Effective MySQL: Backup and Recovery (2012)
Chapter 4. Using MySQL Replication
The use of MySQL replication is instrumental in many practical MySQL environments and is generally considered as a primary backup and first viable fail-over option in a higher availability environment. Under normal operating conditions, MySQL replication may be sufficient; however, there are a number of limitations that must be carefully confirmed and verified for replication to be part of a valid backup and recovery strategy. As discussed in Chapter 3, a backup and recovery strategy is critical for ensuring business continuity and meeting the needs of system availability.
In this chapter we will be covering:
• Using replication for backups
• Various replication limitations that can affect backups
• Additional considerations with your backup approach
![]()
MySQL Replication Architecture
To understand the features and limitations of MySQL replication for any applicable backup method, it is important to understand the basic mechanics between a MySQL master and slave.
As outlined in Figure 4-1, the following are the key steps in the success of a transaction applied in a MySQL replication environment. This is not an exhaustive list of all data, memory, and file I/O operations performed, rather a high level representation of important steps.
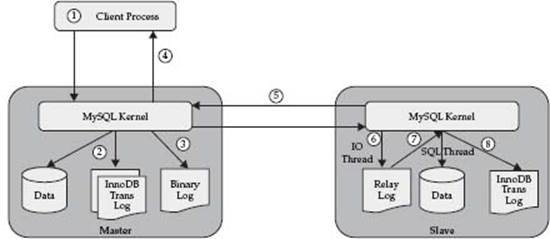
Figure 4-1 MySQL replication workflow
• A MySQL transaction is initiated on the master (1).
• One or more SQL statements are applied on the master (2). The true implementation of the physical result depends on the storage engine used. Generally regardless of storage engine, the data change operation is first recorded within the applicable memory buffer. For InnoDB, the statement is recorded in the InnoDB transaction logs (note that InnoDB data is written to disk by a separate background thread). For MyISAM, the operation is written directly to the applicable table data file.
• At the completion of the transaction, the master binary log records the result of the DML statement(s) applied (3). MySQL supports varying modes that may record the DML statement or the actual data changes.
• A success indicator is returned to the calling client program to indicate the completion of the transaction (4).
• The slave server detects a change in the master binary log position (5).
• The changes are received (i.e., a pull process) by the slave server and written to the slave relay log by the slave IO thread (6).
• The slave SQL thread reads the relay log and applies all new changes (7 and 8). These changes may be recorded as a statement to be executed, or as a physical row level data modification.
• A success indicator is returned to the slave replication management.
In summary, the SQL transactions are recorded in the master binary log and the change of this log is used as a triggering event for the slave to pull the change. Chapter 2 discussed more information about the operation of the binary log. In Chapter 5, the point in time recovery section provides detailed information on how to review and analyze the master binary log.
MySQL Replication Characteristics
The following are important characteristics of the MySQL implementation of data replication that can impact a backup and recovery strategy:
• Each MySQL slave has only one MySQL master.
• A replication slave pulls new information from the master.
• MySQL replication by default is an asynchronous process (*), i.e., a master does not wait for acknowledgment or confirmation from a slave for a completed and successful transaction on the master.
• A MySQL slave can also be used for read operations, or additional write operations if configured.
• MySQL does not require a slave to be identical to a master. Tables could be stored in a different storage engine or may even contain additional columns. Providing the SQL operation completes without error, replication will not fail.
(*) MySQL 5.5 provides support for semi-sync replication, which is discussed in a following section.
CAUTION Using MySQL replication for high availability (HA) does not imply you now have a disaster recovery (DR) solution. A MySQL slave may be configured to not include all data on the master or be configured with a different schema structure. While a MySQL slave may include all data, the process of promoting a slave from a read only status, reconfiguring your application to use this slave, and altering other operations designed for the slave are all steps in ensuring a functional DR plan.
MySQL replication generally exists in a production environment to support scalability, data redundancy, and high availability. These architectural features provide an immediate and viable approach as a backup and recovery strategy option. By combining MySQL replication with the various backup options described in Chapter 2, several problems including locking and availability of the production database can now be avoided.
![]()
MySQL Replication Limitations
MySQL replication is not without issues; there are some key limitations for using replication effectively and these can affect a functional database backup and recovery strategy.
Replication Lag
One of the primary issues with a MySQL topology is replication lag. Replication lag can have a significant effect on an up to date backup and on an application that uses replication for read only workloads. The asynchronous nature of MySQL replication implies that a difference between the data on a master and slave is possible at any point in time.
You can determine all information about MySQL replication including lag with the SHOW SLAVE STATUS command on a MySQL instance that is a MySQL slave:
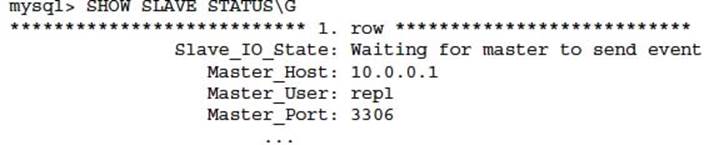
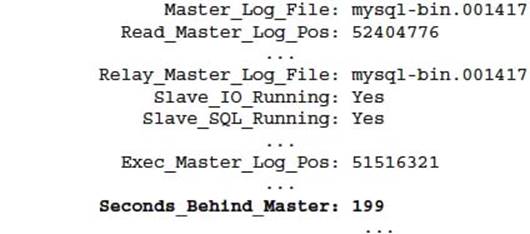
Replication lag is determined by a non-zero number in Seconds_Behind_Master. This number does not represent the actual number of seconds it will take replication to catch up. Seconds_Behind_Master displays the time difference between the local time on the slave against the time stamp of the replication event applied on that master and that is currently being processed by the slave SQL.
Replication lag has several causes:
• The volume of concurrent SQL statements performed on a multithreaded master exceeds the capacity of the single replication IO and SQL threads to process. A high volume production system with an increase of 5 to 10 percent is enough for replication lag to occur and never catch up.
• A DML or DDL statement that takes a long time to execute. As replication is single threaded, subsequent pending statements are further delayed. A good example is an ALTER TABLE statement.
• Replication stopped due to a specific error. The problem was subsequently addressed and replication restarted; however, replication lag now exists.
• MySQL replication supports both local area network (LAN) and wide area network (WAN) connectivity. The use of a slow network with inconsistent transaction throughput or selective connectivity can contribute to lag.
• Replication may be stopped intentionally, for example, a MySQL backup, software upgrade, or a delayed replication implementation.
• Lag can also be the result of a nested replication topology. This can be difficult to correctly determine that the master is indeed a slave of another instance.
NOTE It is important to monitor MySQL replication lag to detect and report an increase over time, as this is an indication that replication may not catch up.
Consistency
It is possible for both the data and schema of a MySQL slave to be different from the applicable MySQL master and replication is operating without errors and/or lag. This is due to the flexibility of a MySQL slave not to be a true read only version of a given master, and the per statement execution of any given SQL statement that can complete without error yet still perform more or less data manipulation than on the master.
A MySQL slave can have different table structures including a change in storage engine and indexes and still support the primary function of executing a successful SQL statement. For example, it is common for a scale-out read architecture to have differing indexes to support SELECT optimizations. A change in table structure does not necessarily mean the data is inconsistent.
There are several basic settings that can be used to limit and/or check schema and data consistency.
Data Consistency
Under normal circumstances the slave should be read only to ensure data consistency. This is enabled with the MySQL configuration option read_only=TRUE. This is an important setting to minimize data manipulation on a MySQL slave when a user connects accidentally or intentionally to a MySQL slave and executes a DML or DDL statement. This will result in the slave having different data or schema structure than the master and may cause future replication errors. Any user connecting to the MySQL slave with the SUPER privilege can override this setting, so it is important to also restrict user permissions accordingly. The slave-skip-error option can also cause inconsistency where these listed errors will not result in a replication failure.
CAUTION A MySQL slave that does have a read_only=TRUE configuration and has application user access with the SUPER privilege can easily lead to inconsistent data between a master and a slave.
The use of MySQL triggers and stored procedures may cause inconsistency if any database object definitions differ between the master and the slave.
