Achieving Extreme Performance with Oracle Exadata (Oracle Press) (2011)
PART II
Best Practices
CHAPTER 7
Deploying Data Warehouses on the Oracle Exadata Database Machine
When Oracle first launched the Oracle Exadata Database Machine, it was aimed only at the broad solution area defined as data warehousing. The reason why the initial focus was on data warehousing was simple. Predesigned hardware configurations are well accepted in the data warehousing market and were available from many of Oracle’s competitors. Over the past decade, they have evolved from providing merely balanced server and storage configurations containing fast interconnects to delivering hardware-specific optimizations for typical data warehousing workloads.
Although Oracle’s entry into this arena of providing integrated hardware and software solutions is relatively recent, Oracle is not new to providing data warehousing solutions. In fact, information technology analysts generally agree that Oracle has provided the leading database for data warehousing for many years. Oracle began to introduce key optimization techniques for data warehousing in its database more than 20 years ago. For many organizations, these database optimization techniques provided solutions to their business needs while delivering the solutions on a familiar database engine that was also deployed elsewhere in their organization for transaction-processing applications. However, growing data volumes and workload demands would sometimes tax the capabilities of Oracle-based data warehousing solutions designed around optimization provided by just the database software. Even more challenging, many data warehouses were deployed without careful consideration of the impact of storage throughput needed to deliver the required query response time at the server(s).
In this chapter, we’ll give you a complete view of data warehousing considerations when deploying the Oracle Exadata Database Machine. We’ll start with a basic definition of data warehousing and a description of common topologies. We’ll then review some of the key features in the Oracle database that enable better reporting and ad hoc query performance, some of which were covered in more detail in Chapter 2. Since another desired capability of data warehousing is analytics, including trending and forecasting and predictive analysis through data mining, we’ll also cover how the Oracle database supports those workloads.
After covering generic Oracle data warehousing topics, we’ll discuss specific capabilities that are unique to the Oracle Exadata Database Machine and Exadata Storage Servers. We’ll cover unique optimization techniques and the role of Hybrid Columnar Compression. We’ll then describe how the generic features and special features for this platform work together to provide great performance in solving a query. We’ll also point out some of the best practices for data loading, partitioning, and backing up data specific to data warehousing. Finally, we’ll cover surrounding business intelligence tools, data models, security considerations, and how to justify purchase of the Oracle Exadata Database Machine for your data warehousing project.
Data Warehousing Basics
A data warehouse can be defined as providing a repository of trusted historical data in a form especially useful and optimized for reporting and performing ad hoc queries and analyses. Examples of analyses include trending, forecasting, and mathematical modeling where outcomes are influenced by a complex set of variables. A data warehousing system differs from an online transaction processing (OLTP) system, in that the data held in the data warehouse is nonvolatile and generally retained for long periods. The data is cleansed of errors and duplication during an extraction, transformation, and loading (ETL) process. The data warehouse sometimes incorporates sources of data outside of the company or organization to augment internal data sources.
Data warehousing has its roots in what were once called decision support systems that gained popularity in the late 1970s. While OLTP systems predate this concept, the initial design point of transaction processing systems is to provide a repository for current and frequently updated data. As a result, the primary focus of OLTP systems is to report on the current business situation. But as organizations gather more and more data, business strategists envision new usages of such data to better understand historical business trends and predict future trends and business results. Thus was born the need for a separate repository flexible enough to handle this rather different workload with the ability to grow and support extremely large amounts of data.
Initially, the schema (the collection of tables, views, indexes, and synonyms) was most often deployed with third normal form design for a data warehouse, the same type of schema design used for OLTP databases. In such a schema, tables contain only detailed data, stored only once, and nonprimary attributes are linked among tables using foreign keys. Figure 7-1 illustrates such a schema containing customer, order, product, and shipping information. The third normal form schema is ideal where the goal is to provide fast and frequent updates. For enterprise data warehouses that provide a gathering point for data from many sources, such a schema can align with business needs when the IT organization is prepared to build business intelligence reports (since IT is most adept at understanding such an irregular data model). Bill Inmon is most associated with this approach and has long described the benefits of the enterprise data warehouse. However, if the goal is to have a schema that enables more of a self-service reporting and query experience for business analysts and users, then either the IT organization must build views to help the analysts navigate the schema or another schema choice must be made.
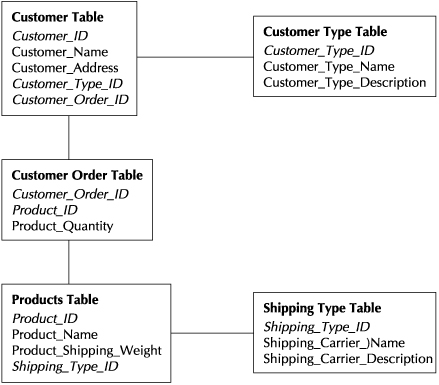
FIGURE 7-1. Third normal form schema
Ralph Kimball is largely credited with introducing a compelling alternative, the star schema. The schema might best be described as a large transaction or fact table that is surrounded by multiple dimension or look-up tables, where time is almost always one of the dimensions. The schema often evolves into a variation of a star, where dimension tables are further normalized and broken into multiple tables. That variation is called a snowflake schema. Figure 7-2 illustrates a snowflake schema as the customer dimension has been further normalized.
Dimension tables consist of multiple levels in the form of a hierarchy. So a time dimension might include fiscal years, months, and days, for example. Though the list is endless, a few examples of other commonly seen dimension hierarchies include products, geographic regions, channels, promotions, shipments, and human resources organizational structures.
The consistent form and support of this schema by business intelligence ad hoc query tools enables self-service queries and reporting. Using our schema illustrated in Figure 7-2, a typical query might be, “Show me how many overnight shipments I made of a certain product in the northeast region over the past six months.” Another query could be, “What discount levels are associated with deals for products that were shipped overnight over the past six months?”
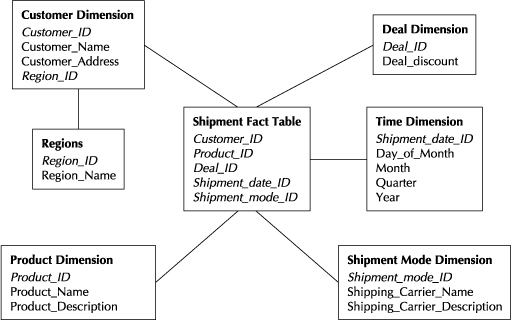
FIGURE 7-2. Snowflake variation of star schema
As star schemas became popular, they were most often deployed outside of the enterprise data warehouse as data marts. Data marts might be deployed in lines of business to address the business needs specific to those portions of the business. Where efforts are well coordinated among lines of business and IT, the data marts remain “dependent” on data definitions established in the enterprise data warehouse. When established separately instead as “independent” data marts where data definitions vary, organizations often face dealing with multiple versions of the truth (e.g., the same query in different departments using different data marts would generate different results). Figure 7-3 illustrates a classical topology, including source systems, data warehouses and data marts, and business intelligence tools.
The difficulty and expense in keeping data marts and enterprise data warehouses aligned and maintaining them as separate entities led many data warehouse architects to consider a “hybrid” approach. Data marts consisting of a star schema are embedded in the enterprise data warehouse in a hybrid. As database optimizers such as Oracle’s became more sophisticated, such hybrids became more practical. Oracle further expanded the hybrid model by introducing the ability to embed Oracle OLAP multidimensional cubes in the relational database.
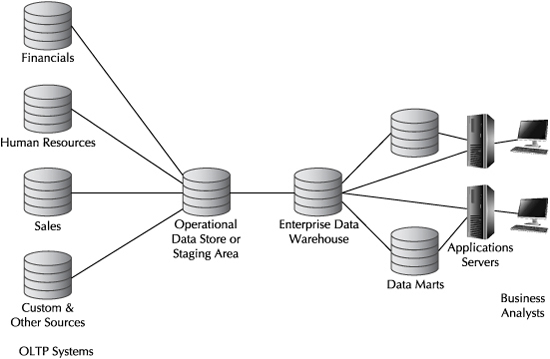
FIGURE 7-3. Classic data warehouse topology
The Oracle Exadata Database Machine is often considered when organizations evaluate a platform to serve as an enterprise data warehouse (typically where a platform such as Teradata might also be under consideration) or where the platform serves as a high-performance data mart (typically where platforms such as those provided by IBM / Netezza or Microsoft might also be under consideration). Given the sophistication of the platform, many Oracle data warehousing implementations on the Oracle Exadata Database Machine contain consolidated data marts and warehouses. Consolidation can take several forms, including the hosting of multiple data warehouses and data marts in separate databases or merging data marts and the enterprise data warehouse into a single hybrid data warehouse database. Figure 7-4 serves to illustrate such possibilities, where the Oracle Exadata Database Machine is represented by the gray shading in the figure. In addition to providing a more manageable and cost-effective deployment model, consolidation efforts are sometimes put in place to eliminate the need for federated queries that attempt to assemble very large result sets returned across relatively slow network connections. We cover consolidation considerations in a separate chapter in this book.
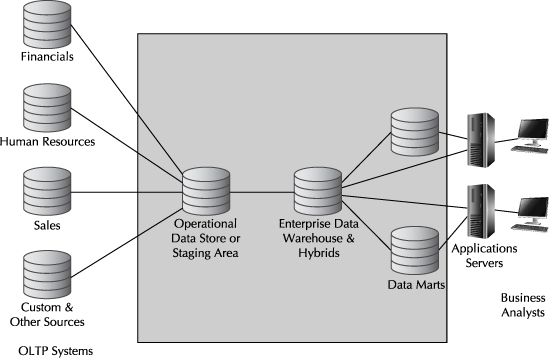
FIGURE 7-4. Oracle Exadata Database Machine roles in data warehouse topology
Before we get into the specifics of the Oracle Exadata Database Machine, we will next look at some of the key Oracle database data warehousing features that are available anywhere that the Oracle database runs. These features will play an important part in your Oracle Exadata Database Machine deployment strategy as well.
Generic Oracle Query Optimization
Oracle first began to put special emphasis on the support of data warehousing workloads with the introduction of Oracle7 in the early 1990s. At that time, most Oracle databases were deployed with a database optimizer that was rules-based. Essentially, the database administrators (DBAs) influenced the rules that would be applied when SQL was submitted. Of course, the most interesting queries submitted to a data warehouse by business analysts are usually of an ad hoc nature. Recognizing the manpower, expertise, and planning needed in the rules-based approach, Oracle embarked on evolving the database that would instead use a cost-based optimizer to solve queries, where the database estimated the costs, in terms of CPU and I/O, of different potential execution paths. Over time, the cost-based optimizer replaced any need for rules-based techniques.
One of the first data warehousing-specific features introduced to the Oracle database was static bitmap indexes in Oracle7. Static bitmap indexes are useful to represent data of low cardinality (e.g., having relatively few variations in comparison to the number of rows). The data is stored in bitmaps, with a “1” indicating that a value is present and a “0” indicating that the value is not present. In cost-based optimization, bit-wise operations take place that provide extremely fast joins. A side benefit is the reduced storage required for bitmaps.
Oracle7 also was the first version in which the optimizer recognized a star schema and optimized the solving of a query against such a schema. Initially, the optimizer used only Cartesian product joins to solve the query, first generating Cartesian products for the dimension tables, then doing a single join back to the fact table to speed performance. In Oracle8, the optimizer added more advanced techniques to be used where the number of dimensions was quite large or data within such tables was found to be sparse. Star query optimization typically occurs today on such schemas where a bitmap index is created on the foreign key column in the fact table and the Oracle database initialization parameter STAR_TRANSFORMATION_ENABLED is set to TRUE.
Of course, many queries are submitted by business analysts that return answer sets containing subtotals or summaries of detailed data. For example, a query might be issued to return results of shipments by region over the past six months against the schema illustrated earlier in Figure 7-2. For those sorts of queries that can rely on summary data (such as regions in our example schema), Oracle introduced materialized views in Oracle8i. Essentially, materialized views are physical tables in the Oracle database containing the aggregated or summary-level data, so regions might be deployed in materialized views. A faster answer to the query occurs because the query is transparently redirected to the aggregated data table and detailed data does not need to be scanned to provide the answer. Over subsequent releases of the Oracle database, the optimizer made better use of materialized views so that today, they can be joined even where they don’t align at exactly the same levels of detail. The creation of materialized views also became much more automated since Oracle’s Automatic Database Diagnostics Monitor can make recommendations as to where materialized views are useful, the materialized views advisor in Oracle Enterprise Manager can recommend their creation, and DBAs can simply respond positively to the recommendation to create them.
An additional database feature, the Oracle database Partitioning Option, is more often associated with effective Oracle data warehouse management. We will describe its importance in enabling an effective loading and backup strategy in a few sections. But the Oracle Partitioning Option also has important implications for query optimization.
The Oracle Partitioning Option is used simply to separate the database into smaller sets of data, using ranges, hashes, or other means of distributing the data. The most popular strategies for using the Partitioning Option are to manage the database based on a range of dates, or a range of values, or a composite mix of the two. However, since many queries also often map to specific date ranges or values when determining results, the Oracle optimizer is smart enough to direct queries to only the partitions that contain results. Thus, the Partitioning Option is often used as part of a performance optimization approach for large-scale data warehousing where hundreds of such partitions might exist. Query results are much faster, since large numbers of partitions that are outside the bounds of ranges that contain data needed to answer the query are avoided. A Partition Advisor in the SQL Access Advisor can recommend table, index, and materialized views partitioning strategies for optimal query performance.
Let’s look again at our schema example in Figure 7-2, assuming that the shipment fact table has been partitioned by shipment dates. If we query the database and seek shipments between specific date ranges, the query optimizer will only explore the relevant partitions that can contain query answers when assembling the results set. Figure 7-5 illustrates this concept for a query that seeks the products shipped to the northeast region from October 1 through November 30, 2010. Only the October 2010 and November 2010 partitions are explored.
Query performance can be improved even more by enabling the usage of partition-wise joins. This optimization technique minimizes the data exchanged among parallel execution servers when joins execute in parallel. If both tables are equally partitioned on their join keys, a full partition-wise join will occur. If only one table is partitioned on the join key, the Oracle database optimizer can choose to dynamically repartition the second table based on the first and perform what is called a partial partition-wise join.
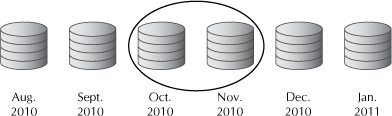
FIGURE 7-5. Partition elimination optimization based on dates in a query
Embedded Analytics in Oracle
Advanced optimization techniques in the database optimizer can speed query results. But data warehousing is about more than simple ad hoc queries. More advanced statistics, trending and forecasting, and modeling through data mining can be useful when fully trying to understand what is happening in the business and what will happen in the future. These types of analyses often deal with large quantities of data. To speed performance, you can execute these analyses in the database where the data lives.
Embedded analytics in the Oracle database provide everything from basic statistics to OLAP to data mining. In this section, we’ll cover these three topics. As with many of Oracle’s advanced features, these were introduced and improved over a series of Oracle database releases.
SQL Aggregation and Analytics Extensions
Basic statistical and analytic functions are provided as extensions to Oracle database SQL, including extensions that follow the International Standards Organization (ISO) 1999 standards. Other extensions are also present that provide functionality beyond what the standards addressed. Oracle first started to extend SQL for analytics by adding basic CUBE and ROLLUP extensions to GROUP BY functions in Oracle8i. Such aggregation extensions are used to improve the performance of the data warehouse. Today, the SQL aggregation extensions also include GROUPING functions and the GROUP SETs expression, as well as pivoting operations.
The database also provides a host of SQL analytics covering analysis, reporting, and other types of calculations and clauses. Examples of these extensions include ranking functions, windowing functions, reporting functions, LAG/LEAD functions, FIRST/LAST functions, linear regression functions, inverse percentiles, hypothetical rank and distribution, and a useful MODEL clause for multidimensional data. Table 7-1 briefly describes what each is used for.
OLAP
When trying to better understand the future of the business by analyzing trends and preparing forecasts, OLAP solutions often enter the picture to provide faster resolution of queries and provide additional advanced analysis techniques. Oracle offers two different multidimensional OLAP (MOLAP) engines most applicable for different situations and used for storing “cubes.” The cube terminology is somewhat a misnomer, as multidimensional objects frequently contain more than three dimensions, but long ago gained popularity for describing these objects.

TABLE 7-1. Oracle SQL Analytic Functions
One of the engines Oracle offers is Essbase, a MOLAP database engine that is external to the Oracle relational database (and therefore is deployed outside of the Oracle Exadata Database Machine). Essbase is especially useful where business analysts want to extract data from Oracle and other data sources for custom analyses of their own design. But in some situations, data volumes can be so large that moving data out of an Oracle database across a network link and into Essbase is not desirable. In these scenarios, deploying in-database OLAP can make sense as an alternative approach.
Oracle provides in-database OLAP via the Oracle OLAP Option. OLAP cubes are stored as embedded objects called analytic workspaces within the relational structure of the Oracle database. The cubes are created by defining dimensions, levels, and hierarchies within dimensions, attributes, and mappings from relational source schema to the OLAP cube dimensions. Cubes and other dimensional objects appear in the Oracle database data dictionary. Oracle’s Analytic Workspace Manager (AWM) is commonly used as the tool for creating and managing this process as an alternative to using SQL commands. AWM can also be used to set up and populate allocations of data down a hierarchy.
Access to the OLAP Option analytic workspace data structures is most commonly via SQL, though a Java OLAP application programming interface (API) is also supported for applications development. A variety of functions are available within the OLAP Option, including analytic functions, arithmetic functions, aggregations, statistical time-series, and allocations. Forecasts can be generated for short periods using a timeseries approach and for longer periods by doing causal analysis using statistical regression.
As of Oracle Database 11g, cube-based materialized views provide views over the cubes that have already been created, populated, and aggregated. As a result, SQL queries to an Oracle relational database will be transparently redirected to the proper level in the OLAP Option cube to answer a query, much the same as would occur where any materialized view is present. Cube-based materialized views also enable OLAP Option cube data refreshes to be handled like those of any materialized views. The OLAP Option can provide a highly desirable and simpler alternative database structure in comparison to maintaining large quantities of materialized views across many dimensions in an Oracle relational database.
