Java 8 in Action: Lambdas, streams, and functional-style programming (2015)
Part 3. Effective Java 8 programming
Chapter 11. CompletableFuture: composable asynchronous programming
This chapter covers
· Creating an asynchronous computation and retrieving its result
· Increasing throughput using non-blocking operations
· Designing and implementing an asynchronous API
· Consuming asynchronously a synchronous API
· Pipelining and merging two or more asynchronous operations
· Reacting to the completion of an asynchronous operation
In recent years, two trends are obliging us to rethink the way we write software. The first trend is related to the hardware on which we run our applications, and the second trend concerns how applications are structured and particularly how they interact with each other. We discussed the impact of the hardware trend in chapter 7. We noted that since the advent of multicore processors, the most effective way to speed up your applications is to write software that’s able to fully exploit the multicore processors. You saw that this is possible by splitting large tasks and making each subtask run in parallel with the others; you also learned how the fork/join framework (available since Java 7) and parallel streams (new in Java 8) allow you to accomplish this in a simpler and more effective way than by directly working with threads.
The second trend reflects the increasing availability and use by applications of internet services accessible through public APIs, made available by known providers such as Google (for example, localization information), Facebook (for example, social information), and Twitter (for example, news). Nowadays it’s relatively rare to develop a website or a network application that works in total isolation. It’s far more likely that your next web application will be a mash-up: it will use content from multiple sources and aggregate it to ease the life of your end users.
For instance, you might like to provide the collective sentiment about a given topic to your French users; to do this you could ask the Facebook or Twitter API for the most trending comments about that topic in any language and maybe rank the most relevant ones with your internal algorithms. Then you might use Google Translate to translate them into French, or even Google Maps to geolocate where their authors live, and finally aggregate all this information and display it on your website.
Oh, and of course, if any of these external network services are slow to respond, then you’ll wish to provide partial results to your users, for example, showing your text results alongside a generic map with a question mark in it, instead of showing a totally blank screen until the map server responds or times out. Figure 11.1 illustrates how this typical mash-up application interacts with the remote services it needs to work with.
Figure 11.1. A typical mash-up application
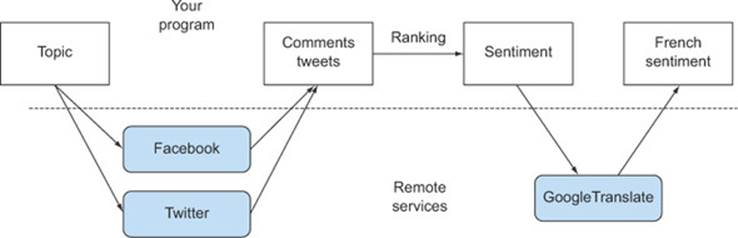
To implement a similar application, you’ll have to contact multiple web services across the internet. But what you don’t want to do is block your computations and waste billions of precious clock cycles of your CPU waiting for an answer from these services. For example, you shouldn’t have to wait for data from Facebook to start processing the data coming from Twitter.
This situation represents the other side of the multitask-programming coin. The fork/join framework and parallel streams discussed in chapter 7 are valuable tools for parallelism; they split an operation into multiple suboperations and perform those suboperations in parallel on different cores, CPUs, or even machines.
Conversely, when dealing with concurrency instead of parallelism, or when your main goal is to perform several loosely related tasks on the same CPUs, keeping their cores as busy as possible to maximize the throughput of your application, what you really want to achieve is to avoid blocking a thread and wasting its computational resources while waiting, potentially for quite a while, for a result from a remote service or from interrogating a database. As you’ll see in this chapter, the Future interface and particularly its new CompletableFuture implementation are your best tools in such circumstances. Figure 11.2 illustrates the difference between parallelism and concurrency.
Figure 11.2. Concurrency vs. parallelism
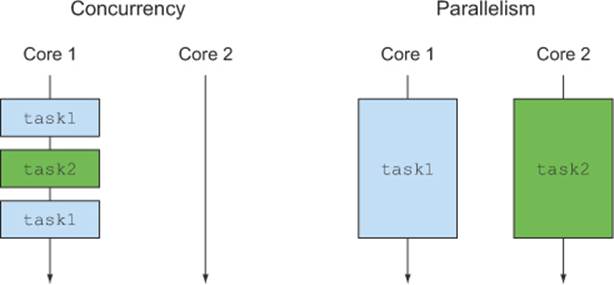
11.1. Futures
The Future interface was introduced in Java 5 to model a result made available at some point in the future. It models an asynchronous computation and provides a reference to its result that will be available when the computation itself is completed. Triggering a potentially time-consuming action inside a Future allows the caller Thread to continue doing useful work instead of just waiting for the operation’s result. You can think of it as taking a bag of clothes to your favorite dry cleaner. They will give you a receipt to tell you when your clothes are cleaned (a Future). In the meantime, you can do some other activities. Another advantage of Future is that it’s friendlier to work with than lower-level Threads. To work with a Future, you typically have to wrap the time-consuming operation inside a Callable object and submit it to an Executor-Service. The following listing shows an example written before Java 8.
Listing 11.1. Executing a long-lasting operation asynchronously in a Future

