Java SE 8 for the Really Impatient (2014)
Chapter 2. The Stream API
Topics in This Chapter
![]() 2.1 From Iteration to Stream Operations
2.1 From Iteration to Stream Operations
![]() 2.2 Stream Creation
2.2 Stream Creation
![]() 2.3 The filter, map, and flatMap Methods
2.3 The filter, map, and flatMap Methods
![]() 2.4 Extracting Substreams and Combining Streams
2.4 Extracting Substreams and Combining Streams
![]() 2.5 Stateful Transformations
2.5 Stateful Transformations
![]() 2.6 Simple Reductions
2.6 Simple Reductions
![]() 2.7 The Optional Type
2.7 The Optional Type
![]() 2.8 Reduction Operations
2.8 Reduction Operations
![]() 2.9 Collecting Results
2.9 Collecting Results
![]() 2.10 Collecting into Maps
2.10 Collecting into Maps
![]() 2.11 Grouping and Partitioning
2.11 Grouping and Partitioning
![]() 2.12 Primitive Type Streams
2.12 Primitive Type Streams
![]() 2.13 Parallel Streams
2.13 Parallel Streams
![]() 2.14 Functional Interfaces
2.14 Functional Interfaces
![]() Exercises
Exercises
Streams are the key abstraction in Java 8 for processing collections of values and specifying what you want to have done, leaving the scheduling of operations to the implementation. For example, if you want to compute the average of the values of a certain method, you specify that you want to call the method on each element and get the average of the values. You leave it to the stream library to parallelize the operation, using multiple threads for computing sums and counts of each segment and combining the results.
The key points of this chapter are:
• Iterators imply a specific traversal strategy and prohibit efficient concurrent execution.
• You can create streams from collections, arrays, generators, or iterators.
• Use filter to select elements and map to transform elements.
• Other operations for transforming streams include limit, distinct, and sorted.
• To obtain a result from a stream, use a reduction operator such as count, max, min, findFirst, or findAny. Some of these methods return an Optional value.
• The Optional type is intended as a safe alternative to working with null values. To use it safely, take advantage of the ifPresent and orElse methods.
• You can collect stream results in collections, arrays, strings, or maps.
• The groupingBy and partitioningBy methods of the Collectors class allow you to split the contents of a stream into groups, and to obtain a result for each group.
• There are specialized streams for the primitive types int, long, and double.
• When you work with parallel streams, be sure to avoid side effects, and consider giving up ordering constraints.
• You need to be familiar with a small number of functional interfaces in order to use the stream library.
2.1. From Iteration to Stream Operations
When you process a collection, you usually iterate over its elements and do some work with each of them. For example, suppose we want to count all long words in a book. First, let’s put them into a list:
String contents = new String(Files.readAllBytes(
Paths.get("alice.txt")), StandardCharsets.UTF_8); // Read file into string
List<String> words = Arrays.asList(contents.split("[\\P{L}]+"));
// Split into words; nonletters are delimiters
Now we are ready to iterate:
int count = 0;
for (String w : words) {
if (w.length() > 12) count++;
}
What’s wrong with it? Nothing really—except that it is hard to parallelize the code. That’s where the Java 8 bulk operations come in. In Java 8, the same operation looks like this:
long count = words.stream().filter(w -> w.length() > 12).count();
The stream method yields a stream for the words list. The filter method returns another stream that contains only the words of length greater than twelve. The count method reduces that stream to a result.
A stream seems superficially similar to a collection, allowing you to transform and retrieve data. But there are significant differences:
1. A stream does not store its elements. They may be stored in an underlying collection or generated on demand.
2. Stream operations don’t mutate their source. Instead, they return new streams that hold the result.
3. Stream operations are lazy when possible. This means they are not executed until their result is needed. For example, if you only ask for the first five long words instead of counting them all, then the filter method will stop filtering after the fifth match. As a consequence, you can even have infinite streams!
In this chapter, you will learn all about streams. Many people find stream expressions easier to read than the loop equivalents. Moreover, they can be easily parallelized. Here is how you count long words in parallel:
long count = words.parallelStream().filter(w -> w.length() > 12).count();
Simply changing stream into paralleStream allows the stream library to do the filtering and counting in parallel.
Streams follow the “what, not how” principle. In our stream example, we describe what needs to be done: get the long words and count them. We don’t specify in which order, or in which thread, this should happen. In contrast, the loop at the beginning of this section specifies exactly how the computation should work, and thereby forgoes any chances of optimization.
When you work with streams, you set up a pipeline of operations in three stages.
1. You create a stream.
2. You specify intermediate operations for transforming the initial stream into others, in one or more steps.
3. You apply a terminal operation to produce a result. This operation forces the execution of the lazy operations that precede it. Afterwards, the stream can no longer be used.
In our example, the stream was created with the stream or parallelStream method. The filter method transformed it, and count was the terminal operation.
![]() NOTE
NOTE
Stream operations are not executed on the elements in the order in which they are invoked on the streams. In our example, nothing happens until count is called. When the count method asks for the first element, then the filter method starts requesting elements, until it finds one that has length > 12.
In the next section, you will see how to create a stream. The subsequent three sections deal with stream transformations. They are followed by five sections on terminal operations.
2.2. Stream Creation
You have already seen that you can turn any collection into a stream with the stream method that Java 8 added to the Collection interface. If you have an array, use the static Stream.of method instead.
