JavaScript Regular Expressions (2015)
Chapter 4. Regex in Practice
In the previous two chapters, we covered Regex's syntax in depth, and at this point, have all the pieces required to build a real-world project, which will be the goal of this chapter.
Knowing Regex's syntax allows you to model text patterns, but sometimes coming up with a good reliable pattern can be more difficult, so taking a look at some actual use cases can really help you learn some common design patterns.
So, in this chapter, we will develop a form, and we will explore the following topics:
· Validating a name
· Validating e-mails
· Validating a Twitter username
· Validating passwords
· Validating URLs
· Manipulating text
Regular expressions and form validation
By far, one of the most common uses for regular expressions on the frontend is for use with user submitted forms, so this is what we will be building. The form we will be building will have all the common fields, such as name, e-mail, website, and so on, but we will also experiment with some text processing besides all the validations.
In real-world applications, you usually are not going to implement the parsing and validation code manually. You can create a regular expression and rely on some JavaScript libraries, such as:
· jQuery validation: Refer to http://jqueryvalidation.org/
· Parsely.js: Refer to http://parsleyjs.org/
Note
Even the most popular frameworks support the usage of regular expressions with its native validation engine, such as AngularJS (refer to http://www.ng-newsletter.com/posts/validations.html).
Setting up the form
This demo will be for a site that allows users to create an online bio, and as such, consists of different types of fields. However, before we get into this (since we won't be building a backend to handle the form), we are going to setup some HTML and JavaScript code to catch the form submission and extract/validate the data entered in it.
To keep the code neat, we will create an array with all the validation functions, and a data object where all the final data will be kept.
Here is a basic outline of the HTML code for which we begin by adding fields:
<!DOCTYPE HTML>
<html>
<head>
<title>Personal Bio Demo</title>
</head>
<body>
<form id="main_form">
<input type="submit" value="Process" />
</form>
<script>
// js goes here
</script>
</body>
</html>
Next, we need to write some JavaScript to catch the form and run through the list of functions that we will be writing. If a function returns false, it means that the verification did not pass and we will stop processing the form. In the event where we get through the entire list of functions and no problems arise, we will log out of the console and data object, which contain all the fields we extracted:
<script>
var fns = [];
var data = {};
var form = document.getElementById("main_form");
form.onsubmit = function(e) {
e.preventDefault();
data = {};
for (var i = 0; i < fns.length; i++) {
if (fns[i]() == false) {
return;
}
}
console.log("Verified Data: ", data);
}
</script>
The JavaScript starts by creating the two variables I mentioned previously, we then pull the form's object from the DOM and set the submit handler. The submit handler begins by preventing a page from actually submitting, (as we don't have any backend code in this example) and then we go through the list of functions running them one by one.
Validating fields
In this section, we will explore how to validate different types of fields manually, such as name, e-mail, website URL, and so on.
Matching a complete name
To get our feet wet, let's begin with a simple name field. It's something we have gone through briefly in the past, so it should give you an idea of how our system will work. The following code goes inside the script tags, but only after everything we have written so far:
function process_name() {
var field = document.getElementById("name_field");
var name = field.value;
var name_pattern = /^(\S+) (\S*) ?\b(\S+)$/;
if (name_pattern.test(name) === false) {
alert("Name field is invalid");
return false;
}
var res = name_pattern.exec(name);
data.first_name = res[1];
data.last_name = res[3];
if (res[2].length > 0) {
data.middle_name = res[2];
}
return true;
}
fns.push(process_name);
We get the name field in a similar way to how we got the form, then, we extract the value and test it against a pattern to match a full name. If the name doesn't match the pattern, we simply alert the user and return false to let the form handler know that the validations have failed. If the name field is in the correct format, we set the corresponding fields on the data object (remember, the middle name is optional here). The last line just adds this function to the array of functions, so it will be called when the form is submitted.
