Client-Server Web Apps with JavaScript and Java (2014)
Chapter 8. API Design
In theory, there is no difference between theory and practice. But, in practice, there is.
—Author Unknown
There are two basic ways to solve problems: start with a comprehensive theory and work out the details, or start with particular facts and develop a theory that ties them together. “Detail people” derive solutions by studying the minutiae of a particular problem. “Big-picture people” fit problems into categories that relate to their overarching theories. Each approach has value, and much problem-solving involves adeptly switching between them.
WAXING PHILOSOPHICAL
In philosophy, Plato describes “universals” as abstracted to the highest and most fundamental “realm of ideas.” His student Aristotle instead finds them in specific, particular, real-world things. These starting points are more than an intellectual curiosity. In design analysis, starting points affect the ultimate outcome of the process. The best solutions are often the result of both approaches being applied in a complementary manner. These ancient starting points are related to modern data science techniques by the authors of The Handbook of Statistical Analysis and Data Mining Applications (Elsevier):
Traditional statistical analysis follows the deductive method in the search for relationships in data sets. Artificial intelligence (e.g., expert systems) and machine learning techniques (e.g., neural nets and decision trees) follow the inductive method to find faint patterns of relationship in data sets. Deduction (or deductive reasoning) is the Aristotelian process of analyzing detailed data, calculating a number of metrics, and forming some conclusions based (or deduced) solely on the mathematics of those metrics. Induction is the more Platonic process of using information in a data set as a “spring board” to make general conclusions, which are not wholly contained directly in the input data.
REST and practical web API design are representative of these starting points as well. REST was articulated by Roy Fielding in purely abstract terms. RESTful web APIs, while inspired by the ideals of REST, are created to solve specific problems and accept implementation details that don’t fit the theory in its purest form. Much of the disagreement that occurs in discussions concerning REST can be traced to the starting points chosen consciously or unconsciously by each party.
Obviously, REST does specify constraints that provide immediate practical value for web API authors. The discrete division between client and server tiers, the use of HTTP verbs, and identification of web resources have been clearly demonstrated to be useful in the creation of a variety of real-world web APIs. The fact remains that HATEOAS, while theoretically compelling, has proved difficult to implement consistently. It is especially challenging to reconcile due to the widespread adoption of JSON as the de facto data transport format for web APIs.
A Decision to Design
Although web services have existed in one form or another for years, the shift to using them as a foundational design element did not occur immediately. The gradual adoption of Ajax and the creation of JSON and related lightweight web APIs initially impacted existing systems built on server-side MVC. As developers pushed the limits of these technologies to create sophisticated single-page applications, it became clear that an server-driven MVC approach did not adapt well to pervasive use of the new technologies. This lead to a fundamental change to the design of web applications that broke continuity with previous practices. See Figure 8-1 for a timeline illustrating the technological progress that led to client-server-style web applications.
A SHIFT TO A CLIENT-SERVER APPROACH
The technologies used in a client-server approach to web development are not new. The programming languages used have matured but are not fundamentally different, and servers, browsers, and the HTTP protocol have been around since the Web was created. However, the design methodology applied in a consistent manner is a more recent development and is largely a result of various technologies being developed.
The first web pages were simple, static content served by web servers and rendered in browsers. Dynamic content was introduced in the mid-1990s as CGI programs on the server and JavaScript in the browser. JavaScript was relatively slow, and client computers were not powerful, so the focus was on utilizing server-side processing to create dynamic content. The complexities involved resulted in the introduction of patterns such as Model-View-Controller (MVC) to the server side.
The MVC pattern remains a staple of server-side Java development and appears in major standards like JEE and frameworks like Spring. Further JavaScript innovations like Ajax and JSON immediately influenced server-side MVC developers, who used these technologies in an ad hoc, piecemeal manner. Frameworks have not disappeared, but their design and use has been significantly affected. In terms of design, MVC frameworks like Spring have adopted “pretty URLs” that reflect resources being acted on. In terms of use, APIs can of course be used in conjunction with traditional MVC. Regardless of the framework in use, many applications today are based on web APIs without MVC, which is effectively a client-server approach.