MySQL replication does not currently provide a checksum of the events recorded in the binary log. There are very isolated situations when corruption from related hardware and network situations may cause a replication error producing a data inconsistency. The current development release of MySQL 5.6 includes the new -binlog-checksum, --master-verify-checksum, and slave-sql-verify-checksum options. More information can be found at http://dev.mysql.com/doc/refman/5.6/en/replication-options-binary-log.html.
The CHECKSUM TABLE command enables you to determine a CRC-32 checksum of all rows in the table. As this reads all rows, different versions of MySQL and even storage engines will produce a different result while the data may actually be identical.
The practical use of CHECKSUM TABLE in a highly concurrent master/slave environment is limited as it is necessary to ensure a precise comparison at the same point in time within the execution of statements. This command does not have a SQL equivalent syntax to inject within the replication stream. In a low volume environment this command may easily produce a confirmation that tables are identical. When tables do differ, use a read lock with LOCK TABLE <tablename> READ to obtain a more consistent version. This command does read all rows of a table, so for very large tables this may take a significant time to execute.
The MySQL Reference Manual does state that due to the hashing approach it is not guaranteed two tables of differing data may result in the same value. This is true for many hash algorithms. What is important is that using a checksum approach is far more important than assuming your data is consistent following any type of replication error.
The Percona toolkit pt-table-checksum utility available at http://www.percona.com/software/percona-toolkit/ is an open source tool that can be used for the consistency checking of table data, providing various algorithm options and built-in replication support. This tool replaces the original Maatkit mk-table-checksum utility. This tool can be difficult to understand and operate, as the documentation is not written to be user friendly. The following instructions will provide a simple to use example providing the necessary Perl DBI and DBD::mysql dependencies are already installed.

A quick explanation of the options used:
• --algorithm This defines the algorithm to use for the table checksum. The most command and useful values include CHECKSUM, BIT_XOR, and ACCUM.
• --ask-pass Prompts the user to specify the user account password.
• --replicate This specifies the schema.table where checksum information is stored to support replication comparison.
• --create-replicate-table This option pre-creates the checksum table if it does not exist.
• --databases This defines the schema(s) to perform a checksum for.
When combined with the following SQL query executed on all slave servers, it is possible to detect any data drift and inconsistency between a master and a slave.
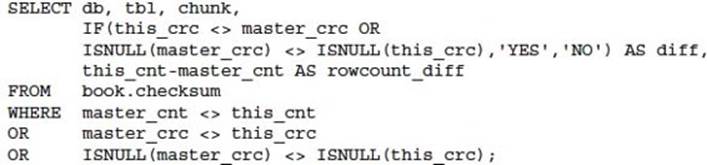
The execution of this utility can have a significant performance overhead on a large database. This utility has many different options including different algorithm selections and determining chunk sizes for data. Refer to the documentation at http://www.maatkit.org/doc/mk-table-checksum.html for more information. Please note that this utility is no longer active as an open source project; however, this is still widely used among the MySQL community. The corporate sponsored Percona toolkit product contains current work.
Schema Consistency
The layman’s approach to detecting schema differences is to use the mysqldump utility and to generate the schema only and compare. For example:

This process is not ideal as there is no guarantee the output is ordered, and the format does differ between MySQL versions; however, this process can be used to confirm that no schema differences exist. In a high volume production system, the additional pruning of AUTO_INCREMENT=N from the CREATE TABLE statement is necessary to produce a clean comparison of the schema only. The following syntax can be added to the previously mentioned commands to produce this output:
![]()
The schema sync utility available at http://schemasync.org/ is a Python script that will perform a schema comparison. This tool will also produce a patch script that can be used to bring the two schema definitions into sync. This is a valuable tool to help in the automation of schema correction.