The last thing required to get this working is to add HTML for this form field, so inside the form tags (right before the submit button), you can add this text input:
Name: <input type="text" id="name_field" /><br />
Opening this page in your browser, you should be able to test it out by entering different values into the Name box. If you enter a valid name, you should get the data object printed out with the correct parameters, otherwise you should be able to see this alert message:
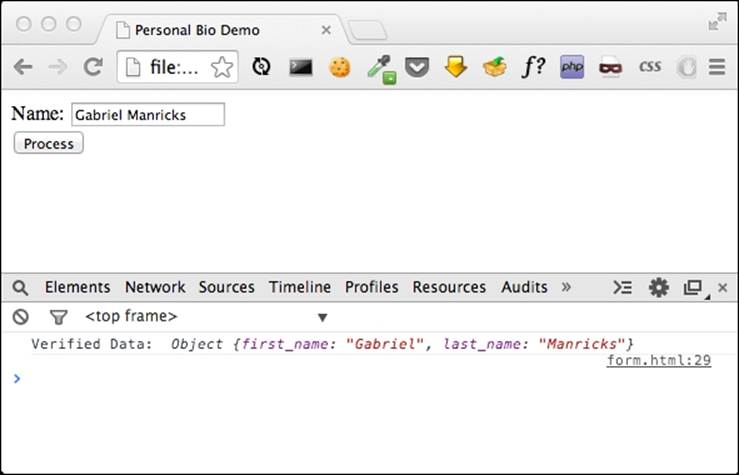
Understanding the complete name Regex
Let's go back to the regular expression used to match the name entered by a user:
/^(\S+) (\S*) ?\b(\S+)$/
The following is a brief explanation of the Regex:
· The ^ character asserts its position at the beginning of a string
· The first capturing group (\S+)
· \S+ matches a non-white space character [^\r\n\t\f]
· The + quantifier between one and unlimited times
· The second capturing group (\S*)
· \S* matches any non-whitespace character [^\r\n\t\f]
· The * quantifier between zero and unlimited times
· " ?" matches the whitespace character
· The ? quantifier between zero and one time
· \b asserts its position at a (^\w|\w$|\W\w|\w\W) word boundary
· The third capturing group (\S+)
· \S+ matches a non-whitespace character [^\r\n\t\f]
· The + quantifier between one and unlimited times
· $ asserts its position at the end of a string
Matching an e-mail with Regex
The next type of field we may want to add is an e-mail field. E-mails may look pretty simple at first glance, but there are a large variety of e-mails out there. You may just think of creating a word@word.word pattern, but the first section can contain many additional characters besides just letters, the domain can be a subdomain, or the suffix could have multiple parts (such as .co.uk for the UK).
Our pattern will simply look for a group of characters that are not spaces or instances where the @ symbol has been used in the first section. We will then want an @ symbol, followed by another set of characters that have at least one period, followed by the suffix, which in itself could contain another suffix. So, this can be accomplished in the following manner:
/[^\s@]+@[^\s@.]+\.[^\s@]+/
Note
The pattern of our example is very simple and will not match every valid e-mail address. There is an official standard for an e-mail address's regular expressions called RFC 5322. For more information, please read http://www.regular-expressions.info/email.html.
So, let's add the field to our page:
Email: <input type="text" id="email_field" /><br />
We can then add this function to verify it:
function process_email() {
var field = document.getElementById("email_field");
var email = field.value;
var email_pattern = /^[^\s@]+@[^\s@.]+\.[^\s@]+$/;
if (email_pattern.test(email) === false) {
alert("Email is invalid");
return false;
}
data.email = email;
return true;
}
fns.push(process_email);
Note
There is an HTML5 field type specifically designed for e-mails, but here we are verifying manually, as this is a Regex book. For more information, please refer to http://www.w3.org/TR/html-markup/input.email.html.
Understanding the e-mail Regex
Let's go back to the regular expression used to match the name entered by the user:
/^[^\s@]+@[^\s@.]+\.[^\s@]+$/
Following is a brief explanation of the Regex:
· ^ asserts a position at the beginning of the string
· [^\s@]+ matches a single character that is not present in the following list:
· The + quantifier between one and unlimited times
· \s matches any white space character [\r\n\t\f ]
· @ matches the @ literal character
· [^\s@.]+ matches a single character that is not present in the following list:
· The + quantifier between one and unlimited times
· \s matches a [\r\n\t\f] whitespace character
· @. is a single character in the @. list, literally
· \. matches the . character literally
· [^\s@]+ match a single character that is not present in the following list:
· The + quantifier between one and unlimited times
· \s matches [\r\n\t\f] a whitespace character
· @ is the @ literal character
· $ asserts its position at end of a string
Matching a Twitter name
The next field we are going to add is a field for a Twitter username. For the unfamiliar, a Twitter username is in the @username format, but when people enter this in, they sometimes include the preceding @ symbol and on other occasions, they only write the username by itself. Obviously, internally we would like everything to be stored uniformly, so we will need to extract the username, regardless of the @ symbol, and then manually prepend it with one, so regardless of whether it was there or not, the end result will look the same.