Data Mining
Data mining addresses the problem of how to analyze the likelihood of observed outcomes when there are too many variables to easily understand the driving factors. Typically, organizations build and deploy mathematical models based on the algorithm that best predicts when such very good or very bad outcomes are likely to occur. Example applications might include fraud detection, churn analysis, cross-sell effectiveness, threat detection, and a host of others. The designers of the models are usually among the most advanced statisticians and analysts within an organization. One emerging trend is the embedding of such data mining models into applications to make the sophistication of them transparent and available to a much wider group of business analysts.
A variety of data mining algorithms are provided in the Oracle Data Mining Option to address different business problems, since predicting their outcomes will likely align with a specific algorithm. For example, clustering algorithms are ideal when segmenting groups; classification algorithms are commonly used to predict response; regression is used when estimating values; feature extraction is used to create new but fewer attributes that represent the same information; attribute importance identifies key predictors of outcomes; associations are used to find groups of items with affinity to each other; and anomaly detection identifies rare situations and events. Table 7-2indicates the specific data mining algorithms available in the Oracle database and when these data mining techniques are required.
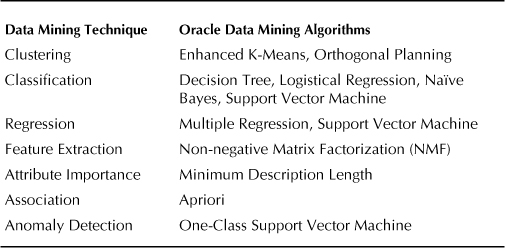
TABLE 7-2. Data Mining Techniques and Oracle Data Mining Algorithms
When developing a data mining analysis workflow, Oracle’s Data Miner tool is used for data exploration, data preparation, determining the appropriate Oracle Data Mining model, and model scoring. Data mining steps are outlined using Data Miner’s graphical interface, and PL/SQL can then be generated to create data mining applications. For analysts that instead would prefer to use the R language (an open-source offering that is part of the GNU project and also features a runtime environment with graphics and a debugger), there is an Oracle Data Mining Option interface.
Unique Exadata Features for Optimal Query Response
Thus far, we described Oracle data warehousing features that are available for any server and storage platform that Oracle supports. The Oracle Exadata Database Machine with Exadata storage provides additional optimization techniques that are unique to this platform. Exadata consists of a storage hardware solution, previously described in this book, and Oracle Exadata Storage Server Software, whose features were covered in Chapter 3. Though the Oracle Exadata Storage Server Software enables storage-specific optimization, the optimization is handled under the covers of the Oracle database so it is transparent to SQL queries.
Much of the early focus of the Oracle Exadata Storage Server Software was to provide optimization for data warehousing. Oracle continues to roll out additional data warehousing optimizations with each release of the Oracle Database and Exadata Storage Server Software. For example, with the Oracle Database 11g Release 1 (version 11.1.0.7), the corresponding Oracle Exadata Storage Server Software introduced Smart Scans, row filtering based on a “where” predicate, join filtering, and incremental backup filtering. The Oracle Exadata Storage Server Software introduced with Oracle Database 11g Release 2 added storage indexing, support for scans on encrypted data, data mining model scoring, support for the Smart Flash Cache, and Hybrid Columnar Compression. Oracle Database 11g Release 2 introduced the Database File System (DBFS).
To give you an appreciation of Smart Scans, let’s first look at a simplified version of how Oracle handles SQL queries on a non-Exadata system. Where Oracle is deployed on non-Exadata systems, when a SQL query is executed, the database server will identify table extents and issue I/Os to storage.
If there is not a match of indexes that identify query results, a full table scan occurs. When dealing with large data warehouse tables, a large volume of data could be sent to the database server, where subsequent determination of the query results occurs prior to returning the results to the business analyst. Return of such large data volumes from storage to database server nodes through limited bandwidth is the reason that many poorly performing Oracle data warehouses are said to be throughput-bound.
In comparison, where Exadata storage is present and Smart Scans are used, the database server kernel is “Exadata aware.” In reality, there is constant modulation between database processes and the Exadata Storage Server cells, but to provide you with a simplified explanation and diagram, we show an iDB command sent to the Exadata Storage Server cells in Figure 7-6. A CELLSRV process in the Oracle Exadata Storage Server Software scans data blocks in each cell into memory and identifies only the rows and columns that provide valid results for the query. These results are returned from the Exadata Storage Server cells to the database server nodes in a constant flow of data that matches the predicates. There, the database consolidates the results and returns them to the client. This technique has been described by some as a hybrid approach to solving queries, using a shared nothing technique in the Exadata Storage Server cells in combination with the Oracle database server’s shared disk approach.
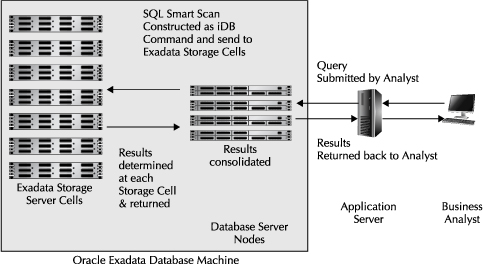
FIGURE 7-6. Smart scans
The presence of Smart Scans and the usage of these techniques enabled by the Exadata Storage Server Software can be observed in Explain Plans. Smart Scans are designed to provide predicate filtering and column projection. Bloom filters are constructed to provide join filtering in storage between large tables and small lookup tables (common in star schemas where fact tables are surrounded by dimension tables). Smart Scans also deal transparently with other Oracle database internal mechanisms and optimization techniques, as we’ll describe in a subsequent section.
A couple of key management tasks for large-scale data warehouses are also much faster because of the Oracle Exadata Storage Server Software. Incremental database backups are much faster because changes are tracked at the individual Oracle block level. The CREATE TABLESPACE command can appear to be nearly instantaneous, as an InfiniBand iDB protocol command is sent directly to the Exadata Storage Server cells to create a tablespace and format blocks, instead of using the database CPUs for the formatting of these blocks before being written to storage.