Stream<String> words = Stream.of(contents.split("[\\P{L}]+"));
// split returns a String[] array
The of method has a varargs parameter, so you can construct a stream from any number of arguments:
Stream<String> song = Stream.of("gently", "down", "the", "stream");
Use Arrays.stream(array, from, to) to make stream from a part of an array.
To make a stream with no elements, use the static Stream.empty method:
Stream<String> silence = Stream.empty();
// Generic type <String> is inferred; same as Stream.<String>empty()
The Stream interface has two static methods for making infinite streams. The generate method takes a function with no arguments (or, technically, an object of the Supplier<T> interface—see Section 2.14, “Functional Interfaces,” on page 42). Whenever a stream value is needed, that function is called to produce a value. You can get a stream of constant values as
Stream<String> echos = Stream.generate(() -> "Echo");
or a stream of random numbers as
Stream<Double> randoms = Stream.generate(Math::random);
To produce infinite sequences such as 0 1 2 3 ..., use the iterate method instead. It takes a “seed” value and a function (technically, a UnaryOperator<T>), and repeatedly applies the function to the previous result. For example,
Stream<BigInteger> integers
= Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE));
The first element in the sequence is the seed BigInteger.ZERO. The second element is f(seed), or 1 (as a big integer). The next element is f(f(seed)), or 2, and so on.
![]() NOTE
NOTE
A number of methods that yield streams have been added to the API with the Java 8 release. For example, the Pattern class now has a method splitAsStream that splits a CharSequence by a regular expression. You can use the following statement to split a string into words:
Stream<String> words
= Pattern.compile("[\\P{L}]+").splitAsStream(contents);
The static Files.lines method returns a Stream of all lines in a file. The Stream interface has AutoCloseable as a superinterface. When the close method is called on the stream, the underlying file is also closed. To make sure that this happens, it is best to use the Java 7 try-with-resources statement:
try (Stream<String> lines = Files.lines(path)) {
Do something with lines
}
The stream, and the underlying file with it, will be closed when the try block exits normally or through an exception.
2.3. The filter, map, and flatMap Methods
A stream transformation reads data from a stream and puts the transformed data into another stream. You have already seen the filter transformation that yields a new stream with all elements that match a certain condition. Here, we transform a stream of strings into another stream containing only long words:
List<String> wordList = ...;
Stream<String> words = wordList.stream();
Stream<String> longWords = words.filter(w -> w.length() > 12);
The argument of filter is a Predicate<T>—that is, a function from T to boolean.
Often, you want to transform the values in a stream in some way. Use the map method and pass the function that carries out the transformation. For example, you can transform all words to lowercase like this:
Stream<String> lowercaseWords = words.map(String::toLowerCase);
Here, we used map with a method expression. Often, you will use a lambda expression instead:
Stream<Character> firstChars = words.map(s -> s.charAt(0));
The resulting stream contains the first character of each word.
When you use map, a function is applied to each element, and the return values are collected in a new stream. Now suppose that you have a function that returns not just one value but a stream of values, such as this one:
public static Stream<Character> characterStream(String s) {
List<Character> result = new ArrayList<>();
for (char c : s.toCharArray()) result.add(c);
return result.stream();
}
For example, characterStream("boat") is the stream ['b', 'o', 'a', 't']. Suppose you map this method on a stream of strings:
Stream<Stream<Character>> result = words.map(w -> characterStream(w));
You will get a stream of streams, like [... ['y', 'o', 'u', 'r'], ['b', 'o', 'a', 't'], ...] To flatten it out to a stream of characters [... 'y', 'o', 'u', 'r', 'b', 'o', 'a', 't', ...], use the flatMap method instead of map:
Stream<Character> letters = words.flatMap(w -> characterStream(w))
// Calls characterStream on each word and flattens the results
![]() NOTE
NOTE
You may find a flatMap method in classes other than streams. It is a general concept in computer science. Suppose you have a generic type G (such as Stream) and functions f from some type T to G<U> and g from U to G<V>. Then you can compose them, that is, first apply f and then g, by using flatMap. This is a key idea in the theory of monads. But don’t worry—you can use flatMap without knowing anything about monads.
2.4. Extracting Substreams and Combining Streams
The call stream.limit(n) returns a new stream that ends after n elements (or when the original stream ends if it is shorter). This method is particularly useful for cutting infinite streams down to size. For example,
Stream<Double> randoms = Stream.generate(Math::random).limit(100);
yields a stream with 100 random numbers.
The call stream.skip(n) does the exact opposite. It discards the first n elements. This is handy in our book reading example where, due to the way the split method works, the first element is an unwanted empty string. We can make it go away by calling skip:
Stream<String> words = Stream.of(contents.split("[\\P{L}]+")).skip(1);
You can concatenate two streams with the static concat method of the Stream class:
Stream<Character> combined = Stream.concat(
characterStream("Hello"), characterStream("World"));
// Yields the stream ['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd']
Of course, the first stream should not be infinite—otherwise the second wouldn’t ever get a chance.
![]() TIP
TIP
The peek method yields another stream with the same elements as the original, but a function is invoked every time an element is retrieved. That is handy for debugging:
Object[] powers = Stream.iterate(1.0, p -> p * 2)
.peek(e -> System.out.println("Fetching " + e))
.limit(20).toArray();
When an element is actually accessed, a message is printed. This way you can verify that the infinite stream returned by iterate is processed lazily.
2.5. Stateful Transformations
The stream transformations of the preceding sections were stateless. When an element is retrieved from a filtered or mapped stream, the answer does not depend on the previous elements. There are also a few stateful transformations. For example, the distinct method returns a stream that yields elements from the original stream, in the same order, except that duplicates are suppressed. The stream must obviously remember the elements that it has already seen.
