Adaptive Code via C# Agile coding with design patterns and SOLID principles (2014)
Part II: Writing SOLID code
Chapter 6. The open/closed principle
After completing this chapter, you will be able to
![]() Understand different interpretations of the open/closed principle.
Understand different interpretations of the open/closed principle.
![]() Treat SOLID code as append-only.
Treat SOLID code as append-only.
![]() Compare and contrast different class extension-point mechanisms.
Compare and contrast different class extension-point mechanisms.
![]() Use protected variation as a guideline for extension points.
Use protected variation as a guideline for extension points.
The oxymoronic nature of the open/closed principle causes some confusion. Its pithy name suggests code that is permissive but at the same time restrictive. The several variations of the definition serve only to cloud matters further.
Picking one definition over another and using it alone would be remiss of me. Rather, this chapter compares each definition and its consequences to try to distill the principle down to its essence. The goal is a very useful guideline that will enable you to create code that is more adaptive to future changes.
Introduction to the open/closed principle
There are two definitions of the open/closed principle that must be examined, the original coining from the 1980s and a more contemporary definition. The latter seeks to elaborate on the former by giving it more context and clarifying the principle’s scope.
The Meyer definition
Bertrand Mayer, in his 1988 book, Object-Oriented Software Construction (Prentice Hall), defined the open/closed principle (OCP) as follows:
Software entities should be open for extension, but closed for modification.
—Bertrand Meyer
The Meyer definition is the most commonly cited definition of the principle, but there is a second: the Martin definition.
The Martin definition
Robert C. Martin has defined the OCP in many different writings over the years. A more verbose version has been chosen here to contrast with the brief original:
“Open for extension.” This means that the behavior of the module can be extended. As the requirements of the application change, we are able to extend the module with new behaviors that satisfy those changes. In other words, we are able to change what the module does.
“Closed for modification.” Extending the behavior of a module does not result in changes to the source or binary code of the module. The binary executable version of the module, whether in a linkable library, a DLL, or a Java .jar, remains untouched.
—Robert C. Martin, Agile Software Development: Principles, Patterns, and Practices (Prentice Hall, 2003)
For both sides of the open/closed principle, Martin explains in further detail what is meant by the key terms from the Meyer definition. To be open for extension, Martin explains, developers must be able to respond to changing requirements and support new features. This must be achieved despite modules being closed to modification. Developers must support new functionality without editing the source code—or compiled assembly—of the existing modules.
Before this chapter begins to describe how this is possible, there are exceptions to the restrictive “closed for modification” clause of the OCP that are sometimes cited: changes for fixing bugs or defects and changes that can be made without any client awareness.
Bug fixes
Bugs are a common problem in software, and they are impossible to prevent entirely. When they do occur, though, you need to respond by fixing the problem code. Of course, this involves a modification to an existing class—that is, unless you are willing to duplicate the class and implement the bug fix on the new version. This sounds needlessly convoluted and runs counter to the guiding principle of erring on the side of pragmatism rather than purity.
The two-step process for fixing a bug is outlined as follows:
1. Write a failing unit test and/or integration test that specifically targets the bug. This requires reliable and repeatable reproduction steps to create the conditions under which the code fails. Referring back to the AAA syntax of a unit test, you need to be able to Arrange the system under test so that it is in a state that might exhibit the defect, perform the specific Act in which the defect resides, and finally Assert the expected behavior. When you write such a test, the test will initially fail. This demonstrates the fact that all bugs are the result of missing tests. If a test is present that captures the defect, the test fails and, by extension, so does the build on the build server, when continuous integration is used.
2. The source code is modified so that the unit test passes. The bug fix exception to the OCP becomes necessary at this juncture because, without it, you would not be able to modify any existing code. Editing the system under test allows you to transition the failing test from red to green—from failure to success. When you ensure that no other tests are failing as a side effect, the bug is fixed.
Client awareness
A more permissive exception to the “closed for modification” rule is that any change is allowed to existing code as long as it does not also require a change to any client of that code. This places an emphasis on how coupled the software modules are, at all levels of granularity: between classes and classes, assemblies and assemblies, and subsystems and subsystems.
