Mastering Lambdas: Java Programming in a Multicore World (2015)
CHAPTER 2. The Basics of Java Lambda Expressions
Chapter 1 gave an informal introduction to lambda expressions and motivated their introduction to Java. This chapter defines more precisely what lambda expressions are, and how and where they can be used in Java programs.
2.1 What Is a Lambda Expression?
In mathematics and computing generally, a lambda expression is a function: for some or all combinations of input values it specifies an output value. Until now, there has been no way to write a freestanding function in Java. Methods have often been used to stand in for functions, but always as part of an object or a class. Lambda expressions now provide a closer approach to the idea of freestanding functions.1 In conventional Java terms, lambdas can be understood as a kind of anonymous method with a more compact syntax that also allows the omission of modifiers, return type, throws clause, and in some cases parameter types as well.
2.1.1 The Syntax of Lambdas
A lambda expression in Java consists of a parameter list separated from a body by a function arrow: “->”. The examples of Chapter 1 all had a single parameter:

But, as you would expect from the similarity to method declarations, lambdas can in general have any number of parameters. Except for lambdas that have a single parameter, like those we have seen, parameter lists must be surrounded by parentheses:
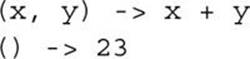
Also, until now, parameters have been declared without being given explicit types, because lambdas are often more readable without them. It is always permissible, however, to supply parameter types—and sometimes it is necessary, when the compiler cannot infer them from the context. If you supply any types explicitly, you must supply all of them, and the parameter list must be enclosed in parentheses:
![]()
Such explicitly typed parameters can be modified in the same way as method parameters—for example, they can be declared final—and annotated.
The lambda body on the right-hand side of the function arrow can be an expression, as in all the examples seen so far. (Notice that method calls are expressions, including those that return void.) Lambdas like these are sometimes called “expression lambdas.” A more general form is the “statement lambda,” in which the body is a block—that is, a sequence of statements surrounded by braces:
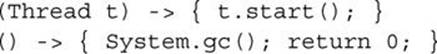
An expression lambda
![]()
can be seen as a short form of the corresponding statement lambda
![]()
The rules for using or omitting the return keyword in a block body are the same as those for an ordinary method body—that is, return is required whenever an expression within the body is to return a value, or can instead be used without an argument to terminate execution of the body immediately. If the lambda returns void, then return may be omitted or used without an argument.
Lambda expressions are neither required nor allowed to use a throws clause to declare the exceptions they might throw.
2.2 Lambdas vs. Anonymous Inner Classes
If you followed the progressive transformation in Chapter 1 of an anonymous inner class into a lambda expression, you may be wondering whether, aside from concrete syntax, there is any real difference between the two. Indeed, lambda expressions are sometimes incorrectly called “syntactic sugar” for anonymous inner classes, implying that there is a simple syntactic transformation between the two. In fact, there are a number of significant differences; two in particular are important to the programmer:
1. An inner class creation expression is guaranteed to create a new object with unique identity, while the result of evaluating a lambda expression may or may not have unique identity, depending on the implementation. This flexibility allows the platform to use more efficient implementation strategies than for the corresponding inner classes.
2. An inner class declaration creates a new naming scope, within which this and super refer to the current instance of the inner class itself; by contrast, lambda expressions do not introduce any new naming environment. In this way they avoid the complexity in name lookup for inner classes that causes many subtle errors, such as mistakenly calling Object methods on the inner class instance when the enclosing instance was intended.
These points are explained further in the next two subsections.
2.2.1 No Identity Crisis
Until now, behavior in a Java program has been associated with an object, characterized by identity, state, and behavior. Lambdas are a departure from this rule; although they share some of the properties of objects, their only use is to represent behavior. Since they have no state, the question of their identity is unimportant. The language specification explicitly leaves it undetermined, the only requirement being that a lambda must evaluate to an instance of a class that implements the appropriate functional interface (§2.4). The intention is to give the platform flexibility to optimize in ways that would not be possible if every lambda expression were required to have a unique identity.
2.2.2 Scoping Rules for Lambdas
The scoping rules for anonymous inner classes, like those for most inner classes, are complicated by the fact that they can refer both to names inherited from their supertypes and to names declared in their enclosing class. Lambda expressions are simpler, because they do not inherit names from their supertypes.2 Other than its parameters, names used in the body of a lambda expression mean exactly the same as they do outside the body. So, for example, it is illegal to redeclare a local variable within a lambda:
![]()
Parameters are like local declarations in that they may introduce new names:
![]()
Lambda parameters and lambda body local declarations may shadow field names (i.e., a field name can be temporarily redeclared as a parameter or local variable name).
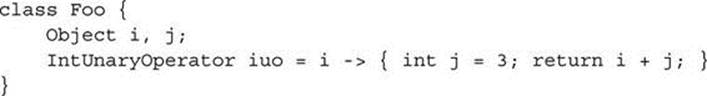
Since lambda declarations are scoped like simple blocks, the keywords this and super have the same meaning as in the enclosing environment: that is, they refer respectively to the enclosing object and its superclass object. For example, the following program prints the message Hello, world! twice to the console:

