Achieving Extreme Performance with Oracle Exadata (Oracle Press) (2011)
PART II
Best Practices
CHAPTER 8
Exadata and OLTP
When the first Oracle Exadata Database Machine, the HP Oracle Database Machine, was introduced, it represented the first version of the power of the Database Machine. This version was aimed at delivering extreme performance for data warehousing, performance many times faster than was previously achievable with standard database systems.
Version 2 of the Database Machine, the Sun Oracle Database Machine, was released about a year later, with additional capabilities. This version of the Database Machine not only further improved performance for data warehouse workloads, but also provided a solution that delivered extraordinary performance for OLTP workloads. The X2 versions of the Oracle Exadata Database Machine provided even more flexibility in deployment choices for OLTP workloads.
This chapter will explore the use of the Database Machine for OLTP workloads. As with data warehouse workloads, the power of the Oracle Exadata Database Machine stems from a combination of state-of-the-art hardware and software, which includes features that are standard in the Oracle Database 11g environment and features that are exclusive to the Exadata platform.
OLTP Workloads and Exadata Features
Before jumping into an examination of the features and functionality of the Exadata Database Machine as it relates to OLTP, we should start by reviewing some of the key aspects of both OLTP and Exadata software.
The first thing to discuss is the nature of OLTP workloads themselves. OLTP stands for Online Transaction Processing, a description that refers to the core nature of OLTP systems. OLTP systems are used to handle the tactical operations of an organization, that is transactions where data is written to and updated in the database on an ongoing basis. Although data is also written to data warehouses, that data input is traditionally in the form of some type of batch activity, while the write activity in an OLTP system comes in a large number of smaller transactions. Because of this, OLTP workloads typically have a higher number of database operations with a smaller data payload, and the performance emphasis is on the responsiveness of the database in handling these smaller transactions.
But OLTP workloads consist of more than just small write transactions. An OLTP workload inevitably includes read activity of a type more typical of OLTP than data warehousing (e.g., single row lookups) and activities like production reporting where the characteristics of the workload are similar to those of data warehouse workloads. Some of these portions of an OLTP workload will benefit from the features of a Database Machine in the same way that data warehouse workloads will benefit—from the dramatic reduction in data returned to the database nodes through predicate filtering in the Exadata Storage Server, the use of storage indexes to reduce the amount of I/O from storage disks, and join filtering to further reduce the amount of data returned from storage.
The second point to make is that Exadata features either improve the performance of database operations or remain transparent. Remember that, for instance, the Exadata Storage Server can return a greatly reduced set of data when using Smart Scan techniques, or that the Server can simply return data blocks, just like a standard storage for an Oracle database. Similarly, a storage index can help to eliminate storage regions from being read by the storage server, or simply remain in Exadata Storage Server memory until it can be used effectively—neither case negatively affects an operation that does not use the storage index.
This transparency works in two ways. Exadata features will not intrude on operations where they cannot help improve performance, and all the standard features of the Oracle 11g Database are available to all operations on a Database Machine. The Oracle Database has long been the leading OLTP database in the world, and nothing in the Exadata environment degrades any of that industry-leading functionality.
Another key aspect of the Exadata Database Machine is the imposition of best practices in hardware design through the use of a balanced configuration. The Database Machine is specifically architected to avoid bottlenecks due to oversubscription for resources, an all-too-common problem that can affect database servers supporting any type of workload. Remember that a resource shortage in one area is typically relieved by compensating with excess resource consumption in another area. By avoiding bottlenecks caused by read-intensive query operations, the robust configuration of a Database Machine helps to avoid unbalanced configurations for all systems, both data warehouse and OLTP.
Finally, remember the focal point of discussion in Chapter 3 on Exadata software. The overall direction of Exadata software is to improve the efficiency of database operations. Improved efficiency, once again, means better use of database resources across the board. In the following discussions, you continually see how the improved efficiency of the Exadata Database Machine leads to better resource utilization, resulting in improvement in all types of workloads and database operations.
Exadata Hardware and OLTP
Although, as should be abundantly clear at this point, Exadata is about much more than hardware, any discussion of OLTP and Exadata should include some mention of the hardware configuration and how this hardware is used by the Exadata Database Machine.
General Hardware and Infrastructure Considerations
Version 2 of the Exadata Database Machine used Xeon 5500 Nehalem CPUs with four cores per CPU—extremely fast, state-of-the-art processors. Version X2 of the Exadata Database machine uses six core processors in the X2-2 models and the Exadata Storage Server, and eight core processors in the X2-8 model. The X2-8 model also has 2TBs of DRAM. Given this history, you can expect future versions of the Database Machine to benefit from further increased capabilities in the core hardware components—and some of these improvements might have already happened by the time you are reading this sentence.
The Exadata Storage Server features a large number of disks—up to 168 disks in a full rack—so the overall system benefits from the ability to seek data across many disks through parallel operations. Automatic Storage Management (ASM) optimizes the use of large numbers of disks and, in so doing, gives you the benefits of distributed data and parallel retrieval without a large amount of overhead to manage the data placement.
The Exadata Database Machine is also built as a balanced configuration, which means that data flow does not encounter bottlenecks between the storage system and the database nodes. Although this type of configuration primarily benefits more I/O-intensive applications, such as data warehousing, the minimization of bottlenecks for all types of I/O ensures that OLTP workload components, like production reporting, will not limit the availability of bandwidth in a way that could compromise other OLTP workload components.
Finally, there is one internal change in the way that the Oracle database accesses data from the Exadata Storage Server. In a non-Exadata environment, the Oracle kernel queues and dequeues I/O requests using C libraries. In the world of Exadata, the Oracle kernel can request data directly from the processes on the Exadata Storage Server using Remote Direct Memory Access, or RDMA. When you think about OLTP workloads, you think about very large numbers of individual transactions and I/O requests. With Exadata, the queueing and dequeuing requests do not dive into the kernel, meaning less CPU overhead to perform all of these small I/Os.
This last point again illustrates that the Exadata Database Machine is much more than simply a bunch of hot hardware components strung together. The Exadata Smart Flash Cache combines a fast hardware component and flexible software intelligence in a similar way.
Exadata Smart Flash Cache
The Exadata Smart Flash Cache uses a fast hardware component, delivering data many times faster than retrieval from disk, coupled with smart software to optimize its benefits, as described in Chapter 3.
Each Exadata Storage Cell contains 384GBs of Flash Cache, located on 4 flash PCIe cards. This hardware means that a full rack contains around 5.4TBs of flash-based storage, a figure we will return to in our discussion of working sets later. In all scenarios, satisfying an I/O request from the Exadata Smart Flash Cache means that this request will not have to be satisfied from disk, resulting in greater available bandwidth for the requests that do go to disk. In addition, remember that I/O bandwidth is consumed by both reads and writes, so satisfying reads from the Exadata Smart Flash Cache removes those requests from the disk workload, increasing the number of operations available for writes to disk.
You can use the Exadata Smart Flash Cache in three different ways to support OLTP operations.
Default Usage
The Exadata Storage Server Software, by default, places the results of small I/O operations into the cache, for the same reasons that the data cache does not use the results of large I/O operations to avoid flushing the cache unnecessarily. These smaller I/O operations are the type that are typically performed by OLTP workloads, so, over time, the I/O operations performed by OLTP workloads end up populating the available Flash Cache. Since the default operation of the Flash Cache includes caching the results of write operations, reuse of these data blocks can also benefit from the speed of this cache.
The concept of a working set is one way to describe the way that OLTP workloads interact with storage. The term working set refers to the portion of data that is used by an application workload at any particular time. If a working set can be kept entirely available in high-speed access areas, such as the SGA or the Exadata Smart Flash Cache, the workload will not be subjected to any performance bottlenecks based on data used in read operations.
Exadata Smart Flash Cache can hold a little over 18 percent of the data stored on disks in the cell with High Performance storage, given normal redundancy and reserves for system space. This percentage is close to the commonly accepted size of an OLTP working set in relation to the overall store of data. Because of this and the way that the Exadata Smart Flash Cache operates, the Flash Cache can conceivably hold the entire working set providing improved OLTP workload performance.
Keep in mind that the default operation of the Exadata Smart Flash Cache allows for the composition of the cached data to evolve over time. As data moves into the “hot spots” of usage, the Exadata Smart Flash Cache software will automatically end up storing this heavily requested data into the cache. The dynamic nature of this population means that you can benefit from the speed improvements of Flash Cache without excessive management overhead.