If a change in one class forces a change in another, the two are said to be tightly coupled. Conversely, if a class can change in isolation without forcing other classes to change, the participating classes are loosely coupled. At all times and at all levels, loose coupling is preferable. Maintaining loose coupling limits the impact that the OCP has if you allow modifications to existing code that does not force further changes to clients.
Extension points
Now that the “closed for modification” rule of the OCP is clarified, the “open for extension” rule can be considered. Classes that honor the OCP should be open to extension by containing defined extension points where future functionality can hook into the existing code and provide new behaviors.
Some options for different kinds of extension points are detailed in this section, with their pros and cons explored. These examples continue the TradeProcessor example of the previous chapter, this time focusing on the client’s interaction with the class.
Code without extension points
First, what does code look like when it has no extension points? Figure 6-1 shows what happens when a class that has no extension points needs new functionality.
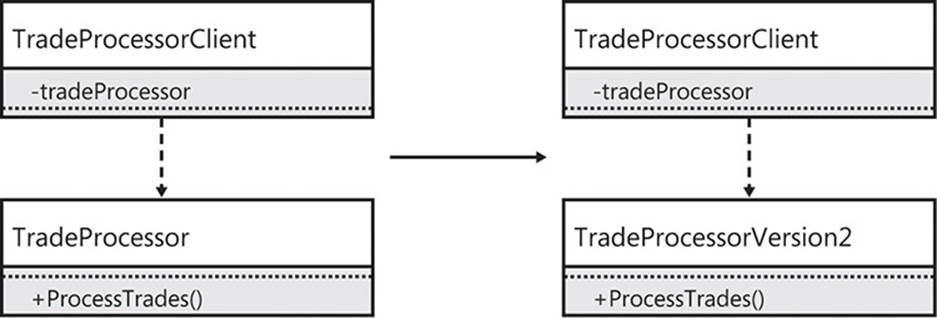
FIGURE 6-1 When there are no extension points, clients are forced to change.
The TradeProcessorClient depends directly on the TradeProcessor class. A new requirement is handed to you, resulting in necessary changes to the TradeProcessor class. Without modifying the original class, you create a new version (TradeProcessorVersion2) that contains the new functionality as specified in your new requirement. Because the client directly depends on the TradeProcessor class, and because of the lack of extension points in the TradeProcessor class, you need to place the new functionality inside a new class. The side effect of this change is that the TradeProcessorClient must be edited so that it depends on the new version of the class.
If you allow changes to existing code as long as they have no client impact, you might not have to create an entirely new version of the TradeProcessor. If the ProcessTrades method were to change, this would not simply be an implementation change for the class, it would also be an interface change. All interface changes force client changes because clients are always tightly coupled to the interfaces of their services.
Virtual methods
An alternative implementation for the TradeProcessor class contains an extension point: the ProcessTrades method is virtual. Figure 6-2 shows how the three classes are now arranged.
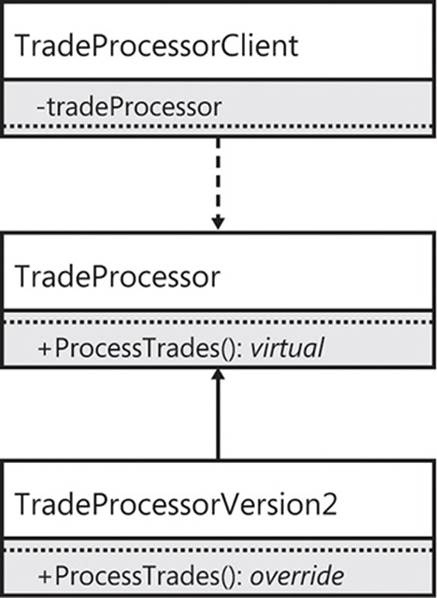
FIGURE 6-2 The client depends on the TradeProcessor class, which can be extended via inheritance.
Any class that marks one of its members as virtual is open to extension. This type of extension is via implementation inheritance. When your requirement for a new feature in the TradeProcessor class arrives, you can subclass the existing TradeProcessor and—without modifying its source code—alter the ProcessTrades method.
