Microsoft .NET Architecting Applications for the Enterprise, Second Edition (2014)
Part III: Supporting architectures
CHAPTER 8 Introducing Domain Model
CHAPTER 9 Implementing Domain Model
CHAPTER 10 Introducing CQRS
CHAPTER 11 Implementing CQRS
CHAPTER 12 Introducing event sourcing
CHAPTER 13 Implementing event sourcing
Chapter 8. Introducing Domain Model
The model and the heart of the design shape each other.
—Eric Evans
About 10 years ago, a relatively young and fast-growing company hired Dino for ASP.NET training. They said that they mostly wanted some advanced web stuff, but they also wanted to learn more about those emerging patterns that help shape a more conceptual view of the business domain. They asked if they could reserve a day to get an overview of domain-driven design (DDD).
People with at least a smattering of DDD were not numerous at the time. Fortunately, Andrea was one of them and we were already in touch. So Andrea put together a quick primer on DDD that helped Dino immensely to prepare the extra day for the customer. By the way, that customer is now a worldwide leader in its industry, and we can’t help but think that their CTO’s visionary interest in DDD was very savvy and made it possible for the company to effectively tackle the complexity of a growing business.
DDD was originally defined as an approach to software development that starts from a ubiquitous language, passes through a map of bounded contexts, and ends with a recommended layered architecture centered on an object-oriented model of the business domain. Following the DDD principles, common steps such as understanding requirements, turning requirements into specs, actual coding and testing come easily—or at least, it’s the easiest they can come given an objectively high level of business complexity.
This chapter provides you with the rationale of DDD, putting emphasis on the alphabet soup of the domain layer. In the next chapter, we’ll see DDD in action applied to a concrete business domain.
The data-to-behavior shift
For a long time, the typical approach to development has been more or less the following. First, you collect requirements and make some analysis to identify both relevant entities (for example, customer, order, product) and processes to be implemented. Second, armed with this understanding you try to infer a physical (and mostly relational) data model that can support the processes. You make sure the data model is relationally consistent (primary keys, constraints, normalization, indexing) and then start building software components against tables that identify the most relevant business entities. You can also rely on database-specific features such as stored-procedures as a way to implement behavior while keeping the structure of the database hidden from upper levels of code. The final step is finding a comfortable model for representing data and moving it up to the presentation layer.
This approach to modeling a business domain is not wrong per se, and it just works. Nearly every developer knows about it; it’s a mature and consolidated practice and, again, it just works. So why should one change it for something that has a more attractive and exotic name—say, DDD—but also represents to many a sort of leap into the unknown?
Rationale behind models and domains
Over the years, the two of us many times have accepted the challenge of explaining the pluses of a domain-driven approach compared to a database-driven approach to software design. And often we just failed. Most of those times, however, we failed because we put the whole thing down as objects versus data readers.
It’s not about using objects instead of data readers
Well aware of what data access was before .NET, we recognize that the availability of ADO.NET was a landmark for Microsoft Windows developers. ADO.NET is a relatively thin layer over the infrastructure of a relational database. A data source provider hides the nitty-gritty details of the underlying storage and exposes .NET objects for cursors and result sets. The working pattern is crystal clear and easy: you open a connection, define a SQL command, decide how you want data back—either as a cursor or result set—execute the command, and close the connection. Nicely enough, ADO.NET cursors are also handy objects and result sets are even serializable.
In ADO.NET, you face some trouble only with type conversion and naming is not as strong as it is when you work with classes. To refer to a table column, for example, you must know the name and the name is a plain string. You know only at run time if you happened to type it wrong.
Narrowing the view to the Microsoft .NET Framework, LINQ-to-SQL and Entity Framework offered a quick-and-easy wizard to package up an existing database into a set of easy-to-manage objects. In addition, the burden of dealing with database connections and SQL commands was moved within the folds of ad hoc components that, moreover, were implementing patterns like unit-of-work, query object, lazy loading, and optimistic concurrency.
To cut a long story short, LINQ-to-SQL (now defunct) and Entity Framework were in the beginning Object/Relational Mapper (O/RM) tools with some additional wizardry to infer an object model out of a new or existing relational database.
Well, this is not what it means to take a domain-driven approach to software design.
This is simply writing a data-access layer using handy objects instead of ADO.NET data readers or DataSets. And it is a great achievement, anyway.
A persistent object model is not a domain model
As we discussed in Chapter 5, “Discovering the domain architecture,” DDD is an approach that involves much more than just writing data-access code using objects instead of records. DDD is primarily about crunching knowledge of the domain and has ubiquitous language and bounded contexts as the primary outcome. Within a bounded context, you often express the knowledge of the domain through a model. And most of the time—but not necessarily—this model is a special type of an object model and is called a “domain model.”
 Important
Important
Doing DDD is too often perceived simply as having an object model with some special characteristics. As we described in Chapter 5, DDD is especially about mapping contexts and their relationships, and then it is about giving each context an appropriate architecture. The architecture that Eric Evans recommended in his seminal book Domain-Driven Design: Tackling Complexity in the Heart of Software (Prentice Hall, 2003) is based on a domain model defined as an object model with special features. A few things have changed since. Today, in DDD context mapping is paramount and modeling the domain through objects is just one of the possible options—though the most broadly used one. We’re going with the assumption that the domain model is an object model in this chapter and the next.
In the end, an object-based domain model is just a persistent object model, except that it is decorated by some apparently weird characteristics: the preference of factories over plain constructors, abundant use of complex types, limited use of primitive types, mostly private setters on properties, and methods. All those apparently weird characteristics of the set of classes called a “domain model” exist for a specific reason.
What a model is and why you need one
The Mercator projection is a graphical representation of the world map. Its unique characteristics make it suitable for nautical purposes; in fact, the Mercator projection is the standard map projection used to elaborate nautical courses. See http://en.wikipedia.org/wiki/Mercator_projection for more details. Therefore, the Mercator projection is a model.
Is it a model that truly mirrors the real world? Is it both real and ideal?
The Mercator projection is based on a scale that increases as you proceed from the Equator up and down to the poles. Near the poles, the scale becomes infinite. Every square you see on the map represents—regardless of size—the same physical area. The net effect of the scale is that some areas of the world are seemingly larger or smaller than real. For example, if you look at the world layout through the perspective of the Mercator projection, you would say that Alaska is as large as Brazil. The reality, instead, is different, as Brazil takes up as much as five times the area of Alaska.
