Joe Celko's Complete Guide to NoSQL: What Every SQL Professional Needs to Know about NonRelational Databases (2014)
Chapter 10. Biometrics, Fingerprints, and Specialized Databases
Abstract
Biometric databases attempt to identify people from biological and physical differences. Some (very) old methods for identifying people were branding, tattooing, and maiming; this is not popular today. This kind of data goes back to naive biometrics that start with simple photographs, then moved to Bertillon’s measurement system, and finally to various fingerprinting systems. The Bertillon system evolved into machine-collected and precise measurements. Facial recognition evolved from human judgment to photographic and geometric-based computerized systems. Finally, we added retina prints and then moved to DNA to get human identity within 600 billion possibilities.
Keywords
Bertillon card; biometrics; DNA (deoxyribonucleic acid); facial recognition; fingerprints; Galton system; loop; whorls; arch; NIST (National Institute for Science and Technology); SO/IEC 19794-14:2013: Information Technology—Biometric Data Interchange Formats; STR (short tandem repeats); VNTR (variable-number tandem repeats)
Introduction
Currently, biometrics fall outside commercial use. They identify a person as a biological entity rather than a commercial entity. We are now in the worlds of medicine and law enforcement. Eventually, however, biometrics may move into the commercial world as security becomes an issue and we are willing to trade privacy for security.
Automobiles come with VINs (vehicle identification numbers), books come with an International Standard Book Number (ISBN), companies have a Data Universal Numbering System (DUNS), and retail goods come with a Universal Product Code (UPC) bar code. But people are not manufactured goods and do not have an ANSI/ISO standard.
One of the standard troll questions on SQL database forums is how to identify a person with a natural key. The troll will object to any identifier that is linked to a role a person plays in the particular data model, such as an account number. It has to be a magical, universal “person identifier” that is 100% error-free, cheap to use, and instantly available. Of course, pointing out that you do not have a magical, universal generic database for all of humanity, so it is both absurd and probably illegal under privacy laws, does not stop a troll.
We are biological goods! We do have biometric identifiers by virtue of being biological. The first problem is collecting the raw data, the biometric measurements. It obviously involves having a human body and some kind of instrument. The second problem is encoding those measurements in such a way that we can put them into a database and search them.
People are complex objects with lots of dimensions. There is no obvious way you classify a person, no common scales. You might describe someone as “he/she looks < ethnic/gender/age group>” when trying to help someone find a person in a crowd. If the person is statistically unusual and the crowd is small, this can work. Wilt Chamberlain entitled his autobiography Wilt: Just Like Any Other 7-Foot Black Millionaire Who Lives Next Door, as if he would be lost in a crowd. But at the other extreme, there is an advantage for fashion models to be racially and age ambiguous.
10.1 Naive Biometrics
The first biometric identifier is facial recognition. Human beings can identify other human beings by sight, but computerizing this is difficult. People use fuzzy logic in their brains and do not have precise units of measurement to classify a person. This is physically hardwired into the human brain. If the part of the brain that does this survival task is damaged, you become “face blind” and literally cannot match a photograph to the person sitting next to you, or even your own image in a mirror.
Some (very) precomputer-era methods for identifying people were branding, tattooing, and maiming to physically mark a criminal or member of some group. Think of this as a bar code solution with really bad equipment. Later, we depended on visual memory and books full of photographs. But people change over time. Body weight varies, facial hair changes with age and fashion, and age takes its toll. Matching old school yearbook photographs and current photographs of celebrities is a popular magazine feature. Yet, we still accept an awful driver’s license photo as valid identification.
What we need for a database is an encoding system as opposed to a human narrative. Around 1870, French anthropologist Alphonse Bertillon devised a three-part identification system. The first part was a record of the dimensions of certain bony parts of the body. These measurements were reduced to a formula that, theoretically, would apply to only one person and would not change during his or her adult life. The other two parts were a formalized description and the “mugshot” photograph we still use today (Figure 10.1).
