Machine Learning with Spark (2015)
Chapter 2. Designing a Machine Learning System
In this chapter, we will design a high-level architecture for an intelligent, distributed machine learning system that uses Spark as its core computation engine. The problem we will focus on will be taking the existing architecture for a web-based business and redesigning it to use automated machine learning systems to power key areas of the business. In this chapter, we will:
· Introduce our hypothetical business scenario
· Provide an overview of the current architecture
· Explore various ways in which machine learning systems can enhance or replace certain business functions
· Provide a new architecture based on these ideas
A modern large-scale data environment includes the following requirements:
· It must integrate with other components of the system, especially with data collection and storage systems, analytics and reporting, and frontend applications.
· It should be easily scalable and independent of the rest of the architecture. Ideally, this should be in the form of horizontal as well as vertical scalability.
· It should allow efficient computation in respect of the type of workload in mind, that is machine learning and iterative analytics applications.
· If possible, it should support both batch and real-time workloads.
As a framework, Spark meets these criteria. However, we must ensure that the machine learning systems designed on Spark also meet these criteria. There is no good in implementing an algorithm that ends up having bottlenecks that cause our system to fail in terms of one or more of these requirements.
Introducing MovieStream
To better illustrate the design of our architecture, we will introduce a practical scenario. Let's assume that we have just been appointed to head the data science team of MovieStream, a fictitious Internet business that streams movies and television shows to its users.
MovieStream is growing rapidly, adding both users and titles to its catalogue. The current MovieStream system is outlined in the following diagram:
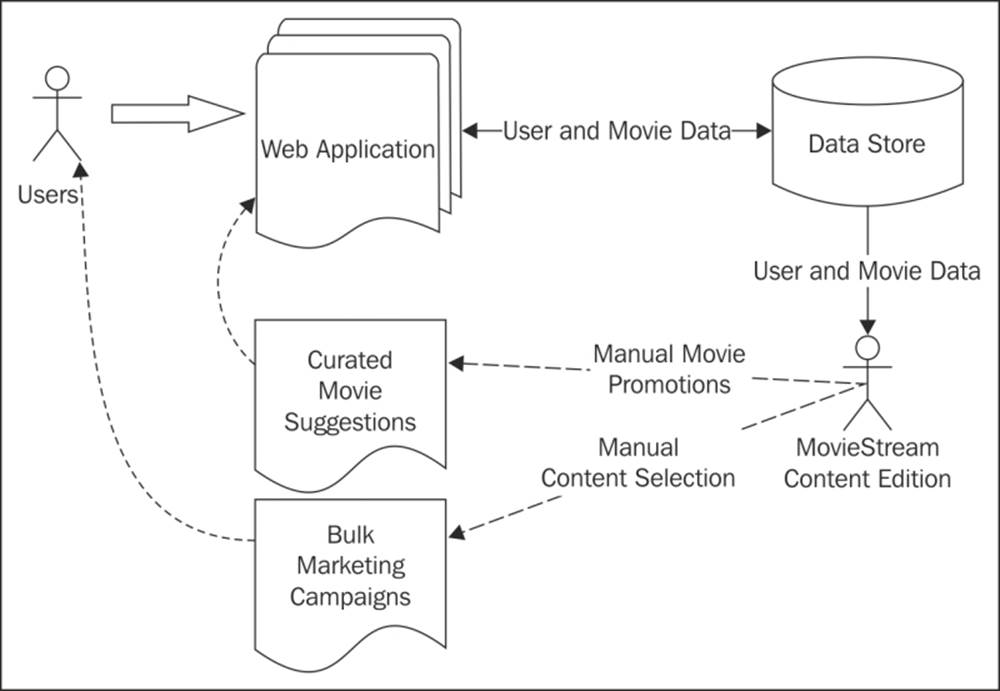
MovieStream's current architecture
As we can see in the preceding diagram, currently, MovieStream's content editorial team is responsible for deciding which movies and shows are promoted and shown on the various parts of the site. They are also responsible for creating the content for MovieStream's bulk marketing campaigns, which include e-mail and other direct marketing channels. Currently, MovieStream collects basic data on what titles are viewed by users on an aggregate basis and has access to some demographic data collected from users when they sign up to the service. In addition, they have access to some basic metadata about the titles in their catalogue.