Stream<String> uniqueWords
= Stream.of("merrily", "merrily", "merrily", "gently").distinct();
// Only one "merrily" is retained
The sorted method must see the entire stream and sort it before it can give out any elements—after all, the smallest one might be the last one. Clearly, you can’t sort an infinite stream.
There are several sorted methods. One works for streams of Comparable elements, and another accepts a Comparator. Here, we sort strings so that the longest ones come first:
Stream<String> longestFirst =
words.sorted(Comparator.comparing(String::length).reversed());
Of course, you can sort a collection without using streams. The sorted method is useful when the sorting process is a part of a stream pipeline.
![]() NOTE
NOTE
The Collections.sort method sorts a collection in place, whereas Stream.sorted returns a new sorted stream.
2.6. Simple Reductions
Now that you have seen how to create and transform streams, we will finally get to the most important point—getting answers from the stream data. The methods that we cover in this section are called reductions. They reduce the stream to a value that can be used in your program. Reductions are terminal operations. After a terminal operation has been applied, the stream ceases to be usable.
You have already seen a simple reduction: the count method that returns the number of elements of the stream.
Other simple reductions are max and min that return the largest or smallest value. There is a twist—these methods return an Optional<T> value that either wraps the answer or indicates that there is none (because the stream happened to be empty). In the olden days, it was common to return null in such a situation. But that can lead to null pointer exceptions when an unusual situation arises in an incompletely tested program. In Java 8, the Optional type is the preferred way of indicating a missing return value. We discuss the Optional type in detail in the next section. Here is how you can get the maximum of a stream:
Optional<String> largest = words.max(String::compareToIgnoreCase);
if (largest.isPresent())
System.out.println("largest: " + largest.get());
The findFirst returns the first value in a nonempty collection. It is often useful when combined with filter. For example, here we find the first word that starts with the letter Q, if it exists:
Optional<String> startsWithQ
= words.filter(s -> s.startsWith("Q")).findFirst();
If you are okay with any match, not just the first one, then use the findAny method. This is effective when you parallelize the stream since the first match in any of the examined segments will complete the computation.
Optional<String> startsWithQ
= words.parallel().filter(s -> s.startsWith("Q")).findAny();
If you just want to know there is a match, use anyMatch. That method takes a predicate argument, so you won’t need to use filter.
boolean aWordStartsWithQ
= words.parallel().anyMatch(s -> s.startsWith("Q"));
There are also methods allMatch and noneMatch that return true if all or no elements match a predicate. These methods always examine the entire stream, but they still benefit from being run in parallel.
2.7. The Optional Type
An Optional<T> object is either a wrapper for an object of type T or for no object. It is intended as a safer alternative than a reference of type T that refers to an object or null. But it is only safer if you use it right.
The get method gets the wrapped element if it exists, or throws a NoSuchElementException if it doesn’t. Therefore,
Optional<T> optionalValue = ...;
optionalValue.get().someMethod()
is no safer than
T value = ...;
value.someMethod();
As you saw in the preceding section, the isPresent method reports whether an Optional<T> object has a value. But
if (optionalValue.isPresent()) optionalValue.get().someMethod();
is no easier than
if (value != null) value.someMethod();
In the next section, you will see how you should really work with Optional values.
2.7.1. Working with Optional Values
The key to using Optional effectively is to use a method that either consumes the correct value or produces an alternative.
There is a second form of the ifPresent method that accepts a function. If the optional value exists, it is passed to that function. Otherwise, nothing happens. Instead of using an if statement, you call
optionalValue.ifPresent(v -> Process v);
For example, if you want to add the value to a set if it is present, call
optionalValue.ifPresent(v -> results.add(v));
or simply
optionalValue.ifPresent(results::add);
When calling this version of ifPresent, no value is returned. If you want to process the result, use map instead:
Optional<Boolean> added = optionalValue.map(results::add);
Now added has one of three values: true or false wrapped into an Optional, if optionalValue was present, or an empty optional otherwise.
![]() NOTE
NOTE
This map method is the analog of the map method of the Stream interface that you have seen in Section 2.3, “The filter, map, and flatMap Methods,” on page 25. Simply imagine an optional value as a stream of size zero or one. The result again has size zero or one, and in the latter case, the function has been applied.
You have just seen how to gracefully consume an optional value when it is present. The other strategy for working with optional values is to produce an alternative if no value is present. Often, there is a default that you want to use when there was no match, perhaps the empty string:
String result = optionalString.orElse("");
// The wrapped string, or "" if none
You can also invoke code to compute the default,
String result = optionalString.orElseGet(() -> System.getProperty("user.dir"));
// The function is only called when needed
Or, if you want to throw another exception if there is no value,
String result = optionalString.orElseThrow(NoSuchElementException::new);
// Supply a method that yields an exception object
2.7.2. Creating Optional Values
So far, we have discussed how to consume an Optional object that someone else created. If you write a method that creates an Optional object, there are several static methods for that purpose. Either create an Optional.of(result) or Optional.empty(). For example,
public static Optional<Double> inverse(Double x) {
return x == 0 ? Optional.empty() : Optional.of(1 / x);
}
The ofNullable method is intended as a bridge from the use of null values to optional values. Optional.ofNullable(obj) returns Optional.of(obj) if obj is not null, and Optional.empty() otherwise.