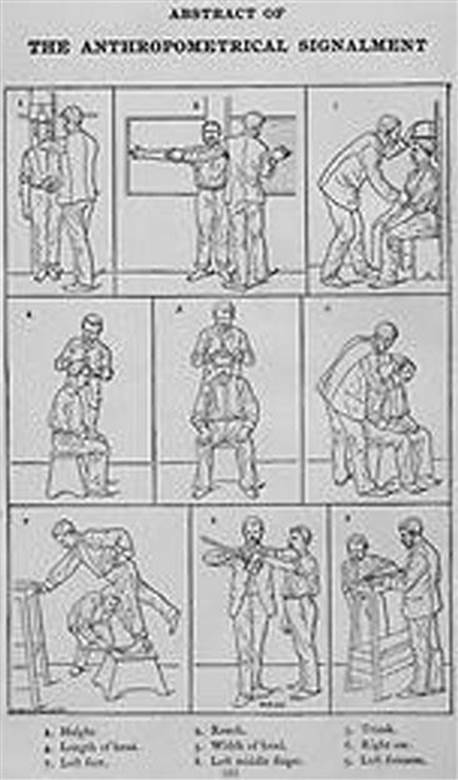
FIGURE 10.1 Bertillon Identification System.
This system also introduced the idea of keeping data on cards, known as Bertillon cards, that could be sorted by characteristics and retrieved quickly instead of paper dossiers. A trained, experienced user could reduce hundreds of thousands of cards down to a small deck of candidates that a human could compare against a suspect or photograph. The cards used holes on the edges to make visual sorting easier.
The Bertillon card encoded the prisoner’s eyes, ears, lips, beard, hair color, skin color, ethnicity, forehead, nose, build, chin, general contour of head, hair growth pattern, eyebrows, eyeballs and orbits, mouth, physiognomic expression, neck, inclination of shoulders, attitude, general demeanor, voice and language, and clothing.
The Bertillon system was generally accepted for over 30 years. Since you had to have the person to measure him or her, and it takes a while, it was used to determine if a suspect in custody was a repeat offender or repeat suspect. It was not useful for crime scene investigations (CSI) that we see on television shows.
The Bertillon system’s descendants are the basis for facial recognition systems, hand geometry recognition, and other biometric identification systems. Rather than trying to reduce a person to a single number, modern systems are based on ratios that can be constructed from still images or video.
10.2 Fingerprints
Fingerprints have been used for identification going back to Babylon and clay tablets. They were used in ancient China, Japan, and India as a signature for contracts. But it was not until 1788 when Johann Christoph Andreas Mayer, a German anatomist, recognized that fingerprints are individually unique.
Collecting fingerprints is much easier than a Bertillon card. Even today, with computerized storage, law enforcement uses the term ten-card for the form that holds prints from all ten fingers. As a database person would expect, the problem was the lack of a classification system. There were several options depending on where you lived. The most popular ten-print classification systems include the Roscher system, the Juan Vucetich system, and the Henry system. The Roscher system was developed in Germany and implemented in both Germany and Japan. The Vucetich system was developed in Argentina and is still in use in South America today. The Henry system was developed in India and implemented in most English-speaking countries, including the United States. Today, it is usually called the Galton–Henry classification because of the work done by Sir Francis Galton from which the Henry system was built.
10.2.1 Classification
In the original Galton system of classification, there are three basic fingerprint patterns: loop (60–65%), whorl (30–35%), and arch (5%). From this basic model, we get more subclassifications for plain arches or tented arches, and into loops that may be radial or ulnar, depending on the side of the hand toward which the tail points. Ulnar loops start on the pinky-side of the finger, the side closer to the ulna, the lower arm bone. Radial loops start on the thumb-side of the finger, the side closer to the radius. Whorls may also have subgroup classifications including plain whorls, accidental whorls, double-loop whorls, peacock’s eye, composite, and central pocket–loop whorls. Then there are tented arch, the plain arch, and the central pocket loop.
The modern system should delight a database person because it uses a simple hashing algorithm. It consists of five fractions, in which R stands for right, L for left, i for the index finger, m for the middle finger, t for the thumb, r for the ring finger, and p (pinky) for the little finger. The encoding is Ri/Rt + Rr/Rm + Lt/Rp + Lm/Li + Lp/Lr The numbers assigned to each print are based on whether or not they are whorls. A whorl in the first fraction is given a 16, the second an 8, the third a 4, the fourth a 2, and 0 to the last fraction. Arches and loops are assigned 0. The numbers in the numerator and denominator are added up, using the scheme:
![]()
and 1 is added to both top and bottom, to exclude any possibility of division by 0. For example, if the right ring finger and the left index finger have whorls, the encoding would look like this:
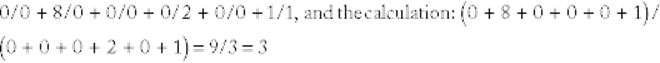
Only fingerprints with a hash value of 3 can match this person.
