Effective MySQL: Backup and Recovery (2012)
Chapter 5. Using Recovery Options
A backup is only as good as the ability to correctly recover and then use your data. A successful recovery is both the verification step of your backup procedures, and the peace of mind for your business sustainability. It is important that you test your entire recovery process from end to end regularly, practicing, verifying, refining, and most importantly, timing. In the event of a disaster after knowing recovery is possible, knowing how long this will take is an important business consideration.
In this chapter we will be covering:
• The different types of MySQL recovery
• Review of the recovery option for each backup type
• The importance of testing and verification
![]()
A Word About Testing
Backups become regular daily operations after initially configured. Recovery is rarely routine; they happen at any time, and generally require immediate action with the quickest response possible to resolve the problem. Testing of the recovery process to ensure that the backups are indeed valid and functional, and that the recovery process is known, documented, and verified, is an ideal practice to master.
This information may sound like repetition, and it is because this is the single most important process not to perform. As a consultant, every disaster engagement involving recovery has been in a situation that the client had not considered, or indeed tested. In many situations these were the common occurrences of the most obvious cases as discussed throughout this book.
A memorable quote found on the Internet regarding backup and recovery is, “Only two types of people work here, those who do backups [and restores] and those who wish they had.”
NOTE There is a common misconception that testing is about ensuring your software works correctly. Testing is really a process for trying to find ways to break your software, and then applying improvements to address these failures. Many testing practices are flawed because this correct approach is not used. The backup and recovery process of a MySQL ecosystem requires the same due diligence. As with many real world life situations, your successes are never publicly applauded; you are remembered by your failures.
![]()
Determining the Type of Recovery Necessary
While you have a backup approach in place, the primary purpose for this is for a full data recovery. Is this necessary to restore production operations in every situation? As described in Chapter 3, the business may accept a certain amount of data loss depending on the total recovery time. A data recovery process may also be necessary for a system crash or corruption and may not require a full restore from backup. This chapter will cover a variety of crash situations and possible recovery requirements.
MySQL Software Failure
The underlying MySQL process mysqld may fail. The following options discuss the primary operations in the event of a MySQL crash. The cause of failure may include a physical hardware problem, a MySQL bug, the process failing due to an exhausted memory or disk resource, or the process being intentionally terminated. For example:

Depending on the storage engine used, no further action may be required to ensure a functioning and accessible database. The MySQL error log will generally provide information about this situation, as described in the following section. However, it is important to determine why this has occurred and to prevent the situation from recurring.
NOTE In a low volume Linux production system you may not detect that MySQL has even crashed unless you review the MySQL error log. Under default operations, the mysqld process will automatically restart through the wrapper daemon mysqld_safe. If your application does not use persistent connections, this can occur without any obvious application effect.
Crash Recovery
When using the InnoDB transactional storage engine, crash recovery is performed after a system failure. This process will detect a difference between the InnoDB data files and the InnoDB transactional logs and perform a necessary roll forward to ensure data consistency if applicable. Depending on the size of your InnoDB transaction logs, that can take some time to complete.
The MySQL error log will provide detailed information of the InnoDB crash recovery when performed.

The InnoDB crash recovery process performs the following specific steps:
1. Detects if the underlying data on disk is not consistent by comparing the checkpoint LSN with the recorded redo log LSN.
2. Applies any half written data pages that were first written to the doublewrite buffer.
3. Applies all committed transactions in the InnoDB transaction redo logs.
4. Rolls back any incomplete transactions.
In addition, during a crash recovery the insert buffer merge and the delete record purge are performed. These steps are also performed in general background operations on a working MySQL instance and are not specific to the crash recovery process.
More recent versions of MySQL have greatly improved the final stage of InnoDB crash recovery when applying the redo log, starting with MySQL 5.1.46 (InnoDB plugin 1.07) and MySQL 5.5.4. In the past, one consideration was to have smaller InnoDB transaction logs due to possible long recovery time. For more information on the specific improvement see http://blogs.innodb.com/wp/2010/04/innodb-performance-recovery/.
Testing InnoDB Crash Recovery
Testing of InnoDB crash recovery on a loaded system is important to determine if this process completes in a few minutes or can take more than one hour.
