NoSQL For Dummies (2015)
Part VI. Search Engines
Chapter 25. Search Engines in the Enterprise
In This Chapter
![]() Finding unstructured data
Finding unstructured data
![]() Providing a user-friendly search experience
Providing a user-friendly search experience
Providing search engine functionality for your local computer files is easy, and the same is true for adding basic text search to a web shop front end.
Where things start to get really complex is when you try and provide a single search application over multiple sources of information. Not only are the data formats different but also the individual systems are different.
Some data must have text snippets in search results; others need image previews. Each data source displays its own set of facets about its data. Some of these facets (or search fields) may be similar across different systems. The security access rules are also different within each system, requiring a central concept of identity and permissions to map effectively in a search application.
This is why enterprise search — that is, searching across a large enterprise’s information stores — is a difficult problem to solve. However, you can mitigate this complexity in a number of ways.
In this chapter I discuss the unique issues of applying search across a large Enterprise, and making such a complex system accessible to end users.
Searching the Enterprise
Web search engines have long had to index web pages, images, PDF files, word documents, and other formats. As a result, the main issue in enterprise search solutions stems from the differences between source systems’ architectures (the systems where the content resides) and the variety of available data. For example, there is a great variance in the functionality needed to easily collate different data from a range of sources and in how to provide a consistent way to manage the indexes of that data.
In this section, I talk about the variety of systems that typically contain useful data that needs searching, and how to recognize challenges that arise because of the differences in implementation between these systems.
Connecting to systems
As I discuss in detail in Chapter 24, many enterprise search engines provide out-of-the-box connectors for source systems; IBM OmniFind, HP Autonomy, and Microsoft FAST all have connectors for common systems and databases.
These connectors provide an easy way to pull data from many sources into a single repository — there’s no need to code your own integrations. The downside is that these connectors invariably are run on a timed basis; they don’t show the exact live state of all your enterprise’s data, which is very similar to how web search engines work.
In some cases, you may be better off consolidating all your unstructured data in a common database platform. NoSQL document databases are ideal for this situation, because they provide a schema-free way to store data sourced from a variety of systems.
This data consolidation also means you reduce costs by replacing multiple data sources used to power your custom applications with a single enterprise data platform. Another side benefit is that you’re not duplicating the storage of data, unlike traditional search engines where the primary data store’s own indexes are separate from the search engines.
Finally, because a database with search capabilities knows when new data arrives, there’s the possibility of real time, or at least improved latency, between the data and the search indexes.
Ensuring data security
An often overlooked problem is that of mapping different stores’ security models onto a common model used to lock down information in the search application.
A relational database has a very different security model from an enterprise content management system, which in turn differs from a network file share.
Being able to reconcile roles and users in one system with roles and users in other systems is vital to ensuring the security of data. If this is not done correctly, then the best case scenario is that only the existence of a document (for example, its title or source system ID) is revealed in the search results. This is called a false positive because, when users try to access the source document, they’re told they don’t have permission to do so. For high-security systems, you don’t even want users to know the document exists!
Now for the worst case scenario. If someone uses “the right” search words in a query, entire paragraphs of the should-be secured document are revealed in the snippets of the search results! A “snippet” showing text that matches a query may contain 30 words. A user could keep typing the last three words in each snippet to reveal the next 30 words — until the whole document is read!
In an enterprise search application, it’s vital that a standard security model and auditing checks be created and enforced in order to prevent data leakage. To a certain extent, a consolidated single database is easier to secure (if security of records is provided by the database itself) than multiple systems linked to a single search engine through role mappings.
Creating a Search Application
Search has become the default way we all find information on websites. You no longer click through departments and categories on websites to find what you want; instead, you simply type a description of what you’re looking for in a search bar.
Providing a user-friendly search experience, therefore, is vital in ensuring that customers find your products quickly and that the product is right for them, and it helps you in terms of sales.
In this section, I discuss how users access a system, both from an interface usability standpoint and in common search engine features used to aid users in locating the most relevant results.
Configuring user interfaces
Many enterprise search engines provide their own web application for searching through their catalogs. You can configure your application so that it’s branded, and you can design its navigation system according to your website’s user-interface styles and layout.
Some search engines provide widgets — small pieces of JavaScript web application code — that you can embed into your website. This is a good approach if you want fine control over how the site looks, but don’t want to write a search web application entirely from scratch.
Other search engines, especially those embedded within databases, provide an API, which gives you an easy way to access advanced search functionality, without having to create the entire user interface yourself.