10.2.2 Matching
Matching a fingerprint is not the same as classifying it. The ten-card is made by rolling each finger on the ten-card to get the sides of the finger as well. In the real world, the sample to be matched against the database is a partial print, smeared or damaged.
This meant a search had to start with the classification as the first filter, then the technician counted the ridges. The final matches were done by hand. At one time, IBM made a special device with a front panel that had ten rotary dial switches, one for each finger with the ridge counts. This was easy for noncomputer police personnel to operate.
Fingerprint image systems today use different technology—optical, ultrasonic, capacitive, or thermal—to measure the physical difference between ridges and valleys. The machinery can be grouped into two major families: solid-state fingerprint readers and optical fingerprint readers. The real problem is that people are soft, so each image is distorted by pressure, skin condition, temperature, and other sampling noises.
To overcome these problems we now use noncontact three-dimensional fingerprint scanners. The images are now digital. We are very good at high-resolution image processing today that can be adjusted by comparing the distances between ridges to get a scale, and distorted back to the original shape.
Since fingerprints are used for security and access, these systems typically use a template that was previously stored and a candidate fingerprint. The algorithm finds one or more points in the fingerprint image and aligns the candidate fingerprint image to it. This information is local to the hardware and it is not meant for data exchange. Big Data databases take time for matching, so we try to optimize things with algorithms and database hardware; current hardware matches around 1,000 fingerprints per second.
In April 2013 Safe Gun Technology (SGTi) said it is hoping it can begin production on its version of a smart gun within the next two months. The Columbus, GA–based company uses relatively simple fingerprint recognition through a flat, infrared reader positioned on the weapon’s grip. The biometrics reader enables three other physical mechanisms that control the trigger, the firing pin, and the gun hammer. The controller chip can save from 15,000 to 20,000 fingerprints. If a large military unit wanted to program thousands of fingerprints into a single weapon, it would be possible. A single gun owner could also temporarily program a friend’s or family member’s print into the gun to go target shooting and then remove it upon returning home.
10.2.3 NIST Standards
NIST (National Institute for Science and Technology) has been setting standards as a member of both ANSI and ISO for decades. They deal with more than just fingerprints; they have specifications for fingerprints, palm prints, plantars, faces, irises, and other body parts, as well as scars, marks, and tattoos (SMTs). Marks, as used in this standard, mean needle marks or tracks from drug use.
The first version of this standard was ANSI/NBS-ICST 1-1986 and was a fingerprint standard. It evolved over time, with revisions made in 1993, 1997, 2000, and 2007. In 2008, NIEM-conformant encoding using eXtensible Markup Language (XML) was adopted. NIEM (National Information Exchange Model) is a partnership of the U.S. Department of Justice and Department of Homeland Security. The most useful part of this document for the causal user is the list of the types of identifiers and their records, shown in Table 10.1.
Table 10.1
Types of Identifiers and Their Records
|
Record Identifier |
Record Contents |
|
1 |
Transaction information |
|
2 |
User-defined descriptive text |
|
3 |
Low-resolution grayscale fingerprint image (deprecated) |
|
4 |
High-resolution grayscale fingerprint image |
|
5 |
Low-resolution binary fingerprint image (deprecated) |
|
6 |
High-resolution binary fingerprint image (deprecated) |
|
7 |
User-defined image |
|
8 |
Signature image |
|
9 |
Minutiae data |
|
10 |
Face, other body part, or SMT image |
|
11 |
Voice data (future addition to the standard) |
|
12 |
Dental record data (future addition to the standard) |
|
13 |
Variable-resolution latent friction ridge image |
|
14 |
Variable-resolution fingerprint image |
|
15 |
Variable-resolution palm print image |
|
16 |
User-defined variable-resolution testing image |
|
17 |
Iris image |
|
18 |
DNA data |
|
19 |
Variable-resolution plantar image |
|
20 |
Source representation |
|
21 |
Associated context |
|
22–97 |
Reserved for future use |
|
98 |
Information assurance |
|
99 |
Common Biometric Exchange Formats Framework (CBEFF) biometric data record |
Please note that voice prints and dental records are not part of these specifications. They show up on television crime shows, but are actually so rare they are not worth adding. Dental records are used after death in most cases to identify a corpse. Voice is hard to match and we do not have an existing database to search.