Additional monitoring can be put into place by a DBA to detect a schema change command and then trigger some applicable reporting and verification approach. The MySQL status variables can be used to detect a CREATE, ALTER, or DROP command. For example:
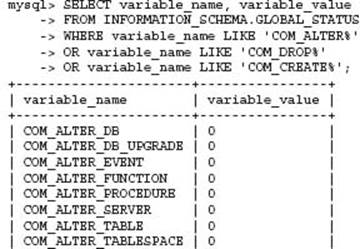
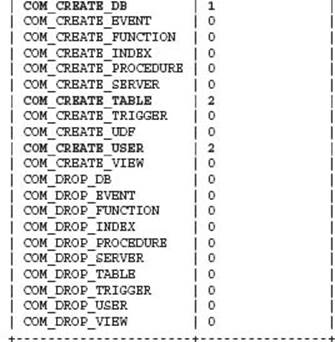
This SQL statement shows the number of statements that have been executed in total since the server was restarted. You can use this information to perform regular difference checks between previously recorded values. Alternatively you can use the mysqlbinlog command to filter and parse the MySQL binary logs for any CREATE, ALTER, or DROP commands. Neither of these options is ideal nor provides an absolute guarantee to capture the occurrence of a schema modification.
Object Consistency
It is also important that triggers and stored procedures are consistent between the master and the slave. You can leverage the same trick with comparing the master and slave object definitions using mysqldump with the additional --routines option. For example:

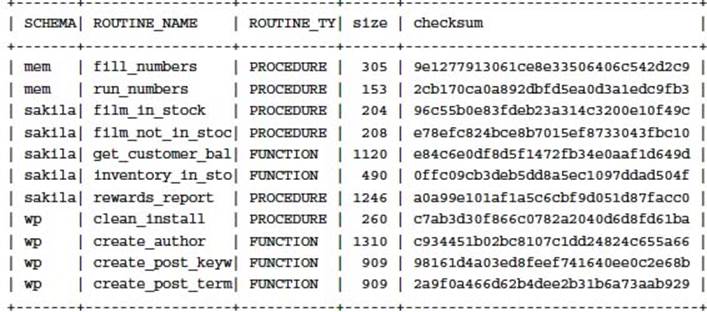
All routine definitions and other metadata are held in the INFORMATION_SCHEMA database. It is possible to use SQL to perform a quick sanity check. For example:

This statement will produce a list of all routines, the size, and a checksum. This output can be recorded daily and a comparison performed to verify any object changes. For example:
Completeness
MySQL binary logging can be affected by several configuration options including binlog-do-db and binlog-ignore-db. This can result in DML and DDL statements not being logged to the binary log. The relay log application on a MySQL slave can further be affected by several configuration options including replicate-do-db, replicate-ignore-db, replicate-wild-do-table, replicate-wild-ignore-table, and replicate-rewrite-db.
Combined with the ability to disable individual SQL statements by the SET SQL_LOG_BIN=0 command with applicable privileges, there is no guarantee that all successful SQL statements applied with your master data will be applied on a given MySQL slave.
When combined with a more complex MySQL replication topology, ensuring that the schema and data are consistent is not enough to determine that the slave used for a backup strategy contains all data.
For a detailed list of MySQL replication options and variables refer to the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/replication-options-table.html.
![]()
Replication Design Considerations
Several MySQL configuration options can have an effect on the design of your MySQL replication.
Binary Log Row Format
Starting with MySQL 5.1, it is possible to alter the binary log format from the historic and default value of STATEMENT, to either ROW or MIXED by using the binlog_format variable. The STATEMENT format, as the name suggests, records the actual SQL statements, which are then applied on the slave. This is known as statement-based replication (SBR). The ROW format provides a binary representation of each table row after modification of the data on the master, which is subsequently applied precisely on the slave. This is known as row-based replication (RBR).
Several configuration operations or statements may lend themselves to requiring or requesting a different row format. For example, altering the transaction isolation variable tx_isolation from the default setting of REPEATABLE_READ will require a MIXED or ROW format to be used. MySQL will provide the following error message in this situation:

Unsafe Statements
MySQL may determine a SQL statement as unsafe with SBR. The updating or deleting of a limited number of rows with the LIMIT statement will produce a warning. Statements that contain system functions, nondeterministic functions, user defined functions (UDFs), and auto-increment changes are also considered unsafe. For example:

A full list can be found in the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/replication-rbr-safe-unsafe.html.
Trigger Operation
MySQL triggers operate differently for the binary log formats. With SBR, triggers executed on the master are also executed on the slave. The definition of triggers and stored procedures may also differ between the master and a slave, which can further cause potential data inconsistency. For RBR, triggers are not executed on the slave. The row changes on the master resulting from any trigger action are applied directly.
