Effective MySQL: Backup and Recovery (2012)
Chapter 7. Disaster Scenarios
“Disaster is inevitable. Total failure is avoidable.”
Ronald Bradford & Paul Carlstroem – 2011
Disaster happens. This is generally when you are not expecting or prepared. Having an idea of what sort of problems may occur that require a level of recovery will help you understand how your backup and recovery strategy plan will succeed. Understanding these various situations and the many other possible cases can help in the testing and verification steps implemented for your business information. Disaster recovery (DR) is a requirement in the planning for a high availability (HA) solution. In many environments clear procedures and architectural design is in place enabling growth more seamlessly. Unfortunately the same is not said for disaster preparedness, the poor cousin. Improving, refining, and testing various disaster recovery situations are often left to a crisis situation where costly mistakes can occur.
In this chapter we will cover several situations including:
• Actual business ending disaster situations
• Common MySQL disaster situations
• MySQL recovery tool options
• Managing the human factor
![]()
Handling a MySQL Disaster
A backup is only as good as the ability to perform a successful recovery. Unfortunately performing a recovery in a controlled situation is never the case. The need to perform a disaster recovery is always at an unpredictable time and often includes other factors or cascading failures. An action in one situation may be critical to protect against further data loss, while the same action in a different situation will lead to permanent data loss. There is no instruction manual for every situation; foreknowledge of a wide range of situations and practice of these is your best asset in the decision making process. The following examples showcase some typical and less typical disasters. A number of common and less common disaster situations are provided to enable the preparation and testing for these situations. Some of these disaster situations are completely avoidable with pre-emptive procedures.
With over 20 years of IT experience, the author has been involved in averting serious business loss in a number of situations and varying technologies. He is also not immune to having caused a few minor disasters as a result of human error. Learning from the mistakes of others is a critical step in a database administrator (DBA) or system administrator (SA) mastering their respective fields. This book hopes to outline the tools for creating an appropriate backup and recovery strategy for your specific environment and provide invaluable tips and information to avoid making the mistakes others have encountered.
In fact, during the final production stage of this book, two different disasters were encountered working with two separate clients on consecutive days. Both situations were then added to this chapter as unique examples. In both cases the final outcome was positive, but the risk of not being prepared is that your business may suffer a serious if not fatal situation. You never want this to occur on your watch and be a line item you try to avoid mentioning on your resume for the next job opportunity.
![]()
Notable MySQL Disasters
For every disaster that is discussed in this chapter, many more exist that are not known or spoken of. Rarely do organizations advertise a data failure that resulted in loss of revenue, users, creditability, or that resulted in a total failure of the business. The following are a few very public examples of situations with varying levels of disaster and outcome.
DISCLAIMER: The author of this book is repeating knowledge that is provided and generally available online. These examples demonstrate possible situations and results regardless of the validity of the information in the source story.
Magnolia
Ma.gnolia.com was a social bookmarking site that shut down due to a MySQL data disaster in 2009. The public information about the problem includes a one-man operation, limited equipment redundancy, a faulty backup system, a hard drive failure, and an apparent inability for a specialist to recover any data.
A quote from a listed reference, “A clear lesson for users is not to assume that online services have lots of staff, lots of servers and professional backups, and to keep your own copies of your data, especially on free services,” highlights that you should not assume your data is safe. If you have the ability to obtain a copy of your own recorded data, then do it. In the case with Magnolia they provided APIs to download all of your recorded personal data.
From a different reference is the comment “Outsource your IT infrastructure as much as possible (e.g., AWS, AppEngine, etc.).” This is not a wise practice to blindly trust your information with a third party. How are you sure their practices are fully functional, secure, and result in a timely recovery? You should always keep your important and critical data close to physical control. The loss of control is a potential career limiting move if your responsibility is to ensure the integrity and availability of information.
CAUTION Any organization that provides third party services for your backup and recovery strategy and that states certain characteristics of data availability and recovery is not a guarantee until it can be proven and verified.
The following lessons can be learned from this experience:
1. Adequate hardware redundancy is important.
2. Testing the backup and recovery process is important.
3. A particular hardware failure may not mean all data is lost.
4. If data you store on an external website is important, make your own backup.
5. Being upfront with your customers during a situation is a sound business practice.
References
• http://www.datacenterknowledge.com/archives/2009/02/19/magnolia-data-is-gone-for-good/
• http://www.wired.com/epicenter/2009/01/magnolia-suffer/
• http://www.transparentuptime.com/2009/02/magnolia-downtime-saas-cloud-rrust.html
Couch Surfing
The information obtained from the shutdown of Couch Surfing reads like a story that should be told to every database administrator and decision maker for any company that cares about their data. The TechCrunch article title sums the risk to any organization, “CouchSurfing Deletes Itself, Shuts Down.”
This environment contained both MyISAM and InnoDB data. There was apparently no binary logging enabled, and the backup procedure, which had been failing for over a month, was not performing a remote sync of all important MySQL data files. Even if the rsync backup process was operating correctly, a restore process would still result in a corrupted database, as the rsync of a running database is not a consistent view of all MySQL data. It took a hard drive crash for the situation of an incomplete backup process to become apparent and destroy the dream of an entrepreneur who had contributed over three years to this project.
The following lessons can be learned from this experience:
1. Disaster is inevitable; be prepared.
2. Any level of sane production system availability in MySQL starts with two servers. This uses MySQL replication, and the all important binary logging.
3. Daily verification of your backup process should be one of the top daily tasks of your administrator. Simple metrics such as the size of your database, and the size of your backup, and a check of change over time are simple red flags.
4. Test and verify.
References
• http://techcrunch.com/2006/06/29/couchsurfing-deletes-itself-shuts-down/
• http://forums.mysql.com/read.php?28,99328,99328#msg-99328
Journal Space
In 2009, a six-year-old blog hosting website ceased operations due to all data being destroyed and with no appropriate backup in place.
Information from articles indicates that data was managed on a RAID-1 configuration. While RAID-1 provides a level of disk mirroring to support a hardware failure in one of two drives, this is not a total backup solution. Disk mirroring supports one situation when there is a failure of one drive. Due to the hardware or software implementation of RAID-1, an action applied on one disk is mirrored to the second disk under normal operating procedures. If a system administrator physically removed the database either intentionally or unintentionally, the deletion is applied to the mirrored disk. The purpose of mirroring is to have an identical copy of the original on the same server host. An attempt to recover the data that was apparently deleted was also unsuccessful. Data recovery in this situation is usually possible providing information is not overwritten.
CAUTION RAID is not a data backup solution. RAID provides a level of redundancy for only one type of physical disk failure. RAID is an important first step in data protection only.
While backups apparently existed for the application code base, this is useless without an underlying source of data held in the database.
The following lessons can be learned from this experience.
1. Hardware redundancy is not an adequate backup strategy.
2. Secure offsite backups are necessary if your data is critical for business viability.
3. Data loss and corruption can easily occur as a result of human factors.
4. If the data you store on an external website is important, make your own backup.
References
• http://blog.backblaze.com/2009/01/05/journal-space-shuts-down-due-to-no-backups/
• http://blog.bismuth.com/?p=275
• http://idm.net.au/blog/006734-blogging-community-destroyed-lack-backup
Percona
Even industry leaders in the field of MySQL are not immune to a disaster scenario. Percona, the largest independent organization that provides MySQL support services, reported a “catastrophic failure of three disks on our primary web server” in 2011. As mentioned in an earlier example, being open with your customers regarding the recovery process is as important as correcting the problem. A cascading series of issues including a disk failure, a disk controller failure, and then data corruption due to configuration highlight that being prepared for more than one situation is always necessary. The delay in the recovery time was also attributed to staff changes.
As reported, “no customer data was compromised,” and some services, including customer service activities, were not affected. These references indicate that sound architectural practices for a system failure of varying components do not necessarily result in total system unavailability.
This example is included to indicate that compounding problems do occur and that there are ways to address potential problems. The article also highlights that due to a configuration setting, data corruption occurred after a series of unexpected events.
