Mastering Lambdas: Java Programming in a Multicore World (2015)
CHAPTER 1. Taking Java to the Next Level
The changes in Java 8 are the biggest in the history of the language, combining coordinated changes to the language, the libraries, and the virtual machine. They promise to alter the way we think about the execution of Java programs and to make the language fit for use in a world, soon to arrive, of massively parallel hardware. Yet for such an important innovation, the actual changes to the language seem quite minor. What is it about these apparently minor modifications that will make such a big difference? And why should we change a programming model that has served us so well throughout the lifetime of Java, and indeed for much longer before that? In this chapter we will explore some of the limitations of that model and see how the lambda-related features of Java 8 will enable Java to evolve to meet the challenges of a new generation of hardware architectures.
1.1 From External to Internal Iteration
Let’s start with code that simply iterates over a collection of mutable objects, calling a single method on each of them. The following code fragment constructs a collection of java.awt.Point objects (Point is a conveniently simple library class, consisting only of a pair (x,y) of coordinates). Our code then iterates over the collection, translating (i.e., moving) each Point by a distance of 1 on both the x and y axes.

Before Java 5 introduced the for-each loop, we would have written the loop like this:

Or, in a clearer idiom (though less favored because it increases the scope of pointItr):

Here we are asking pointList to create an Iterator object on our behalf, and we are then using that object to access the elements of pointList in turn. This version is still relevant, because today this is the code that the Java compiler generates to implement the for-each loop. Its key aspect for us is that the order of access to the elements of pointList is controlled by the Iterator—there is nothing that we can do to change it. The Iterator for an ArrayList, for example, will return the elements of the list in sequential order.
Why is this problematic? After all, when the Java Collections Framework was designed in 1998, it seemed perfectly reasonable to dictate the access order of list elements in this way. What has changed since then?
Part of the answer lies in how hardware has been evolving. Workstations and servers have been equipped with multiple processors for a long time, but between the design of the Java Collections Framework in 1998 and the appearance of the first dual-core processors in personal computers in 2005, a revolution had taken place in chip design. A 40-year trend of exponentially increasing processor speed had been halted by inescapable physical facts: signal leakage, inadequate heat dissipation, and the hard truth that, even at the speed of light, data cannot cross a chip quickly enough for further processor speed increases.
But clock speed limitations notwithstanding, the density of chip components continued to increase. So, since it wasn’t possible to offer a 6 GHz core, the chip vendors instead began to offer dual-core processors, each core running at 3 GHz. This trend has continued, with currently no end in sight; at the time of the Java 8 ship date (March 2014) quad-core processors have become mainstream, eight-core processors are appearing in the commodity hardware market, and specialist servers have long been available with dozens of cores per processor. The direction is clear, and any programming model that doesn’t adapt to it will fail in the face of competition from models that do adapt. Adaptation would mean providing developers with an accessible way of making use of the processing power of multiple cores by distributing tasks over them to be executed in parallel.1Failing to adapt, on the other hand, would mean that Java programs, bound by default to a single core, would run at a progressively greater speed disadvantage compared to programs in languages that had found ways to assist users in easily parallelizing their code.
The need for change is shown by the code at the start of this section, which could only access list elements one at a time in the order dictated by the iterator. Collection processing is not the only processor-intensive task that programs have to carry out, but it is one of the most important. The model of iteration embodied in Java’s loop constructs forces collection element processing into a serial straitjacket, and that is a serious problem at a time when the most pressing requirement for runtimes—at least as far as performance is concerned—is precisely the opposite: to distribute processing over multiple cores. Although we will see in Chapter 6 that by no means every problem will benefit from parallelization, the best cases give us speedup that is nearly linear in the number of cores.
1.1.1 Internal Iteration
