Mastering JavaScript Promises (2015)
Chapter 2. The JavaScript Asynchronous Model
In this chapter, we will look at the model behind asynchronous programming, why it was needed, and how it is implemented in JavaScript.
We will also learn what a programming model is and its significance, starting from a simple programming model to a synchronous model to an asynchronous model. Since our prime focus is on JavaScript, which employs an asynchronous programming model, we will discuss it in more detail than the rest of the models.
Let's start with what models are and their significance.
Models are basically templates upon which the logics are designed and fabricated within a compiler/interpreter of a programming language so that software engineers can use these logics in writing their software logically. Every programming language we use is designed on a particular programming model. Since software engineers are asked to solve a particular problem or to automate any particular service, they adopt programming languages as per the need.
There is no set rule that assigns a particular language to create products. Engineers adopt any language based on the need.
Programming models
Ideally, we will focus on three major programming models, which are as follows:
· The first one is a single-threaded synchronous model
· The second one a is multithreaded model
· The third one is an asynchronous programming model
Since JavaScript employs an asynchronous model, we will discuss it in greater detail. However, let's start by explaining what these programming models are and how they facilitate their end users.
The single-threaded synchronous model
The single-threaded synchronous model is a simple programming model or single-threaded synchronous programming model, in which one task follows the other. If there is a queue of tasks, the first task is given first priority, and so on and so forth. It's the simplest way of getting things done, as shown in the following diagram:
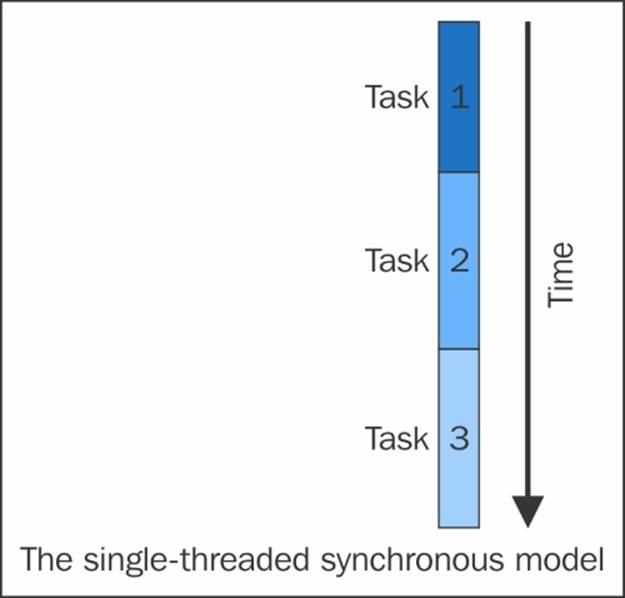
The single-threaded synchronous programming model is one of the best examples of a Queue data structure, which follows the First In First Out (FIFO) rule. This model assumes that if Task 2 is being executed at the moment, it must have been done after Task 1was finished without errors with all the output available as predicted or needed. This programming model is still supported for writing down simple programs for simple devices.
The multithreaded synchronous model
Unlike single-thread programming, in multi-thread programming, every task is performed in a separate thread, so multiple tasks need multiple threads. The threads are managed by the operating system, and may run concurrently on a system with multiple process or multiple cores.
It seems quite simple that multiple threads are managed by the OS or the program in which it's being executed; it's a complex and time-consuming task that requires multiple level of communications between the threads in order to conclude the task without any deadlock and errors, as can be seen from the following diagram:
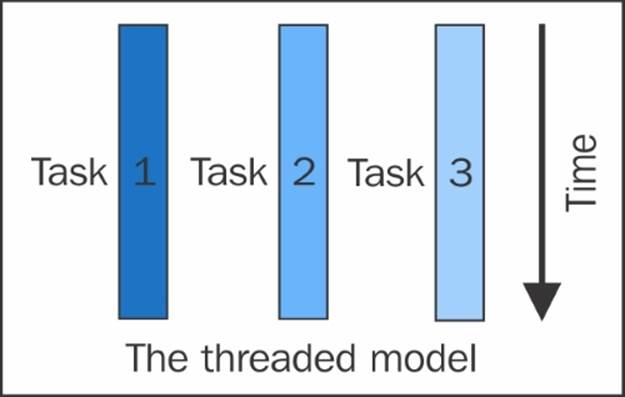
Some programs implement parallelism using multiple processes instead of multiple threads, although the programming details are different.