The MovieStream team is stretched thin due to their rapid growth, and they can't keep up with the number of new releases and the growing activity of their users. The CEO of MovieStream has heard a lot about big data, machine learning, and artificial intelligence, and would like us to build a machine learning system for MovieStream that can handle many of the functions currently handled by the content team in an automated manner.
Business use cases for a machine learning system
Perhaps the first question we should answer is, "Why use machine learning at all?" Why doesn't MovieStream simply continue with human-driven decisions? There are many reasons to use machine learning (and certainly some reasons not to), but the most important ones are mentioned here:
· The scale of data involved means that full human involvement quickly becomes infeasible as MovieStream grows
· Model-driven approaches such as machine learning and statistics can often benefit from uncovering patterns that cannot be seen by humans (due to the size and complexity of the datasets)
· Model-driven approaches can avoid human and emotional biases (as long as the correct processes are carefully applied)
However, there is no reason why both model-driven and human-driven processes and decision making cannot coexist. For example, many machine learning systems rely on receiving labeled data in order to train models. Often, labeling such data is costly, time consuming, and requires human input. A good example of this is classifying textual data into categories or assigning a sentiment indicator to the text. Many real-world systems use some form of human-driven system to generate labels for such data (or at least part of it) to provide training data to models. These models are then used to make predictions in the live system at a larger scale.
In the context of MovieStream, we need not fear that our machine learning system will make the content team redundant. Indeed, we will see that our aim is to lift the burden of time-consuming tasks where machine learning might be able to perform better while providing tools to allow the team to better understand the users and content. This might, for example, help them in selecting which new content to acquire for the catalogue (which involves a significant amount of cost and is therefore a critical aspect of the business).
Personalization
Perhaps one of the most important potential applications of machine learning in MovieStream's business is personalization. Generally speaking, personalization refers to adapting the experience of a user and the content presented to them based on various factors, which might include user behavior data as well as external factors.
Recommendations are essentially a subset of personalization. Recommendation generally refers to presenting a user with a list of items that we hope the user will be interested in. Recommendations might be used in web pages (for example, recommending related products), via e-mails or other direct marketing channels, via mobile apps, and so on.
Personalization is very similar to recommendations, but while recommendations are usually focused on an explicit presentation of products or content to the user, personalization is more generic and, often, more implicit. For example, applying personalization to search on the MovieStream site might allow us to adapt the search results for a given user, based on the data available about that user. This might include recommendation-based data (in the case of a search for products or content) but might also include various other factors such as geolocation and past search history. It might not be apparent to the user that the search results are adapted to their specific profile; this is why personalization tends to be more implicit.
Targeted marketing and customer segmentation
In a manner similar to recommendations, targeted marketing uses a model to select what to target at users. While generally recommendations and personalization are focused on a one-to-one situation, segmentation approaches might try to assign users into groups based on characteristics and, possibly, behavioral data. The approach might be fairly simple or might involve a machine learning model such as clustering. Either way, the result is a set of segment assignments that might allow us to understand the broad characteristics of each group of users, what makes them similar to each other within a group, and what makes them different from others in different groups.
This could help MovieStream to better understand the drivers of user behavior and might also allow a broader targeting approach where groups are targeted as opposed to (or more likely, in addition to) direct one-to-one targeting with personalization.
These methods can also help when we don't necessarily have labeled data available (as is the case with certain user and content profile data) but we still wish to perform more focused targeting than a complete one-size-fits-all approach.
Predictive modeling and analytics
A third area where machine learning can be applied is in predictive analytics. This is a very broad term, and in some ways, it encompasses recommendations, personalization, and targeting too. In this context, since recommendations and segmentation are somewhat distinct, we use the term predictive modeling to refer to other models that seek to make predictions. An example of this can be a model to predict the potential viewing activity and revenue of new titles before any data is available on how popular the title might be. MovieStream can use past activity and revenue data, together with content attributes, to create a regression model that can be used to make predictions for brand new titles.
