not use file servers or if databases are not critical to the production environment, you can skip these. The next step would be to set up parenting and start adopting more hosts. At some point, you will also need to start planning how to group hosts and services. In the beginning, the configuration might simply be definitions of people, hosts, and services. After several iterations of setting up more hosts and services to be monitored, you should get to a point where all of the things that are critical to the company's business are monitored. This should be an indication that the setting up of the Nagios configuration is complete.
As the number of objects grows, you will need to group them. Contacts need to be defined as groups, because if your team consists of more than one to two people, they will likely rotate over time. So, it's better to maintain a group than change the people responsible for each host individually. Hosts and services should be grouped for many reasons. It makes viewing the status and infrastructure topology on the web interface much easier. Also, after you start defining escalations for your objects, it is much easier to manage these using groups.
You should take some time to plan how group hosts and services should be set up. How will you use the groupings? For escalations? For viewing single host groups via the web interface? Learn how you can take advantage of this functionality, and then plan how you will approach the setup of your groups.
If your network has common services, it is better to define them for particular groups and only once—such as the SSH server for all Linux servers and Telnet for all AIX (Advanced Interactive eXecutive) machines, which is an IBM operating system that is mainly used by IBM enterprise-level servers. It is possible to define a service only once, and tell Nagios to which hosts or host groups the service should be bound. By specifying that all Linux servers offer SSH, and all AIX servers offer telnet, it will automatically add such services to all of the machines in these groups. This is often more convenient than specifying services for each of the hosts separately.
In such cases, you should either set up a new host group or use an existing one to keep track of the hosts that offer a particular service. Combined with keeping a list of host groups inside each host definition, this makes things much easier to manage—disabling a particular host also takes care of the corresponding service definitions.
It is also worth mentioning that Nagios performs and schedules service checks in a much better way than it does host checks—the service checks are scheduled in a much better way. That is why it is recommended that you do not schedule host checks at all. You can set up a separate service for your hosts that will send a ping to them and report how many packets have returned and the approximate time taken for them to return.
Nagios can be set up to schedule host checks only if one of the hosts is failing (that is, it is not responding to the pings). A host will be periodically checked until it recovers. In this way, problems with hosts will still be detected, but host checks will only be scheduled on demand. This will cause Nagios to perform much better than it would if regular checks of all hosts on your network are made. To disable regular host checks, simply don't specify the check interval for the hosts that you want checked only on demand.
Configuring the file structure
A very important issue is how to store all our configuration files. We can put every object definition in a single file, but this will not make it easy to manage. As mentioned in Chapter 2, Installing Nagios 4, it is recommended to store different types of objects in separate folders.
Assuming your Nagios configuration is in /etc/nagios, it is recommended that you create folders for all types of objects in the following manner:
/etc/nagios/commands
/etc/nagios/timeperiods
/etc/nagios/contacts
/etc/nagios/hosts
/etc/nagios/services
Of course, these files will need to be added to the nagios.cfg file. After having followed the instructions in Chapter 2, Installing Nagios 4, these directories should already be added to our main Nagios configuration file.
It would also be worthwhile to use a version control mechanism such as Git (visit http://www.git-scm.com/), Hg (Mercurial, visit http://mercurial.selenic.com/) or SVN (Subversion, visit http://subversion.tigris.org/) to store your Nagios configuration. While this will add overhead to the process of applying configuration changes, it will also prevent someone from overwriting a file accidentally. It will also keep track of who changed which parts of the configuration, so you will always know whom to blame if things break down.
You might consider writing a simple script that will perform an export from the source code repository into a temporary directory, verify that Nagios works fine by using the nagios -v command. Only if that did not fail, we will copy the new configuration in place of the older one and restart Nagios. This will make deployment of configuration changes much easier, especially in cases where multiple people are managing it.
As for naming the files themselves—for time periods, contacts, and commands, it is recommended that you keep single definitions per file, as in contacts/nagiosadmin.cfg. This greatly reduces naming collisions and also makes it much easier to find particular object definitions.