The asynchronous programming model
Within the asynchronous programming model, tasks are interleaved with one another in a single thread of control.
This single thread may have multiple embedded threads and each thread may contain several tasks linked up one after another. This model is simpler in comparison to the threaded case, as the programmers always know the priority of the task executing at a given slot of time in memory.
Consider a task in which an OS (or an application within OS) uses some sort of a scenario to decide how much time is to be allotted to a task, before giving the same chance to others. The behavior of the OS of taking control from one task and passing it on to another task is called preempting.
Note
The multithreaded sync model is also referred to as preemptive multitasking. When it's asynchronous, it's called cooperative multitasking.
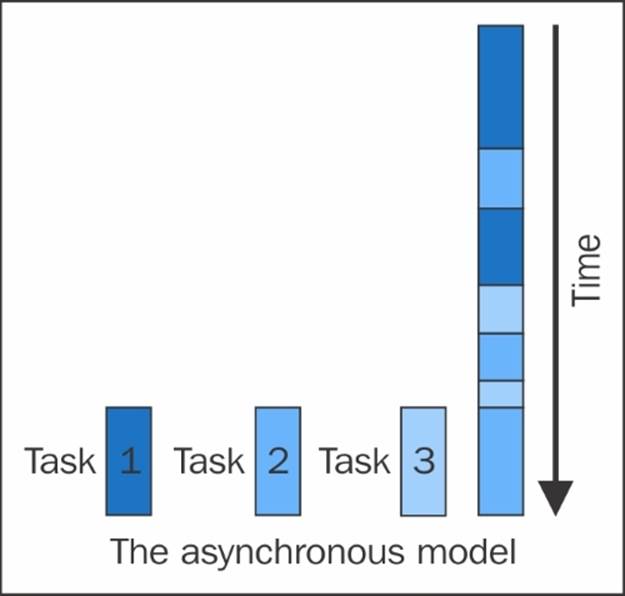
With threaded systems, the priority to suspend one thread and put another on the exaction is not in the programmer's hand; it's the base program that controls it. In general, it's controlled by the operating system itself, but this is not the case with an asynchronous system.
In asynchronous systems, the control of execution and suspension of a thread is in complete discretion of the programmer and the thread won't change its state until it's explicitly asked to do so.
Densities with an asynchronous programming model
With all these qualities of an asynchronous programming model, it has its densities to deal with.
Since the control of execution and priority assignment is in a programmer's hand, he/she will have to organize each task as a sequence of smaller steps that are executed immediately. If one task uses the output of the other, the dependent task must be engineered so that it can accept its input as a sequence of bits not together; this is how programmers fabricate their tasks on and set their priorities. The soul of an asynchronous system that can outperform synchronous systems almost dramatically is when the tasks are forced to wait or are blocked.
Why do we need to block the task?
A more common reason why a task is forcefully blocked is that it is waiting to perform an I/O or transfer data to and from an external device. A normal CPU can handle data transfer faster than any network link is capable of, which in result makes a synchronous program blocked that is spending so much time on I/O. Such programs are also referred as blocking programs for this reason.
The whole idea behind an asynchronous model is avoid wasting CPU time and avoid blocking bits. When an asynchronous program encounters a task that will normally get blocked in a synchronous program, it will instead execute some other tasks that can still make progress. Because of this, asynchronous programs are also called non-blocking program.
Since the asynchronous program spends less time waiting and roughly giving an equal amount of time to every task, it supersedes synchronous programs.