As another example, we can use a classification model to automatically assign tags, keywords, or categories to new titles for which we only have partial data.
Types of machine learning models
While we have highlighted a few use cases for machine learning in the context of the preceding MovieStream example, there are many other examples, some of which we will touch on in the relevant chapters when we introduce each machine learning task.
However, we can broadly divide the preceding use cases and methods into two categories of machine learning:
· Supervised learning: These types of models use labeled data to learn. Recommendation engines, regression, and classification are examples of supervised learning methods. The labels in these models can be user-movie ratings (for recommendation), movie tags (in the case of the preceding classification example), or revenue figures (for regression). We will cover supervised learning models in Chapter 4, Building a Recommendation Engine with Spark, Chapter 5, Building a Classification Model with Spark, and Chapter 6, Building a Regression Model with Spark.
· Unsupervised learning: When a model does not require labeled data, we refer to unsupervised learning. These types of models try to learn or extract some underlying structure in the data or reduce the data down to its most important features. Clustering, dimensionality reduction, and some forms of feature extraction, such as text processing, are all unsupervised techniques and will be dealt with in Chapter 7, Building a Clustering Model with Spark, Chapter 8, Dimensionality Reduction with Spark, and Chapter 9, Advanced Text Processing with Spark.
The components of a data-driven machine learning system
The high-level components of our machine learning system are outlined in the following diagram. This diagram illustrates the machine learning pipeline from which we obtain data and in which we store data. We then transform it into a form that is usable as input to a machine learning model; train, test, and refine our model; and then, deploy the final model to our production system. The process is then repeated as new data is generated.
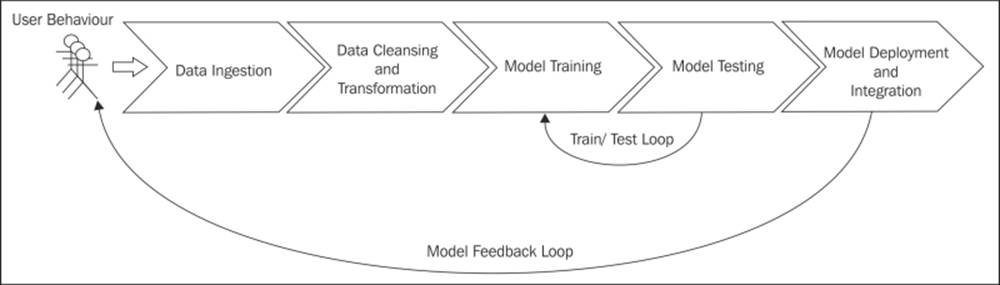
A general machine learning pipeline
Data ingestion and storage
The first step in our machine learning pipeline will be taking in the data that we require for training our models. Like many other businesses, MovieStream's data is typically generated by user activity, other systems (this is commonly referred to as machine-generated data), and external sources (for example, the time of day and weather during a particular user's visit to the site).
This data can be ingested in various ways, for example, gathering user activity data from browser and mobile application event logs or accessing external web APIs to collect data on geolocation or weather.
Once the collection mechanisms are in place, the data usually needs to be stored. This includes the raw data, data resulting from intermediate processing, and final model results to be used in production.
Data storage can be complex and involve a wide variety of systems, including HDFS, Amazon S3, and other filesystems; SQL databases such as MySQL or PostgreSQL; distributed NoSQL data stores such as HBase, Cassandra, and DynamoDB; and search engines such as Solr or Elasticsearch to stream data systems such as Kafka, Flume, or Amazon Kinesis.
For the purposes of this book, we will assume that the relevant data is available to us, so we will focus on the processing and modeling steps in the following pipeline.
Data cleansing and transformation
The majority of machine learning models operate on features, which are typically numerical representations of the input variables that will be used for the model.