Type-4 records are single fingerprint images at a nominal scanning resolution of 500 pixels per inch (ppi). You need 14 type-4 records to have the classic ten-card in a file (ten full, rolled individual fingers, two thumb impressions, and two simultaneous impressions of the four fingers on each hand). We want to move over to the type-14 records for fingerprint images.
Type-18 records are for DNA. This uses the ISO/IEC 19794-14:2013 Information Technology—Biometric Data Interchange Formats—Part 14: DNA Data Standard. Because of privacy considerations, this standard only uses the noncoding regions of DNA and avoids phenotypic information in other regions. More on DNA in the next section.
As expected, we have lots of three-letter acronyms: SAP (subject acquisition profile) is the term for a set of biometric characteristics. These profiles have mnemonics: SAP for face, FAP for fingerprints, and IAP for iris records. SAP codes are mandatory in type-10 records with a face image; FAP is optional in type-14 records; and IAP is optional in type-17 records.
Moving to machine processing is important. Humans are simply too error-prone and slow for large databases. In 1995, the Collaborative Testing Service (CTS) administered a proficiency test that, for the first time, was “designed, assembled, and reviewed” by the International Association for Identification (IAI) to see how well trained personnel did with actual data.
The results were disappointing. Four suspect cards with prints of all ten fingers were provided together with seven latent prints. Of 156 people taking the test, only 68 (44%) correctly classified all seven latent prints. Overall, the tests contained a total of 48 incorrect identifications. David Grieve, the editor of the Journal of Forensic Identification, describes the reaction of the forensic community to the results of the CTS test as ranging from “shock to disbelief,” and added:
Errors of this magnitude within a discipline singularly admired and respected for its touted absolute certainty as an identification process have produced chilling and mind-numbing realities. Thirty-four participants, an incredible 22% of those involved, substituted presumed but false certainty for truth. By any measure, this represents a profile of practice that is unacceptable and thus demands positive action by the entire community.
10.3 DNA Identification
DNA (deoxyribonucleic acid) profiling is not full genome sequencing. Profiling is complete enough for paternity testing and criminal evidence. The good news is that a DNA profile can be encoded as a set of numbers that can be used as the person’s identifier. Although 99.9% of human DNA sequences are the same in every person, and humans and chimpanzees differ by less than 2%, there are enough differences to distinguish one individual from another.
In the case of monozygotic (“identical”) twins, there is still enough differences that they can be differentiated by going to the gene level (http://www.scientificamerican.com/article.cfm?id=identical-twins-genes-are-not-identical). At sites of genetic divergence, one twin would have a different number of copies of the same gene, a genetic state called copy number variants. Normally people carry two copies of every gene, one inherited from each parent. But there are regions in the genome that can carry anywhere from 0 to over 14 copies of a gene.
Most of us are familiar with paternity testing that we have seen on television or read about in the tabloids. The initial testing that is done can quickly rule out a father from a sample from the mother and the child. Table 10.2 is a sample report from a commercial DNA paternity test that uses five markers.
Table 10.2
Sample Paternity Report
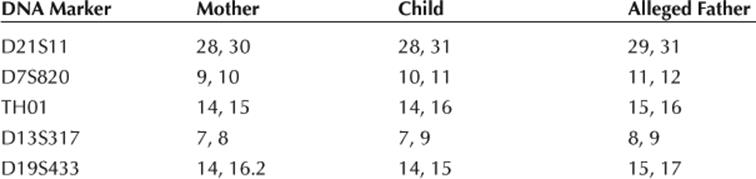
The alleged father’s DNA matches among these five markers, so he is looking guilty. The complete test results need to show this matching on 16 markers between the child and the alleged father to draw a conclusion of whether or not the man is the biological father. The initial test might spot close male relatives. For humans, the complete genome contains about 20,000 genes on 23 pairs of chromosomes. Mapping them is expensive and time consuming.