Additional information about steps to undertake when MySQL is crashing can be found at http://ronaldbradford.com/blog/mysql-is-crashing-what-do-i-do-2010-03-08/ and http://ronaldbradford.com/blog/how-to-crash-mysqld-intentionally-2010-03-05/.
TIP Testing a crash recovery of MySQL is as simple as executing a kill -9 on the mysqld process.
Under normal circumstances when MySQL is stopped correctly, InnoDB crash recovery is not needed. However, as part of starting MySQL you should always check the error log. In this example, while MySQL was stopped gracefully, the error log shows crash recovery was always being performed. As the data set was small (< 1GB) the client was assuming the extended startup time was normal.
Shutdown log information:

Startup log information:

Monitoring InnoDB Crash Recovery
Monitoring the amount of recovery is possible if existing MySQL monitoring includes regular logging of the SHOW ENGINE INNODB STATUS information. The LOG section provides the Log Sequence Number (LSN) position. This can be compared with the reported LSN in the MySQL error log during a crash recovery. This information is also useful for general monitoring of internal InnoDB operations and should be part of proactive administration of any production system.
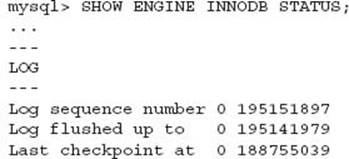
Chapter 7 will discuss advanced techniques diagnosing and correcting an InnoDB crash recovery when this process fails. This is generally required when there is additional corruption of the InnoDB data and transaction log files.
MyISAM Table Recovery
When using the MyISAM storage engine, the default engine for all MySQL versions prior to MySQL 5.5, crash recovery, if necessary, is generally a manual process. Detection of possible corruption can also be more complex. This is because there may be no advance notification until a corrupt MyISAM table is accessed via an index.
A problem can be detected with the CHECK TABLE or myisamchk -c command; however, this is impractical in a large database, as this operation can take a long time to determine if a problem exists. When MySQL does detect a problem, the MySQL error log will report a problem requiring further attention. For example:

Alternatively you may see an error such as:
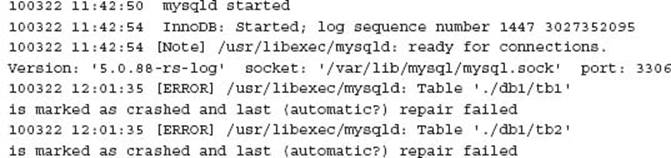
NOTE Data for a MyISAM table (the .MYD file) is always flushed to disk for each DML statement. The error message actually references that the underlying B-tree index (the .MYI file) is inconsistent with the data. The MyISAM recovery process is the rebuilding of the indexes for a given table. This helps with the understanding that the reporting of a MyISAM table as crashed may not occur at system startup, rather when the table data is accessed via a given index.
The MySQL configuration variable myisam-recover can help in some situations where the MySQL process will attempt MyISAM crash recovery. The recommended settings are:
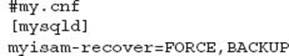
TIP The myisam-recover configuration option can offer some crash safe properties for MyISAM tables.
Chapter 7 will provide more information on managing MyISAM crash recovery.
Other Storage Engines
MySQL offers a number of additional default storage engines as well as third party pluggable engines. The following list provides a summary of recovery capabilities of popular engines.
Included Default Engines
|
Storage Engine |
Recovery Considerations |
|
ARCHIVE |
NONE |
|
MERGE |
The MERGE storage engine is actually a meta-definition of multiple underlying MyISAM tables. This results in the same recovery issues as detailed for MyISAM. |
|
BLACKHOLE |
This storage engine actually stores no data so recovery time is immediate. The data, however, was lost at insertion time, as the statements or blocks are only logged to the binary log. |
|
MEMORY |
As the name suggests, this storage engine does not persist data. After a crash recovery no data recovery is possible. |
Popular Third Party Engines
|
Storage Engine |
Recovery Considerations |
|
Percona XtraDB |
This fork of the InnoDB storage engine is identical in operation to InnoDB auto-recovery. |
|
Tokutek TokuDB |
TokuDB provides a full ACID compliant auto-recovery storage engine. |
|
Akiban AKIBANDB |
AKIBANDB provides a full ACID compliant auto-recovery storage engine. |
|
Schooner SQL |
Schooner SQL provides a full ACID compliant auto-recovery storage engine. |
This is not a full list of MySQL storage engines. You should refer to the individual storage engine vendors for specific crash recovery details.