Storing hosts and services might be done in a slightly different way—host definitions should go to the hosts subdirectory, and the file should be named the same as the hostname, for example, hosts/localhost.cfg. Services can be split into two different types and stored, depending on how they are defined and used.
Services that are associated with more than one host should be stored in the services subdirectory. A good example is the SSH service, which is present on the majority of systems. In this case, it should go to services/ssh.cfg, and use host groups to associate it with the hosts that actually offer connection over this protocol.
Services that are specific to a host should be handled differently. It's best to store them in the same file as the host definition. A good example might be checking the disk space on partitions that might be specific to a particular machine, such as checking the /oraclepartition on a host that's dedicated to Oracle databases.
For handling groups, it is recommended to create files called groups.cfg, and define all groups in it, without any members. Then, while defining a contact, host, or group, you can define to which groups it belongs by using the contactgroups, hostgroups, or servicegroupsdirectives accordingly. This way, if you disable a particular object by deleting or commenting out its definition, the definition of the group itself will still work.
If you plan on having a large number of both check command and notify command definitions, you may want to split this into two separate directories—checkcommands and notifycommands. You can also use a single commands subdirectory, prefix the file names, and store the files in a single directory, for example, commands/check_ssh.cfg and commands/notify_jabber.cfg.
Defining the dependencies
It is a very common scenario that computers, or the applications they offer, depend on other objects to function properly. A typical example is a database on which an e-mail or web server will depend. Another one is a host behind a private network that depends on an OpenVPN service to work. As a system administrator, your job is to know these relations—if you plan to reinstall a database cluster, you need to let people know there will be downtime for almost all applications. Nagios should also be aware of such relations.
In such cases, it is very useful for system monitoring software to consider these dependencies. When analyzing which hosts and services are not working properly, it is good to analyze such dependencies and discard things that are not working because of other failures. This way, it will be easier for you to focus on the real problems. Therefore, it allows you to get to the root cause of any malfunction much faster.
Nagios allows you to define how hosts and services depend on each other. This allows very flexible configurations and checks, and distinguishes it from many other less advanced system monitoring applications. Nagios provides very flexible mechanisms for checking hosts and services—it will take all dependencies into account. This means that if a service relies on another one to function properly, Nagios will perform checks to make sure that all dependent services are working properly. In case a dependent service is not working properly, Nagios may or may not perform checks and may or may not send out any notifications, depending on how the dependency is defined. This is logical, because the service will most probably not work properly if a dependent object is not working.
Nagios also offers the ability to specify parents for hosts. This is, in a way, similar to dependencies, as both specify that one object depends on another object. The main difference is that parents are used to define the infrastructure hierarchy. Parent definitions are also used by Nagios to skip checks for hosts that will obviously be down. Dependencies, on the other hand, can be used to suppress notifications about the problems that are occurring due to dependent services being down, but they do not necessarily cause Nagios to skip checking a particular host or service. Another difference is that parents can only be specified for hosts, whereas dependencies can be set up between hosts and services.
Dependencies also offer more flexibility in terms of how they are configured. It is possible to specify which states of the dependent host or service will cause Nagios to stop sending out notifications. You can also tell Nagios when it should skip performing checks, based on the status of the dependent object.
Dependencies might also be valid only at certain times, for example, a back-up service that needs to monitor your system all of the time, but that needs to have access to networked storage only between 11 PM and 4 AM.
To aid in describing how objects depend on each other, Nagios documentation uses two terms—master and dependent objects. When defining dependency, a master object is the object that needs to be working correctly in order for the other object to function. Similarly, the dependent object is the one that needs another object in order to work. This terminology will be used throughout this section, to avoid confusion.
Creating the host dependencies
Let's start with host dependency definitions. These are objects that have several attributes, and each dependency can actually describe one or more dependencies, for example, it is possible to tell Nagios that 20 machines rely on a particular host in a single dependency definition.