Transparent creation and maintenance of storage indexes by the Oracle Exadata Storage Server Software was released with the introduction of Oracle Database 11 g Release 2. Maintained in the Exadata Storage Server cell’s memory, the storage index tracks minimum and maximum values for eight columns within each MB storage region in the cell. For queries that include a WHERE clause, the Oracle Exadata Storage Server Software will determine whether there are any appropriate rows contained between the minimum and maximum values in-memory, eliminating I/Os if there are not.
The Oracle Exadata Storage Server Software in this release also added offload processing to Exadata Storage Servers in Smart Scans against encrypted tablespaces and columns and offloading of data model scoring. Of course, such offloading provides significant performance gains. For mathematical and data mining functions that tend to be CPU-intensive, it is noteworthy that there are actually more CPUs and processing power in the Exadata Storage Server cells than in the Oracle database server nodes in a Oracle Exadata Database Machine configuration. More than 300 of the mathematical and analytic functions supported in the Oracle database are processed within Exadata storage.
Support of the Exadata Smart Flash Cache was also introduced with this release of the Oracle Exadata Storage Server Software and the Sun Oracle Database Machine. The Oracle Exadata Storage Server Software will cache frequently accessed data by default. However, the data returned by the full table scans common in data warehouses are not, by default, placed in the Flash Cache. In these scenarios, you can override the default by specifying the attribute “CELL_FLASH_CACHE KEEP” in the object definition or an ALTER statement for such an object. In fact, data could be read from both the cache and disk at the same time, achieving higher aggregate throughput.
Data Warehousing Compression Techniques
We discussed compression techniques available in the Oracle database in Chapters 2 and 3. Here, we’ll focus on the role of compression when deploying a data warehouse, primarily used for reducing required storage and improving performance (since I/O is reduced when retrieving data). The types of compression often used for data warehousing are the basic compression included with the Oracle database; the Advanced Compression Option, used where there are frequent updates; and Hybrid Columnar Compression.
The basic compression and Advanced Compression Option provide row-based compression techniques. Typically providing compression ratios of two to four times, the Advanced Compression Option is often more associated with OLTP since it can also handle frequent updates of data. But use cases for data warehouses in some business processes are known to require updates to data on a frequent basis, even data that might reside in very old partitions. In such situations, Advanced Compression can be the optimal choice.
Hybrid Columnar Compression is included as part of the Oracle Exadata Storage Server Software and so is available only for Oracle Exadata Database Machines. It is designed to be used where the data is read-only and can deliver compression ratios that reach ten times or more. Hybrid Columnar Compression combines the benefits of compressing repeating columnar values (and other techniques) within the row-based Oracle database.
Where Hybrid Columnar Compression is used, data is loaded using bulk loading techniques (e.g., INSERT statements with the APPEND hint, parallel DML, SQL*Loader, and Create Table as Select). When the data is loaded, column values are stored separately from the rows as compression units. When a Smart Scan occurs, column projection, filtering, and decompression occurs in the Exadata Storage Server cells, as is normally the case when Smart Scans of compressed data occur. Data required to satisfy query predicates is not decompressed. Only the columns and rows to be returned to the client are decompressed in memory.
As Hybrid Columnar Compression provides choices in query and archival compression algorithms, you can balance your compression needs versus performance requirements. For example, query compression is designed for optimal I/O scan performance and has two settings: HIGH compression (by default) and LOW compression. HIGH compression typically provides about ten times the compression, whereas LOW compression typically provides only about six times the compression but with better load times. Archive compression is designed for optimal storage of infrequently accessed data with typical compression ratios of up to 15 times. But the tradeoff of using archive compression is diminished query performance when compared to warehouse compression.
The type of compression you will choose (basic, Advanced, or Hybrid Columnar) will depend on the frequency of updates and whether you want to optimize for query performance or storage savings. A common technique used in large-scale data warehousing is to apply Oracle’s compression techniques most appropriate for read-only data only on older database partitions that are less likely to be updated and apply an Information Lifecycle Management (ILM) strategy. Hybrid Columnar Compression is often deployed on such older partitions where HIGH compression is used.
The Typical Life of a Query
When the Oracle database executes a query on the Oracle Exadata Database Machine, it will use a combination of optimizations traditionally provided by the Oracle database and optimizations that are specific to the Oracle Exadata Database Machine and Oracle Exadata Storage Server Software. So, as we illustrate the typical life of a query, we take into account several of the optimizations that we have already covered in this chapter.
In our example, the Oracle data warehouse contains seven years of customer data and requires 50TB of storage space to contain the data. The data in the database columns contains a significant number of repeating values. The data is partitioned in composite partitions by geographic region and date. A business analyst submits a query to obtain results that will show sales to customers who purchased over $100,000 in products during the first quarter of the year over the past three years in the northeast region.
Using Hybrid Columnar Compression for warehouse compression, the amount of storage required for user data in the entire data warehouse is reduced from 50TB to 10TB in our example. Since the data is partitioned, when the query is executed, only partitions containing data from the first quarter during the past three years is touched. This reduces the volume of data that is considered to about 2TB. In this stage of solving the query, the Exadata Smart Flash Cache might come into play if any of the partitions were pinned into cache.
Next, a Smart Scan occurs and storage indexes reduce the volume of data to just that where customers have purchased over $100,000. In this example, only about a few dozen rows of results data is obtained from the Exadata Storage Server cells. If some of the data was encrypted, before the Smart Scan is executed, the Oracle Exadata Storage Server Software will first decrypt that data and then it will be expanded as this constant data flow matches the predicates.
Taken together, the amount of query performance speed-up can greatly exceed ten times or more what might be possible on a non-Exadata system. Your performance speed-up will vary due to the number of factors that can come into play, and also will be dependent on how balanced (or unbalanced) the current server and storage platform you are comparing the Oracle Exadata Database Machine to is.
Best Practices for Data Loading
The approach you should take for data loading will depend on a number of factors, including the cleanliness of the source data, the volume of data to be loaded, and how quickly the data must be available in the data warehouse to business analysts. The Oracle database supports loading of data from external tables and via SQL*Loader, using transportable tablespaces to move data from one Oracle database to another, import and export mechanisms such as Oracle Data Pump, and insertion of individual records using database links to other Oracle databases or connectivity to other sources using gateways, ODBC connections, or Java Database Connectivity (JDBC) connections.
