Continuous Enterprise Development in Java (2014)
Chapter 5. Java Persistence and Relational Data
Energy and persistence conquer all things.
— Benjamin Franklin
If we really boil down the primary objective of most applications to bare metal, we’ll find that nearly everything we do involves an interaction with data. We supply it when we make a new online order. We pull it out when we research on a wiki. We update it when we change our credit card’s billing address.
The information contained in a system at any point in time comprises the state of the application, and state comes in a variety of scopes, including:
Request
Limited access within one request/response cycle
Session
Limited access within one user session
Conversation/Sequence/Transaction
Limited access to a sequence of events (treated as one unit) within one user session
Application
Shared throughout the application
Environment
Shared throughout the host environment
Depending upon your view or framework of choice, there may be other ways to slice visibility, but this list outlines some of the most commonly used paradigms.
As is thematic throughout the study of computer science, the rule of thumb is to limit ourselves to the smallest scope required. Fine-grained access to data helps to ensure that we don’t leak out state where it can cause security issues or difficult-to-debug behaviors. Can you imagine what it’d be like if one user’s access to his online bank account were to be replicated to all active sessions?
In addition to the notion of scopes, which limit data’s visibility, we also have the concept of persistence. Persistence is a property that dictates whether or not state will survive outside of its confining scope. For instance, we may allow a user to log in and change her online profile, but if we don’t synchronize these updates with some sort of persistent storage, they’ll be lost as soon as her user session (which defines the scope of this data) is closed.
Perhaps the simplest way to handle persistent storage is to directly serialize information to the filesystem. At first glance, this looks like a nice approach; we open up a file, write whatever we want in there, and close it up. Later we go in and read as needed. Easy!
…until we start to think through how this is going to play out in practice. Our applications are multiuser; they support any number of operations going on in parallel. How are we to ensure that we don’t have two writes happening on the same file at once? We could put a read/write lock in place to ensure that only one write happens at a time, but then we could potentially queue up lots of write requests while work is being done. And what about auditing our changes, or ensuring that the integrity of our data model is preserved in case of an error? Very quickly we’ll discover that the task of persisting our data is a first-class problem in and of itself, and one that probably doesn’t belong on our desks as application developers.
It’d be much better to delegate the task of persistent storage to another component equipped to handle this efficiently and securely. Luckily, we’ll have our pick of any number of database management systems (DBMSs) that do just that. Figure 5-1 illustrates apps using centralized persistent storage.
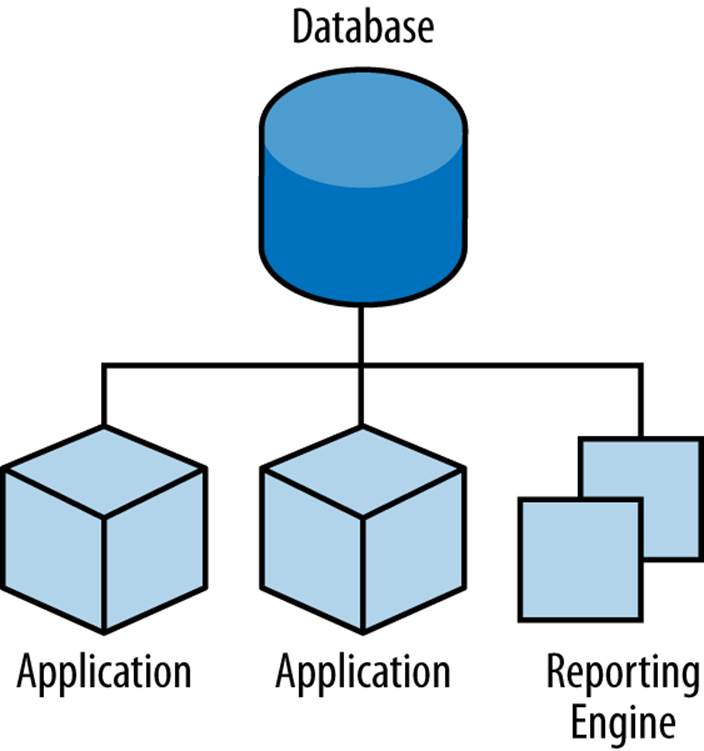
Figure 5-1. A series of applications backed by an RDMBS
The role of a DBMS is very generally to store and provide access to data. They come in a variety of flavors, which are differentiated in terms of how they internally organize information:
Relational (RDBMS)
Like data is grouped into tables where columns represent data types and rows represent records. Most often employs a protocol language called Structured Query Language (SQL) for interaction. Examples: MySQL, PostgreSQL.
Graph
Stores objects with relationships in a graph structure; ideal for traversing nodes. Example: Neo4j.