Table Definition Recovery
For every table in a MySQL instance, regardless of storage engine used, there is an underlying table definition file, represented by a corresponding .frm file. There are circumstances where these files may become corrupt or inconsistent with a storage engine’s additional table meta-information. For example:
![]()
and
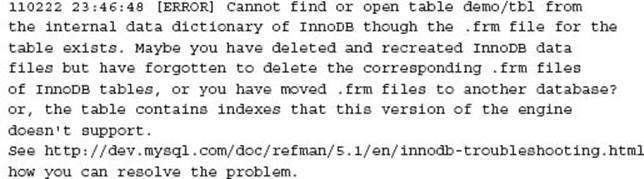
and
![]()
This may require a different approach to obtaining this file and the matching data depending on the type of error.
NOTE An unexpected MySQL restart has an additional impact on performance. The primary memory buffers including the InnoDB buffer pool and the MyISAM key cache are empty. These must be re-populated when data is requested, causing additional disk I/O. Internally, MySQL does not store statistics for InnoDB tables, and these have to be re-calculated when tables are first accessed.
![]()
Performing a Static Recovery
The performing of a static recovery involves a number of clearly defined steps independent of the type of backup option used. These steps are:
1. Necessary software requirements
2. Static data recovery
3. Data verification
4. Point in time recovery (if applicable)
5. Data verification
MySQL Software Installation
The recovery of, and use of, recovered MySQL data are not possible without a functioning MySQL installation. Chapter 2 does not describe in any detail the various approaches for managing the MySQL software. It is beneficial in a disaster recovery situation to minimize risk by using the same version of MySQL, installed via the same procedures—for example, via system packaging or binary distribution—and placing all important MySQL components in the same directory structures.
The use of automated installation and deployment tools can ensure a repeatable approach to MySQL software management. Popular runtime configuration management tools include Puppet, Chef, and CFEngine. These tools can ensure the current MySQL configuration is available before a restore process.
MySQL Configuration
It is important that the MySQL configuration is in place before a data recovery process begins when performing a SQL restore. Important global memory settings, including the innodb_buffer_pool_size and key_buffer_size, are critical for efficient data recovery via SQL execution. Depending on the memory usage of the machine and normal database concurrency, you could choose to adjust these values to utilize as much system memory as possible during recovery.
CAUTION If the physical hardware used for a database recovery does not match the hardware source of the MySQL configuration, it is possible the configuration may cause MySQL to fail to start or not operate optimally.
You may also elect to optimize or adjust the configuration during the recovery process. If the server uses binary logging with the log-bin option, disabling this will aid in the reloading of data via a SQL file for a static backup and point in time recovery. Altering the InnoDB transaction logging with innodb_flush_log_at_trx_commit and sync_binlog can also reduce some disk I/O during a data restore.
Depending on the recovery process used, you should also disable any replication with the skip_slave_start option.
Alternatively, disabling the query cache with query_cache_type=0 and disabling external network access with skip_networking are common additional steps that can make a small improvement as well as restrict unwanted access during the recovery time. The init_file and init_connectoptions may also include steps that should be disabled during the recovery process.
It is critical that the application is disabled from accessing data during the restore process, especially if some important settings for data integrity are altered. The verification process would also require the correction and restarting of the MySQL instance with the correct configuration before application access is permitted. Restriction processes may include skip_networking as mentioned, firewall rules to restrict external access to the MySQL TCP/IP port, normally 3306, or changing the MySQL user privileges to deny SQL access.
CAUTION Removing external access during a database restore by enabling skip_networking does not stop any batch or cron jobs that are executed on the local machine. These may affect the data restore process. It is important you know all data access points when performing a database restore.
MySQL Data
The restore of MySQL data will depend on the backup approach used. Using the backup approaches defined in Chapter 2, we cover each option.
Filesystem Copy
A cold filesystem copy or file snapshot restore is the installation of all MySQL data and configuration files. This has to be performed when the MySQL installation is not running. It is important that the MySQL configuration is correctly restored to match the copied files, as several parameters will cause MySQL to fail to start correctly, or may disable important components, for example, the InnoDB storage engine. For example, any change in the file size with the innodb_data_file_path and innodb_log_file_size configuration settings will cause InnoDB not to be enabled or may stop the MySQL instance from starting.