CAUTION A disaster does not always match your prepared disaster recovery situations when one component or system fails. A disaster can easily result in multiple cascading failures causing unexpected effects.
The outcome of any disaster is an acknowledgment for an organization to learn from the experience. The following quote is an important message that describes the business decisions resulting from this experience and is a great lesson for all readers. “The recovery lessons learned for us have been considerable and will be incorporated into our internal processes. Availability and performance of all of our websites is a top priority.”
The following lessons can be learned from this experience:
1. A disaster can easily lead to more than one problem occurring at one time.
2. A documented process and knowledge by additional resources are important for timely resolution.
3. Disaster preparedness is a continual improvement process.
Reference
• http://www.mysqlperformanceblog.com/2011/07/19/server-outages-at-percona/
![]()
Other Notable Data Disasters
For additional reference material in the type of disasters that can occur, the following non-MySQL specific examples show failures with cloud based technologies, open source providers, and even a bank.
The Sidekick/Microsoft Data Loss
Disasters happen with large organizations. Danger, a $500 million acquisition by Microsoft, had no backups for the users of the Sidekick phone. All information about contacts, photos, calendars, etc., for potentially hundreds of thousands of devices was stored in the cloud. Official statements of a serious failure included “likely lost all user data that was being stored on Microsoft’s servers due to a server failure... Microsoft/Danger is describing the likelihood of recovering the data from their servers as extremely low.” Later reports claimed that the company failed to make a backup before a Storage Area Network (SAN) upgrade, and when this was botched, the result was loss of all data.
An important question in this situation is not “Why was there no backup?”, but why executive management did not ask “What confirmation do we have in our business that our data is safe?” Executives should also be asking in any business “How do we recover from a disaster?” and “When was the last time we did this?”
TIP A decision maker of any organization should be paranoid with what could occur during a data loss situation while having full knowledge of what procedures, practices, and drills are in place to protect data from ever being lost.
References
• http://techcrunch.com/2009/10/10/t-mobile-sidekick-disaster-microsofts-servers-crashed-and-they-dont-have-a-backup/
• http://www.zdnet.com/blog/btl/the-t-mobile-microsoft-sidekick-data-disaster-poor-it-management-going-mainstream/25777
• http://gizmodo.com/5378805/t+mobile-sidekick-outrage-your-datas-probably-gone-forever
Github
One of the most popular repositories of source code version control for open source projects and many commercial companies suffered a severe database failure. Using references from the official blog post: “Due to the configuration error GitHub’s production database was destroyed then recreated. Not good” and “Worse, however, is that we may have lost some data from between the last good database backup and the time of the deletion. Newly created users and repositories are being restored, but pull request state changes and similar might be gone” we get a picture that adequate backup and recovery procedures were not in place.
However, the true cause of the problem was actually a configuration error. This was due to a test environment co-located on a production environment, and most likely a lack of appropriate user security settings that should be different between environments. The result, a perfectly normal test practice of dropping and re-creating the database, worked as designed; it was just never designed to be executed on a production situation.
TIP Do not run development or test environments on the same machine as your production environment. A production environment should always have a different user account and password for management than non-production environments.
Reference
• https://github.com/blog/744-today-s-outage
TD Bank
Of all the industries, you would expect that banks would have iron clad procedures for management of customers’ bank account information. In this botched upgrade, when two systems were merged into one, customers found out the frustration of not having accurate information and not being able to access their cash. System interruptions and inaccessible accounts were prolonged for days and were compounded by batch processing operations causing additional data corruption. This upgrade failure shows that adequate backups before an upgrade, and an executable recovery process in the event of a failed upgrade, are simple steps that can be tested before a production migration.
References
• http://www.zdnet.com/blog/btl/td-bank-botches-it-system-consolidation-customer-havoc-ensues/25321
• http://www.bizjournals.com/philadelphia/stories/2009/09/28/daily30.html
• http://www.olegdulin.com/2009/10/this-weeks-tdbank-debacle-and-takeaways-for-it-leaders.html
• http://www.nbcphiladelphia.com/news/business/Computer-Glitch-Causes-Problems-at-TD-Bank-63103572.html
![]()
General MySQL Disaster Situations
The lack of basic MySQL configuration requirements is a common cause of avoidable disasters. These situations that will be discussed include:
1. Not using MySQL binary logging
2. Using a single MySQL server in production
3. Using appropriate MySQL security
Other types of common and avoidable disasters are the result of a human resource deleting something. What do you do in these situations?
1. Deleting MySQL data
2. Deleting the MySQL InnoDB data file
3. Deleting MySQL binary logs
Binary Logging Not Enabled
Using MySQL in a production system with only nightly backups and not point in time capabilities is not a sound business practice. With a particular customer’s e-commerce operation that included sales of several million dollars daily and large transactions exceeding $100,000, a loss of any successful transaction would have a business impact. A loss of all data from the last successful backup would have a significant and serious business effect.
If any data was accidentally deleted, if the server had any hardware failure that simply resulted in downtime of the website for a day, or any serious disk failure resulting in data loss occurs, it would have resulted in serious financial loss. Under any of these situations, the lack of binary logging makes it impossible to retrieve critical lost information.
For any production system, binary logging is critical to enable the possible recovery of any data following a nightly backup. While not adequate to support different types of disaster, the lack of this essential setting is a common failure for a new business.
Chapter 2 describes the MySQL configuration settings necessary to enable MySQL binary logging.
NOTE No binary logging means no point in time recovery, period.
A Single Server
A single MySQL database with nightly backups and binary logging is a sound business practice that can provide adequate data recovery. Unfortunately, in a production situation even with the ability to perform a successful recovery, the absence of access to data such as in a read only mode, or access to hardware to perform a recovery, is a primary loss of credibility with your existing customers while your site is unavailable.
Every minute of time taken to provision or re-purpose a server and install and configure the necessary technology stack is loss of business reputation and business sales.
Any MySQL infrastructure in a production system should always start with two database servers. MySQL replication is very easy to set up and configure. The MySQL Reference Manual provides a detailed guide at http://dev.mysql.com/doc/refman/5.5/en/replication-howto.html. Chapter 4describes the benefits of replication for backup and recovery. The next book in the Effective MySQL series titled Advanced Replication Techniques will also cover replication in greater detail.
Appropriate MySQL Security
The greatest cause of system administrator related problems with MySQL is a lack of appropriate security permissions on underlying MySQL data. It is recommended that the MySQL data directory, as defined by datadir, and the binary log directory, as defined by log-bin, have permissions only for the mysqld process, generally the mysql OS user. For a common Linux distribution installation, the following permissions would be used for optimal security:
![]()
Depending on the installation, the MySQL data directory may not reside in /var/lib/mysql.
CAUTION Some distributions place the socket file in the data directory. This has to be moved to a world readable directory in order for MySQL to function normally with a secure data directory.
Application Security
The greatest cause of application developer related problems with MySQL is the lack of appropriate permissions and privileges for user accounts that can modify data, structure, or configuration settings. A MySQL environment where an application user is given ALL PRIVILEGES on all objects (i.e., *.*) can, for example, disable binary logging, which would affect any MySQL slaves, and then possibly your defined backup and recovery strategy. There are many additional reasons why this blanket privilege can cause issues in a production environment.
More information on the effects of GRANT ALL ON *.* can be found at http://ronaldbradford.com/blog/why-grant-all-is-bad-2010-08-06/.
Appropriate MySQL Configuration
Several MySQL configuration settings can lead to data integrity issues that can cause undesirable situations with production data.
Read Only Replication Slaves
The most common problem is not setting a MySQL slave to read only with the read_only configuration option. Without this option, an application that incorrectly connects to a replicated copy of the data has the ability to modify this data. The first impact is data inconsistency, also referred to as data drift. The second impact may cause MySQL replication to fail in the future, which can lead to further complications for data correction and slave usage.
To reiterate the point in the previous section regarding the importance of applicable application security, the following example demonstrates the potential disastrous effects.
Two MySQL users are defined, a user with the appropriate permissions for an application, and then a user with all privileges. These users are defined on a replication slave that is correctly configured as read only.

This one example should highlight the importance of appropriate user privileges for application users.
SQL Server Modes
The lack of an appropriate SQL server mode with the sql_mode configuration option can easily cause data integrity issues that when not adequately monitored by the application can result in disastrous results that may not be detected for some time. The following are simple examples to show that data loss can occur without error in MySQL when operating with default SQL server mode settings:

Everything may appear correct; however, the final name was actually silently truncated by MySQL without producing an error.
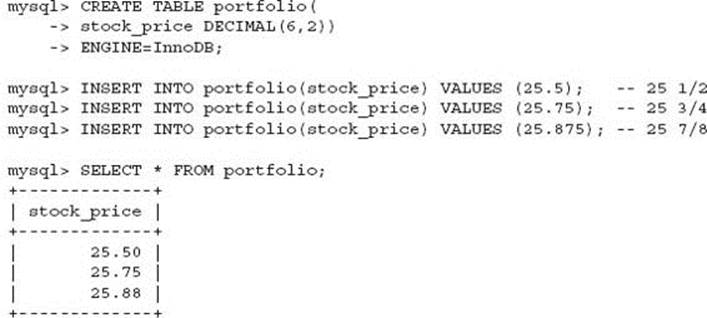
In this example, the 0.005 rounding error could be great for your portfolio, as it rounded up:

In this example, an invalid date is modified causing the data that was entered to be lost, and a zero data value is permissible.
Fortunately, setting a correct SQL server mode within MySQL can easily solve these data integrity issues. For example:

TIP One of the greatest sources of creeping data corruption that goes undetected and is almost impossible to recover is due to the MySQL default SQL server mode. One configuration option, when set at the creation of a new MySQL instance, can provide great relief for future data integrity.
CAUTION The modification of the SQL server mode on an existing production system will generally result in unexpected errors, especially with date management. When using certain recommended date settings, issues may also not present as problems until table alterations are applied.
Deleting MySQL Data
“I have deleted all the data in a table. What do I do now?” In this situation with a single server, a database recovery is generally needed. In a MySQL replicated environment it is likely the destructive statement has affected all slaves. If detected immediately, it may be possible to stop replication execution on a slave to preserve the data that was deleted. This is only likely if your slave is lagging adequately, not a usual situation in a production situation.
However, depending on certain conditions, data may be recoverable via other means. The following is an actual customer example of a successful data recovery provided by Johan Idrén from the SkySQL support team and reproduced with permission.
The customer has executed a rather devastating “DELETE FROM table_a;” command. The only backup available was made several hours after the erroneous statement, so what we had left to work with was the underlying table_a.idb file. Based on the underlying file size of the individual tablespace for this InnoDB table, most of the data may be still recoverable. This was a job suited for the Percona InnoDB data recovery tool.
The first requirement is to obtain the table definition from the customer. The output of the SHOW CREATE TABLE command provides this. After creating an identical table on a local MySQL server, the create_defs.pl script is used to create a necessary table_defs.h file.
![]()
With this definition, it is possible to build a binary to extract data from the available table data file. Execution appeared to work well, providing output consistent with the table definition provided.

A suitable LOAD DATA INFILE statement was used to process the generated data file:

After initial testing some additional work was needed to remove some duplicate rows and garbage data in the generated data file. The end result was that all data was recovered and the customer was happy, a great success!
What caused this recovery process to go relatively easy?
1. The InnoDB storage engine was used.
2. No further DML statements were run on the table.
3. The innodb_file_per_table configuration option makes the use of the InnoDB recovery tool a lot simpler, as this only has to process the individual tablespace file and not the common tablespace, which supports all InnoDB tables.
The closing comment by Johan echoes all this reference stands for. “The moral of the story? Backup, backup, backup.”
NOTE In some conditions, data recovery from a DELETE FROM TABLE command is possible.
References
• http://blogs.skysql.com/2011/05/innodb-data-recovery-success-story.html
• https://launchpad.net/percona-data-recovery-tool-for-innodb
• http://www.chriscalender.com/?p=49
--i-am-a-dummy Configuration Option
An additional configuration option that could have averted this situation is the --i-am-a-dummy variable. While you may laugh, this is a valid configuration alias for the --safe-updates option. This option disables table level delete and update operations as described in the following example:

For more information refer to the MySQL Reference Manual at http://dev.mysql.com/doc/refman/5.5/en/mysql-command-options.html#option_mysql_safe-updates.
Deleting the InnoDB Data File
The circumstances for how data has been deleted matters. For example, if the InnoDB tablespace file (e.g., ibdata1) is deleted while MySQL is running on a Linux operating system, it is possible to recover your MySQL data but only if the MySQL server has not been stopped.
On a test system, the following is performed to demonstrate this situation:
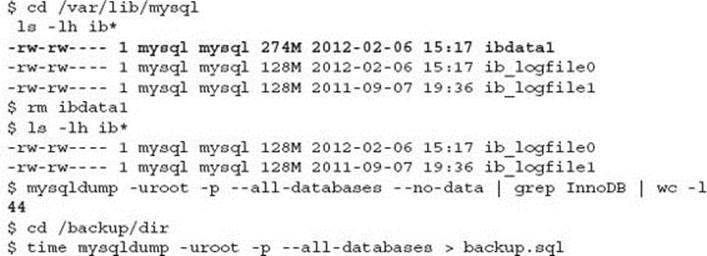
As you can see there were 44 tables that were defined as InnoDB tables. If the mysqldump of data was not performed before the MySQL instance was stopped, that data is lost without performing a full data recovery.

This situation for possible data recovery after deleting the InnoDB tablespace file is because the mysqld process retains the file inode link until the process terminates. In this situation it is possible to extract the data using mysqldump.
Any online advice that states to shut down the MySQL process if data is deleted may or may not be the correct advice. Knowing the situation that caused the disaster is necessary information before making any decision, as shown in this example.
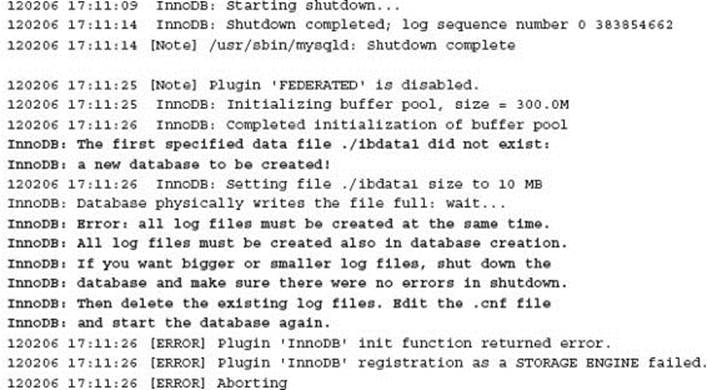
In this situation, as indicated in the error log, it is necessary to also remove the InnoDB transaction logs to enable the MySQL instance to start before performing a data recovery.
Deleting MySQL Binary Logs
A common problem is the disk partition holding the MySQL data directory filling up. While many situations include the case where no monitoring is in place to detect a full filesystem, a common action is a system administrator detects a filesystem at 80% or 90% full and then acts to delete files rather than consulting the database administrator or considering the ramifications of a database system, not a filesystem. Allowing a system administrator to remove MySQL binary log files causes multiple problems.
The best file to consider removing to reclaim space in a MySQL installation is the binary log. These can grow in size; in a large production system these can be as much as 500MB per minute. The first problem when removing files manually is the reference to this file in MySQL is not removed. The correct approach to remove binary log files is with the PURGE MASTER command. This will remove the physical file and the internal definition.
Removing the binary logs also affects your disaster recovery possibilities and your MySQL replication topology. If a MySQL slave has stopped for some reason and is one day behind the master, removing the binary logs on the master that are older than six hours will render the slave useless and will have to be fully recovered. A full recovery involves using a backup (for example, from last night), and then the application of the binary logs until the current point in time. If those binary logs the system administrator so wisely deleted to ensure the disk does not fill up have not been backed up during the day—for example, if that only happens daily or even every 12 hours—your environment is not recoverable with existing backups. A different approach including an immediate backup is needed.
The final problem is common when the binary log files and the MySQL data are found in the same directory. This is the default configuration for the popular RedHat/CentOS/Oracle Linux and Ubuntu distribution installations. An over-zealous system administrator running a smart find command that is used for cleanup on other filesystems can easily remove files in the MySQL data directory that are important and can easily crash or corrupt a MySQL installation.
TIP A well configured MySQL installation should clearly separate the MySQL data directory, the MySQL binary log, and MySQL relay log directories for better system administration.
A final frustrating example is when a client performs a volume test in preparation for a production deployment and the result of the test fills up the partitions for the data and/or binary logs. The action of the experienced DBA to reduce the amount of logs kept with by setting theexpire_logs_days configuration option to 1, or the proactive removal of the master binary logs during the test is not a wise practice. The purpose of a volume test is to prove a production situation. Are you going to proactively remove important files necessary for any level of disaster recovery? Would considering that the defined (and organizational standard) filesystem structures are inappropriate for this deployment be a more applicable action?
TIP The purpose of testing is to break your software, and then correct discovered issues so these situations are avoided in the future within a production environment.
![]()
Existing Backup and Recovery Procedure Disasters
The following examples are where an existing MySQL backup approach was in place; however, the recovery encountered situations where the process was insufficient in some way.
• Does your backup work after a software upgrade?
• Does MySQL still perform after a restart?
• Handling MyISAM corruption.
• Missing schema data in backup.
• Restoring a backup on a running server.
MySQL Software Upgrades
Running a MySQL backup and ensuring this completed successfully and that backup files exist are not enough. In the Chapter 5 quiz one important step is “Do you review your backup logs EVERY SINGLE day or have tested backup log monitoring in place?”
This is what was found when reviewing a backup log for a client:

The backup script was completing, and backup files were in place (and were listed in the log file output); however, these errors were occurring. Some data was potentially not being included in the backup due to this error.
This server was running multiple MySQL instances and recently one instance was upgraded from MySQL 5.1 to MySQL 5.5; however, the call to mysqldump was not. This error was the result of running a version 5.1 mysqldump against a version 5.5 MySQL instance. By changing the hard coded path in the backup the error message went away.
In this example, a backup process was in place and historically operated without error. The greater problem is teaching people to understand the importance of the verification process.
Operating System Security Patch Upgrade
Backing up the MySQL configuration file can be as important as the MySQL data.
A production MySQL system was upgraded to include new operating system security patches. This resulted in the Linux distribution also updating MySQL 5.0 to a new point release. The correct process of taking a database backup before the upgrade was performed; however, following the upgrade, application performance was seriously degraded. It was reported by the client that it was not possible to undo the software upgrade.
Discussion and analysis determined that no application changes were applied, the system load was much higher, and the application was now taking 10 times longer to perform basic tasks. The client believed only the MySQL upgrade could be the cause. The system had been running over 150 days without any similar issues.
The first observation is that MySQL has been restarted. This has three significant effects on performance.
1. The first is time taken to refresh the applicable memory caches of data and indexes over time as they are first accessed from disk. In some situations there is a benefit in pre-caching important data on a system restart.
2. The second situation is the need for InnoDB to recalculate the table statistics for the query optimizer. This occurs when a table is first opened and requires random dives of accessing index information, initially having to read from disk. MySQL 5.6 includes a new feature to save and load these table statistics for faster restarts.
3. The third effect is less obvious but important. MySQL will read the configuration from the applicable filesystem files, e.g., my. cnf. This means that any dynamic changes made to the previously running system that were not applied to the configuration file are lost. If this was not documented, the previous running system could have improvements in performance that were not persisted during the restart.
The simple solution is to record the running values of all MySQL configuration variables by adding this to the daily backup process. A further verification of running values with the filesystem values in the default MySQL configuration file can be performed. This information can be obtained in the following ways:

With the runtime configuration of a number of system variables, the system was able to improve performance. The review of the worst offending SQL statements and the creation of additional indexes also made a significant improvement. While a minor upgrade should not affect the performance of SQL statements, it is always a good practice to run important SQL statements without using the query cache, capturing execution time and execution plan details before and after any upgrade.
Handling MyISAM Corruption
The following scenario is a detailed explanation of a MyISAM corruption situation that recently occurred and the steps to triangulate a possible recovery and the ultimate solution. The environment was a single MySQL production server with binary logging (that was disabled prior in the day). There was no MySQL replication server in place.
The Call for Help
While checking my inbox at breakfast the following e-mail draws attention:

NOTE Disaster does not care if you are on vacation.
The Confirmation of a Serious Problem
I immediately contact the client, determine that the situation appears serious, and connect to a running production system finding the following errors in the MySQL error log:
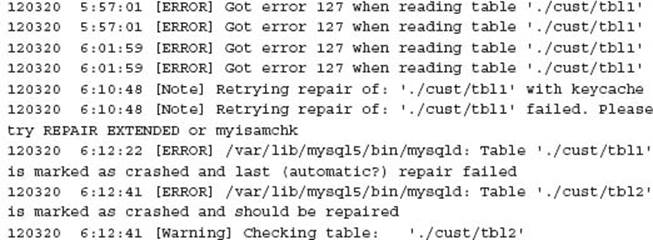
This is the first obvious sign of MyISAM corruption. This generally occurs when the MySQL instance crashes or is not cleanly shut down. A quick review confirms that three minutes earlier this occurred. It is always recommended to try and find the cause to ensure this is understood in future situations.


The First Resolution Attempt
In this situation it is best to shut down MySQL and perform a myisamchk of underlying MyISAM data. Depending on the size of your database, this can take some time. By default, myisamchk with no options will perform a check only.

This output is good:
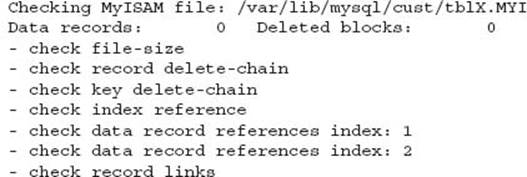
This output is not good:
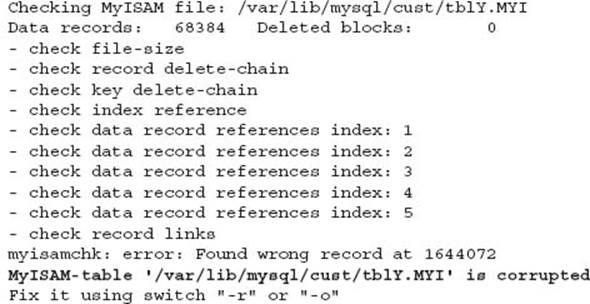
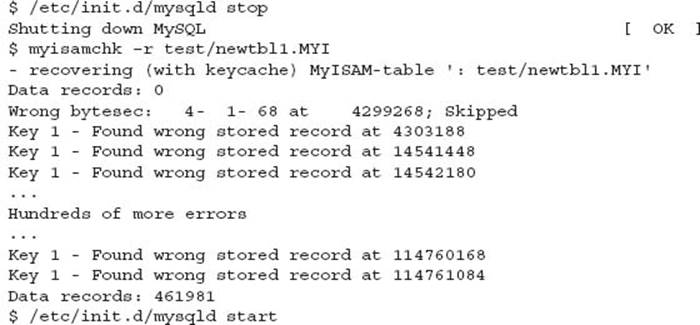
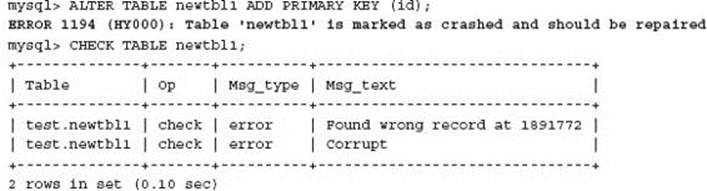
To perform a repair on a MyISAM table the –r option is required. For example:


This shows a successful repair. The following shows an unsuccessful repair:
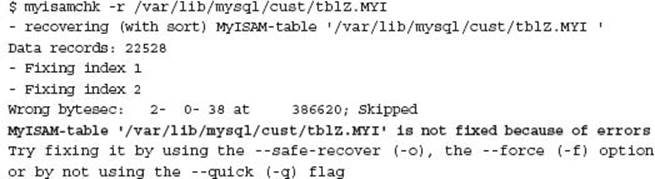
This following error on the client’s largest and most important table is that classic WTF moment:
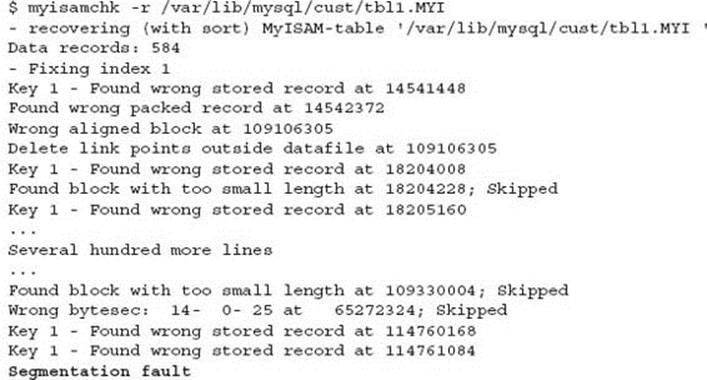
As a side note, if myisamchk fails to complete, a temporary file is actually left behind. (First time experienced by the author.)

![]()
The Second Resolution Attempt
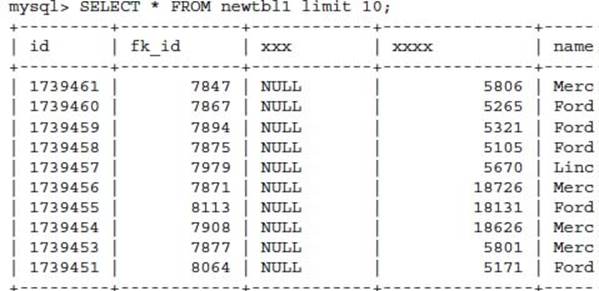
One of the benefits of MyISAM is that the underlying data and indexes are simply flat files. These can be copied around between database Schemas with the appropriate table definition file (i.e.,. frm). The following steps were used to simulate a new table.
1. Obtain the table definition from a backup file or SHOW CREATE TABLE command.
2. Create a new table in a different schema with the table definition and all indexes removed.
3. Copy the existing .MYD file over the newly created table .MYD file. The new table does not need to be the same name as the old table; however, the .MYD name must match the new name.
4. Repair table (requires MySQL instance to be stopped).
5. Confirm the data is accessible.
As you can see, a repair of the table this time did not produce a core dump. A further confirmation defines data is accessible.
At this time an attempt to re-create the indexes on the table is performed to enable this table and index structure to be copied back to the production schema.
It is clear that the table does not want to be repaired.
The Third Resolution Attempt
At this time, the decision to continue or to pursue data recovery or a restore from the previous night’s backup is considered, and both options are undertaken in parallel. A more detailed recovery is performed using initially the –o option for the older recovery method, and then with –e option for an extended recovery. It should be noted that the myisamchk documentation states “Do not use this option if you are not totally desperate.”
The table is confirmed as crashed again.

