Test Scoring and Analysis Using SAS (2014)
Chapter 6. Adding Special Features to the Scoring Program
Introduction
This chapter shows you how to add alternate correct answers to test items, how to rescore a test after deleting items, and how to score a test that has alternate versions. The first topic is of use when you have an item that you do not want to delete from the test but, after reviewing the item, you believe that you should accept an alternate answer to that item. Deleting items and rescoring a test is useful if your item analysis identifies one or more poor items. Finally, having alternate versions of a test (the same items but in different order) is a useful technique to discourage cheating.
Modifying the Scoring Program to Accept Alternate Correct Answers
At the Robert Wood Johnson Medical School, where one of the authors worked, a number of the professors requested that the test scoring program have the ability to accept alternate correct answers. The program discussed next demonstrates one way to allow a scoring program to accept alternate correct answers.
There are several ways to supply alternate answers to your test items. One way is to create a separate data set with each observation containing an item number and the alternate correct answers. Another way, demonstrated here, is to supply the answer key (including the alternate correct values) as the first line of the student data file. For this example, you want to accept answers b and c for item 2 and answers a, c, and d for item 6. Here is a listing of the data file:
Listing of File alternate.txt
a bd c e d acd a b e d
123456789 abcdeaabed
111111111 abcedaabed
222222222 cddabedeed
333333333 bbdddaaccd
444444444 abcedaabbb
555555555 eecedabbca
666666666 aecedaabed
777777777 dbcaaaabed
888888888 bbccdeebed
999999999 cdcdadabed
The first line of this file contains the correct answers to each of the test items—the remaining lines contain the student IDs and answers. The following program demonstrates how to include the alternate answers in the scoring process:
Program 6.1: Modifying the Scoring Program to Accept Alternate Answers
*Program to demonstrate how to process multiple correct
answers;
data alternate_correct;
infile 'c:\books\test scoring\alternate.txt' pad;
array Ans[10] $ 1 Ans1-Ans10; ***student answers;
array Key[10] $ 4 Key1-Key10; ***answer key;
array Score[10] Score1-Score10; ***score array 1=right,0=wrong;
retain Key1-Key10;
if _n_ = 1 then input (Key1-Key10)(: $4.);
input @1 ID $9.
@11 (Ans1-Ans10)($1.);
do Item=1 to 10;
if findc(Ans[Item],Key[Item],'i') then Score[Item] = 1;
else score[Item] = 0;
end;
Raw=sum(of Score1-Score10);
Percent=100*Raw / 10;
keep Ans1-Ans10 Key1-Key10 ID Raw Percent;
label ID = 'Student ID'
Raw = 'Raw Score'
Percent = 'Percent Score';
run;
If you prefer using commas instead of blanks to separate the answer key values, add the DSD option to the INFILE statement as demonstrated in Chapter 2 (Program 2.3).
Instead of storing each answer key value in a single byte, you allocate four bytes for each key value (although it would be unusual to have more than one alternate correct answer). The INPUT statement that reads the 10 key values reads up to four values and stops when it reaches a delimiter (a blank in this example). The colon in the informat list (the list in parentheses following the list containing the 10 Key variables) is the instruction not to read past the delimiter.
Comparing the answer key to the student answer is done using the FINDC function. This function searches the first argument (the student answer) for any one of the values in the corresponding answer key. The third argument (the 'i') is a modifier that tells the function to ignore case. If the student answer matches any one of the answer key values, the Score variable is set to 1; otherwise, it is set to 0. Output from this program is shown below:
Output from Program 6.1
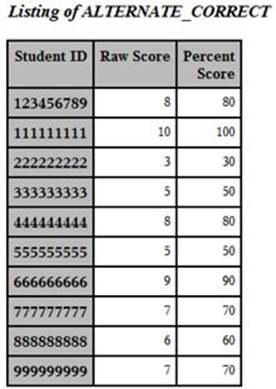
As a quick check to verify that students choosing alternate answers are getting credit, let's take a look at the responses for student 222222222. Responses for this student to the 10 items were:
222222222 1=c, 2=d, 3=d, 4=a, 5=b, 6=e, 7=d, 8=e, 9=e, 10=d
and the answer key was:
1=a, 2=bd, 3=c, 4=e, 5=d, 6=acd, 7=a, 8=b, 9=e, 10=d
Therefore, this student answered three items correctly (getting credit for items 2, 9, and 10) and received a raw score of three (Note: This student needs to study more!).