As depicted in figure 11.3, this style of programming allows your thread to perform some other tasks while the long-lasting operation is executed concurrently in a separate thread provided by the ExecutorService. Then, when you can’t do any other meaningful work without having the result of that asynchronous operation, you can retrieve it from the Future by invoking its get method. This method immediately returns the result of the operation if it’s already completed or blocks your thread, waiting for its result to be available.
Figure 11.3. Using a Future to execute a long operation asynchronously
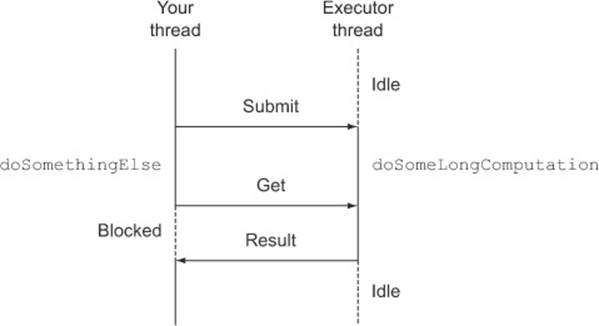
Can you think of a problem with this scenario? What if the long operation never returns? To handle this possibility, even though there also exists a get method that doesn’t take a parameter, it’s almost always a good idea to use its overloaded version, accepting a timeout defining the maximum time your thread has to wait for the Future’s result, as you did in listing 11.1, instead of waiting indefinitely.
11.1.1. Futures limitations
This first small example shows that the Future interface provides methods to check if the asynchronous computation is complete (using the isDone method), to wait for its completion, and to retrieve its result. But these features aren’t enough to let you write concise concurrent code. For example, it’s difficult to express dependencies between results of a Future; declaratively it’s easy to say, “When the result of the long computation is available, please send its result to another long computation, and when that’s done, combine its result with the result from another query.” But implementing this with the operations available in a Future is a different story. This is why more declarative features would be useful, such as these:
· Combining two asynchronous computations in one—both when they’re independent and when the second depends on the result of the first
· Waiting for the completion of all tasks performed by a set of Futures
· Waiting for the completion of only the quickest task in a set of Futures (possibly because they’re trying to calculate the same value in different ways) and retrieving its result
· Programmatically completing a Future (that is, by manually providing the result of the asynchronous operation)
· Reacting to a Future completion (that is, being notified when the completion happens and then having the ability to perform a further action using the result of the Future, instead of being blocked waiting for its result)
In this chapter, you’ll learn how the new CompletableFuture class (which implements the Future interface) makes all of this possible in a declarative way using Java 8’s new features. The designs of Stream and CompletableFuture follow similar patterns: both use lambda expressions and the idea of pipelining. For this reason you could say that CompletableFuture is to a plain Future what Stream is to a Collection.
11.1.2. Using CompletableFutures to build an asynchronous application
To demonstrate the CompletableFuture features, we incrementally develop a best-price-finder application that contacts multiple online shops to find the lowest price for a given product or service. Along the way, you’ll learn several important skills:
· First, you’ll learn how to provide an asynchronous API for your customers (useful if you’re the owner of one of the online shops).
· Second, you’ll learn how to make your code non-blocking when you’re a consumer of a synchronous API. You’ll discover how to pipeline two subsequent asynchronous operations, merging them into a single asynchronous computation. This situation would arise, for example, when the online shop returns a discount code along with the original price of the item you wanted to buy—so you have to contact a second remote discount service to find out the percentage discount associated with this discount code before finally calculating the actual price of that item.
· You’ll also learn how to reactively process events representing the completion of an asynchronous operation and how that allows the best-price-finder application to constantly update the best-buy quote for the item you want to buy as each shop returns its price, instead of having to wait for all the shops to return their respective quotes (which also risks giving the user a blank screen forever if one of the shops’ servers is down).
Synchronous vs. asynchronous API
The phrase synchronous API is just another way of talking about a traditional call to a method: you call it, the caller then waits while the method computes, the method then returns, and the caller continues with the returned value. Even if the caller and callee were executed on different threads, the caller would still wait for the callee to complete; this gives rise to the phrase blocking call.
In contrast, in an asynchronous API the method returns immediately, or at least before its computation is complete, delegating its remaining computation to a thread, which runs asynchronously to the caller—hence the phrase non-blocking call. The remaining computation gives its value to the caller, either by calling a callback method or by the caller invoking a further “wait until the computation is complete” method. This style of computation is common for I/O systems programming: you initiate a disc access, which happens asynchronously while you do more computation, and when you have nothing more useful to do, you simply wait until the disc blocks are loaded into memory.
11.2. Implementing an asynchronous API
To start implementing the best-price-finder application, let’s begin by defining the API that each single shop should provide. First, a shop declares a method that returns the price of a product given its name:
public class Shop {
public double getPrice(String product) {
// to be implemented
}
}
The internal implementation of this method would query the shop’s database but probably also perform other time-consuming tasks, such as contacting various other external services (for example, the shop’s suppliers or manufacturer-related promotional discounts). To fake such a long-running method execution, in the rest of this chapter we simply use a delay method, which introduces an artificial delay of 1 second, defined in the following listing.
Listing 11.2. A method to simulate a 1-second delay
public static void delay() {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
For the purpose of this chapter, the getPrice method can be modeled by calling delay and then returning a randomly calculated value for the price, as shown in the next listing. The code for returning a randomly calculated price may look like a bit of a hack. It randomizes the price based on the product name by using the result of charAt as a number.
Listing 11.3. Introducing a simulated delay in the getPrice method
public double getPrice(String product) {
return calculatePrice(product);
}
private double calculatePrice(String product) {
delay();
return random.nextDouble() * product.charAt(0) + product.charAt(1);
}
This implies that when the consumer of this API (in this case, the best-price-finder application) invokes this method, it will remain blocked and then idle for 1 second while waiting for its synchronous completion. This is unacceptable, especially considering that the best-price-finder application will have to repeat this operation for all the shops in its network. In the subsequent sections of this chapter, you’ll discover how you can resolve this problem by consuming this synchronous API in an asynchronous way. But for the purpose of learning how to design an asynchronous API, we continue this section by pretending to be on the other side of the barricade: you’re a wise shop owner who realizes how painful this synchronous API is for its users and you want to rewrite it as an asynchronous API to make your customers’ lives easier.
11.2.1. Converting a synchronous method into an asynchronous one
To achieve this you first have to turn the getPrice method into a getPriceAsync method and change its return value:
public Future<Double> getPriceAsync(String product) { ... }
As we mentioned in the introduction of this chapter, the java.util.concurrent .Future interface was introduced in Java 5 to represent the result of an asynchronous computation (that is, the caller thread is allowed to proceed without blocking). This means a Future is just a handle for a value that isn’t yet available but can be retrieved by invoking its get method after its computation has finally terminated. As a result, the getPriceAsync method can return immediately, giving the caller thread a chance to perform other useful computations in the meantime. The newCompletableFuture class gives you various possibilities to implement this method in an easy way, for example, as shown in the next listing.
Listing 11.4. Implementing the getPriceAsync method