KEEP Option
You can also use the STORAGE (CELL_FLASH_CACHE KEEP) option when defining or altering tables, partitions, and indexes. With this clause, all data blocks for the specified object are automatically placed into the Exadata Smart Flash Cache after they are initially read. You can use up to 80 percent of the capacity of the Exadata Smart Flash Cache for storing objects with the KEEP clause.
Bear in mind that the KEEP clause, as explained in Chapter 3, does not guarantee that all data blocks for an object will be in the Exadata Smart Flash Cache at any one time. The clause does specify that the KEEP objects will be aged out of the cache with a less aggressive algorithm and that data blocks being added to the cache with the algorithm used, by default, will not force out an object with the KEEP clause.
In general, you should not assign more data as KEEP objects than can be held simultaneously in that portion of the Exadata Smart Flash Cache. The reason you would use this clause is to ensure that this data is “pinned” in the cache, and if there is more data than can be held at one time, other KEEP data blocks could force blocks out of the cache. Remember this guideline if you are considering assigning an object this status, as database objects tend to increase in size over time. What may be less than 80 percent of the Exadata Smart Flash Cache today could end up being larger in the future, requiring management overhead to track and adjust.
Of course, the KEEP attribute is manually assigned, so the contents of the Exadata Smart Flash Cache will not evolve as usage conditions change, as they would with the default use of the cache. You can use this attribute to improve performance by keeping specific data in the Flash Cache, but you will obviously have to be familiar with usage patterns of your workload in order to best assign tables and partitions to the KEEP portion of the Exadata Smart Flash Cache.
Flash-Based Grid Disks
There is another way you can use the Exadata Smart Flash Cache with OLTP workloads. As described in Chapter 3, the flash storage can be provisioned as grid disks, just as you would use cell disks based on physical disks. These grid disks are used by ASM just as any other group of grid disks would operate.
When you use flash storage in this way, you can write directly to the flash drives, which is quite fast. However, this use of flash storage comes with a significant downside. You would lose either half the capacity of the Flash Cache, with ASM normal redundancy, or two-thirds of the capacity, with ASM high redundancy. Although the PCIe flash cards used in the Exadata Storage Server are highly reliable, the memory-based nature of flash grid disks would call for high redundancy, resulting in less flash to use.
This scenario could result in higher performance for extremely high levels of concurrent writes. However, keep in mind that the Oracle database already has implemented ways to process high levels of write operations, with the DBWR process performing “lazy” writes and the option to have multiple DBWR processes handling the workload. Before jumping immediately to an architecture that uses flash-based grid disks for high-write environments, you should test to see if the performance enhancement you are looking for actually materializes with this implementation.
NOTE
Are you thinking that you could realize performance gains by putting redo logs onto flash-based grid disks? Flash storage provides significant performance improvements over physical disks for random I/O writes, but not much of an improvement over physical disks for sequential writes. This approach will not really get you much in the way of improved performance. In addition, wear leveling in flash storage could result in unpredictable performance changes as data is reorganized in the storage-performance changes that result in writes being two orders of magnitude slower.
Exadata Smart Flash Cache and Data Integrity
The Oracle database has been supporting enterprise-class applications for decades, and the development team at Oracle knows that supporting the integrity of data is an absolute pre-requisite for their database. Flash Cache is memory-based, and memory is inherently less stable than disk. Does this difference cause any potential issues with data integrity, since data stored on flash-based storage could potentially disappear?
First of all, you should be aware that the particular flash cards used in the Exadata Storage Server have a number of features to compensate for potentially instability, including only using a portion of the available storage to allow for automatic detection and swapping out of bad blocks in memory, as well as an integrated super capacitor to supply power to the card in the event of a power failure. In addition to these hardware-based protections, if you choose to use the Exadata Flash as flash-based grid disks, you can use high-redundancy mirroring with ASM.
Second, one of the most crucial aspects of data integrity that could be affected by a loss of data in the cache would be if a user wrote data to the cache and the values were lost before they could be written to disk. The Oracle Database can handle data loss as long as the write activity has been written to the log file. The redo logs hold the primary responsibility for avoiding data loss in the event of a failure, and these logs are not stored in the Flash Cache.
Finally, remember that the Exadata Smart Flash Cache is normally used as a cache. If any portion of the cache goes away, all that happens is the Exadata Storage Server gets the requested data from disk. You would lose the performance advantages of the Flash Cache for the duration of the time that this portion of the cache was not available, but the failure would not have any other impact on the operating environment.