Statement-based Replication (SBR)
This format has been the default since the earliest versions of MySQL starting with 3.23. The advantages of this format include, in general, less data is written to the binary log. A DML statement that alters thousands of rows is reflected only as a single SQL statement. The slave has to perform the same amount of work that occurred on the master. An expensive statement needs to be repeated on all slaves. The binary log can be analyzed with mysqlbinlog to produce an audit of all SQL DML and DDL statements.
Row-based Replication (RBR)
With this new format, there is an improved safety of data changes. This is especially applicable for several operations that are considered unsafe. In general, more data is written to the binary log to reflect a change for every row, which can affect disk performance. Starting with MySQL 5.6.2 this can be adjusted with the binlog_row_image configuration option. Less locking is required on the slave for INSERT, UPDATE, and DELETE statements. The binary log is also unable to provide details of SQL statements executed. In MySQL 5.6.2 you can use thebinlog_rows_query_log_events configuration option to provide this information.
Semi-synchronous Replication
Starting with MySQL 5.5, it is possible to improve the asynchronous nature of MySQL replication by enabling semi-synchronous functionality. In this mode, the master waits for an acknowledgment from a configured slave where the transaction has been successfully written and flushed before returning a success indicator to the client. Semi-synchronous replication must be configured and enabled on both the master and the slave for this to occur.
The production master performance is impacted due to the additional slave acknowledgment; however, the benefit is a better guarantee of data integrity.
Semi-synchronous replication in described in greater detail in Chapter 3 of Effective MySQL: Advanced Replication Techniques. More information is also available from the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/replication-semisync.html.
![]()
Replication Backup Considerations
Understanding that MySQL replication provides a copy of the primary database and with listed limitations including lag, schema, and data consistency, you can leverage a replication topology for an effective backup option.
It is possible to stop MySQL replication temporarily to provide better consistency for an optimized backup. This includes control for stopping either the IO or SQL thread separately depending on your needs. These options do not affect your primary master database when performing operations (except when using semi-synchronous replication); however, the time replication is stopped has downstream effects depending on the use of the MySQL slave instance in question.
You can stop the applying of data changes to your MySQL replication environment with the STOP SLAVE SQL_THREAD command. When correctly configured as a read slave this enables a consistent version of data, for example, with the mysqldump command independently of varying storage engines and locking strategies used.
By stopping the IO thread and ensuring all data is flushed, you are providing an environment where there are no physical file system changes. This can be of benefit for providing a more consistent snapshot view.
Additional Prerequisite Checks
Before using a backup option described in Chapter 2, there are several checks that affect a consistent backup that should be considered.
Checking Replication Lag
A small amount of replication lag is acceptable, This lag time is identical for replaying the master binary logs during a point in time recovery. A larger replication lag will result in a longer recovery time, which may be unacceptable. Your backup script that uses a MySQL slave should perform a precheck similar to the following:
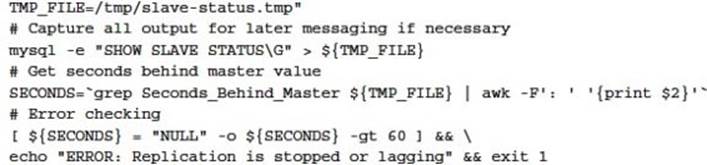
MySQL Temporary Tables
The use of MySQL temporary tables on the master has an impact on ensuring a successful database recovery using a slave. Due to the per session nature, a temporary table can span multiple transactions; however, if a backup is performed while temporary tables are in use, these will not be present during a point in time recovery process that processes the replication stream. This issue also exists when using temporary tables during a MySQL slave instance restart and can result in a SQL error.
You can determine if a MySQL slave SQL thread has open temporary tables using the INFORMATION_SCHEMA or SHOW command. This check should be performed both before and after a STOP SLAVE SQL_THREAD command. Should a non-zero value be returned, the backup process should re-try and ensure this condition before commencing.

or

The design of SBR can help in some circumstances to overcome this loss of data with temporary table use. SBR provides a copy of the actual data change, not a statement that will cause the data change. The interaction of temporary table use and a backup approach is very dependent on the specific application design. In general, it is best to ensure there are no open temporary tables to avoid a potential situation that you do not test for.
