Apache Flume: Distributed Log Collection for Hadoop, Second Edition (2015)
Chapter 6. Interceptors, ETL, and Routing
The final piece of functionality required in your data processing pipeline is the ability to inspect and transform events in flight. This can be accomplished using interceptors. Interceptors, as we discussed in Chapter 1, Overview and Architecture, can be inserted after a source creates an event, but before writing to the channel occurs.
Interceptors
An interceptor's functionality can be summed up with this method:
public Event intercept(Event event);
A Flume event is passed to it, and it returns a Flume event. It may do nothing, in which case, the same unaltered event is returned. Often, it alters the event in some useful way. If null is returned, the event is dropped.
To add interceptors to a source, simply add the interceptors property to the named source, for example:
agent.sources.s1.interceptors=i1 i2 i3
This defines three interceptors: i1, i2, and i3 on the s1 source for the agent named agent.
Note
Interceptors are run in the order in which they are listed. In the preceding example, i2 will receive the output from i1. Then, i3 will receive the output from i2. Finally, the channel selector receives the output from i3.
Now that we have defined the interceptor by name, we need to specify its type as follows:
agent.sources.s1.interceptors.i1.type=TYPE1
agent.sources.s1.interceptors.i1.additionalProperty1=VALUE
agent.sources.s1.interceptors.i2.type=TYPE2
agent.sources.s1.interceptors.i3.type=TYPE3
Let's look at some of the interceptors that come bundled with Flume to get a better idea of how to configure them.
Timestamp
The Timestamp interceptor, as its name suggests, adds a header with the timestamp key to the Flume event if one doesn't already exist. To use it, set the type property to timestamp.
If the event already contains a timestamp header, it will be overwritten with the current time unless configured to preserve the original value by setting the preserveExisting property to true.
Here is a table summarizing the properties of the Timestamp interceptor:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
timestamp |
|
preserveExisting |
No |
boolean |
false |
Here is what a total configuration for a source might look like if we only want it to add a timestamp header if none exists:
agent.sources.s1.interceptors=i1
agent.sources.s1.interceptors.i1.type=timestamp
agent.sources.s1.interceptors.i1.preserveExisting=true
Recall this HDFSSink path from Chapter 4, Sinks and Sink Processors, utilizing the event date:
agent.sinks.k1.hdfs.path=/logs/apache/%Y/%m/%d/%H
The timestamp header is what determines this path. If it is missing, you can be sure Flume will not know where to create the files, and you will not get the result you are looking for.
Host
Similar in simplicity to the Timestamp interceptor, the Host interceptor will add a header to the event containing the IP address of the current Flume agent. To use it, set the type property to host:
agent.sources.s1.interceptors=i1
agent.sources.s1.interceptors.type=host
The key for this header will be host unless you specify something else using the hostHeader property. Like before, an existing header will be overwritten, unless you set the preserveExisting property to true. Finally, if you want a reverse DNS lookup of the hostname to be used instead of the IP as a value, set the useIP property to false. Remember that reverse lookups will add processing time to your data flow.
Here is a table summarizing the properties of the Host interceptor:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
host |
|
hostHeader |
No |
String |
host |
|
preserveExisting |
No |
boolean |
false |
|
useIP |
No |
boolean |
true |
Here is what a total configuration for a source might look like if we only want it to add a relayHost header containing the DNS hostname of this agent to every event:
agent.sources.s1.interceptors=i1
agent.sources.s1.interceptors.i1.type=host
agent.sources.s1.interceptors.i1.hostHeader=relayHost
agent.sources.s1.interceptors.i1.useIP=false
This interceptor might be useful if you wanted to record the path your events took though your data flow, for instance. