Time Series Databases: New Ways to Store and Access Data (2014)
Chapter 5. Solving a Problem You Didn’t Know You Had
Whenever you build a system, it’s good practice to do testing before you begin using it, especially before it goes into production. If your system is designed to store huge amounts of time series data—such as two years’ worth of sensor data—for critical operations or analysis, it’s particularly important to test it. The failure of a monitoring system for drilling or pump equipment on an oil rig, for manufacturing equipment, medical equipment, or an airplane, can have dire consequences in terms financial loss and physical damage, so it is essential that your time series data storage engine is not only high performance, but also robust. Sometimes people do advance testing on a small data sample, but tests at this small scale are not necessarily reliable predictors of how your system will function at scale. For serious work, you want a serious test, using full-scale data. But how can you do that?
The Need for Rapid Loading of Test Data
Perhaps you have preexisting data for a long time range that could be used for testing, and at least you can fairly easily build a program to generate synthetic data to simulate your two years of information. Either way, now you’re faced with a problem you may not have realized you have: if your system design was already pushing the limits on data ingestion to handle the high-velocity data expected in production, how will you deal with loading two years’ worth of such data in a reasonable time? If you don’t want to have to wait two years to perform the test, you must either give up having a full-scale test by downsampling or you must find a clever way to speed up test data ingestion rates enormously compared with normal production rates. For this example, to ingest two years of data in a day or two, you will need to ingest test data 100–1,000 times faster than your production rate. Even if your production data ingestion rate is only moderately high, your test data ingestion rate is liable to need to be outrageous. We choose the option to speed up the ingestion rate for test data. That’s where the open source code extensions developed by MapR (described in Chapter 4) come to the rescue.
Using Blob Loader for Direct Insertion into the Storage Tier
The separate blob loader described in Chapter 4 (see Figure 4-3) is ideal for ingesting data to set up a test at scale. The blob loader design has been shown to provide more than 1,000-fold acceleration of data loading over the rate achieved by unmodified Open TSDB’s hybrid wide table/blob design as shown in Figure 4-1. The advantages of this direct-insertion approach are especially apparent when you imagine plotting the load times for the different approaches, as shown in Figure 5-1.
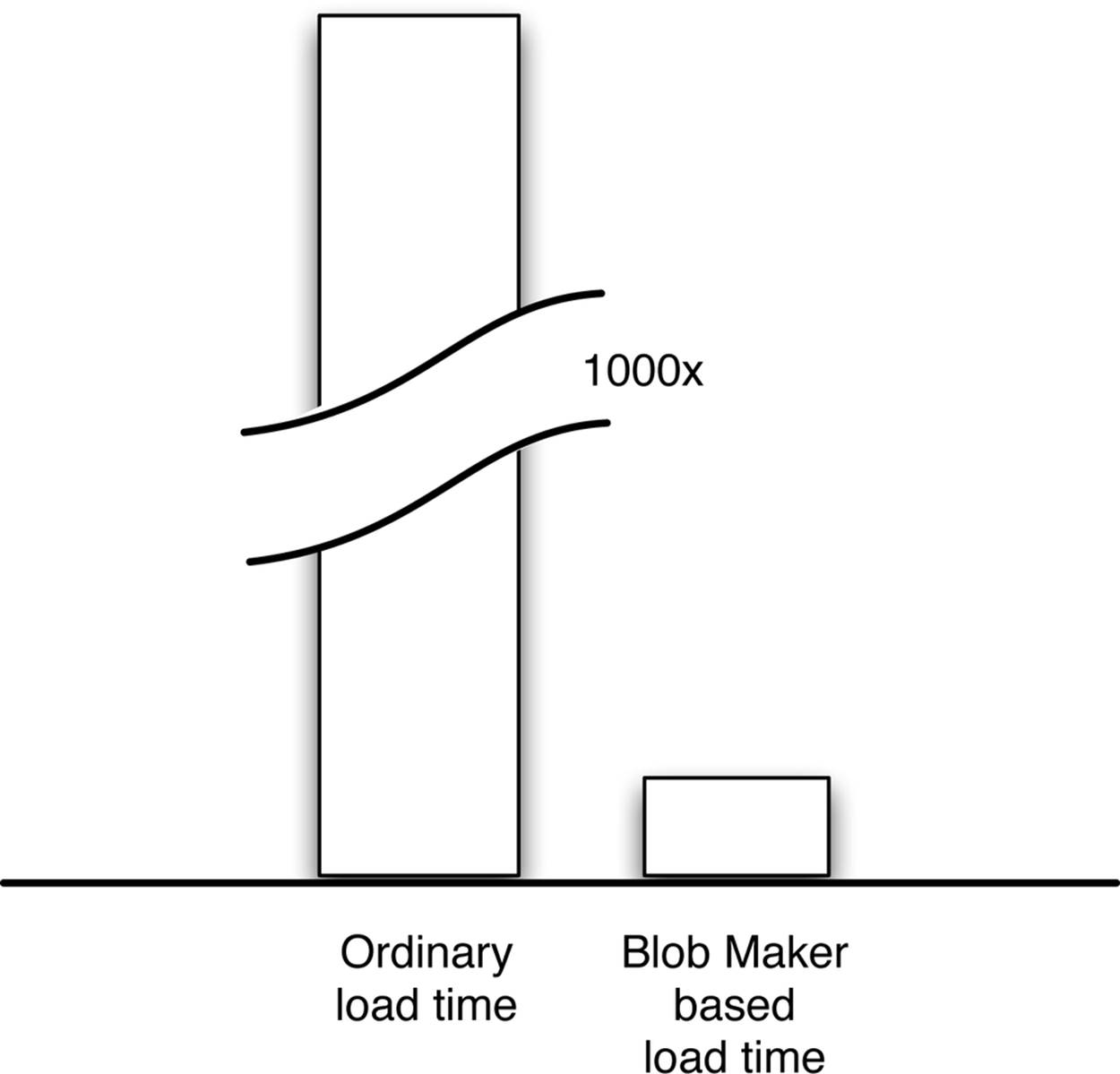
Figure 5-1. Load times for large-scale test data can be prohibitive with the hybrid-style format (point-by-point + blob) produced by ordinary Open TSDB (left), but this problem is solved with rapid ingestion rates obtained by using the open source code extensions to do direct blob insertion (right).
There are other situations in which direct blob insertion can be beneficial as well, but even by just making it practical to do realistic testing at scale of a critical time series database, this approach can have wide impact.