Microsoft .NET Architecting Applications for the Enterprise, Second Edition (2014)
Part I: Foundation
Chapter 2. Designing for success
How does a project get to be a year late? One day at a time.
—Fred Brooks
We define a successful software project as a project that derives a working solution from well-understood business needs. We define successfully designed software as software that, in the context of a successful project, is designed reusing existing code and infrastructure (wherever possible) and refined in light of available technologies and known best practices.
The availability of successfully designed software today is critical for any type and any size of business, but even more critical for any business today is avoiding poor-quality software. Bad software can cause organizations to lose money in various ways—whether it is a slow-responding page that drives traffic away from your website, a cumbersome user interface that turns into a bottleneck and generates queues in the service you provide, or even an unhandled exception that triggers an uncontrolled chain reaction and produces really unpredictable effects.
Software projects rarely live up to expectations. We guess that everybody who happens to hold this book in their hands knows the truth of that statement quite well. So what can impede success in designing software? If we have to go to the very foundation of what makes software projects not fully meet expectations, we would track it back to something called the “Big Ball of Mud” (BBM).
The BBM is a nice euphemism for “a software disaster.”
In our definition, a software disaster is a system that grows badly and uncontrolled and, just because of that, is really hard to fix. Sometimes, poorly designed line-of-business systems get patched up enough to work and, in the end, become legacy code for others to deal with. In general, we think that teams should always aim at designing software for success even though the proverbial piece of tape can help make history. In fact, as reported by Space.com (at http://bit.ly/1fJW6my), cosmonaut Yuri Gagarin—the first man to enter space in 1961—was instructed to tear off a piece of tape and adjust some gear right before the launch.
 Note
Note
A great recent example of a BBM is probably healthcare.gov. It was built by a consortium of over 50 vendors under the theoretical control of the US federal government. In the end, and looking at it from the outside, it seems that none of the vendors building the various pieces were responsible and accountable for the overall quality. Integration tests were probably ignored for the most part, and no end-to-end scenarios—the body and soul of such a multivendor system—were tested in a timely manner. Finally, if concerns about the project were ever raised, they were blissfully ignored or withheld in the name of business or looming deadlines. But, in the end, by hook or by crook, the site works.
The “Big Ball of Mud”
The term Big Ball of Mud was created years ago to refer to a system that’s largely unstructured, padded with hidden dependencies between parts, has a lot of data and code duplication, and doesn’t clearly identify layers and concerns—namely, a spaghetti-code jungle. The term was coined by Brian Foote and Joseph Yoder, from the University of Illinois, and discussed in their paper, which is available at http://www.laputan.org/pub/foote/mud.pdf.
In this paper, the authors don’t condemn the BBM as the worst-ever practice; they just recommend that architects and developers be ready to face the BBM risk and learn how to keep it under control. Put another way, the BBM threat is a constant in nearly any software projects that grow beyond some critical mass. Learning how to recognize and handle a BBM is then the only way to avoid software disasters.
Causes of the “Big Ball of Mud”
There are a few basic facts about the BBM that can invade a software project. First and foremost, the BBM doesn’t get formed overnight and isn’t that big in the beginning. Second, no single developer can create the BBM from scratch. The BBM is always a product of teamwork.
In an effort to get at the root of things, we identified a few main causes that can lead—often in cooperation—to developing the BBM.
Failing to capture all the client asked for
Architects and developers build software, especially enterprise software, for a clear purpose. The purpose of the software is expressed through high-level statements declaring the objectives the customer intends to achieve and the problems to be solved. There’s a full branch of the software engineering science that deals with software requirements and classifies requirements in a variety of levels—business requirements, stakeholder requirements, functional requirements, testing requirements, and maybe more.
The point is how you go from a long list of roughly expressed requirements to concrete features to code in a programming language.
In Chapter 1, “Architects and architecture today,” we listed the acknowledgement of requirements among the primary responsibilities of an architect. Requirements often come from various sources and refer to different views of the same system. It is therefore not surprising that some requirements contradict one another or that the relevance of some requirements looks quite different when coming out of interviews with different stakeholders. Analyzing the requirements and deciding which ones really map directly to a feature is only the first phase of the architect’s job.
A second phase comes when the list of selected features is submitted for validation. The proposed list of features must address the entire list of requirements for all stakeholders. It is acceptable that some requirements for some stakeholders are just cut off.
Yes, it is acceptable as long as you’re able to explain and justify why those requirements have been dropped.
To design a system that solves a problem, you must fully understand the problem and its domain. This might not happen right away, and it might not happen smoothly from a plain reading of requirements. Sometimes you have to say “No.” More often, you have to ask why and then discuss the pros and cons of having a new feature to back a given set of requirements.
The lesson we all learned in years past is that a first run of code, which might be written according to a partial and incomplete understanding of needs, helps a lot more than spending days seeking the perfect solution up front. An Agile approach to development in this regard is based more on common sense than methodology.
Acknowledging requirements requires communication and communication skills. And sometimes communication just doesn’t work. Sometimes both parties believe the wrong thing, and both parties ultimately try to save their proverbial rear end. So developers find it easy to complain that they didn’t get enough details, and business people retort every point by saying that the details were there, written in the documents.
At the foundation of communication issues, there’s the fact that business and developers use different vocabularies and use and expect different levels of precision in the description. In addition, nearly everybody—except developers—tends to believe that programming is far easier than it actually is. Adding a new requirement is for business or sales people just as easy as adding a new line to the document. In reality, some adaptation to the system is necessary and comes at an extra cost.
Because software adaptation that results from new or changed requirements does have a cost—and nobody wants to pay for it—some feature adaptation is performed by removing other features, or more likely, by cutting down refactoring, testing, debugging, and documentation. When this scenario happens, which is too often, the Big Ball of Mud is served.
 Important
Important
In the previous chapter, we discussed how we usually deal with requirements. We want to briefly recall the points here. Essentially, we group raw requirements by categories and use International Organization for Standards/International Electrotechnical Commission (ISO/IEC) categories as a starting point. The actual process of grouping can be as simple as having a Microsoft Office Excel worksheet with one tab per category. We then go through the various tabs and add or remove requirements because it seems to make more sense. We also look carefully at the tabs that remained nearly empty and try to learn more about those aspects. In the end, the process makes us proactively seek more information and clearer information, generating it out of known data or getting it by asking for more details.
Sticking to RAD when the system grows
In the beginning, the project seems quite simple to arrange. The project—the customer says—is not supposed to grow and become a large and complex system. So you might opt for some forms of Rapid Application Development (RAD) and pay little attention to aspects of the design that could scale up well with the size of the application.
If it turns out that the system grows, the RAD approach shows its inherent limitations.
Although a RAD approach might be just right for small and simple data-centric applications (like CRUD applications), it turns out to be a dangerous approach for large applications containing a lot of ever-changing domain rules.
Imprecision of estimates
Business people always want to know exactly what they get before they commit and loosen the purse strings. Business people, however, reason in terms of high-level features and behavior. Once they have said they want the website available only to authenticated users, they believe they have said all there is to say on the topic. They don’t feel the need to specify that users should also be able to log in via a long list of social networks. And should this point be raised later, they would swear that it was there, written in the documents.
Developers, instead, want to know exactly what they are supposed to build in order to make reasonable estimates. At this level, developers think in terms of nitty-gritty details and break up business features into smaller pieces. The problem is that estimates can’t be precise until all requirements have been clearly defined and acknowledged. And an estimate is subject to change as requirements change.
Uncertainty reigns. Here’s a common scenario:
![]() The business and development teams reach an initial agreement on features and schedule, and everybody is happy. The development team is expected to provide a prototype as the first step.
The business and development teams reach an initial agreement on features and schedule, and everybody is happy. The development team is expected to provide a prototype as the first step.
![]() The development team delivers the prototype and sets up a demo session.
The development team delivers the prototype and sets up a demo session.
![]() The demo session gives some more concrete insight about the system being built. The business people somehow extend their vision of the system and ask for some changes.
The demo session gives some more concrete insight about the system being built. The business people somehow extend their vision of the system and ask for some changes.
![]() The development team is happy to add more project items but needs extra time. Subsequently, building the system becomes more expensive.
The development team is happy to add more project items but needs extra time. Subsequently, building the system becomes more expensive.
![]() For the business people, however, it’s always the same system, and there’s no reason why it shouldn’t cost the same. All they did was add a new level of precision!
For the business people, however, it’s always the same system, and there’s no reason why it shouldn’t cost the same. All they did was add a new level of precision!
When you make an estimate, it is extremely important to point out where the uncertainty lies.
Lack of timely testing
In a software project, testing happens at various levels:
![]() You have unit tests to determine whether individual components of the software meet functional requirements. Unit tests are also important to catch any regression in the functionality when code is refactored.
You have unit tests to determine whether individual components of the software meet functional requirements. Unit tests are also important to catch any regression in the functionality when code is refactored.
![]() You have integration tests to determine whether the software fits into the environment and infrastructure and whether two or more components work well together.
You have integration tests to determine whether the software fits into the environment and infrastructure and whether two or more components work well together.
![]() You have acceptance tests to determine whether the completed system, in all of its parts, meets all customer requirements.
You have acceptance tests to determine whether the completed system, in all of its parts, meets all customer requirements.
Unit tests and integration tests pertain to the development team and serve the purpose of making the team confident about the quality of the software. Test results tell the team if the team is doing well and is on the right track.
For both unit and integration tests, a critical aspect is when tests are written and performed.
As far as unit tests are concerned, there’s a large consensus on that you should write tests along with the code and have test runs integrated with the build process. Running unit tests, however, is generally faster than running integration tests. Integration tests also might take much longer to set up and likely need to be reset before each run.
In a project where you bring components together from individual developers or teams, chances are that components won’t fit together easily at first. For this reason, it is recommended that integration costs be diluted incrementally throughout the project so that issues show up as soon as possible. Pushing integration tests to the end is painfully risky because it cuts down the margin of time you have to fix things without introducing patches and hacks on top of other patches and hacks.
Unclear ownership of the project
As the healthcare.gov case proves, many vendors might be contracted to build the system and clear ownership of the project is a must.
The vendor or individual who owns the project is responsible for the overall quality and lists among her duties checking that every piece is of the best possible quality and fits with the rest of the system. This figure can easily push testing to be done in a timely manner so that integration issues are detected early. At the same time, this figure can mediate schedules and needs between the teams and stakeholders so that every vendor plays on the same team without damaging other players.
When project leadership is not clearly defined or, as in healthcare.gov, it is defined but not strictly exercised, taking the project home is left to the good will of individual vendors—except that each vendor has no reason to look beyond their contract. So especially under pressure, it is easy to focus on what just works regardless of the integration and design aspects.
When this happens, in only a few iterations, the spaghetti-code is ready to be served.
Ignoring a status of “crisis”
Technical difficulties are the norm rather than a novelty in a software project.
Whenever such difficulties arise, it makes no sense to stay vague and try to reassure the client. Hiding problems won’t gain you any additional rewards if you close the project successfully. If the project fails, however, having hidden problems will certainly cause you a lot of extra troubles.
As an architect, you should aim at being as open and transparent as open-sourced software.
If you recognize a sort of a crisis, let others know about it and tell them what you’re doing and plan to do. Providing a detailed calendar of fixes is the hardest part of the job. However, stakeholders just need to be informed about what’s going on and feel confident that the teams are moving in the right direction. Sometimes, a detailed calendar of updates and numbers about the work being done is more than enough to avoid pressure increasing on you beyond any bearable threshold.
How is recognizing a status of “crisis” related to the Big Ball of Mud and successful projects?
Again, it is a matter of common sense. Being open and transparent about difficulties sounds an alarm, and there’s a chance that bad things can be stopped earlier than when it’s too late.
Symptoms of the “Big Ball of Mud”
It should be clear that as an architect, project manager, or both you should maximize your efforts to avoid a BBM. But are there clear and unambiguous symptoms that indicate you’re on the trajectory of a rolling ball of mud?
Let’s identify a few general signs that make the alarm bells ring if the design is headed down the slippery slope.
Rigid, therefore fragile
Can you bend a piece of wood? And what would you risk if you insist on doing it?
A piece of wood is typically a stiff and rigid matter characterized by some resistance to deformation. When enough force is applied, the deformation becomes permanent and the wood breaks up.
What about rigid software?
Rigid software is characterized by some resistance to changes. Resistance is measured in terms of regression. You make a change in one class, but the effects of your change cascade down the list of dependent classes. As a result, it’s really hard to predict how long a change—any change, even the simplest—will actually take.
If you pummel a glass, or any other fragile material, you break it down into several pieces. Likewise, when you enter a change in software and break it in various places, that software is definitely fragile.
Like in real life, fragility and rigidity also go hand in hand in software. When a change in a software class breaks (many) other classes because of (hidden) dependencies, you have a clear symptom of a bad design that you need to remedy as soon as possible.
Easier to use than to reuse
Imagine you have a piece of software that works in one project and you would like to reuse it in another project. However, copying the class or linking the assembly in the new project just doesn’t work.
Why is that so?
When you move the same code to another project and it doesn’t work, it’s usually because of dependencies or because it was not designed for being shared. Of the two, dependencies are the biggest issue.
The real problem isn’t just dependencies, but the number and depth of dependencies. The risk is that to reuse a piece of functionality in another project, you have to import a much larger set of functions. At the end of the day, no reuse is ever attempted and code is rewritten from scratch.
This is not a good sign for your design, either. This negative aspect of a design is often referred to as immobility.
Easier to work around than to fix
When applying a change to a software class, you often figure out two or more ways to do it. Most of the time, one way of doing things is nifty, elegant, and coherent with the design, but terribly hard and laborious to implement. The other way, conversely, is much smoother and quicker to code, but it is a sort of a hack.
What should you do?
Actually, you can solve it both ways, depending on the given deadlines and your manager’s direction about it.
In general, a situation is less than ideal when a workaround seems much easier and faster to apply than the right solution. Sometimes, in fact, there’s more to it than plain extra labor. Sometimes, well, you’re just scared to opt for more than a basic workaround. Regression, that’s what really scares you. If you have good and abundant unit tests, at least you can be sure that regression, if any occurs, will be quickly caught. But then you start thinking that, well, unit tests don’t fix code and maybe the workaround is the fastest way to give it another go!
And a feature that’s easier to hack than a fix doesn’t sound like a great statement about your overall design either. It simply means that too many unneeded dependencies exist between classes and that your classes do not form a particularly cohesive mass of code. So this is enough to scare you away from applying the right solution, which is likely more obtrusive than a quick fix and requires a deeper level of refactoring.
This negative aspect of a design is often referred to as viscosity.
Using metrics to detect a BBM
In literature, another common name used to refer to building a software-intensive system on top of poor code is technical debt (TDBT).
Created by Ward Cunningham, the metaphor of debt is particularly appropriate because poor code, much like financial debt, can grow over time and accumulates interest to be paid back. In the long run, TDBT becomes a heavy weight to carry and affects, and sometimes prevents, further due actions. Paraphrasing a popular quote from Sir Winston Churchill, one could say, “TDBT, for a development team, is like a man standing in a bucket and trying to lift it up by the handle.”
TDBT is an abstract idea and claiming to have tools to measure or even remove it is like claiming you can do magic. However, metrics descend from careful observation of the facts and a bit of analysis. Results are not necessarily pure gold, but at a minimum they help increase awareness.
Let’s look into some metrics and tools to help you determine whether a BBM is trying to bite you.
Static code analysis
In general, people on a team know where most problems lie, but sometimes you need to provide evidence of code-related problems instead of just listing them orally. Static code-analysis tools scan and probe the code for you and produce a useful report to bring to the table for discussion.
Microsoft Visual Studio 2013 has its own static-code analyzer that can calculate things such as code coverage and cyclomatic complexity. Other similar frameworks are embedded in the CodeRush and ReSharper products (discussed later in the chapter), or they are available as separate products from the same vendors.
An interesting static-analysis tool is NDepend (http://ndepend.com), which also has the capability to create a dependency graph for you to visually spot and easily show the quantity and location of the most troublesome areas.
Important
In spite of possible appearances, static code-analysis tools will tell you neither what originated technical debt nor what is necessary to do in order to reduce it. They’re all about providing input for making a decision; they’re not about making the decision for you.
Knowledge silos
Another interesting set of manual metrics you can use to identify a flavor of TDBT is the number of bottlenecked skills you have on the team. If there’s only one member on the team who holds certain skills, or owns a given subsystem or module, that’s going to be a big pain if the individual leaves the company or suddenly becomes unavailable.
The term knowledge silo or information silo is commonly used to refer to a situation where ownership of the code is on an individual’s shoulders. It might not be a problem for the individual, but it’s definitely a problem for the team.
 Terminology
Terminology
We just used a couple of terms whose meaning can be different depending on the team. The terms are module and subsystem. In this context, we’re not giving these terms any special meaning other than being a way to refer to blocks of code. A subsystem generically refers to a subset of the entire system; a module is a part of the subsystem.
Mechanics of software projects
If you ask the question “What makes projects fail?”, probably the most common answer you receive will trace failures back to business-related issues such as missing requirements, inadequate project management, incorrect cost estimates, lack of communication, and even incompatibility between people on the various teams. You hardly see the perception that bad code might hurt.
Given all this, we think that an undetected BBM can seriously damage a software project, but an unfought BBM can really kill it.
In the end, it’s individuals, and the actual interaction between individuals, that really determines the success or failure of a software project. However, the structure of the organization and the overall culture within it also has an impact on the final result.
Organizational culture
Apple’s organization, at least during the Steve Jobs era, looked inspired by the one-man-show idea. One man pushes ideas and strategy, and all the teams work to support and implement the strategy. As long as the idea is a great one and the strategy is appropriate, success comes.
The Microsoft model that Steve Ballmer announced the company was revisiting in the summer of 2013 (which you can read a critical review of at http://www.mondaynote.com/2013/07/14/microsoft-reorg-the-missing-answer) is based on divisions that often compete with one another and hardly talk to each other.
You may remember what happened around 2008 when two groups within Microsoft produced two nearly equivalent frameworks—Linq-to-SQL and Entity Framework. To the outside world, it was hard to make sense which combination of events led to that situation.
Note
In the biography of Steve Jobs written by Walter Isaacson, you can read a very interesting opinion about companies organized in divisions. Steve Jobs shares his perspective of why Apple, and not say Sony, was actually successful with the iPod idea. To turn the idea into reality, Apple had to first build hardware and software and then negotiate rights on music. A company like Sony had at least the same experience as Apple with hardware and software and, additionally, already had in-house access to rights for music and movies. Why didn’t Sony build the iPod business then?