Compared to the synchronous model, the asynchronous model performs best in the following scenarios:
· There are a large number of tasks, so it's likely that there is always at least one task that can make progress
· The tasks perform lots of I/O, causing a synchronous program to waste lots of time blocking, when other tasks are running
· The tasks are largely independent from one another, so there is little need for intertask communication (and thus for one task to wait for another)
Keeping all the preceding points in mind, it will almost perfectly highlight a typical busy network, say a web server in a client-server environment, where each task represents a client requesting some information from the server. In such cases, an asynchronous model will not only increase the overall response time, but also add value to the performance by serving more clients (requests) at a time.
Why not use some more threads?
At this point, you may ask why not add another thread by not relying on a single thread. Well, the answer is quite simple. The more the threads, the more memory it will consume, which in turn will create low performance and a higher turnaround time. Using more threads doesn't only come with a cost of memory, but also with effects on performance. With each thread, a certain overhead is linked to maintain the state of that particular thread, but multiple threads will be used when there is an absolute need of them, not for each and every other thing.
Learning the JavaScript asynchronous model
Keeping this knowledge in mind, if we see what the JavaScript asynchronous model is, we can now clearly relate to an asynchronous model in JavaScript and understand how it's implemented.
In non-web languages, most of the code we write is synchronous, that is, blocking. JavaScript does its stuff in a different way.
JavaScript is a single-threaded language. We already know what single threaded actually means for the sake of simplicity—two bits of the same script cannot run at the same time. In browsers, JavaScript shares a thread with loads of other processes inline. These "inline processes" can be different from one browser to another, but typically, JavaScript (JS) is in the same queue as painting, updating styles, and handling user actions (an activity in one of these processes delays the others).
As in the image beneath, whenever the asynchronous (non-blocking) script executes in a browser, it goes from top to bottom in an execution pattern. Starting from the page load, the script goes to a document object where the JavaScript object is created. The script then goes into the parsing phase where all the nodes and HTML tags are added. After the completion of parsing, the whole script will be loaded in the memory as an asynchronous (non-blocking) script.
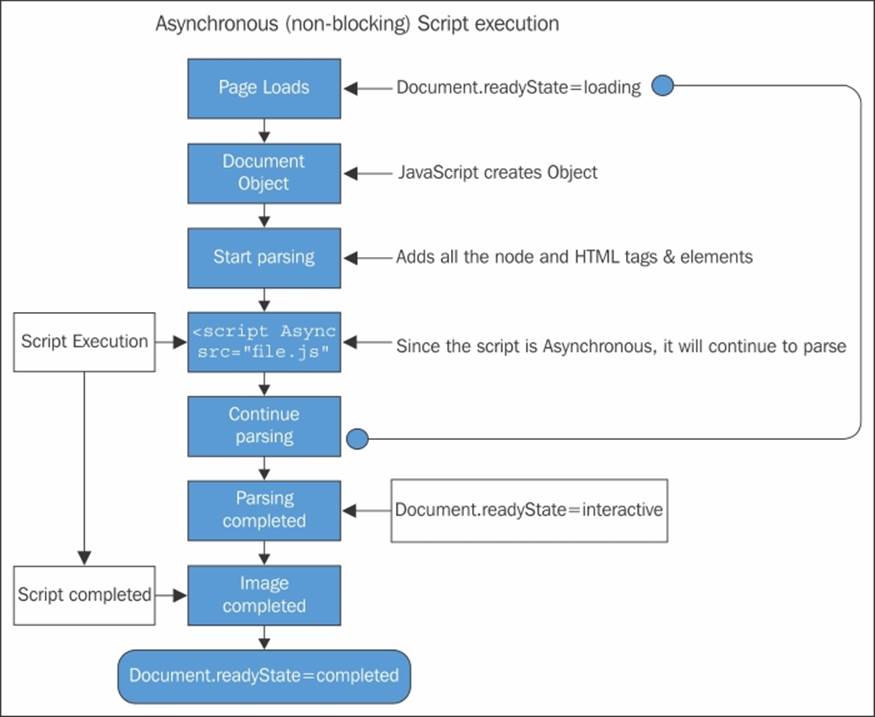
How JavaScript implements an asynchronous model
JavaScript uses an loop event and its cycle is called a "tick" (as in a clock), since it runs within the time slot bound by the CPU. An interpreter is responsible for checking whether every tick is an asynchronous callback to be executed. All other synchronous operations take place within the same tick. The time value passed is not guaranteed—there's no way of knowing how long it will take until the next tick, so we usually say the callbacks will run "as soon as possible"; although, some calls may even be dropped.
