A practical guide to Fedora and Red Hat Enterprise Linux, 7th Edition (2014)
Part VI: Appendixes
Appendix A Regular Expressions
Appendix B Help
Appendix C Security Including GPG
Appendix D Keeping the System Up-to-Date Using apt-get
Appendix E LPI and CompTIA Certification
A. Regular Expressions
In This Appendix
Characters
Delimiters
Simple Strings
Special Characters
Rules
Bracketing Expressions
The Replacement String
Extended Regular Expressions
A regular expression defines a set of one or more strings of characters. A simple string of characters is a regular expression that defines one string of characters: itself. A more complex regular expression uses letters, numbers, and special characters to define many different strings of characters. A regular expression is said to match any string it defines.
This appendix describes the regular expressions used by ed, vim, emacs, grep, mawk/gawk, sed, Perl, and many other utilities. The regular expressions used in shell ambiguous file references are different and are described in “Filename Generation/Pathname Expansion” on page 165.
Characters
As used in this appendix, a character is any character except a NEWLINE. Most characters represent themselves within a regular expression. A special character, also called a metacharacter, is one that does not represent itself. If you need to use a special character to represent itself, you must quote it as explained on page 1143.
Delimiters
A character called a delimiter usually marks the beginning and end of a regular expression. The delimiter is always a special character for the regular expression it delimits (that is, it does not represent itself but marks the beginning and end of the expression). Although vim permits the use of other characters as delimiters and grep does not use delimiters at all, the regular expressions in this appendix use a forward slash (/) as a delimiter. In some unambiguous cases, the second delimiter is not required. For example, you can sometimes omit the second delimiter when it would be followed immediately by RETURN.
Simple Strings
The most basic regular expression is a simple string that contains no special characters except the delimiters. A simple string matches only itself (Table A-1). In the examples in this appendix, the strings that are matched are underlined and look like this.

Table A-1 Simple strings
Special Characters
You can use special characters within a regular expression to cause the regular expression to match more than one string. A regular expression that includes a special character always matches the longest possible string, starting as far toward the beginning (left) of the line as possible.
Periods
A period (.) matches any character (Table A-2).