If the same program were written using anonymous inner classes instead of lambdas, it would print the result of calling the toString method of Object on the inner classes. The more common use case of accessing the current instance of the enclosing object, which is straightforward for lambdas, requires the awkward syntax OuterClass.this for anonymous inner classes.
One question often arises in connection with the rule for interpreting this: can a lambda refer to itself? A lambda can refer to itself if its name is in scope, but the rules restricting forward references in initializers (for both local and instance variables) prevent lambda variable initialization. It is still possible to declare a recursively defined lambda:

This idiom is considered adequate for the relatively unusual occasions on which a recursive lambda definition is required.
2.3 Variable Capture
In the previous section, we saw how to interpret names that a lambda expression inherits from its enclosing environment. But name interpretation is only part of the story; once we have understood the meaning of a variable name inherited from the environment, we still have to know what we can do with it—and what we should do with it, which may not be the same thing.
First, notice that many useful lambda expressions do not in fact inherit any names from their environment. Object-oriented programmers can understand this by analogy with static methods; although in general the behavior of objects depends on their state, it is often useful to define methods that do not depend on the system state in any way. The utility class java.lang.Math, for example, contains only static methods—it makes no sense to take account of the system state in calculating, for example, the square root of a number. Lambdas can fulfill the same role; a lambda that will produce the same result as a call of Math.sqrt could be written like this:
DoubleUnaryOperator sqrt = x -> Math.sqrt(x)
Lambdas like these, which interact with their environment only via arguments and return values, are called stateless, or non-capturing. Capturing lambdas, by contrast, can access the state of their enclosing object. “Capture” is the technical term for the retention by a lambda of a reference to its environment. The connotation is that the variable has been ensnared by the lambda and held, to be queried or—in other languages—modified, when the lambda is later evaluated.
The access provided by capture is restricted; the central principle of the restriction is that captured variables may not have their values changed. So although the traditional term is “variable capture,” in fact it would be more accurate to call it “value capture.” To understand how the principle is implemented, let’s first consider local variable capture; after that, field capture will be a simpler case.
Traditionally, for local classes in general and anonymous inner classes in particular, the only local variables from the enclosing method that could be accessed in the inner class were those declared final. The rule for lambdas in Java 8 is very similar, with only a little relaxation of the syntactic requirements: to ensure that a lambda can never change the value of a variable that it has captured from its enclosing environment, the variable must be effectively final, meaning that it is never anywhere assigned to after its initialization. (As of Java 8, anonymous and local classes can also access effectively final variables.)
Essentially, effective finality allows omission of the keyword final from the declaration of a variable that is going to be treated as final. The restriction of capture to effectively final variables has attracted controversy around the contrast with other languages, for example JavaScript, that do not have this restriction. The justification for preventing mutation of local variables by lambdas is that it would introduce very complex changes that would affect both program correctness and performance, and that it is in any case unnecessary:
• Correctness: Lifting this restriction would allow the introduction of a new class of multithreading bugs involving local variables. Local variables in Java have until now been immune to race conditions and visibility problems because they are accessible only to the thread executing the method in which they are declared. But a lambda can be passed from the thread that created it to a different thread, and that immunity would therefore be lost if the lambda, when evaluated by the second thread, were given the ability to mutate local variables.
Further, regardless of the number of threads involved, a lambda can outlive the call to the method that evaluated it. If captured locals were mutable, they too would need to outlive the method call that created them. This change would introduce, among other consequences, a new possibility of memory leaks involving local variables.
• Performance: Programs that allow multithread access to mutable variables can be guaranteed correct, if access to the variables is guarded by synchronization. But the cost of this would frustrate one of the principal purposes of introducing lambdas—to allow strategies that efficiently distribute evaluation of a function for different arguments to different threads. Even the ability to read the value of mutable local variables from a different thread would introduce the necessity for synchronization or the use of volatile in order to avoid reading stale data.
• Inessentiality: Another way to view this restriction is to consider the use cases that it discourages. The idioms that are forbidden by this restriction involve initialization and mutation, like this simple example for summing the values in a List<Integer>:
![]()
The Stream API offers better alternatives. In this simple case, we can write