Oracle 11g and OLTP
The Oracle Database has long been the leading database for OLTP workloads. As the authors have updated some of their other books over the past few releases, we have found that not many features have been added to the Oracle Database to improve OLTP operations, for the simple reason that the product is fairly complete already in this area.
The Exadata Database Machine benefits from all of these features for OLTP, and, since Oracle on Exadata works transparently for all applications, these features can provide the same benefits on this new platform as on the classic Oracle Database.
Classic Oracle Features
There are a number of features and best practices that you should use for OLTP workloads on an Exadata Database Machine, which have been used with the Oracle Database for many years.
![]() MVRC Multiversion read consistency was first introduced to the Oracle Database more than 20 years ago and still provides one of the key advantages for OLTP workloads. Just as Exadata technology improves the overall performance of a workload by removing bottlenecks, such as I/O bandwidth, MVRC performs a similar function by removing delays caused by contention for resources, primarily in OLTP environments. With MVRC, writers don’t block readers, and readers don’t block writers. MVRC provides additional benefits, as described in Chapter 2, but the core capability of removing delays caused by locks used to protect data integrity remains one of the most powerful features of the Oracle Database.
MVRC Multiversion read consistency was first introduced to the Oracle Database more than 20 years ago and still provides one of the key advantages for OLTP workloads. Just as Exadata technology improves the overall performance of a workload by removing bottlenecks, such as I/O bandwidth, MVRC performs a similar function by removing delays caused by contention for resources, primarily in OLTP environments. With MVRC, writers don’t block readers, and readers don’t block writers. MVRC provides additional benefits, as described in Chapter 2, but the core capability of removing delays caused by locks used to protect data integrity remains one of the most powerful features of the Oracle Database.
![]() Shared servers Normally, each user process connecting to Oracle from a client has a shadow process, or dedicated server, on the server machine. Oracle allows you to use a shared server which, as the name implies, can share a server process among more than one user. Shared servers work by assigning clients to a dispatcher rather than a dedicated server process. The dispatcher places requests into queues, which are processed by a pool of shared server processes, as shown in Figure 8-1.
Shared servers Normally, each user process connecting to Oracle from a client has a shadow process, or dedicated server, on the server machine. Oracle allows you to use a shared server which, as the name implies, can share a server process among more than one user. Shared servers work by assigning clients to a dispatcher rather than a dedicated server process. The dispatcher places requests into queues, which are processed by a pool of shared server processes, as shown in Figure 8-1.
Since each server process consumes resources, reducing the number of servers required reduces resource demand and improves the scalability of an Oracle environment, especially in situations that support a large number of users, such as OLTP environments. Shared or dedicated servers are determined by configuration parameters, so applications can take advantage of this feature without any change in code.
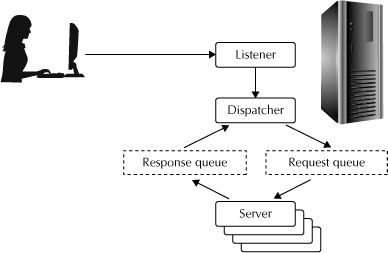
FIGURE 8-1. Shared server architecture
![]() Connection pooling Just as server processes consume resources on the database server, connections from clients to those servers consume network resources as well as server resources. Connection pooling allows client connects to multiplex over a single connection, analogous to the way shared servers save resources. Once again, in a high-transaction OLTP environment, connection pooling can provide greater scalability with the same amount of resources.
Connection pooling Just as server processes consume resources on the database server, connections from clients to those servers consume network resources as well as server resources. Connection pooling allows client connects to multiplex over a single connection, analogous to the way shared servers save resources. Once again, in a high-transaction OLTP environment, connection pooling can provide greater scalability with the same amount of resources.
![]() RAC scalability Real Application Clusters, like MVRC, is both a key Oracle differentiator and a feature that provides benefits in several areas, including availability and scalability. For OLTP workloads, the scalability aspect of RAC is particularly important. OLTP workloads are typically CPU-bound, and with RAC, you can add more CPU power to an existing cluster by simply adding a node to an existing cluster. Without any changes in applications or client configuration, you can relieve any CPU stress on your RAC database. You can even accomplish this without bringing the database down. As you add more nodes to your RAC cluster, you are also spreading the pool of connections over more CPUs and servers, giving you greater scalability in this resource area as well. Although the number of nodes in a specific configuration of an Exadata database machine is fixed, you can upgrade the machine by filling out a partially full rack or add more racks, and you can have multiple RAC databases on a single Database Machine, shifting nodes between them as appropriate.
