Node.js in Action (2014)
Part 1. Node fundamentals
When learning a programming language or framework, you’ll often encounter new concepts that require you to think about things in a new way. Node is no exception, as it takes a new approach to a number of aspects of application development.
The first part of this book will outline exactly how Node is different from other platforms and will teach the basics of its use. You’ll learn what applications created in Node look like, how they’re organized, and how to deal with development challenges specific to Node. What you learn inpart 1 will give you the foundation needed to learn how to create web applications in Node, detailed in part 2, and how to create nonweb applications, discussed in part 3.
Chapter 1. Welcome to Node.js
This chapter covers
· What Node.js is
· JavaScript on the server
· The asynchronous and evented nature of Node
· Types of applications Node is designed for
· Sample Node programs
So what is Node.js? It’s likely you’ve heard the term. Maybe you already use Node. Maybe you’re curious about it. At this point in time, Node is very popular and young (it debuted in 2009). It’s the second-most-watched project on GitHub (https://github.com/joyent/node), it has quite a following in its Google group (http://groups.google.com/group/nodejs) and IRC channel (http://webchat.freenode.net/?channels=node.js), and it has more than 15,000 community modules published in NPM, the package manager (http://npmjs.org). All this to say, there’s considerable traction behind this platform.
Ryan Dahl on Node
You can watch the first presentation on Node by creator Ryan Dahl on the JSCONF Berlin 2009 website: http://jsconf.eu/2009/video_nodejs_by_ryan_dahl.html.
The official website (http://www.nodejs.org) defines Node as “a platform built on Chrome’s JavaScript runtime for easily building fast, scalable network applications. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices.”
In this chapter, we’ll look at these concepts:
· Why JavaScript matters for server-side development
· How the browser handles I/O using JavaScript
· How Node handles I/O on the server
· What’s meant by DIRTy applications, and why they’re a good fit for Node
· A sampling of a few basic Node programs
Let’s first turn our attention to JavaScript...
1.1. Built on JavaScript
For better or worse, JavaScript is the world’s most popular programming language.[1] If you’ve done any programming for the web, it’s unavoidable. JavaScript, because of the sheer reach of the web, has fulfilled the “write once, run anywhere” dream that Java had back in the 1990s.
1 See “JavaScript: Your New Overlord” on YouTube: www.youtube.com/watch?v=Trurfqh_6fQ.
Around the time of the Ajax revolution in 2005, JavaScript went from being a “toy” language to something people wrote real and significant programs with. Some of the notable firsts were Google Maps and Gmail, but today there are a host of web applications from Twitter to Facebook to GitHub.
Since the release of Google Chrome in late 2008, JavaScript performance has improved at an incredibly fast rate due to heavy competition between browser vendors (Mozilla, Microsoft, Apple, Opera, and Google). The performance of these modern JavaScript virtual machines is literally changing the types of applications you can build on the web.[2] A compelling, and frankly mind-blowing, example of this is jslinux,[3] a PC emulator running in JavaScript where you can load a Linux kernel, interact with the terminal session, and compile a C program, all in your browser.
2 See the “Chrome Experiments” page for some examples: www.chromeexperiments.com/.
3 Jslinux, a JavaScript PC emulator: http://bellard.org/jslinux/.
Node uses V8, the virtual machine that powers Google Chrome, for server-side programming. V8 gives Node a huge boost in performance because it cuts out the middleman, preferring straight compilation into native machine code over executing bytecode or using an interpreter. Because Node uses JavaScript on the server, there are also other benefits:
· Developers can write web applications in one language, which helps by reducing the context switch between client and server development, and allowing for code sharing between client and server, such as reusing the same code for form validation or game logic.
· JSON is a very popular data interchange format today and is native to JavaScript.
· JavaScript is the language used in various NoSQL databases (such as CouchDB and MongoDB), so interfacing with them is a natural fit (for example, MongoDB’s shell and query language is JavaScript; CouchDB’s map/reduce is JavaScript).
· JavaScript is a compilation target, and there are a number of languages that compile to it already.[4]
4 See the “List of languages that compile to JS”: https://github.com/jashkenas/coffee-script/wiki/List-of-languages-that-compile-to-JS.
· Node uses one virtual machine (V8) that keeps up with the ECMAScript standard.[5] In other words, you don’t have to wait for all the browsers to catch up to use new JavaScript language features in Node.