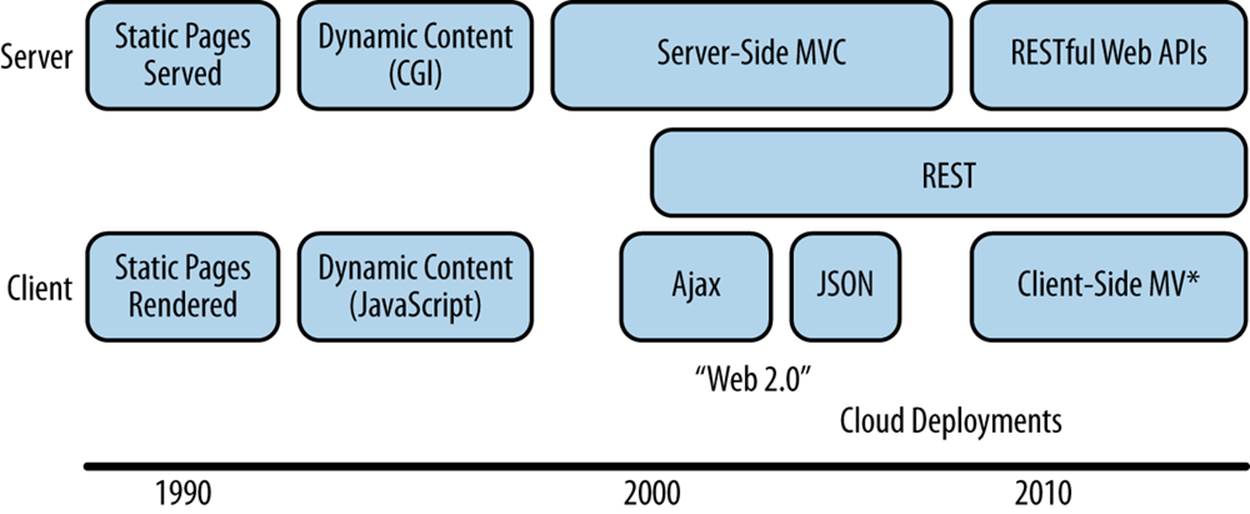
Figure 8-1. History of technologies related to client-server web development
A client-server approach involves a specific design decision to develop RESTful web APIs to deliver data to client-side views and to avoid generating views server-side. This begs the question of how to best design web APIs in a consistent, supportable manner. Design decisions of this type always elicit a range of opinions, but there is a fairly established consensus. The general agreement is that web APIs should be significantly influenced by REST without being rigidly restricted by controversial or impractical constraints.
Practical Web APIs Versus RESTful APIs
While what is practical might be subject to interpretation, there is widespread agreement that web APIs should be easy to use. They should be easily understood by an outside developer, consistent, predictable, and conform to many parts of REST. Implementation of certain aspects of REST provides this kind of ease-of-use by design. This is despite the fact that REST was not originally specified with any particular intention about short-term productivity or developer ease-of-use as it is sometimes understood.
ROY SAYS…
REST is software design on the scale of decades: every detail is intended to promote software longevity and independent evolution. Many of the constraints are directly opposed to short-term efficiency.
—Roy Fielding
So which parts of REST are most easily applied in a practical manner? The consistent identification of resources as nouns that are acted upon by HTTP verbs is fundamental to REST, and especially clear in applications that rely on CRUD operations. “Pretty URLs” are one result of such identification. REST makes no specific demands involving performance but does reference cachable resources that promote systems that perform and scale well. And of course, the clear client-server distinction is of immense value as described in previous chapters. REST has been so influential because its very design tends to promote development of applications in concert with the design of the Web itself. Well-engineered applications that can be easily understood and extended result when these parts of REST are in use.
There are qualities of practical web API design that do conflict with REST. Most notably, the use of JSON leads to a lack of linkability defined in the media type itself. The use of a media type that is not linkable immediately results in an API that is not self-describing, and therefore requires documentation. What is perhaps even more challenging is determining a course of action when considering areas not directly touched upon in REST. Securing and supporting changes to APIs are relevant topics outside of the scope of REST.