Here is an example of a dependency specifying that during maintenance, a Windows backup storage server in another branch depends upon a VPN server.
define hostdependency
{
dependent_host_name backupstorage-branch2
host_name vpnserver-branch1
dependency_period maintenancewindows
}
The following table describes all of the available directives for defining a host dependency. Items in bold are required when specifying a dependency:
|
Option |
Description |
|
dependent_host_name |
Defines hostnames that are dependent on the master hosts, separated by commas |
|
dependent_hostgroup_name |
Defines the host group names whose members are dependent on the master hosts, separated by commas |
|
host_name |
Defines the master hosts, separated by commas |
|
hostgroup_name |
Defines the host groups whose members are to be the master hosts, separated by commas |
|
inherits_parent |
Defines whether a dependency should inherit dependencies of the master hosts |
|
execution_failure_criteria |
Specifies which master host states should prevent Nagios from checking the dependent hosts, separated by commas; it can be one or more of the following: n: none, checks should always be executed p: pending state (no check has yet been done) o: host UP state d: host DOWN state u: host UNREACHABLE state |
|
notification_failure_criteria |
Specifies which master host states should be prevented from generating notifications about the dependent host's status changes, separated by commas; it can be one or more of the following: n: none, notification should always take place p: pending state (no check has yet been done) o: host UP state d: host DOWN state u: host UNREACHABLE state |
|
dependency_period |
Specifies the time periods during which the dependency will be valid; if not specified, the dependency is always valid |
The question is where to store such dependency files. As for service definitions, it is recommended that you store dependencies specific to a particular host in the file containing the definition of the dependent host. For the previous example, we would put it in thehosts/backupstorage-branch2.cfg file.
When defining a dependency that will describe a relationship between more than one master or dependent host, it's best to put these into a generic file for dependencies—for example, we can put it in hosts/dependencies.cfg. Another good option is to put the dependency definitions that only affect a single master host in the master host's definition.
If you are defining a dependency that covers more than one master or dependent host, it is best to use host groups to manage the list of hosts that should be included in the dependency's definition. This can be one or more host group names, and very often, these groups will also be the same as for the service definitions.
Creating the service dependencies
Service dependencies work in a similar way as host dependencies. For hosts, you need to specify one or more master hosts and one or more dependent hosts; for services, you need to define a master service and a dependent service.
Service dependencies can be defined only for a single service, but on multiple hosts. For example, you can tell Nagios that POP3 services on the emailservers host group depend on the LDAP service on the ldapserver host.
Here is an example of how to define such a service dependency:
define servicedependency
{
host_name ldapserver
service_description LDAP
dependent_hostgroup_name emailservers
dependent_service_description POP3
execution_failure_criteria c,u
notification_failure_criteria c,u,w
}
The following table describes all available directives for defining a service dependency. Items in bold are required when specifying a dependency:
|
Option |
Description |
|
dependent_host_name |
Defines the hostnames whose services should be taken into account for this dependency, separated by commas |
|
dependent_hostgroup_name |
Defines the host group names whose members' services should be taken into account for this dependency, separated by commas |
|
dependent_service_description |
Defines the service that should be the dependent service for all the specified dependent hosts |
|
host_name |
Defines the master hosts whose services should be taken into account by this dependency, separated by commas |
|
hostgroup_name |
Defines the master host groups whose members' services should be taken into account by this dependency, separated by commas |
|
service_description |
Defines the service that should be the master service for all the provided master hosts |
|
inherits_parent |
Specifies whether this dependency should inherit the dependencies of the master hosts |
|
execution_failure_criteria |
Specifies which master service states should prevent Nagios from checking the dependent services, separated by commas; it can be one or more of the following: n: none, checks should always be executed p: pending state (no check has yet been done) o: service OK state w: service WARNING state c: service CRITICAL state u: service UNKNOWN state |
|
notification_failure_criteria |
Specifies which master service states should be prevented from generating notifications for the dependent service status changes, separated by commas; it can be one or more of the following: n: none, checks should always be executed p: pending state (no check has yet been done) o: service OK state w: service WARNING state c: service CRITICAL state u: service UNKNOWN state |
|
dependency_period |
Specifies the time periods during which the dependency will be valid; if not specified, the dependency is always valid |
As in the case of host dependencies, there is a question of where to store the service dependency definitions. A good answer to this is that store dependencies in the same files where the dependent service definitions are kept. If you are following the previous suggestions regarding how to keep services in the file structure, then for a service bound to a single host, both service and the related dependencies should be kept in the same file as the host definition itself. If a service is used by more than one host, it is kept in a separate file. In this case, dependencies related to that service should also be kept in the same file as the service.