When you draw a course on a Mercator world projection, the angle between the course and the Equator remains constant across all meridians. This made it easy—already back in the 1500s—to measure courses and bearings via protractors.
The Mercator map is a model that distorts both areas and distances; in this regard, it is not suited to faithfully representing the map of the world as it really is. You don’t want to use it instead of, say, Google Maps to represent a city on a map. On the other hand, it’s a great model for the (bounded) context it was created for—nautical cartography.
It’s all about behavior
The domain model is intended to express, as faithfully as possible, the core business concepts for the application to deal with. The domain model is the API of the core business, and you want domain model classes to be always consistent with the business concept they represent.
When designing the domain model, you should make sure that no incorrect call to the API is possible that might determine, subsequently, that any of the domain objects are in an invalid state. Restrictions on a domain model have the sole purpose of making classes perfectly adherent to the core business concepts and continuously consistent.
It should be clear that to stay continuously consistent with the business you should focus your design on behavior much more than on data. To make DDD a success, you must understand how it works and render it with software. The software you write is primarily a domain model.
DDD is always good for everyone
The analytical part of DDD, as explained in Chapter 5, is good for any project of a significant lifespan. It’s about analysis in the end, and it consists of learning the mechanics of the domain and expressing that through an appropriate vocabulary. It’s not about coding, and it’s not about technologies.
It’s just what as an architect you would do in any case—analysis and top-level architecture. However, DDD establishes an approach and introduces the concept of ubiquitous language. Domain modeling is another aspect of DDD closer to software design and coding. And the DDD recipes for domain modeling might or might not work in all cases.
Up until a few years ago, DDD was considered viable only for extremely complex systems characterized by an extremely dynamic set of business rules. The rationale was that the costs of setting up a domain model were too high and easily absorbable only in a long-term project. The final decision results from trading off the need of having a model that mimics the structure and behavior of the system and the costs of having that. Building a successful, all-encompassing object model might be really hard, and it requires the right skills and attitude.
Sometimes, you can just decide that having a domain model is not worth the cost—and it could be both because the return is not perceived to be high and because the costs, instead, are perceived to be too high. When it comes to this, out of your DDD analysis you simply pick up an alternate supporting architecture for each bounded context.
Database is infrastructure
In our experience, one of the aspects that most scares people about DDD is that you end up with a model that has the aura of being database agnostic. How can I effectively design my system and make it perform as expected—many say—if I relegate the database to the bottom of my concerns?
There’s a clear misconception here.
All that DDD suggests is that you focus on business concepts and the processes of a given bounded context, learn about them, and plot a system that can faithfully reproduce those business concepts and processes. The resulting system is centered on a model that contains the core business logic.
As long as you are busy designing the model, the database is not your primary concern. Put another way, DDD simply says that domain modeling comes first and the persistence of the modeled domain comes later. But it surely comes. A common way of formulating this same concept is by saying that the database is just part of the infrastructure layer, albeit the most prominent part.
A domain model doesn’t have persistence concerns
By design, a domain model is not concerned about persistence. The model is concerned about relevant entities and their relationships, events, and observable behavior. The model just renders such entities through classes and methods. There’s no overlapping with databases in this.
The term persistence ignorance is often presented as a key attribute of a domain model. But what does this term mean concretely?
Persistence ignorance means that domain model classes should not be given methods to save or materialize instances from disk. Similarly, classes in the domain model should not be exposing methods that require access to the persistence layer to determine things like the total of an order or the status of a customer in the company’s reward system.
An application should care about persistence
There’s no such thing as a system that doesn’t need persistence. The domain model is better if it ignores persistence concerns, but the same certainly can’t be true for the rest of the application. All applications need some infrastructure for persistence and various cross-cutting concerns like security, caching, and logging.
DDD applications are no exception.
Furthermore, in a real-world scenario the database is almost always a constraint. Migrating data to a new database is rarely an option; more often, instead, you have some legacy subsystem to integrate and deal with. In this situation, focusing on data design makes even less sense. You are better off focusing on a business-oriented model that is serializable but neatly separated from the persistence layer. First you get the model; next you map it to a new or existing database.
A domain model is serializable if it can be saved to a database. Persistence typically occurs via Object/Relational Mapper (O/RM) tools. If you use an O/RM tool for persistence, the domain model might be subject to some of the requirements set by the O/RM tool. A typical example is when you need to give a domain model class an otherwise unnecessary parameter-less constructor only to let Entity Framework (or NHibernate) materialize the object after a query.
In the end, the domain model should be independent of persistence implementation details, but it often happens that the O/RM technology might place some minor constraints on the model.
 Note
Note
A domain model class doesn’t need dependencies to the O/RM. However, you shouldn’t be too surprised if you happen to make some minor concessions to O/RM tools just to be able to serialize the model. An example is having a protected constructor in classes. Another example is having an extra property and a bit of scaffolding to serialize arrays or, in some older versions of Entity Framework, also enumerated types. Let’s say that a realistic goal is having a domain model with the absolute minimum dependencies on infrastructure that could possibly work—and it’s better if it is zero.
Inside the domain layer
The most common supporting architecture for a bounded context is a layered architecture with a domain model. As described in Chapter 5, on top of the presentation layer, a layered architecture has orchestration code (the application layer) to act on the domain and infrastructure layer. The domain layer consists of a model and services. We assume here that the model is an object model.
Domain model
Overall, one of the most appropriate definitions for a domain model is this: a domain model provides a conceptual view of a business domain. Made of entities and value objects, it models real-world concepts with the declared purpose of turning them into software components.
Inspired by the big picture of DDD you find in the Evans’ book, Figure 8-1 summarizes the goal and structure of the domain layer: domain model, modules, and domain services.