So again, let's add a field for this:
Twitter: <input type="text" id="twitter_field" /><br />
Now, let's write the function to handle it:
function process_twitter() {
var field = document.getElementById("twitter_field");
var username = field.value;
var twitter_pattern = /^@?(\w+)$/;
if (twitter_pattern.test(username) === false) {
alert("Twitter username is invalid");
return false;
}
var res = twitter_pattern.exec(username);
data.twitter = "@" + res[1];
return true;
}
fns.push(process_twitter);
If a user inputs the @ symbol, it will be ignored, as we will add it manually after checking the username.
Understanding the twitter username Regex
Let's go back to the regular expression used to match the name entered by the user:
/^@?(\w+)$/
This is a brief explanation of the Regex:
· ^ asserts its position at start of the string
· @? matches the @ character, literally
· The ? quantifier between zero and one time
· First capturing group (\w+)
· \w+ matches a [a-zA-Z0-9_] word character
· The + quantifier between one and unlimited times
· $ asserts its position at end of a string
Matching passwords
Another popular field, which can have some unique constraints, is a password field. Now, not every password field is interesting; you may just allow just about anything as a password, as long as the field isn't left blank. However, there are sites where you need to have at least one letter from each case, a number, and at least one other character. Considering all the ways these can be combined, creating a pattern that can validate this could be quite complex. A much better solution for this, and one that allows us to be a bit more verbose with our error messages, is to create four separate patterns and make sure the password matches each of them.
For the input, it's almost identical:
Password: <input type="password" id="password_field" /><br />
The process_password function is not very different from the previous example as we can see its code as follows:
function process_password() {
var field = document.getElementById("password_field");
var password = field.value;
var contains_lowercase = /[a-z]/;
var contains_uppercase = /[A-Z]/;
var contains_number = /[0-9]/;
var contains_other = /[^a-zA-Z0-9]/;
if (contains_lowercase.test(password) === false) {
alert("Password must include a lowercase letter");
return false;
}
if (contains_uppercase.test(password) === false) {
alert("Password must include an uppercase letter");
return false;
}
if (contains_number.test(password) === false) {
alert("Password must include a number");
return false;
}
if (contains_other.test(password) === false) {
alert("Password must include a non-alphanumeric character");
return false;
}
data.password = password;
return true;
}
fns.push(process_password);
All in all, you may say that this is a pretty basic validation and something we have already covered, but I think it's a great example of working smart as opposed to working hard. Sure, we probably could have created one long pattern that would check everything together, but it would be less clear and less flexible. So, by breaking it into smaller and more manageable validations, we were able to make clear patterns, and at the same time, improve their usability with more helpful alert messages.
Matching URLs
Next, let's create a field for the user's website; the HTML for this field is:
Website: <input type="text" id="website_field" /><br />
A URL can have many different protocols, but for this example, let's restrict it to only http or https links. Next, we have the domain name with an optional subdomain, and we need to end it with a suffix. The suffix itself can be a single word, such as .com or it can have multiple segments, such as.co.uk.
All in all, our pattern looks similar to this:
/^(?:https?:\/\/)?\w+(?:\.\w+)?(?:\.[A-Z]{2,3})+$/i
Here, we are using multiple noncapture groups, both for when sections are optional and for when we want to repeat a segment. You may have also noticed that we are using the case insensitive flag (/i) at the end of the regular expression, as links can be written in lowercase or uppercase.
Now, we'll implement the actual function:
function process_website() {
var field = document.getElementById("website_field");
var website = field.value;
var pattern = /^(?:https?:\/\/)?\w+(?:\.\w+)?(?:\.[A-Z]{2,3})+$/i
if (pattern.test(website) === false) {
alert("Website is invalid");
return false;
}
data.website = website;
return true;
}
fns.push(process_website);
At this point, you should be pretty familiar with the process of adding fields to our form and adding a function to validate them. So, for our remaining examples let's shift our focus a bit from validating inputs to manipulating data.
Understanding the URL Regex
Let's go back to the regular expression used to match the name entered by the user:
/^(?:https?:\/\/)?\w+(?:\.\w+)?(?:\.[A-Z]{2,3})+$/i
This is a brief explanation of the Regex:
· ^ asserts its position at start of a string
· (?:https?:\/\/)? is a non-capturing group
· The ? quantifier between zero and one time
· http matches the http characters literally (case-insensitive)
· s? matches the s character literally (case-insensitive)
· The ? quantifier between zero and one time
· : matches the : character literally
· \/ matches the / character literally
· \/ matches the / character literally
· \w+ matches a [a-zA-Z0-9_] word character
· The + quantifier between one and unlimited times
· (?:\.\w+)? is a non-capturing group
· The ? quantifier between zero and one time
· \. matches the . character literally
· \w+ matches a [a-zA-Z0-9_] word character
· The + quantifier between one and unlimited times
· (?:\.[A-Z]{2,3})+ is a non-capturing group
· The + quantifier between one and unlimited times
· \. matches the . character literally
· [A-Z]{2,3} matches a single character present in this list
· The {2,3} quantifier between2 and 3 times
· A-Z is a single character in the range between A and Z (case insensitive)
· $ asserts its position at end of a string
· i modifier: insensitive. Case insensitive letters, meaning it will match a-z and A-Z.