RAC scalability Real Application Clusters, like MVRC, is both a key Oracle differentiator and a feature that provides benefits in several areas, including availability and scalability. For OLTP workloads, the scalability aspect of RAC is particularly important. OLTP workloads are typically CPU-bound, and with RAC, you can add more CPU power to an existing cluster by simply adding a node to an existing cluster. Without any changes in applications or client configuration, you can relieve any CPU stress on your RAC database. You can even accomplish this without bringing the database down. As you add more nodes to your RAC cluster, you are also spreading the pool of connections over more CPUs and servers, giving you greater scalability in this resource area as well. Although the number of nodes in a specific configuration of an Exadata database machine is fixed, you can upgrade the machine by filling out a partially full rack or add more racks, and you can have multiple RAC databases on a single Database Machine, shifting nodes between them as appropriate.
![]() Bind variables The Oracle optimizer is used to generate an execution plan for all SQL statements—a task that requires some CPU resources. In an Oracle Database, the execution plan for a SQL statement is placed into the shared SQL area of the SGA. If the database receives another SQL statement that is identical to one stored in the SGA, Oracle retrieves and uses the existing execution plan, replacing a relatively resource-intensive operation with a simple retrieval from memory. This approach can save loads of resources in a high-volume transaction environment like OLTP.
Bind variables The Oracle optimizer is used to generate an execution plan for all SQL statements—a task that requires some CPU resources. In an Oracle Database, the execution plan for a SQL statement is placed into the shared SQL area of the SGA. If the database receives another SQL statement that is identical to one stored in the SGA, Oracle retrieves and uses the existing execution plan, replacing a relatively resource-intensive operation with a simple retrieval from memory. This approach can save loads of resources in a high-volume transaction environment like OLTP.
An OLTP workload is characterized by a high number of short transactions, and many of these transactions use almost identical SQL statements, differing only by the use of different values for some clauses, such as WHERE clauses. For instance, a SQL statement could make a comparison with the same column and the same relational operator, with the only difference being the values that these are compared with.
As an example, the following two SQL statements
SELECT count(*) FROM customers WHERE last_name ='SMITH'
and
SELECT count(*) FROM customers WHERE last_name ='JONES'
could both be represented with this SQL statement, which uses bn as a bind variable:
SELECT count(*) FROM customers WHERE last_name = :bn
The first two statements would not be recognized as the same statement, while the bind variable version would reuse the version in the shared SQL area.
One of the key best practices for writing SQL statements as part of an OLTP-style application is to use bind variables instead of literal values wherever possible to allow for the reuse of execution plans. This approach does require some planning when creating applications, but can offer significant rewards. Remember, OLTP transactions are typically fairly small, so recompiling and creating a plan, and the corresponding impact of latching for shared pool resources, can be comparatively large.
This capability of the Oracle Database is not unique to Exadata, but still represents an important way that OLTP workloads can perform well in the Oracle environment.
![]() Database Resource Manager Database Resource Manager, as discussed in Chapter 2, is a key tool for dividing oversubscribed resources between competing applications or tasks. OLTP workloads tend to be CPU-bound, so the CPU allocation capabilities of Database Resource Manager can be used to ensure that responsecritical components of the overall workload continue to receive adequate CPU, even in times of great demand.
Database Resource Manager Database Resource Manager, as discussed in Chapter 2, is a key tool for dividing oversubscribed resources between competing applications or tasks. OLTP workloads tend to be CPU-bound, so the CPU allocation capabilities of Database Resource Manager can be used to ensure that responsecritical components of the overall workload continue to receive adequate CPU, even in times of great demand.
An OLTP workload usually has some response-sensitive portions, such as write requests, and some components that have less critical response requirements, such as production reporting or batch jobs.
For these types of workload mixes, the ability to divide resources at different priority levels is the key. With Database Resource Manager, you can specify that the response-critical components are in the top priority group, receiving either all resources or some percentage of overall CPU. All other groups will only receive the CPU cycles that are left over from this top priority group, ensuring that any CPU-bound delays affect all noncritical tasks before they touch the high priority group—just the type of allocation that an OLTP workload would benefit from.