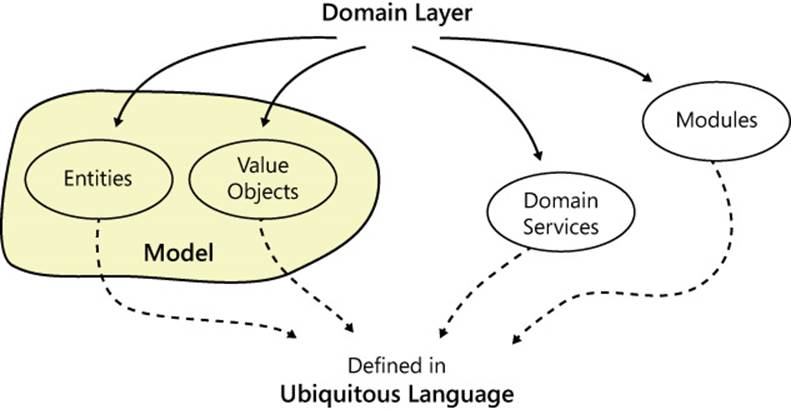
FIGURE 8-1 Terms in the ubiquitous language identify the building blocks of the domain layer.
Note
The term service in this context just refers to pieces of business logic, and it has no reference to any technologies (for example, Windows Communication Foundation), architecture (service-oriented architecture), and web infrastructure (web services).
Modules
When you turn a domain model into software, you identify one or more modules. Modules ultimately contain objects and partition the entire domain so that all concerns that surface in the domain model are clearly and cleanly separated. In concrete terms, a DDD module is just the same as a .NET namespace that you use to organize classes in a class library project.
In .NET, you use a namespace to group related types. During refactoring sessions, .NET namespaces can be renamed and change the set of types each contains. Likewise, DDD modules are subject to change over time to better reflect the current understanding of the business domain and actual conceptual contours of the various parts of the model.
If you realize that, at some point, different conceptual contours exist than those currently implemented, you should modify the implementation of the model to reflect that. Conceptual DDD modules and concrete .NET namespaces should be kept in sync all the time.
Within a bounded context, a domain model is organized in modules. Within a .NET project, a domain model is organized in namespaces, and groups of namespaces can be isolated in distinct class libraries. Here’s a summary of the cardinalities involved:
![]() One bounded context has one domain model.
One bounded context has one domain model.
![]() One bounded context can have several modules.
One bounded context can have several modules.
![]() One domain model can be related to several modules.
One domain model can be related to several modules.
Value objects
A DDD module contains entities and value objects. In the end, both are rendered as .NET classes, but entities and value objects represent quite different concepts and lead to different implementation details.
In DDD, a value object is fully defined by its attributes. The attributes of a value object never change after the instance has been created. If it does change, the value object becomes an instance of another value object fully identified by the new collection of attributes. In .NET, DDD value objects are referred to as immutable types. The Int32 and String types are the most popular immutable types in the .NET Framework.
Entities
All objects have attributes, but not all objects are fully identified by their collection of attributes. When attributes are not enough to guarantee uniqueness, and when uniqueness is important to the specific object, you have DDD entities. Put another way, if the object needs an ID attribute to track it uniquely throughout the context for the entire life cycle, the object has an identity and is said to be an entity.
In his book, Evans uses an example from a banking application to illustrate the difference between entities and value objects and explain why both concepts are relevant to the domain model. How would you consider two deposits of the same amount into the same account on the same day? Are they the same operation done twice, or are they distinct operations that each occur once?
It’s clearly the latter.
You have two distinct banking transactions, and the domain requires that you treat each independently. You can always uniquely refer to the transaction later, and the domain must clearly indicate what’s required to uniquely identify the object. We’ll return to entities and value objects in a moment and discuss in greater detail what it means to create classes for each.
Value objects are just data aggregated together; entities are typically made of data and behavior. When it comes to behavior, though, it’s important to distinguish domain logic from application logic. Domain logic goes in the domain layer (model or services); the implementation of use-cases goes into the application layer. For example, an Order entity is essentially a document that lays out what the customer wants to buy. The logic associated with the Order entity itself is related to the content of the document—taxes and discount calculation, order details, or perhaps estimated date of payment. The entire process of fulfilment, tracking status, or just invoicing for the order are outside the domain logic of the order. They are essentially use-cases associated with the entity, and services are responsible for their implementation.
Persistence of entities
A domain model must be persistent but, as repeatedly mentioned, it doesn’t take direct care of its own persistence. Nothing in the domain model implementation refers to load and save operations; yet, these operations are necessary for materializing instances of domain entities and for implementing the business logic.
A special flavor of components—repositories—takes care of persistence on behalf of entities.
Repositories are usually invoked from outside the domain model—for example, from the application layer—or from other components of the domain layer, such as domain services. The contracts for repositories are in the domain layer; the implementation of repositories belongs, instead, to a different layer—the infrastructure layer.
The statement that repositories take care of persisting entities is correct given what we have discussed so far. It is inaccurate in the broader perspective you’ll gain by the end of the chapter. The bottom line is that repositories persist aggregates, a special subset of entities.
Aggregates
As you go through the use-cases found in the requirements and work out the domain model of a given bounded context, it is not unusual that you spot a few individual entities being constantly used and referenced together. In a way, this can be seen as an occurrence of the data clump code smell—logically related objects being treated individually instead of being logically grouped and treated as a single object.
An aggregate is basically a consistency boundary that groups and separates entities in the model. The design of aggregates is closely inspired by the business transactions required by your system. Consistency is typically transactional, but in some cases it can also take the form of eventual consistency.
Note
It is a common practice to decompose a domain model in aggregates first, and then, within any aggregate, identify the domain entities.
Devising the aggregate model
In a domain model, the aggregation of multiple entities under a single container is called an aggregate. To use the Evans’ words, “An aggregate is a cluster of associated objects that we treat as a single unit for the purpose of data changes.”
The resulting model is then the union of aggregates, individual entities, and their value objects, as shown in Figure 8-2.