Key/value
Nested Map or document-oriented structure, has become very popular in recent years. Examples: Infinispan, MongoDB.
Column-oriented
Stores data in columns, as opposed to an RDBMS, where the records are kept in rows. Best suited for very large tables. Examples: Apache HBase, Apache Cassandra.
This chapter will focus on today’s most commonly used relational model (NoSQL will be covered next, in Chapter 6).
The Relational Database Model
To best understand the relational model, let’s highlight how it differs from the object model with which we’re already familiar. For this example we’ll seek to describe a family.
Each member of the family can be represented by a Person object:
public class Person {
// Instance members
private Long id;
private String name;
private Boolean male;
private Person father;
private Person mother;
private List<Person> children;
// Accessors / Mutators
public Long getId() {
return id;
}
public void setId(final Long id) {
this.id = id;
}
/* Other properties omitted for brevity... */
}
Simple enough: this value object that explicitly declares the relationship between a parent and child is sufficient for us to further infer siblings, grandparents, cousins, aunts, uncles, and so on. If we populate a few of these objects and wire them together, we’ll end up with a graph representing our family, as shown in Figure 5-2.
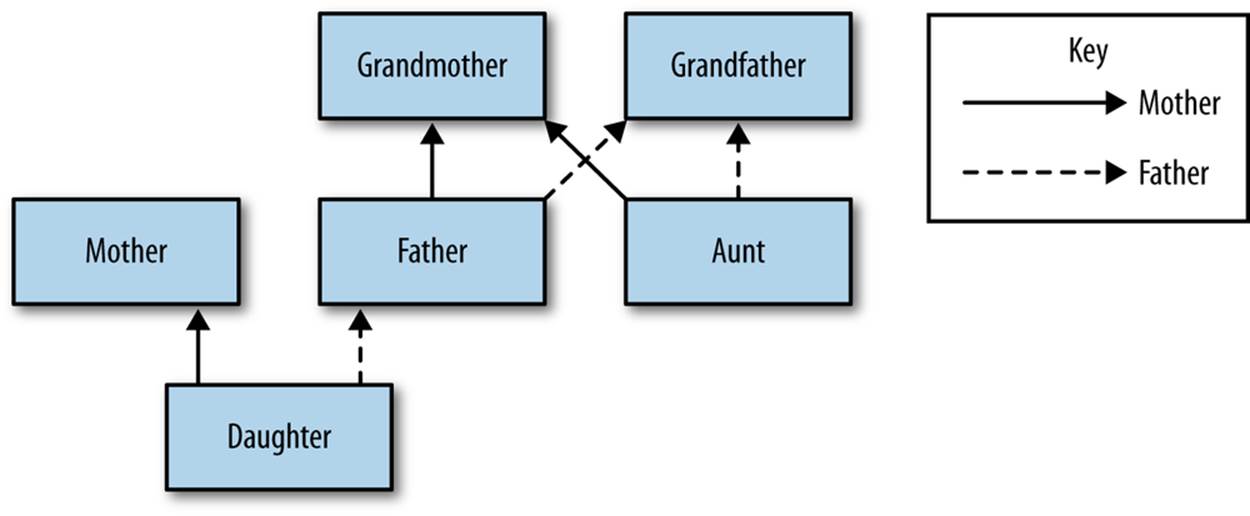
Figure 5-2. Family relationships represented as a graph
Now, let’s take a look at how that same information might be represented in a relational database in Table 5-1. Much like a spreadsheet, classes from our object model are instead organized into tables.
Table 5-1. Data types representing a “person”
|
Data type |
Field name |
|
UNSIGNED INTEGER (PK) |
id |
|
VARCHAR(255) |
name |
|
BIT(1) |
male |
|
UNSIGNED INTEGER |
father |
|
UNSIGNED INTEGER |
mother |
Already we see some differences here. The id, name, and male fields are as we might expect; simple data types where a Java Long is now represented as a database UNSIGNED INTEGER, a Java String maps to a VARCHAR(255) (variable-length character String with maximum length of 255), and a Java Boolean becomes a BIT type. But instead of a direct reference to the mother or father, instead we see that the data type there is UNSIGNED INTEGER. Why?
This is the defining characteristic of relationality in RDBMS. These fields are in fact pointers to the primary key, or the identifying id field of another record. As such, they are called foreign keys. So our data may look something like Table 5-2.