Even though Fielding does not address all issues related to web API design, he does make many observations that are applicable in other areas. For example, though ease-of-reading for an API response is not a particular concern of REST itself, Fielding highlights the lack of visibility incurred when using solutions like Java applets. This concern could imply that in many situations, formatted JSON would be beneficial. The clarity provided to a client-side developer often outweighs the few spaces saved in a compacted message (not to mention that server compression is more effective for improving transport size and performance).
REST was conceived of as an abstract model. Abstract models stand outside of space and time. As such, it does not directly take into account the fact that systems change over time. The ease-of-use value suggests that changes should be made in a manner that is backward compatible if possible. Versioning of APIs provides a great deal of flexibility in this area.
Recall that one of the constraints of REST is a uniform interface. A uniform interface is almost completely self-describing. Ideally, a system with such an interface needs no documentation beyond a system entry point. This is a stark contrast to protocols like SOAP, which often include a Web Services Description Language (WSDL) to describe a web service’s functionality. A RESTful system would provide links to all resources and not require any additional description. In practice, web APIs are far more usable if they are well documented.
Guidelines
Unlike technologies whose specifications are dictated by standards committees, web APIs can be constructed at the whim of a developer. In practice, it makes sense to create APIs that conform to the expectations of the broader development community. The following sections reflect the significant influence of REST on development of lightweight web services. They are suggested guidelines for designing easily understandable and usable web APIs.
Nouns as Resources; Verbs as HTTP Actions
As dictated by REST, resources are nouns. Nouns in a RESTful system are represented in the URL path and are used to manipulate the resource referenced. Actions are verbs that correspond with functions and are used to manipulate the resources. Verbs in a RESTful system are specifically related to HTTP operations.
Resources correspond with objects, entities, or tables in other design approaches. Nouns are modeled as classes in UML class diagrams. They are modeled as entities, which are often later implemented as tables in relational databases in Entity Relationship Diagrams (ERDs).
NOTE
UML class diagrams and ERDs are related in that they are notations based on mathematical graphs, but include additional semantics to indicate what nodes and edges represent.
UML and ERDs are not unique in giving special attention to nouns. REST gives them a place of prominence as well. Table 8-1 shows the correspondence between these systems. In REST, nouns are represented as resources; in UML class diagrams, they are classes; and in ERDs, they are entities that are implemented as database tables. Methods used to decompose domains for presentation on class or ERD diagrams can be used when analyzing and modeling a system for a REST API. This is especially true in systems that map well to CRUD operations.
Table 8-1. Noun representation in modeling system
|
Architecture |
Entity that a noun represents |
|
Object-oriented class hierarchy |
Class |
|
Relational database |
Table |
|
REST API |
Resource |
When designing a system that includes CRUD operations, consider the applicability of every action on every resource. This can prevent the need to later change a system to include required functionality that was simply overlooked. For example, a blog engine might be modeled to include users, blog posts, and comments as resources. Most blog systems need to be able to create, read, and delete these resources. The ability to update a user or change a comment might not be necessary. Such a system is shown in Table 8-2, where the first column identifies the resources (nouns) and each row identifies the actions (verbs).
Table 8-2. Sample API design grid for a blog
|
Create |
Read |
Update |
Delete |
|
|
User |
x |
x |
x |
|
|
Post |
x |
x |
x |
x |
|
Comment |
x |
x |
x |
BUT I HAVE NO NOUNS…
REST model resources are a fundamental unit of the architecture. Analysis of REST resources using techniques similar to those used in UML class diagrams and ERDs map well to CRUD-type applications. An application that is not resource based might be thought of as a group of verbs. Such an application might be better represented as a series of remote procedure calls. This type of system cannot easily be represented in RESTful terms.
In many cases, such a system can be redesigned to be resource based, but this is not always possible. Abstractions might be good enough to model certain systems but insufficient for others.