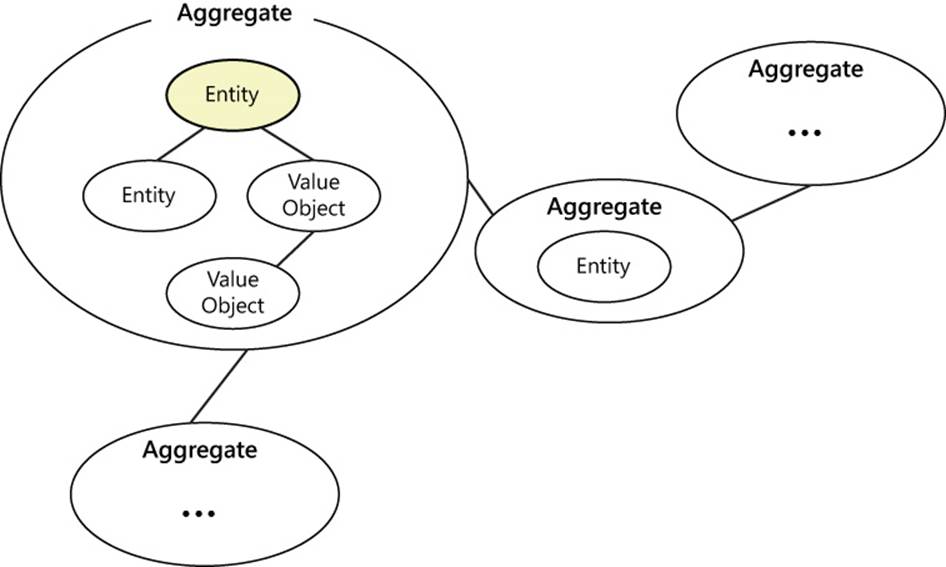
FIGURE 8-2 Representation of an aggregate model.
Entities in the model are partitioned into aggregates. Most aggregates are made of multiple entities bound together by their mutual parent/child relationships. Other aggregates are just made by individual entities that still relate to other aggregates but do not have child entities.
Each aggregate is subject to a logical boundary that simply defines which entities are inside the aggregate. More importantly, an aggregate has a root entity, which is called the aggregate root. The aggregate root is the root of a graph of objects; it encapsulates contained entities and acts as the proxy to them.
Using business invariants to discover aggregates
Aggregates are part of the design; architects and developers define aggregates to better reflect with code the ongoing business. In a bounded context, aggregates represent invariant conditions in the domain model. An invariant condition is essentially a business rule that is required to be constantly verified in a domain model. Put another way, aggregates are a way to ensure business consistency.
In general, there are two types of consistency: transactional consistency and eventual consistency. Transactional consistency refers to the aggregate for preserving consistency after every business transaction (that is, operation) that takes place in the domain. Eventual consistency refers to consistency that, at some point, is guaranteed to be preserved but might not be guaranteed after each business transaction. The aggregate is not concerned at all about the consistency and operations taking place outside of the boundary.
When thinking of aggregates, you’ll find that the first approximation that often comes to mind is that an aggregate is a graph of objects. You have orders that contain order items, which contain products, which contain categories, and so forth. While an aggregate can contain—and often it does contain—a graph of objects, the cardinality of the graph is typically limited to two or three objects.
 Important
Important
In a well-designed domain model, only one aggregate is modified in each single transaction. If at some point you find that a given use-case seems to require that multiple aggregates are modified in multiple transactions, you are probably not in an optimal design, although it is acceptable. Instead, when the use-case seems to indicate that multiple aggregates should be updated in a single transaction, that’s the clear sign that something is wrong somewhere. Most likely, you’re missing an invariant and the decomposition in the aggregate you created is less than ideal for the business.
Benefits of an aggregate model
There are a couple of significant benefits to creating an aggregate model within the boundaries of a domain model. In the first place, the implementation of the entire domain model and its business logic comes easier because you work with fewer and coarse-grained objects and with fewer relationships.
If this benefit seems to contradict SOLID (Single responsibility, Open/close, Liskov’s principles, Interface segregation, and Dependency inversion) principles and seems like it might lead to bloated objects, consider the following:
![]() The aggregate model is a purely logical grouping. The aggregate root class might undergo some changes because of its role, and those changes mostly deal with the management of external access to child entities.
The aggregate model is a purely logical grouping. The aggregate root class might undergo some changes because of its role, and those changes mostly deal with the management of external access to child entities.
![]() In terms of code, entity classes remain distinct classes and each retains its implementation. However, you don’t want to have public constructors on child entities, because those can break the consistency of the aggregate.
In terms of code, entity classes remain distinct classes and each retains its implementation. However, you don’t want to have public constructors on child entities, because those can break the consistency of the aggregate.
![]() The aggregate model doesn’t necessarily introduce new classes that group the code of logically embedded classes; however, for convenience aggregates often are coded just as new classes that encapsulate the entire graph of child objects. When this happens, it’s because you want to protect the graph as much as possible from outsider access. The boundary of the aggregate is explicit in code in this case.
The aggregate model doesn’t necessarily introduce new classes that group the code of logically embedded classes; however, for convenience aggregates often are coded just as new classes that encapsulate the entire graph of child objects. When this happens, it’s because you want to protect the graph as much as possible from outsider access. The boundary of the aggregate is explicit in code in this case.
The aggregate model raises the level of abstraction and encapsulates multiple entities in a single unit. The cardinality of the model decreases and, with it, the number of inter-entity relationships that are actionable in code also decreases. Have a look at Figure 8-3, which expands the idea ofFigure 8-2 to a realistic scenario.
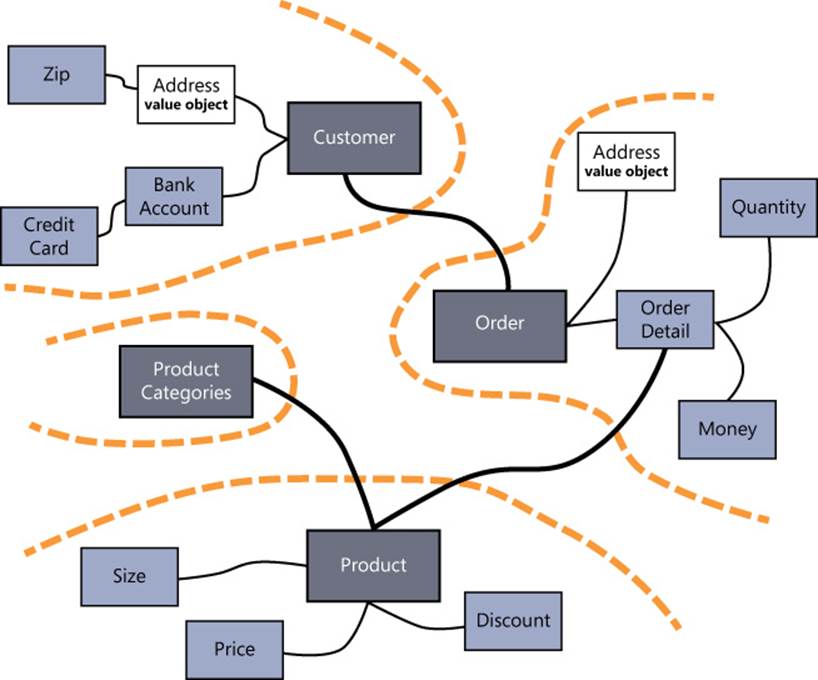
FIGURE 8-3 Partitioning an entity model into an aggregate model.