A successfully reported repair is performed.
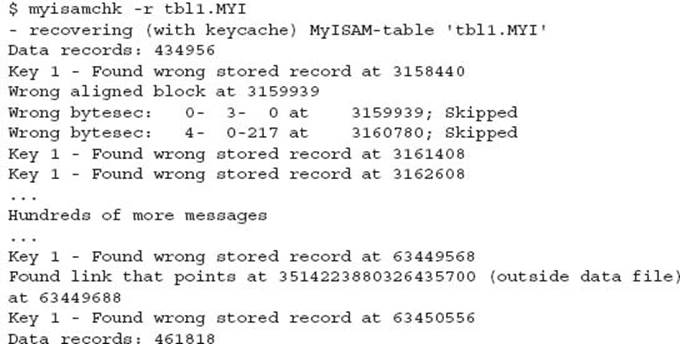
However, the table is still considered corrupt.
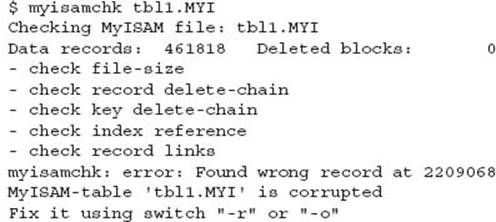
A more extensive recovery is performed.
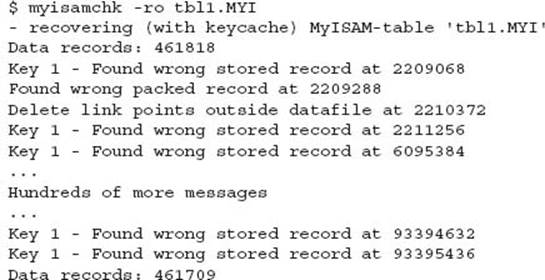
The number of data records has decreased from 461,818 to 461,709.
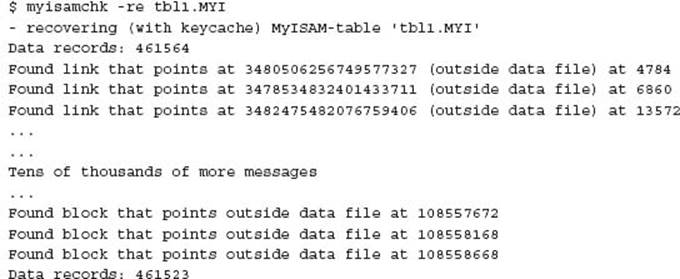
The number of data records has decreased again from 461,818 originally to 461,523, an indication that perhaps corrupted data has been removed.
At this time, the best approach is to try and obtain as much data as possible by extracting data.

This more in-depth approach to try and recover data has also failed.
A Failed Database Backup
There is now no other option than to perform a database restore from the previous night’s backup. This, however, failed with the following problems:
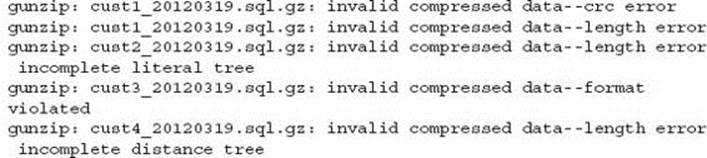
Some 25% of individual schema backup files failed to uncompress on both the production server and a remote server containing the backup files. What was interesting was the variety of different error messages. The customer was now forced with considering an older backup.
TIP Testing your backup on an external system is important to ensure corruption is not occurring at the time of your backup.
Detecting Hardware Faults
In isolated situations and when other plausible explanations are exhausted, faulty hardware can be the issue. During this data restore process other symptoms of slow performance, especially compressing the original data, and some of the unexplained outcomes shown indicated a possible hardware error. The system log showed no indication of problems to validate this hypothesis; however, in previous situations the end result has been hardware.
During the process of taking additional filesystem backups of the current data and configuration files for contingency, the system failed with a kernel panic. At this time the client was left with no production server, no current backup of data or binary logs, and an uneasy time as the host provider system engineers looked into the problem.
Almost an hour passes before the system is accessible again, and the host provider reports a fault memory error on the console. MySQL is restarted, a myisamchk is performed on the entire database, and several tables require a recover process—all occur without further incident. Another hour later, the database is in what is considered a stable state. A backup is then performed. The client is now convinced of the importance of the need for the process.
NOTE Any organization without an adequate backup and recovery process is at risk for serious business disruption. In this actual example, luck was on their side.
Conclusion
This client backup process had two important flaws. The first was the backup was not checked for any type of error. The uncompressing of backup files was producing errors.
The second flaw was that the binary logs were not being stored on a separate system. If the hardware failure was a disk and not memory, data recovery may have not been possible. Not mentioned in any detail in this example is an additional restore issue where the binary log position was not recorded during the backup.
This is a good working example of the various approaches to attempting to correct a MyISAM database failure. All of these steps were performed with a client that had an emergency and no plan. If you do not have access to expert resources attempting to resolve this type of problem, the likelihood of not exhausting all options increases.
Missing Database Schemas
A client needed to perform a restore from the previous night’s backup. When verifying the recovery process using the most recent customer that had been created, the application was completely crashing when viewing customer information. What happened was one transaction that recorded the customer was included in the backup, and new data for the customer was not included.
The cause was in not understanding that mysqldump does not produce a consistent static backup. Using mysqldump with--all-databases and the implied--lock-tables does not provide a consistent backup. For this disaster, the application would create a new schema for a software as a service model. The first step is recording the new customer in a central master database, then creating a new customer database, starting with the letter c followed by a three letter hash, and finally reporting this has successfully completed.
When mysqldump got to the backup of the master schema, all tables were locked, and the data extracted, including a reference to the new customer schema, was not included in the backup because database schemas are processed sequentially, and locking only occurs on a per schema basis. To better understand the cause, the following example is a look at the actual SQL statements of a mysqldump of the example database environment in Chapter 8. You can capture all SQL statements using the general query log.


A further error was in the application where it was not correctly handling the error of a non-existing database table for a given customer. It was assumed that if the customer could log in, confirming credentials from the master database, that the underlying per customer schema objects already existed.
Restoring a Backup on a Running MySQL Instance
For all restore options except using mysqldump, the process requires the MySQL instance to not be running. When using MySQL Enterprise Backup (MEB), no check is performed to ensure the instance is not running, and it is therefore possible to perform a restore on a running instance. This is likely to result in inconsistent data and a potentially corrupt database. The following occurred while documenting the recovery options described in Chapter 5. This type of problem can also occur with other backup and restore products.
The steps taken were:
1. A backup was performed.
2. A new schema was created (before_restore), an existing schema was dropped (employees), and an individual table was dropped (book2.artist).
3. A restore was performed on a running instance.