Using the templates
The templates in Nagios allow you to create a set of parameters that can then be used in the definitions of multiple hosts, services, and contacts. The main purpose of the templates is to keep parameters that are generic to all objects, or a group of objects, in one place. This way, you can avoid putting the same directives in hundreds of objects, and your configuration is more maintainable.
Note
Nagios allows an object to inherit from single or multiple templates. The templates can also inherit from other templates. This allows the creation of very simple templates, where objects inherit from a single template as well as complex templating system, where actual objects (such as services or hosts) inherit from multiple templates. It is recommended to start with a simple template. Multiple templates are more useful when monitoring larger number of hosts and services across multiple sites.
It is also good to start using templates for hosts and services, and decide how they should be used. Sometimes, it is better to have one template, inherit another, and create a hierarchical structure. In many cases, it is more reasonable to create hosts so that they use multiple templates. This functionality allows the inheritance of some options from one template and some parameters from another template. The following is an illustration of how the templates can be structured using both techniques:
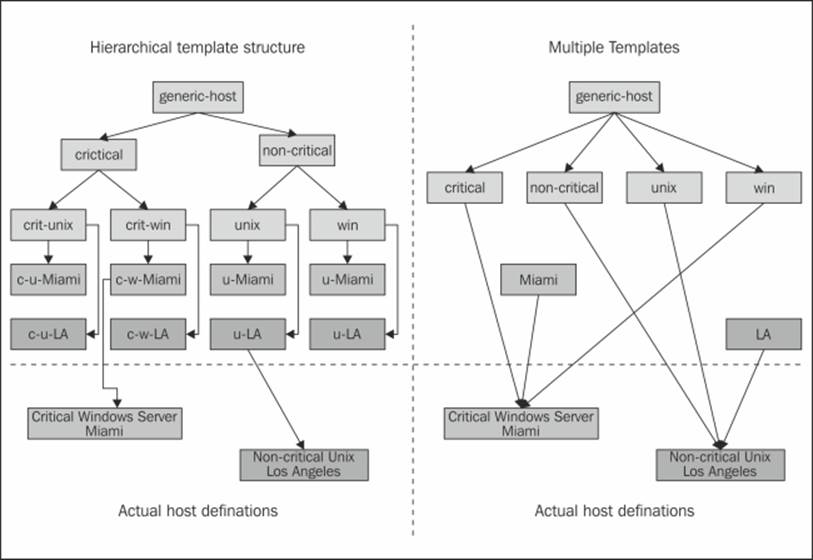
This example illustrates how the templates can be structured using both hierarchy and multiple templates inheritance. The preceding diagram shows how to use templates for host definitions. Similar rules apply for services as well, but the inheritance structure might be quite different.
In both of the methods shown in the preceding diagram, there is a distinction between critical and non-critical servers. Hosts are also split into ones that are Unix-based and ones that are Windows-based. There is also a distinction between the two branches that are configured—Miami and LA (Los Angeles). Furthermore, there is also a generic-host template that is used by every other template.
Usually, such distinctions make sense, because Windows and Unix boxes might be checked differently. Based on the operating system and the location of the machine, different people should be assigned as contacts in case of problems. There may also be different time periods during which these hosts should be checked.
The example on the left shows the inheritance of one type of parameter at a time. First, a distinction is made between critical and non-critical machines. Usually, both types have different values for the notification and check intervals, as well as the number of checks to perform before generating a notification for a problem. The next step is to differentiate between Windows- and Unix- based servers—this might involve the check command to verify that a server is up. The last step is to define templates for each system in both of the branches (Miami and LA). The actual host definition inherits from one template in the final set of templates.