The other big benefit of the aggregate model is that it helps prevent a tightly coupled model, where each entity is potentially associated with a number of others. As you can see in Figure 8-3, boundaries can identify multiple entities linked to a root or just one entity that is the root of a single-node cluster.
The canonical example is the aggregate rooted in the Order entity in an e-commerce system. An Order is made of a collection of OrderItem entities. Both concepts are expressed via entities with identity and life, but OrderItem is a child of Order in the sense that the business logic might not require access to an order item outside the context of an order.
Important
Obviously, the actual boundaries of aggregates are determined exclusively by looking at requirements and business rules. Although, in general, an order item is expected to be child of an order, there might be a hypothetical scenario where OrderItem constitutes the root of a distinct aggregate. An even better example is Address, which could be a value object in some domains and an entity in others, such as utility companies (electricity and telephone).
An entity is either an aggregate root or is included in just one aggregate. A good example is the Product entity. When you look at orders, it turns out that products are referenced in order items. So the first thought is that Product belongs to the Order aggregate. However, next you might find out that use-cases exist to treat products outside of orders—for example, for the catalog of products. This makes up for another aggregate rooted in Product. The same goes for ProductCategories: as long as categories are subject to change (for example, deserve their own table), you need an aggregate and it will likely be a single-entity aggregate.
The final word on the boundaries of an aggregate belongs to the ubiquitous language. If the language says that the order contains product information and quantity, it’s clear that Order doesn’t reference Product but a value object instead.
What about value objects? They are definitely part of aggregates because they are referenced from entities. Value objects can be referenced by multiple entities and, subsequently, they can be used in multiple aggregates.
In terms of design, it might be interesting to consider the Address concept. We presented Address as one of the canonical examples of a value object. In this regard, an address is used to represent the residence of a customer as well as the shipping address of an order.
Suppose now that requirements change or your understanding of the system improves. As a result, you think it’s preferable to give addresses an identity and store them as individual entities on a distinct table. That would immediately be reflected in the aggregate model because nowAddress becomes the root of the aggregate itself; likely, it is a single-entity aggregate. Subsequently, two new relationships come into existence: Customer to Address and Order to Address.
Relationships between aggregates
Implementing the aggregate model requires minimal changes to the involved entity classes, but it does have a huge impact on the rest of the domain model—services and repositories in particular. Figure 8-4 shows how the use of aggregates reduces the cardinality of objects actionable in code and helps prevent a bloated system.
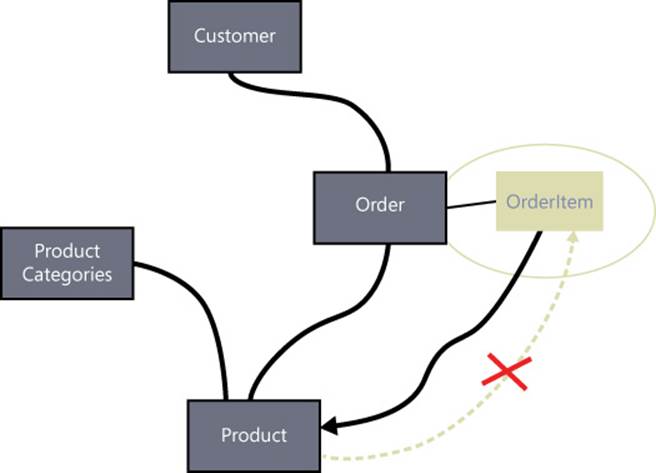
FIGURE 8-4 Collapsed view of the aggregate model laid out in Figure 8-3.
Aggregate root classes hide related classes from callers and require that callers refer to them for any interaction. In other words, an entity is only allowed to reference an entity in the same aggregate or the root of another aggregate. At the same time, a child entity—like OrderItem in Figure 8-4—can hold a reference to another aggregate root.
Marking aggregate roots
An aggregate root object is the root of the cluster of associated objects that form the aggregate. An aggregate root has global visibility throughout the domain model and can be referenced directly. Entities inside the aggregate still have their identity and life, but they can’t be referenced directly from outside the aggregate.
This is the foundation of the aggregate model.
An object (for example, a service) can use, say, the address of a customer or the items of an order. Access to this encapsulated information, though, must always occur through the root. Callers should consider any references to internal objects they get as transient and avoid using them beyond the scope of a single call.
The aggregate root object has relevant responsibilities. Here’s the list:
![]() The aggregate root guarantees that contained objects are always in a valid state according to the applicable business rules (consistency). For example, if a rule requires that no detail of the order can be updated after it has shipped, the root must make this update impossible in code.
The aggregate root guarantees that contained objects are always in a valid state according to the applicable business rules (consistency). For example, if a rule requires that no detail of the order can be updated after it has shipped, the root must make this update impossible in code.
![]() Subsequently, the aggregate root is responsible for the persistence of all encapsulated objects.
Subsequently, the aggregate root is responsible for the persistence of all encapsulated objects.
![]() Subsequently, the aggregate root is responsible for cascading updates and deletions through the entities in the aggregate.
Subsequently, the aggregate root is responsible for cascading updates and deletions through the entities in the aggregate.
![]() Subsequently, a query operation can only retrieve an aggregate root. Access to internal objects must always happen by navigation through the interface of the aggregate root.
Subsequently, a query operation can only retrieve an aggregate root. Access to internal objects must always happen by navigation through the interface of the aggregate root.
It should be clear that most of the code changes required to support the rules of an aggregate model occur at the level of services and repositories. In terms of code, what does it mean to be an aggregate root?
An aggregate root usually implements an interface commonly called IAggregateRoot, as shown here:
public class Order : IAggregateRoot
{
...