Query Parameters as Modifiers
While nouns are significant parts of the URL, and verbs relate to HTTP actions, they do not tell the whole story. Other parts of a URL can include additional information. As is the case in the grammar of spoken languages, additional parts of speech are used to qualify or clarify the intent of nouns and verbs.
Query parameters can be useful when referencing a collection of resources. Parameters can be used to filter a collection to only return a subset of the set. They might return a selected number of resources, such as only the first 10. They can also be used to sort the results.
Pagination is a special case of filtering. Parameters can be used to explicitly reference a subset of returned results. Query parameters are better suited for limiting the set of data included in a collection request (serving as adjectives or adverbs, if you will). Pagination has implications beyond the use of query parameters, most notably, linking.
GitHub’s API provides a good, well-documented example of pagination parameters. The page parameter indicates which page of those available is returned, and the per_page parameter limits the results returned to 100:
curl https://api.github.com/user/repos?page=2&per_page=100
HTTP GETS WITH REQUEST BODIES
Request parameters tend to “uglify” URLs that were otherwise pretty. In some circumstances, it might be necessary to take an action that seems to map to an HTTP GET and yet involve a request object that is more easily defined as a hierarchical data structure. One example is the retrieval of a number of items that each require several fields for lookup. Roy Fielding and the HTTP spec seem to allow for it, though lack of any formal requirement for the server to parse the body suggests that while it works in many instances, this should not be used in a system as a long-term solution.
Web API Versions
REST does not demand that a web API be designed for updates and modifications, but its constraints tend to promote a system that is more easily changed. Versioning APIs is an important consideration not touched upon in Fielding’s thesis. Including a portion of a URL with a version number prevents changes to an API from disrupting client activities. Without versioning, it is necessary to coordinate a parallel upgrade to client-side code to account for server-side modifications (which in many cases is not even possible, let alone practical). Though a version identifier lacks theoretical simplicity and elegance, using one can greatly improve a system. Because there is a range of opinion on their usage and they are not self-describing, version segments in web API URLs need to be clearly called out and documented to be effective.
There is a range of opinion on where a version might be included. Some suggest that the version be included in the URL path. Others suggest that it be specified as a query parameter. Still others prefer that a version not clutter the URLs and suggest that it be communicated as an HTTP header.
HTTP Headers
A version identifier is only one of many uses for request and response headers. Other “out of band” information can be stored here as well. Twitter reports rate limit data in headers to alert a developer when her application is approaching a limit. ETags can be used to control caching, and other headers apply to security authentication and authorization. Headers are often used to communicate secondary but essential information. They don’t neatly fit into an abstract model, but they have many practical uses that need to be considered.
Accept and content type headers can be used to impact how the server responds to a request and what sort of response it provides. Besides the obvious differentiation between XML and JSON content, these are used to return padded JSON (JSONP) rather than straight JSON. This is part of the magic that allows JSON content to be sent to a remote server without violating cross-domain restrictions. In essence, it allows access to a JSON API by wrapping a JSON payload in a function call. An example of this is provided in the project later in this chapter.
Linking
Pagination presumes the ability to link to the previous and next resources relative to the subset being displayed. Some API designers recommend including the entire link for the next and previous page in the results of your API, while others recommend only the inclusion of IDs to save space and eliminate repeated text. While providing links is often a good decision and limits the need for additional documentation, strict HATEOAS is not practical or possible for every situation at this point.
Responses
Having an API that is self-describing is an excellent ideal. If resources are specified and reflected in the URLs and HTTP verbs are leveraged, this can be accomplished to a significant degree. Following convention in the use of HTTP response codes (for example, 400 reflects client concerns while 500 indicates server issues) will contribute to this as well. Ideally, your system’s error messages will provide immediate, actionable descriptions to address their triggers. But in most systems, some documentation will be needed at least in a few basic areas. Error codes and messages are often a bit terse. They should therefore be keyed to documentation. Ideally, errors will be described in documentation at a level that is impractical in a system error message (for instance, identifying each field in a PUT/POST/PATCH and the errors it can cause).