2.7.3. Composing Optional Value Functions with flatMap
Suppose you have a method f yielding an Optional<T>, and the target type T has a method g yielding an Optional<U>. If they were normal methods, you could compose them by calling s.f().g(). But that composition doesn’t work here, since s.f() has type Optional<T>,has not T. Instead, call
Optional<U> = s.f().flatMap(T::g);
If s.f() is present, then g is applied to it. Otherwise, an empty Optional<U> is returned.
Clearly, you can repeat that process if you have more methods or lambdas that yield Optional values. You can then build a pipeline of steps that succeeds only when all parts do, simply by chaining calls to flatMap.
For example, consider the safe inverse method of the preceding section. Suppose we also have a safe square root:
public static Optional<Double> squareRoot(Double x) {
return x < 0 ? Optional.empty() : Optional.of(Math.sqrt(x));
}
Then you can compute the square root of the inverse as
Double result = inverse(x).flatMap(MyMath::squareRoot);
or, if you prefer,
Double result = Optional.of(-4.0).flatMap(Test::inverse).flatMap(Test::squareRoot);
If either the inverse method or the squareRoot returns Optional.empty(), the result is empty.
![]() NOTE
NOTE
You have already seen a flatMap method in the Stream interface (see Section 2.3, “The filter, map, and flatMap Methods,” on page 25). That method was used to compose two methods that yield streams, by flattening out the resulting stream of streams. TheOptional.flatMap method works in the same way if you consider an optional value to be a stream of size zero or one.
2.8. Reduction Operations
If you want to compute a sum, or combine the elements of a stream to a result in another way, you can use one of the reduce methods. The simplest form takes a binary function and keeps applying it, starting with the first two elements. It’s easy to explain this if the function is the sum:
Stream<Integer> values = ...;
Optional<Integer> sum = values.reduce((x, y) -> x + y)
In this case, the reduce method computes v0 + v1 + v2 + ..., where the vi are the stream elements. The method returns an Optional because there is no valid result if the stream is empty.
![]() NOTE
NOTE
In this case, you can write values.reduce(Integer::sum) instead of values.reduce((x, y) -> x + y).
In general, if the reduce method has a reduction operation op, the reduction yields v0 op v1 op v2 op ..., where we write vi op vi + 1 for the function call op(vi, vi + 1). The operation should be associative: It shouldn’t matter in which order you combine the elements. In math notation, (x op y) op z = x op (y op z). This allows efficient reduction with parallel streams.
There are many associative operations that might be useful in practice, such as sum and product, string concatenation, maximum and minimum, set union and intersection. An example of an operation that is not associative is subtraction. For example, (6 – 3) – 2 ≠ 6 – (3 – 2).
Often, there is an identity e such that e op x = x, and you can use that element as the start of the computation. For example, 0 is the identity for addition. Then call the second form of reduce:
Stream<Integer> values = ...;
Integer sum = values.reduce(0, (x, y) -> x + y)
// Computes 0 + v0 + v1 + v2 + ...
The identity value is returned if the stream is empty, and you no longer need to deal with the Optional class.
Now suppose you have a stream of objects and want to form the sum of some property, such as all lengths in a stream of strings. You can’t use the simple form of reduce. It requires a function (T, T) -> T, with the same types for the arguments and the result. But in this situation, you have two types. The stream elements have type String, and the accumulated result is an integer. There is a form of reduce that can deal with this situation.
First, you supply an “accumulator” function (total, word) -> total + word.length(). That function is called repeatedly, forming the cumulative total. But when the computation is parallelized, there will be multiple computations of this kind, and you need to combine their results. You supply a second function for that purpose. The complete call is
int result = words.reduce(0,
(total, word) -> total + word.length(),
(total1, total2) -> total1 + total2);
![]() NOTE
NOTE
In practice, you probably won’t use the reduce method a lot. It is usually easier to map to a stream of numbers and use one of its methods to compute sum, max, or min. (We discuss streams of numbers in Section 2.12, “Primitive Type Streams,” on page 39.) In this particular example, you could have called words.mapToInt(String::length).sum(), which is both simpler and more efficient, since it doesn’t involve boxing.
2.9. Collecting Results
When you are done with a stream, you often just want to look at the results instead of reducing them to a value. You can call the iterator method, which yields an old-fashioned iterator that you can use to visit the elements. Or you can call toArray and get an array of the stream elements.
Since it is not possible to create a generic array at runtime, the expression stream.toArray() returns an Object[] array. If you want an array of the correct type, pass in the array constructor:
String[] result = words.toArray(String[]::new);
// words.toArray() has type Object[]
Now suppose you want to collect the results in a HashSet. If the collection is parallelized, you can’t put the elements directly into a single HashSet because a HashSet object is not threadsafe. For that reason, you can’t use reduce. Each segment needs to start out with its own empty hash set, and reduce only lets you supply one identity value. Instead, use collect. It takes three arguments:
1. A supplier to make new instances of the target object, for example, a constructor for a hash set
2. An accumulator that adds an element to the target, for example, an add method
3. An combiner that merges two objects into one, such as addAll
![]() NOTE
NOTE
The target object need not be a collection. It could be a StringBuilder or an object that tracks a count and a sum.