5 For more about the ECMAScript standard, see Wikipedia: http://en.wikipedia.org/wiki/ECMAScript.
Who knew JavaScript would end up being a compelling language for writing server-side applications? Yet, due to its sheer reach, performance, and other characteristics mentioned previously, Node has gained a lot of traction. JavaScript is only one piece of the puzzle though; the way Node uses JavaScript is even more compelling. To understand the Node environment, let’s dive into the JavaScript environment you’re most familiar with: the browser.
1.2. Asynchronous and evented: the browser
Node provides an event-driven and asynchronous platform for server-side JavaScript. It brings JavaScript to the server in much the same way a browser brings JavaScript to the client. It’s important to understand how the browser works in order to understand how Node works. Both are event-driven (they use an event loop) and non-blocking when handling I/O (they use asynchronous I/O). Let’s look an example to explain what that means.
Event Loops and Asynchronous I/O
For more about event loops and asynchronous I/O, see the relevant Wikipedia articles at http://en.wikipedia.org/wiki/Event_loop and http://en.wikipedia.org/wiki/Asynchronous_I/O.
Take this common snippet of jQuery performing an Ajax request using XMLHttp-Request (XHR):

This program performs an HTTP request for resource.json. When the response comes back, an anonymous function is called (the “callback” in this context) containing the argument data, which is the data received from that request.
Notice that the code was not written like this:
![]()
In this example, the assumption is that the response for resource.json would be stored in the data variable when it is ready and that the console.log function will not execute until then. The I/O operation (the Ajax request) would “block” script execution from continuing until ready. Because the browser is single-threaded, if this request took 400 ms to return, any other events happening on that page would wait until then before execution. You can imagine the poor user experience if an animation was paused or the user was trying to interact with the page somehow.
Thankfully, that’s not the case. When I/O happens in the browser, it happens outside of the event loop (outside the main script execution) and then an “event” is emitted when the I/O is finished,[6] which is handled by a function (often called the “callback”) as shown in figure 1.1.
6 Note that there are a few exceptions that “block” execution in the browser, and their use is typically discouraged: alert, prompt, confirm, and synchronous XHR.
Figure 1.1. An example of non-blocking I/O in the browser
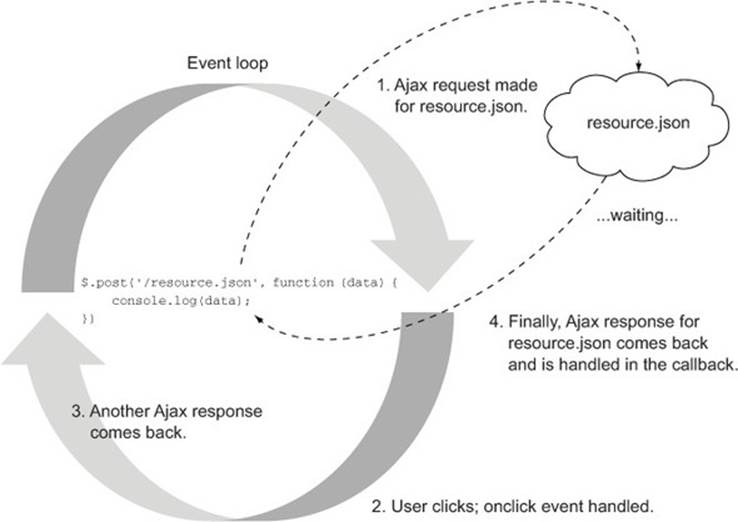
The I/O happens asynchronously and doesn’t “block” the script execution, allowing the event loop to respond to whatever other interactions or requests are being performed on the page. This enables the browser to be responsive to the client and to handle a lot of interactivity on the page.
Make a note of that, and let’s switch over to the server.
1.3. Asynchronous and evented: the server
For the most part, you’re likely to be familiar with a conventional I/O model for server-side programming, like the “blocking” jQuery example in section 1.2. Here’s an example of how it looks in PHP:
![]()
This code does some I/O, and the process is blocked from continuing until all the data has come back. For many applications this model is fine and is easy to follow. What may not be apparent is that the process has state, or memory, and is essentially doing nothing until the I/O is completed. That could take anywhere from 10 ms to minutes depending on the latency of the I/O operation. Latency can also result from unexpected causes:
· The disk is performing a maintenance operation, pausing reads/writes.
· A database query is slower because of increased load.
· Pulling a resource from sitexyz.com is sluggish today for some reason.