SQL Dump Recovery
A SQL dump recovery requires a correctly configured, running MySQL installation. The restore uses the mysql command line client to execute all SQL statements in the dump file. For example:

This example syntax requires the dump file to include necessary create database schema commands. These are included by default with mysqldump when using the --all-databases option to create the backup. The backup file will include the following syntax, for example:
![]()
If you dump an individual schema with mysqldump this is not included by default. The --databases option is necessary to generate this SQL syntax within the backup file.
By default, mysqldump will not drop database schemas. To include this syntax to enable a clean restore for a MySQL instance when existing data may be present, use the --add-drop-database option.
The restore of a mysqldump generated file is a single threaded process. Some benefit may be obtained by multi-threading this process; however, this requires a means to create parallel files and monitoring of resources for any bottlenecks. Chapter 8 will discuss a number of options for considering a more optimized recovery approach.
The use of per table dump files, particularly in a known format, may be significantly faster to load using the LOAD DATA statement rather than individual INSERT SQL statements generated by mysqldump. There is a trade-off between the complexity to generate these files consistently, the additional scripting for restoring data, and point in time recovery capabilities. Chapter 8 will discuss situations when using the per table dump approach can speed up data access during a recovery procession.
For more information on all possible options with the mysqldump command, refer to the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/mysqldump.html.
SQL Dump Recovery Monitoring There is no easy means of determining where the database recovery process is or how long the process will actually take; however, there are several tricks that can be used to view the recovery process. There is no substitute for testing and timing the recovery process to have an indicator of the expected time. This will change over time as your database grows in size.
You can use the SQL statement being executed, as shown by the SHOW PROCESSLIST command, to determine how much of the mysqldump file has been processed. You can compare this line with the total number of lines in the dump file. This can provide a rough approximation.
Recording table sizes and row counts in a daily audit process will greatly assist in calculation of the approximate table size. This can be easily determined via the INFORMATION_SCHEMA. For example:

NOTE Depending on the type of storage engine, some information provided by this SQL statement is only an estimate. For example, with the InnoDB storage engine, the data and index size information are accurate; the number of rows is only an estimate.
Including this information with the backup process is of benefit for later analysis and verification.
MySQL Enterprise Backup (MEB) Recovery
The restoration of a static backup from MEB is a simple command. It is necessary to perform some prerequisite steps to ensure a successful restore.
• Stop the MySQL instance.
• Remove any existing data directory.
• Create a clean data directory, or enable permissions for the user to create the data directory.
• Run mysqlbackup copy-back.
For example:


When MySQL is restarted the following messages may occur. This is expected:
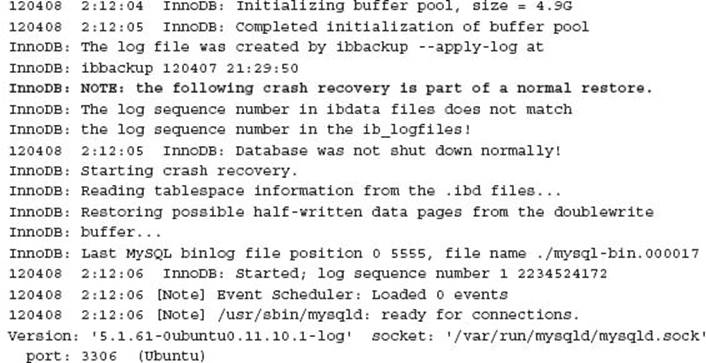
CAUTION The current MEB version 3.7.0 requires the specification of the innodb-log-files-in-group configuration variable to operate correctly. If this is not defined in your MySQL installation, this must be specified on the command line.
Generally the MySQL data directory is owned by the mysql user; however, the parent directory does not provide sufficient permissions to create. If the directory is removed, the following error may occur:
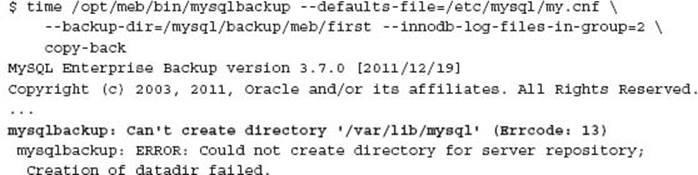
MEB does not perform any of the pre-checks as noted in these instructions. MEB can perform a successful recovery with a running MySQL installation; however, this will not produce the results you would expect. Chapter 7 provides an example of the level of inconsistency and errors that occur.