Documentation
Documentation should be easy to locate, search, and understand. One convention adopted by some web API developers is to use a Web Application Description Language (WADL), which is a machine-readable description of a web application, generally in XML format. These are often easy to locate, but will not be sufficient if simply generated by a utility. Providing examples that can be replicated by a developer using Curl at the command line can go a long way toward clarifying the intent of your API. If an API is directed toward third-party developers, even more attention will be required.
Documentation on RESTful web APIs will involve manual effort, but there are tools that can ease this burden by automatically generating documentation. Some servers create a WADL as a resource available from the web API server. For example, Jersey generates a basic WADL at runtime that you can request using a GET to /application.wadl. Additional information can be included in the WADL by specifying selected directives. If you are using a server that does not generate a WADL out of the box, a package like Enunciate can be added and configured for your project to generate one. There are also websites like http://apiary.io where you can design and document your API outside of the context of any specific project.
Formatting Conventions
Finally, following simple format conventions can make an API much more approachable. Developers need to actually view and read documents during initial development as well as ongoing support. Because JSON is JavaScript, it makes sense to follow idiomatic JavaScript practices like using camel case for naming fields.
Another simple practice is to pretty-print JSON responses to make it easier for people to read. The usual argument against this is that pretty-printing JSON increases the response side and hurts performance, but greater performance gains are possible by configuring JSON responses to be GZipped. The few spaces added in a formatted response can be worth the performance hit because developers can view returned responses without first formatting it in an IDE or using a command-line utility like jq.
Security
REST does not provide specific guidelines related to security. This is because it was designed with the assumption that APIs would be publicly available on the Internet. It is often also a good idea to serve APIs over HTTPS rather than HTTP. For APIs that are not intended to be restricted to a server, a JSON API can be made public via JSONP or CORS.
Project
The following project demonstrates how Jersey can be used to return JSON, XML, or JSONP content. A single resource (greeting) is used in this Hello World-style application. The project is available on GitHub.
Running the Project
The project is configured to run a Java class from Maven. The class contains a main method that starts a local HTTP Server on port 8080. A single command can be used to build and run the application:
mvn clean install exec:java
Server Code
The server code consists of three Java classes. App.java contains a main method that runs the server. It creates an instance of a Grizzly HTTP server and defines /api as the context root for the web API. It then adds a static HTTP handler to serve the HTML and JavaScript code:
package com.saternos.jsonp;
import org.glassfish.jersey.grizzly2.httpserver.GrizzlyHttpServerFactory;
import org.glassfish.jersey.server.ResourceConfig;
import org.glassfish.grizzly.http.server.*;
public class App {
public static void main(String[] args) throws java.io.IOException{
HttpServer server = GrizzlyHttpServerFactory.createHttpServer(
java.net.URI.create("http://localhost:8080/api"),
new ResourceConfig(GreetingResource.class)
);
StaticHttpHandler staticHttpHandler =
new StaticHttpHandler("src/main/webapp");
server.getServerConfiguration().addHttpHandler(staticHttpHandler, "/");
System.in.read();
server.stop();
}
}
GreetingBean is a POJO with an annotation related to rendering XML responses:
package com.saternos.jsonp;
import javax.xml.bind.annotation.*;
@XmlRootElement(name = "greeting")
public class GreetingBean {
@XmlAttribute
public String text;
public GreetingBean() {}
public GreetingBean(String text) {
this.text = text;
}
}
GreetingResource provides the ability to return the data contained in a GreetingBean through the server. Jersey is the JAX-RS reference implementation that maps web requests to Java methods. JAX-RS applies annotations to Java objects. Annotations became available in Java in version 1.5. They are used by frameworks to apply behaviors to classes and methods and effectively reduce the amount of code needed to complete common tasks. These annotations effectively provide a DSL that maps pretty clearly to underlying HTTP functionality.
The @GET annotation indicates the HTTP request verb in view. The @Path annotation describes the URL path in context, and the @Produces annotation describes what content type will be produced by Jersey when returning the bean from the method. The @QueryParam is used to assign the query parameter as a method argument to getGreeting. Table 8-3 presents representative annotations.