Within JavaScript, there are four core ways on how an asynchronous model is implemented in it. These four methods help not only for better performance of your program, but also in easier maintainability of code. These four methods are as follows:
· A callback function
· The event listener
· The publisher/subscriber
· The promises object
Callbacks in JavaScript
In JavaScript, functions are first class citizens, which means they can be treated as objects and because of the fact that they really are objects themselves. They can do what a regular object is capable of, such as these:
· Stored in variables
· Passed as augments to other functions
· Created within functions
· Returned from functions after a payload of some processed data mechanism
A callback function, also known as a higher-order function, is a function that is passed to another function (let's call this other function as otherFunction) as a parameter, and the callback function is called (executed) inside otherFunction.
A callback function is essentially a pattern (an established solution to a common problem), and therefore the use of a callback function is also known as a callback pattern. Because functions are first class objects, we can use callback functions in JavaScript.
Since functions are first class objects, we can use callback functions in JavaScript, but what are callback functions? The idea behind callback functions is derived from functional programming, which uses functions as arguments as implementing callback functions is as easy as passing regular variables as arguments to functions.
A common use of a callback function can be seen in the following lines of code:
$("#btn_1).click().click.function() {
alert ("Button one was clicked");
});
The code explains itself as follows:
· We pass a function as a parameter to the click function
· The click function will call (or execute) the callback function we passed to it
This is a typical use of callback functions in JavaScript, and indeed, it is widely used in jQuery. We will examine promise with respect to jQuery in more details in Chapter 8, Promises in jQuery.
Blocking functions
While we are discussing what a blocking function in JavaScript is and how one should implement it, many of us really don't clearly understand what we mean by a blocking function in JavaScript.
As humans, we have a mind that is designed in such a way that it can do many tasks at a time, such as while reading this book, you are aware of the surroundings around you, you can think and type simultaneously, and you can talk to someone while you are driving.
These examples are for multithreaded models, but is there any blocking function in our human body? The answer is yes. We have a blocking function because of which we all have other activities in our mind and within our body; it stops for a tiny pinch of a nanosecond. This blocking function is called sneezing. When any human sneezes, all the functions related to mind and body became blocked for a tiny fraction of nanosecond. This is rarely noticed by people. The same goes with the blocking function of JavaScript.
The mechanism of a callback function in JavaScript
The question here is, how on earth does a callback function work?
As we know that functions are like first class objects in JS, we can pass them around in a similar way to variables and return them as functions and use them in other functions.
When we pass a callback function as arguments to another function, we are only passing the function definition. We aren't executing functions in parameters. We are also not passing the function with the trailing pair of executing parenthesis (), as we would when we are executing a function.
Since the containing function has the callback function in its parameter as a function definition, it can execute the callback at any time.
It is important to note that the callback function is not executed immediately. It is "called back" and can still be accessed later via the arguments object by the containing function.
Basic rules to implement callbacks
There are some basic rules that you need to keep in mind while you are implementing the callbacks.
Callbacks are normally simple, but you should be familiar with the rule if you are crafting your own callback functions. Here are some key pointers that you must take into account while you are working on your callback functions:
· Use named or anonymous functions as callbacks
· Pass parameters to callback functions
· Make sure callback is a function before executing it
Handling callback hell
As JavaScript uses callback functions to handle asynchronous control flow, working with nesting of callbacks can become messy and most of the time, out of control.