According to Jobs, it was the culture at Sony deriving from having divisions within the company that each had their own profit/loss account. Probably, the division making profits from the music rights saw the division making money from the MP3 players as a threat. The two divisions might have fought each other instead of working together for the success of the company. The book is Steve Jobs by Walter Isaacson (Simon & Schuster, 2011).
Teams and players
There’s an old joke about an Italian team and a German team participating in an eight-man rowing race. Composed of one leader and all rowers, the German team wins the race hands down. The Italian team investigates the reasons for the failure and finds out that the team was composed of all leaders and one young rower.
A team is all about having people with complementary skills making a coordinated effort.
Note
The joke about rowing teams then continues by discussing how the Italian team made plans for the return race, but that’s probably a bit beyond the scope here. Anyway, if you’re curious we’ll tell you that the Italian team fired the rower and managed to maintain four leaders, two supervisors of leaders, one commander-in-chief, and one new, older (because he was more experienced) rower.
In a software project, both managers and developers pursue their objectives. Managers tend to do that in a more aggressive way than most developers do. Developers report to managers, and this sometimes makes developers more inclined to just take on any tasks and deadlines. It should not be underestimated here that the nature of most developers is that of being a hero. Developers wish to be considered superheroes who come down to earth and save the world.
As an example, suppose a manager plans to show a potential customer a demo on Monday morning. He wants to make sure he has an impressive demo to show. So the manager approaches the development team and asks for the demo to be ready on Monday. That likely breaks the ongoing sprint or, in general, alters the scheduled activity. What’s the best way to handle such an inherent conflict of interest on a team or in a company? Here are a few possible scenarios:
![]() The development team can try to accommodate the new deadline so that the manager can pursue his own legitimate objectives.
The development team can try to accommodate the new deadline so that the manager can pursue his own legitimate objectives.
![]() The development team doesn’t accept the new deadline and holds on to the current schedule, thus making it problematic for the manager to keep the customer happy.
The development team doesn’t accept the new deadline and holds on to the current schedule, thus making it problematic for the manager to keep the customer happy.
![]() The development team and manager work together to find a reasonable goal that fits in both schedules and doesn’t prevent anyone from pursuing their respective objectives.
The development team and manager work together to find a reasonable goal that fits in both schedules and doesn’t prevent anyone from pursuing their respective objectives.
In our experience, the first scenario is the most common and the last one is the most desirable. With regard to developers trying to accommodate any modified schedule, we find particularly valuable again the opinion of Uncle Bob. By promising to try to accommodate the new deadline, the development team is making an implicit admission of having held back for a while. It’s like saying, “Yes, we could do more, but for some reason we haven’t been; now it’s about time we squeeze out every bit of energy.” But if the team has not been holding back on effort, trying to accommodate a tighter deadline will force members to work extra hours, sacrificing their own personal time. This is not fair to developers, who deserve their own life, and it is not fair to management, who just heard a lie.
How many times have we tried ourselves to accommodate tighter schedules? If we did it, we likely did it to avoid a potentially rude confrontation. The only good rule to be a great team player is being a great communicator who’s always honest and never lies.
The keyword here is negotiation, with the aim being to share a reasonable goal and find a reasonable compromise between respective needs and schedules. With reference to the previous example, a good compromise could be to fork out some work and create an ad hoc build that is padded with fake code and just works for a demo. This doesn’t remove much effort from the main branch, doesn’t introduce a significant delay in the ongoing sprint, and doesn’t require team members to work extra hours or cut features.
Scrum firefighters
Especially in an Agile environment, every unforeseen event is potentially a crisis and needs to be addressed properly and instantly.
In Scrum, a common way of doing that is giving one or more members of the team the title of firefighters.
The Scrum firefighter is responsible for doing any extra work that diverges from the iteration but is still necessary to preserve the efforts of the rest of the team. Just as it is OK for real-world firefighters to be idle sometimes, it is OK for the Scrum firefighters to be idle, or just minimally active on the project, during the iteration.
Because it could be highly annoying to be a Scrum firefighter, it should be a role that all members of the team rotate into and out of. In our experience, 20 percent of the development workforce should be the maximum you concede to firefighting. From this, you might think you’re facing a 20 percent cut in productivity; instead, you’re actually getting possibly higher throughput.
Leader vs. boss
We all know that costs are the sore point of software projects. Costs are a function of the hours required to code all the requested features, including testing, debugging, documentation, and a number of other side activities. The development team leader takes care of this, usually reporting to a project manager.
Sometimes there’s a mutual lack of trust between these two figures: the manager thinks the development team is holding back effort, and the development team thinks the manager just wants to produce more with less.
Needless to say, leadership is a critical skill.
It is not infrequent to see managers who halve the estimates and then complain that the project is late. And then they go to their bosses, blame the development team, and ask for more resources. In this way, they experience the effects of the Brooks’ law, which says that “Adding manpower to a late software project makes it later.”
There’s a profound difference between leaders and bosses.
First and foremost, the boss expects the team to serve them instead of serving the team. Bosses sit on top of the business hierarchy and command others to perform tasks that they are not willing to do or are unable to do. A leader, conversely, focuses on the business and leads development from the trenches. A good way to summarize the difference is by saying that a boss creates followers whereas a leader creates other leaders.
The difference between leaders and bosses is well summarized by a popular picture you might have seen a million times around your Facebook pages; you can find it at http://www.lolwall.co/lol/264722.
Helping the team write better code
We’ve found out that too many developers seem to have the perception that bad code, in the end, doesn’t hurt that much.
If you count the number of projects that reportedly failed because of code-related issues, well, we agree that the number is not going to be huge. However, you don’t have to create a true disaster to lose a lot of money on a software project.
As an architect, what can you do to help the team write better code?
Bad code is really more expensive than good code
We’re not sure about you, but we definitely think that writing bad code is really more expensive than writing good code. At least, we think it is more expensive in the context of a project with a significant lifespan and business impact.
As simple as it may sound, a project dies of bad code when the cost of working with that code—that is, creating, testing and maintaining it—exceeds the cost that the business model can bear. By the same token, no projects would fail for code-related issues if companies managed to keep the cost of code extremely low.
This is the sore point.