The intrusiveness of the serial model of iteration becomes obvious when we imagine imposing it on a real-world situation. If someone were to ask you to mail some letters with the instruction “repeat the following action: if you have any more letters, take the next one in alphabetical order of addressee’s surname and put it in the mailbox,” your kindest thought would probably be that they have overspecified the task. You would know that ordering doesn’t matter in this task, and neither does the mode—sequential or parallel—of execution, yet it would seem you aren’t allowed to ignore them. In this situation you might feel some sympathy with a collection forced by external iteration to process elements serially and in a fixed order when much better strategies may be available.
In reality, all you need to know for that real-world task is that every letter in a bundle needs mailing; exactly how to do that should be up to you. And in the same way, we ought to be able to tell collections what should be done to each element they contain, rather than specifying how, as external iteration does. If we could do that, what would the code look like? Collections would have to expose a method accepting the “what,” namely the task to be executed on each element; an obvious name for this method is forEach. With it, we can imagine replacing the iterative code from the start of this section with this:
pointList.forEach(/*translate the point by (1,1)*/);
Before Java 8 this would have been a strange suggestion, since java.util.List (which is the type of pointList) has no forEach method and, as an interface, cannot have one added. However, in Chapter 7 we’ll see that Java 8 overcomes this problem with the introduction of non-abstract interface methods.
The new method Collection.forEach (actually inherited by Collection from its superinterface Iterable) is an example of internal iteration, so called because, although the explicit iterative code is no longer obvious, iteration is still taking place internally. It is now managed by the forEachmethod, which applies its behavioral parameter to each element of its collection.
The change from external to internal iteration may seem a small one, simply a matter of moving the work of iteration across the client-library boundary. But the consequences are not small. The parallelization work that we require can now be defined in the collection class instead of repeatedly in every client method that must iterate over the collection. Moreover, the implementation is free to use additional techniques such as laziness and out-of-order execution—and, indeed, others yet to be discovered—to get to the answer faster.
So internal iteration is necessary if a programming model is to allow collection library writers the freedom to choose, for each collection, the best way of implementing bulk processing. But what is to replace the comment in the call of forEach—how can the collection’s methods be told what task is to be executed on each element?
1.1.2 The Command Pattern
There’s no need to go outside traditional Java mechanisms to find an answer to this question. For example, we routinely create Runnable instances and pass them as arguments. If you think of a Runnable as an object representing a task to be executed when its run method is called, you can see that what we now require is very similar. For another example, the Swing framework allows the developer to define an action that will be executed in response to a number of different events—menu item selection, button press, etc.—on the user interface. If you are familiar with classical design patterns, you will recognize this loose description of the Command Pattern.
In the case we’re considering, what command is needed? Our starting point was a call to the translate method of every Point in a List. So for this example, it appears that forEach should accept as its argument an object exposing a method that will call translate on each element of the list. If we make this object an instance of a more general interface, PointAction say, then we can define different implementations of PointAction for different actions that we want to have iteratively executed on Point collections:

Right now, the implementation we want is

Now we can sketch a naϊve implementation of forEach:

and if we make pointList an instance of PointArrayList, our goal of internal iteration is achieved with this client code:
pointList.forEach(new TranslateByOne());
Of course, this toy code is absurdly specialized; we aren’t really going to write a new interface for every element type we need to work with. Fortunately, we don’t need to; there is nothing special about the names PointAction and doForPoint; if we simply replace them consistently with other names, nothing changes. In the Java 8 collections library they are called Consumer and accept. So our PointAction interface becomes:

Parameterizing the type of the interface allows us to dispense with the specialized ArrayList subclass and instead add the method forEach directly to the class itself, as is done by inheritance in Java 8. This method takes a java.util.function.Consumer, which will receive and process each element of the collection.