If a program blocks on I/O, what does the server do when there are more requests to handle? Typically you’d use a multithreaded approach in this context. A common implementation is to use one thread per connection and set up a thread pool for those connections. You can think of threads as computational workspaces in which the processor works on one task. In many cases, a thread is contained inside a process and maintains its own working memory. Each thread handles one or more server connections. Although this may sound like a natural way to delegate server labor—at least to developers who’ve been doing this a long time—managing threads within an application can be complex. Also, when a large number of threads is needed to handle many concurrent server connections, threading can tax operating system resources. Threads require CPU to perform context switches, as well as additional RAM.
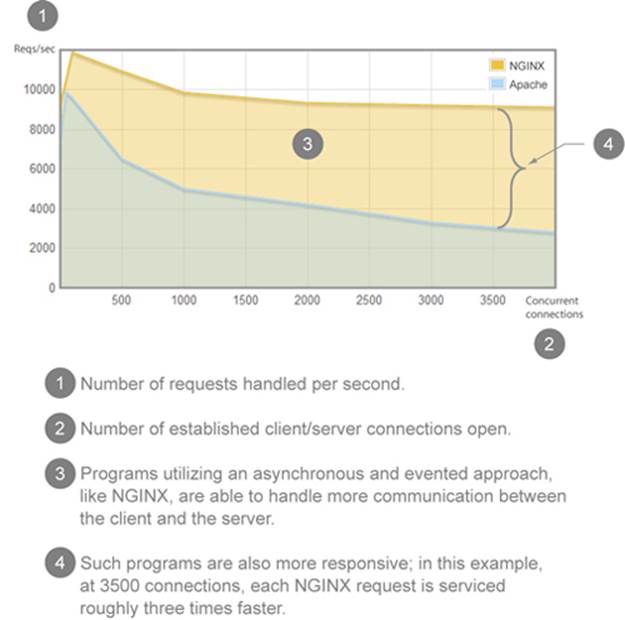
To illustrate this, let’s look at a benchmark (shown in figure 1.2, from http://mng.bz/eaZT) comparing NGINX and Apache. NGINX (http://nginx.com/), if you aren’t familiar with it, is an HTTP server like Apache, but instead of using the multithreaded approach with blocking I/O, it uses an event loop with asynchronous I/O (like the browser and Node). Because of these design choices, NGINX is often able to handle more requests and connected clients, making it a more responsive solution.[7]
7 If you’re interested in learning more about this problem, see “The C10K problem”: www.kegel.com/c10k.html.
Figure 1.2. WebFaction Apache/NGINX benchmark
In Node, I/O is almost always performed outside of the main event loop, allowing the server to stay efficient and responsive, like NGINX. This makes it much harder for a process to become I/O-bound because I/O latency isn’t going to crash your server or use the resources it would if you were blocking. It allows the server to be lightweight on what are typically the slowest operations a server performs.[8]
8 Node’s “About” page has more details about this: http://nodejs.org/about/.
This mix of event-driven and asynchronous models and the widely accessible JavaScript language helps open up an exciting world of data-intensive real-time applications.
1.4. DIRTy applications
There actually is an acronym for the types of applications Node is designed for: DIRT. It stands for data-intensive real-time applications. Because Node itself is very lightweight on I/O, it’s good at shuffling or proxying data from one pipe to another. It allows a server to hold a number of connections open while handling many requests and keeping a small memory footprint. It’s designed to be responsive, like the browser.
Real-time applications are a new use case of the web. Many web applications now provide information virtually instantly, implementing things like online whiteboard collaboration, real-time pinpointing of approaching public transit buses, and multiplayer games. Whether it’s existing applications being enhanced with real-time components or completely new types of applications, the web is moving toward more responsive and collaborative environments. These new types of web applications, however, call for a platform that can respond almost instantly to a large number of concurrent users. Node is good at this, and not just for web applications, but also for other I/O-heavy applications.