One other standard Oracle feature requires some discussion as it applies to the Exadata platform and OLTP workloads. The Oracle Database supports a number of types of indexes, and these indexes are used for a variety of purposes, from implementing constraints, such as uniqueness and foreign constraints, to use as a way to improve the performance of specific data access operations. For non-Exadata environments, the use of a full table or full index scan could result in poor performance, since these operations incur a high I/O cost.
As you have seen, though, through the use of features such as offloading certain types of query processing, full table scans on an Exadata Database Machine can really fly—one published example showed that a full table scan of 2 million rows took approximately the same time as retrieving 10 to 15 single data blocks. This type of performance with full table and full index scans can eliminate the need for some indexes whose purpose is strictly to improve retrieval performance. Because of the elimination of this need, you can frequently eliminate a portion of existing indexes on your data, which can cut down correspondingly on the cost of database writes, since the eliminated indexes will not have to be updated. You can use the option of making an index invisible to the optimizer to quickly compare query performance with and without the use of one or more indexes.
Oracle and Linux
The Oracle Exadata Database Machine uses Oracle Enterprise Linux (OEL) as the operating system on both the database server nodes and the Exadata Storage Server. In 2011, Oracle also began supporting Solaris as an alternative operating system you might deploy on the database server nodes. Although you cannot modify the software or configuration of OEL on the Exadata Storage Server, there is a useful configuration change you should make for Oracle Enterprise Linux on the database server nodes.
The effect of the configuration change will be to instruct applications, in this case, the Oracle database instance, to use hugepages. When Linux uses hugepages, there are two important effects. First of all, the page size for shared memory is increased from the default of 4KB to a much larger size, such as 2MB, meaning the management of those pages will be greatly reduced. Second, memory used by hugepages is locked, so it cannot be swapped out. These two effects mean that the Linux-based overhead of managing shared database memory, the SGA, is significantly reduced in a heavily loaded environment.
You should set the overall size for hugepages to a size greater than the memory requirements of all the SGAs you will have for all the instances the server will be supporting. This setting will avoid having to swap out the SGA, especially when you have a large number of client processes, as is typical with an OLTP workload.
You can find information on setting up hugepages for the OEL environment in a number of places in the Oracle Database documentation, including the Administrator’s Reference for Linux and UNIX-based Operating Systems.
In the most current release of the Oracle Database software, you can set a parameter that will check to see if hugepages are properly configured before starting an instance and that will fail if hugepages are not properly configured.
Quality of Service Management
Oracle 11g Release 2 introduced one feature that can have a significant impact on using the Oracle Database for OLTP workloads. The feature is an expansion of the capabilities of Real Application Clusters to allow for dynamic reprovisioning of CPU resources in order to meet service levels—a method that will help you to guarantee quality of service (QoS) for a RAC-based database.
Server Pools
QoS is based on a few core concepts used for managing servers in a RAC environment. The first concept is that of a server pool. A server pool is a group of servers that are, in effect, partitioned to separate them from other server pools. A RAC installation has a default server pool, the free pool, and a generic pool, as well as any number of additional pools, which you can define.
Each server pool has a minimum number of servers, a maximum number of servers, and an importance. RAC allocates servers to the server pools until all pools have the minimum number of servers. Once this level is reached, RAC allocates any additional servers for a pool, up to the maximum number, based on the importance of the pool. Any servers left once these levels are reached remain in the free pool.
In the event of a server failure, QoS first determines if the failure results in the number of servers in a server pool dipping below the minimum specified. If the failure does not have this effect, no action is taken. If the number of servers in a pool does go below the specified minimum, QoS first looks to the free pool for a replacement server. If no servers are available in the free pool, QoS looks to server pools with a lower importance for replacement servers.
Performance Classes
The concept of a RAC-based service was described in Chapter 2. QoS management adds the concept of a performance class. A performance class consists of one or more services that share a performance objective. These performance objectives are used to evaluate the quality of service being provided by the managed RAC environment.
For instance, you could group a variety of sales applications as one performance class, with maintenance and batch operations grouped together in another performance class.
Policies
Performance classes and server pools come together in a policy. A policy associates the available server pools with performance classes, as shown in Figure 8-2.