A guiding principle of the Java 8 design, explained in detail in the following chapters, is that the effort of learning to use this functional style will be more than repaid by the improvement in code quality that it brings. The fact that code in this style is also parallel-ready(§3.1.1) can be seen as a bonus, bringing better performance in some situations now, and in many more situations in future.
It is no secret that the restriction to effective finality is easily evaded. For example, if the local variable is an array reference, the variable can be final but the array contents will still be mutable. You can use this well-known trick to implement an iterative idiom, but then executing in parallel, even unintentionally, will expose race conditions. You can prevent these by synchronization, but only at the cost of increased contention and reduced performance.3 In short, don’t do it!
It appears that no restriction such as effective finality applies to the capture of field names, but this is actually consistent with the treatment of local variables: a reference to a fieldname foo is actually a shorthand for this.foo, with the pseudo-variable this in the role of an effectively immutable local variable. As with a reference to a field of any other object, the only value captured when the lambda is the object reference—in this case, this. When the lambda is evaluated, this is dereferenced—in the same way as any local reference variable—and the field accessed.
It may appear that the arguments against allowing mutation of local variables should apply to fields as well. But lambdas are intended to provide a gentle impetus away from mutation, where better alternatives are available, not a wholesale conversion of Java into a functional language. The situation prior to Java 8 was that shared variable mutation was easily achieved—perhaps too easily!—and the responsibility on developers was to avoid it or, if that was impossible, to manage it. Mutation of field values by lambdas doesn’t change that situation.
2.4 Functional Interfaces
We know from §1.1.3 that a lambda expression must implement a functional interface. But to make practical use of lambdas and functional interfaces, we need to understand the relationship between them more precisely. This section gives an overview and briefly surveys the functional interfaces provided in the library java.util.function. Later (in §2.7), we’ll explore the relationship in more detail.
The reason that functional interfaces have this central role derives from their most important property, the one that gives them their name: they can be used to describe the type of a function. For example, the interface UnaryOperator
![]()
describes the function
![]()
This is its function type, which in the simplest and most common case, as here, is just the method type of a functional interface’s single abstract method: that is, the method’s type parameters, formal parameter types, return types, and—where applicable—thrown types. (Function types were previously called “function descriptors”; you may still come across this term.) §2.7.1 explains function types in more detail.
The function type is what a lambda must match, allowing for some adaptation of types through boxing or unboxing, widening or narrowing, etc. For example, suppose we have declared a variable pointList as a List<Point>, and we now want to replace every element in it. The methodreplaceAll is suitable for this purpose:

Class Diagram Conventions
The class diagrams for platform library APIs in this book use some simplifying abbreviations:
• The icon at the top right contains “i” or “s” to indicate whether the diagram contains instance or static methods.
• Wildcard bounds on generic parameter types are omitted (for example, the parameter to forEach is actually Consumer<? extends T>).
• If you see a type variable in a method declaration but not in the class declaration, then you can assume it is a type parameter of the method.
• Diagrams are not necessarily complete—they list only the methods important for the discussion.
The call could look like this:
![]()
For this to compile, the lambda expression must match the function type of UnaryOperator<Point>, which is the type of the method
public Point apply(Point p);
This case is straightforward, but in general the matching process offers some new challenges to type checking. Previously, any well-formed Java expression had a defined type; now, although every lambda in a well-typed statement or expression implements a functional interface, exactlywhich functional interface it implements is only partly determined by the lambda itself. Enough information must be provided by the context to allow an exact type to be inferred, a process known as target typing.4 Here is an example of a lambda expression that, in isolation, has many possible types:
x -> x * 2
This expression can be an instance of many functional interfaces, including these two, declared in java.util.function:

So both of the assignments

are legal, because in each case the type of the lambda expression is compatible with the target type, namely the functional interface type of the variable being assigned. The compiler determines that type for the first case by typing the lambda parameter as int, making the lambda as a whole a function from int to int. That matches the function type of IntUnaryOperator, which also takes an int and returns an int. Similarly, in the second case, the lambda parameter can be typed as double, making the lambda a function from double to double, which matches the function type ofDoubleUnaryOperator.
Two lambdas can be textually identical, like those we have just seen, but have different types—and different meanings; the operation on int values is different from the one on doubles. The types are established at compile time and cannot be changed, so there is no way of reusing the same lambda text for different types (unless they are compatible by casting in the usual way). The next section shows an example (p. 31).
Table 2-1 shows the four basic types of functional interfaces declared in java.util.function, with sample use cases and examples of lambda instances (with the type parameter T instantiated to String and U to Integer).