One needs to be very careful while writing callbacks or using it from any other library.
Here is what happens if the callbacks are not handled properly:
func1(param, function (err, res)) {
func1(param, function (err, res)) {
func1(param, function (err, res)) {
func1(param, function (err, res)) {
func1(param, function (err, res)) {
func1(param, function (err, res)) {
//do something
});
});
});
});
});
});
The preceding situation is commonly referred to as callback hell. This is quite common in JavaScript, which makes the lives of engineers miserable. This also makes the code hard for other team members to understand and hard to maintain for further use. The most drastic of all is that it confuses an engineer, making it hard for him/her to remember where to pass on the control.
Here are the quick reminders for callback hell:
· Never let your function be unnamed. Give your function an understandable and meaningful name. The name must show it's a callback function that is performing certain operations instead of defining an anonymous function in the parameter of the main function.
· Make your code less scary to look at and easier to edit, refactor, and hack on later. Most of the engineers write code in a flow of thought with less focus on beautification of code, which makes it difficult to maintain the code later. Use online tools such ashttp://www.jspretty.com to add readability to your code.
· Separate your code into modules; don't write all your logic in a single module. Instead, write short meaningful modules so that you can export a section of code that does a particular job. You can then import that module into your larger application. This approach can also help you reuse the code in similar applications, thus making a whole library of your modules.
Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
The events
Events are signals that are generated when a specific action takes place. JavaScript is aware of such signals and responds accordingly.
Events are messages fired in a constant stream as the user works along. Events are normally based on user actions, and if programmed well, they act upon as directed. Any event is useless if it doesn't have a handler that works to handle events.
Since JavaScript provides a handsome control to programmers/engineers, it's their ability to handle events, monitor, and respond to them. The more capable you are at handling events, the more interactive your application will be.
The mechanism of event handling
There are two conventional ways to implement events in JavaScript. The first one is via HTML using attributes and second is via script.
To make your application respond to a user's action, you need to do the following:
1. Decide which event should be monitored.
2. Set up event handlers that trigger functions when an event occurs.
3. Write the functions that provide the appropriate responses to the events.
The event handler is always the name of the event perceived by on, for example, click event handled by a event handler, onClick(). This event handler causes a function to run, and the function provides the response to the event.
DOM – event capture and event bubbling
Document Object Model (DOM) makes it much easier to detect the events and assign related event handlers to react to them. This uses two concepts of event capture and event bubbling for this purpose. Let's take a look at how each can help in detecting and assigning the right handler for the right event.
Capturing an event is referred to as the process of an event as it commutes to its destination document. Also, it has the ability to capture or intercept this event.
This makes the whole round trip go incrementally downwards to its containing elements of the tree until it reaches to itself.
On the contrary, event bubbling is the inverse of event capture. With bubbling, the event is first captured and handled by the innermost element and then propagated to the outer elements.
A list of the most common events handlers
There is an entire array of event handlers to be put to use for different needs and situations, but let's add a few more common and regular events handlers.
Note
Please bear in mind that some event handlers may vary from one browser to another, and this specification becomes more limited when it comes to Microsoft's Internet Explorer or Mac's Safari.
The following list is quite handy and self-explanatory. To use this list more effectively, I recommend developers/engineers to make a handy note of it for reference.