Table 5-2. Relationships among family members
|
id |
name |
male |
father |
mother |
|
1 |
Paternal Grandpa |
1 |
||
|
2 |
Paternal Grandma |
0 |
||
|
3 |
Dad |
1 |
1 |
2 |
|
4 |
Mom |
0 |
||
|
5 |
Brother |
1 |
3 |
4 |
|
6 |
Sister |
0 |
3 |
4 |
Note especially that there is no direct data reference to the children of a person in the relational model. That’s because this is the “many” side of a “one-to-many” relationship: one person may have many children, and many children may have one father and one mother. Therefore, to find the children of a given person, we’d ask the database something like:
“Please give me all the records where the mother field is my ID if I’m not a male, and where the father field is my ID if I am a male.”
Of course, the English language might be a bit more confusing than we’d like, so luckily we’d execute a query in SQL to handle this for us.
The Java Persistence API
It’s nice that a DBMS takes care of the details of persistence for us, but introducing this separate data layer presents a few issues:
§ Though SQL is an ANSI standard, its use is not truly portable between RDBMS vendors. In truth, each database product has its own dialect and extensions.
§ The details of interacting with a database are vendor-dependent, though there are connection-only abstractions (drivers) in Java (for instance, Java Database Connectivity, or JDBC).
§ The relational model used by the database doesn’t map on its own to the object model we use in Java; this is called the object/relational impedance mismatch.
To address each of these problems, Java EE6 provides a specification called the Java Persistence API (JPA), defined by JSR 317. JPA is composed of both an API for defining and interacting with entity objects, and an SQL-like query language called Java Persistence Query Language(JPQL) for portable interaction with a variety of database implementations. Because JPA is itself a spec, a variety of open source–compliant implementations are available, including Hibernate, EclipseLink, and OpenJPA.
So now our tiered data architecture may look something like Figure 5-3.
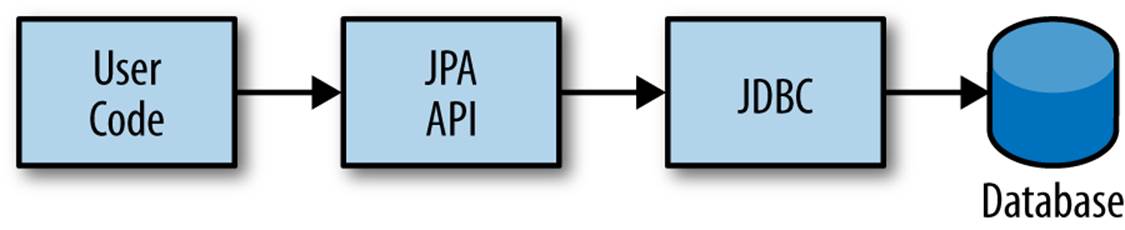
Figure 5-3. Persistence layers of abstraction from user code to the database
NOTE
Though a full overview of this technology stack is beyond the scope of this book, we’ll be sure to point you to enough resources and explain the basics of interacting with data via JPA that you’ll be able to understand our application and test examples. For readers interested in gaining better insight into JPA (and its parent, EJB), we recommend Enterprise Java Beans 3.1, 6th Edition by Andrew Lee Rubinger and Bill Burke (O’Reilly, 2010).
POJO Entities
Again, as Java developers we’re used to interacting with objects and the classes that define them. Therefore, JPA allows us to design our object model as we wish, and by sprinkling on some additional metadata (typically in the form of annotations, though XML may also be applied), we can tell our JPA provider enough for it to take care of the object/relational mapping for us. For instance, applying the javax.persistence.Entity annotation atop a value object like our Person class is enough to denote a JPA entity. The data type mapping is largely inferred from our source Java types (though this can be overridden), and we define relationship fields using the @javax.persistence.OneToOne, @javax.persistence.OneToMany, and @javax.persistence.ManyToMany annotations. We’ll see examples of this later in our application.
The important thing to keep in mind is the concept of managed entities. Because JPA exposes a POJO programming model, consider the actions that this code might do upon an entity class Person:
Person person = new Person();
person.setName("Dick Hoyt");
OK, so very clearly we’ve created a new Person instance and set his name. The beauty of the POJO programming model is also its drawback; this is just a regular object. Without some additional magic, there’s no link to the persistence layer. This coupling is done transparently for us, and the machine providing the voodoo is the JPA EntityManager.