10.3.1 Basic Principles and Technology
DNA profiling uses repetitive (“repeat”) sequences that are highly variable, called variable number tandem repeats (VNTRs), particularly short tandem repeats (STRs). VNTR loci are very similar between closely related humans, but so variable that unrelated individuals are extremely unlikely to have the same VNTRs.
This DNA profiling technique was first reported in 1984 by Sir Alec Jeffreys at the University of Leicester in England, and is now the basis of several national DNA databases. Dr. Jeffreys’ genetic fingerprinting was made commercially available in 1987, when a chemical company, Imperial Chemical Industries (ICI), started a blood-testing center in England.
The goal has been personalized medicine rather than identification. Identification does not need a full genome, so it should be cheaper. To get an idea of the cost reduction, the first complete sequencing of a human genome, done by the Human Genome Project, cost about $3 billion when it was finally completed in 2003. As of 2010, we can identify markers for specific diseases and genetic traits for under $1,000. Dogs can be identified for under $100; this has been used by anal (pun intended) homeowner associations to tag dogs and their poop to fine owners who do not clean up after their animals.
While every country uses STR-based DNA profiling systems, they do not all use the same one. In North America, CODIS 13 core loci are almost universal, while the United Kingdom uses the SGM + 11 loci system (which is compatible with their national DNA database). There are overlaps in the sets of STR regions used because several STR regions can be tested at the same time.
Today, we have microchips from several companies (Panasonic, IBM, Fujitsu, etc.) that can do a DNA profile in less than an hour. The chips are the size of a coin and work with a single drop of blood or other body fluid. DNA is extracted inside the chip via submicroscopic “nanopores” (holes) in the chip from the blood. A series of polymerase chain reactions (PCRs) are completed inside the chip, which can be read via an interface.
10.4 Facial Databases
We have grown up with television crime shows where a video surveillance camera catches the bad guy, and the hero takes a freeze frame from the video back to the lab to match it against a facial database of bad guys. The mugshots flash on a giant television screen so fast you cannot recognize anyone, until a single perfect match pops up and the plot advances. The video graphics are beautiful and flashy, the heroes are beautiful and flashy, too. The case is always solved, unless we need a cliffhanger for the next season.
Facial databases do not work that way. Like any other biometric data, it can be used in a security system with a local database or as part of a centralized database. While it is pretty much the same technology, database people do not care so much about personal security uses.
Recognition algorithms can be divided into two main approaches: geometric or photometric. Photometric algorithms basically try to overlay the pictures for a match. It easy to have multiple matches when you have a large database to search. This approach automates what people do by eyeball. There is a section of the human brain that does nothing but recognize faces, so we have evolved a complex process for this survival trait (“Hey, you’re not my tribe!”). However, some people have a brain condition called prosopagnosia, or “face blindness,” and they cannot do this. But I digress.
Geometric algorithms extract landmarks, or features, from an image of the subject’s face. These points, such as the center of the eyes, top of the nose, cheekbones, and so forth, can be normalized and then compressed to a mathematical value. A “probe image” is compared with the compressed face data. This is like the hashing algorithm or CRC code—you get a set of candidate matches that you filter.
There is no single algorithm, but some of them are principal component analysis using eigenfaces, linear discriminate analysis, elastic bunch graph matching using the Fisherface algorithm, hidden Markov model, multilinear subspace learning using tensor representation, and neuronal motivated dynamic link matching, if you want to read more technical details.
The bad news is that faces are three dimensional, not flat like fingerprints. In older methods, the viewing angle, lighting, masks, hats, and hairdos created enough “noise-to-signal” that those wonderful matches you see on television shows are not always possible. They worked from static, flattened images from the 8 × 10 glossy headshots of actors!
10.4.1 History
The earliest work in this area was done for an intelligence agency in the mid-1960s by Woody Bledsoe, Helen Chan Wolf, and Charles Bisson. Using an early graphics tablet, an operator would mark coordinates and 20 distances on a mugshot. With practice, they could do about 40 photographs per house. The recognition algorithm was a simple match of the set of distances for the suspect and the database records. The closest matches were returned, using a chi-square matching algorithm.