When intermediate data is required within your application there are several techniques that can be implemented to overcome this situation.
InnoDB Background Threads
Stopping the SQL thread is not sufficient to ensure a consistent version of the underlying MySQL data on the filesystem. While this stops the application of data changes, internally InnoDB manages flushing of data from the InnoDB Buffer pool to disk by background IO threads. When performing a file copy, inconsistency between different data files will result, as a file copy is a sequential process. When using a filesystem snapshot utility, all underlying database files will be consistent at the time of the snapshot. When restored, the MySQL database will still need to perform a consistency check and statements in the InnoDB transaction log may be applied. This occurs as part of an automatic recovery process. There is no way with the current version of official MySQL binaries to produce a clean state without shutting down the server.
Cold Backup Options
Stopping a MySQL slave instance has no impact to operations on a master system. However, it is important to ensure any application using the MySQL slave for additional purposes, including handling read scalability and/or reporting, will be affected. Generally the procedure is to ensure the server is removed from application access accordingly during the backup. By default, a MySQL slave instance, when started, will automatically connect to the master and start the process of synchronizing. The configuration option skip-slave-start will disable the slave from automatically commencing replication on startup. Depending on the time the slave instance is unavailable it may take minutes to hours before the slave is consistent.
mysqldump Options
Using mysqldump of a production database with the --master-data option and combined with the master binary logs enables a full point in time recovery option. When using a MySQL slave, the --master-data option does not provide the position of the master. At best, this option will produce an error message; at worst, it will record the position of the master binary log on the slave, if the slave is also configured as a master. The following examples show both conditions:
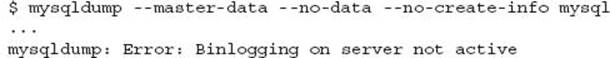
A MySQL slave may be configured to record a binary log using the -log-bin option and optionally the -log-slave-updates option. This means the MySQL slave is actually configured as a master for additional slaves. This is known as chaining where a replication environment may have three or more levels (e.g., a grandfather, father, and child). In this situation the --master-data option would result in information; however, this is the position of the binary log of this slave, not the master of the slave.
Using the MySQL Sandbox tool available at http://mysqlsandbox.net/ is an excellent way to quickly test and verify different replication situations. To highlight this specific condition we create a standard master and two slave sandbox replication environments:
We can then look at the specific mysqldump output for a given slave in this replication topology:

As described in the earlier point, the position described is not the actual position of the master for this slave, but rather the position of the binary log on this slave, which is also acting as a master. This can be confirmed with:
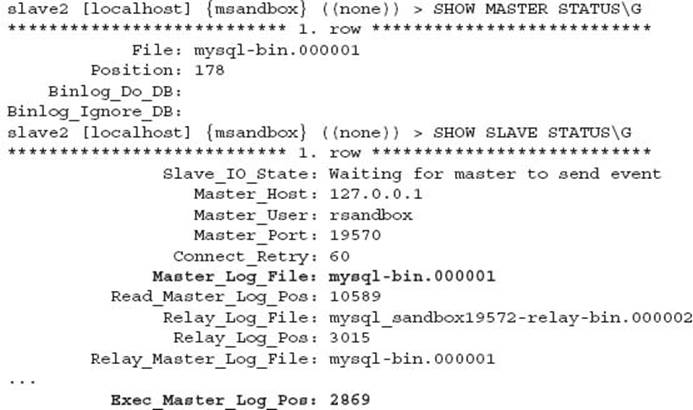
By stopping the MySQL slave and capturing the SHOW SLAVE STATUS, it is possible to create a backup of the MySQL slave, and use this in conjunction with the master binary logs to perform a successful point in time recovery.
Starting with MySQL 5.5 the --dump-slave option provides the correctly formatted output you would expect:

CAUTION The use of MySQL replication requires careful consideration for correctly identifying the position of the master when using a static backup of a slave and the master binary log files for point in time recovery.
The --apply-slave-statements option can also be used to streamline the use of a mysqldump file for automated recovery. This option adds the STOP SLAVE and SLAVE START commands to the output produced.