Here you create an instance of CompletableFuture, representing an asynchronous computation and containing a result when it becomes available. Then you fork a different Thread that will perform the actual price calculation and return the Future instance without waiting for that long-lasting calculation to terminate. When the price of the requested product is finally available, you can complete the Completable-Future using its complete method to set the value. Obviously this feature also explains the name of this new Future implementation. A client of this API can invoke it, as shown in the next listing.
Listing 11.5. Using an asynchronous API

As you can see, the client asks the shop to get the price of a certain product. Because the shop provides an asynchronous API, this invocation almost immediately returns the Future, through which the client can retrieve the product’s price at a later time. This allows the client to do other tasks, like querying other shops, instead of remaining blocked waiting for the first shop to produce the requested result. Later, when there are no other meaningful jobs that the client could do without having the product price, it can invoke get on the Future. By doing so the client either unwraps the value contained in the Future (if the asynchronous task is already finished) or remains blocked until that value is available. The output produced by the code in listing 11.5 could be something like this:
Invocation returned after 43 msecs
Price is 123.26
Price returned after 1045 msecs
You can see that the invocation of the getPriceAsync method returns far sooner than when the price calculation eventually finishes. In section 11.4 you’ll learn that it’s also possible for the client to avoid any risk of being blocked. Instead it can just be notified when the Future is completed, and execute a callback code, defined through a lambda expression or a method reference, only when the result of the computation is available. For now we’ll address another problem: how to correctly manage the possibility of an error occurring during the execution of the asynchronous task.
11.2.2. Dealing with errors
The code we developed so far works correctly if everything goes smoothly. But what happens if the price calculation generates an error? Unfortunately, in this case you’ll get a particularly negative outcome: the exception raised to signal the error will remain confined in the thread, which is trying to calculate the product price, and will ultimately kill it. As a consequence, the client will remain blocked forever, waiting for the result of the get method to arrive.
The client can prevent this problem by using an overloaded version of the get method that also accepts a timeout. It’s a good practice to always use a timeout to avoid similar situations elsewhere in your code. This way the client will at least avoid waiting indefinitely, but when the timeout expires, it will just be notified with a TimeoutException. As a consequence, it won’t have a chance to discover what really caused that failure inside the thread that was trying to calculate the product price. To make the client aware of the reason the shop wasn’t able to provide the price of the requested product, you have to propagate the Exception that caused the problem inside the CompletableFuture through its completeExceptionally method. This refines listing 11.4 to give the code shown in the listing that follows.
Listing 11.6. Propagating an error inside the CompletableFuture

The client will now be notified with an ExecutionException (which takes an Exception parameter containing the cause—the original Exception thrown by the price calculation method). So, for example, if that method throws a RuntimeException saying “product not available,” the client will get an ExecutionException like the following:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: product not available
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:2237)
at lambdasinaction.chap11.AsyncShopClient.main(AsyncShopClient.java:14)
... 5 more
Caused by: java.lang.RuntimeException: product not available
at lambdasinaction.chap11.AsyncShop.calculatePrice(AsyncShop.java:36)
at lambdasinaction.chap11.AsyncShop.lambda$getPrice$0(AsyncShop.java:23)
at lambdasinaction.chap11.AsyncShop$$Lambda$1/24071475.run(Unknown Source)
at java.lang.Thread.run(Thread.java:744)
Creating a CompletableFuture with the supplyAsync factory method
Until now you’ve created CompletableFutures and completed them programmatically, when it seemed convenient to do so, but the CompletableFuture class itself comes with lots of handy factory methods that can make this process far easier and less verbose. For example, thesupplyAsync method can let you rewrite the getPriceAsync method in listing 11.4 with a single statement, as shown in the following listing.
Listing 11.7. Creating a CompletableFuture with the supplyAsync factory method
public Future<Double> getPriceAsync(String product) {
return CompletableFuture.supplyAsync(() -> calculatePrice(product));
}
The supplyAsync method accepts a Supplier as argument and returns a Completable-Future that will be asynchronously completed with the value obtained by invoking that Supplier. This Supplier will be run by one of the Executors in the ForkJoinPool, but you can specify a different Executor by passing it as a second argument to the overloaded version of this method. More generally, it’s possible to optionally pass an Executor to all other CompletableFuture factory methods, and you’ll use this capability in section 11.3.4, where we demonstrate that using an Executor that fits the characteristics of your application can have a positive effect on its performance.
Also note that the CompletableFuture returned by the getPriceAsync method in listing 11.7 is totally equivalent to the one you created and completed manually in listing 11.6, meaning it provides the same error management you carefully added.
For the rest of this chapter, we’ll suppose you sadly have no control over the API implemented by the Shop class and that it provides only synchronous blocking methods. This is also what typically happens when you want to consume an HTTP API provided by some service. You’ll learn how it’s still possible to query multiple shops asynchronously, thus avoiding becoming blocked on a single request and thereby increasing the performance and the throughput of your best-price-finder application.
11.3. Make your code non-blocking
So you’ve been asked to develop a best-price-finder application, and all the shops you have to query provide only the same synchronous API implemented as shown at the beginning of section 11.2. In other words, you have a list of shops, like this one:
List<Shop> shops = Arrays.asList(new Shop("BestPrice"),
new Shop("LetsSaveBig"),
new Shop("MyFavoriteShop"),
new Shop("BuyItAll"));
You have to implement a method with the following signature, that given the name of a product returns a List of strings, where each string contains the name of a shop and the price of the requested product in that shop:
public List<String> findPrices(String product);
Your first idea will probably be to use the Stream features you learned in chapters 4, 5, and 6. You may be tempted to write something like what’s shown in the next listing (yes, it’s good if you’re already thinking this first solution is bad!).
Listing 11.8. A findPrices implementation sequentially querying all the shops
public List<String> findPrices(String product) {
return shops.stream()
.map(shop -> String.format("%s price is %.2f",
shop.getName(), shop.getPrice(product)))
.collect(toList());
}
Okay, this was straightforward. Now try to put the method findPrices to work with the only product you want madly these days (yes, you guessed it; it’s the myPhone27S). In addition, record how long the method takes to run, as shown in the following listing; this will let you compare its performance with the improved method we develop later.
Listing 11.9. Checking findPrices correctness and performance
long start = System.nanoTime();
System.out.println(findPrices("myPhone27S"));
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("Done in " + duration + " msecs");
The code in listing 11.9 produces output like this:
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price is 214.13, BuyItAll price is 184.74]
Done in 4032 msecs
As you may have expected, the time taken by the findPrices method to run is just a few milliseconds longer than 4 seconds, because the four shops are queried sequentially and blocking one after the other, and each of them takes 1 second to calculate the price of the requested product. How can you improve on this result?
11.3.1. Parallelizing requests using a parallel Stream
After reading chapter 7, the first and quickest improvement that should occur to you would be to avoid this sequential computation using a parallel Stream instead of a sequential, as shown in the next listing.
Listing 11.10. Parallelizing the findPrices method