}
The interface doesn’t strictly require any functionality. It can easily be a plain marker interface that is used only to clarify to the outside world that an entity is actually a root.
public interface IAggregateRoot
{
}
An aggregate root can also be given a slightly more sophisticated implementation that, overall, can make the implementation of the model more robust:
public interface IAggregateRoot {
bool CanBeSaved { get; }
}
By making the property blindly return true, you’re back to the scenario where IAggregateRoot is a mere marker and memberless interface. By adding some logic in the getters, instead, you can validate that the aggregate state is effectively ready for saving or deleting. Here’s a possible way to use this variation of the interface:
public class Order : IAggregateRoot
{
bool IAggregateRoot.CanBeSaved
{
get { return Validate(); }
}
...
}
The aggregate root interface is typically used as a type constraint for repository classes. In this way, the compiler enforces the rule that only aggregate roots have repositories and handle persistence.
Note
A simple rule to help developers with a strong database background orientate themselves in the DDD world is the following. Entities are those things for which, in a relational model, you want to have a separate table. Aggregates are the union of tables linked together by foreign-key relationships. Finally, an aggregate root is the unique table in a graph of foreign-key relationships that contain only outbound foreign-key references.
Domain services
Domain services are classes whose methods implement the domain logic that doesn’t belong to a particular aggregate and most likely span multiple entities. Domain services coordinate the activity of aggregates and repositories with the purpose of implementing a business action. In some cases, domain services might consume services from the infrastructure, such as when sending an email or a text message is necessary.
When a given piece of business logic doesn’t fit in any of the existing aggregates and aggregates can’t be redesigned in a way that the operation fits, you typically look into using domain services. So, in a way, domain services are the last resort for logic that doesn’t fit anywhere else.
Domain services, however, are not plain, working-class items in a domain model. Actions they implement come from requirements and are approved by domain experts. Last but not least, names used in domain services are strictly part of the ubiquitous language.
Services as contracts
It is common to represent domain services through interfaces and implementation classes. When you use interfaces, most of the time you intend to preserve testability or create an extensibility point in your software.
This is not the case for domain services.
The interface of domain services represents a contract written in the ubiquitous language and lists actions available for application services to call.
Cross-aggregate behavior
The most common scenario for domain services is to implement any behavior that involves multiple aggregates, database access methods, or both. A good example is a domain service that determines whether a given customer reached the status of “gold” customer. Suppose the domain says that a customer earns the status of “gold” customer after she exceeded a given threshold of orders on a selected range of products.
How would you check that?
You can’t reasonably have a method IsGold on the Customer aggregate that calculates the status. Calculating the status requires accessing the database—not the right job for an aggregate to do. A domain service is then the perfect fit. A service, in fact, is able to query orders and products for a customer.
The structure of the model largely influences the number of and interface for domain services.
Consider a booking scenario. You have a club member who wants to book a resource—say, a meeting room. The action of booking requires the application of some business logic steps, such as verifying availability and processing payment. There at least two ways you can do this. You can have a Booking domain service that reads the member credit status and checks the room availability, or you can have a Booking entity that deals with Member and Room dependencies. The repository of the Booking entity is then responsible for the whole task. Both options are equally valid because they both effectively model the domain.
Note
In his book, Evans uses a similar example to illustrate the case for a domain service. He mentions a bank wire-transfer service as an example of a domain service working across multiple entities (bank accounts).
Repositories
Repositories are the most popular type of domain service, and they take care of persisting aggregates. You’re going to have one repository per aggregate root: CustomerRepository, OrderRepository, and so forth.
A common practice is extracting an interface out of these classes and defining the interfaces in the same class library as the core model. The implementation of repository interfaces, instead, belongs to the infrastructure layer. A repository is often based on a common interface likeIRepository:
public interface IRepository<T> where T:IAggregateRoot
{
// You can keep the interface a plain marker or
// you can have a few common methods here.
T Find (object id);
void Save (T item);
}
Specific repositories are then derived from the base interface:
public interface IOrderRepository : IRepository<Order>
{
// The actual list of members is up to you
...
}
Note that there’s no way to build a repository that is absolutely right or wrong. A good repository can also simply be an interface-based class with a list of members arranged as you need them to be. You can even ignore the IAggregateRoot interface and just implement persistence for the entire graph as it should be:
public interface IOrderRepository
{
// The actual list of members is up to you
...
}
Members of a repository class will actually perform data access—either queries, updates, or insertions. The technology used for data access is up to you. Most commonly today, you use an O/RM like Entity Framework, but nothing prevents you from using ADO.NET, plain stored procedures or, why not, a NoSQL store.
An interesting implementation of the IRepository<T> interface consists of marking the interface with a Code Contracts class so that the CLR can inject some Intermediate Language (IL) code into any implementation of the IRepository methods:
[ContractClass(typeof(RepositoryContract<>))]
public interface IRepository<T> where T:IAggregateRoot
{
...
}
And here’s the implementation of the contract class:
[ContractClassFor(typeof(IRepository<>))]
sealed class RepositoryContract<T> : IRepository<T> where T : IAggregateRoot
{
public void Save(T item)
{
Contract.Requires<ArgumentNullException>(item != null, “item”);
Contract.Requires<ArgumentException>(item.CanBeSaved);
throw new NotImplementedException();
}
}
When the Save method is invoked, the CanBeSaved method on the provided aggregate is automatically invoked care of the CLR. For the sake of consistency, the check on CanBeSaved should happen at the domain service level before the repository is invoked to persist the aggregate and within the repository just before saving. Developers are responsible for writing this code. The contract gimmick ensures that, whatever happens, the CLR checks whether the aggregate can be saved and throws otherwise.
The interface of repositories is usually defined in the assembly where you code the domain layer, but the implementation clearly belongs to the infrastructure layer.
The assembly that contains the implementation of repositories has a direct dependency on O/RMs like Entity Framework, NoSQL, or in-memory databases; external persistence services; and whatever data provider you might need.
To clear up any remaining doubts, we want to point out that a repository is where you deal with connection strings and use SQL commands.
Important
So far, we have repeatedly mentioned persistence, but we never focused on physical storage. We’ll return to this aspect in detail in Chapter 14, “The persistence layer,” which is dedicated to the persistence layer. For now, it suffices to say that a domain model exists to be persisted; to achieve persistence successfully, though, you might need to make some concessions in your domain model and make other compromises.
Note
Repository is a rather bloated term. If you look around, you might find several conflicting definitions for it and several strongly recommended implementations. We think the same term is used to refer to different concepts. In the context of DDD, a repository is what we described in this chapter—the class that handles persistence on behalf of entities and, ideally, aggregate roots. We’ll say more about this in Chapter 14.