Oracle has tools that can aid in this process, including the ETL tools in the Oracle Data Integrator (ODI) Suite—Oracle Data Integrator and Oracle Warehouse Builder. Both of these tools push transformation and load processing into the target Oracle database for better performance. Where source data is clean and does not need extensive transformations, Oracle’s GoldenGate can provide lighter-weight, near-real-time, simple data extraction and loading to the target Oracle database as data in the sources change.
Where large data volumes are going to be moved, as is typical in database loads where complex data transformations are necessary, a staging area is commonly established to store flat files prior to loading the database. The Oracle database features a DBFS that can be used for this purpose and enables the Oracle database to be used as an IEEE POSIX-standards compatible file system. Consisting of a PL/SQL package on the server and a Linux DBFS client, the combination enables files to be accessed easily by database applications and file-based tools to access the files stored in the database. DBFS is a distributed file system where files are stored as SecureFiles LOBs. The DBFS client is used to mount the file system with “direct_io” set where moving raw files. DBFS should reside in its own database, not in the data warehouse database.
If complex transformations are to occur in the target data warehouse database, an additional staging layer is sometimes set up to avoid impact on business analysts as these transformations are in progress. The speed of loading is, of course, directly affected by the number and speed of the CPUs used during the loading process. To do this effectively, Oracle must be able to look inside raw data files and determine where rows of data begin and end. For that reason, where performance is a key consideration, data is typically loaded as uncompressed, and partitions might later be compressed as they age.
The use of external tables is now recommended where you are loading from flat files. External tables allow transparent parallelization within the Oracle database, applying transformations via SQL and PL/SQL, precluding the need for a staging layer, and providing more efficient space management (especially with partitioned tables) when parallelizing loads. External tables are described using the CREATE TABLE syntax. Loading data from an external table is via a CREATE TABLE AS SELECT (CTAS) or INSERT AS SELECT (IAS) statement.
By default, a CTAS statement will use direct path loading, key to good loading performance, since database blocks are created and written directly to the target database during direct path loading and the loads can be run in parallel server processes. The IAS statement will also use direct path loading where you provide an APPEND hint. A direct path load parses the input data according to the description given in the external table definition, converts the data for each input field to its corresponding Oracle data type, and then builds a column array structure for the data. These column array structures are used to format Oracle data blocks and build index keys. The newly formatted database blocks are then written directly to the database, bypassing the standard SQL processing engine and the database buffer cache.
Since large-scale data warehouses are usually partitioned based on ranges or discrete values, another complementary technique often used during this loading process is the EXCHANGE PARTITION command. The EXCHANGE PARTITION command allows you to swap the data in a nonpartitioned table into a particular partition in your partitioned table. The command does not physically move data. Instead, it updates the data dictionary to exchange a pointer from the partition to the table and vice versa. Because there is no physical movement of data, an exchange does not generate redo and undo, making it a subsecond operation and far less likely to affect performance than any traditional data-movement approaches such as INSERT.
Partitioning, Backups, and High Availability in Data Warehouses
Backup and high availability strategies are important in large-scale data warehousing where the warehouses are used for tactical business decisions, as they are in other enterprise databases. A sound backup strategy for data in the data warehouse is critical to making such a warehouse recoverable in a reasonable amount of time. Reloads from source systems and re-creating complex data transformations that occurred over time are an impractical approach to recovery. However, even where backups are efficiently taken, the reload process might be too lengthy to meet business service-level requirements. In such scenarios, providing high availability by deploying and maintaining both primary and secondary data warehouses can be justified.
While we cover high availability strategies in Chapter 2, some considerations are especially relevant where a large-scale data warehouse is deployed. Part of a sound backup strategy for a data warehouse includes careful consideration of how data changes over time. Where the data warehouse contains very large data volumes, older data might not be undergoing updates. Where this situation exists, the Partitioning Option of the Oracle database can fulfill an important role in creating a more manageable backup scenario. As mentioned earlier in this chapter, data warehouses are often partitioned based on date ranges. A common backup strategy for any database is to provide ongoing backups frequently enough to capture critical updates that might have occurred that can affect business decisions. In a data warehouse, partitioning can separate data that is being updated from stagnant data. Older data that is nonchanging (read only) can be terabytes or tens of terabytes in size in such large-scale data warehouses and would not need to be backed up going forward if that data is held in separate partitions. For example, in Figure 7-5, if the August and September 2010 partitions contain nonchanging data, once they are backed up, no further backups are needed.
In some organizations, old data might be restated on an ongoing basis because of how business occurs. In others, tactical near-real-time business management using the data warehouse means that nonavailability of the system will not be tolerated during a system failure and subsequent reload process. Such scenarios will force you to create a highly available backup system containing a duplicate copy of the data. Oracle Data Guard can be used to maintain consistency between a primary and secondary site. Reporting can take place from the secondary site even while updates are occurring. An alternative to the Data Guard approach used in some organizations is to fork ETL processes from source systems simultaneously to primary and secondary locations. Generally where either method is used, the standby or backup system is configured identically to the primary (e.g., the same Oracle Exadata Database Machine configuration is used for both sites) to assure the same levels of performance in solving queries if the primary system fails.
Data Models, Business Intelligence Tools, and Security
An effective data warehouse deployment includes more than just the Oracle database and Oracle Exadata Database Machine. Also key to overall success are the quality of the data models, business intelligence tools, and the security mechanisms that are put into place.
Data models provide definitions and schemas that contain the data elements aligned to key performance indicators tracked by business analysts. Logical data models provide the data definitions and entity relationships among objects. The logical models are then translated into deployable physical data models designed to take advantage of the Oracle database’s capabilities. Logical entities are generally mapped into tables in the physical data models; relationships are mapped into foreign key constraints; attributes are mapped into columns; primary unique identifiers are mapped into primary key constraints; and unique identifiers are mapped into unique key constraints. The schemas for the physical data models are of the types described earlier in this chapter.
Business intelligence tools provide a means for business analysts to access data residing in the data warehouse. Reporting, ad hoc query, and advanced analytics are delivered to the analysts through these dashboards and tools. The dashboards and tools are designed to be of a self-service nature when underlying data models in the data warehouse are properly aligned with business needs.