TABLE 2-1. Basic functional interfaces in java.util.function
The forty-odd types defined in java.util.function are evolved from these four by various combinations of three different routes:
• Primitive specializations: these interfaces replace type parameters with primitive types. Examples include:

• The function types of Consumer, Predicate, and Function all take a single argument. There are corresponding interfaces that take two arguments, for example:

• Common use cases for Function require its parameter and result to have the same type. We saw an example of this in the parameter to List.replaceAll. These use cases are met by specializing the variations of Function to corresponding Operators, for example:

This library is a “starter kit,” intended to cover the common use cases for functional interfaces. If your use case is not covered, it is easy to declare a functional interface of your own, although it is good practice to make use of those in the library when possible. It is also good practice to annotate custom functional interface declarations with @FunctionalInterface so that the compiler can check that your interface declares exactly one abstract method, and so that the Javadoc for it will automatically have an explanatory section added.
2.5 Using Lambda Expressions
A lambda expression can be written wherever a reference to a functional interface instance would be valid, provided that the context of the occurrence provides an appropriate target type—that is, provided the context unambiguously requires a functional interface type. For example, the target type of the declaration
IntPredicate ip = i -> i > 0;
is IntPredicate, a functional interface whose function type is compatible with the lambda i -> i > 0. By contrast, the declaration
Object o = i -> i > 0; // invalid
does not compile, because the target type required by the context is not that of a functional interface, so does not give the compiler the type information that it needs to compile the lambda.
Six kinds of contexts can provide appropriate target types:
• Method or constructor arguments, for which the target type is the type of the appropriate parameter. We have already seen straightforward examples of this throughout Chapter 1.
• Variable declarations and assignments, for which the target type is the type being assigned to:
![]()
Array initializers are similar except that the target type is the type of the array component:
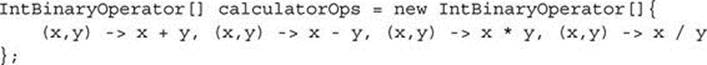
Arrays of lambdas have limited application, however, since most functional interfaces are generic, and generic array creation is not allowed.
• Return statements, for which the target type is the return type of the method:

• Lambda expression bodies, for which the target type is the type expected for the body, which is derived in turn from the outer target type. Consider
![]()
The outer target type here is Callable<Runnable>, whose function type is the type of the method
Runnable call() throws Exception;
so the target type of the lambda body is the function type of Runnable, which is the type of the run method. This takes no arguments and returns no values, so matches the inner lambda.
• Ternary conditional expressions, for which the target type for both arms is provided by the context. For example:
![]()
• Cast expressions, which provide the target type explicitly. For example:

The first of these declarations is illegal because no target type is available to resolve the ambiguous declaration of the lambda. The second and third are legal because the casts provide a target type. This example also illustrates the point that textually identical lambdas can have different types; attempting to reuse a lambda with a different type, for example by writing
Callable c1 = (Callable) s;
will compile, but would fail at run time with a ClassCastException.
2.6 Method and Constructor References
We have seen that any lambda expression may be thought of as an implementation of (in the common case) the single abstract method declaration of a functional interface. But when a lambda expression is simply a way of calling a named method of an existing class, a better way of writing it may be just using the existing name. For example, consider this code, which prints to the console every element of a list:
pointList.forEach(s -> System.out.print(s));
The lambda expression here simply passes its argument on to the call of print. A lambda like this, whose only purpose is to supply its arguments to a concrete method, is fully defined by the type of that method. So, provided the type can be determined by some means, a shorthand form containing only the method name will provide as much information as the full lambda but in a more readable form. Instead of the preceding code we can write:
pointList.forEach(System.out::print);
to mean exactly the same thing. This way of writing a handle to a concrete method of an existing class is called a method reference. There are four types of method reference, as shown in Table 2-2. The rest of this section explains the purpose of each type.