How would you define the items that contribute to the final bill for the code? Which actions comprise “writing the code”: coding, building, debugging? Should you consider testing as an extra, on-demand feature? What about documentation? And bug fixing?
Sometimes managers just short-circuit the problem and boil it down to cutting development costs by hiring cheap developers or deciding to cut off tests and documentation.
Unfortunately, these managers don’t realize they are only lowering the cost of producing code that possibly, but not necessarily, just works. Producing code that just works is only one aspect of the problem. In modern times, requirements change frequently, complexity grows and, worse yet, complexity is often fully understood only as you go. In this scenario, producing code is only one item in the total bill of costs. Code maintenance and evolution is the biggest item.
As the good architect knows very well, one can address code maintainability only through well-written code, a good understanding of software principles and language features, well-applied patterns and practices, and testability. This makes coding more expensive than producing code that just works, but it is far cheaper than maintaining and evolving code that just works.
Using tools to assist coding
We think that a successful project is based on two factors: management that knows about leadership, and development that knows about code quality.
As far as coding is concerned, there doesn’t have to be a time for developers to write just code and then a later time to fix it and clean it up. As every developer can swear to, this second pass never happens and even when it happens, it’ll never be as deep and profound as it should be.
A significant aid to writing better code the first time comes from code-assistant tools. Typically integrated into the IDE, these tools simplify common development tasks, making developers proceed faster and with a great chance to write much better code. At worst, code is written faster, possibly leaving some time for a second pass.
Services like auto-completion, tips on idiomatic design (that is, writing code in accordance with the language or framework-suggested idiom), code inspections, predefined snippets associated with keystrokes, and having predefined and customizable templates available are all practices that speed up development and ensure consistency and possibly better and cleaner code.
Code-assistant tools make development a sustainable effort and vastly improve the quality of the code you write with a couple of extra clicks. A code-assistant tool can catch duplicated and unused code, make refactoring a pleasant experience, simplify navigation and inspection, and force patterns.
For example, all developers agree in principle that a well-chosen naming convention is key to the readability and quality of code. (See Chapter 4, “Writing software of quality.”) However, when you realize that you should change a namespace or a method name, you have the problem of doing that at least throughout the entire codebase you own. It’s crazy work that code-assistant tools can conduct for you in a fraction of the time it would take for you to do it yourself.
ReSharper is the most popular code-assistant tool available. For more information, visit http://www.jetbrains.com/resharper. Other analogous tools are CodeRush from DevExpress (http://www.devexpress.com/Products/CodeRush), and JustCode from Telerik (http://www.telerik.com/products/justcode.aspx).
Be sure to keep in mind, however, that code-assistant tools are not magic and all they do is give you a chance to write better and cleaner code at a lower cost and with less effort. Beyond this point, everything else is still up to you. You guide tools in the refactoring process as well as during code editing.
How to tell people their code is bad
Suppose you noticed that some people on the team are writing bad code. How would you tell them about it?
There are psychological aspects involved here. You don’t want to be sharp, and you don’t want to hurt anybody; at the same time, you don’t like it that other people’s work can turn on you at some point. Communication is key, isn’t it? So you have to find the best way to tell people when their code is bad.
Overall, we believe that the best way to focus attention on some code is by subtly asking why it was written the way it is. You might find out more about the motivation, whether it was misinformation, a bad attitude, limited skills or perhaps constraints you just didn’t know about.
Be sure you never judge your coding alternative to be better without first having clear evidence. So you can simply look curious and interested about the real motivation for the offending code and express a willingness to know more because you would have coded it differently.
Make everyone a better developer
We like to summarize the golden rule of having teams write good code:
Address the code, not the coder. But try to improve the code through the coder.
You can have any piece of bad code fixed in some way. When this happens, however, you don’t want to blame the coder; you do want, instead, to help the coder to improve his way of doing things. If you’re able to do this, you get benefits in at least two areas. You get a better developer on the team, and you possibly have a happier and more motivated developer on the team. You made the developer feel as close to the hero status as possible because he now has the perception of having done his job in the best possible way.
To improve in some areas, everybody needs both training and practice. The most effective way to do this, though, is combining training and practice in an Agile manner. Too often, instead, we see companies that buy training packages, have them squeezed and delivered in a handful of days, and then expect people to be up and running the next Monday. It doesn’t work this way—not that effectively, at least.
Let’s revive an expression that was quite popular a few years ago: training on the job. It refers to doing some actual work while learning. It results from the collaboration of people on the same team with different skills.
Inspect before you check-in code
You can have the best coding standards ever in your company, but how do you enforce them? Trusting developers is nice, but verifying is probably more effective. Peer programming and regular design reviews are concrete ways to check the health of the codebase. In a typical design review, you can take some sample code and discuss it openly and collectively. The code can be a real snippet from the project—that some of the participants actually wrote—or, to avoid emotional involvement, it could even be an aptly written piece of code that illustrates the points you want to make.
To enforce coding standards, you can also consider applying check-in policies to your source control system, whether it is Microsoft Team Foundation Server (TFS), TeamCity, or other system. Can the process be automated in some way?
Today nearly any source-code management tool offers ways to exercise control over the files being checked in. For example, TFS has gated check-ins. A gated check-in is essentially a check-in subject to rules. Files, in other words, will be accepted into the system only if they comply with established rules. When you choose to create a gated check-in, TFS invites you to indicate an existing build script to use. Only if the build completes successfully will the files be checked in.
In TFS, a build is just an MSBuild script, and it can be customized with a variety of tasks. TFS comes with a number of predefined tasks that can be integrated. For example, you find code-analysis (formerly FxCop) tasks and a task for running selected test lists. Because an MSBuild task is nothing more than a registered component that implements a contracted interface, you can create new tasks yourself to add your own validation rules.
Note that JetBrains’ ReSharper—one of the aforementioned code-assistant tools—features a set of free command-line tools in its latest edition that can be used in a custom MSBuild task to detect duplicated code and apply typical inspections, including custom inspections against custom templates you might have defined. Interestingly, you don’t even need a ReSharper license to use the command-line tools. For more information on ReSharper command-line tools, have a look at http://www.jetbrains.com/resharper/features/command-line.html.
Happy is the project that doesn’t need heroes
Developers tend to have a super ego and, at least in their most secret dreams, wish they could work 80-plus hours a week to save the project, keep customers happy, and be true heroes in the eyes of management and fellow developers.