CAUTION MySQL Enterprise Backup does not perform any checks on whether MySQL is running, or whether the existing data directory exists. While a restore may complete successfully, this will cause an inconsistency and possible errors.
XtraBackup Recovery
The XtraBackup restore process is a simple command. XtraBackup also requires several prerequisite steps. The XtraBackup was created with the commands:

Before restoring an XtraBackup you must first stop MySQL, and you must ensure the existing data directory exists and is empty. XtraBackup will not check that MySQL is not running. Common errors are:
![]()
and
![]()
The restore is a single command:
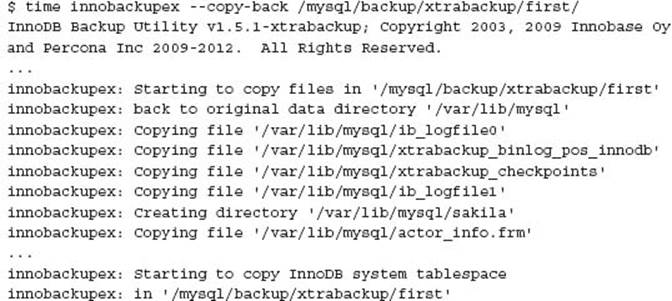
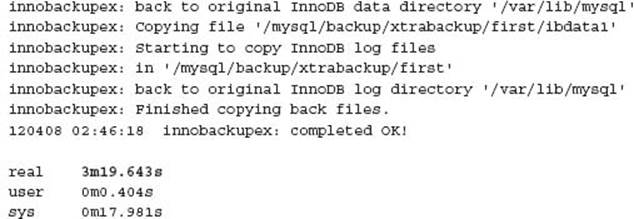
It is important to check the file and directory permissions after the Xtra-Backup restore. In the previous example performed by the root OS user, starting MySQL would result in an error similar to:

Innobackupex has a lot of verbose information, but no message at the end stating that permissions should be set. The following is required to correctly start MySQL following an XtraBackup restore with the root OS user:
![]()
More information on XtraBackup recovery options is available in the documentation at http://www.percona.com/doc/percona-xtrabackup/.
Chapter 8 will discuss more advanced XtraBackup options including streaming, compressing, filtering, and parallel operations.
XtraBackup Manager The XtraBackup Manager (XBM) project provides additional wrapper commands and database logging for XtraBackup. This is written in PHP. See http://code.google.com/p/xtrabackup-manager/wiki/ QuickStartGuide for detailed instructions in getting started.
![]()
Performing a Point in Time Recovery
Regardless of the static recovery approach used, a point in time recovery is the application of MySQL master binary logs from the time of the backup, to a given time, generally all possible data. A point in time recovery can also be performed to a particular time or binary log position if necessary.
There are two mechanisms for using the master binary logs; these depend on the use of the restored MySQL environment in relation to MySQL replication. If the server is standalone, the extraction of SQL statements from the binary log and application via the mysql command line client is performed. If the server is a slave in a MySQL topology, the replication stream can be used to perform this automatically, levering the binary logs that exist on the MySQL master.
Both options require the correct position and corresponding binary log for a successful recovery.
Binary Log Position
The current position at the time of the database backup is necessary to apply binary log statements.
Using mysqldump
With mysqldump, the use of the --master-data on the master server, or --dump-slave on the slaver server, will generate the following SQL statement with the output:

The referenced information will be used in later examples.
By default the CHANGE MASTER TO statement is applied during the data recovery. If a value of 2 was specified for either of these options, for example, --master-data=2, then this SQL statement is only a comment and must be manually applied during the recovery process. For older style backup approaches, the CHANGE MASTER syntax can be generated via the SHOW SLAVE STATUS output.

Filesystem Copy or Filesystem Snapshot
Depending on the other backup approaches used, the position is held in the underlying master.info file and will be defined when the data is restored via a filesystem approach.
MySQL Enterprise Backup (MEB)
MySQL Enterprise Backup has this information in the meta sub-directory of the backup. For example:
![]()
XtraBackup
XtraBackup has this information in the backup directory. For example:
![]()
Standalone Recovery
Following a successful static recovery, the application of the MySQL binary logs requires the use of the mysqlbinlog command to translate the information into SQL statements that can be applied by the mysql command.