While we might want to spend the majority of our time exploring machine learning models, data collected via various systems and sources in the preceding ingestion step is, in most cases, in a raw form. For example, we might log user events such as details of when a user views the information page for a movie, when they watch a movie, or when they provide some other feedback. We might also collect external information such as the location of the user (as provided through their IP address, for example). These event logs will typically contain some combination of textual and numeric information about the event (and also, perhaps, other forms of data such as images or audio).
In order to use this raw data in our models, in almost all cases, we need to perform preprocessing, which might include:
· Filtering data: Let's assume that we want to create a model from a subset of the raw data, such as only the most recent few months of activity data or only events that match certain criteria.
· Dealing with missing, incomplete, or corrupted data: Many real-world datasets are incomplete in some way. This might include data that is missing (for example, due to a missing user input) or data that is incorrect or flawed (for example, due to an error in data ingestion or storage, technical issues or bugs, or software or hardware failure). We might need to filter out bad data or alternatively decide a method to fill in missing data points (such as using the average value from the dataset for missing points, for example).
· Dealing with potential anomalies, errors, and outliers: Erroneous or outlier data might skew the results of model training, so we might wish to filter these cases out or use techniques that are able to deal with outliers.
· Joining together disparate data sources: For example, we might need to match up the event data for each user with different internal data sources, such as user profiles, as well as external data, such as geolocation, weather, and economic data.
· Aggregating data: Certain models might require input data that is aggregated in some way, such as computing the sum of a number of different event types per user.
Once we have performed initial preprocessing on our data, we often need to transform the data into a representation that is suitable for machine learning models. For many model types, this representation will take the form of a vector or matrix structure that contains numerical data. Common challenges during data transformation and feature extraction include:
· Taking categorical data (such as country for geolocation or category for a movie) and encoding it in a numerical representation.
· Extracting useful features from text data.
· Dealing with image or audio data.
· We often convert numerical data into categorical data to reduce the number of values a variable can take on. An example of this is converting a variable for age into buckets (such as 25-35, 45-55, and so on).
· Transforming numerical features; for example, applying a log transformation to a numerical variable can help deal with variables that take on a very large range of values.
· Normalizing and standardizing numerical features ensures that all the different input variables for a model have a consistent scale. Many machine learning models require standardized input to work properly.
· Feature engineering is the process of combining or transforming the existing variables to create new features. For example, we can create a new variable that is the average of some other data, such as the average number of times a user watches a movie.
We will cover all of these techniques through the examples in this book.
These data-cleansing, exploration, aggregation, and transformation steps can be carried out using both Spark's core API functions as well as the SparkSQL engine, not to mention other external Scala, Java, or Python libraries. We can take advantage of Spark's Hadoop compatibility to read data from and write data to the various different storage systems mentioned earlier.
Model training and testing loop
Once we have our training data in a form that is suitable for our model, we can proceed with the model's training and testing phase. During this phase, we are primarily concerned with model selection. This can refer to choosing the best modeling approach for our task, or the best parameter settings for a given model. In fact, the term model selection often refers to both of these processes, as, in many cases, we might wish to try out various models and select the best performing model (with the best performing parameter settings for each model). It is also common to explore the application of combinations of different models (known as ensemble methods) in this phase.
This is typically a fairly straightforward process of running our chosen model on our training dataset and testing its performance on a test dataset (that is, a set of data that is held out for the evaluation of the model that the model has not seen in the training phase). This process is referred to as cross-validation.
However, due to the large scale of data we are typically working with, it is often useful to carry out this initial train-test loop on a smaller representative sample of our full dataset or perform model selection using parallel methods where possible.
For this part of the pipeline, Spark's built-in machine learning library, MLlib, is a perfect fit. We will focus most of our attention in this book on the model training, evaluation, and cross-validation steps for various machine learning techniques, using MLlib and Spark's core features.
Model deployment and integration
Once we have found the optimal model based on the train-test loop, we might still face the task of deploying the model to a production system so that it can be used to make actionable predictions.
Usually, this process involves exporting the trained model to a central data store from where the production-serving system can obtain the latest version. Thus, the live system refreshes the model periodically as a new model is trained.