javax.persistence.EntityManager is our hook to a defined persistence unit, our abstraction above the database. By associating POJO entities with the EntityManager, they become monitored for changes such that any state differences that take place in the object will be reflected in persistent storage. An object under such supervision is called managed. Perhaps this is best illustrated by some examples:
Person person = entityManager.find(Person.class, 1L); // Look up "Person" with
// Primary Key of 1
System.out.println("Got " + person); // This "person" instance is managed
person.setName("New Name"); // By changing the name of the person,
// the database will be updated when
// the EntityManager is flushed (likely when the
// current transaction commits)
Here we perform a lookup of the entity by its primary key, modify its properties just as we would any other object, then let the EntityManager worry about synchronizing the state changes with the underlying database. Alternatively, we could manually attach and detach the POJO from being managed:
Person person = new Person();
person.setId(1L); // Just a POJO
managedPerson = entityManager.merge(person); // Sync the state with the existing
// persistence context
managedPerson.setName("New Name"); // Make a change which be eventually become
// propagated to the DB
entityManager.detach(managedPerson); // Make "managedPerson" unmanaged
managedPerson.setName("Just a POJO"); // This state change will *not* be
// propagated to the DB, as we're now
// unmanaged
Use Cases and Requirements
This is the first chapter in which we’ll be dealing with the companion GeekSeek example application for the book; its purpose is to highlight all layers working in concert to fulfill the user requirements dictated by each chapter. From here out, we’ll be pointing to selections from the GeekSeek application in order to showcase how we wire together the domain, application, view, and test layers in a cohesive, usable project.
As we proceed, we’ll note each file so that you can draw references between the text and the deployable example. We’re firm believers that you best learn by doing (or at least exploring real code), so we invite you to dig in and run the examples as we go along.
Testing is a first-class citizen in verifying that our development is done correctly, so, for instance, in this chapter we’ll be focusing on interactions with persistent data. Before we can hope to arrive at any solutions, it’s important to clearly identify the problem domain. Each subsequent chapter will first outline the goals we’re looking to address.
User Perspective
Our users are going to have to perform a series of CRUD (Create, Read, Update, Delete) operations upon the entities that drive our application’s data. As such, we’ve defined a set of user-centric requirements:
As a User, I should be able to:
...add a Conference.
...add a Session.
...view a Conference.
...view a Session.
...change a Conference.
...change a Session.
...remove a Conference.
...remove a Session.
Quite simple (and maybe even redundant!) when put in these terms, especially for this persistence example. However, it’s wise to get into the habit of thinking about features from a user perspective; this technique will come in quite handy later on when, in more complex cases, it’ll be easy to get mired in the implementation specifics of providing a feature, and we don’t want to lose track of the real goal we’re aiming to deliver.
To state even more generally:
As a User, I should be able to Create, Read, Update,
and Delete Conference and Session types.
Of course, we have some other requirements that do not pertain to the user perspective.
Technical Concerns
As noted in the introduction, the issue of data persistence is not trivial. We must ensure that our solution will address:
§ Concurrent access
§ Multiuser access
§ Fault-tolerance
These constraints upon the environment will help to inform our implementation choices. Again, explicitly stating these issues may seem obvious, but our experience teaches that sometimes we get so comfortable with an implementation choice that we may not first stop to think if it’s even appropriate! For instance, a news or blogging site that has a high read-to-write ratio may not even need to worry about concurrency if the application can support stale data safely. In that case, we might not even need transactions, and bypassing that implementation choice can lead to great gains in performance.
In GeekSeek, however, we’ll want to ensure that users are seeing up-to-date information that’s consistent, and that implies a properly synchronized data source guarded by transactions.
Implementation
Given our user and technical concerns, the Java EE stack using JPA described earlier will do a satisfactory job toward meeting our requirements. And there’s an added benefit: by using frameworks designed to relieve the application developer of complicated programming, we’ll end up writing a lot less code. This will help us to reduce the conceptual weight of our code and ease maintenance over the long run. The slices of Java EE that we’ll use specifically include:
§ Java Transaction API (JTA)
§ Enterprise JavaBeans (EJB, JSR 318)
§ JPA
Transactions are a wide subject that merits its own book when dealing with the mechanics of implementing a viable transactional engine. For us as users, however, the rules are remarkably simple. We’ll imagine a transaction is a set of code that runs within a block. The instructions that are executed within this block must adhere to the ACID properties—Atomicity, Consistency, Isolation, and Durability:
Atomicity
The instructions in the block act as one unit; they either succeed (commit) or fail (rollback) together.
Consistency
All resources associated with the transaction (in this case, our database) will always be in a legal, viable state. For instance, a foreign key field will always point to a valid primary key. These rules are typically enforced by the transactional resource (again, our database).
Isolation
Actions taken upon transactional resources within a Tx block will not be seen outside the scope of the current transaction until and unless the transaction has successfully committed.
Durability
Once committed, the state of a transactional resource will not revert back or lose data.
Enterprise JavaBeans, or EJBs, enjoy close integration with JTA, so we won’t have to touch much of the transactional engine directly. By managing our JPA entities through an EntityManager that is encapsulated inside a transactional EJB, we’ll get the benefits of transaction demarcation and management for free.