The example on the right uses a slightly different approach. It first defines different templates for Unix and Windows systems. Next, a pair of templates for critical and noncritical machines is also defined. Finally, a set of templates defines the branches Miami and LA. The actual host definition inherits templates for the operating system, for the level of criticality and for the branch to which it belongs. It inherits parameters partially from each of the templates.
In both cases, attributes that are passed at different levels are the same, even though the approach is different. Usually, the templates that define the operating system also define how a host check should be done. They might also indicate the time period over which a host should be checked.
Templates for critical and noncritical machines usually specify how notifications should be carried out. If a host is crucial to infrastructure, its owners should be notified in a more aggressive way. Similarly, machines that are not affecting business directly do not need that much attention.
Templates for locations usually define the owners of the machines. The locations are not always branches, as in this example; they can be branches, floors, or even network connection types. Locations can also point machines to their parent hosts—usually computers located in the same place that are connected to the same router.
Creating the templates
Defining the templates in Nagios is very similar to defining actual objects. You simply define the template as the required object type. The only difference is that you need to specify the register directive and specify a value of 0 for it. This will tell Nagios that it should not treat this as an actual object, but as a template. You will also need to use the name directive for defining template names. You do not need to specify other directives for naming objects, such as host_name, contact_name, or service_description.
When defining an object, simply include the use directive and specify all of the templates to be used as its value. If you want to inherit from multiple templates, separate all of them by commas.
The following is an example of defining a template for a Linux server and then using this in an actual host definition:
define host {
register 0
name generic-servers
check_period 24x7
retry_interval 1
check_interval 15
max_retry_attempts 5
notification_period 24x7
notification_interval 60
notification_options d,r
}
define host
{
register 0
use generic-servers
name linux-servers
check_command check-host-alive
contact_groups linux-admins
}
define host
{
use linux-servers
host_name ubuntu1
address 192.168.2.1
}
As mentioned earlier, templates use name for defining the template, and the actual host uses the host_name directive.
Inheriting from multiple templates
Nagios allows us to inherit from multiple templates and the templates using other (nested) templates. It's good to know how Nagios determines the order in which every directive is looked for in each of the templates. When inheriting attributes from more than one template, Nagios tries to find the directive in each of the templates, starting from the first one. If it is found in the first template, that value is used; if not, Nagios checks for a value in the second one. This cycle continues until the last template in the list. If any of the templates is also inheriting from another template, then a check for the second level of templates is done recursively. This means that checking for a directive will perform a recursive check of all of the templates that are inherited from the currently checked one.
The following illustration shows an example of this situation. The actual host definition inherits three templates—B, F, and G. Template B inherits A, F inherits D and E, and finally, D inherits attributes from template C.
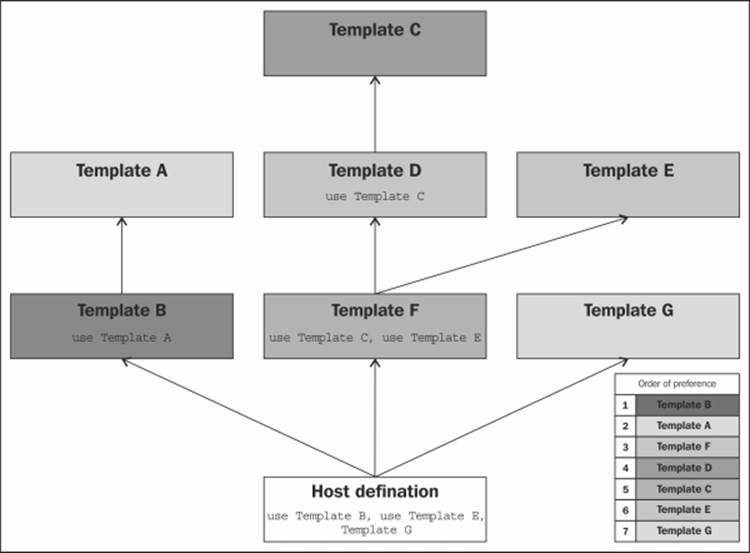
If Nagios tries to find any directive related to this host, the first thing that will be checked is the actual host definition. If the host does not include the directive, Nagios will first look under B, as this is the first template that should be used. If it is not found in B, Nagios will recursively try to find the attribute in A, as it is used by template B. The next step is to look in F along with all of the templates it is using. F inherits D and E. The first one to check is B along with all parent templates—this dictates that D, C, and the next E should now be checked. If the attribute is still not found, then template G is used. Let's assume that the following directives (among others) are defined for the previous illustration:
define host
{
register 0
name A
check_period workinghours
retry_interval 1
check_interval 15
}
define host
{
register 0
use A
name B
check_period 24x7
}
define host
{
register 0
name D
use C
max_retry_attempts 4
}
define host
{
register 0
name E
max_retry_attempts 3
}
define host
{
register 0
use D,E
name F
notification_interval 30
}
define host
{
use B,F,G
host_name ubuntu1
address 192.168.2.1
notification_interval 20
}
For this particular example, the values for the address and notification_interval directives are taken directly from the host ubuntu1 definition. Even though notification_interval is also defined in F, it is overwritten by the actual host definition.
The value for max_retry_attempts is taken from the template D, regardless of whether it is also defined in C. Even though the template E also defines a value for it, as D is put before E, the values defined in both of them are taken from D.
The value for check_period is taken from B, which overwrites the value defined for the template A. Values for retry_interval and check_interval are taken from A.
Even though the preceding examples mention host configurations, templates for other types of objects work in the same way. Templates are often used extensively for service definitions. They usually use a similar approach as the one for hosts. It is a good idea to define templates for branches depending on the priority or type of service, such as a template common for all services in a specific branch, another template for all services for web / mail / other applications and for critical / non-critical / backup servers. This increases the maintainability of the configurations, especially for the larger setups. It is much easier to change contact address or notification settings for all the critical applications if that info is defined in the template used by all services. In this case, our configuration may have several templates, and most of the service definitions will just re-use existing templates, perhaps only specifying how checks for those services should be made.
Contacts, on the other hand, usually use only a couple of templates. They depend on the working hours and the notification preferences. The remaining parameters can be kept in an individual contact's definition. Very often, users may have their own preferences on how they should be notified, so it's better not to try and design templates for that.
Using the custom variables
The custom variables allow you to include your own directives when defining objects. These can then be used in commands. This allows you to define objects in a more concise way, and define service checks in a more general fashion.
The idea is that you define directives that are not standard Nagios parameters in host, service, or contact objects, and they can be accessed from all commands, such as check commands, notifications, and event handlers. This is very useful for complex Nagios configurations where you might want commands to perform nontrivial tasks for which they will require additional information.
Let's assume we want Nagios to check that the hosts have correct MAC addresses. We can then define a service once and use that custom variable for the check command. When defining an object, a custom variable needs to be prefixed with an underscore and written in uppercase.
The custom variables are accessible as the following macros:
· $_HOST<variable>$: This is used for directives defined within a host object
· $_SERVICE<variable>$: This is used for directives defined within a service object
· $_CONTACT<variable>$: This is for directives defined within a contact object
For the preceding example, a macro definition would be $_HOSTMAC$.
These variables can be used for command definitions, notifications, or time periods. The following is an example of a contact and notification command that uses a custom variable for the Jabber address:
define contact
{
contact_name jdoe
alias John Doe
host_notification_commands host-notify-by-jabber
_JABBERID jdoe@jabber.yourcompany.com
}
define command
{
command_name host-notify-by-jabber
command_line $USER1$/notify_via_jabber $_CONTACTJABBERID$
"Host $HOSTDISPLAYNAME$ changed state to $HOSTSTATE$"
}
Of course, you will also need a plugin to send notifications over Jabber. This can be downloaded from the Nagios project on SourceForge (visit http://nagios.sf.net/download/contrib/notifications/notify_via_jabber). The previous example will work with any other protocol you might be using. All that's needed is a plugin that will send commands over such a protocol.