Here is how the collect method works for a hash set:
HashSet<String> result = stream.collect(HashSet::new, HashSet::add, HashSet::addAll);
In practice, you don’t have to do that because there is a convenient Collector interface for these three functions, and a Collectors class with factory methods for common collectors. To collect a stream into a list or set, you can simply call
List<String> result = stream.collect(Collectors.toList());
or
Set<String> result = stream.collect(Collectors.toSet());
If you want to control which kind of set you get, use the following call instead:
TreeSet<String> result = stream.collect(Collectors.toCollection(TreeSet::new));
Suppose you want to collect all strings in a stream by concatenating them. You can call
String result = stream.collect(Collectors.joining());
If you want a delimiter between elements, pass it to the joining method:
String result = stream.collect(Collectors.joining(", "));
If your stream contains objects other than strings, you need to first convert them to strings, like this:
String result = stream.map(Object::toString).collect(Collectors.joining(", "));
If you want to reduce the stream results to a sum, average, maximum, or minimum, then use one of the methods summarizing(Int|Long|Double). These methods take a function that maps the stream objects to a number and yield a result of type (Int|Long|Double)SummaryStatistics, with methods for obtaining the sum, average, maximum, and minumum.
IntSummaryStatistics summary = words.collect(
Collectors.summarizingInt(String::length));
double averageWordLength = summary.getAverage();
double maxWordLength = summary.getMax();
![]() NOTE
NOTE
So far, you have seen how to reduce or collect stream values. But perhaps you just want to print them or put them in a database. Then you can use the forEach method:
stream.forEach(System.out::println);
The function that you pass is applied to each element. On a parallel stream, it’s your responsibility to ensure that the function can be executed concurrently. We discuss this in Section 2.13, “Parallel Streams,” on page 40.
On a parallel stream, the elements can be traversed in arbitrary order. If you want to execute them in stream order, call forEachOrdered instead. Of course, you might then give up most or all of the benefits of parallelism.
The forEach and forEachOrdered methods are terminal operations. You cannot use the stream again after calling them. If you want to continue using the stream, use peek instead—see Section 2.4, “Extracting Substreams and Combining Streams,” on page 26.
2.10. Collecting into Maps
Suppose you have a Stream<Person> and want to collect the elements into a map so that you can later look up people by their ID. The Collectors.toMap method has two function arguments that produce the map keys and values. For example,
Map<Integer, String> idToName = people.collect(
Collectors.toMap(Person::getId, Person::getName));
In the common case that the values should be the actual elements, use Function.identity() for the second function.
Map<Integer, Person> idToPerson = people.collect(
Collectors.toMap(Person::getId, Function.identity()));
If there is more than one element with the same key, the collector will throw an IllegalStateException. You can override that behavior by supplying a third function argument that determines the value for the key, given the existing and the new value. Your function could return the existing value, the new value, or a combination of them.
Here, we construct a map that contains, for each language in the available locales, as key its name in your default locale (such as "German"), and as value its localized name (such as "Deutsch").
Stream<Locale> locales = Stream.of(Locale.getAvailableLocales());
Map<String, String> languageNames = locales.collect(
Collectors.toMap(
l -> l.getDisplayLanguage(),
l -> l.getDisplayLanguage(l),
(existingValue, newValue) -> existingValue));
We don’t care that the same language might occur twice—for example, German in Germany and in Switzerland, and we just keep the first entry.
However, suppose we want to know all languages in a given country. Then we need a Map<String, Set<String>>. For example, the value for "Switzerland" is the set [French, German, Italian]. At first, we store a singleton set for each language. Whenever a new language is found for a given country, we form the union of the existing and the new set.
Map<String, Set<String>> countryLanguageSets = locales.collect(
Collectors.toMap(
l -> l.getDisplayCountry(),
l -> Collections.singleton(l.getDisplayLanguage()),
(a, b) -> { // Union of a and b
Set<String> r = new HashSet<>(a);
r.addAll(b);
return r; }));
You will see a simpler way of obtaining this map in the next section.
If you want a TreeMap, then you supply the constructor as the fourth argument. You must provide a merge function. Here is one of the examples from the beginning of the section, now yielding a TreeMap:
Map<Integer, Person> idToPerson = people.collect(
Collectors.toMap(
Person::getId,
Function.identity(),
(existingValue, newValue) -> { throw new IllegalStateException(); },
TreeMap::new));
![]() NOTE
NOTE
For each of the toMap methods, there is an equivalent toConcurrentMap method that yields a concurrent map. A single concurrent map is used in the parallel collection process. When used with a parallel stream, a shared map is more efficient than merging maps, but of course, you give up ordering.
2.11. Grouping and Partitioning
In the preceding section, you saw how to collect all languages in a given country. But the process was a bit tedious. You had to generate a singleton set for each map value, and then specify how to merge the existing and new values. Forming groups of values with the same characteristic is very common, and the groupingBy method supports it directly.
Let’s look at the problem of grouping locales by country. First form this map:
Map<String, List<Locale>> countryToLocales = locales.collect(
Collectors.groupingBy(Locale::getCountry));
The function Locale::getCountry is the classifier function of the grouping. You can now look up all locales for a given country code, for example
List<Locale> swissLocales = countryToLocales.get("CH");
// Yields locales [it_CH, de_CH, fr_CH]
![]() NOTE
NOTE
A quick refresher on locales: Each locale has a language code (such as en for English) and a country code (such as US for the United States). The locale en_US describes English in the United States, and en_IE is English in Ireland. Some countries have multiple locales. For example, ga_IE is Gaelic in Ireland, and, as the preceding example shows, my JVM knows three locales in Switzerland.