Applying these changes to the client code, we get

You may think that this code is still pretty clumsy. But notice that the clumsiness is now concentrated in the representation of each command by an instance of a class. In many cases, this is overkill. In the present case, for example, all that forEach really needs is the behavior of the single method accept of the object that has been supplied to it. State and all the other apparatus that make up the object are included only because method arguments in Java, if not primitives, have to be object references. But we have always needed to specify this apparatus—until now.
1.1.3 Lambda Expressions
The code that concluded the previous section is not idiomatic Java for the command pattern. When, as in this case, a class is both small and unlikely to be reused, a more common usage is to define an anonymous inner class:

Experienced Java developers are so accustomed to seeing code like this that we have often forgotten how we felt when we first encountered it. Common first reactions to the syntax for anonymous inner classes used in this way are that it is ugly, verbose, and difficult to understand quickly, even though all it is really doing is to say “do this for each element.” You don’t have to agree completely with these judgements to accept that any attempt to persuade developers to rely on this idiom for every collection operation is unlikely to be very successful. And this, at last, is our cue for the introduction of lambda expressions.2
To reduce the verbosity of this call, we should try to identify those places where we are supplying information that the compiler could instead infer from the context. One such piece of information is the name of the interface being implemented by the anonymous inner class. It’s enough for the compiler to know that the declared type of the parameter to forEach is Consumer<T> that is sufficient information to allow the supplied argument to be checked for type compatibility. Let’s de-emphasize the code that the compiler can infer:

Second, what about the name of the method being overridden—in this case, accept? There’s no way that the compiler can infer that in general. But in the case of Consumer there is no need to infer the name, because the interface has only a single method. This “one method interface” pattern is so useful for defining callbacks that it has an official status: any object to be used in the abbreviated form that we are developing must implement an interface like this, exposing a single abstract method (this is called a functional interface, or sometimes a SAM interface). That gives the compiler a way to choose the correct method without ambiguity. Again let’s de-emphasize the code that can be inferred in this way:

Finally, the instantiated type of Consumer can often be inferred from the context, in this case from the fact that when the forEach method calls accept, it supplies it with an element of pointList, previously declared as a List<Point>. That identifies the type parameter to Consumer as Point, allowing us to omit the explicit type declaration of the argument to accept.
This is what’s left when we de-emphasize this last component of the forEach call:

The argument to forEach represents an object, implementing the interface (Consumer) required by forEach, such that when accept (the only abstract method on that interface) is called for a pointList element p, the effect will be to call p.translate(1, 1).
Some extra syntax (“->”) is required to separate the parameter list from the expression body. With that addition, we finally get the simple form for a lambda expression. Here it is, being used in internal iteration:
pointList.forEach(p -> p.translate(1, 1));
If you are unused to reading lambda expressions, you may find it helpful for the moment to continue to think of them as an abbreviation for a method declaration, mentally mapping the parameter list of the lambda to that of the imaginary method, and its body (often preceded by an addedreturn) to the method body. In the next chapter, we will see that it is going to be necessary to vary the simple syntax of the preceding example for lambda expressions with multiple parameters and with more elaborate bodies and in cases where the compiler cannot infer parameter types. But if you have followed the reasoning that brought us to this point, you should have a basic understanding of the motivation for the introduction of lambda expressions and of the form that they have taken.
This section has covered a lot of ground. To summarize: we began by considering the adaptations that our programming model needs to make in order to accommodate the requirements of changing hardware architectures; this brought us to a review of processing of collection elements, which in turn made us aware of the need to have a concise way of defining behavior for collections to execute; finally, paring away the excess text from anonymous inner class definitions brought us to a simple syntax for lambda expressions.
In the remaining sections of this chapter, we will look at some of the new idioms that lambda expressions make possible. We will see that bulk processing of collection elements can be written in a much more expressive style, that these changes in idiom make it much easier for library writers to incorporate parallel algorithms to take advantage of new hardware architectures, and finally that emphasizing functional behavior can improve the design of APIs. It’s an impressive list of achievements for such an innocuous-looking change!
1.2 From Collections to Streams
Let’s extend the example of the previous section a little. In real-life programs, it’s common to process collections in a number of stages: a collection is iteratively processed to produce a new collection, which in turn is iteratively processed, and so on. Here is an example—rather artificial, in the interests of simplicity—which starts with a collection of Integer instances, then applies an arbitrary transformation to produce a collection of Point instances, and finally finds the maximum among the distances of each Point from the origin.