Table A-2 Periods
Brackets
Brackets ([]) define a character class1 that matches any single character within the brackets (Table A-3). If the first character following the left bracket is a caret (^), the brackets define a character class that matches any single character not within the brackets. You can use a hyphen to indicate a range of characters. Within a character-class definition, backslashes and asterisks (described in the following sections) lose their special meanings. A right bracket (appearing as a member of the character class) can appear only as the first character following the left bracket. A caret is special only if it is the first character following the left bracket. A dollar sign is special only if it is followed immediately by the right bracket.
1. GNU documentation and POSIX call these List Operators and define Character Class operators as expressions that match a predefined group of characters, such as all numbers (page 1242).
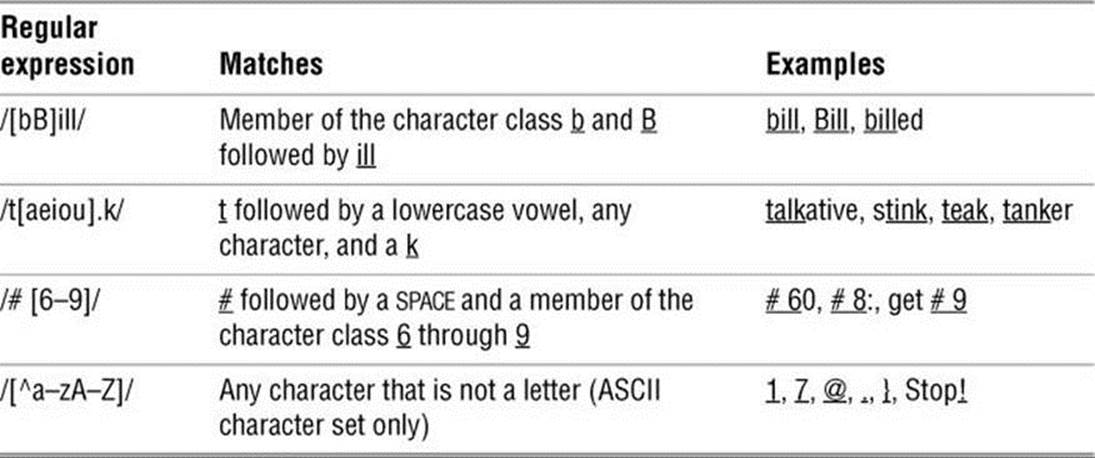
Table A-3 Brackets
Asterisks
An asterisk can follow a regular expression that represents a single character (Table A-4). The asterisk represents zero or more occurrences of a match of the regular expression. An asterisk following a period matches any string of characters. (A period matches any character, and an asterisk matches zero or more occurrences of the preceding regular expression.) A character-class definition followed by an asterisk matches any string of characters that are members of the character class.
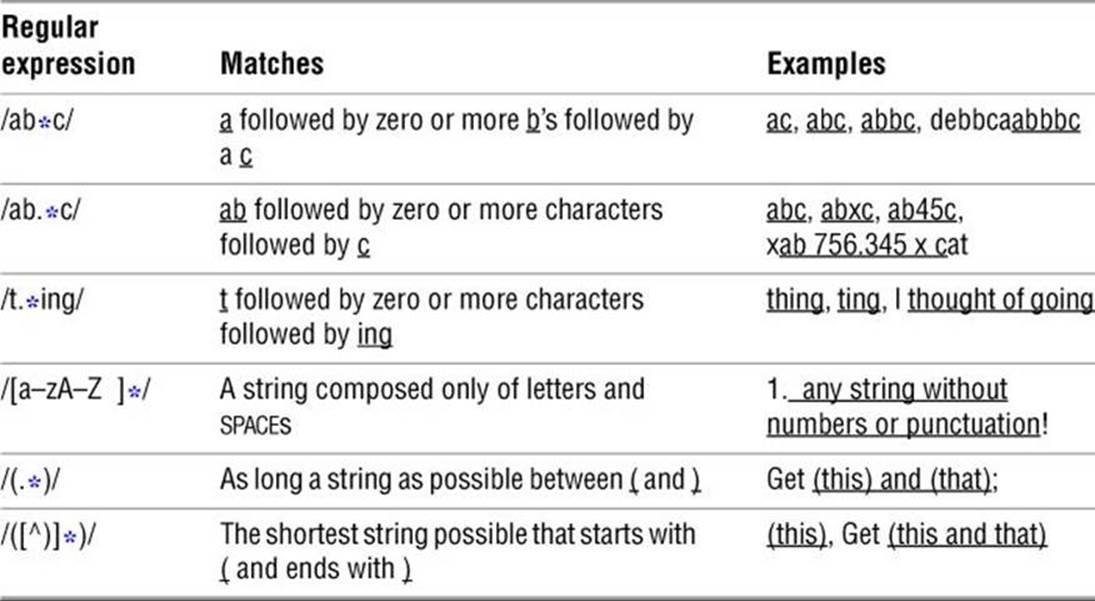
Table A-4 Asterisks
Carets and Dollar Signs
A regular expression that begins with a caret (^) can match a string only at the beginning of a line. In a similar manner, a dollar sign ($) at the end of a regular expression matches the end of a line. The caret and dollar sign are called anchors because they force (anchor) a match to the beginning or end of a line (Table A-5).

Table A-5 Carets and dollar signs
Quoting Special Characters
You can quote any special character (but not parentheses [except in Perl] or a digit) by preceding it with a backslash (Table A-6). Quoting a special character makes it represent itself.

