NoSQL For Dummies (2015)
Part VI. Search Engines
Chapter 26. Search Engine Use Cases
In This Chapter
![]() Enabling customers to find your products online
Enabling customers to find your products online
![]() Making best use of all your enterprise’s data
Making best use of all your enterprise’s data
![]() Supporting proactive user working processes
Supporting proactive user working processes
Search applications vary widely both in the kind of information that’s cataloged and in how users interact with search engines. For example, a hotel-booking website differs greatly from eBay’s site, which is different from Amazon’s site. Each use case has its particular features and approaches.
In this chapter, I discuss some aspects involved in providing user-friendly search capabilities in your application and in providing the behavior that you want your application to have.
Searching E-Commerce Products
There is an old adage in sales — “A customer not only needs your product, they need to know that they need your product.” However, the trick is to lead customers not only to the product most relevant to their search terms, but to what they really need.
The simplest form of search is a search of a single-product catalog; for example, searching for printer toner on Amazon.
In this chapter, I discuss how to use a search engine to provide e-commerce website product search capabilities.
Amazon-type cataloguing
Many people, myself included, see Amazon.com as the default place to go when shopping online. Some key features make it the go-to place, and those features have nothing to do with the variety of products available or to Amazon’s size.
Instead, the features are more personal in nature. For example, when I search for a book on a particular topic, Amazon lets me know what other people think about the book and how it compares to similar titles. I also appreciate Amazon’s relevant suggestions based other shoppers’ purchases. (I find this aspect of Amazon’s search technology to be weirdly accurate!)
A list of recommendations isn’t typically what people expect from a search engine interface, but, at its core, recommendations are absolutely powered by search indexes. This search isn’t over the products themselves; rather, the search is of purchases, order history, and products I’ve viewed but not yet bought.
Geospatial distance scoring
Every hotel website of note provides a search-based interface that shows summary information about the hotel and often a map view of the results as well. Positional search functionality is called geospatial search, which I introduce in Chapter 25.
Figure 26-1 shows the trivago website, which is my default site for finding hotel deals. It provides search federation rather than just its own indexes. With search federation, trivago performs a search over a wide range of hotel websites and displays the consolidated result — it does not store the hotel availability information itself, instead asking individual hotel providers’ websites.
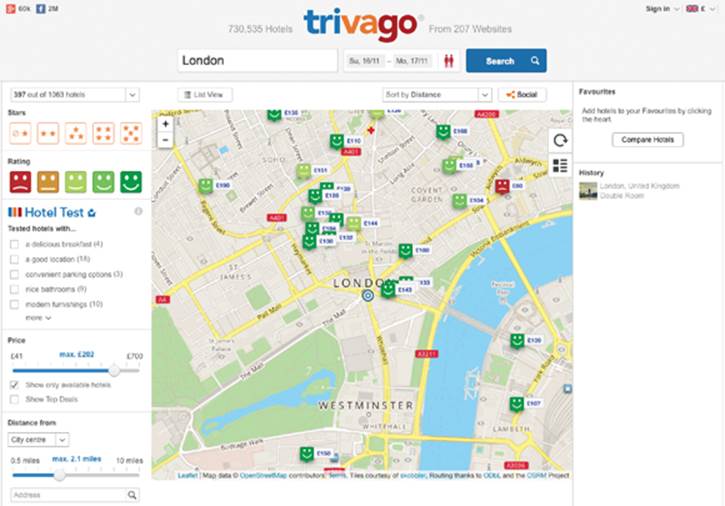
Figure 26-1: Trivago hotel search results ordered by distance on a map.
The interesting thing about the view in Figure 26-1 is that the order of the results is determined not by a field within the hotel’s description, but rather by a value calculated from a difference of the field’s information and my search criteria.
I didn’t ask for just all hotels with positions within a particular area; I asked for the distance from them to a central point to be calculated and used for sorting.
Some search engines go further, allowing you to take this geospatial distance and use it to affect relevancy scoring. I may prefer closer hotels but want this factor weighed against hotels with good ratings. Therefore, the website’s search engine recommends hotels that are further away at a higher relevance if they have substantially better reviews.