Is it a service or is it an aggregate?
As mentioned, we tend to consider domain services to be backup solutions for pieces of behavior that we can’t fit naturally—for whatever reasons—in aggregates. However, sometimes we also wonder whether that business action really doesn’t fit in the domain model or whether we are just unable to model it right.
When the ubiquitous language seems to present an operation as a first-class concept—for example, transfer or booking—we wonder whether we wouldn’t be better off using a new persistent entity instead of a domain service to orchestrate the process.
In the end, however, both options can be made to work.
Domain events
Imagine the following scenario: in an online store application, an order is placed and processed successfully by the system. The payment was made OK, the delivery order was passed on and received by the shipping company, and the order was generated and inserted into the system. Now what? What should the system be doing when an order is created? Let’s say that the ubiquitous language tells you exactly what to do, and that is some task T. Where would you implement task T?
From sequential logic to events
The first option is just concatenating the code for task T to the domain service method that performed the order processing. Here’s some pseudocode:
void Checkout(ShoppingCart cart)
{
// Proceed through the necessary steps
...
if (success)
{
// Execute task T
...
}
}
This code has some problems. In the first place, it is not very expressive. All steps form an end-to-end monolithic checkout procedure. Outside the Checkout method, there’s no visibility into what might have happened internally. Is this really a problem? Well, it depends. In this case, for example, it might be an indication of some violation of the ubiquitous language.
A few lines earlier, we wrote the adverb “when” in italics. We did so to call your attention to the specific word. Any time you find “when” in the requirements, you likely have the occurrence of a relevant event in the domain. An event registers the occurrence of a fact in some context; the word “when” in requirements indicates that there’s some business interest in knowing when a given fact occurs.
Requirements indicate what to do when a given event is observed. If you place the handling code in the domain service method, you have to touch the domain service method in case requirements change or it becomes necessary to perform more actions for the same event. Modifying a domain service class is not dangerous per se, but in general any other approach that minimizes the risk of modifying existing classes is more than welcome.
Raising an event when something relevant occurs
Wouldn’t it be better if we just raise an event when a given domain-relevant fact occurs? The event would remove the need to have all handling code in a single place. This brings two main benefits to the table:
![]() Enables us to dynamically define the list of handlers without touching the code that generates the event
Enables us to dynamically define the list of handlers without touching the code that generates the event
![]() Enables us to potentially have multiple places where the same event is raised. This means that handlers will run regardless of the actual caller
Enables us to potentially have multiple places where the same event is raised. This means that handlers will run regardless of the actual caller
Let’s see how to define an event in a domain model.
Formalizing a domain event
At the end of the day, a domain event is a plain simple class that represents an interesting occurrence in the domain. Good examples are when an order is created or when a customer reaches the gold status according to the fidelity program. If you spend only a few moments thinking about events, you find plenty of examples in nearly any domain model you consider. An event is when an invoice is issued or modified, when a credit note is issued for an outbound invoice, when a new customer is registered in the system, and so forth.
In line with this principle, a domain event can simply be an event member defined on a class. In a Domain Model scenario, however, events are typically represented via a domain-specific class marked with an ad hoc interface.
public interface IDomainEvent
{
}
Here’s a sample class:
public class CustomerReachedGoldMemberStatus : IDomainEvent
{
public Customer Customer { get; set; }
}
Note
In .NET, an event is an instance of a class derived from EventArgs, and it contains the information that describes the circumstance. In the end, IDomainEvent and a base class like EventArgs are two different ways of giving the event class a role.
Using EventArgs as the base class, the .NET mechanism of raising events might definitely be an option. However, it’s a common practice in a domain model to implement an internal event engine, mark events via an interface, and signal significant state changes in the domain entities via an internal publish/subscribe mechanism, as in the following code:
public class OrderRequestService
{
public void RegisterOrder(ShoppingCart cart)
{
// Create and persist the new order
...
// Check gold status for the customer who made the order
CheckGoldStatusForCustomer(cart.Customer);
}
public void CheckGoldStatusForCustomer(Customer customer)
{
// Get total amount of orders placed in current year
var totalOrdered = CalculateTotalOrdersForCustomer(customer, DateTime.Today.Year)
if (totalOrdered > 1000)
{
Bus.Raise(new CustomerReachedGoldMemberStatus() { Customer = customer });
}
}
}
Handling domain events
Raising the event is only part of the job. The next step consists of figuring out a way to define handlers for those domain events. Here’s a basic implementation of the class that raises events:
public class Bus
{
private static IList<IHandler<IDomainEvent>> Handlers = new List<IHandler<IDomainEvent>>();
public static void Register(IHandler<IDomainEvent> handler)
{
if (handler != null)
Handlers.Add(handler);
}
public static void Raise<T>(T eventData) where T : IDomainEvent
{
foreach (var handler in Handlers)
{
if (handler.CanHandle(eventData))
handler.Handle(eventData);
}
}
}
As you can see, raising an event actually means going through the list of known subscribers and giving each the chance to handle the event. Any registered handler always gets a chance to handle an event of a given type.
A handler is a small class that contains some logic to run in reaction to a given event. Obviously, you can have multiple classes to handle the same domain event. This allows for the composition of actions, such as when an event occurs, you first do task 1 and then task 2. Here’s some sample code for a handler:
public class GoldStatusHandler : IHandler<IDomainEvent>
{
public void Handle(IDomainEvent eventData)
{
// Some synchronous task
...
return;
}
public bool CanHandle(IDomainEvent eventType)
{
return eventType is CustomerReachedGoldMemberStatus;
}
}
Note that if the body of the method Handle needs to contain some async operation (for example, sending an email), instead of using events you can use plain messages on some queue. Or, if it is possible given the context, you can just place a fire-and-forget request for the async operation to yet another component invoked from within the method Handle.
Cross-cutting concerns
In a layered architecture, the infrastructure layer is where you find anything related to concrete technologies. The layer primarily encompasses data persistence through O/RM tools but is not limited to that. The infrastructure layer is also the place for cross-cutting concerns and encompasses specific API for security (for example, OAuth2), logging, tracing, as well as IoC frameworks.
Let’s briefly see how cross-cutting concerns and persistence affect a domain model.