Deleting Items and Rescoring the Test
Once you have inspected your item statistics, you may decide that you want to delete some items and rescore the test. Doing this can increase the overall reliability of the test. To demonstrate this process, the statistics test used in previous examples was scored again with the answer key modified to contain an incorrect choice for the first five items on the test. This obviously affects the item statistics for these items, as well as the overall test reliability. The following output displays the item statistics (for the first few items) on this modified test:
Item Analysis for the First Few Items on the Statistics Test with a Modified Answer Key
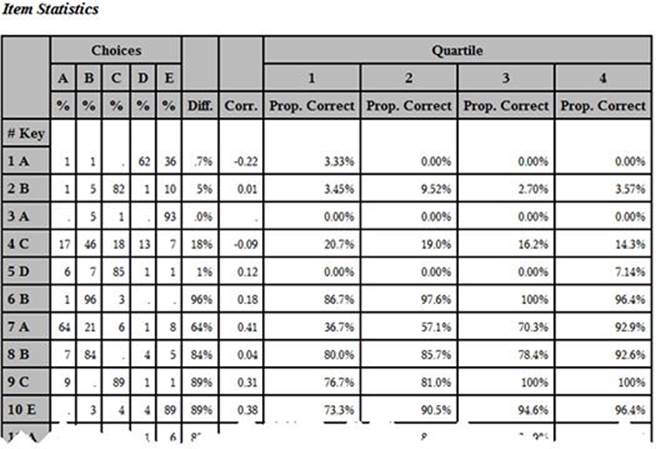
Notice that the item statistics for the first five items are quite poor.
The KR-20 reliability for the modified test (with the incorrect answer key) is .752, compared to a value of .798 on the original test (with the correct answer key). This demonstrates that including items that have low point-biserial coefficients may lower the test reliability.
You may decide to rescore this test with the first five items deleted. The following program demonstrates how to do this.
The short program that follows rescores the statistics test with the first five items deleted.
Program 6.2: Deleting Items and Rescoring the Test
%let List = 1 2 3 4 5;
data temp;
set wrong_ans_stat(keep=ID Score1-Score56);
retain Num;
*List is the list of items to delete,
Num is the number of items on the test after deletion;
array Score[56] Score1-Score56;
Num = 56;
do Item = 1 to 56;
Raw + Score[Item]*(Item not in (&List));
if Item in(&List) then Num = Num - 1;
end;
Percent = 100*Raw/Num;
run;
The list of items to delete is assigned to a macro variable (&List) with a %LET statement. This method of assignment makes it easier to rerun the program with a different set of items to delete. It also makes it easier to convert the program to a macro.
The variable Num is the number of items on the original test minus the number of items you want to delete. The DO loop performs two functions. First, it sums the Score variables (1=correct, 0=incorrect) for all the items not in the delete list. The statement that performs the scoring combines a logical statement (Item not in &list) with an arithmetic computation (multiplying it by Score[Item]). This is how that statement works: If an item number is not in the delete list (&List), then the logical statement is true and SAS treats a true value as a 1, when combined with an arithmetic calculation. When an item is in the delete list, the logical statement is false. Since a false value is equal to 0, you multiply the score value (either a 0 or 1) by 0, thus ignoring deleted items in the scoring process. The second function of the DO loop computes the number of non-deleted items. You do this by decrementing the value of Num by one for each item in the delete list. The percent score is 100 times the raw score divided by the number of non-deleted items.