Security considerations come into play because of the value of the data and information available in the data warehouse and the broad user communities that can have access to it. Security features are used to restrict access to data on a need-to-know basis. They can be used to track who had access to data during specific periods.
We’ll next go into a bit more detail regarding data models, business intelligence tools, and security and describe how each would fit in an Oracle Exadata Database Machine data warehousing deployment strategy.
Data Models
Until the past decade, developing physical data models for large-scale Oracle data warehouses was largely undertaken from the ground up by IT organizations or consulting services companies. Today, Oracle and a number of Oracle’s partners have physical data models that are extremely useful in solving problems and serve as starting points in deployment. While many businesses and organizations start with such standard data models, most will customize them to reflect their own unique needs and strategies. Of course, these models can be deployed as schema in the database or databases on the Oracle Exadata Database Machine.
Examples of Oracle’s physical data models for industries include data models in communications, finance, healthcare, retail, and utilities. The models range in schema type from completely third normal form for enterprise data warehouse solutions to “analytics” models that resemble star schemas more aligned for business intelligence self-discovery. In some industries, Oracle offers complementary models that address both sets of needs.
Oracle also has horizontal Oracle Business Intelligence Applications that address areas such as sales, marketing, service and contact centers, pricing, loyalty, financials, procurement and spend, supply chain and order management, projects, and human resources. The horizontal models are star schemas with conformed (common) dimensions that enable queries across the various models. The Business Intelligence Applications also come with prebuilt ETL available for sources such as Oracle’s own suite of enterprise resource planning (ERP) applications and Siebel CRM.
Business Intelligence Tools
Business intelligence tools commonly generate SQL statements to the data warehouse database when queries are submitted and reports are to be populated with results. Given the transparency provided in Exadata optimizations, all of the major business intelligence tools vendors and opensource providers that support the current version of the Oracle database can support the Oracle Exadata Database Machine.
Oracle Business Intelligence Enterprise Edition (OBIEE) is one such set of business analyst tools, providing dashboards, reporting capabilities, ad hoc query capabilities, and action frameworks for automating business processes. These tools are deployed using applications server platforms that are configured to support Business Intelligence (BI) Server workloads. So this part of the infrastructure does not reside on the Oracle Exadata Database Machine, but instead resides on separate servers deployed around it. Figure 7-7 illustrates the ability of OBIEE 11 g to drill into hierarchies as defined in the subject areas in the figure. These hierarchies could be stored as relational OLAP in the Oracle database or as MOLAP cubes.
In addition to standard relational data types, the Oracle database is capable of storing other data types, including spatial. Spatial data can be useful when determining and displaying query results that include geographic information. OBIEE 11g supports map views that are used to display data containing longitude and latitude information (geocodes) on maps.
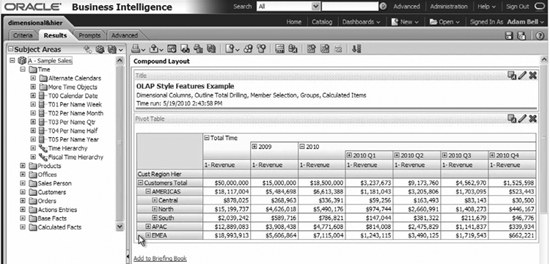
FIGURE 7-7. OBIEE 11g ad hoc query interface
The Oracle database contains a unique schema (named MDSYS) that denotes storage, syntax, and semantics of supported geometric data types; spatial indexing functions; and operators, functions, and procedures for “area of interest” queries. The Oracle Exadata Database Machine has demonstrated excellent performance speed-up in handling queries of spatial data, given the mathematical nature of resolving such queries and the number of mathematical functions handled in Exadata storage.
Oracle’s industry vertical and horizontal business intelligence analytics development teams are continuing to build reporting engines and dashboards using OBIEE for use with their data models. Within the OBIEE BI Server, Oracle has what is called a “Common Enterprise Information Model.” This model consists of a presentation layer, semantic object layer, and physical layer. The presentation layer defines the interface; the semantic object layer defines dimensions, hierarchies, measures, and calculations; and the physical layer provides a mapping and connections back into the physical data models residing in the Oracle database. For Oracle’s analytics solutions, all of these layers are predefined and mapped to the data models.
Security Considerations
As business analyst communities grow and become more diverse, with members sometimes accessing data from outside the bounds of the organization that deploys the data warehouse, additional security considerations come into play. Given the usefulness of data residing in the very large data warehouses that are common on the Oracle Exadata Database Machine, the demand for such access and need for advanced security is common. For example, an organization might want to share access to data unique to a supplier or distributor with that supplier or distributor. They might want all of their suppliers and distributors to have similar access to the common data warehouse but only be able to see and work with their own detailed data. To protect who sees what, a virtual private database can be defined using a combination of the Oracle database and OBIEE. Different user communities are restricted to seeing only relevant data based on security profiles defined in the database.
Similarly, business analysts using OBIEE can be restricted from seeing certain records by deploying data masking in the database. Specific database fields might also be encrypted through database encryption to restrict access. In addition, the database might be more securely managed through the use of Database Vault (limiting DBA access to data residing in tables) and Audit Vault (to track who saw what data and when they saw it).
Sizing the Platform for Data Warehousing and Justifying Purchase
Sizing the Oracle Exadata Database Machine properly for a data warehouse implementation requires that the person performing the sizing have in-depth knowledge of current workload characteristics and future requirements, raw data storage requirements (both for current data size and planned data growth), compression techniques that might be used and their impact, and availability considerations. The last three of the aforementioned are typically well understood within an IT organization. But the current workload characteristics and future requirements are likely to be less well understood. Having knowledge of these is critical when developing a business case for purchase of the Oracle Exadata Database Machine and sizing it properly.
Data warehouses and enterprise-class platforms such as the Oracle Exadata Database Machine are usually deployed for one of two reasons—to better determine where to reduce bottom-line business costs or to increase top-line business growth. While IT management might initially want to focus on the ability to meet business Service Level Agreements or reduced IT costs by deploying this platform, this may not provide enough justification to get funding. Discussing the business analysis needs with lines-of-business communities might be thought of as difficult by some in IT. To help you along, the following questions might serve as a starting point in uncovering key business initiatives that could fund a data warehouse project on this platform:
![]() How is the data warehouse being used by the lines of business today?