Figure 8-2 shows more than one policy, based on the time of day and within a quarter. You can have multiple policies, but only one policy can be in place at any one time on any one server. A collection of policies is known as a policy set.
A policy also includes a performance metric associated with a particular performance class. In Figure 8-2, you could require that an application in the online server pool deliver an average response time of two seconds during normal business operations, but that this requirement is relaxed to four seconds in the after-hours policy or three seconds during the crunch in the end-of-the-quarter server policy.

FIGURE 8-2. Policies
A policy also contains server pool directive overrides. These overrides prescribe the action that should be taken in the event that a performance objective is not met. For instance, you could specify that the minimum number of servers be increased if a performance objective was not being achieved.
A policy can contain more than one performance class, so the performance classes can be ranked in importance. The ranking is used to determine which performance objectives should be satisfied in the event that the RAC database does not have sufficient resources available to meet all performance objectives. In this scenario, the higher-ranking performance class receives resources ahead of lower-ranking performance classes.
QoS at Work
Quality of service management works in the runtime environment by collecting performance metrics from the cluster every five seconds. Those metrics are evaluated every minute to determine if performance objectives are being met.
If an objective is not being met, there are two potential courses of action. One course is to allocate additional servers to the performance class. If servers in the free pool are available, they are added to the server pool for the performance class. If there are no servers in the free pool, QoS management looks to performance classes with a lower importance that have servers in excess of their minimum number. As a final choice, QoS looks to server pools with the same importance as the stressed pool where giving up a server node would not result in that node falling below the minimum number of servers.
Another course of action is for QoS to look at the consumer groups defined in Database Resource Manager to find a consumer group with a larger percentage of resources assigned. If this option is available, QoS migrates the underperforming services to this higher-priority consumer group to allocate more resources for the performance class.
QoS evaluates these options and more before it makes a recommendation to modify allocation of resources. In addition to looking at simply addressing the need to provide service to an underperforming performance class, QoS determines the impact that the recommended changes may have on the performance class that will lose resources. The recommendation, and the projected effect on all performance classes, is delivered to Enterprise Manager. With this recommendation, you can see the estimated impact on performance time for all performance classes defined for the policy currently in place.
In Chapter 2, you learned how you can use Database Resource Manager to design and implement highly flexible schemes for allocating resources to different groups of consumers. QoS management provides a similar level of flexibility in defining the use of resources and couples this design capability with real-time monitoring of service levels to ensure the optimal level of service for all types of work on an Oracle database.
At this time, QoS is all about OLTP workloads, since one measurement criterion is CPU response time, one of the key service levels used to evaluate performance for these workloads. When you use the Exadata Database Machine as an OLTP platform, or as a consolidation platform that includes OLTP operations, you can use the monitoring and management capabilities provided by QoS management to ensure that the resources of the Database Machine are used to provide optimal performance across the spectrum of service levels required.
NOTE
Quality of Service does more than simply monitor CPU utilization. QoS also tracks memory use on individual nodes, preventing additional sessions from being directed towards nodes that do not have enough free memory to support more connections. In addition, QoS evaluates the negative impact of reallocating servers versus the positive impact of this action. If the negatives outweigh the positives, QoS may not recommend changing resource allocations. For more details on QoS and its implementation, please refer to the Oracle documentation.
Exadata Software and OLTP
As mentioned earlier in this chapter, the Exadata feature with the biggest impact on OLTP workloads is the Exadata Smart Flash Cache. The default operation of the Flash Cache is designed to provide high-speed access to the type of smaller I/Os that are characteristic of OLTP operations. With the KEEP option and the ability to define flash-based grid disks, the Exadata Smart Flash Cache gives you additional options for using this high-speed device for OLTP workloads. The other software features of Exadata play a smaller role in an OLTP environment.
Partitions have been a part of OLTP database design for many years, as they can eliminate the amount of data required to satisfy a query. Storage indexes, as described in Chapter 3, provide a similar benefit, but to an even more granular level of 1MB storage regions. Storage indexes will have their greatest effect when used with data that is loaded in sorted order, but even data added to the database through the small insert operations typical of OLTP workloads could potentially benefit from the use of storage indexes, as this data can share a fairly small set of values for some time-sensitive columns. And storage indexes, like other Exadata software features, do not harm performance, so any incremental gains produced with this technology will not be offset by any performance degradation caused by their implementation.