When the classifier function is a predicate function (that is, a function returning a boolean value), the stream elements are partitioned into two lists: those where the function returns true and the complement. In this case, it is more efficient to use partitioningBy instead ofgroupingBy. For example, here we split all locales into those that use English, and all others:
Map<Boolean, List<Locale>> englishAndOtherLocales = locales.collect(
Collectors.partitioningBy(l -> l.getLanguage().equals("en")));
List<Locale>> englishLocales = englishAndOtherLocales.get(true);
![]() NOTE
NOTE
If you call the groupingByConcurrent method, you get a concurrent map that, when used with a parallel stream, is concurrently populated. This is entirely analogous to the toConcurrentMap method.
The groupingBy method yields a map whose values are lists. If you want to process those lists in some way, you supply a “downstream collector.” For example, if you want sets instead of lists, you can use the Collectors.toSet collector that you saw in the preceding section:
Map<String, Set<Locale>> countryToLocaleSet = locales.collect(
groupingBy(Locale::getCountry, toSet()));
![]() NOTE
NOTE
In this example, as well as the remaining examples of this chapter, I assume a static import of java.util.stream.Collectors.* to make the expressions easier to read.
Several other collectors are provided for downstream processing of grouped elements:
• counting produces a count of the collected elements. For example,
Map<String, Long> countryToLocaleCounts = locales.collect(
groupingBy(Locale::getCountry, counting()));
counts how many locales there are for each country.
• summing(Int|Long|Double) takes a function argument, applies the function to the downstream elements, and produces their sum. For example,
Map<String, Integer> stateToCityPopulation = cities.collect(
groupingBy(City::getState, summingInt(City::getPopulation)));
computes the sum of populations per state in a stream of cities.
• maxBy and minBy take a comparator and produce maximum and minimum of the downstream elements. For example,
Map<String, City> stateToLargestCity = cities.collect(
groupingBy(City::getState,
maxBy(Comparator.comparing(City::getPopulation))));
produces the largest city per state.
• mapping applies a function to downstream results, and it requires yet another collector for processing its results. For example,
Map<String, Optional<String>> stateToLongestCityName = cities.collect(
groupingBy(City::getState,
mapping(City::getName,
maxBy(Comparator.comparing(String::length)))));
Here, we group cities by state. Within each state, we produce the names of the cities and reduce by maximum length.
The mapping method also yields a nicer solution to a problem from the preceding section, to gather a set of all languages in a country.
Map<String, Set<String>> countryToLanguages = locales.collect(
groupingBy(l -> l.getDisplayCountry(),
mapping(l -> l.getDisplayLanguage(),
toSet())));
In the preceding section, I used toMap instead of groupingBy. In this form, you don’t need to worry about combining the individual sets.
• If the grouping or mapping function has return type int, long, or double, you can collect elements into a summary statistics object, as discussed in Section 2.9, “Collecting Results,” on page 33. For example,
Map<String, IntSummaryStatistics> stateToCityPopulationSummary = cities.collect(
groupingBy(City::getState,
summarizingInt(City::getPopulation)));
Then you can get the sum, count, average, minimum, and maximum of the function values from the summary statistics objects of each group.
• Finally, the reducing methods apply a general reduction to downstream elements. There are three forms: reducing(binaryOperator), reducing(identity, binaryOperator), and reducing(identity, mapper, binaryOperator). In the first form, the identity is null. (Note that this is different from the forms of Stream::reduce, where the method without an identity parameter yields an Optional result.) In the third form, the mapper function is applied and its values are reduced.
Here is an example that gets a comma-separated string of all city names in each state. We map each city to its name and then concatenate them.
Map<String, String> stateToCityNames = cities.collect(
groupingBy(City::getState,
reducing("", City::getName,
(s, t) -> s.length() == 0 ? t : s + ", " + t)));
As with Stream.reduce, Collectors.reducing is rarely necessary. In this case, you can achieve the same result more naturally as
Map<String, String> stateToCityNames = cities.collect(
groupingBy(City::getState,
mapping(City::getName,
joining(", "))));
Frankly, the downstream collectors can yield very convoluted expressions. You should only use them in connection with groupingBy or partitioningBy to process the “downstream” map values. Otherwise, simply apply methods such as map, reduce, count, max, or min directly on streams.
2.12. Primitive Type Streams
So far, we have collected integers in a Stream<Integer>, even though it is clearly inefficient to wrap each integer into a wrapper object. The same is true for the other primitive types double, float, long, short, char, byte, and boolean. The stream library has specialized typesIntStream, LongStream, and DoubleStream that store primitive values directly, without using wrappers. If you want to store short, char, byte, and boolean, use an IntStream, and for float, use a DoubleStream. The library designers didn’t think it was worth adding another five stream types.
To create an IntStream, you can call the IntStream.of and Arrays.stream methods:
IntStream stream = IntStream.of(1, 1, 2, 3, 5);
stream = Arrays.stream(values, from, to); // values is an int[] array
As with object streams, you can also use the static generate and iterate methods. In addition, IntStream and LongStream have static methods range and rangeClosed that generate integer ranges with step size one:
IntStream zeroToNinetyNine = IntStream.range(0, 100); // Upper bound is excluded
IntStream zeroToHundred = IntStream.rangeClosed(0, 100); // Upper bound is included
The CharSequence interface has methods codePoints and chars that yield an IntStream of the Unicode codes of the characters or of the code units in the UTF-16 encoding. (If you don’t know what code units are, you probably shouldn’t use the chars method. Read up on the sordid details in Core Java, 9th Edition, Volume 1, Section 3.3.3.)