Persistence is a case that’s well-understood by and lives at the heart of most Java EE applications, and these standards have been built specifically with our kind of use case in mind. What’s left for us is to sanely tie the pieces together, but not before we consider that the runtime is not the only thing with which we should be concerned.
Entity Objects
There are a few common fields we’ll want from each of our entities and ultimately the tables they represent. All will have a primary key (ID), and a created and last modified Date. To avoid duplication of code, we’ll create a base class from which our entities may extend; this is provided byorg.cedj.geekseek.domain.persistence.model.Base Entity:
@MappedSuperclass
public abstract class BaseEntity
implements Identifiable, Timestampable, Serializable {
The @javax.persistence.MappedSuperclass annotation signals that there will be no separate table strategy for this class; its fields will be reflected directly in the tables defined by its subclasses.
We’ll also want to fulfill the contract of org.cedj.app.domain.model.Identifiable, which mandates we provide the following:
/**
* @return The primary key, or ID, of this entity
*/
String getId();
Objects of type Identifiable simply have an ID, which is a primary key.
Similarly, we’ll be org.cedj.geekseek.domain.model.Timestampable, which notes that we provide support for the following timestamps:
/**
* @return the Date when this Entity was created
*/
Date getCreated();
/**
* Returns the LastUpdated, or the Created Date
* if this Entity has never been updated.
*
* @return the Date when this Entity was last modified
*/
Date getLastModified();
BaseEntity will therefore contain fields and JPA metadata to reflect these contracts:
@Id
private String id;
@Temporal(TemporalType.TIMESTAMP)
private Date created = new Date();
@Temporal(TemporalType.TIMESTAMP)
private Date updated;
You’ll notice a few interesting bits in play here.
We denote the id field as our primary key by use of the @javax.persistence.Id annotation.
@javax.persistence.Temporal is required by JPA upon Date and Calendar fields that are persistent.
We’re primarily concerned with the introduction of our Conference and Session entities; a Conference may have many Session objects associated with it. So org.cedj.app.domain.conference.model.Conference looks a bit like this:
@Entity
public class Conference extends BaseEntity {
Our class definition indicates that we’ll be a JPA entity through use of the @javax.persistence.Entity annotation. We’ll extend the Timestampable and Identifiable support from our BaseEntity.
Next we can put in place the fields holding the state for Conference:
private static final long serialVersionUID = 1L;
private String name;
private String tagLine;
@Embedded
private Duration duration;
@OneToMany(fetch = FetchType.EAGER, orphanRemoval = true,
mappedBy = "conference", cascade = CascadeType.ALL)
private Set<Session> sessions;
public Conference() {
this.id = UUID.randomUUID().toString();
}
The duration field is @javax.persistence.Embedded, which is used to signal a complex object type that will decompose into further fields (columns) when mapped to relational persistence. org.cedj.app.domain.conference.model.Duration looks like this:
public class Duration implements Serializable {
private static final long serialVersionUID = 1L;
private Date start;
private Date end;
// hidden constructor for Persistence
Duration() {
}
public Duration(Date start, Date end) {
requireNonNull(start, "Start must be specified");
requireNonNull(end, "End must be specified");
if (end.before(start)) {
throw new IllegalArgumentException("End can not be before Start");
}
this.start = (Date)start.clone();
this.end = (Date)end.clone();
}
public Date getEnd() {
return (Date) end.clone();
}
public Date getStart() {
return (Date) start.clone();
}
public Integer getNumberOfDays() {
return -1;
}
public Integer getNumberOfHours() {
return -1;
}
}
Conference also has a relationship with Session as denoted by the @OneToMany annotation. This is a bidirectional relationship; we perform the object association in both the Conference and Session classes.
Let’s define the constructors that will be used to create new instances:
// JPA
protected Conference() {}
public Conference(String name, String tagLine, Duration duration) {
super(UUID.randomUUID().toString());
requireNonNull(name, "Name must be specified)");
requireNonNull(tagLine, "TagLine must be specified");
requireNonNull(duration, "Duration must be specified");
this.name = name;
this.tagLine = tagLine;
this.duration = duration;
}
A no-argument constructor is required by JPA, so we’ll provide one, albeit with protected visibility so we won’t encourage users to call upon it.