Under the umbrella of a single transaction
Not just because you do smart and cool domain modeling, you don’t need to dirty your hands with database connection strings and fancy things like cascade rules, foreign keys, and stored procedures. As mentioned, persistence is not a concern you let emerge through the public interface of a domain. CRUD operations, though, happen and are coded mostly via repositories and combined via domain services and, at a higher level, via the application layer.
Today, most advanced aspects of a CRUD interface are fully handled via the O/RM. When you use, say, Entity Framework, you operate transactionally per units of work that the framework’s context object transparently manages for you. The unit of work spans only a single database connection. For multiconnection transactions, you can resort to the TransactionScope class. Often, you might need to use this class from the application layer to sew together multiple steps of a single logical operation.
In the end, you isolate data-access code in repositories and use repositories from within the application layer or domain services.
Validation
In DDD, there are two main sentiments as far as validation is concerned. Most people say that an entity must always be in a valid state, meaning that the state must be constantly consistent with known business rules. Some other people reckon that entities should be treated as plain .NET objects until they’re used in some way. It’s only at this time—the run time—that validation takes place and exceptions are thrown if something is wrong.
As DDD is about modeling the domain faithfully, it should always deal with valid entities—except that honoring validation rules all the time might be quite problematic. Validation rules, in fact, are like invariants; hence, entities should be responsible for fulfilling invariants in their lifetime. Unfortunately, invariant conditions for an entity are often scoped to the domain model (not the class) and often require checking information out of reach for the given entity (for example, database unique values).
This is exactly what makes some situations desirable for making concessions and admitting entities in an invalid state where some of the invariants are missed.
In any .NET class, validation logic can be as simple as an if-then-throw control flow, or it can pass through a validation framework such as .NET data annotations or the Enterprise Library Validation Block. While we find that data annotations are great in the user interface and presentation layer, we still aim to keep a domain model as lean as possible. This means that we mostly use if-then-throw statements or .NET Code Contracts—mostly preconditions and postconditions.
The simple use of preconditions, however, might not ensure that the object is in a valid state. Because invariants apply at the domain-model level, the entity alone can’t realistically be expected to check its consistency at all times. This is where an ad hoc domain service can be created to perform full validation.
Important
Classes in the domain model should check whatever they can check and throw ad hoc exceptions whenever something wrong is detected. We don’t expect the domain model to be forgiving: we expect it to yell out as soon as something goes against expectations. What about error messages? A domain model should have its own set of exceptions and expose them to upper layers such as the application layer. The application layer will decide whether the domain exception should be bubbled up as-is to the presentation layer, rethrown, or swallowed. The actual error message, instead, is up to the presentation layer.
Security
We distinguish two aspects of security. One has to do with the surrounding environment of the application and touches on things like access-control permissions, cross-site scripting, and user authentication. None of these aspects—relevant in the overall context of the application—apply to the domain-layer level.
The second aspect of security has to do with authorization and ensuring that only authorized users are actually allowed to perform certain operations. As we see it, the application layer should allow only an authorized call pass to reach the domain logic.
It might be hard for the domain service OrderHistory to check from within the domain layer whether the caller has been granted the right permissions. Security at the gate is our favorite approach, and we see it implemented by the presentation layer (say, by hiding links and buttons) along with the application layer.
Note
Security at the gate in the presentation layer is acceptable in situations in which the granularity of the security matches the use-case. The typical example is when a user within a given role is not authorized to perform a given action. You can achieve that simply by hiding user-interface elements. In general, security at the gate means security restrictions are applied as early as possible in the call stack. Often, it is already applied in application services at the beginning of the use-cases.
Logging
The fundamental thing about logging is that it’s you who decide what to log and from where. If you decide it’s critical to log from within the domain model, you need a reference to the logging infrastructure right in the domain model.
However, you don’t want to create a tight coupling between the domain model and a logger component. What you can do to log from the domain model is inject a logger interface in the model classes but keep the implementation of the logger in the infrastructure project.
This said, we believe that in a .NET executable, logging should happen whenever possible through built-in trace listeners, such as the EventLogTraceListener class. These classes are built into the .NET Framework and don’t require additional dependencies, such as log4net and the Logging Application Block in the Enterprise Library.
Caching
Like logging, the ideal implementation of caching and the placement of the relative code strictly depends on what you really want to cache. Unlike logging, caching doesn’t really seem to be a concern of the domain model. However, domain services and repositories might take advantage of caching to improve performance and save some database reads or the invocation of remote services.
From a design perspective, all you do is hide components that are subject to the use of the cache behind a contract. For example, you define the public interface of the repository and then use whatever caching infrastructure you like in the implementation of the repository. That keeps the caching system completely transparent for the consumer of the repository.
For testing and extensibility reasons, you can also abstract the cache API to an interface and inject a valid implementation in the repository or domain service.
Important
Caching means serving users some stale data. Even though we recognize that very few applications can’t afford data only a few seconds stale, it’s not the development team who can decide whether serving stale data is appropriate. It mostly works like this: the domain expert shares his performance expectations, and the development team indicates the costs involved to achieve that, whether it is the cost of hardware or caching. The final word belongs to the domain experts.
Summary
A domain model attempts to model a business domain in terms of entities and value objects and their relationships, state, and behavior. In a domain model, an entity is a pertinent object in the business space; it has an identity and a life. A value object, instead, is simply an inanimate thing within the business space. Some entities are then grouped in aggregates for the sake of code and design.
In this chapter, we mostly focused on the foundation of the Domain Model pattern and looked into its theoretical aspects. In the next chapter, we’ll move deeper into the implementation aspects. In upcoming chapters, we discuss other supporting architectures, such Command/Query Responsibility Segregation (CQRS) and event sourcing.
Finishing with a smile
As far as we know, there are no official Murphy’s laws for developers. However, we came up with interesting candidates while searching for developer jokes and funny software things on the Internet, and we also invented some on our own:
![]() If a developer can use an API the wrong way, he will.
If a developer can use an API the wrong way, he will.
![]() Actual data will rarely reflect your preconceived notions about it. You will usually discover this at the most inappropriate time.
Actual data will rarely reflect your preconceived notions about it. You will usually discover this at the most inappropriate time.
![]() Those who have the least amount of practical experience usually have the strongest opinions about how things should be done.
Those who have the least amount of practical experience usually have the strongest opinions about how things should be done.
![]() The solution to a problem changes the problem.
The solution to a problem changes the problem.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.