I/O Resource Management (IORM) is used to ensure that the I/O resources of the Exadata Storage Server are properly allocated across different consumer groups. The primary focus of IORM is I/O-intensive workloads, which describe data warehouse operations more than traditional OLTP. But, as stated previously, OLTP workloads include tasks that can generate a fair amount of I/O activity, such as production reporting. You can use IORM to ensure that OLTP operations receive adequate resources to avoid any potential bottlenecks. In addition, you can use IORM to avoid the potential for I/O-intensive workloads to require too much of the database CPUs by saturating them with requests to receive data from the Exadata Storage Server.
This last point comes around to the key reason why the Exadata Database Machine works for OLTP workloads as well as data warehouse workloads. With Exadata software and a balanced configuration, the Database Machine implements best configuration practices for any Oracle Database. In doing so, the Database Machine provides performance and throughput benefits for all types of workloads.
Exadata Nodes and OLTP
At Oracle OpenWorld in 2010, Oracle announced new configurations of the Exadata Database Machine, as described in Chapter 4. One of the biggest configuration changes was the introduction of a new type of database node, with eight CPUs, each of which has eight cores, and 1TB of memory.
Many highly utilized OLTP systems run on enormous SMP systems, where a single machine has a large number of CPUs as well as a large amount of memory. The new “heavyweight” database nodes in the X2-8 configuration have 64 database cores per server node, as well as 1TB of memory on each node. This configuration comes closer to matching the type of machine used for high-volume OLTP systems than the database nodes in the X2-2 series, which have 12 cores and 96GBs per server, although these systems can use eight of these nodes, rather than the two nodes used in an X2-8 system.
OLTP systems are designed to support many users running many short transactions, and the demands of this environment may be better met with a smaller number of large nodes, rather than a larger number of smaller nodes. Of course, the X2-8 models, with only two nodes, could be affected more seriously by a node failure, but some OLTP scenarios might find that the benefits of increased scalability outweigh this potential risk.
Exadata as a Complete System
There is one more aspect of the Database Machine that helps to improve OLTP workloads. OLTP systems are frequently stand-alone systems, where the database servers are completely dedicated to these systems. But these systems are also frequently tied into some type of shared storage arrangement, such as SAN disk arrays. Because of this, the owners of the system have to negotiate to ensure that the needs and priorities of the systems are properly handled by the shared resources, whether storage resources or network resources.
Unfortunately, these negotiations are not always totally successful. OLTP systems may not be able to get enough of these crucial resources, so their operations can suffer as the resources become inadequate under particular workloads.
The Oracle Exadata Database Machine is a self-contained unit, with all computing resources included. This ownership means that developers and administrators can allocate resources to best address the needs of their workloads.
Of course, the allocation tools available for Oracle and the Database Machine, including Database Resource Manager and the I/O Resource Manager, mean that you have a tremendous amount of flexibility in assigning resources dynamically. Without the need to compromise allocations based on reasons outside the immediate database environment, you will have the freedom to give your systems what they need to deliver optimal performance.
In this way, the self-contained implementation of the Database Machine means that you can avoid some of the external political issues that can interfere with your attempts to provide the highest levels of service for your customers.
Summary
The Exadata Database Machine can support both data warehouse and OLTP workloads. The features of the Database Machine that support data warehousing are also useful for the reporting aspects of OLTP systems, while a number of features, such as Exadata Smart Flash Cache, contribute directly to improved performance for OLTP workloads. In addition, the introduction of new nodes for the X2-8 configuration, with 64 cores and 1TB of memory per node, provide the type of heavyweight processing power needed by high volume OLTP systems.
The context for this chapter has been the assumption that you will be using an Oracle Exadata Database Machine for an OLTP application. The discussion of the features and the techniques used with the Database Machine have not really focused on some of the unique issues that arise when you have more than one application running on an Exadata system.
Of course, you likely will have more than one application on your Database Machine eventually, if not at the initial deployment, whether the multiple applications are all OLTP or a mixture of OLTP and more read-intensive applications, such as a data warehouse.
Certainly, many of the features discussed in this chapter have relevance to this type of consolidated platform, such as Database Resource Manager and I/O Resource Manager. And the overall benefit derived from a Database Machine could very well consist of some advantages for data warehouse workloads and others oriented towards OLTP applications.
The entire subject of consolidation is, in fact, the topic of the next chapter.