When you run this program with the first five items marked for deletion, the computed value of KR-20 is .779, an improvement over the value with the five items included (.752).
A macro version of this program is included in Chapter 11.
Analyzing Tests with Multiple Versions (with Correspondence Information in a Text File)
In testing conditions where students are packed closely together, one way to discourage cheating is to administer your test in multiple versions. Obviously, the version number needs to be included with the student answers. In order to score multiple test versions, you need to supply a correspondence file containing information on where each of the test items on an alternate version is located on the master version (which we will call version 1).
You may choose to supply the correspondence information in a text file or an Excel workbook. The example that follows has three versions of a five-item test, with the correspondence information placed in a text file, as shown here:
Correspondence Information in File c:\books\test scoring\corresp.txt
1 2 3 4 5
5 4 3 2 1
1 3 5 2 4
The first line of this file contains the item number on the first version. Line two contains the correspondence between versions 2 and 1. For example, the first item on the version 2 exam is item 5 on version 1, the second item on the version 2 exam is item 4 on version 1, and so forth. The third line contains correspondence information for version 3. The data in this text file is used to populate a two-dimensional temporary SAS array in this program.
The student data for this example is stored in a text file called mult_versions.txt. The first line of this file contains the answer key (for version 1). The remaining lines contain data for each student: a nine-digit ID, the test version (1, 2, or 3), and the student answers. A listing of this file is shown below:
Listing of Text File mult_versions.txt
ABCDE
1234567891ABCDE
3333333331ABCDD
2222222222EDCBA
4444444441AAAAA
5555555553ACEBD
The program that follows uses the correspondence information to unscramble the student data so that it looks like every student took version 1 of the test:
Program 6.3: Scoring Multiple Test Versions
data multiple;
retain Key1-Key5;
array response[5] $ 1;
array Ans[5] $ 1;
array Key[5] $ 1;
array Score[5];
array correspondence[3,5] _temporary_; ➊
if _n_ = 1 then do;
*Load correspondence array;
infile 'c:\books\test scoring\corresp.txt';
do Version = 1 to 3; ➋
do Item = 1 to 5;
input correspondence[Version,Item] @;
end;
end;
infile 'c:\books\test scoring\mult_versions.txt' pad; ➌
input @11 (Key1-Key5)($upcase1.); ➍
end;
infile 'c:\books\test_scoring\mult_versions.txt' pad;
input @1 ID $9. ➎
@10 Version 1.
@11 (Response1-Response5)($upcase1.);
Raw = 0;
do Item = 1 to 5;
Ans[Item] = Response[correspondence[Version,Item]]; ➏
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item Response1-Response5;
run;
➊ The array CORRESPONDENCE has two dimensions (three rows and five columns) and is declared to be a temporary array by the key word _TEMPORARY_. The row and column dimensions are created by placing a comma between the 3 and 5 on the ARRAY statement. Temporary arrays are similar to real arrays in SAS. The only difference is that temporary arrays are not associated with any variables—only the array elements (that are stored in memory) are accessible in the DATA step.
The first dimension of the array (correspondence) is the version number; the second dimension of the array is the correspondence value. For example, suppose a student has version 2 of the test and she selects E as her answer to the first question. The program will select the first value in the second row of the correspondence table, which is a 5. The program then assigns the answer E to the variable Ans5.
➋ You load the CORRESPONDENCE array from the data in the corresp.txt file using nested DO loops. The outer loop cycles the version number and the inner loop cycles through the items.
➌ Once you have loaded the CORRESPONDENCE array, you then change the INFILE location to your test data. In this example, the test data is placed in a file called multi_versions.txt in a folder called c:\books\test scoring.
➍ You next read the key variables and student answers in the usual manner. The informat $UPCASE1. is used to read student answers instead of the usual $1. informat used previously. The $UPCASE informat, as you may have guessed, converts all character values to uppercase.