Manipulating data
We are going to add one more input to our form, which will be for the user's description. In the description, we will parse for things, such as e-mails, and then create both a plain text and HTML version of the user's description.
The HTML for this form is pretty straightforward; we will be using a standard textbox and give it an appropriate field:
Description: <br />
<textarea id="description_field"></textarea><br />
Next, let's start with the bare scaffold needed to begin processing the form data:
function process_description() {
var field = document.getElementById("description_field");
var description = field.value;
data.text_description = description;
// More Processing Here
data.html_description = "<p>" + description + "</p>";
return true;
}
fns.push(process_description);
This code gets the text from the textbox on the page and then saves both a plain text version and an HTML version of it. At this stage, the HTML version is simply the plain text version wrapped between a pair of paragraph tags, but this is what we will be working on now. The first thing I want to do is split between paragraphs, in a text area the user may have different split-ups—lines and paragraphs. For our example, let's say the user just entered a single new line character, then we will add a <br /> tag and if there is more than one character, we will create a new paragraph using the <p> tag.
Using the String.replace method
We are going to use JavaScript's replace method on the string object This function can accept a Regex pattern as its first parameter, and a function as its second; each time it finds the pattern it will call the function and anything returned by the function will be inserted in place of the matched text.
So, for our example, we will be looking for new line characters, and in the function, we will decide if we want to replace the new line with a break line tag or an actual new paragraph, based on how many new line characters it was able to pick up:
var line_pattern = /\n+/g;
description = description.replace(line_pattern, function(match) {
if (match == "\n") {
return "<br />";
} else {
return "</p><p>";
}
});
The first thing you may notice is that we need to use the g flag in the pattern, so that it will look for all possible matches as opposed to only the first. Besides this, the rest is pretty straightforward. Consider this form:
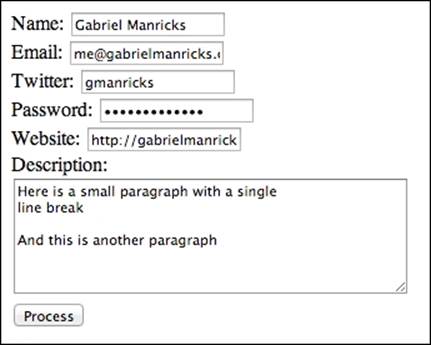
If you take a look at the output from the console of the preceding code, you should get something similar to this:

Matching a description field
The next thing we need to do is try and extract e-mails from the text and automatically wrap them in a link tag. We have already covered a Regexp pattern to capture e-mails, but we will need to modify it slightly, as our previous pattern expects that an e-mail is the only thing present in the text. In this situation, we are interested in all the e-mails included in a large body of text.
If you were simply looking for a word, you would be able to use the \b matcher, which matches any boundary (that can be the end of a word/the end of a sentence), so instead of the dollar sign, which we used before to denote the end of a string, we would place the boundary character to denote the end of a word. However, in our case it isn't quite good enough, as there are boundary characters that are valid e-mail characters, for example, the period character is valid. To get around this, we can use the boundary character in conjunction with a lookahead group and say we want it to end with a word boundary, but only if it is followed by a space or end of a sentence/string. This will ensure we aren't cutting off a subdomain or a part of a domain, if there is some invalid information mid-way through the address.
Now, we aren't creating something that will try and parse e-mails no matter how they are entered; the point of creating validators and patterns is to force the user to enter something logical. That said, we assume that if the user wrote an e-mail address and then a period, that he/she didn't enter an invalid address, rather, he/she entered an address and then ended a sentence (the period is not part of the address).
In our code, we assume that to the end an address, the user is either going to have a space after, such as some kind of punctuation, or that he/she is ending the string/line. We no longer have to deal with lines because we converted them to HTML, but we do have to worry that our pattern doesn't pick up an HTML tag in the process.