TABLE 2-2. Method Reference Types
2.6.1 Static Method References
The syntax for static method references simply requires class and static method name, separated by a double colon. For example,
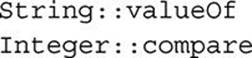
are references to static methods. To see how static method references can be used, suppose we want to sort an array of Integer by magnitude, treating the values as unsigned. The natural order for Integer is numerical (i.e., it takes account of the sign of values), so we will need to provide an explicit Comparator. We can make use of the static method Integer.compareUnsigned:
![]()
so sorting our array, integerArray say, by this call
Arrays.sort(integerArray, (x,y) -> Integer.compareUnsigned(x, y));
would be legal, but more verbose and repetitive than its static method reference equivalent:
Arrays.sort(integerArray, Integer::compareUnsigned);
In fact, this method was introduced in Java 8 partly in anticipation of its use in this way. In the future, one factor in API design will be the desirability of method signatures being suitable for functional interface conversion.
Notice in Table 2-2 that the syntax ReferenceType::Identifier doesn’t always represent a reference to a static method. As we are about to see, this syntax can be used to reference instance methods as well.
2.6.2 Instance Method References
There are two ways of referring to instance methods. Bound method references are analogous to the static case, replacing the form ReferenceType::Identifier with ObjectReference::Identifier. The example that introduced this section was a bound method reference: the forEach method was used to pass each element from a collection into the instance method print of the PrintStream object System.out for processing, replacing the lambda expression
pointList.forEach(p -> System.out.print(p));
with the bound method reference
pointList.forEach(System.out::print);
Bound references are so called because the receiver is fixed as part of the method reference. Every invocation of the method reference System.out::print will have the same receiver: System.out. Often, however, you want to invoke a method reference with the method receiver as well as its arguments taken from the arguments to the method reference. For this, you need an unbound method reference, so called because the receiver is not fixed; rather, the first argument to the method reference is used as the receiver. Unbound method references are easiest to understand when there is only one argument; for example, to create a Comparator using the factory method comparing (p. 16), we could use an unbound reference to replace the lambda expression
Comparator personComp = Comparator.comparing(p -> p.getLastName());
with the unbound method reference
Comparator personComp = Comparator.comparing(Person::getLastName);
An unbound method reference can be recognized from its syntax: as with static method references, the form ReferenceType::Identifier is used, but in this case Identifier refers to an instance method rather than a static one. To explore the difference between bound and unbound method references, consider calling the method Map.replaceAll supplying each kind of instance method reference:

The effect of Map.replaceAll is to apply its BiFunction argument to every key-value pair in the map, replacing the value component of the key-value pair with the result. So if the variable map refers to a TreeMap with this as its string representation:
{alpha=X, bravo=Y, charlie=Z}
then the effect of calling replaceAll with a bound method reference

would be three applications of str.replace, namely:

The result of each call would replace the corresponding value, so afterwards the map would contain
{alpha=X-bravo-charlie, bravo=alpha-Y-charlie, charlie=alpha-bravo-Z}
Now let’s restart the example with map at its initial value, and again call replaceAll, this time with the unbound method reference String::concat, a reference to an instance method of String that takes a single argument. It seems strange to be using a one-argument instance method as aBiFunction, but in fact it is the method reference that is the BiFunction: it is passed two arguments, the key-value pair, and takes the first argument as the receiver, so the method itself is called like this:
key.concat(value)
The first argument to the method reference is shifted into the receiver position, and the second (and subsequent, if any) arguments are shifted left one position. So the result of the call
![]()
is
![]()
2.6.3 Constructor References
In the same way that method references are handles to existing methods, constructor references are handles to existing constructors. Constructor references are created using syntax similar to that of method references, but with the method name replaced by the keyword new. For example:
ArrayList::new
File::new
As with method references, the choice between overloaded constructors is made using the target type of the context. For example, in the following code, the target type of the map argument is a function of type String -> File; to match this, the File constructor with a single Stringparameter will be chosen by the compiler.
![]()
2.7 Type Checking
This section examines the conditions needed for a lambda to match a function type, and the next section explains how type inference can resolve a call to the “best” method overload. These two sections are quite detailed; you may choose either to skip them or scan them quickly on a first reading.
Earlier in this chapter, we saw that a lambda expression can be said to have a single type only when it appears in a context that provides a target type. Expressions like this, whose type is partly decided by their context, are called poly expressions. Method and constructor references are also poly expressions; without context, the expression String::valueOf could refer to any of the nine different String methods of that name. This section and the next one explore the process of type checking lambdas and method and constructor references. But since that type checking takes place against a functional interface’s function type, it’s necessary first to have a precise definition of function types.
2.7.1 What Exactly Is a Function Type?
In the rest of this chapter, the idea of a function type will often be important to understanding how type checking works, so it is worth pinning it down precisely. In fact, the simple definition given in §2.4 is sufficient in most cases: the function type of a functional interface is the type of its single abstract method—that is, its type parameters together with its parameter, return, and thrown types.
However, this simple definition can be complicated by two factors: first, all interfaces declare (implicitly, if not explicitly) abstract methods corresponding to the public methods in Object, and the single abstract method of a functional interface is in addition to these. Most often the Objectmethods are declared implicitly, but not always; for example, Comparator explicitly declares a method equals that matches the equals method of Object. In such cases the explicit declaration makes no difference; Comparator still meets the definition of a functional interface.
The second complicating factor is that two interfaces might have methods that are not identical but are related by erasure. For example, the methods of the two interfaces