However, for complex custom applications, you may have to live with the API approach and writing your own application; otherwise, your website might wind up looking like a competitor’s.
What a good search API gives you
Users don’t just want an empty text field in which to type search text. They need guidance on what terms or phrases to use, and how to drill down into search results. A good search API provides some or all of the following features:
· Suggestions: Phrases or criteria that appear as the user types. The suggestions could be phrases from search indexes or could be based on previous or commonly used search terms.
· Facets: Facets are a listing of fields and the most common values for them from the matching search results. They show values for particular fields in the whole search result (not just the ten results shown in the first page) and how common that value is. Facets are great for narrowing result sets.
· Grammar: A rich default or configurable search grammar that is easy to use and expressive in the ease of control over the search experience that the users have when using it. Here are some examples:
· Double quotes to specify phrases
· AND and OR keywords with parentheses to indicate complex Boolean logic
· The negation character (-) to exclude a search term
· Snippets: For text searches. Snippets are one or more short sections of the matching text with the matching search terms highlighted.
· Similar results: For each search result shown, also listing the three most similar records to this search result.
 Similar result matching is useful for identifying common sets of documents in the results that are closely related by content.
Similar result matching is useful for identifying common sets of documents in the results that are closely related by content.
· Preview: For images or documents. These are previews of the matching image, or document cover, or PDF front page, shown as a thumbnail in the search results.
Going beyond basic search with analytics
Rather than just providing the ten most-relevant search results, it’s sometimes more appropriate to display statistics about the results to the user. The use of facets is the most typical example of returning information about the set of search results. Figure 25-1 shows how Amazon uses snippets to assist in navigation.
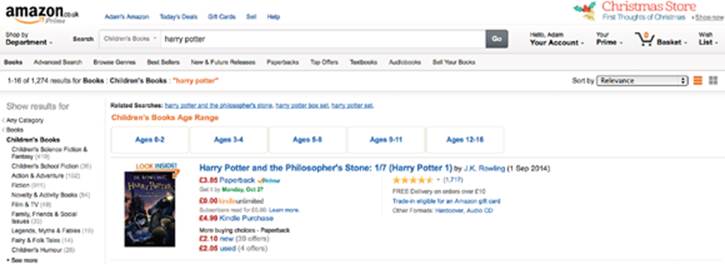
Figure 25-1: Amazon search results showing facets.
As you can see in Figure 25-1, the Children’s Books category facet has many values (ten shown, more available), and each value has a count of the number of results matching. For example, the Children’s Books Science Fiction and Fantasy value with a count of 419 matching search results. These clickable facet values allow users to drill into the datasets.
However, in some search engines, you can configure the preceding mechanism to provide other aggregated statistics for document values. Here are some statistics that you can calculate from facet or other range index calculations:
· Count of the number of results matching a particular facet value.
· Age buckets for children’s reading age groups (refer to Children’s Books Age Range in Figure 25-1).
· Average age of people diagnosed with conditions, grouped by condition name, across a search of medical records.
· Geographic dispersal of search results across a country, typically shown as either a heat map or color-coded counties/states/countries.
· Co-occurrence of different fields in the search results. How often a particular actor is shown in each genre of the search results, for example. This is an example of two-way co-occurrence.
Some search engines support N-way co-occurrences, which is particularly useful for discovering patterns you didn’t know existed. Examples include products mentioned with other products or with medical conditions on Twitter.
All of these calculations are performed at high speeds by accessing just the search indexes. These can be calculated as one of the following:
· Part of the search results (such as for facets or heat maps)
· A separate statistical operation over the same indexes (such as co-occurrence)
A typical way to provide analytics over a dataset is to delegate the responsibility to a business intelligence tool such as Cognos, Business Objects, or Tableau. The problem with these tools is that they typically pull information from the data store and perform analytics over a stored copy of the data. This is called a data warehouse. The problem is that the information isn’t in real time; often it’s updated only once in 24 hours.
If BI tools don’t pull a copy of the data, then performing a wide ranging analysis affects the performance of the underlying database or search engine, which has obvious implications for the cost of hardware and software licenses to provide analytical functionality. Business intelligence (BI) tools typically charge per user, making the cost prohibitive for end-user applications.
Using the built-in analytical capabilities of the database or search engine may be a better solution. Rather than shift vast amounts of data to a BI tool, you perform fast calculations over an in-memory copy of the search indexes.
Doing so enables the support of many users for both search and analytical workloads. Many organizations in financial services and government are looking at NoSQL databases with search functionality to provide near-real-time analytics for their data, without a complex, separate BI or data warehouse infrastructure.