Model monitoring and feedback
It is critically important to monitor the performance of our machine learning system in production. Once we deploy our optimal trained model, we wish to understand how it is doing in the "wild". Is it performing as we expect on new, unseen data? Is its accuracy good enough? The reality is regardless of how much model selection and tuning we try to do in the earlier phases; the only way to measure true performance is to observe what happens in our production system.
Also, bear in mind that model accuracy and predictive performance is only one aspect of a real-world system. Usually, we are concerned with other metrics related to business performance (for example, revenue and profitability) or user experience (such as the time spent on our site and how active our users are overall). In most cases, we cannot easily map model-predictive performance to these business metrics. The accuracy of a recommendation or targeting system might be important, but it relates only indirectly to the true metrics we are concerned about, namely whether we are improving user experience, activity, and ultimately, revenue.
So, in real-world systems, we should monitor both model-accuracy metrics as well as business metrics. If possible, we should be able to experiment with different models running in production to allow us to optimize against these business metrics by making changes to the models. This is often done using live split tests. However, doing this correctly is not an easy task, and live testing and experimentation is expensive, in the sense that mistakes, poor performance, and using baseline models (they provide a control against which we test out production models) can negatively impact user experience and revenue.
Another important aspect of this phase is model feedback. This is the process where the predictions of our model feed through into user behavior; this, in turn, feeds through into our model. In a real-world system, our models are essentially influencing their own future training data by impacting decision-making and potential user behavior.
For example, if we have deployed a recommendation system, then, by making recommendations, we might be influencing user behavior because we are only allowing users a limited selection of choices. We hope that this selection is relevant due to our model; however, this feedback loop, in turn, can influence our model's training data. This, in turn, feeds back into real-world performance. It is possible to get into an ever-narrowing feedback loop; ultimately, this can negatively affect both model accuracy and our important business metrics.
Fortunately, there are mechanisms by which we can try to limit the potential negative impact of this feedback loop. These include providing some unbiased training data by having a small portion of data coming from users who are not exposed to our models or by being principled in the way we balance exploration, to learn more about our data, and exploitation, to use what we have learned to improve our system's performance.
We will briefly cover some aspects of real-time monitoring and model updates in Chapter 10, Real-time Machine Learning with Spark Streaming.
Batch versus real time
In the previous sections, we outlined the common batch processing approach, where the model is retrained using all data or a subset of all data, periodically. As the preceding pipeline takes some time to complete, it might not be possible to use this approach to update models immediately as new data arrives.
While we will be mostly covering batch machine learning approaches in this book, there is a class of machine learning algorithms known as online learning; they update immediately as new data is fed into the model, thus enabling a real-time system. A common example is an online-optimization algorithm for a linear model, such as stochastic gradient descent. We can learn this algorithm using examples. The advantages of these methods are that the system can react very quickly to new information and also that the system can adapt to changes in the underlying behavior (that is, if the characteristics and distribution of the input data are changing over time, which is almost always the case in real-world situations).
However, online-learning models come with their own unique challenges in a production context. For example, it might be difficult to ingest and transform data in real time. It can also be complex to properly perform model selection in a purely online setting. Latency of the online training and the model selection and deployment phases might be too high for true real-time requirements (for example, in online advertising, latency requirements are measured in single-digit milliseconds). Finally, batch-oriented frameworks might make it awkward to handle real-time processes of a streaming nature.
Fortunately, Spark's real-time stream processing component, Spark Streaming, is a good potential fit for real-time machine learning workflows. We will explore Spark Streaming and online learning in Chapter 10, Real-time Machine Learning with Spark Streaming.
Due to the complexities inherent in a true real-time machine learning system, in practice, many systems target near real-time operations. This is essentially a hybrid approach where models are not necessarily updated immediately as new data arrives; instead, the new data is collected into mini-batches of a small set of training data. These mini-batches can be fed to an online-learning algorithm. In many cases, this approach is combined with a periodic batch process that might recompute the model on the entire data set and perform more complex processing and model selection. This can help ensure that the real-time model does not degrade over time.