are said to be override-equivalent. If the superinterfaces of an interface contain override-equivalent methods, the function type of that interface is the type of a single method that can legally override all the inherited abstract methods. In this example, if
interface Foo extends Foo1, Foo2 {}
then the function type of Foo is the method type corresponding to
public void bar(List arg);
These complications do not have much general impact on the appealingly simple idea of a single abstract method, but it is useful to bear them in mind when encountering corner cases like Comparator.
2.7.2 Matching a Function Type
Type checking a lambda against a functional interface type provided by target typing requires that the lambda expression be compatible with the interface’s function type. For example, the assignment
UnaryOperator<Integer> b = x -> x.intValue();
compiles because the lambda expression is compatible with the function type of UnaryOperator<Integer>. These are the conditions for compatibility to hold:5
Arities The lambda and the function type must have the same number of arguments.
Parameter types If the lambda expression is explicitly typed, the types must exactly match the parameters of the function type; if the lambda is implicitly typed then, for return type checking (in the next step), its argument types are assumed to be the same as those of the function type.
Return types
• If the function type returns void, then the lambda body must be a statement expression (i.e., an expression that can be used as a statement, like a method call or an assignment), for example:
(int i) -> i++;
—notice that the value of the statement expression is discarded—or a block body without a value-bearing6 return statement, for example:
(Thread t) -> { t.start(); }
• If the function type has a non-void return type, then the lambda body must return an assignment-compatible value. For example, this lambda body returns an int value, to be assigned to the Integer result of the UnaryOperator’s function type:
UnaryOperator<Integer> b = x -> x.intValue();
To the compatibility conditions just given, a further condition must be added to ensure that a lambda expression will compile:
Thrown types A lambda can throw a checked exception only if that exception, or one of its supertypes, is declared to be thrown by the function type.
This last condition can cause problems. For example, suppose we want to declare a method to centralize the handling of IOException for a number of different I/O operations implemented by parameterless methods of File. A first thought might be to declare it like this:
![]()
but the function type for Function does not declare any exceptions, so a call like
executeFileOp(f, File::delete);
will fail to compile. Instead, a custom functional interface is needed:

so that we can then declare executeFileOp as we intended:

To summarize: a lambda can handle an exception thrown to it in the same two possible ways as any other method—it can (implicitly) declare it to its caller or it can handle it in a catch block. Since none of the library functional interfaces declare any exceptions, a lambda can only pass an exception to its caller if it implements a user-defined functional interface, as in the example. By contrast, we will see in §5.3 that for stream processing we have to take the alternative route of handling checked exceptions inside lambdas, since the parameters of the stream processing operations are all library functional interfaces. To summarize more briefly: checked exception handling is a problem area in the design of Java 8 lambdas.
2.8 Overload Resolution
Using the compatibility criteria of §2.7.2, target typing of lambda expressions is straightforward when the functional interface type can be determined without ambiguity. Most of the target type contexts listed in §2.5 provide unambiguous contexts. Unfortunately, the most commonly used contexts for lambda expressions—method call sites—can also be the most problematic when the method in question has different overloaded variants. The difficulties described in this section are not commonly met; when they do appear, however, they can lead to frustrating compilation problems. And if you are designing an API, your users are depending on you to avoid them. So it is worth studying the topic now—forewarned is forearmed!
Here is a short summary of the challenge of overload resolution: calls to overloads of different arities are usually easily distinguished, but choosing between two overloads of the same arity requires the compiler to know the type of the arguments being supplied. In the case of an untyped lambda this is a problem, since its type cannot be inferred without a target type, and the target type is provided by the method declaration, so cannot be known until overload resolution is done! It’s possible to break this circularity by imposing some arbitrary rules, making the process of type inference counterintuitive and unpredictable, or to force the user to supply lambda parameter types. To avoid these undesirable alternatives, the designers ended up making overload resolution more tolerant of reasoning under uncertainty and designing new APIs so as to allow effective overload resolution with implicitly typed lambdas.
2.8.1 Overloading with Lambda Expressions
Before exploring the difficulties of using type inference, let’s see how it works in a straightforward case. Chapter 1 (§1.4) introduced the method Comparator.comparing which, given a key extractor, creates a Comparator from it. This is one overload of comparing (with most type bounds omitted for readability):
![]()
Suppose that we want to sort strings by their length. Given an unambiguous target type such as assignment provides, comparing can take an untyped lambda and use it to create a comparator for the purpose:
![]()
Here is a highly simplified account of how the lambda type in ![]() is resolved. First, the compiler must choose a set of comparing overloads against which to check the lambda. This set can only contain
is resolved. First, the compiler must choose a set of comparing overloads against which to check the lambda. This set can only contain ![]() , given that the other overload has two arguments. Now that the overload has been chosen, matching the return type of
, given that the other overload has two arguments. Now that the overload has been chosen, matching the return type of ![]() against the target type provided by
against the target type provided by ![]() allows the compiler to deduce that in this case T is String. Now the lambda expression can be matched against the function type for Function<T,U>:
allows the compiler to deduce that in this case T is String. Now the lambda expression can be matched against the function type for Function<T,U>:
public U apply(T t)
Since the argument type T to the lambda is known to be String, the type returned by String.length—which is int, boxed to Integer—can be substituted for U. All the types are now known and the type bound on U in ![]() , which guarantees that the result of the lambda implements Comparable, can be checked for Integer. Everything is consistent, and the call can be compiled.
, which guarantees that the result of the lambda implements Comparable, can be checked for Integer. Everything is consistent, and the call can be compiled.
So far, so good. But suppose that Comparator declared another overload of comparing:

At one time in the development of Java 8, this overload really did exist. If we try again to type check ![]() in its presence, we will see why it was withdrawn. Following the same process as before, the compiler first tries to choose a set of overloads to type check. The rule is that this must be done before any type checking of untyped lambdas. (Certain untyped lambdas could in fact be type checked before method overload resolution, but this was abandoned when the designers found that it made the overall process more inconsistent and confusing.)
in its presence, we will see why it was withdrawn. Following the same process as before, the compiler first tries to choose a set of overloads to type check. The rule is that this must be done before any type checking of untyped lambdas. (Certain untyped lambdas could in fact be type checked before method overload resolution, but this was abandoned when the designers found that it made the overall process more inconsistent and confusing.)
Given that rule, there is little information available to help with method overload resolution. The compiler cannot use the target type provided by the assignment context, because another important rule says that a method call with a given set of arguments must be resolved to the same overload anywhere it occurs, regardless of context. It can use other arguments to the method call, but in this case there are none. It can use some information from the lambda expression, but for the compatibility conditions an untyped lambda like this one can only report the number of arguments it accepts and whether it is returning a value. In this case, those are no help either: the lambda accepts one argument and returns a value, matching the function types of both candidate functional interfaces. So progress is blocked and the compiler reports an error, with the message “reference to comparing is ambiguous.”
How could we avoid this? If the lambda’s argument type were known, the compiler could use that information to check both of the candidate function types, using the algorithm described at the start of this section. Since the argument type is String, it would find them both compatible with the lambda. It could then choose between them on the basis of which returns the most specific result: ToIntFunction returns an int, which matches more closely against the return type of String.length than does Integer, as returned by Function<String,Integer>. So the call
![]()
would compile, resolving to ![]() . For Comparator.comparing, the Java 8 designers wanted to avoid forcing the user to provide explicit lambda typing in this way, so they replaced the overloads that accepted ToIntFunction, ToLongFunction, and ToDoubleFunction with new methodscomparingInt, comparingLong, and comparingDouble. For other APIs, it may be possible to provide different overloads with functional interface parameters with different arities, or to provide other disambiguating parameters to the overload. If you are designing an API, your users will thank you for choosing one of these alternatives.
. For Comparator.comparing, the Java 8 designers wanted to avoid forcing the user to provide explicit lambda typing in this way, so they replaced the overloads that accepted ToIntFunction, ToLongFunction, and ToDoubleFunction with new methodscomparingInt, comparingLong, and comparingDouble. For other APIs, it may be possible to provide different overloads with functional interface parameters with different arities, or to provide other disambiguating parameters to the overload. If you are designing an API, your users will thank you for choosing one of these alternatives.
2.8.2 Overloading with Method References
Method and constructor references add another difficulty: if the method or constructor they refer to is generic or overloaded, they are called inexact, because their syntax allows no equivalent to explicit lambda typing, so you cannot specify the precise type at which you intend them to be used. Note that this is a relatively unusual situation: in practice, most methods are neither overloaded nor generic. As we see at the end of this section, difficulties with inexact method references can be avoided by using typed lambdas instead, and it can be argued that this should be your first, rather than your last, resort.
For an example of an inexact constructor reference, Exception::new could refer to either of the constructors for Exception, including these two:
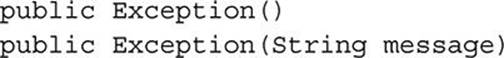
The first of these could match the function type of Supplier<Exception>, and the second could match the function type of Function<String,Exception>. So if we declare method overloads