Filesystem Snapshot Options
The stopping of the MySQL SQL slave thread prior to performing a FLUSH TABLES WITH READ LOCK can reduce the pending wait time of this command. The optional stopping of the MySQL IO thread will provide a consistent file system copy of the relay logs; however, this is not necessary with any filesystem snapshot technology.
The replication position is also recorded on the filesystem in the file defined by the relay_log_info_file system variable. Using the MySQL replication environment configured in the previous section with MySQL Sandbox this can be verified. For example:

MySQL Enterprise Backup (MEB) Options
The MEB product has an additional option when used with a MySQL slave server:
• --slave-info This option creates the meta/ibbackup_slave_info file containing the necessary CHANGE MASTER command to restore the backup to produce an identical slave server.
CAUTION An important change to the use of the --slave-info option was introduced in the most recent version of MEB version 3.7.1 regarding the synchronizing of data between the slave SQL thread and slave I/O thread.
XtraBackup Options
The XtraBackup utility manages MySQL slave specific instances using these options:
• --slave-info This option creates the xtrabackup_slave_info file containing the necessary CHANGE MASTER command for recovery.
• --safe-slave-backup This option stops the SQL thread and waits until there are no temporary tables in use.
Using the syntax for XtraBackup from Chapter 2, these two options are added for a backup of a MySQL slave:
![]()
This produces the necessary SQL for use during recovery with the defined MySQL master:
![]()
For more information see http://www.percona.com/doc/percona-xtrabackup/innobackupex/replication_ibk.html.
![]()
Architecture Design Considerations
When knowing the strengths and weaknesses of MySQL replication you may consider alternative approaches when designing your scalable architecture. While replication is well known for read scalability, other options that leverage improvements in data manageability, backup, recovery, and caching are possible. This could include the separation of write once data or batch managed data from more general read/write data.
The use of MySQL replication may also impact these design needs. Understanding data availability differently for write, read, and cached needs combined with read and write scalability, MySQL replication may be implemented and used in many different ways.
For example, if you have 30 years of financial data that is added to daily, however, each year of data is completely static, the separation of data into a static table of the first 29 years of data and a dynamic table of growing data could enable a vastly different backup and recovery strategy. This would improve caching options; however, it would add programming complexity to your application to support this level of manual partitioning. This one architecture decision could reduce daily backup operations of time and volume by 90 percent. Recovery may also be five to ten times faster. The complexity is now two different database environments with different caching strategies, different backup and recovery approaches, and the appropriate application overhead.
MySQL provides functionality for several different approaches towards addressing this specific example. MySQL partitioning and the ARCHIVE storage engine provide different advantages for functionality and should be evaluated in combination with the merits of applicable backup and recovery for these choices.
Improving your schema design for intermediate processing of data and temporary tables, enabling a specific database schema to be ignored for binary logging and replication may greatly improve replication performance. This in turn minimizes potential limitations.
![]()
Upcoming Replication Functionality
The current development version of MySQL 5.6 includes numerous replication improvements which address some of the identified backup concerns. In summary these improvements include:
• Binary log checksums
• Removing the row format before image
• Logging SQL statements in addition to row format
• Delayed replication
• Logging binary log and relay log positions using tables as well as files
• Multi-threading support on slaves supporting parallel transactions per database schema
More information about MySQL 5.6 features can be found in the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.6/en/mysqlnutshell.html and http://dev.mysql.com/doc/refman/5.6/en/news-5-6-x.html. These options are also discussed in Effective MySQL: Advanced Replication Techniques.
![]()
Conclusion
MySQL replication is an essential component for any high availability and scale out MySQL environment. Understanding how MySQL replication can be used for a backup and recovery strategy can be beneficial for designing a suitable MySQL topology to support both HA and DR requirements.
The backup approach is only the first component of a successful backup and recovery strategy. Applying the various options in Chapter 2, with MySQL replication considerations and with the business needs detailed in Chapter 3, it is now possible in the following chapter to fully evaluate the successful recovery of your valuable business information.
The SQL statements and web links listed in this chapter can be downloaded from http://effectivemysql.com/book/backup-recovery/.