Find out if this new version of findPrices is any better by again running the code in listing 11.9:
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price is 214.13, BuyItAll price is 184.74]
Done in 1180 msecs
Well done! It looks like this was a simple but very effective idea: now the four different shops are queried in parallel, so it takes in total just a bit more than a second to complete. Can you do even better? Let’s try to turn all the synchronous invocations to the different shops in thefindPrices method into asynchronous invocations, using what you learned so far about CompletableFutures.
11.3.2. Making asynchronous requests with CompletableFutures
You saw that you can use the factory method supplyAsync to create Completable-Future objects. Let’s use it:
List<CompletableFuture<String>> priceFutures =
shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f",
shop.getName(), shop.getPrice(product))))
.collect(toList());
Using this approach, you obtain a List<CompletableFuture<String>>, where each CompletableFuture in the List will contain the String name of a shop when its computation is completed. But because the findPrices method you’re trying to reimplement usingCompletableFutures has to return just a List<String>, you’ll have to wait for the completion of all these futures and extract the value they contain before returning the List.
To achieve this result, you can apply a second map operation to the original List<CompletableFuture<String>>, invoking a join on all the futures in the List and then waiting for their completion one by one. Note that the join method of the CompletableFuture class has the same meaning as the get method also declared in the Future interface, with the only difference being that join doesn’t throw any checked exception. By using it you don’t have to bloat the lambda expression passed to this second map with a try/catch block. Putting everything together, you can rewrite the findPrices method as follows.
Listing 11.11. Implementing the findPrices method with CompletableFutures

Note that you use two separate stream pipelines, instead of putting the two map operations one after the other in the same stream-processing pipeline—and for a very good reason. Given the lazy nature of intermediate stream operations, if you had processed the stream in a single pipeline, you would have succeeded only in executing all the requests to different shops synchronously and sequentially. This is because the creation of each CompletableFuture to interrogate a given shop would start only when the computation of the previous one had completed, letting the joinmethod return the result of that computation. Figure 11.4 clarifies this important detail.
Figure 11.4. Why Stream's laziness causes a sequential computation and how to avoid it
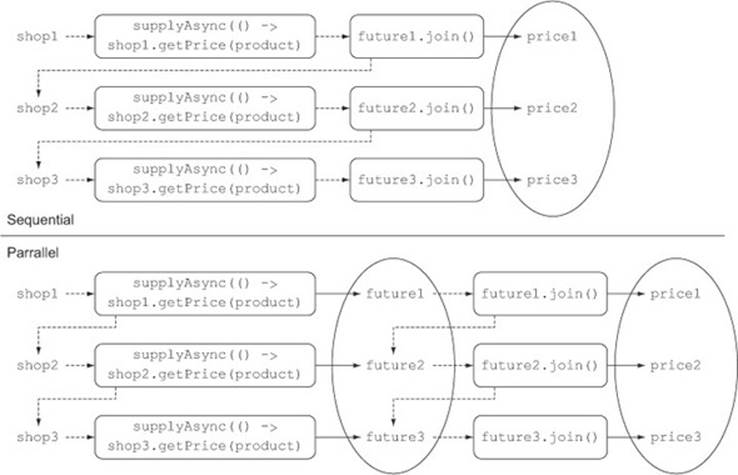
The top half of figure 11.4 shows that processing the stream with a single pipeline implies the evaluation order (identified by the dotted line) is sequential. In fact, a new CompletableFuture is created only after the former one has been completely evaluated. Conversely, the bottom half of the figure demonstrates how gathering the CompletableFutures in a list first, represented by the oval, allows all of them to start before waiting for their completion.
Running the code in listing 11.11 to check the performance of this third version of the findPrices method, you could obtain output along the lines of this:
[BestPrice price is 123.26, LetsSaveBig price is 169.47, MyFavoriteShop price is 214.13, BuyItAll price is 184.74]
Done in 2005 msecs
This is quite disappointing, isn’t it? More than 2 seconds means this implementation using CompletableFutures is faster than the original naïve sequential and blocking implementation from listing 11.8. But it’s also almost twice as slow as the previous implementation using a parallel stream. Moreover, it’s even more disappointing considering you obtained the parallel stream version with a trivial change to the sequential version.
In comparison, our newer version using CompletableFutures required quite a bit of work! But is this the whole truth? Is using CompletableFutures in this scenario really a waste of time? Or are we perhaps overlooking something important? Take a few minutes before going forward, particularly recalling that you’re testing the code samples on a machine capable of running four threads in parallel.[1]
1 If you’re using a machine capable of running more threads in parallel (for example, eight), then it will require more shops and processes in parallel to reproduce the behavior shown in these pages.
11.3.3. Looking for the solution that scales better
The parallel stream version performs so well only because it can run four tasks in parallel, so it’s able to allocate exactly one thread for each shop. But what happens if you decide to add a fifth shop to the list of shops crawled by your best-price-finder application? Not surprisingly, now the sequential version requires just a bit more than 5 seconds to run, as shown in the following output:

Unfortunately, the parallel stream version will also now require a whole second more than before, because all four threads it can run in parallel (available in the common thread pool) are now busy with the first four shops. The fifth query will have to wait for the completion of one of the former operations to free up a thread, as shown here:

What about the CompletableFuture version? Let’s also give it a try with the additional fifth shop:

The CompletableFuture version seems just a bit faster than the one using parallel stream. But this last version isn’t satisfying either. For instance, if you try to run your code with nine shops, the parallel stream version takes 3143 milliseconds, whereas the CompletableFuture one requires 3009 milliseconds. They look equivalent and for a very good reason: they both internally use the same common pool that by default has a fixed number of threads equal to the one returned by Runtime.getRuntime() .availableProcessors(). Nevertheless, CompletableFutures have an advantage because, in contrast to what’s offered by the parallel Streams API, they allow you to specify a different Executor to submit their tasks to. This allows you to configure this Executor, and in particular to size its thread pool, in a way that better fits the requirements of your application. Let’s see if you can translate this better level of configurability into practical performance gain for your application.
11.3.4. Using a custom Executor
In this case, a sensible choice seems to be to create an Executor with a number of threads in its pool that takes into account the actual workload you could expect in your application, but how do you correctly size it?
Sizing thread pools
In the great book Java Concurrency in Practice (http://mng.bz/979c), Brian Goetz and coauthors give some advice to find the optimal size for a thread pool. This is important because if the number of threads in the pool is too big, they’ll end up competing for scarce CPU and memory resources, wasting their time performing context switching. Conversely, if this number is too small (as it very likely is in your application), some of the cores of the CPU will remain underutilized. In particular, Goetz suggests that the right pool size to approximate a desired CPU utilization rate can be calculated with the following formula:
Nthreads = NCPU * UCPU * (1 + W/C)
where
· NCPU is the number of cores, available through Runtime.getRuntime().availableProcessors()
· UCPU is the target CPU utilization (between 0 and 1), and
· W/C is the ratio of wait time to compute time
The application is spending about the 99% of the time waiting for the shops’ responses, so you could estimate a W/C ratio of 100. This means that if your target is 100% CPU utilization, you should have a pool with 400 threads. In practice it will be wasteful to have more threads than shops, because in doing so you’ll have threads in your pool that are never used. For this reason, you need to set up an Executor with a fixed number of threads equal to the number of shops you have to query, so there will be exactly one thread for each shop. But you must also set an upper limit of 100 threads in order to avoid a server crash for a larger number of shops, as shown in the following listing.
Listing 11.12. A custom Executor fitting our best-price-finder application

Note that you’re creating a pool made of daemon threads. A Java program can’t terminate or exit while a normal thread is executing, so a leftover thread waiting for a never-satisfiable event causes problems. By contrast, marking a thread as a daemon means it can be killed on program termination. There’s no performance difference. You can now pass the new Executor as the second argument of the supplyAsync factory method. For example, you should now create the CompletableFuture retrieving the price of the requested product from a given shop as follows:
CompletableFuture.supplyAsync(() -> shop.getName() + " price is " +
shop.getPrice(product), executor);
After this improvement, the solution using the CompletableFutures takes only 1021 ms to process five shops and 1022 ms to process nine. In general this trend carries on until the number of shops reaches that threshold of 400 we calculated earlier. This demonstrates that it was a good idea to create an Executor that better fits the characteristics of your application and to make use of CompletableFutures to submit their tasks to it. This is almost always an effective strategy and something to consider when making intensive use of asynchronous operations.
Parallelism—via Streams or CompletableFutures?
You’ve now seen two different ways to do parallel computing on a collection: either convert it to a parallel stream and use operations like map on it, or iterate over the collection and spawn operations within a CompletableFuture. The latter provides more control using resizing of thread pools, which helps ensure that your overall computation doesn’t block just because all of your fixed number of threads are waiting for I/O.
Our advice for using these APIs is as follows:
· If you’re doing computation-heavy operations with no I/O, then the Stream interface gives the simplest implementation and one likely to be the most efficient (if all threads are compute-bound, then there’s no point in having more threads than processor cores).
· On the other hand, if your parallel units of work involve waiting for I/O (including network connections), then CompletableFutures give more flexibility and the ability to match the number of threads to the wait/computer, or W/C, ratio as discussed previously. Another reason to avoid using parallel streams when I/O waits are involved in the stream-processing pipeline is that the laziness of streams can make it harder to reason about when the waits actually happen.
You’ve learned how to take advantage of CompletableFutures both to provide an asynchronous API to your clients and as the client of a synchronous but slow server. But we performed only a single time-consuming operation in each Future. In the next section, you’ll see how you can use CompletableFutures to pipeline multiple asynchronous operations, in a declarative style similar to what you’ve already learned using the Streams API.
11.4. Pipelining asynchronous tasks
Let’s now suppose that all the shops have agreed to use a centralized discount service. This service uses five different discount codes, and each code has a different discount percentage. You represent this idea by defining a Discount.Code enumeration, as shown in the following listing.
Listing 11.13. An enumeration defining the discount codes
public class Discount {
public enum Code {
NONE(0), SILVER(5), GOLD(10), PLATINUM(15), DIAMOND(20);
private final int percentage;
Code(int percentage) {
this.percentage = percentage;
}
}
// Discount class implementation omitted, see Listing 11.14
}
Also suppose the shops have agreed to change the format of the result of the getPrice method. It now returns a String in the format ShopName:price:DiscountCode. Our sample implementation will return a random Discount.Code together with the random price already calculated:
public String getPrice(String product) {
double price = calculatePrice(product);
Discount.Code code = Discount.Code.values()[
random.nextInt(Discount.Code.values().length)];
return String.format("%s:%.2f:%s", name, price, code);
}
private double calculatePrice(String product) {
delay();
return random.nextDouble() * product.charAt(0) + product.charAt(1);
}
Invoking getPrice might then return a String such as
BestPrice:123.26:GOLD
11.4.1. Implementing a discount service
Your best-price-finder application should now obtain the prices from the different shops, parse the resulting Strings, and for each String, query the discount server’s needs. This process determines the final discounted price of the requested product (the actual discount percentage associated with each discount code could change, so this is why you query the server each time). We’ve encapsulated the parsing of the Strings produced by the shop in the following Quote class:
public class Quote {
private final String shopName;
private final double price;
private final Discount.Code discountCode;
public Quote(String shopName, double price, Discount.Code code) {
this.shopName = shopName;
this.price = price;
this.discountCode = code;
}
public static Quote parse(String s) {
String[] split = s.split(":");
String shopName = split[0];
double price = Double.parseDouble(split[1]);
Discount.Code discountCode = Discount.Code.valueOf(split[2]);
return new Quote(shopName, price, discountCode);
}
public String getShopName() { return shopName; }
public double getPrice() { return price; }
public Discount.Code getDiscountCode() { return discountCode; }
}
You can obtain an instance of the Quote class, which contains the name of the shop, the nondiscounted price, and the discount code, by simply passing the String produced by a shop to the static parse factory method.
The Discount service will also have an applyDiscount method accepting a Quote object and returning a String stating the discounted price for the shop that produced that quote, as shown in the next listing.
Listing 11.14. The Discount service