A very useful client called EKG2 (visit http://www.ekg2.org/) allows you to send messages over various protocols, including Jabber, and has a pipe that can be used to send messages over these protocols. A sample command to do this can be as follows:
define command
{
command_name host-notify-by-ekg2
command_line /usr/bin/printf "%b" "msg $_CONTACTEKGALIAS$
Host $HOSTDISPLAYNAME$ changed state to $HOSTSTATE$\n" >>~/.ekg2/.pipe
}
A major benefit of custom variables is that they can also be changed on the fly over an external command pipe. This way, the custom variables functionality can be used in more complex configurations. Event handlers may trigger changes in the attributes of other checks.
An example might be that a ping check with 50 ms and 20 percent packet loss limits are made to ensure that the network connectivity is working correctly. However, if the main router is down and a failover connection is used, the check is set to a more relaxed limit of 400 ms and 50 percent packet loss.
An example configuration might be as follows:
define service
{
host_name router2
service_description PING
check_command check_ping_limits
_LIMITS 50.0,20%
}
define command
{
command_name check_ping_limits
command_line $USER1$/check_ping –H $HOSTADDRESS$
-w $_SERVICELIMITS$ -c $_SERVICELIMITS$
}
When a service that checks if the main router is up (that is, it is in a critical state) an event handler will invoke a change in the limits by sending a CHANGE_CUSTOM_SVC_VAR command (http://www.nagios.org/developerinfo/externalcommands/commandinfo.php?command_id=140) over the external commands pipe to set the _LIMITS custom variable.
Chapter 6, Notifications and Events, covers event handlers and external commands pipe in more detail. So, it is recommended that you read this chapter in order to understand this approach better.
Understanding flapping
Flapping is a situation where a host or service changes states very rapidly—constantly switching between working correctly and not working at all. This can happen due to various reasons—a service might crash after a short period of operating correctly or due to some maintenance work being done by system administrators.
Nagios can detect that a host or service is flapping, if Nagios is configured to do so. It does so by analyzing previous results in terms of how many state changes have taken place within a specific period of time. Nagios keeps a history of the 21 most recent checks and analyzes changes within that history.
The following is an screenshot illustrating the 21 most recent check results, which means that Nagios can detect up to 20 state changes in the recent history of an object. It also shows how Nagios detects state transitions:
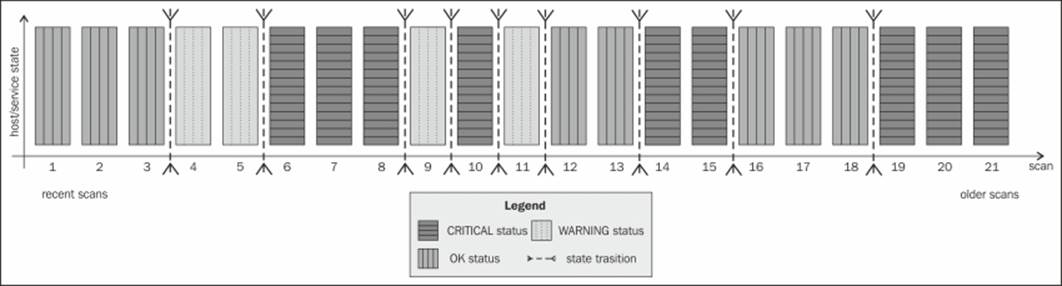
Nagios then finds all of the changes between different states, and uses them to determine if a host or service is flapping. It checks to see if a state is the same as the result from the previous check, and if it has changed, a state transition is counted at this place. In the preceding example, we have nine transitions.
Nagios calculates a flapping threshold based on this information. The value reflects how many of the state changes have occurred recently. If there are no changes in the last 21 state checks, the value would be 0 percent. If all checks have different states, the flapping threshold would be 100 percent.
Nagios also differentiates older results from newer ones. This means that a state transition that took place during the previous 18th check will cause the flapping threshold to be much lower than a transition that took place during the previous third check.