Now we can flush out the accessors/mutators of this POJO entity, applying some intelligent defaults along the way:
public String getName() {
return name;
}
public Conference setName(String name) {
requireNonNull(name, "Name must be specified)");
this.name = name;
return this;
}
public String getTagLine() {
return tagLine;
}
public Conference setTagLine(String tagLine) {
requireNonNull(tagLine, "TagLine must be specified");
this.tagLine = tagLine;
return this;
}
public Conference setDuration(Duration duration) {
requireNonNull(duration, "Duration must be specified");
this.duration = duration;
return this;
}
public Duration getDuration() {
return duration;
}
public Set<Session> getSessions() {
if (sessions == null) {
this.sessions = new HashSet<Session>();
}
return Collections.unmodifiableSet(sessions);
}
public Conference addSession(Session session) {
requireNonNull(session, "Session must be specified");
if (sessions == null) {
this.sessions = new HashSet<Session>();
}
sessions.add(session);
session.setConference(this);
return this;
}
public void removeSession(Session session) {
if(session == null) {
return;
}
if (sessions.remove(session)) {
session.setConference(null);
}
}
}
Similar in form to the Conference entity, org.cedj.app.domain.conference.model.Session looks like this:
@Entity
public class Session extends BaseEntity {
@Lob
private String outline;
@ManyToOne
private Conference conference;
// ... redundant bits omitted
@PreRemove
public void removeConferenceRef() {
if(conference != null) {
conference.removeSession(this);
}
}
}
We’ll allow an outline for the session of arbitrary size, permitted by the @Lob annotation.
At this end of the relationship between Session and Conference, you’ll see that a Session is associated with a Conference via the ManyToOne annotation.
We’ve also introduced a callback handler to ensure that before a Session entity is removed, we also remove the association it has with a Conference so that we aren’t left with orphan references.
Repository EJBs
The “Repository” EJBs are where we’ll define the operations that may be taken by the user with respect to our entities. Strictly speaking, they define the verbs “Store,” “Get,” and “Remove.”
Because we want to completely decouple these persistent actions from JPA, we’ll define an interface to abstract out the verbs from the implementations. Later on, we’ll want to provide mechanisms that fulfill these responsibilities in both RDBMS and other NoSQL variants. Our contract is inorg.cedj.geekseek.domain.Repository:
public interface Repository<T extends Identifiable> {
Class<T> getType();
T store(T entity);
T get(String id);
void remove(T entity);
}
This means that for any Identifiable type, we’ll be able to obtain the concrete class type, store the entity, and get and remove it from the database. In JPA, we do this via an EntityManager, so we can write a base class to support these operations for all JPA entities. The following is from org.cedj.geekseek.domain.persistence.PersistenceRepository:
public abstract class PersistenceRepository<T extends Identifiable>
implements Repository<T> {
@PersistenceContext
private EntityManager manager;
private Class<T> type;
public PersistenceRepository(Class<T> type) {
this.type = type;
}
@Override
public Class<T> getType() {
return type;
}
@Override
public T store(T entity) {
T merged = merge(entity);
manager.persist(merged);
return merged;
}
@Override
public T get(String id) {
return manager.find(type, id);
}
@Override
public void remove(T entity) {
manager.remove(merge(entity));
}
private T merge(T entity) {
return manager.merge(entity);
}
protected EntityManager getManager() {
return manager;
}
}
An instance member of this class is our EntityManager, which is injected via the @PersistenceContext annotation and will be used to carry out the public business methods store (Create), remove (Delete), and get (Read). Update is handled by simply reading in an entity, then making any changes to that object’s state. The application server will propagate these state changes to persistent storage when the transaction commits (i.e., a transactional business method invocation completes successfully).
We can now extend this behavior with a concrete class and supply the requisite EJB annotations easily; for instance, org.cedj.geekseek.domain.conference.ConferenceRepository:
@Stateless
@LocalBean
@Typed(ConferenceRepository.class)
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public class ConferenceRepository extends PersistenceRepository<Conference> {
public ConferenceRepository() {
super(Conference.class);
}
}
Despite the small amount of code here, there’s a lot of utility going on.
The Stateless annotation defines this class as an EJB, a Stateless Session Bean, meaning that the application server may create and destroy instances at will, and a client should not count on ever receiving any particular instance. @LocalBean indicates that this EJB has no business interface; clients may call upon ConferenceRepository methods directly.
The TransactionAttribute annotation and its REQUIRED value on the class level notes that every method invocation upon one of the business methods exposed by the EJB will run in a transaction. That means that if a transaction does not exist one will be created, and if there’s currently a transaction in flight, it will be used.
The @Typed annotation from CDI is explained best by the ConferenceRepository JavaDocs:
/**
* This EJB is @Typed to a specific type to avoid being picked up by
* CDI under Repository<Conference> due to limitations/error in the CDI EJB
* interactions. A EJB Beans is always resolved as Repository<T>, which means
* two EJBs that implements the Repository interface both respond to
* the InjectionPoint @Inject Repository<X> and making the InjectionPoint
* ambiguous.