|
Event category |
When will the event be triggered |
Event handler |
|
Browser events |
A page completes loading |
Onload |
|
The page is removed from the browser window |
Onunload |
|
|
JavaScript throws an error |
Onerror |
|
|
Mouse events |
The user clicks over an element |
onclick |
|
The user double-clicks over an element |
ondblclick |
|
|
The mouse button is pressed down over an element |
onmousedown |
|
|
The mouse button is released over an element |
onmouseup |
|
|
The mouse pointer moves onto an element |
onmouseover |
|
|
The mouse pointer leaves an element |
Onmouseout |
|
|
Keyboard events |
A key is pressed |
onkeydown |
|
A key is released |
onkeyup |
|
|
A key is pressed and released |
Onkeypress |
|
|
Form events |
The element receives focus from a pointer or by tabbing navigation |
onfocus |
|
The element loses focus |
onblur |
|
|
The user selects the type in text or text area field |
onselect |
|
|
The user submits a form |
onsubmit |
|
|
The user resets a form |
onreset |
|
|
The field loses focus and the content has changed since receiving focus |
onchange |
As mentioned earlier, these are the most common list of event handlers. There is a separate list of specifications for Microsoft's Internet explorer that can be found at http://msdn.microsoft.com/en-us/library/ie/ms533051(v=vs.85).aspx.
A complete list of the event's compatibility can be seen at:
http://www.quirksmode.org/dom/events/index.html
Triggering functions in response to events
JavaScript events need triggering in order to get a response. An event handler is responsible for responding to such events, but there are four commonly used ways to trigger events in a proper manner:
· The JavaScript pseudo protocol
· The inline event handler
· The handler as an object property
· Event listeners
Types of events in JavaScript
There are many different types of events in JavaScript, some listed as follows:
· Interface events
· Mouse events
· Form events
· W3C events
· Microsoft events
· Mozilla events
Interface events
The interface events occur due to the user's action. When the user clicks on any element, he/she always causes a click event. When clicking on the element has specific purpose, an additional interface event is caused.
Mouse events
When the user moves the mouse into the link area, the mouseover event fires. When he/she clicks on it, the click event fires.
Form events
Forms recognize submit and reset events, which predictably, fire when the user submits or resets a form. The submit event is the key of any form of a validation script.
W3C events
W3C events fire when the DOM structure of a document is changed. The most general one is the DOMSubtreeModified event that is fired when the DOM tree below the HTML element is triggered.
The DOM 2 event specification can be seen at http://www.w3.org/TR/2000/REC-DOM-Level-2-Events-20001113/events.html#Events-eventgroupings-mutationevents.
Microsoft events
Microsoft has created a number of its own event's handler specification, which (of course) can only run on its platform. This can be seen at http://msdn.microsoft.com/en-us/library/ie/ms533051(v=vs.85).aspx.
Mozilla events
Mozilla has its own specification, and it be seen at https://developer.mozilla.org/en/docs/Web/API/Event.
The publisher/subscriber
Events are yet another solution to communicate when asynchronous callbacks finish execution. An object can become emitter and publish events that other objects can listen to. This is one of the finest examples of the observer pattern.
The nature of this method is similar to "event listener", but much better than the latter because we can view the "message center" in order to find out how much signal is present and the number of subscribers for each signal, which runs the monitoring program.
A brief account of the observer pattern
The observer provides very loose coupling between objects. This provides the ability to broadcast changes to those who are listening to it. This broadcast may be for the single observer or a group of observers who are waiting to listen. The subject maintains a list of observers to whom it has to broadcast the updates. The subject also provides an interface for objects to register themselves. If they are not in the list, the subject doesn't care who or what is listening to it. This is the way how the subject is decoupled from the observers, allowing easy replacement of one observer for another observer or even one subject, as long as it maintains the same series of events.
A formal definition of observer
The following is the definition of observer:
|
Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically. |
||
|
--Gang of Four |
||
The source of this definition is page 20 of Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley Professional.
The push and pull model
When you create a subject/observer relationship, you would want to send information to the subject; sometimes, this information can be brief, or sometimes, it can be additional information. This can also happen that your observer sends a little chunk of information, and in return, your subject queries more information in response.
When you're sending a lot of information, it's referred to as the push model, and when the observers query for more information, it's referred to as the pull model.
|
The pull model emphasizes the subject's ignorance of its observers, whereas the push model assumes subjects know something about their observers' needs. The push model might make observers less reusable because Subject classes make assumptions about Observer classes that might not always be true. On the other hand, the pull model may be inefficient because Observer classes must ascertain what changed without help from the Subject. |
||
|
--Gang of Four |
||
The source of this definition is page 320, Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley Professional.