Another similar approach involves making approximate updates to a more complex model as new data arrives while recomputing the entire model in a batch process periodically. In this way, the model can learn from new data, with a short delay (usually measured in seconds or, perhaps, a few minutes), but will become more and more inaccurate over time due to the approximation applied. The periodic recomputation takes care of this by retraining the model on all available data.
An architecture for a machine learning system
Now that we have explored how our machine learning system might work in the context of MovieStream, we can outline a possible architecture for our system:
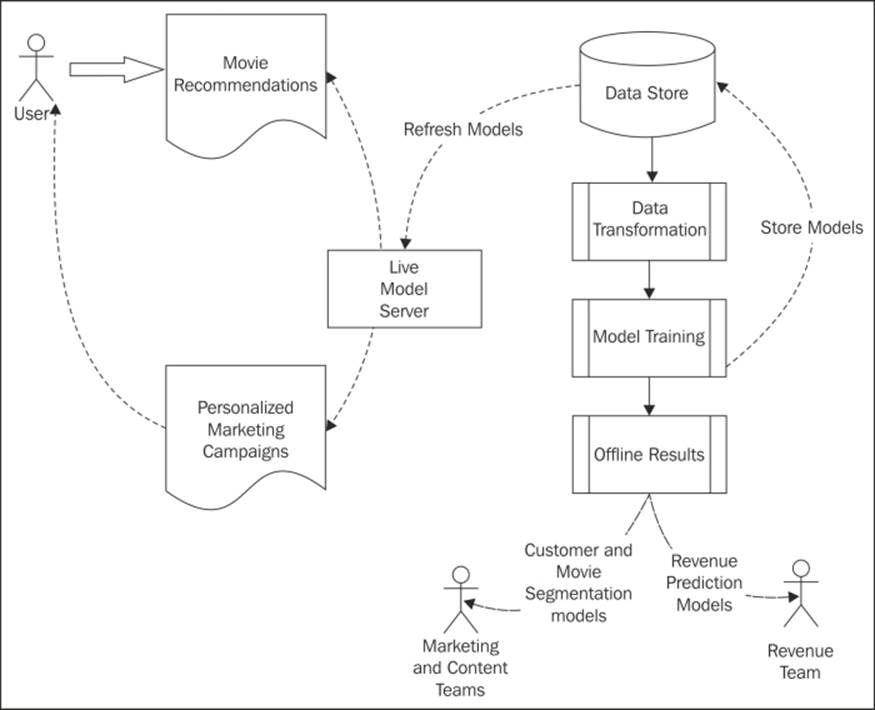
MovieStream's future architecture
As we can see, our system incorporates the machine learning pipeline outlined in the preceding diagram; this system also includes:
· Collecting data about users, their behavior, and our content titles
· Transforming this data into features
· Training our models, including our training-testing and model-selection phases
· Deploying the trained models to both our live model-serving system as well as using these models for offline processes
· Feeding back the model results into the MovieStream website through recommendation and targeting pages
· Feeding back the model results into MovieStream's personalized marketing channels
· Using the offline models to provide tools to MovieStream's various teams to better understand user behavior, characteristics of the content catalogue, and drivers of revenue for the business
Practical exercise
Imagine that you now need to provide input to the frontend and infrastructure engineering team about the data that your machine learning system will need. Consider a brief for them on how they should structure the data-collection mechanisms. Write down some examples of what the raw data might look like (for example, web logs, event logs, and so on) and how it should flow through the system. Take into account the following aspects:
· What data sources will be required
· What format should the data be in
· How often should data be collected, processed, potentially aggregated, and stored
· What data storage will you use to ensure scalability
Summary
In this chapter, you learned about the components inherent in a data-driven, automated machine learning system. We also outlined how a possible high-level architecture for such a system might look in a real-world situation.
In the next chapter, we will discuss how to obtain publicly-available datasets for common machine learning tasks. We will also explore general concepts related to processing, cleaning, and transforming data so that they can be used to train a machine learning model.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.