How is the data warehouse being used by the lines of business today?
![]() How accessible is the current data? Is it trusted and is it available in time to make key business decisions?
How accessible is the current data? Is it trusted and is it available in time to make key business decisions?
![]() What business key performance indicators (KPIs) and data will be needed in the future? What would be the potential business value in delivery of these additional KPIs and data?
What business key performance indicators (KPIs) and data will be needed in the future? What would be the potential business value in delivery of these additional KPIs and data?
![]() What is the mix of reporting, ad hoc query, analysis, and modeling today? How might that mix change in the future?
What is the mix of reporting, ad hoc query, analysis, and modeling today? How might that mix change in the future?
![]() How might data loading characteristics change in the future?
How might data loading characteristics change in the future?
Table 7-3 lists some of the key data warehousing initiatives currently under way in selected industries that are driven by real business needs and, when linked to performance and availability criteria, can lead to an understanding of how to properly size the platform. The initiatives change over time based on changing business conditions. In shrinking economies or market segments, organizations most often focus on cost savings. In growing economies or market segments, the focus is more often on business growth. For government agencies that are typically much less influenced by economic conditions, the data warehousing initiatives tend to be about better delivery of information to sponsors and constituents to provide proof points as to the value that the agency provides.
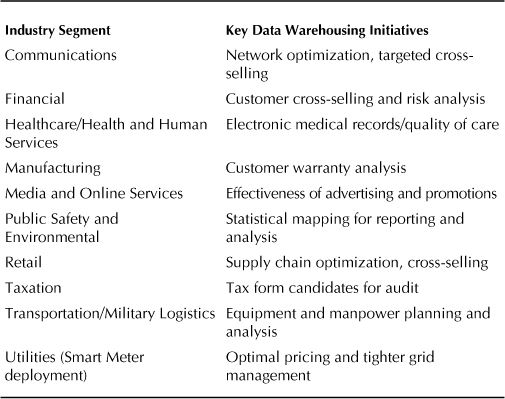
TABLE 7-3. Key Data Warehousing Initiatives in Various Industries
As an example, let’s take a look at how the purchase of an Oracle Exadata Database Machine might be justified in solving a transportation or logistics problem. In our theoretical organization, if transported items do not arrive within 24 hours of their scheduled delivery time, the value of the contents is significantly diminished due to increased risk of spoilage. Lines of business in this organization track metrics that reflect the declining value of these items. They have measured the impact of delays as reducing the price of delivered goods by $88,000 per day. Analysis used in optimizing routing of the items currently occurs only once a day and prior to shipment since queries and analyses are so complex that they take hours to run.
The manager of logistics knows that if they could run queries and analyses every hour and see results within an hour (e.g., the results will come back five to eight times faster than currently possible), they’d run their business differently. They would be able to adjust routes and schedules and to changes in demand that appear during the day. By making these adjustments, they could reduce the revaluation of these items by 75 percent and save $66,000 per day through more on-time deliveries.
Given these business metrics, the IT organization can now size the Oracle Exadata Database Machine. They will need a configuration large enough to return query results submitted by the logistics analysts in about an hour to deliver the anticipated business cost savings. Upon sizing of the Oracle Exadata Database Machine configuration, the costs for the hardware and software required, implementation, and ongoing support can be calculated. The business sponsor, CFO, and CIO can then do a simple benefit-cost analysis and determine how long it will take to achieve a return on investment. In this example, the Oracle Exadata Database Machine likely will pay for itself within months.
At this point, you might have expected to read about best practices for executing data warehousing benchmarks. The fact is, unless you have identified business drivers similar to those covered in this example, it probably doesn’t make any difference how much faster the Oracle Exadata Database Machine turns out to be in such a test. If you do decide you want to run performance tests on the platform before you make a final commitment to buying it, the criteria for a successful test should be driven by providing performance needed to deliver query and analysis results in time to make appropriate business decisions that deliver business value. Of course, you should also satisfy yourself that future deployment conditions are being simulated with the right mix of workload concurrency and database data volume that will give you confidence that your data warehouse will perform.
Summary
In this chapter, we quickly journeyed through the history of Oracle in data warehousing and provided descriptions of how the Oracle Exadata Database Machine and Oracle Exadata Storage Server Software combine to deliver functionality and performance that only a tightly integrated hardware and software solution can deliver. The flexibility of the Oracle database enables deployment of schemas appropriate for enterprise data warehouses, data marts, or hybrid combinations of these types. The Oracle Exadata Database Machine and Oracle Exadata Storage Server Software enable successful deployment of the largest and most complex configurations supporting all of these deployment models.
Given new classes of business problems that can be solved using this platform, data warehousing workloads will continue to grow more complex. Queries and analyses will be performed against ever-growing data volumes. Data loads will move toward near real-time in response to the need for faster tactical business decisions based on current information. As these loads become trickle feeds, the platform must not only perform traditional data warehousing workloads efficiently, but also exhibit excellence in performance and loading characteristics that can appear more akin to transaction processing workloads.
The Oracle Exadata Database Machine is designed to handle workloads that cross this entire spectrum of workload demands. Since the platform is balanced out-of-the box and incrementally grows in a balanced fashion, the CPUs, memory, flash, storage, and interconnect scale as workload demands grow, enabling consistent query response times to be delivered. Automatic Storage Management (ASM) provides a critical role in distributing data in a striped fashion across the disk. The Oracle Exadata Storage Server Software further speeds obtaining results to queries by processing more of the data in storage, where the data lives.
As you plan your data warehouse deployment, traditional Oracle and data warehousing best practices do apply to the Oracle Exadata Database Machine. But you will also find this platform to be a lot more forgiving and easier to manage than traditional Oracle database platforms. Of course, the business justification exercise will likely be similar to other data warehousing initiatives, but with new potential areas to explore due to new levels of performance delivered. The end result for you should be faster deployment of a platform that delivers the query response and analytics needed by your business analysts and delivers measurable business value.