At the end of this, our pattern will look similar to this:
/\b[^\s<>@]+@[^\s<>@.]+\.[^\s<>@]+\b(?=.?(?:\s|<|$))/g
We start off with a word boundary, then, we look for the pattern we had before. I added both the (>) greater-than and the (<) less-than characters to the group of disallowed characters, so that it will not pick up any HTML tags. At the end of the pattern, you can see that we want to end on a word boundary, but only if it is followed by a space, an HTML tag, or the end of a string. The complete function, which does all the matching, is as follows:
function process_description() {
var field = document.getElementById("description_field");
var description = field.value;
data.text_description = description;
var line_pattern = /\n+/g;
description = description.replace(line_pattern, function(match) {
if (match == "\n") {
return "<br />";
} else {
return "</p><p>";
}
});
var email_pattern = /\b[^\s<>@]+@[^\s<>@.]+\.[^\s<>@]+\b(?=.?(?:\s|<|$))/g;
description = description.replace(email_pattern, function(match){
return "<a href='mailto:" + match + "'>" + match + "</a>";
});
data.html_description = "<p>" + description + "</p>";
return true;
}
We can continue to add fields, but I think the point has been understood. You have a pattern that matches what you want, and with the extracted data, you are able to extract and manipulate the data into any format you may need.
Understanding the description Regex
Let's go back to the regular expression used to match the name entered by the user:
/\b[^\s<>@]+@[^\s<>@.]+\.[^\s<>@]+\b(?=.?(?:\s|<|$))/g
This is a brief explanation of the Regex:
· \b asserts its position at a (^\w|\w$|\W\w|\w\W) word boundary
· [^\s<>@]+ matches a single character not present in the list:
· The + quantifier between one and unlimited times
· \s matches a [\r\n\t\f ] whitespace character
· <>@ is a single character in the <>@ list (case-sensitive)
· @ matches the @ character literally
· [^\s<>@.]+ matches a single character not present in this list:
· The + quantifier between one and unlimited times
· \s matches any [\r\n\t\f] whitespace character
· <>@. is a single character in the <>@. list literally (case sensitive)
· \. matches the . character literally
· [^\s<>@]+ matches a single character not present in this the list:
· The + quantifier between one and unlimited times
· \s matches a [\r\n\t\f ] whitespace character
· <>@ is a single character in the <>@ list literally (case sensitive)
· \b asserts its position at a (^\w|\w$|\W\w|\w\W) word boundary
· (?=.?(?:\s|<|$)) Positive lookahead - Assert that the Regex below can be matched
· .? matches any character (except new line)
· The ? quantifier between zero and one time
· (?:\s|<|$) is a non-capturing group:
· First alternative: \s matches any white space character [\r\n\t\f]
· Second alternative: < matches the character < literally
· Third alternative: $ assert position at end of the string
· The g modifier: global match. Returns all matches of the regular expression, not only the first one
Explaining a Markdown example
More examples of regular expressions can be seen with the popular Markdown syntax (refer to http://en.wikipedia.org/wiki/Markdown). This is a situation where a user is forced to write things in a custom format, although it's still a format, which saves typing and is easier to understand. For example, to create a link in Markdown, you would type something similar to this:
[Click Me](http://gabrielmanricks.com)
This would then be converted to:
<a href="http://gabrielmanricks.com">Click Me</a>
Disregarding any validation on the URL itself, this can easily be achieved using this pattern:
/\[([^\]]*)\]\(([^(]*)\)/g
It looks a little complex, because both the square brackets and parenthesis are both special characters that need to be escaped. Basically, what we are saying is that we want an open square bracket, anything up to the closing square bracket, then we want an open parenthesis, and again, anything until the closing parenthesis.
Tip
A good website to write markdown documents is http://dillinger.io/.
Since we wrapped each section into its own capture group, we can write this function:
text.replace(/\[([^\]]*)\]\(([^(]*)\)/g, function(match, text, link){
return "<a href='" + link + "'>" + text + "</a>";
});
We haven't been using capture groups in our manipulation examples, but if you use them, then the first parameter to the callback is the entire match (similar to the ones we have been working with) and then all the individual groups are passed as subsequent parameters, in the order that they appear in the pattern.
Summary
In this chapter, we covered a couple of examples that showed us how to both validate user inputs as well as manipulate them. We also took a look at some common design patterns and saw how it's sometimes better to simplify the problem instead of using brute force in one pattern for the purpose of creating validations.
In the next chapter, we will continue exploring some real-world problems by developing an application with Node.js, which can be used to read a file and extract its information, displaying it in a more user friendly manner.