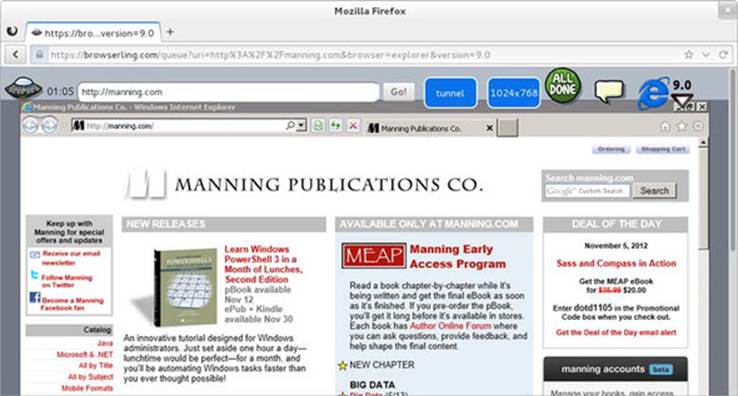
A good example of a DIRTy application written with Node is Browserling (browserling.com, shown in figure 1.3). The site allows in-browser use of other browsers. This is extremely useful to front-end web developers because it frees them from having to install numerous browsers and operating systems solely for testing. Browserling leverages a Node-driven project called StackVM, which manages virtual machines (VMs) created using the QEMU (Quick Emulator) emulator. QEMU emulates the CPU and peripherals needed to run the browser.
Figure 1.3. Browserling: interactive cross-browser testing using Node.js
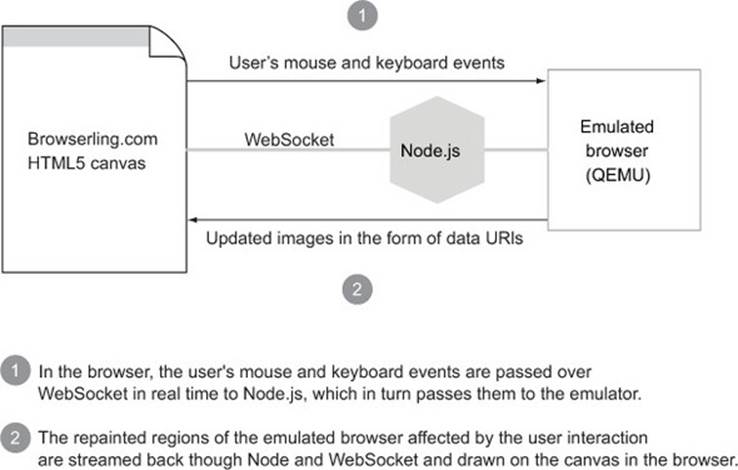
Browserling has VMs run test browsers and then relays the keyboard and mouse input data from the user’s browser to the emulated browser which, in turn, streams the repainted regions of the emulated browser and redraws them on the canvas of the user’s browser. This is illustrated in figure 1.4.
Figure 1.4. Browserling workflow
Browserling also provides a complementary project using Node called Testling (testling.com), which allows you to run a test suite against multiple browsers in parallel from the command line.
Browserling and Testling are good examples of DIRTy applications, and the infrastructure for building scalable network applications like them is at play when you sit down to write your first Node application. Let’s take a look at how Node’s API provides this tooling right out of the box.
1.5. DIRTy by default
Node was built from the ground up to have an event-driven and asynchronous model. JavaScript has never had standard I/O libraries, which are common to server-side languages. The “host” environment has always determined this for JavaScript. The most common host environment for JavaScript—the one most developers are used to—is the browser, which is event-driven and asynchronous.
Node tries to keep consistency between the browser and the server by reimplementing common host objects, such as these:
· Timer API (for example, setTimeout)
· Console API (for example, console.log)
Node also includes a core set of modules for many types of network and file I/O. These include modules for HTTP, TLS, HTTPS, filesystem (POSIX), Datagram (UDP), and NET (TCP). The core is intentionally small, low-level, and uncomplicated, including just the building blocks for I/O-based applications. Third-party modules build upon these blocks to offer greater abstractions for common problems.
Platform vs. framework
Node is a platform for JavaScript applications, and it’s not to be confused with a framework. It’s a common misconception to think of Node as Rails or Django for JavaScript, whereas it’s much lower level.
But if you’re interested in frameworks for web applications, we’ll talk about a popular one for Node called Express later on in this book.
After all this discussion, you’re probably wondering what Node code looks like. Let’s cover a few simple examples:
· A simple asynchronous example
· A Hello World web server
· An example of streams
Let’s look at a simple asynchronous application first.
1.5.1. Simple async example
In section 1.2, we looked at this Ajax example using jQuery:
$.post('/resource.json', function (data) {
console.log(data);
});
Let’s do something similar in Node, but instead we’ll use the filesystem (fs) module to load resource.json from disk. Notice how similar the program is to the previous jQuery example:
var fs = require('fs');
fs.readFile('./resource.json', function (er, data) {
console.log(data);
})
In this program, we read the resource.json file from disk. When all the data is read, an anonymous function is called (a.k.a. the “callback”) containing the arguments er, if any error occurred, and data, which is the file data.