Although it could certainly be improved, this is idiomatic Java—most developers have seen many examples of code in this pattern—but if we look at it with fresh eyes, some unpleasant features stand out at once. Firstly, it is very verbose, taking nine lines of code to carry out only three operations. Secondly, the collection pointList, required only as intermediate storage, is an overhead on the operation of the program; if the intermediate storage is very large, creating it would at best add to garbage collection overheads, and at worst would exhaust available heap space. Thirdly, there is an implicit assumption, difficult to spot, that the minimum value of an empty list is Double.MIN_VALUE. But the worst aspect of all is the gap between the developer’s intentions and the way that they are expressed in code. To understand this program, you have to work out what it’s doing, then guess the developer’s intention (or, if you’re very fortunate, read the comments), and only then check its correctness by matching the operation of the program to the informal specification you deduced.3 All this work is slow and error-prone—indeed, the very purpose of a high-level language is supposed to be to minimize it by supporting code that is as close as possible to the developer’s mental model. So how can the gap be closed?
Let’s restate the problem specification:
“Apply a transformation to each one of a collection of Integer instances to produce a Point, then find the greatest distance of any of these Points from the origin.”
If we de-emphasize the parts of the preceding code that do not correspond to the elements of this informal specification, we see what a poor match there is between code and problem specification. Omitting the first line, in which the list intList is initially created, we get:

This suggests a new, data-oriented way of looking at the program, one that will look familiar if you are used to Unix pipes and filters: we can follow the progress of a single value from the source collection, viewing it as being transformed first from an Integer to a Point and second from aPoint to a double. Both of these transformations can take place in isolation, without any reference to the other values being processed—exactly the requirement for parallelization. Only with the third step, finding the greatest distance, is it necessary for the values to interact (and even then, there are techniques for efficiently computing this in parallel).
This data-oriented view can be represented diagrammatically, as in Figure 1-1. In this figure it is clear that the rectangular boxes represent operations. The connecting lines represent something new, a way of delivering a sequence of values to an operation. This is different from any kind of collection, because at a given moment the values to be delivered by a connector may not all have been generated yet. These value sequences are called streams. Streams differ from collections in that they provide an (optionally) ordered sequence of values without providing any storage for those values; they are “data in motion,” a means for expressing bulk data operations. If the idea of streams is new to you, it may help to imagine a kind of iterator on which the only operation is like next, except that besides returning the next value, it can signal that there are no more values to get. In the Java 8 collections API, streams are represented by interfaces—Stream for reference values, and IntStream, LongStream, and DoubleStream for streams of primitive values—in the package java.util.stream.

FIGURE 1-1. Composing streams into a data pipeline
In this view, the operations represented by the boxes in Figure 1-1 are operations on streams. The boxes in this figure represent two applications of an operation called map; it transforms each stream element using a systematic rule. Looking at map alone, we might think that we were dealing with operations on individual stream elements. But we will soon meet other stream operations that can reorder, drop, or even insert values; each of these operations can be described as taking a stream and transforming it in some way. Each rectangular box represents an intermediate operation, one that is not only defined on a stream, but that also returns a stream as its output. For example, assuming for a moment that a stream IntStream forms the input to the first operation, the transformations made by the intermediate operations of Figure 1-1 can be represented in code as:
![]()
The circle at the end of the pipeline represents the terminal operation max. Terminal operations consume a stream, optionally returning a single value, or—if the stream is empty—nothing, represented by an empty Optional or one of its specializations (see p. 65):
OptionalDouble maxDistance = distances.max();
Pipelines like that in Figure 1-1 have a beginning, a middle, and an end. We have seen the operations that defined the middle and the end; what about the beginning? The values flowing into streams can be supplied by a variety of sources—collections, arrays, or generating functions. In practice, a common use case will be feeding the contents of a collection into a stream, as here. Java 8 collections expose a new method stream() for this purpose, so the start of the pipeline can be represented as:
Stream<Integer> intStream = intList.stream();
And the complete code with which this section began has become:

This style, often called fluent because “the code flows,” is unfamiliar in the context of collection processing and may seem initially difficult to read in this context. However, compared to the successive iterations in the code that introduced this section, it provides a nice balance of conciseness with a close correspondence to the problem statement: “map each integer in the source intList to a corresponding Point, map each Point in the resulting list to its distance from the origin, then find the maximum of the resulting values.” The structure of the code highlights the key operations, rather than obscuring them as in the original.
As a bonus, the performance overhead of creating and managing intermediate collections has disappeared as well: executed sequentially, the stream code is more than twice as fast as the loop version. Executed in parallel, virtually perfect speedup is achieved on large data sets (for more details of the experiment, see p. 148).
1.3 From Sequential to Parallel
This chapter began with the assertion that Java now needs to support parallel processing of collections, and that lambdas are an essential step in providing this support. We’ve come most of the way by seeing how lambdas make it easy for client code developers to make use of internal iteration. The last step is to see how internal iteration of the collection classes actually implements parallelism. It’s useful to know the principles of how this will work, although you don’t need them for everyday use—the complexity of the implementations is well hidden from developers of client code.
Independent execution on multiple cores is accomplished by assigning a different thread to each core, each thread executing a subtask of the work to be done—in this case, a subset of the collection elements to be processed. For example, given a fourcore processor and a list of N elements, a program might define a solve algorithm to break the task down for parallel execution in the following way:

The preceding pseudocode is a highly simplified description of parallel processing using a list specialization of the pattern of recursive decomposition—recursively splitting large tasks into smaller ones, to be executed in parallel, until the subtasks are “small enough” to be executed in serial. Implementing recursive decomposition requires knowing how to split tasks in this way, how to execute sufficiently small ones without further splitting, and how to then combine the results of these smaller executions. The technique for splitting depends on the source of the data; in this case, splitting a list has an obvious implementation. Combining the results of subtasks is often achieved by applying the pipeline terminal operation to them; for the example of this chapter, it involves taking the maximum of two subtask results.
The Java fork/join framework uses this pattern, allocating threads from its pool to new subtasks rather than creating new ones. Clearly, reimplementing this pattern is far more coding work than can realistically be expected of developers every time a collection is to be processed. This is library work—or it certainly should be!
In this case, the library class is the collection; from Java 8 onward, the collections library classes will be able to use the fork/join framework in this way, so that client developers can put parallelization, essentially a performance issue, to the back of their minds and get on with solving business problems. For our current example, the only change necessary to the client code is emphasized here:

This illustrates what is meant by the slogan for the introduction of parallelism in Java 8: explicit but unobtrusive. Parallel execution is achieved by breaking the initial list of Integer values down recursively, as in the pseudocode for solve, until the sublists are small enough, then executing the entire pipeline serially, and finally combining the results with max. The process for deciding what is “small enough” takes into account the number of cores available and, sometimes, characteristics of the list. Figure 1-2 shows the decomposition of a list for processing by four cores: in this case, “small enough” is just the list size divided by four. (A connected problem is deciding when a list is “big enough” to make it worthwhile to incur the overhead of executing in parallel. Chapter 6 will explore this problem in detail.)
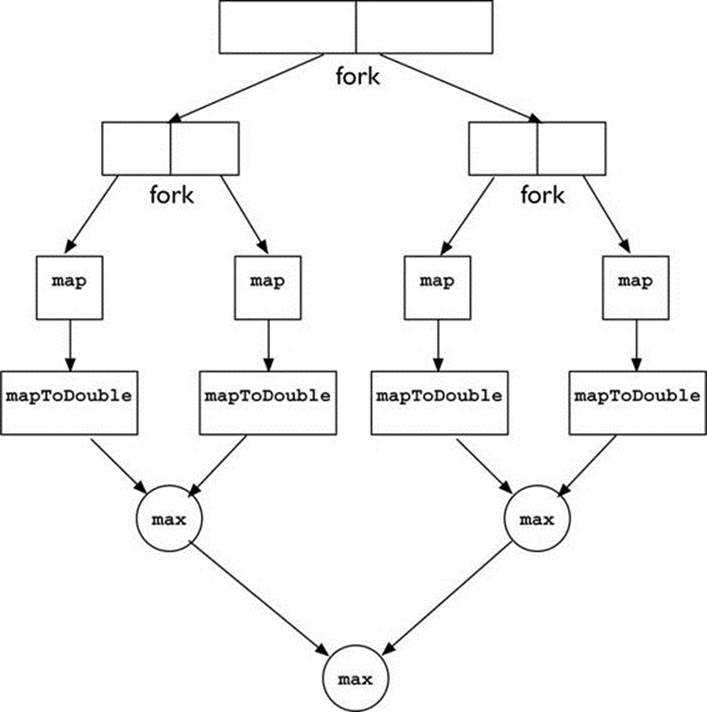
FIGURE 1-2. Recursive decomposition of a list processing task
Unobtrusive parallelism is an example of one of the key themes of Java 8; the API changes that it enables give much greater freedom to library developers. One important way in which they can use it is to explore the many opportunities for performance improvement that are provided by modern—and future—machine architectures.
1.4 Composing Behaviors
Earlier in this chapter we saw how functionally similar lambda expressions are to anonymous inner classes. But writing them so differently leads to different ways of thinking about them. Lambda expressions look like functions, so it’s natural to ask whether we can make them behave like functions. That change of perspective will encourage us to think about working with behaviors rather than objects, and that in turn will lead in the direction of some very different programming idioms and library APIs.
For example, a core operation on functions is composition: combining together two functions to make a third, whose effect is the same as applying its two components in succession. Composition is not an idea that arises at all naturally in connection with anonymous inner classes, but in a generalized form it corresponds very well to the construction of traditional object-oriented programs. And just as object-oriented programs are broken down by decomposition, the reverse of composition will work for functions too.
Suppose, for example, that we want to sort a list of Point instances in order of their x coordinate. The standard Java idiom for a “custom” sort4 is to create a Comparator:

Substituting a lambda expression for the anonymous inner class declaration, as described in the previous section, improves the readability of the code:
![]()
But that doesn’t help with another very significant problem: Comparator is monolithic. If we wanted to define a Comparator that compared on y instead of x coordinates, we would have to copy the entire declaration, substituting getY for getX everywhere. Good programming practice should lead us to look for a better solution, and a moment’s reflection shows that Comparator is actually carrying out two functions—extracting sort keys from its arguments and then comparing those keys. We should be able to improve the code of ![]() by building a Comparator function parameterized on these two components. We’ll now evolve the code to do that. The intermediate stages may seem awkward and verbose, but persist: the conclusion will be worthwhile.
by building a Comparator function parameterized on these two components. We’ll now evolve the code to do that. The intermediate stages may seem awkward and verbose, but persist: the conclusion will be worthwhile.
To start, let’s turn the two concrete component functions that we have into lambda form. We know the type of the functional interface for the key extractor function—Comparator—but we also need the type of the functional interface corresponding to the function p -> p.getX(). Looking in the package devoted to the declaration of functional interfaces, java.util.function, we find the interface Function:

So we can now write the lambda expressions for both key extraction and key comparison:
![]()
And our version of Comparator<Point> can be reassembled from these two smaller functions:
![]()
This matches the form of ![]() but represents an important improvement (one that would be much more significant in a larger example): you could plug in any keyComparer or keyExtractor that had previously been defined. After all, that was the whole purpose of seeking to parameterize the larger function on its smaller components.
but represents an important improvement (one that would be much more significant in a larger example): you could plug in any keyComparer or keyExtractor that had previously been defined. After all, that was the whole purpose of seeking to parameterize the larger function on its smaller components.
But although recasting the Comparator in this way has improved its structure, we have lost the conciseness of ![]() . We can recover that in the special but very common case where keyComparer expresses the natural ordering on the extracted keys. Then
. We can recover that in the special but very common case where keyComparer expresses the natural ordering on the extracted keys. Then ![]() can be rewritten as:
can be rewritten as:
![]()
And, noticing the importance of this special case, the platform library designers added a static method comparing to the interface Comparator; given a key extractor, it creates the corresponding Comparator5 using natural ordering on the keys. Here is its method declaration, in which generic type parameters have been simplified for this explanation:
![]()

Using that method allows us to write the following (assuming a static import declaration of Comparators.comparing) instead of ![]() :
:
![]()
Compared to ![]() ,
, ![]() is a big improvement: more concise and more immediately understandable because it isolates and lays emphasis on the important element, the key extractor, in a way that is possible only because comparing accepts a simple behavior and uses it to build a more complex one from it.
is a big improvement: more concise and more immediately understandable because it isolates and lays emphasis on the important element, the key extractor, in a way that is possible only because comparing accepts a simple behavior and uses it to build a more complex one from it.
To see the improvement in action, imagine that our problem changes slightly so that instead of finding the single point that is furthest from the origin, we decide to print all the points in ascending order of their distance. It is straightforward to capture the necessary ordering:
Comparator<Point> byDistance = comparing(p -> p.distance(0, 0));
And to implement the changed problem specification, the stream pipeline needs only a small corresponding change:

The change needed to accommodate the new problem statement illustrates some of the advantages that lambdas will bring. Changing the Comparator was straightforward because it is being created by composition and we needed to specify only the single component being changed. The use of the new comparator fits smoothly with the existing stream operations, and the new code is again close to the problem statement, with a clear correspondence between the changed part of the problem and the changed part of the code.
1.5 Conclusion
It should be clear by now why the introduction of lambda expressions has been so keenly awaited. In the earlier sections of this chapter we saw the possibilities they will create for performance improvement, by allowing library developers to enable automatic parallelization. Although this improvement will not be universally available—one purpose of this book is to help you to understand exactly when your application will benefit from “going parallel”—it represents a major step in the right direction, of starting to make the improved performance of modern hardware accessible to the application programmer.
In the last section, we saw how lambdas will encourage the writing of better APIs. The signature of Comparator.comparing is a sign of things to come: as client programmers become comfortable with supplying behaviors like the key extraction function that comparing accepts, fine-grained library methods like comparing will become the norm and, with them, corresponding improvements in the style and ease of client coding.
____________
1The distribution of a processing task over multiple processors is often called parallelization. Even if we dislike this word, it’s a useful shorthand that will sometimes make explanations shorter and more readable.
2People are often curious about the origin of the name. The idea of lambda expressions comes from a model of computation developed in the 1930s by the American mathematician Alonzo Church, in which the Greek letter (lambda) represents functional abstraction. But why that particular letter? Church seems to have liked to tease: asked about his choice, his usual explanation involved accidents of typesetting, but in later years he had an alternative answer: “Eeny, meeny, miny, moe.”
3The situation is better than it used to be. Some of us are old enough to remember how much of this kind of work was involved in writing big programs in assembler (really low-level languages, not far removed from machine code). Programming languages have become much more expressive since then, but there is still plenty of room for progress.
4Two ways of comparing and sorting objects are standard in the Java platform: a class can have a natural order; in this case, it implements the interface Comparable and so exposes a compareTo method that an object can use to compare itself with another. Or a Comparator can be created for the purpose, as in this case.
5Other overloads of comparing can create Comparators for primitive types in the same way, but since natural ordering can’t be used, they instead use the compare methods exposed by the wrapper classes.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.