The TradeProcessorClient does not need to change in this case, because you can use polymorphism to supply the client with the new version of the TradeProcessor and have it call the subclass’s implementation of the ProcessTrades method.
You are somewhat limited in the scope of your reimplementation, however. You have access to the base class—so you can call TradeProcessor.ProcessTrades()—but you cannot alter individual lines of the original method. You either call the original method in its entirety, perhaps implementing the new feature before or after the call, or you reimplement it completely. There is no middle ground with a virtual method. Remember, subclasses can only access members from their base class that are marked as protected. If the TradeProcessor was created with many private members, you would not have access to them, and altering the original class is, of course, prohibited by the OCP.
Abstract methods
A more flexible extension point that uses implementation inheritance is an abstract method. In this case, the TradeProcessor is an abstract class that defines a public ProcessTrades method, which delegates the work of the processing algorithm to three protected abstract methods. The client has no knowledge of these protected methods and, because they are abstract, no implementation is provided. Figure 6-3 shows the relationships between the classes involved.
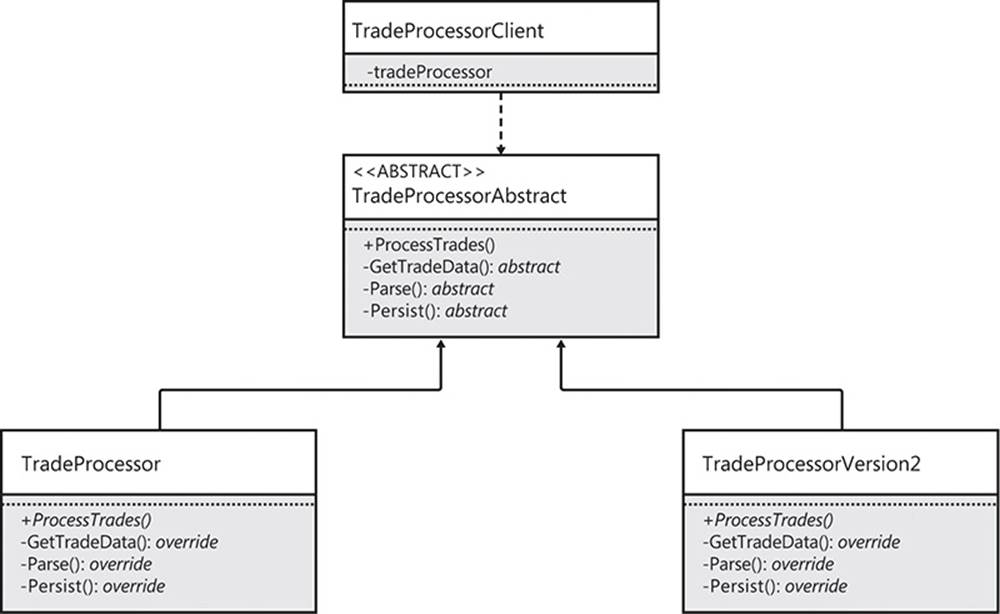
FIGURE 6-3 Abstract methods provide extension points for future subclasses.
Two versions of the trade processor are provided. Both inherit the ProcessTrades method directly from the abstract base class, and both provide their own implementations for the abstract methods. The client depends on the abstract base class, so either concrete subclass—or a new subclass for new requirements—could be provided and the OCP would be preserved.
This is an example of the Template Method pattern, in which an algorithm is modeled but its general steps are customizable because of delegation to abstract methods. In effect, the base class delegates the individual steps of the process to subclasses.
Interface inheritance
The final type of extension point discussed in this chapter is the alternative to implementation inheritance: interface inheritance. Here, the client’s dependency on a class is replaced with the now-familiar delegation to an interface. Figure 6-4 shows the client’s dependency on the interface and the two implementations of the interface.