Enterprise Data Searching
Being able to bring together disparate types of data while providing a single search interface is the main challenge in enterprise searches.
In this section, I discuss challenges around discovering and providing a consistent search interface over the variety of information stores present in a modern enterprise.
Storing web data
Web data includes the text on web pages, images shown on those pages, and files linked for downloads on those pages. Being able to extract text from web-page markup while preserving paragraphs and concepts of a summary or title are basic features of web search indexers.
Web data also requires that metadata and text be extracted from binary files. Where an image was taken, on what camera, and at what resolution are now common search criteria.
Similarly, being able to extract text from PDFs and Word documents and metadata such as author and publisher is also useful for search applications.
Searching corporate data
Most corporate data is still held on people’s laptops, network file shares, or increasingly in email or instant messages. Understanding the similarities and differences between these types of data is key to creating a user-friendly search experience.
A good example is searching by people. Perhaps it’s an email address within an email, or a person’s full name in the author field of a document, or an employee id in an instant message. Being able to identify all these different sources as the same person is a useful piece of functionality in an enterprise search engine.
As I mention in Chapter 25, reconciling the different data source’s security models into a single search security model and enforcing auditing are essential to preventing unauthorized access to corporate data in a search engine.
Searching application data
Many applications include their own search functionality. You can provide a single search interface for this information in one of two ways. You can
· Consolidate the information, or an extract, in a central search engine.
· Federate the query, effectively performing one query on each of a set of sources and consolidating and interpreting the results, showing one search result set to the user.
Because application versions and functionality change over time, setting up and maintaining a federated search engine is complex. For example, each application provides its own subset of search functionality that may or may not map well onto a central search grammar. You often end up with the lowest common denominator of functionality when implementing search federation.
A consolidated index does cost more in storage, but it allows fine control over what is indexed and which search functionality is exposed to end users. Also, you can consolidate multiple databases into a single data and search platform, which reduces cost when compared to the search federation approach.
Alerting
Users don’t want to waste their time staring at a search interface and pressing the refresh button. Similarly, lengthy, complex business processes that pause while waiting for new content to arrive can be hard to manage.
With search alerts, a search can be saved and actions can be configured to perform useful functionality when new content that matches the search criteria arrives.
In this section, I discuss the various interesting ways that alerting can be used in order to support more proactive and responsive working practices.
Enabling proactive working
Imagine a senior police investigator whose job requires surveillance of all drug-related activity in one area of a city. This investigator can’t be effective if he has to scan through reports and arrests every day. A better route for him is to include specific, related terms in search query over all this content, including, for example, names of organizations and individuals of interest, a geospatial area he works in, crime terms such as drug names, or people’s nicknames.
By saving his exact information query requirements as an alert, the investigator is notified about new, relevant information as it arrives, which shortens the time it takes to react to new information.
Finding bad guys
Using the preceding intelligence-gathering scenario, a long-term investigative officer might be made aware of crucial and actionable intelligence that could prevent a crime. The same mechanism can be used across public data sources. This gathering of information from public sources is called open-source intelligence. Here “open” refers to the fact information is published to the web and requires no special description devices or legal warrants to obtain, and includes mining such sources as Twitter, Facebook, data.gov and other publicly available sources for data of interest.
When new data arrives, the NoSQL database can perform some of the analysis and enrichment functions before adding the data to the search engine’s index and making it available to intelligence officers. This way, the officer doesn’t have to do the enrichment manually, trawling through paragraphs of text and highlighting and tagging key terms and phrases, and he winds up with a rich set of search fields to save for search alerts with minimal human work.
Another example is in a military context. Suppose that, by using alerting, an agent discovers that a person of interest isn’t in the current operation’s targeted area as expected, but in an entirely different location. This information could prevent a failed mission and perhaps even civilian casualties. Moreover, the data could lead to a better use of resources.
In defense and intelligence search use cases, it’s important to combine a range of functions, but especially geospatial search. Knowing where and when things occur is key to planning operations. Also very important are links (relationships) between physical objects, such as people and places, and also intangible objects, such as meetings, organizational hierarchies, and social networks of influence. This emerging approach is called object-based intelligence and includes aspects of full text, geospatial, and semantic (web of facts and relationships) search.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.