11.4.2. Using the Discount service
Because the Discount service is a remote service, you again add a simulated delay of 1 second to it, as shown in the following listing. As you did in section 11.3, first try to reimplement the findPrices method to fit these new requirements in the most obvious (but sadly sequential and synchronous) way.
Listing 11.15. Simplest findPrices implementation that uses the Discount service

The desired result is obtained by pipelining three map operations on the stream of shops:
· The first operation transforms each shop into a String that encodes the price and discount code of the requested product for that shop.
· The second operation parses those Strings, converting each of them in a Quote object.
· Finally, the third one contacts the remote Discount service that will calculate the final discounted price and return another String containing the name of the shop with that price.
As you may imagine, the performance of this implementation will be far from optimal, but try to measure it, as usual, by running your benchmark:
[BestPrice price is 110.93, LetsSaveBig price is 135.58, MyFavoriteShop price is 192.72, BuyItAll price is 184.74, ShopEasy price is 167.28]
Done in 10028 msecs
As expected, it takes 10 seconds, because the 5 seconds used in sequentially querying the five shops is now added to the 5 seconds consumed by the discount service to apply the discount code to the prices returned by the five shops. You already know you can easily improve this result by converting the stream into a parallel one. However, you also learned in section 11.3 that this solution doesn’t scale very well when you increase the number of shops to be queried, due to the fixed common thread pool that streams rely on. Conversely, you learned that you could better utilize your CPU by defining a custom Executor that will schedule the tasks performed by the CompletableFutures.
11.4.3. Composing synchronous and asynchronous operations
Let’s try to reimplement the findPrices method asynchronously, again using the features provided by CompletableFuture. Here’s the code for it. Don’t worry if there’s something that looks unfamiliar; we explain it shortly.
Listing 11.16. Implementing the findPrices method with CompletableFutures

Things look a bit more complex this time, so try to understand what’s going on here, step by step. The sequence of these three transformations is depicted in figure 11.5.
Figure 11.5. Composing synchronous operations and asynchronous tasks
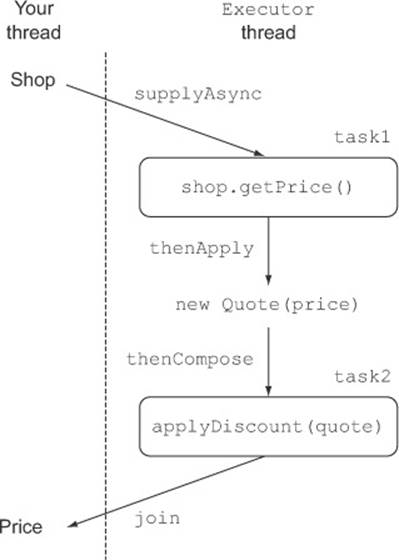
You’re performing the same three map operations as you did in the synchronous solution of listing 11.15, but you make those operations asynchronous when necessary, using the feature provided by the CompletableFuture class.
Getting the prices
You’ve already seen the first of these three operations in various examples in this chapter; you just query the shop asynchronously by passing a lambda expression to the supplyAsync factory method. The result of this first transformation is a Stream<Completable-Future<String>>, where each CompletableFuture will contain, once completed, the String returned by the corresponding shop. Note that you configure the CompletableFutures with the custom Executor developed in listing 11.12.
Parsing the quotes
Now you have to convert those Strings into Quotes with a second transformation. But because this parsing operation isn’t invoking any remote service or doing any I/O in general, it can be performed almost instantaneously and can be done synchronously without introducing any delay. For this reason, you implement this second transformation by invoking the thenApply method on the CompletableFutures produced by the first step and passing to it a Function converting a String into an instance of Quote.
Note that using the thenApply method doesn’t block your code until the Completable-Future on which you’re invoking it is completed. This means that when the Completable-Future finally completes, you want to transform the value it contains using the lambda expression passed to the then-Apply method, thus transforming each Completable-Future<String> in the stream into a corresponding CompletableFuture<Quote>. You can see this as building a recipe of what to do with the result of the CompletableFuture, just like when you were working with a stream pipeline.
Composing the futures for calculating the discounted price