A mysqlbackup copy-back as described in Chapter 5 was performed. The following initial SQL statements were run after to initially verify the recovery:

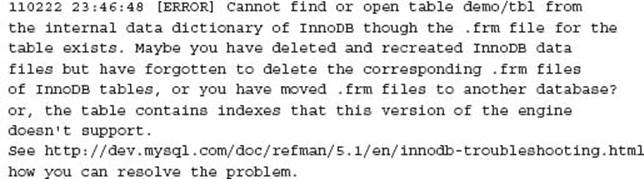
As you can see the employees schema was restored, as well as the table book2.artist; however, the before_restore schema still exists. Further analysis showed the following error on a restored table that appears to exist:
![]()
Investigation of the MySQL error log shows numerous errors to confirm that the restoration failed to complete successfully.
This highlights two practices that are required:
1. Determine the necessary prerequisites for the restore process.
2. Always check the MySQL error log.
![]()
Handling InnoDB Specific Situations
The most commonly used storage engine in MySQL is InnoDB. One of the strengths of InnoDB is the ability to support transactions and the ability to perform automatic crash recovery. What happens when this does not work as designed? This section includes several InnoDB examples:
1. When automatic recovery fails
2. Internal data dictionary corruption
3. InnoDB data recovery
Automatic Recovery
The InnoDB storage engine will automatically perform a crash recovery when necessary, generally when the MySQL instance is not shut down safely. In this example, crash recovery was occurring every time MySQL was started.

While MySQL was cleanly shut down, an automatic crash recovery was being performed. This would take several minutes before the system was available for general use. It is unclear exactly why this problem was occurring. The client reported the situation was the result of an unexpected MySQL instance failure on an Amazon Web Services (AWS) instance running on Elastic Block Storage (EBS).
InnoDB provides for a forced recovery mode, which enables six varying levels of disabling various crash recovery features. In a failed InnoDB crash recovery, you can use each of these modes, starting with 1, to attempt to retrieve as much data as possible. In this example, this configuration option was set to 1.


At this time, the database has successfully started without performing a crash recovery. In any non-zero mode InnoDB will self-protect the data and prevent any modification with INSERT, UPDATE, or DELETE statements. In this example, a clean shutdown, the removal of theinnodb_force_recovery option, and the restarting of MySQL addressed the issue.
InnoDB Data Dictionary Inconsistency
Every table in MySQL has a related table definition file that is located in the schema sub-directory within the data directory of the instance. This is known as an.frm file. In addition, InnoDB holds meta-data within the InnoDB common tablespace (e.g., the ibdata 1 file) about the table definitions.
At times these may appear inconsistent or be inconsistent and report errors similar to:

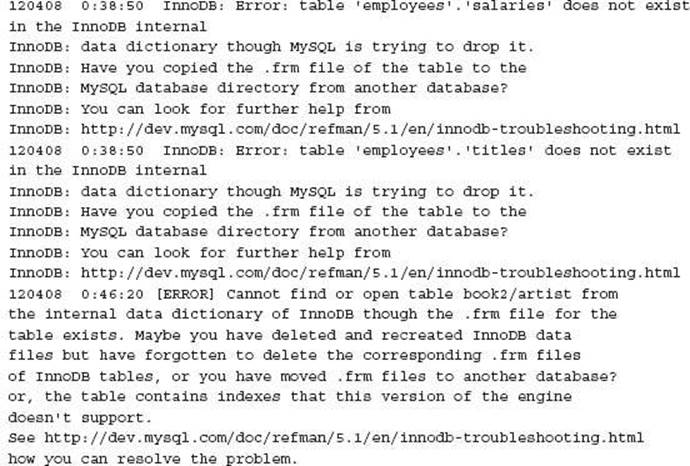
and
These situations occur where the InnoDB tablespace has been rebuilt and the underlying table definitions were in place. Alternatively insufficient file permissions with the MySQL data directory can cause an underlying inconsistency.
Automatic Recovery Crashes the Database Server
The InnoDB storage engine is designed to perform automatic crash recovery. This is possible because the InnoDB transaction logs (redo logs) record all successful transactions that may not have been applied to the underlying InnoDB data. The doublewrite buffer also holds committed data that may not be applied to the same underlying InnoDB data.
When the MySQL instance is started, InnoDB will detect a difference in the Log Sequence Number (LSN) between the InnoDB transaction logs and the InnoDB data. This is an indication that the MySQL instance was not shut down correctly. In this case InnoDB will automatically detect then rectify the situation to produce a consistent view. In the following example this then caused the MySQL server to crash:
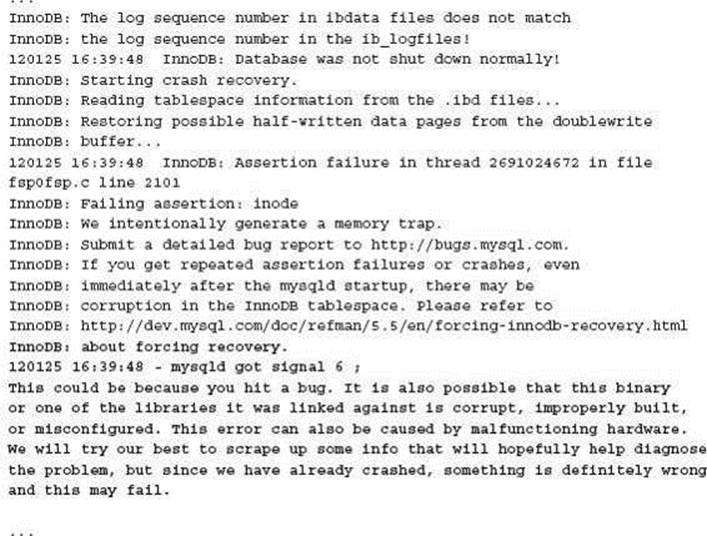
![]()
Other MySQL Situations
The following examples complete some different situations using MySQL:
• Replication inconsistency
• Third party product recovery limitations
Replication Inconsistency
The following error message was discovered on a MySQL replication server:
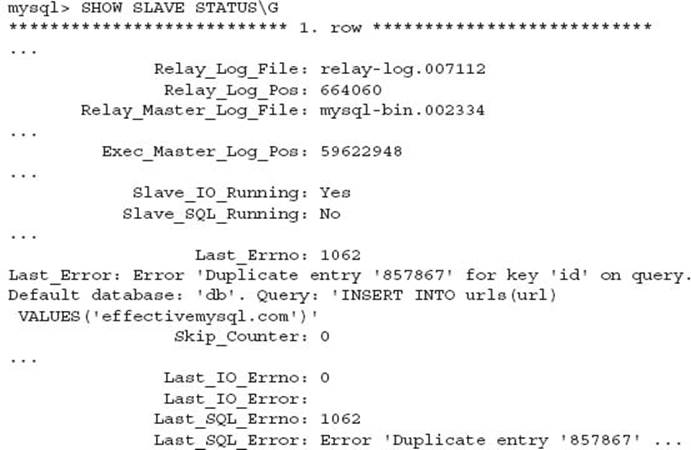
A review of the data on the slave host shows the data for the SQL statement was already applied.