Using the details of the master position as shown in the previous CHANGE MASTER example, we know the binary log file is ‘mysql-bin.000146’ and the position is 810715371.
![]()
It is likely additional binary log files are also required for a point in time recovery to the most current transaction.
![]()
NOTE A trick with managing the binary logs is to perform a FLUSH LOGS command during the backup process. This produces a new binary log file at the time of the backup, and can reduce the complexity necessary to determine the start position with binary logs to be applied.
You can also use the mysqlbinlog command to retrieve selected SQL transactions for a more specific period via time or position using the --start-datetime, --stop-datetime, --start-position, and --stop-position options, respectively. These options can be used to perform a point in time recovery to a date or position before the end of the binary log, generally to undo a human generated data error such as an accidental deletion of data. These options are particularly beneficial for data analysis of a binary/relay log when an error has occurred.
Analysis of the binary log using an unknown start position or unknown end position can result in misleading information. The following shows an error in processing the binary log; however, this not a result of the contents of the actual binary log:
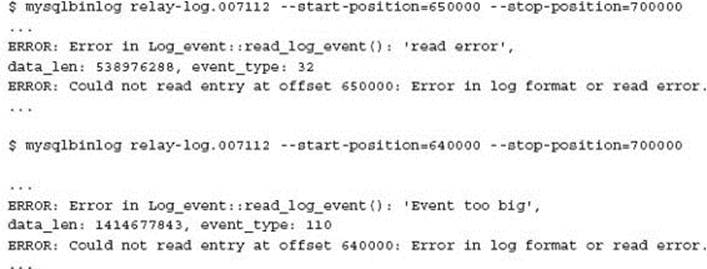
When using correctly aligned event boundaries, no error occurs.
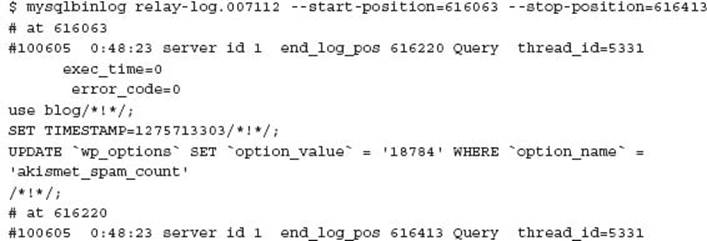

For more information on the full options for the mysqlbinlog command refer to the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/mysqlbinlog.html.
Leveraging the Replication Stream
If the server is the slave of an existing and functioning MySQL master within a replication topology, the normal replication stream can be leveraged providing the position of the master binary log is correctly defined for the slave. Depending on the data backup and static recovery process, this may or may not be already defined for the recovered data.
When using the --master-data or --dump-slave option you will observe in the mysqldump output file a CHANGE MASTER statement that will set the correct position. If using the output information from a SHOW SLAVE STATUS command you can construct the correct syntax as shown in the previous section.
Following this command you should run SHOW SLAVE STATUS in order to verify settings, then START SLAVE to start processing the replication stream. You should review the SHOW SLAVE STATUS output a second time for any errors including invalid permissions and other errors. The following is a command error:
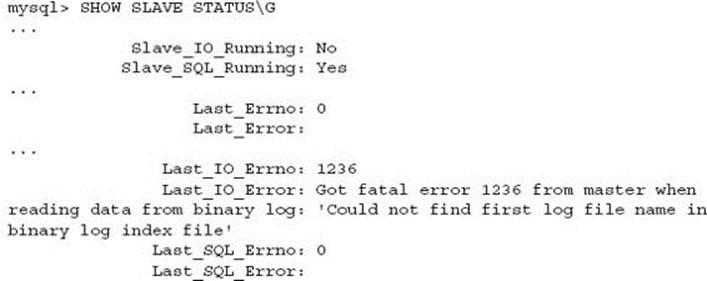
This shows that the master no longer has the required binary log files necessary to replay all SQL statements via the replication stream.
For more information about the SHOW SLAVE STATUS command, refer to the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/mysqlbinlog.html.
Binary Log Mirroring
A new feature of the current 5.6 DMR version is the ability to read the binary logs of a remote system, rather than having to copy the binary logs to process. In addition, a new option is also provided to read a remote binary log and produce an exact copy in binary format. This feature can also allow for binary log mirroring.