The third map operation involves contacting the remote Discount service to apply the appropriate discount percentage to the nondiscounted prices received from the shops. This transformation is different from the previous one because it will have to be executed remotely (or, in this case, it will have to simulate the remote invocation with a delay), and for this reason you also want to perform it asynchronously.
To achieve this, as you did with the first invocation of supplyAsync with getPrice, you pass this operation as a lambda expression to the supplyAsync factory method, which will return another CompletableFuture. At this point you have two asynchronous operations, modeled with two distinct CompletableFutures, that you want to perform in a cascade:
· Retrieve the price from a shop and then transform it into a Quote
· Take this Quote and pass it to the Discount service to obtain the final discounted price
The Java 8 CompletableFutures API provides the thenCompose method specifically for this purpose, allowing you to pipeline two asynchronous operations, passing the result of the first operation to the second operation when it becomes available. In other words, you can compose twoCompletableFutures by invoking the thenCompose method on the first CompletableFuture and passing to it a Function. This Function has as argument the value returned by that first CompletableFuture when it completes, and it returns a second CompletableFuture that uses the result of the first as input for its computation. Note that with this approach, while the Futures are retrieving the quotes from the different shops, the main thread can perform other useful operations such as responding to UI events.
Collecting the elements of the Stream resulting from these three map operations into a List, you obtain a List<CompletableFuture<String>>, and finally you can wait for the completion of those CompletableFutures and extract their values using join, exactly as you did inlisting 11.11. This new version of the findPrices method implemented in listing 11.8 might produce output like this:
[BestPrice price is 110.93, LetsSaveBig price is 135.58, MyFavoriteShop price is 192.72, BuyItAll price is 184.74, ShopEasy price is 167.28]
Done in 2035 msecs
The thenCompose method you used in listing 11.16, like other methods of the Completable-Future class, also has a variant with an Async suffix, thenComposeAsync. In general, a method without the Async suffix in its name executes its task in the same thread as the previous task, whereas a method terminating with Async always submits the succeeding task to the thread pool, so each of the tasks can be handled by a different thread. In this case, the result of the second CompletableFuture depends on the first, so it makes no difference to the final result or to its broad-brush timing whether you compose the two CompletableFutures with one or the other variant of this method. We chose to use the one with thenCompose only because it’s slightly more efficient due to less thread-switching overhead.
11.4.4. Combining two CompletableFutures—dependent and independent
In listing 11.16, you invoked the thenCompose method on one CompletableFuture and passed to it a second CompletableFuture, which needed as input the value resulting from the execution of the first. But another frequently occurring case is where you need to combine the results of the operations performed by two completely independent CompletableFutures, and you don’t want to wait for the first to complete before starting on the second.
In situations like this, use the thenCombine method; this takes as second argument a BiFunction, which defines how the results of the two CompletableFutures are to be combined when they both become available. Just like thenCompose, the thenCombine method also comes with an Async variant. In this case, using the thenCombineAsync method will cause the combination operation defined by the BiFunction to be submitted to the thread pool and then executed asynchronously in a separate task.
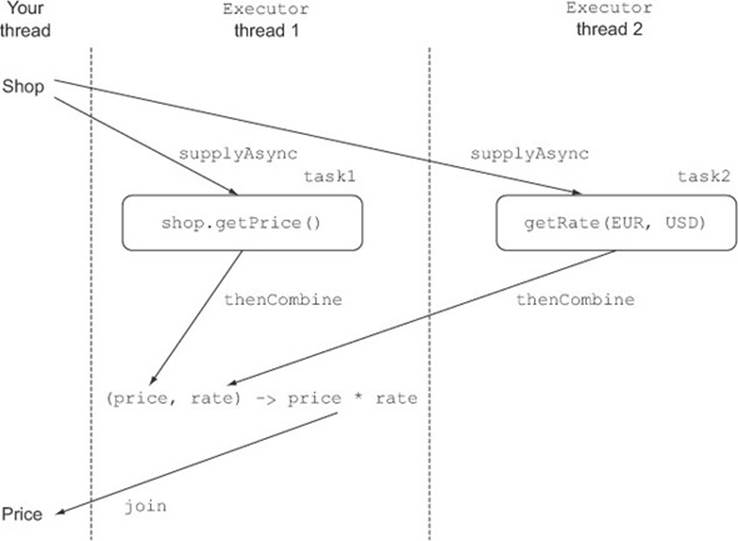
Turning to our running example, you may know that one of the shops provides prices in €(EUR), but you always want to communicate them in $ (USD) to your customers. You can asynchronously ask the shop the price of a given product and retrieve, from a remote exchange-rate service, the current exchange rate between € and $. After both have completed, you can combine the results by multiplying the price by the exchange rate. With this approach, you’ll obtain a third CompletableFuture that will complete when the results of the two CompletableFutures are both available and have been combined using the BiFunction, as done in the following listing.
Listing 11.17. Combining two independent CompletableFutures