then a call to
foo(Exception::new);
will fail to compile with the error message “reference to foo is ambiguous.” However, although we can’t make the constructor reference exact as we could by explicitly typing a lambda, there is a remedy: since foo is generic, we can specify which type instantiation we want for it by providing a type witness. This syntax requires the receiver to be stated explicitly:
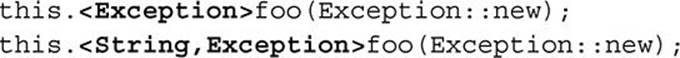
Of course, this will only work to distinguish generic methods with different numbers of type arguments. Suppose instead that we want to call one of two method overloads:

with a reference to String.valueOf, a static method with overloads that match both IntFunction<String> and DoubleFunction<String>. Here, only a cast can save the situation:

This problem only arises because String::valueOf is overloaded in such a way that its different function types match the possible types of the single parameter that distinguishes the different overloads of bar. Although this situation can occur in real life, it will probably not be common. If it does occur, remember that you can always use the lambda equivalent:

To summarize: if type inference or overload resolution fails, you need to supply more type information. Of the different ways of doing this, the least intrusive is to find an equivalent typed lambda or exact method reference. Failing that, supply a type witness. In terms of code style, casting is a last resort; avoid it if you can.
2.9 Conclusion
We’ve now seen all of the syntax changes needed to introduce lambdas; the other major change for Java 8, the introduction of default methods, supports API evolution by allowing interfaces to define behavior. Default methods will be covered in Chapter 7. Some of the details in this chapter may have seemed intricate, but overall, the ideas are quite simple, much simpler in fact than seemed achievable at many points in the long debate that led to their final form.
Language evolution is always hard because of the number of interactions that each new feature can have with existing ones; a case in point is the complexity, outlined in this chapter, that boxing/unboxing and untyped poly expressions have brought to method overload resolution. Another is the difficulty of writing lambdas that throw checked exceptions. Of the many trade-offs that had to be considered in the design and implementation of lambda syntax, the ones involving type inference will probably be most noticeable, in particular because it sometimes seems less powerful than you would expect. That is because the overriding motivation in designing the type inference rules was to make them simple and consistent—the same motivation that guided the entire language design.
____________
1One common question about lambdas concerns whether they are objects as traditionally defined in Java. This question has no simple answer, because although lambda expressions do currently evaluate to object references, they don’t behave like objects in all respects—see, for example, §2.2.1.
2The effect of this rule is to exclude from the scope of a lambda any declarations in its supertype (i.e., its functional interface). Interfaces can declare—besides abstract methods—static final fields, static nested classes, and default methods (see Chapter 7). None of these are in scope for an implementing lambda.
3Safer alternatives do exist, like AtomicInteger or LongAdder. But a still better alternative is to avoid shared variable mutation altogether whenever you can.
4Actually, target typing is not altogether new, but its greatly increased use in Java 8 for compiling lambda expressions is a major departure from traditional type checking of Java programs. Until now, the type of an expression has first been computed and then checked for compatibility with its context; if the context is a method call, an appropriate overload is chosen as the context. Untyped lambda expressions, by contrast, have no single type to be checked against the context, so in the case of a method call the overload must be chosen first, but still be compatible with the lambda. This challenge to the compiler is explored further in §§2.7 and 2.8.
5 This section is a simplified version of §15.27.3 of the Java 8 Edition of The Java Language Specification (http://docs.oracle.com/javase/specs/jls/se8/html/).
6 The use of “value-bearing” or “stream-bearing” to describe methods that return values or streams will soon become common enough to use without explanation; not quite yet, however.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.