The --read-from-remote-server option tells mysqlbinlog to connect to a server and request its binary log. This is similar to a slave replication server connecting to its master server. The --raw option produces binary output, and the --stop-never option enables the process to remain open and continue to read new binary log events as they occur on the master. For example:
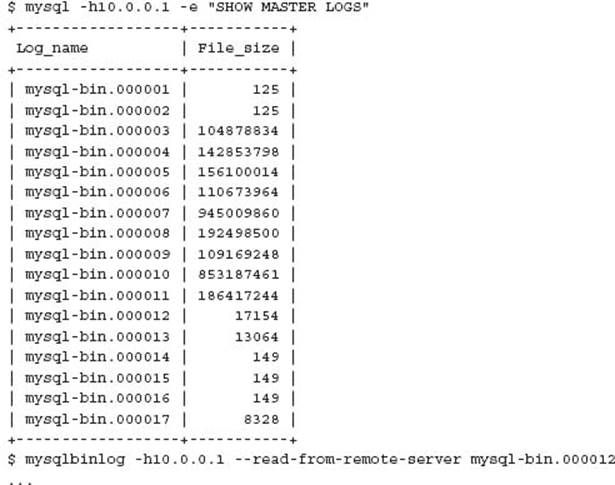
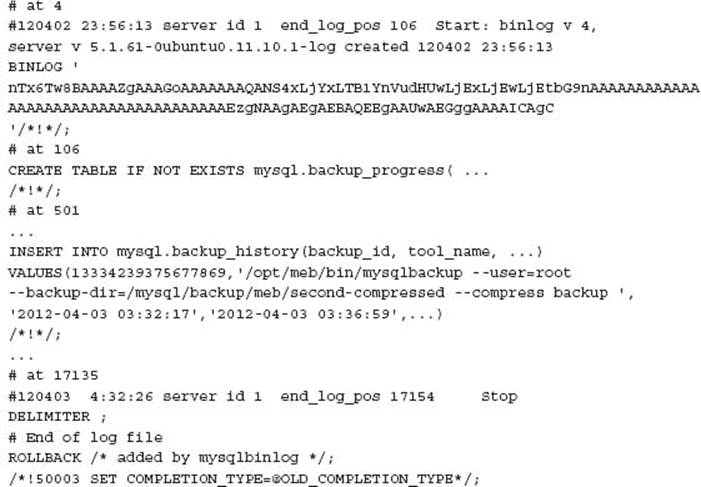
You can produce a copy of the master binary log with:

You can also obtain content from all binary logs from a given file with:
![]()
Analysis of the output provides the following to see the change in filenames:
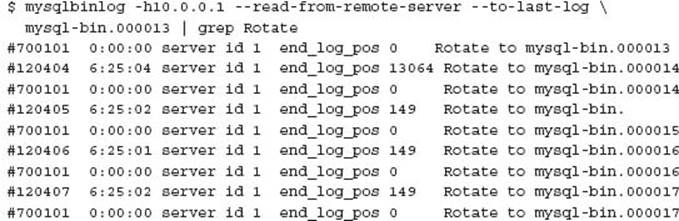
TIP Even if your production environment is not running MySQL 5.6, you can install this MySQL version on another server and use these commands connecting to an older server version, as shown in these examples connecting to a MySQL instance running MySQL 5.1.
For more information see http://dev.mysql.com/doc/refman/5.6/en/mysqlbinlog-backup.html.
![]()
Recovery Verification
The successful recovery of a MySQL environment is not complete until verification is performed. This can be difficult to determine as the various reasons for requiring a recovery may affect the ability to calculate verification results.
The checking of applicable restore command(s) error status, log files, and MySQL error log is a mandatory initial step. While this appears obvious, this author has experienced DBA resources not performing this most basic of steps, so this is mentioned for completeness.
The first obvious data check is to look at the size of your database. This can be as simple as an INFORMATION_SCHEMA query. While this step is not a confirmation of success, this will confirm no obvious import or restore failure. This can indicate no more time consuming validation is required when a failure is immediately detected. This check can be performed after both the static recovery and point in time recovery steps. It is important to also check the number of database objects, including tables, routines, and triggers, in a similar fashion.