Here, because the combination operation is a simple multiplication, performing it in a separate task would have been a waste of resources, so you need to use the then-Combine method instead of its asynchronous thenCombineAsync counterpart. Figure 11.6 shows how the different tasks created in listing 11.17 are executed on the different threads of the pool and how their results are combined.
Figure 11.6. Combining two independent asynchronous tasks
11.4.5. Reflecting on Future vs. CompletableFuture
The last two examples in listings 11.16 and 11.17 clearly show one of the biggest advantages of CompletableFutures over the other pre-Java 8 Future implementations. CompletableFutures use lambda expressions to provide a declarative API that offers the possibility of easily defining a recipe that combines and composes different synchronous and asynchronous tasks to perform a complex operation in the most effective way. To get a more tangible idea of the code readability benefits of Completable-Future, try to obtain the same result of listing 11.17 purely in Java 7. Listing 11.18 shows you how to do it.
Listing 11.18. Combining two Futures in Java 7

In listing 11.18, you create a first Future, submitting a Callable to an Executor querying an external service to find the exchange rate between EUR and USD. Then you create a second Future, retrieving the price in EUR of the requested product for a given shop. Finally, as you did inlisting 11.17, you multiply the exchange rate by the price in the same future that also queried the shop to retrieve the price in EUR. Note that using thenCombineAsync instead of thenCombine in listing 11.17 would have been equivalent to performing the price by rate multiplication in a third Future in listing 11.18. The difference between these two implementations might seem small, but this is because you’re just combining two Futures. Listings 11.19 and 11.20 show how easy it is to create a pipeline that mixes synchronous and asynchronous operations, and the advantages of this declarative style are more evident when the number of tasks to be performed and results to be combined increases.
You’re almost finished with your best-price-finder application, but there’s still one ingredient missing. You’d like to show your users the prices provided by the different shops as soon as they become available (car insurance or flight-comparison websites typically do this), instead of waiting for all the price requests to complete, as you did until now. In the next section, you’ll discover how to achieve this by reacting to the completion of a CompletableFuture instead of invoking get or join on it and thereby remaining blocked until the CompletableFuture itself completes.
11.5. Reacting to a CompletableFuture completion
In all the code examples you’ve seen in this chapter, you simulated methods doing remote invocations with a 1-second delay in their response. Nevertheless, in a real-world scenario, the various remote services you need to contact from your application are likely to have unpredictable delays, caused by everything from server load to network delays, and perhaps even how valuable the server regards your application’s business compared to other applications that perhaps pay more per query.
For these reasons it’s likely the prices of the products you want to buy will be available for some shops far earlier than for others. For the purpose of this section, we simulate this scenario in the following listing by introducing a random delay between 0.5 and 2.5 seconds, using therandomDelay method instead of the previous delay method that always waited 1 second.
Listing 11.19. A method to simulate a random delay between 0.5 and 2.5 seconds
private static final Random random = new Random();
public static void randomDelay() {
int delay = 500 + random.nextInt(2000);
try {
Thread.sleep(delay);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
Until now, you’ve implemented the findPrices method so it shows the prices provided by the different shops only when all of them are available. What you want to do now is have the best-price-finder application display the price for a given shop as soon as it becomes available, without waiting for the slowest one (which perhaps even times out). How can you achieve this further improvement?
11.5.1. Refactoring the best-price-finder application
The first thing to avoid is waiting for the creation of a List already containing all the prices. You’ll need to work directly with the stream of CompletableFutures, where each CompletableFuture is executing the sequence of operations necessary for a given shop. To do this, in the next listing you’ll refactor the first part of the implementation from listing 11.12 into a findPricesStream method to produce this stream of CompletableFutures.
Listing 11.20. Refactoring the findPrices method to return a stream of Futures
public Stream<CompletableFuture<String>> findPricesStream(String product) {
return shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> shop.getPrice(product), executor))
.map(future -> future.thenApply(Quote::parse))
.map(future -> future.thenCompose(quote ->
CompletableFuture.supplyAsync(
() -> Discount.applyDiscount(quote), executor)));
}
At this point, you add a fourth map operation on the Stream returned by the findPricesStream method to the three already performed inside that method. This new operation simply registers an action on each CompletableFuture; this action consumes the value of theCompletableFuture as soon as it completes. The Java 8 CompletableFuture API provides this feature via the thenAccept method, which take as argument a Consumer of the value with which it completes. In this case, this value is the String returned by the discount services and containing the name of a shop together with the discounted price of the requested product for that shop, and the only action you want to perform to consume this value is to print it:
findPricesStream("myPhone").map(f -> f.thenAccept(System.out::println));
Note that, as you’ve already seen for the thenCompose and thenCombine methods, the thenAccept method also has an Async variant named thenAcceptAsync. The Async variant schedules the execution of the Consumer passed to it on a new thread from the thread pool instead of directly performing it using the same thread that completed the CompletableFuture. Because you want to avoid an unnecessary context switch, and more importantly you want to react to the completion of the CompletableFuture as soon as possible (instead of risking having to wait for a new thread to be available), you don’t use this variant here.
Because the thenAccept method already specifies how to consume the result produced by the CompletableFuture when it becomes available, it returns a Completable-Future<Void>. As a result, the map operation will return a Stream-<Completable-Future<Void>>. There’s not much you can do on a Completable-Future<Void> except wait for its completion, but this is exactly what you need. You also want to give the slowest shop a chance to provide its response and print its returned price. To do this, you can put all the CompletableFuture<Void>s of the stream into an array and then wait for the completion of all of them, as in the following listing.
Listing 11.21. Reacting to CompletableFuture completion
CompletableFuture[] futures = findPricesStream("myPhone")
.map(f -> f.thenAccept(System.out::println))
.toArray(size -> new CompletableFuture[size]);
CompletableFuture.allOf(futures).join();
The allOf factory method takes as input an array of CompletableFutures and returns a CompletableFuture<Void> that’s completed only when all the CompletableFutures passed have completed. This means that invoking join on the CompletableFuture returned by theallOf method provides an easy way to wait for the completion of all the CompletableFutures in the original stream. This is useful for the best-price-finder application because it can then display a message saying “All shops returned results or timed out,” so a user doesn’t keep wondering whether more prices might become available.
Conversely, in other applications you may wish to wait for the completion of only one of the CompletableFutures in an array, perhaps if you’re consulting two currency-exchange servers and are happy to take the result of the first to respond. In this case, you can similarly use the anyOffactory method. As a matter of detail, this method takes as input an array of CompletableFutures and returns a Completable-Future<Object> that completes with the same value as the first-to-complete CompletableFuture.
11.5.2. Putting it to work
As we discussed at beginning of this section, you’ll now suppose that all the methods simulating a remote invocation will use the randomDelay method of listing 11.19, introducing a random delay distributed between 0.5 and 2.5 seconds instead of a delay of 1 second. Running the code inlisting 11.21 with this change, you’ll see that the prices provided by the different shops don’t appear all at the same time as happened before but are printed incrementally as soon as the discounted price for a given shop is available. To make the result of this change more obvious, we slightly modified the code to report a timestamp showing the time taken for each price to be calculated:
long start = System.nanoTime();
CompletableFuture[] futures = findPricesStream("myPhone27S")
.map(f -> f.thenAccept(
s -> System.out.println(s + " (done in " +
((System.nanoTime() - start) / 1_000_000) + " msecs)")))
.toArray(size -> new CompletableFuture[size]);
CompletableFuture.allOf(futures).join();
System.out.println("All shops have now responded in "
+ ((System.nanoTime() - start) / 1_000_000) + " msecs");
Running this code produces output similar to the following:
BuyItAll price is 184.74 (done in 2005 msecs)
MyFavoriteShop price is 192.72 (done in 2157 msecs)
LetsSaveBig price is 135.58 (done in 3301 msecs)
ShopEasy price is 167.28 (done in 3869 msecs)
BestPrice price is 110.93 (done in 4188 msecs)
All shops have now responded in 4188 msecs
You can see that, due to the effect of the random delays, the first price is now printed more than twice as fast as the last!
11.6. Summary
In this chapter, you learned the following:
· Executing relatively long-lasting operations using asynchronous tasks can increase the performance and responsiveness of your application, especially if it relies on one or more remote external services.
· You should consider providing an asynchronous API to your clients. You can easily implement it using CompletableFutures features.
· A CompletableFuture also allows you to propagate and manage errors generated within an asynchronous task.
· You can asynchronously consume from a synchronous API by simply wrapping its invocation in a CompletableFuture.
· You can compose or combine multiple asynchronous tasks both when they’re independent and when the result of one of them is used as the input to another.
· You can register a callback on a CompletableFuture to reactively execute some code when the Future completes and its result becomes available.
· You can determine when all values in a list of CompletableFutures have completed, or alternatively you can wait for just the first to complete.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.