The advent of observer/push-pub
This observer/push-pub pattern provides a way of thinking on how to maintain relationship between different parts of an application. This also gives us an idea of what part of our application should be replaced with observers and subjects in order to achieve maximum performance and maintainability. Here are some points to bear in mind when using this pattern in JavaScript in particular, and for other languages in general:
· Using this pattern, it can break down an application into smaller, more loosely coupled blocks to improve code management and potential for reuse
· The observer pattern is best when there is a need to maintain consistency between related objects, without making classes tightly coupled
· Due to the dynamic relationship that exists between observers and subjects, it provides great flexibility, which may not be as easy to implement when disparate parts of our application are tightly coupled
The drawbacks of observer/push-pub
Since every pattern has its own price, it is the same with this pattern. The most common one is due to its loosely coupled nature, it's sometimes hard to maintain the states of objects and track the path of information flow, resulting in getting irrelevant information to subjects by those who have not subscribed for this information.
The more common drawbacks are as follows:
· By decoupling publishers from subscribers, it can sometimes become difficult to obtain guarantees that particular parts of our application are functioning as we may expect
· Another drawback of this pattern is that subscribers are unaware of the existence of each other and are blind to the cost of switching between publishers
· Due to the dynamic relationship between subscribers and publishers, the update dependency can be difficult to track
The promises object
The promises object is the last of the major concepts of asynchronous programming model implemented. We will be looking at promise as a design pattern.
Promise is a relatively new concept in JavaScript, but it's been around for a long time and has been implemented in other languages.
Promise is an abstraction that contains two main properties, which make them easier to work with:
· You can attach more than one callback with a single promise
· Values and states (errors) get passed along
· Due to these properties, a promise makes common asynchronous patterns using callback easy
A promise can be defined as:
A promise is an observable token given from one object to another. Promises wrap an operation and notify their observers when the operation either succeeds or fails.
The source of this definition is Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley Professional.
Since the scope of this book revolves around the promise and how it is implemented, we will discuss it in greater detail in Chapter 3, The Promise Paradigm.
Summing up – the asynchronous programing model
So far, we have seen how the asynchronous model is implemented in JavaScript. This is one core aspect of understanding that JavaScript has its own implementation for the asynchronous programming model, and it has employed much of the core concepts in the asynchronous programming model.
· The asynchronous mode is very important. In the browser, a very time-consuming operation should be performed asynchronously, avoiding the browser unresponsive time; the best example is the Ajax operations.
· On the server side, the asynchronous mode of execution since the environment is single threaded. So, if you allow synchronization to perform all http requests, server performance will decline sharply and will soon lose responsiveness.
· These are simple reasons why implementation on JavaScript is widely accepted in modern applications on all ends of needs. Databases such as MongoDB, Node.js as Server Side JavaScript, Angular.js, and Express.js as frontend, and logic building tools are examples of how heavily JavaScript is implemented throughout the industry. Their stack is commonly refer red to as the MEAN stack (MongoDB, Angular.js, Express.js, and Node.js)
Summary
In this chapter, we learned what a programming model is and how they are implemented in different languages, starting from a simple programming model to the synchronous model to the asynchronous model.
We also saw how tasks were organized in the memory and how they were served according to their turns and priorities, and how programming models decide what task is to be served.
We have also seen how the asynchronous programming model works in JavaScript, and why it's necessary to learn the dynamics of the asynchronous model to write better, maintainable, and robust code.
This chapter also explained how the major concepts of JavaScript are implemented and their roles from different angles in an application development.
We have also seen how callbacks, events, and observer were applied within JavaScript and how these core concepts are driving today's application development scenes.
In the next chapter, Chapter 3, The Promise Paradigm, we will learn a great deal about promise and how it's helping in making applications more robust and scalable.