We like to paraphrase a popular quote from the poet and dramatist Berthold Brecht and say that we’d love to always be in a situation that doesn’t need heroism. The need for heroes and the subsequent high pressure comes mostly from inadequate deadlines.
Sometimes deadlines are unfair from the beginning of a project. In other cases, deadlines prove to be wrong along the way.
When this happens, it’s emotionally easier to just acquiesce, but being afraid to point out unfair deadlines brings about the need for heroes. Communicating and making troubles clear is a matter of transparency and also an effective way to regain a bit more of control and reduce pressure.
In software, we’d say you experience pressure because of looming deadlines or lack of skills. Both situations can be addressed properly if communicated in a timely way.
We don’t want heroes, and although we’ve been heroes ourselves quite a few times (as most of you, we guess, have been), we think we have learned that heroism is an exceptional situation. And in software, exceptions are mostly something to avoid.
Encourage practice
Why on earth do professional athletes in nearly any sport practice every day for hours? Is there really some analogy between developers and professional players? It depends.
One way to look at it is that developers practice every day at work and don’t compete with other developers. Based on this, one can conclude that there’s no analogy and, subsequently, no point in practicing.
Another way to look at it is that players exercise basic movements very frequently so that they can repeat them automatically. Going regularly back to the foundation of object-orientation, design patterns, coding strategies, and certain areas of the API helps to keep knowledge in the primary cache and more quickly accessible.
 Note
Note
After having written ASP.NET books for years and practiced with authentication and membership systems for as many years, Dino lately has felt like he’s in serious trouble when having to work on a role-based ASP.NET system. “Man,” he recently said to me, “when was the last time that I dealt with roles?” In the end, it took a lot more than expected to create a role-based UI infrastructure and related membership system.
Continuous change is part of the deal
Continuous change is an effective way to describe the dynamics of modern software projects. A software project begins by following an idea or a rather vague business idea. Architects and domain experts face the problem of nailing down some formal requirements to make the original idea or business needs a bit more tangible.
In our experience, most software projects are like moving targets and requirements are what move the target around. Every time a new requirement is added, the context changes and the dynamics of the system—designed and working well without that feature—changes as well. Requirements change because a better understanding of the problem domain is developed, because it is a fast-paced problem domain, or just because of timeline pressure.
Requirements churn is a common term to indicate the rate at which requirements—functional nonfunctional, or both—change in the context of a software project. A high requirements churn contributes to creating an ideal habitat for the BBM.
Reconsidering the entire system architecture whenever a new requirement is processed is the only way to be serious about preventing the BBM. Reconsidering the entire system architecture does require refactoring, and it does have a significant cost. The whole point here is finding ways to keep costs low. Refactoring is one of those things that is hardly perceived as bringing value to the project. It’s too bad that failing to refactor takes value away.
Note
Twitter went live in 2010 with a web front end full of client-side capabilities. A lot of functions were provided by generating HTML on the fly on top of dynamically downloaded JSON data. In 2012, Twitter refactored the entire system and chose server-side rendering. It was an architectural refactoring, and it was, of course, expensive. But they figured it was necessary, and they kept on serving a few hundred millions users, so right or wrong it just worked.
As an architect, both architectural and design refactoring are key tools. Architects have no control over history and the evolution of the business scenario and the real world. And architects are required to constantly adjust things and never rebuild. This is where refactoring fits in.
Getting out of the mess
Even with all the best intentions, and regardless of the team’s efforts, the design of a system at some point might head down the slippery slope. Forming the BBM is generally a slow process that deteriorates the design over a relatively long period. It works by studding your classes with hacks and workarounds up until a large share of the code gets hard to maintain and evolve.
At this point, you’re in serious trouble.
Managers face the choice of making a bargain with the devil and calling for more hacks and workarounds or a performing a deep redesign based on reviewed requirements and new architectural choices.
What’s the difference between doing a complete system redesign and starting development entirely from scratch? In terms of a call to action, the difference is minimal, if any. The psychological side of the choice, though, is different. By calling for a redesign, management pushes the message that the team is catching up and fixing things quickly. By calling for a rewrite, management admits failure. And very rarely in software projects is failure is an option.
The moment at which management calls for a significant restructuring of the existing codebase certifies that the team completed a software disaster. The existing codebase then becomes a nasty form of legacy code.
That odd thing called “legacy code”
In software, you often inherit existing code that you must maintain, support, or just keep as is and integrate with the new stuff. This code, too, is commonly referred to as legacy code. However, the main challenge for architects and developers is not surviving existing legacy code, but not creating any more.
Legacy code is just what the name literally says it is. It is code; and it is legacy. According to the Oxford Dictionary, the word legacy means something left or handed down by a predecessor. Furthermore, the dictionary adds a software-specific definition for the word that goes along the lines of something superseded but difficult to replace because of its wide use.
Our general definition of legacy code is any code you have around but don’t want to have around. Legacy code is inherited because it works. There’s no difference at all between well-designed and well-written code that works and poorly designed and poorly written code that works. The troubles begin when you have to put your hands on legacy code to maintain and evolve it in some way.
The idea of legacy code is somehow related to the idea of software disasters. However, having legacy code on a project is not a disaster per se. It just starts turning bad when the legacy code you have on the project is yours. How do you turn legacy code—whether it is yours or inherited—into more manageable code that doesn’t prevent the project as a whole from evolving and expanding as expected?
Note
Michael Feathers wrote a paper a decade ago that neatly wraps up the point of legacy code and strategies around it. The paper is available at http://www.objectmentor.com/resources/articles/WorkingEffectivelyWithLegacyCode.pdf. What makes this paper particularly interesting is the relationship the author identifies between legacy code and tests. Legacy code, in other words, is just code without tests.
Note
Too many developers have to work with legacy codebases where fundamental principles of software design and testing practices are just nonexistent, turning the code into a software disaster. As we move ahead and outline a general strategy to deal with bad code, we also want to point you in advance to a resource that illustrates how to improve the code through a combination of well-known refactoring techniques and code-analysis tools: http://blog.jetbrains.com/blog/2013/05/14/recording-refactoring-legacy-code-bases-with-resharper.