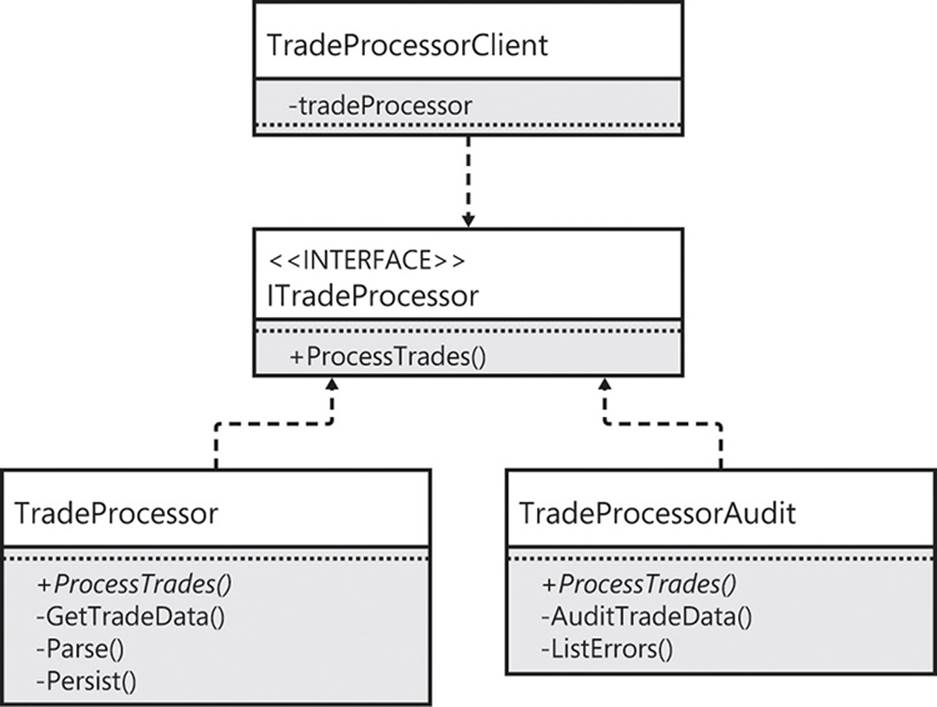
FIGURE 6-4 The client depends on an interface rather than a class.
Interface inheritance is preferable to implementation inheritance. With implementation inheritance, all subclasses—present and future—are clients. This prevents modification because, with implementation inheritance, subclasses depend on the implementation, too. All implementation changes are thus potentially client-aware changes. This echoes the advice to prefer composition over inheritance and to keep inheritance hierarchies shallow, with few layers of subclassing. If a change is made to add a member at the top of the inheritance graph, that change affects all members of the hierarchy.
Interfaces are also better extension points because they can be decorated with rich object graphs of functionality that calls upon many different contexts. They are more flexible than classes. I don’t mean that the virtual and abstract methods that form the extension points of class inheritance are not useful, but that they do not provide quite the same level of adaptability that interfaces do.
“Design for inheritance or prohibit it”
In his book Effective Java (Addison-Wesley, 2008), Joshua Bloch has this to say about inheritance:
Design and document for inheritance or else prohibit it.
—Joshua Bloch
If you choose to use implementation inheritance as an extension point, you must design and document the class properly so as to protect and inform future programmers who extend the class. Inheritance of classes can be tricky—new subclasses can break existing code in unpredictable ways.
It is very important to note that any class that is not marked with the sealed keyword claims to support inheritance. A class does not need to be abstract or to contain virtual methods in order to be subclassed. The new keyword can be used to hide inherited members, but this blocks polymorphism, possibly defying expectations.
Prohibiting inheritance by sealing a class communicates a clear message to other programmers who might use the class: inheritance is not just unsupported in this class, it is prevented. This removes the temptation to try to extend the class, so programmers will redirect their efforts to finding an alternative.
Protected variation
You are now armed with several tools with which to implement the OCP. You know under which circumstances you can edit existing classes, and you know that you need to implement extension points in your code in order to support future changes in requirements. You also know that you can use interfaces as extension points to make your code truly adaptable and, perhaps, future-proof.
The missing ingredient is the knowledge of when and where to apply this principle. Taken to its logical extreme, should you add extension points everywhere, all the time? Would this make your code infinitely flexible, or is there a law of diminishing returns that applies?
This is where another principle related to the OCP is of vital importance: protected variation. Alistair Cockburn coined the term:
Identify points of predicted variation and create a stable interface around them.