A number of checks were performed to look at the master database and binary logs to confirm this statement only occurred once.
A review of the slave host error log showed that MySQL has recently performed a crash recovery.
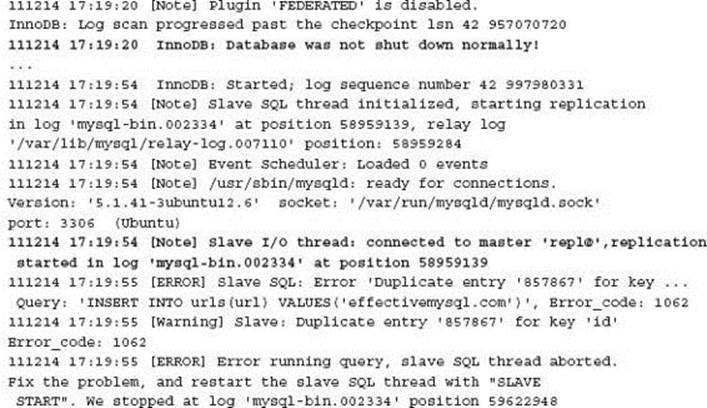
A review of the slave relay log, which details completed SQL statements, showed that this SQL command had actually been executed, yet MySQL replication appeared not to record this. A review of the underlying information file, defined by the relay-log-info-file configuration option, indicated an inconsistency with the error log of the actual master binary log executed log position. The error log indicates that MySQL replication started at the position of 58959139, while the relay log information file shows a different position. This inconsistency was the actual SQL statement that was being reported as the last failure.

As a result, by skipping the SQL statement, the replication slave could be started and continued without incident.
By default the sync_relay_log_info configuration option has a value of 0, which implies the filesystem should flush this file to disk from time to time. In this situation, a database crash caused this file to become inconsistent. More information on this option can be found athttp://dev.mysql.com/doc/refman/5.5/en/replication-options-slave.html#sysvar_sync_relay_log_info.
RDS Recovery Failure
Amazon Web Services (AWS) provides a Remote Database Service (RDS) for MySQL. This is popular when an organization does not have any skills to manage MySQL. This complete packaged solution has several limitations. There is no physical access to the database server. While there are API interfaces to change MySQL configuration settings and look at MySQL error and slow logs, it is not possible to look at the system resources being used, or look at the MySQL binary logs, for example.
An issue arose with a client when a database restore through an RDS snapshot failed. Amazon support informed the client there was some BLOB or TEXT field with bad characters and this prevented mysqlbinlog from performing a successful restoration. They were directed to the following bug: http://bugs.mysql.com/bug.php?id=33048.
The client was looking for a means of tracking down the potential offending records so a database restoration could be performed. First there was no way to confirm this was the actual failure of the restoration, as this third party managed service did not provide access to detailed logs. The listed bug, if this was indeed the true problem, provided two workaround solutions; the first was to analyze the mysqlbinlog output, and then correct if necessary before applying. The second option was to replay the binary log via the replication stream rather than converting to ASCII and then using the mysql client. Both of these options were not possible because the third party did not provide sufficient access. The binary logs, for example, are not accessible.
At this time, the client has no recovery capability. The backup process failed during recovery, and the service provider was both unwilling to help further or provide access to necessary MySQL information to perform more in-depth analysis.
![]()
Common Downtime Causes
What are the most common causes of downtime with MySQL systems? Leading service provider Percona published in the IOUG SELECT magazine, Q1 2011, an article titled “Causes of Downtime in Production MySQL Servers,” which provides a very detailed picture of actual support situations.
One third of all reported downtime was not the result of MySQL in any way. Issues with the storage system were defined as the top factor, with the operating system and networking also attributing to downtime. A SAN or RAID storage system is not a backup solution. The following article by leading PostgreSQL expert Josh Berkus is a great reinforcement of why. In this disaster example, there was not even a physical failure—a vendor-provided firmware update led to eventual total data corruption. More information can be found at http://it.toolbox.com/blogs/database-soup/a-san-is-not-a-highavailability-solution-47644. The Sidekick data disaster as detailed earlier was reported as a SAN upgrade mistake.
CAUTION A RAID system is only as good as the monitoring used to detect a degraded RAID configuration and the time taken to correct the problem. When a service provider, system administrator, or other resource states your data is protected by RAID, ask for proof the RAID system is not degraded. This question is always asked when reviewing a client backup and recovery strategy, and the results observed have been two clients unaware they had degraded production systems.
The whitepaper also shows a breakdown of replication related problems where data drift results in almost 50% of replication issues. The majority of data loss and corruption issues were the result of human factors. An important factor in the management of any system is the result of a failure due to other human factors. The lack of appropriate configuration management, unprepared and untested upgrading, or the lack of performing software upgrades all attribute to controllable situations. An important statement in the prevention of situations that can use a disaster situation clearly highlights a common problem found.
NOTE Quoting from the “Causes of Downtime in Production MySQL Servers” whitepaper: “In most cases, emergencies analyzed could have been prevented best by a systematic, organization-wide effort to find and remove latent problems [before they occur]. Many of the activities involved in this effort could appear to be unproductive, and might be unrewarding for people to do.”
A full copy of the whitepaper is available for download from the Percona website at http://www.percona.com/about-us/mysql-white-paper/causes-of-downtime-in-production-mysql-servers.
![]()
External Help
In some cases, a disaster is correctable. As shown in this chapter, understanding and describing the precise circumstances and seeking input from multiple reputable and experienced resources can be key to avoiding a disaster and career limiting situation. Organizations that provide dedicated MySQL services, that are active in the MySQL community ecosystem, and that are known by this author are included here:
• MySQL technical support services, part of Oracle support services, provides global 24/7 technical support. Details at http://www.mysql.com/support/.
• SkySQL provides world-wide support and services for the MariaDB and MySQL databases. Details at http://www.skysql.com/.
• FromDual provides independent and neutral MySQL, Percona Server, and MariaDB consulting and services. Details at http://fromdual.com/.
• The Pythian Group “love your data” provides remote database services for Oracle, MySQL, and SQL Server. Details at http://www.pythian.com/.
• Blue Gecko provides remote DBA services, database hosting services, and emergency DBA support. Details at http://www.bluegecko.net/.
• Percona provides consulting, support, training, development, and software in MySQL and InnoDB performance. Details at http://www.percona.com/.
• Open Query provides support, training, products, and remote maintenance for MySQL and MariaDB. Details at http://openquery.com/.
• PalominoDB provides remote DBA and system administration services in MySQL, MariaDB, and other open source products. Details at http://palominodb.com/.
• Effective MySQL provides practical education, training, and mentoring resources for MySQL DBAs, developers, and architects. Details at http://effectivemysql.com/.
• Continuent provides continuous data availability and database replication solutions, and provides support managing and running MySQL replication with industry leading experts. Details at http://www.continuent.com/.
Other organizations may state they provide MySQL services. While this list is not exclusive of all possible service providers, these companies are known within the MySQL ecosystem. As with any service you should always independently compare and evaluate for your needs.
![]()
Conclusion
World Backup Day is designated as the 31st of March. The tag line is “Don’t be an April Fool. Back up your data. Check your restores.” More information can be found at http://www.worldbackupday.com/. However, every day is your last day if you do not have a backup and recovery process in place. Disaster recovery (DR) can range from a mildly annoying occurrence to a once in a lifetime tsunami type event. This chapter and this book do not provide all the answers for all situations with a MySQL disaster. This book does provide extensive knowledge and presents all the common options and tools available, with supporting information of situations you should be aware of, plan for, and know how to address when necessary.
Copies of all referenced articles are available on the Effective MySQL website at http://effectivemysql.com/book/backup-recovery/.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.