In our case, if Nagios would only take the number of transitions into account, the flapping threshold would be 45 percent. The weighted algorithm used in Nagios would calculate the flapping threshold as more than 45 percent, because there have been many changes in the more recent checks.
Nagios takes threshold values into consideration when estimating whether a host or service has started or stopped flapping. The configuration for each object allows the definition of low and high flapping thresholds.
If an object was not flapping previously, and the current flapping threshold is equal to or greater than the high flap threshold, Nagios assumes that the object has just started flapping. If an object was flapping previously and the current threshold is lower than the low flap threshold, Nagios assumes the object has just stopped flapping.
The following chart shows how the flapping threshold for an object has changed over time, and when Nagios assumed it started and stopped flapping. In this case, the high flap threshold is set to 40 percent and the low flap threshold is set to 25 percent. Red vertical lines indicate when Nagios assumed the flapping to have started and stopped, and the grey area shows where the service was assumed to be flapping.
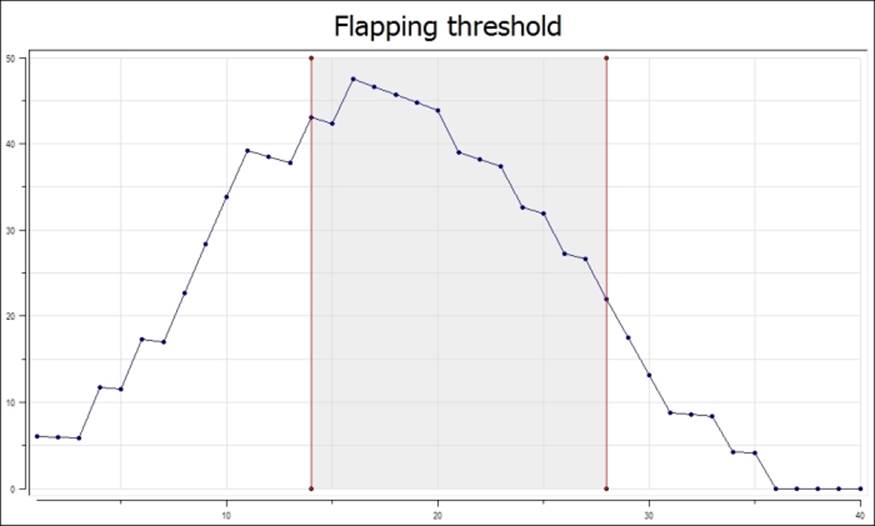
It is worth noting that the low flap threshold should be lower than the high flap threshold. This prevents the situation where after one state transition, flapping would be detected and the next check would tell Nagios that the object has stopped flapping. If both the attributes are set to the same value, an object might be identified as having started and stopped flapping often. This can happen when the flapping threshold changes from below threshold to above threshold or vice versa. This might cause Nagios to send out large number of notifications and cause its performance to degrade.
Summary
When creating or extending Nagios configurations to monitor large number of resources, spend some time planning the layout of your configuration. Some people recommend one file for each single definition, while others recommend storing things in a single file per host. We recommend keeping similar things in the same file and maintaining a directory-based set of files.
In this chapter, we have learned about setting up a directory and file naming structure for configurations. Using proper guidelines for naming and creating the files will help make the configuration maintainable when managing tens and thousands of hosts and services.
We have also defined dependencies, and covered how it can be used to make Nagios automatically notice when a problem is related to other host or when the service is not working properly. We have also learned how to use templates to help define a large number of objects, and how multiple inheritance can be used to automate the defined objects.
This chapter also describes how to use custom variables to access specific information about a host, service, or contact from another object, such as specifying limits for check commands or protocol-specific identification for sending notifications. We have also learned what flapping is and how Nagios uses it to prevent sending notifications about hosts or services that keep changing their state.
The next chapter describes notifications and events in more details. It will help us set up an efficient way to let the IT department know about errors, and when things are back to normal. It will also show how event handlers can be used to proactively fix problems before anyone is notified.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.