Table A-6 Quoted special characters
Rules
The following rules govern the application of regular expressions.
Longest Match Possible
A regular expression always matches the longest possible string, starting as far toward the beginning (left end) of the line as possible. Perl calls this type of match a greedy match. For example, given the string
This (rug) is not what it once was (a long time ago), is it?
the expression /Th.*is/ matches
This (rug) is not what it once was (a long time ago), is
and /(.*)/ matches
(rug) is not what it once was (a long time ago)
However, /([^)]*)/ matches
(rug)
Given the string
singing songs, singing more and more
the expression /s.*ing/ matches
singing songs, singing
and /s.*ing song/ matches
singing song
Empty Regular Expressions
Within some utilities, such as vim and less (but not grep), an empty regular expression represents the last regular expression you used. For example, suppose you give vim the following Substitute command:
:s/mike/robert/
If you then want to make the same substitution again, you can use the following command:
:s//robert/
Alternatively, you can use the following commands to search for the string mike and then make the substitution
/mike/
:s//robert/
The empty regular expression (//) represents the last regular expression you used (/mike/).
Bracketing Expressions
You can use quoted parentheses, \( and \), to bracket a regular expression. (However, Perl uses unquoted parentheses to bracket regular expressions.) The string the bracketed regular expression matches can be recalled, as explained in “Quoted Digit” on the next page. A regular expression does not attempt to match quoted parentheses. Thus a regular expression enclosed within quoted parentheses matches what the same regular expression without the parentheses would match. The expression /\(rexp\)/ matches what /rexp/ would match; /a\(b*\)c/ matches what /ab*c/ would match.
You can nest quoted parentheses. The bracketed expressions are identified only by the opening \(, so no ambiguity arises in identifying them. The expression /\([a–z]\([A–Z]*\)x\)/ consists of two bracketed expressions, one nested within the other. In the string 3 t dMNORx7 l u, the preceding regular expression matches dMNORx, with the first bracketed expression matching dMNORx and the second matching MNOR.
The Replacement String
The vim and sed editors use regular expressions as search strings within Substitute commands. You can use the ampersand (&) and quoted digits (\n) special characters to represent the matched strings within the corresponding replacement string.
Ampersand
Within a replacement string, an ampersand (&) takes on the value of the string that the search string (regular expression) matched. For example, the following vim Substitute command surrounds a string of one or more digits with NN. The ampersand in the replacement string matches whatever string of digits the regular expression (search string) matched:
:s/[0-9][0-9]*/NN&NN/
Two character-class definitions are required because the regular expression [0–9]* matches zero or more occurrences of a digit, and any character string constitutes zero or more occurrences of a digit.
Quoted Digit
Within the search string, a bracketed regular expression, \(xxx\) [(xxx) in Perl], matches what the regular expression would have matched without the quoted parentheses, xxx. Within the replacement string, a quoted digit, \n, represents the string that the bracketed regular expression (portion of the search string) beginning with the nth \( matched. Perl accepts a quoted digit for this purpose, but the preferred style is to precede the digit with a dollar sign ($n). For example, you can take a list of people in the form
last-name, first-name initial
and put it in the form
first-name initial last-name
with the following vim command:
:1,$s/\([^,]*\), \(.*\)/\2 \1/
This command addresses all the lines in the file (1,$). The Substitute command (s) uses a search string and a replacement string delimited by forward slashes. The first bracketed regular expression within the search string, \([^,]*\), matches what the same unbracketed regular expression, [^,]*, would match: zero or more characters not containing a comma (the last-name). Following the first bracketed regular expression are a comma and a SPACE that match themselves. The second bracketed expression, \(.*\), matches any string of characters (the first-name and initial).
The replacement string consists of what the second bracketed regular expression matched (\2), followed by a SPACE and what the first bracketed regular expression matched (\1).
Extended Regular Expressions
This section covers patterns that use an extended set of special characters. These patterns are called full regular expressions or extended regular expressions. In addition to ordinary regular expressions, Perl and vim provide extended regular expressions. The three utilities egrep, grep when run with the –E option (similar to egrep), and mawk/gawk provide all the special characters included in ordinary regular expressions, except for \( and \), as well those included in extended regular expressions.
Two of the additional special characters are the plus sign (+) and the question mark (?). They are similar to *, which matches zero or more occurrences of the previous character. The plus sign matches one or more occurrences of the previous character, whereas the question mark matches zeroor one occurrence. You can use any one of the special characters *, +, and ? following parentheses, causing the special character to apply to the string surrounded by the parentheses. Unlike the parentheses in bracketed regular expressions, these parentheses are not quoted (Table A-7).

Table A-7 Extended regular expressions
In full regular expressions, the vertical bar (|) special character is a Boolean OR operator. Within vim, you must quote the vertical bar by preceding it with a backslash to make it special (\|). A vertical bar between two regular expressions causes a match with strings that match the first expression, the second expression, or both. You can use the vertical bar with parentheses to separate from the rest of the regular expression the two expressions that are being ORed (Table A-8).

Table A-8 Full regular expressions
Appendix Summary
A regular expression defines a set of one or more strings of characters. A regular expression is said to match any string it defines.
In a regular expression, a special character is one that does not represent itself. Table A-9 lists special characters.

Table A-9 Special characters
Table A-10 lists ways of representing character classes and bracketed regular expressions.

Table A-10 Character classes and bracketed regular expressions
In addition to the preceding special characters and strings (excluding quoted parentheses, except in vim), the characters in Table A-11 are special within full, or extended, regular expressions.

Table A-11 Extended regular expressions
Table A-12 lists characters that are special within a replacement string in sed and vim.

Table A-12 Replacement strings