String sentence = "\uD835\uDD46 is the set of octonions.";
// \uD835\uDD46 is the UTF-16 encoding of the letter ![]() , unicode U+1D546
, unicode U+1D546
IntStream codes = sentence.codePoints();
// The stream with hex values 1D546 20 69 73 20 ...
When you have a stream of objects, you can transform it to a primitive type stream with the mapToInt, mapToLong, or mapToDouble methods. For example, if you have a stream of strings and want to process their lengths as integers, you might as well do it in an IntStream:
Stream<String> words = ...;
IntStream lengths = words.mapToInt(String::length);
To convert a primitive type stream to an object stream, use the boxed method:
Stream<Integer> integers = Integer.range(0, 100).boxed();
Generally, the methods on primitive type streams are analogous to those on object streams. Here are the most notable differences:
• The toArray methods return primitive type arrays.
• Methods that yield an optional result return an OptionalInt, OptionalLong, or OptionalDouble. These classes are analogous to the Optional class, but they have methods getAsInt, getAsLong, and getAsDouble instead of the get method.
• There are methods sum, average, max, and min that return the sum, average, maximum, and minimum. These methods are not defined for object streams.
• The summaryStatistics method yields an object of type IntSummaryStatistics, LongSummaryStatistics, or DoubleSummaryStatistics that can simultaneously report the sum, average, maximum, and minimum of the stream.
![]() NOTE
NOTE
The Random class has methods ints, longs, and doubles that return primitive type streams of random numbers.
2.13. Parallel Streams
Streams make it easy to parallelize bulk operations. The process is mostly automatic, but you need to follow a few rules. First of all, you must have a parallel stream. By default, stream operations create sequential streams, except for Collection.parallelStream(). The parallelmethod converts any sequential stream into a parallel one. For example:
Stream<String> parallelWords = Stream.of(wordArray).parallel();
As long as the stream is in parallel mode when the terminal method executes, all lazy intermediate stream operations will be parallelized.
When stream operations run in parallel, the intent is that the same result is returned as if they had run serially. It is important that the operations are stateless and can be executed in an arbitrary order.
Here is an example of something you cannot do. Suppose you want to count all short words in a stream of strings:
int[] shortWords = new int[12];
words.parallel().forEach(
s -> { if (s.length() < 12) shortWords[s.length()]++; });
// Error—race condition!
System.out.println(Arrays.toString(shortWords));
This is very, very bad code. The function passed to forEach runs concurrently in multiple threads, updating a shared array. That’s a classic race condition. If you run this program multiple times, you are quite likely to get a different sequence of counts in each run, each of them wrong.
It is your responsibility to ensure that any functions that you pass to parallel stream operations are threadsafe. In our example, you could use an array of AtomicInteger objects for the counters (see Exercise 12). Or you could simply use the facilities of the streams library and group strings by length (see Exercise 13).
By default, streams that arise from ordered collections (arrays and lists), from ranges, generators, and iterators, or from calling Stream.sorted, are ordered. Results are accumulated in the order of the original elements, and are entirely predictable. If you run the same operations twice, you will get exactly the same results.
Ordering does not preclude parallelization. For example, when computing stream.map(fun), the stream can be partitioned into n segments, each of which is concurrently processed. Then the results are reassembled in order.
Some operations can be more effectively parallelized when the ordering requirement is dropped. By calling the Stream.unordered method, you indicate that you are not interested in ordering. One operation that can benefit from this is Stream.distinct. On an ordered stream,distinct retains the first of all equal elements. That impedes parallelization—the thread processing a segment can’t know which elements to discard until the preceding segment has been processed. If it is acceptable to retain any of the unique elements, all segments can be processed concurrently (using a shared set to track duplicates).
You can also speed up the limit method by dropping ordering. If you just want any n elements from a stream and you don’t care which ones you get, call
Stream<T> sample = stream.parallel().unordered().limit(n);
As discussed in Section 2.10, “Collecting into Maps,” on page 34, merging maps is expensive. For that reason, the Collectors.groupingByConcurrent method uses a shared concurrent map. Clearly, to benefit from parallelism, the order of the map values will not be the same as the stream order. Even on an ordered stream, that collector has a “characteristic” of being unordered, so that it can be used efficiently without having to make the stream unordered. You still need to make the stream parallel, though:
Map<String, List<String>> result = cities.parallel().collect(
Collectors.groupingByConcurrent(City::getState));
// Values aren't collected in stream order
 CAUTION
CAUTION
It is very important that you don’t modify the collection that is backing a stream while carrying out a stream operation (even if the modification is threadsafe). Remember that streams don’t collect their own data—the data is always in a separate collection. If you were to modify that collection, the outcome of the stream operations would be undefined. The JDK documentation refers to this requirement as noninterference. It applies both to sequential and parallel streams.
To be exact, since intermediate stream operations are lazy, it is possible to mutate the collection up to the point when the terminal operation executes. For example, the following is correct:
List<String> wordList = ...;
Stream<String> words = wordList.stream();
wordList.add("END"); // Ok
long n = words.distinct().count();
But this code is not:
Stream<String> words = wordList.stream();
words.forEach(s -> if (s.length() < 12) wordList.remove(s));
// Error—interference
2.14. Functional Interfaces
In this chapter, you have seen many operations whose argument is a function. For example, the Streams.filter method takes a function argument:
Stream<String> longWords = words.filter(s -> s.length() >= 12);
In the javadoc of the Stream class, the filter method is declared as follows:
Stream<T> filter(Predicate<? super T> predicate)
To understand the documentation, you have to know what a Predicate is. It is an interface with one nondefault method returning a boolean value:
public interface Predicate {
boolean test(T argument);
}
In practice, one usually passes a lambda expression or method reference, so the name of the method doesn’t really matter. The important part is the boolean return type. When reading the documentation of Stream.filter, just remember that a Predicate is a function returning aboolean.