—Alistair Cockburn, Pattern Languages of Program Design, vol. 2 (Addison-Wesley, 1996)
Somewhat confusingly, the definition references predicted variation, yet the principle itself is called protected variation. However, “predicted variation” is, to my mind, a more accurate term. The two major facets of this definition bear a closer examination.
Predicted variation
The requirements of an individual class should be linked directly to a business client’s requirement. If this link is ignored, there is a risk that the class will not serve any purpose that the business client requested. Over the course of a sprint, user stories are taken from the sprint backlog, and developers and the product owner converse. At this point, questions should be asked as to the potential for future, related requirements. This informs the predicted variation that can be translated into extension points.
A stable interface
Even if you delegate only to interfaces, clients are still dependent on those interfaces. If the interface changes, the client must also change. A key advantage of depending on interfaces is that they are much less likely to change than implementations. If you place the interface in a separate assembly from its implementation, as the Stairway pattern suggests, the two can vary without affecting each other, and the implementation can change without affecting clients.
Clearly, it is very important that all interfaces chosen to represent an extension point should be stable. The likelihood and frequency of interface changes should be low, otherwise you will need to amend all clients to use the new version.
Just enough adaptability
There is a “Goldilocks Zone” where code contains just the right amount of extension points—in the right places—to enable change in areas where it is needed without increasing complexity or over-engineering the solution. For any individual problem, there can be too little, too much, or just enough adaptability.
Programmers who are beginning their careers tend to write code that is quite procedural, even in object-oriented languages such as C#. They tend to use classes as storage mechanisms for methods, regardless of whether those methods truly belong together. There is no discernible architecture to the code, and there are few extension points (and those that exist are misplaced). Any changes to requirements necessitate direct changes to the existing class or classes. This is how the original Trade-Processor was organized in Chapter 5, “The single responsibility principle.” It was a “god object” that had perfect knowledge of everything to do with the program.
However, sometimes, this is the correct solution. If you assess the predicted variation for a small tool such as the TradeProcessor and conclude that it is very unlikely to change in any way, the original version of the code would suffice. Or perhaps the version that was refactored for clarity would be sufficient. The extra time spent refactoring for abstraction is wasted effort if you never make use of the extension points provided. Not only that, but the code is less readable, spread over different files and assemblies, with implementations hidden behind interfaces.
At the opposite end of the spectrum is the programmer who has started abstracting code behind interfaces. This programmer has discovered a new hammer, and now everything looks like a nail. The code produced by this programmer is a mass of extension points, most of which will never be used. A significant effort is required to piece together the code, which constantly delegates responsibilities to interfaces, and a significant effort is required to write this code in the first place.
If these two archetypal programmers—and their code—were combined, the result might be a harmonious middle ground where there are sufficient extension points, but where code can be adapted only in areas where requirements are unclear, changeable, or difficult to implement. This comes with experience, however, and it is difficult to arrive at this Zen-like state of protected variation without first being a naïve beginner and then transitioning to a know-it-all super-abstractor.
Conclusion
The open/closed principle is a guideline for the overall design of classes and interfaces and how developers can build code that allows change over time. With each passing sprint, new requirements are inevitable and should be embraced. Acknowledging that change is a good thing is only part of the answer, however. If the code you have produced up until this point is not built to enable change, change will be difficult, time consuming, error prone, and costly.
By ensuring that your code is open to extension but closed to modification, you effectively disallow future changes to existing classes and assemblies, which forces programmers to create new classes that can plug into the extension points. There are two main types of extension point available: implementation inheritance and interface inheritance. Virtual and abstract methods allow you to create subclasses that customize methods in a base class. If classes delegate to interfaces, this provides you with more flexibility in your extension points by virtue of a variety of patterns.
Knowing that you can integrate extension points into code is not sufficient, however. You also need to know when this is applicable. The concept of protected variation suggests that you identify parts of the requirements that are likely to change or that are particularly troublesome to implement, and factor these out behind extension points. Code can be quite rigidly defined, with little scope for extension or elaboration, or it can be very fluid, with myriad extension points ready to handle new requirements. Either of these options can be correct, depending on the specific scenario and context.