Table 8-3. Selected JAX-RS annotations
|
Annotation |
Description |
|
@GET |
Requests a representation of a resource |
|
@POST |
Creates a resource at the URI specified |
|
@PUT |
Creates or updates a resource at the URI specified |
|
@DELETE |
Removes a resource |
|
@HEAD |
Provides an identical response to GET, without the content body |
|
@Path |
The relative path for a resource |
|
@Produces |
Indicates the media types a service can return |
|
@Consumes |
Indicates the media types a service can accept in a request |
|
@PathParam |
Binds a method parameter to a segment of the URI path |
|
@QueryParam |
Binds a method parameter to a query parameter |
|
@FormParam |
Binds a method parameter to a form parameter |
There are a number of other annotations available in JAX-RS. See RESTful Java with JAX-RS (O’Reilly) for more information:
package com.saternos.jsonp;
import org.glassfish.jersey.server.JSONP;
import javax.ws.rs.*;
@Path("greeting")
public class GreetingResource {
@GET
@Produces({"application/xml", "application/json"})
public GreetingBean getGreeting() {
return new GreetingBean("Hello World Local");
}
@Path("remote")
@GET
@Produces({"application/x-javascript"})
@JSONP(queryParam = JSONP.DEFAULT_QUERY)
public GreetingBean getGreeting(
@QueryParam(JSONP.DEFAULT_QUERY) String callback
) {
return new GreetingBean("Hello World Remote");
}
}
Curl and jQuery
The client-side code included with the project uses jQuery to call API URLs. The jQuery library has a wide range of Ajax capabilities and hides some of the complexities and cross-browser challenges related to the core JavaScript XMLHTTPRequest object. The calls used in the application can also be replicated using Curl, as illustrated below. Table 8-4 shows web API URLs used in this example.
Table 8-4. Application URLs
|
URL |
Description |
|
/ |
HTML and JavaScript in the web app directory |
|
/api/greeting |
JSON or XML from getGreeting() |
|
/api/greeting/remote |
JSONP from getGreeting (string callback) |
Curl can be used to return a web page in HTML:
curl http://localhost:8080
When using Curl, the -i argument can be specified to include header information. The HTTP response code and content type are of particular interest. For instance, if you specify a URL path that is not recognized by the server, it will return a “Not Found” response:
curl http://localhost:8080/api -i
The application returns XML in the response by default:
curl http://localhost:8080/api/greeting
By modifying the HTTP Accept request header, a JSON response can be returned instead:
curl http://localhost:8080/api/greeting -H 'Accept: application/json'
Finally, a call to return JSONP will often include the specification of a JavaScript function name as a query parameter. The same response returned in the JSON call results, padded by a JavaScript function. Because JavaScript files can be downloaded from different domains, the content is returned. They would otherwise be forbidden by the JavaScript same-origin policy:
curl http://localhost:8080/api/greeting/remote?__callback=myCall
curl http://127.0.0.1:8080/api/greeting/remote?__callback=myCall
Theory in Practice
REST in its pure theoretical form remains an ideal standard. It serves as a measure of projects implemented with it in view. It ought to be studied and understood. But the value of other technologies, namely JSON, has been proven as well. JavaScript-based clients easily consume JSON. The lack of a universally accepted mechanism for linking in JSON has not deterred developers from adopting it as the data transport of choice. Supplementing such APIs with documentation and other practical considerations has made the difference between theoretically perfect systems that are never delivered and practical solutions that meet immediate needs.
The applicability of RESTful web APIs to the practical problems faced by developers has grown over time and resulted in the change in architectural approaches. Such APIs can be consumed by devices with a wide array of capabilities, including those created by third-party developers. They are lighter weight than SOAP and other web service implementations that include complex envelopes and exchange patterns. They can be used to create applications without problems related to stale data on the client. They effectively distribute processing to clients that have significant computing power. They are horizontally scalable by simply adding additional server applications when deployed in a cloud-based platform like Amazon Web Services. These and other characteristics have resulted in developers switching from occasionally implementing or consuming a service to developing entire applications with a consistent approach leveraging RESTful web APIs.