![]() NOTE
NOTE
When you look closely at the declaration of Stream.filter, you will note the wildcard type Predicate<? super T>. This is common for function parameters. For example, suppose Employee is a subclass of Person, and you have a Stream<Employee>. You can filter the stream (where T is Employee) with a Predicate<Employee>, a Predicate<Person>, or a Predicate<Object>. This flexibility is particularly important for supplying method references. For example, you may want to use Person::isAlive to filter a Stream<Employee>. That only works because of the wildcard in the parameter of the filter method.
Table 2–1 summarizes the functional interfaces that occur as parameters of the Stream and Collectors methods. You will see additional functional interfaces in the next chapter.
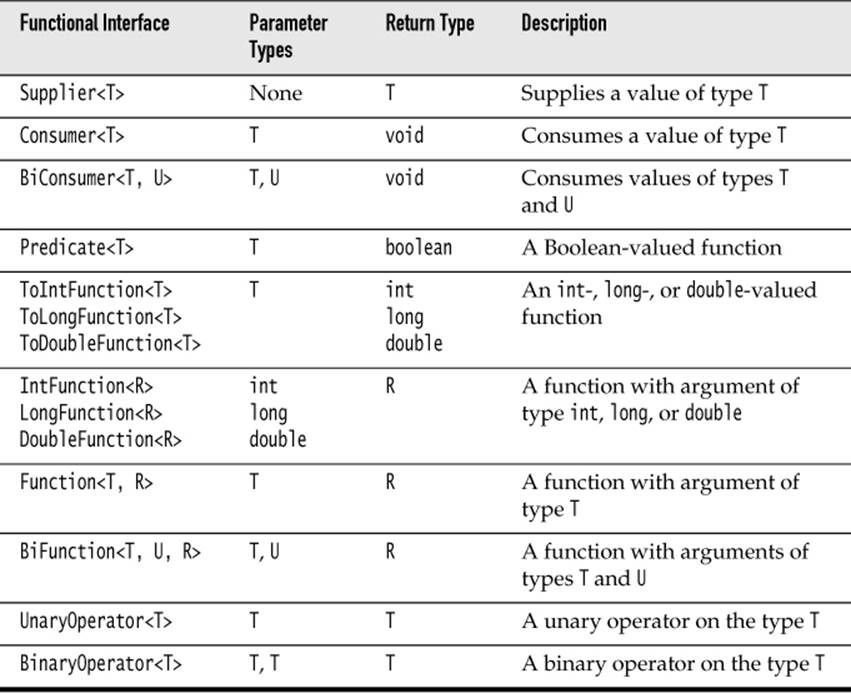
Table 2–1 Functional Interfaces Used in the Stream API
Exercises
1. Write a parallel version of the for loop in Section 2.1, “From Iteration to Stream Operations,” on page 22. Obtain the number of processors. Make that many separate threads, each working on a segment of the list, and total up the results as they come in. (You don’t want the threads to update a single counter. Why?)
2. Verify that asking for the first five long words does not call the filter method once the fifth long word has been found. Simply log each method call.
3. Measure the difference when counting long words with a parallelStream instead of a stream. Call System.currentTimeMillis before and after the call, and print the difference. Switch to a larger document (such as War and Peace) if you have a fast computer.
4. Suppose you have an array int[] values = { 1, 4, 9, 16 }. What is Stream.of(values)? How do you get a stream of int instead?
5. Using Stream.iterate, make an infinite stream of random numbers—not by calling Math.random but by directly implementing a linear congruential generator. In such a generator, you start with x0 = seed and then produce xn + 1 = (a xn + c) % m, for appropriate values of a, c, and m. You should implement a method with parameters a, c, m, and seed that yields a Stream<Long>. Try out a = 25214903917, c = 11, and m = 248.
6. The characterStream method in Section 2.3, “The filter, map, and flatMap Methods,” on page 25, was a bit clumsy, first filling an array list and then turning it into a stream. Write a stream-based one-liner instead. One approach is to make a stream of integers from 0 tos.length() - 1 and map that with the s::charAt method reference.
7. Your manager asks you to write a method public static <T> boolean isFinite(Stream<T> stream). Why isn’t that such a good idea? Go ahead and write it anyway.
8. Write a method public static <T> Stream<T> zip(Stream<T> first, Stream<T> second) that alternates elements from the streams first and second, stopping when one of them runs out of elements.
9. Join all elements in a Stream<ArrayList<T>> to one ArrayList<T>. Show how to do this with the three forms of reduce.
10. Write a call to reduce that can be used to compute the average of a Stream<Double>. Why can’t you simply compute the sum and divide by count()?
11. It should be possible to concurrently collect stream results in a single ArrayList, instead of merging multiple array lists, provided it has been constructed with the stream’s size, since concurrent set operations at disjoint positions are threadsafe. How can you achieve that?
12. Count all short words in a parallel Stream<String>, as described in Section 2.13, “Parallel Streams,” on page 40, by updating an array of AtomicInteger. Use the atomic getAndIncrement method to safely increment each counter.
13. Repeat the preceding exercise, but filter out the short strings and use the collect method with Collectors.groupingBy and Collectors.counting.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.