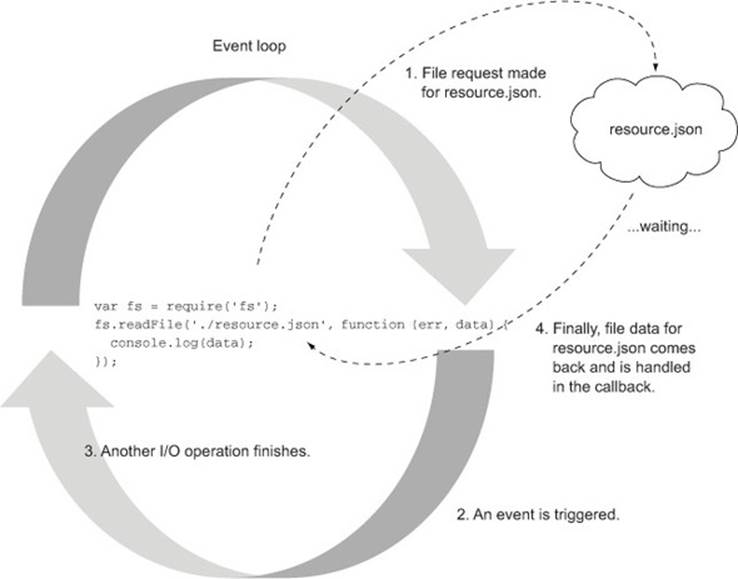
The process loops behind the scenes, able to handle any other operations that may come its way until the data is ready. All the evented and async benefits we talked about earlier are in play automatically. The difference here is that instead of making an Ajax request from the browser using jQuery, we’re accessing the filesystem in Node to grab resource.json. This latter action is illustrated in figure 1.5.
Figure 1.5. An example of non-blocking I/O in Node
1.5.2. Hello World HTTP server
A very common use case for Node is building servers. Node makes it very simple to create different types of servers. This can feel odd if you’re used to having a server host your application (such as a PHP application hosted on an Apache HTTP server). In Node, the server and the application are the same.
Here’s an example of an HTTP server that simply responds to any request with “Hello World”:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(3000);
console.log('Server running at http://localhost:3000/');
Whenever a request happens, the function (req, res) callback is fired and “Hello World” is written out as the response. This event model is akin to listening to an onclick event in the browser. A click could happen at any point, so you set up a function to perform some logic to handle that. Here, Node provides a function that responds whenever a request happens.
Here’s another way to write this same server to make the request event even more explicit:

1.5.3. Streaming data
Node is also huge on streams and streaming. You can think of streams as being like arrays, but instead of having data distributed over space, streams can be thought of as data distributed over time. By bringing data in chunk by chunk, the developer is given the ability to handle that data as it comes in instead of waiting for it all to arrive before acting. Here’s how you would stream resource.json:

A data event is fired whenever a new chunk of data is ready, and an end event is fired when all the chunks have been loaded. A chunk can vary in size, depending on the type of data. This low-level access to the read stream allows you to efficiently deal with data as it’s read instead of waiting for it all to buffer in memory.
Node also provides writable streams that you can write chunks of data to. One of those is the response (res) object when a request happens on an HTTP server.
Readable and writable streams can be connected to make pipes, much like you can do with the | (pipe) operator in shell scripting. This provides an efficient way to write out data as soon as it’s ready, without waiting for the complete resource to be read and then written out.
Let’s use our previous HTTP server to illustrate streaming an image to a client:

In this one-liner, the data is read in from the file (fs.createReadStream) and is sent out (.pipe) to the client (res) as it comes in. The event loop is able to handle other events while the data is being streamed.
Node provides this DIRTy-by-default approach across multiple platforms, including various UNIXes and Windows. The underlying asynchronous I/O library (libuv) was built specifically to provide a unified experience regardless of the parent operating system, which allows programs to be more easily ported across devices and to run on multiple devices if needed.
1.6. Summary
Like any technology, Node is not a silver bullet. It just helps you tackle certain problems and opens new possibilities. One of the interesting things about Node is that it brings people from all aspects of the system together. Many come to Node as JavaScript client-side programmers; others are server-side programmers; and others are systems-level programmers. Wherever you fit, we hope you have an understanding of where Node may fit in your stack.
To review, Node is
· Built on JavaScript
· Evented and asynchronous
· Designed for data-intensive real-time applications
In chapter 2, we’ll build a simple DIRTy web application so you can see how a Node application works.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.