The second check is to confirm a likely most recent transaction. This could be as simple as looking at the last order, status update, or log entry in a given table. When your system performs hundreds of INSERT or UPDATE statements per second and there is a recorded insert or update timestamp or AUTO_INCREMENT primary key, there is an easy comparison of the last reported database modification. Again, this check is not a confirmation of success, rather an indicator of obvious failure or highlighting of potential or expected data loss. This can be performed after both the static recovery and point in time recovery steps.
When a complete point in time recovery process is performed, the reported binary log position from SHOW SLAVE STATUS can be verified with the applicable master binary log position, recorded as part of the backup, the current file size of the last imported binary log, or the current SHOW MASTER STATUS information.
The most conclusive agnostic approach is to perform a table checksum to compare the actual data. The CHECKSUM TABLE command or the Percona Toolkit pt-table-checksum utility can be used. This is impractical in a large database due to the time to read all data to calculate. It may be practical only to check certain tables with this detailed analysis. A more simplified check of the number of rows, or sum of an important column, for example, and order table invoice amount can provide an initial check.
With all these steps, data verification is generally complex because the restored data source cannot be accurately compared with an active and ever changing production environment. Given this situation and knowing these limitations, adding additional checks during the backup process can be critical in reducing risk. By recording a checksum, count, sum, or some other calculation on the database at the time of a static backup, an applicable check can be made after the static recovery step.
Using the same data checksum approach for the schema definition and all stored routines and trigger code is also highly recommended. See Chapter 4 for examples on data and object consistency.
The importance of database verification is to detect any problem before it becomes a real issue. If data is lost or incomplete further application use may compound this problem; a database recovery may not be possible in 12 hours’ time. Difficult and time consuming data analysis may then be needed to address any data corruption, loss, or creep.
Important business metrics are generally the first indicator of a likely problem. The amount of verification is proportional to the important value of the data. It may be critical to ensure that all data is consistent for customer orders, and less important for a review of a product, for example.
During the verification process application access to the underlying database should never occur. It is very important this step is adequately catered for during the recovery process. This is often overlooked when a full end-to-end test is not performed. After any disaster it is advisable to perform a backup as soon as possible.
![]()
The Backup and Recovery Quiz
In response to several organizations failing to have applicable production resilience the following checklist was created in early 2010 to poll what procedures existed.
1. Do you have MySQL backups in place?
2. Do you back up ALL your MySQL data?
3. Do you have consistent MySQL backups?
4. Do you have backups that include both static snapshot and point in time transactions?
5. Do you review your backup logs EVERY SINGLE day or have tested backup log monitoring in place?
6. Do you perform a test restore of your static backup?
7. Do you perform a test restore to a point in time?
8. Do you time your backup and recovery process and review over time?
9. Do you have off-site copies of your backups?
10. Do you back up your primary binary logs to a different server?
This is not an exhaustive checklist of all requirements, only the first ten items necessary for ensuring adequate minimal procedures. If you do not score eight or better in this checklist for your business, you are at higher risk of some level of data loss in a future disaster situation. If you are an owner/founder/executive this should keep you awake at night if you are not sure of your business viability following a disaster.
Source: http://ronaldbradford.com/blog/checked-your-mysql-recovery-process-recently-2010-02-15/
![]()
Other Important Components
This chapter has discussed the recovery of MySQL software, configuration, and data. This is the primary purpose of this book. Any operational production database system generally includes much more than just MySQL software and data. While not discussed it is important that as a database administrator, any additional database and system related features are included in a total backup solution. For example:
• Cron job entries
• Related scripts, run via cron, via batch or manually
• Application code
• Additional configuration files (e.g., SSH, Apache, logrotate, etc.)
• System password and group files
• Monitoring scripts or monitoring plugins
• Backup and restore scripts
• Any system configuration files (e.g., /etc)
• Log files
![]()
Conclusion
Your business viability and data management strategy are only as good as your ability to successfully recover your information after any level of disaster. In this chapter we have discussed the essential steps in the process for a successful data recovery and the importance of data verification.Chapter 7 will extend these essential foundation steps with a number of disaster scenarios to highlight further advanced techniques in ensuring an adequate MySQL backup and recovery strategy. Chapter 8 provides more examples of recovery options for various advanced backup options.
The SQL statements and web links listed in this chapter can be downloaded from http://effectivemysql.com/book/backup-recovery/.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.