*
* As a WorkAround we wrap the EJB that has Transactional properties in CDI bean
* that can be used by the Type system. The EJB is to be considered a internal
* implementation detail. The CDI Type provided by the
* ConferenceCDIDelegateRepository is the real Repository api.
*/
Requirement Test Scenarios
Of course the runtime will be the executable code of our application. However, the theme of this book is testable development, and we’ll be focusing on proof through automated tests. To that end, every user and technical requirement we identify will be matched to a test that will ensure that functions are producing the correct results during the development cycle.
In this case, we need to create coverage to ensure that we can:
§ Perform CRUD operations on the Conference and Session entities
§ Execute operations against known data sets and validate the results
§ Exercise our transaction handling
§ Commits should result in entity object state flushed to persistent storage.
§ Rollbacks (when a commit fails) result in no changes to persistent storage.
Test Setup
Our tests will be taking advantage of the Arquillian Persistence Extension, which has been created to aid in writing tests where the persistence layer is involved. It supports the following features:
§ Wrapping each test in the separated transaction.
§ Seeding database using:
§ DBUnit with XML, XLS, YAML, and JSON supported as data set formats.
§ Custom SQL scripts.
§ Comparing database state at the end of the test using given data sets (with column exclusion).
Creating ad hoc object graphs in the test code is often too verbose and makes it harder to read the tests themselves. The Arquillian Persistence Extension provides alternatives to set database fixtures to be used for the given test.
Adding transactional support to these tests is fairly straightforward. If that’s all you need, simply put a @Transactional annotation either on the test you want to be wrapped in the transaction or on the test class (which will result in all tests running in their own transactions). The following modes are supported:
COMMIT
Each test will be finished with a commit operation. This is default behavior.
ROLLBACK
At the end of the test execution, rollback will be performed.
DISABLED
If you have enabled transactional support at the test class level, marking a given test with this mode will simply run it without the transaction.
We’ll start by defining the Arquillian Persistence Extension in the dependencyManagement section of our parent POM:
code/application/pom.xml:
<properties>
<version.arquillian_persistence>1.0.0.Alpha6</version.arquillian_persistence>
...
</properties>
...
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.arquillian.extension</groupId>
<artifactId>arquillian-persistence-impl</artifactId>
<version>${version.arquillian_persistence}</version>
<scope>test</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
And we’ll also enable this in the dependencies section of the POMs of the projects in which we’ll be using the extension:
code/application/domain/pom.xml:
<dependencies>
<dependency>
<groupId>org.jboss.arquillian.extension</groupId>
<artifactId>arquillian-persistence-impl</artifactId>
<scope>test</scope>
</dependency>
...
</dependencies>
Database configuration for tests powered by the Persistence Extension is done via the same mechanism as is used for the runtime: the persistence.xml configuration file. For instance, we supply a persistence descriptor inorg.cedj.geekseek.domain.persistence.test.integration.PersistenceDeployments:
public static PersistenceDescriptor descriptor() {
return Descriptors.create(PersistenceDescriptor.class)
.createPersistenceUnit()
.name("test")
.getOrCreateProperties()
.createProperty()
.name("hibernate.hbm2ddl.auto")
.value("create-drop").up()
.createProperty()
.name("hibernate.show_sql")
.value("true").up().up()
.jtaDataSource("java:jboss/datasources/ExampleDS").up();
}
CRUD Tests
With our setup and objectives clearly in place, we’d like to assert that the CRUD operations against our Repository implementations hold up. For instance, the org.cedj.geekseek.domain.conference.test.integration.ConferenceTestCase contains a series of tests that aim to do just that, and are backed by the Arquillian Persistence Extension.
First, the test class definition:
@Transactional(TransactionMode.COMMIT)
@RunWith(Arquillian.class)
public class ConferenceTestCase {
This is a plain class with no parent, and will be executed by Arquillian using the JUnit @RunWith annotation, passing along Arquillian.class as the test runner.
The @Transactional annotation from the Arquillian Transaction Extension (a dependency of the Persistence Extension) notes that we’ll be running each test method in a transaction, and committing the result upon completion.
Next we’ll define a ShrinkWrap @Deployment that will be deployed onto the backing server as our application under test:
@Deployment
public static WebArchive deploy() {
return ShrinkWrap.create(WebArchive.class)
.addAsLibraries(
ConferenceDeployments.conference().addClasses(
ConferenceTestCase.class,
TestUtils.class)
.addAsManifestResource(new StringAsset(
PersistenceDeployments.descriptor().exportAsString()),
"persistence.xml")
.addAsManifestResource(
new File("src/main/resources/META-INF/beans.xml")))
.addAsWebInfResource(EmptyAsset.INSTANCE, "beans.xml");
}
This will create a WAR of a structure similar to:
a23508c0-974e-4ae3-a609-cc532828e6c4.war:
/WEB-INF/
/WEB-INF/lib/
/WEB-INF/lib/c2c1eaf4-4f80-49ce-875b-5090cc6dcc7c.jar
/WEB-INF/beans.xml
The nested JAR in WEB-INF/lib are our own libraries under test, which include the core deployments, the ConferenceRepository, and their dependencies.