➎ You read in the student ID, the version number, and the student responses into variables that you name Response1 to Response5.
➏ This is the statement that places each student response, regardless of version, in the appropriate Ans variables. For example, for a student answering item 1 on a version 2 test, the value of correspondence[2,1] is 5. Therefore, the variable Ans1 will be assigned the value of the variable Response5 for this student. In computer science, this method of looking up a value is called indirect addressing.
Here is the output from running this program:
Output from Program 6.3
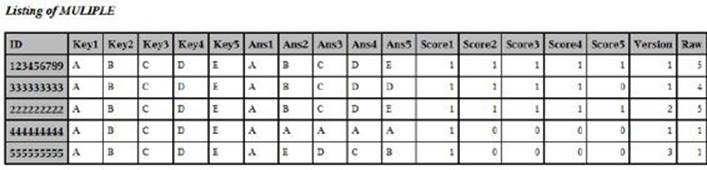
To fully understand this, look at the original answers for student 222222222. This student took version 2 of the test and her answers were E D C B A—the values of the variables Ans1 to Ans5 are A B C D E.
Analyzing Tests with Multiple Versions (with Correspondence Information in an Excel File)
If you prefer to enter your correspondence information in an Excel file, you only need to make a small adjustment to Program 6.3. The format of your Excel spreadsheet needs to be structured as follows: The first row should contain column headings labeled Q1 to Qn, where n is the number of items on the test. The remaining rows should contain the same values as the text file in the previous section. A spreadsheet version of the previous text file is shown below:
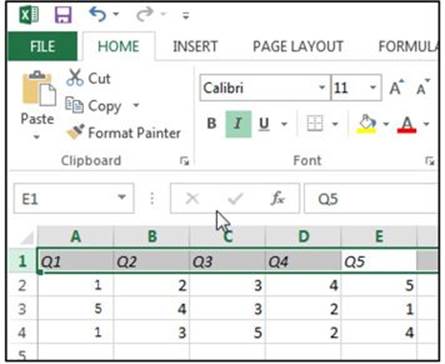
Although the bottom of this spreadsheet is not shown, the default name $Sheet1 was used.
A SAS program to read the correspondence information from the Excel file and score the test follows:
Program 6.4: Reading the Correspondence Information from an Excel File and Scoring the Test
libname readxl 'c:\books\test scoring\correspondence.xlsx';
data multiple;
retain Key1-Key5;
array Response[5] $ 1;
array Ans[5] $ 1;
array Key[5] $ 1;
array Score[5];
array Q[5];
array Correspondence[3,5] _temporary_;
if _n_ = 1 then do;
*Load correspondence array;
do Version = 1 to 3;
set readxl.'Sheet1$'n;
do Item = 1 to 5;
Correspondence[Version,Item] = Q[Item];
end;
end;
infile 'c:\books\test scoring\mult_versions.txt' pad;
input @11 (Key1-Key5)($upcase1.);
end;
infile 'c:\books\test scoring\mult_versions.txt' pad;
input @1 ID $9.
@10 Version 1.
@11 (Response1-Response5)($upcase1.);
Raw = 0;
do Item = 1 to 5;
Ans[Item] = Response[correspondence[Version,Item]];
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item Response1-Response5;
run;
You read the Excel file using the LIBNAME engine (described in Chapter 2). Because you used column headings Q1 to Q5, you read the correspondence information from variables Q1 to Q5 in a DO loop. Also, since the default worksheet name $Sheet1 was used, you use that sheet name in the SET statement. If you choose another name for your worksheet, simply replace the name $Sheet1 with the name you have chosen. The resulting SAS data set is identical to the one in the previous section, so there is no need to show the listing again.
Analyzing Tests with Multiple Versions (with Correspondence Information and Student Data in an Excel File)
The last section of this chapter demonstrates how you can score multiple versions of a test when both your correspondence file and your student data are stored in Excel files. The correspondence file needs to be structured exactly as in the previous section. Your student data file needs to be structured as follows:
The first row of your spreadsheet should contain the column headings as follows:
Column A: ID
Column B: Version
Columns C – end: Student responses labeled R1 through Rn, where n is the number of items on the test.