The real problem was normalizing the data to put the face into a standard frontal orientation. The program had to determine the tilt, lean, and rotation angles, then use projective geometry to make adjustments. To quote Bledsoe (1966): “In particular, the correlation is very low between two pictures of the same person with two different head rotations.” The normalization assumed a “standard head” to which the points and distance could be assigned. This standard head was derived from measurements on seven real heads.
Today, products use about 80 nodal points and more sophisticated algorithms. Some of these measured by the software are the:
◆ Distance between the eyes
◆ Width of the nose
◆ Depth of the eye sockets
◆ Shape of the cheekbones
◆ Length of the jaw line
There is no standard yet, but Identix, a commercial company, has a product called FaceIt®. This product can produce a “face print” from a three-dimensional image. FaceIt currently uses three different templates to confirm or identify the subject: vector, local feature analysis, and surface texture analysis. This can then be compared to a two-dimensional image by choosing three specific points off of the three-dimensional image. The face print can be stored in a computer as numeric values. They now use the uniqueness of skin texture, to yield even more accurate results.
That process, called surface texture analysis (STA), works much the same way facial recognition does. A picture is taken of a patch of skin, called a skin print. That patch is then broken up into smaller blocks. This is not just skin color, but any lines, pores, and the actual skin texture. It can identify differences between identical twins, which is not yet possible using facial recognition software alone.
The vector template is very small and is used for rapid searching over the entire database primarily for one-to-many searching. Think of it as a kind of high-level index on the face. The local feature analysis (LFA) template performs a secondary search of ordered matches following the vector template. Think of it as a secondary-level index, after the gross filtering is done.
The STA is the largest of the three. It performs a final pass after the LFA template search, relying on the skin features in the image, which contain the most detailed information.
By combining all three templates, FaceIt is relatively insensitive to changes in expression, including blinking, frowning, or smiling, and has the ability to compensate for mustache or beard growth and the appearance of eyeglasses. The system is also uniform with respect to race and gender.
Today, sensors can capture the shape of a face and its features. The contour of the eye sockets, nose, and chin can be unique in an individual. Think of Shrek; he is really a three-dimensional triangular mesh frame with a skin over it. This framework can be rotated and flexed and yet still remain recognizable as Shrek. Very recognizable as Shrek. But this requires sophisticated sensors to do face capture for the database or the probe image. Skin texture analysis is a more recent tool that works with the visual details of the skin, as captured in standard digital or scanned images. This can give a 20–25% performance improvement in recognition.
10.4.2 Who Is Using Facial Databases
The first thought is that such databases are only for casinos looking for cheats and criminals or government police agencies. Yes, there is some of that, but there are mundane commercial applications, too.
Google’s Picasa digital image organizer has a built-in face recognition system starting in version 3.5 onward. It can associate faces with persons, so that queries can be run on pictures to return all pictures with a specific group of people together.
Sony’s Picture Motion Browser (PMB) analyzes photos, associates photos with identical faces so that they can be tagged accordingly, and differentiates between photos with one person, many persons, and nobody.
Windows Live Photo Gallery also includes face recognition.
Recognition systems are also used by casinos to catch card counters and other blacklisted individuals.
Police applications are not limited to just mugshot databases in investigations:
◆ The London Borough of Newham tried a facial recognition system in their borough-wide CCTV system.
◆ The German Federal Criminal Police Office has used facial recognition on mugshot images for all German police agencies since 2006. The European Union has such systems in place on a voluntary basis for automated border controls by Germany and Austria at international airports and other border crossing points. Their systems compare the face of the individual with the image in the e-passport microchip.
◆ Law enforcement agencies at the state and federal levels in the United States use arrest mugshot databases. The U.S. Department of State operates one of the largest face recognition systems in the world, with over 75 million photographs, that is actively used for visa processing.
◆ The US-VISIT (U.S. Visitor and Immigrant Status Indicator Technology) is aimed at foreign travelers gaining entry to the United States. When a foreign traveler receives his or her visa, he or she submits fingerprints and has his or her photograph taken. The fingerprints and photograph are checked against a database of known criminals and suspected terrorists. When the traveler arrives in the United States at the port of entry, those same fingerprints and photographs are used to verify that the person who received the visa is the same person attempting to gain entry.
◆ Mexico used facial recognition to prevent voter fraud in their 2000 presidential election. It was a way to detect double voting.