Checkmate in three moves
All in all, recovering from a software disaster is analogous to recovering from an injury. Imagine for a moment that while on vacation you decided to go out running for quite a long time and received some physical damage, such as a strong Achilles strain.
For a very active person, well, that’s just a disaster.
You see a doctor and the doctor goes through the steps of a simple but effective procedure. First, the doctor orders you to stop any physical activity, including in some cases walking. Second, the doctor applies some rigid bandage around the injured ankle and maybe around the whole leg. Third, the doctor suggests you try walking again as you feel better and stop again if you don’t feel comfortable doing that. That’s the way it works, and a lot of people go through that process successfully.
The same procedure can be applied to software injuries, and it mostly works. More precisely, the strategy is reasonably effective but the actual effects depend on the seriousness of the injury.
Stop new development
A strict prerequisite of any strategy aimed at turning badly written code into something much more manageable is stop development on the system. In fact, adding new code can only make a poorly designed system even worse. Stopping development, however, doesn’t mean that you stop working on the system. It simply means don’t add any new feature until you have restructured the current system to a more maintainable codebase that can receive new features without compromising the existing features.
The redesign of an evolving system is like catching a runaway chicken. You need to be in a very good shape to make it. But is the team who failed on it once really in shape at that point?
Isolate sore blocks
Just as the doctor applies a rigid bandage around sore ankles, the architect should apply layers around badly written blocks of code. However, what does block of code mean here specifically? It is probably easier to state what a “block of code” is not.
A block of code is not a class, but it is something that likely spans multiple classes, if not multiple modules. A block of code actually identifies a behavior of the system—a function being performed—and includes all the software components involved in that. It is key to identify macro functions and define an invariant interface for each of them. You define a layer that implements the interface and becomes a façade for the behavior. Finally, you modify the code so that each and every path that leads to triggering that behavior passes through the façade.
As an example, have a look at Figure 2-1. The figure represents a small section of a messy codebase where two critical components, C1 and C2, have too many dependencies on other components.
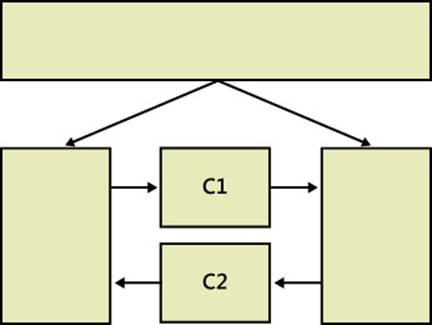
FIGURE 2-1 Representing a section of a messy codebase.
The purpose is turning the layout of Figure 2-1 into something with more separated blocks. You need to understand that you can’t claim you’ll get the right design the first time. Isolating sore points is just the first step, and you should not be too concerned about the size of the layers you introduce. Turning back to the doctor’s analogy, sometimes the doctor applies a bandage to the entire leg even though the problem is mostly around the ankle. After a few days of rest, though, the doctor may decide to reduce the bandage to just the area around the ankle.
Likewise, isolating sore software blocks is an iterative work. Figure 2-2 shows a possible way to isolate the sore blocks of Figure 2-1.
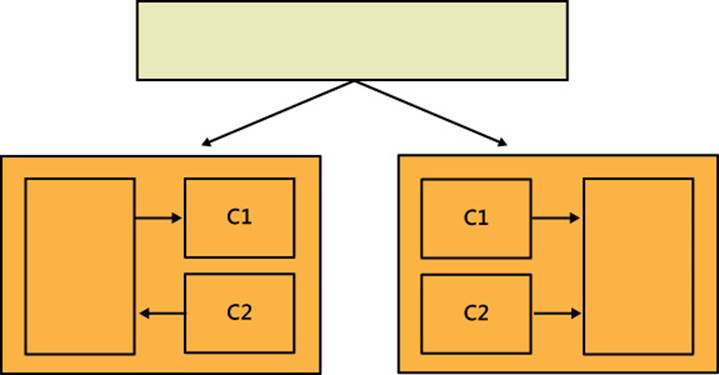
FIGURE 2-2 An intermediate step in the design where the client calls into isolated blocks through a new contracted interface.
Looking at Figure 2-2 you might guess that C1 and C2 have been duplicated; however, this is just an intermediate step, but it is necessary in order to obtain two neatly separated subsystems invoked by a given caller. Separated subsystems should be like black boxes now.
Note also that block of code might even span layers and sometimes tiers. Like the doctor’s bandage, reducing the area covered by isolated blocks is the ultimate purpose of the effort.
 Terminology
Terminology
We’re going to cover Domain-Driven Design (DDD) extensively in this book; in particular, starting with Chapter 5, “Discovering the domain architecture.” So we rate as highly important relating the concept of isolated blocks as described here with the concept of a DDD bounded context. In a DDD project, a bounded context can also be a black box of legacy code. In DDD, a bounded context has a unique related model and can be composed of several modules. Subsequently, several modules can share the same model.
Test coverings
Once you refactor the system into a bunch of neatly separated blocks, you should still have a system that works—only it is a little bit better in terms of design. You don’t want to stop here, however. So it is highly recommended that at this point you introduce tests that can tell you whether after further refactoring the system still works.
In this context, tests are mostly integration tests—namely, tests that possibly span multiple modules, layers, and tiers. They are tests that can be hard to set up—for example, databases to fill with ad hoc data for simulation, services to connect—and long to run. Yet, they are absolutely necessary to have and run. In his aforementioned paper, Feathers uses the term test covering to indicate tests aimed at defining behavior invariants to make further changes against.
Note
Tests play a key role in any refactoring experience. You surely need to end the process with tests that can measure any regression after any future refactoring. However, in some situations you might find it helpful to have tests ready before you even start isolating sore blocks.
Terminology
The term layer usually refers to a logical boundary. Conversely, a tier is a physical boundary. More concretely, when we talk about layers, we refer to blocks of code (that is, classes or even assemblies) that live in the same process space but are logically separated. A tier implies a physical distance and different processing spaces. A tier is usually also a deployment target. Whether some code goes to a layer or tier is a matter of choice and design. Boundaries are what really matters. Once you have clear boundaries, you can choose which is a layer and which one goes to a tier. For example, in an ASP.NET project, you can have some application logic deployed in-process within the same application pool as the core ASP.NET and pages or deployed to a distinct tier hosted, say, on another Internet Information Services (IIS) machine.