For example, your spreadsheet containing the same data as the text file described earlier is displayed next: (Leave the sheet name as the default value Sheet1.)
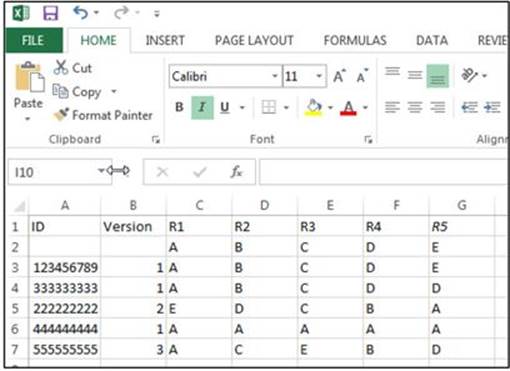
Here is a program to read data from these two Excel files and score the test:
Program 6.5: Reading the Correspondence Information and Student Data from Excel Files and Scoring the Test
libname readxl 'c:\books\test scoring\correspondence.xlsx';
libname readtest 'c:\books\test scoring\mult_versions.xlsx';
data multiple;
retain Key1-Key5;
array R[5] $ 1;
array Ans[5] $ 1;
array Key[5] $ 1;
array Score[5];
array Q[5];
array Correspondence[3,5] _temporary_;
if _n_ = 1 then do;
*Load correspondence array;
do Version = 1 to 3;
set readxl.'Sheet1$'n;
do Item = 1 to 5;
Correspondence[Version,Item] = Q[Item];
end;
end;
set readtest.'Sheet1$'n;
do Item = 1 to 5;
Key[Item] = R[Item];
end;
end;
set readtest.'Sheet1$'n (firstobs=2);
Raw = 0;
do Item = 1 to 5;
Ans[Item] = R[correspondence[Version,Item]];
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item R1-R5 Num_ID;
run;
Because the previous section describes how to use a LIBNAME engine to read Excel files, only a few brief comments are described. You write two LIBNAME statements, one for the correspondence file and one for the student data file. If you override the default sheet name Sheet1, you can substitute the name you chose for Sheet1 in the program. The variable names coming from the Excel file become the variable names in the SAS data set. Because the ID values are numeric in the Excel file, the variable ID in the SAS data set will also be numeric. If you wish, you can perform what SAS calls a swap-and-drop operation, where you rename the variable using a RENAME= data set option and then use a PUT function to create a character variable that you call ID.
The student data begins in column two, so you use the data set option FIRSTOBS=2 to read data values starting with the second observation. The resulting data set is identical to the two previous data sets with the exception that the ID variable will be numeric unless you decide to convert it.
Conclusion
Although you may feel that you should delete (and then rewrite) a multiple-choice item that has more than one correct answer, the first program in this chapter demonstrated how to allow for multiple correct answers.
At a medical school in New Jersey where one of the authors worked for 26 years, it was common practice to first run an item analysis on a test and then delete items that had poor item statistics (such as a difficulty that was too low or where the point-biserial coefficient was very low or negative). This practice often increases the overall test reliability. Program 6.2 demonstrated how to delete items and rescore the test.
The last topic of this chapter, scoring and analyzing multiple test versions, is of particular importance when you have a large number of students in an environment, such as a large lecture hall, where it is easy to copy answers from nearby students. Also, with cell phones and other communication devices, students are finding ways to cheat that we haven't even thought of yet. At the afore-mentioned medical school, we often administered three or four versions of mid-term and final exams. As you saw in Program 6.3, scoring and analyzing multiple test versions is easily accomplished. As a further method to discouraging cheating, Chapter 10 describes programs that can help you detect cheating on multiple-choice exams.