◆ At Super Bowl XXXV in January 2001, police in Tampa Bay, FL, used Viisage facial recognition software to search for potential criminals and terrorists in attendance at the event. Nineteen people with minor criminal records were potentially identified.
Facial recognition for ATM machines and personal computers has been tested, but not widely deployed. The android cell phones have an application called Visidon Applock. This application allows you to put a facial recognition lock on any of your applications. Facial recognition technology is already implemented in the iPhoto application for Macintosh. Another proposal is a smartphone application for people with prosopagnosia, so they can recognize their acquaintances. Smart cameras can detect not just focus, but closed eyes, red eyes, and other situations that mess up portrait photographs.
10.4.3 How Good Is It?
Bluntly, this is not the strongest biometric. DNA and fingerprinting are more reliable, efficient, and easier to search. The main advantage is that it does not require consent or physical samples from the subject and can find them in crowd. Ralph Gross, a researcher at the Carnegie Mellon Robotics Institute, describes one obstacle related to the viewing angle of the face: “Face recognition has been getting pretty good at full frontal faces and 20 degrees off, but as soon as you go towards profile, there have been problems.” In fact, if you have a clear frontal view of a suspect, you can find him or her in more than a million mugshots 92% of the time.
The London Borough of Newham CCTV system mentioned earlier has never recognized a single criminal, despite several criminals in the system’s database living in the Borough, after all these years. But the effect of having cameras everywhere has reduced crime. The same effect occurred in Tampa, FL, and a system at Boston’s Logan Airport was shut down after failing to make any matches during a two-year test period.
The television show Person of Interest that premiered in 2012 is based on the premise that our heroes have a super AI program that can hack every computer, every surveillance, and, with super AI, figure out if someone is going to be in trouble so they can save them before the end of the show. In 2012, the FBI launched a $1 billion facial recognition program called the Next-Generation Identification (NGI) project as a pilot in several states.
The FBI’s goal is to build a database of over 12 million mugshots, voice prints, and iris scans from federal criminal records and the U.S. State Department’s passport and visa databases. They can also add the DMV information from the 30-odd states that currently keep this data.
We are not at “television fantasy level” yet and probably won’t be for many years. However, a test suite provided by NIST called the Face Recognition Grand Challenge (FRGC) (http://www.nist.gov/itl/iad/ig/frgc.cfm) ran from May 2004 to March 2006. The newer algorithms were ten times more accurate than the face recognition algorithms of 2002 and 100 times more accurate than those of 1995. Some of them were able to recognize identical twins who fooled humans.
The 2013 Boston Marathon bombers were not spotted by a fancy FBI facial recognition system, even though Dzhokhar and Tamerlan Tsarnaev’s images existed in official databases. The images that the FBI had of the Tsarnaevs brothers were grainy surveillance camera images taken from far away, with them wearing hats and sunglasses. They were spotted by investigators seeing them planting the bombs on the surveillance footage, then matching a face with an image from the security camera of a 7-11 in Cambridge. After the photos were made public, Facebook and hundreds of cellphone cameras filled in the gaps.
Concluding Thoughts
Biometrics will overcome the technological problems in the near future. It will be possible to have a cheap device that can match DNA and fingerprints or even put it on a smartcard. Identification at a distance is also coming. The real issues are political rather than technical.
References
1. Grieve D. Fingerprints: Scientific proof or just a matter of opinion? 2005; www.sundayherald.com; 2005; http://www.zoominfo.com/CachedPage/?archive_id=0&page_id=1324386827&page_url=//www.sundayherald.com/52920&page_last_updated=2005-11-21T04:47:08&firstName=David&lastName=Grieve.
2. Gross, R. (2001); Shi, J.; Cohn, J. F. Quo vadis face recognition?http://www.ri.cmu.edu/pub_files/pub3/gross_ralph_2001_1/gross_ralph_2001_1.pdf.
3. Bledsoe WW. Semiautomatic facial recognition. Technical Report SRI Project 6693 Menlo Park, CA: Stanford Research Institute; 1968.
4. Bledsoe WW. Man-machine facial recognition: Report on a large-scale experiment. Technical Report PRI 22 Palo Alto, CA: Panoramic Research, Inc; 1966.
5. Bledsoe WW. The model method in facial recognition. Technical Report PRI 15 Palo Alto, CA: Panoramic Research, Inc; 1964.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.