Continuous refactoring
After the first iteration of test coverings, you should have stabilized the system and gained some degree of control over its behavior. You might even be able to apply some input values to tests and check the behavior. Next, you enter in a refactoring loop where you try to simplify the structure of the black boxes you created. In doing so, you might be able to take some code out of black boxes and reuse it through new interfaces. Have a look at Figure 2-3.
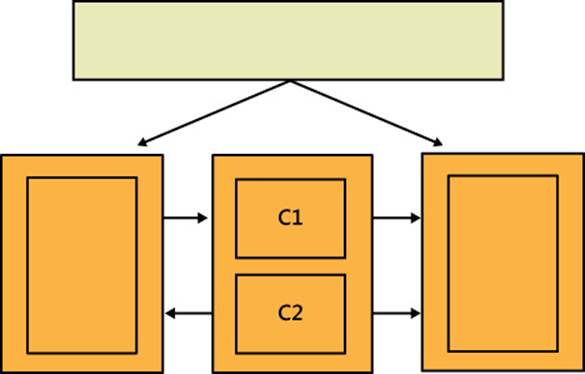
FIGURE 2-3 Another black box added to break the system down into more manageable pieces.
As you can see, now C1 and C2 have been moved out of subsystems and encapsulated in a new black box that is testable itself. By repeating this procedure, you might be able to progressively reduce the size of black boxes. A nice effect is that now existing integration tests may be rewritten to be a lot closer to unit tests.
Deciding whether or not to add manpower
A popular quote from Frederick P. Brooks and his popular book The Mythical Man Month (Addison-Wesley, 1995) says that adding manpower to a late project just makes it later. And for sure—this is our addition—doing so has no chance to significantly affect the schedule. Yet, when a project is late, the first thing that springs to mind is just adding to the workforce. However, in the presence of sequential constraints on project activities (for example, debugging taking place after development), adding to the workforce doesn’t bring any benefit. According to Brooks, the bearing of a child takes nine months, and nine women will never deliver a baby in one month.
So the question is: what should you do when a project is late? Should you never consider adding manpower? It depends on the results of an honest analysis of the reasons why the project is late.
Need for more time
A project might be late just for the obvious reason that each feature needs more time than estimated in order to be completed. If tasks are sequential in nature, more people on the team is just more management work and probably a less-than-optimal use of the assigned resources.
This reality moves the focus to estimates. Software people are not known to be able to estimate effort carefully. Software people live with the underlying certainty that all will go well in the end and that everything can be fixed by simply working longer hours. This attitude also makes monitoring progress hard. The quote at the top of the chapter says it all—a project gets late one day at a time. If progress is tracked in a timely way, falling behind schedule can be fixed without long hours or with a limited extra time. At worst, the extra time can be diluted over a much longer period of time.
But even when estimates of the technical effort are correct, another aspect is often neglected. Any project has both direct and indirect costs. Direct costs comprise things like salaries and travel expenses. Indirect costs include, for example, equipment and administrative tasks. In addition, there are the costs of the unknown: meetings, revisions, and all those little tasks that haven’t been communicated to everyone or fully understood. Estimate omissions are common, and omissions are addressed only by experience—your direct experience or that of subject experts. Obviously, you should always do your best to clearly write out every little task that makes work complete, and count it at least in the time column.
A pragmatic approach is always comparing actual costs to estimates when a project is done. If you determine the delta and turn it into a percentage, under or over, you can use this factor to multiply estimates next time.
In general, there are two main dynamics in software projects depending on the working model: fixed price or time/materials. In the former case, if you realize you need more time, as a project manager you try to find a way to resync with the schedule. You try to lower the quality-cutting development time and testing, limiting documentation and any activity that is not strictly necessary to passing final tests for the iteration. You also try to renegotiate and read carefully back the requirements to see if anything agreed on can be reformulated as a change request. If you are in time/materials mode, you can manage to calculate the delta between estimates and actual time in the past iterations and use that to correct estimates for each new iteration.
Need for more expertise
Another reason why a project might be late is that the implementation of certain features takes longer because some people are not up to the task. If you need more expertise, don’t be afraid to bring in the best talent you can find. When you approach talented people, however, it should be clear why you intend to bring them in. You can have experts to train your people or to solve the issue. Neither option is clearly preferable over the other.
Training delivers more added value because the results of training remain within the company and increase assets. At the same time, training—even when tailor-made courseware is delivered—typically addresses topics at a rather general level and might take extra time to be adapted to the ongoing project. On the other hand, calling for consulting is theoretically more effective but requires that you give experts full access to the code, people, and documentation. The more intricate the codebase is, the longer it might take and the less reliable results might be.
Experts don’t do magic; magic doesn’t exist in software. If an expert does magic, it may be a trick. And so it is in life.
Summary
In spite of the name, software engineering is not about engineering; or at least it is not about engineering in the common sense of the word engineering. Software is a too dynamic and evolving a matter to be boxed in a set of fixed rules.
The major enemy of software projects is the BBM, and the BBM is strictly related to piecemeal growth and the project lifespan. The piecemeal growth of projects is a matter of fact; having an effective strategy to cope with that is essential. This might require the ability and personality to negotiate with project managers, customers, and stakeholders. Domain experience leads you to sensible judgment about features that most likely will be requested and allows you to better guide the customer to discover what they need.
Not all projects are created equal, and understanding the lifespan of the project is another critical factor. You don’t want to put the same effort and care into the design of a short-lived project and a mission-critical system or a line-of-business application. Complexity must be controlled where it really exists, not created where it doesn’t exist and isn’t supposed to be.
The mechanics of software projects is sometimes perverse, but successful projects are possible. Whatever bad can happen around a software project doesn’t happen overnight. If you can catch it in a timely manner and fix it, you spend money on prevention, which is worth much more than any money spent in recovery.
Finishing with a smile
See http://www.murphys-laws.com for an extensive listing of computer (and noncomputer) related laws and corollaries. Here are a few you might enjoy:
![]() All models are wrong, but some models are useful. (George E. P. Box)
All models are wrong, but some models are useful. (George E. P. Box)
![]() Walking on water and developing software to specification are easy as long as both are frozen.
Walking on water and developing software to specification are easy as long as both are frozen.
![]() An oil leak will develop.
An oil leak will develop.