We’ll now be able to use Arquillian to inject the ConferenceRepository right into the test instance, which will be executed inside the deployment on the server. This makes it a local reference to the runtime code:
@Inject
private Repository<Conference> repository;
Our tests will use this repository to interact with persistent storage.
We can also set a few flags to note whether our create and remove JPA events are fired:
// these fields are static because Events observed by this TestClass
// are not observed on the same TestClass instance as @Test is running.
private static boolean createdEventFired = false;
private static boolean removedEventFired = false;
And we’ll put some methods in place to observe the JPA create events and set the flags. Because our test is itself a CDI bean, we can use the CDI @Observes annotation to listen in:
public void createdEventFired(@Observes @Created Conference conference) {
createdEventFired = true;
}
public void removedEventFired(@Observes @Removed Conference conference) {
removedEventFired = true;
}
@Created and @Removed are our own CDI qualifiers, defined like so:
@Qualifier
@Target({ElementType.FIELD, ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface Created {
public static class Literal extends AnnotationLiteral<Created> {
private static final long serialVersionUID = 1L;
}
}
Now we’re set to run some tests. The first one will ensure we can create a conference:
// Story: As a User I should be able to create a Conference
@Test
@ShouldMatchDataSet(value = { "conference.yml" }, excludeColumns = { "*id" })
public void shouldBeAbleToCreateConference() {
Conference conference = createConference();
repository.store(conference);
Assert.assertTrue(createdEventFired);
}
public static Conference createConference() {
Conference conference = new Conference(
"Devoxx Belgium 2013",
"We Code In Peace",
new Duration(toDate(2013, 11, 11), toDate(2013, 11, 15)));
return conference;
}
Because we’ll check that the flag was set based upon the CDI @Observes support, we can be sure that the conference was in fact created. Additionally, we use the @ShouldMatchDataSet annotation from the Arquillian Persistence Extension to check that the values in the DB are in the expected form, given the contents of the conference.xml file, which looks like:
conference:
- id: CA
name: Devoxx Belgium 2013
tagLine: We Code In Peace
start: 2013-11-11 00:00:00.0
end: 2013-11-15 00:00:00.0
In this manner, we can more easily check that data is making its way to and from the persistence layer intact, with an easier syntax to define the values we’ll expect to find. This also frees us from writing a lot of assertions on each individual field of every entry in the DB, and makes for much easier automated checking of large data sets.
Our test class has similar methods to enforce related behaviors mandated by our requirements:
// Story: As a User I should be able to create a Conference with a Session
@Test
@ShouldMatchDataSet(value = { "conference.yml", "session.yml" },
excludeColumns = { "*id" })
public void shouldBeAbleToCreateConferenceWithSession(){...}
// Story: As a User I should be able to add a Session to an
// existing Conference
@Test
@UsingDataSet("conference.yml")
@ShouldMatchDataSet(value = { "conference.yml", "session.yml" },
excludeColumns = { "*id" })
public void shouldBeAbleToAddSessionToConference() {...}
// Story: As a User I should be able to remove a Conference
@Test
@UsingDataSet("conference.yml")
@ShouldMatchDataSet("conference_empty.yml")
public void shouldBeAbleToRemoveConference() {...}
// Story: As a User I should be able to remove a Session from a Conference
@Test
@UsingDataSet({ "conference.yml", "session.yml" })
@ShouldMatchDataSet({ "conference.yml", "session_empty.yml" })
public void shouldBeAbleToRemoveConferenceWithSession(){...}
// Story: As a User I should be able to change a Conference
@Test
@UsingDataSet("conference.yml")
@ShouldMatchDataSet(value = { "conference_updated.yml" })
public void shouldBeAbleToChangeConference() {...}
// Story: As a User I should be able to change a Session
@Test
@UsingDataSet({ "conference.yml", "session.yml" })
@ShouldMatchDataSet(value = { "conference.yml", "session_updated.yml" })
public void shouldBeAbleToChangeSession() {...}
By using Arquillian’s injection facilities along with the additional transactions and data-checking support offered by the Persistence Extension, we can, with very little test logic, perform powerful assertions which validate that our data is making its way to the real persistence layer without the use of mock objects.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.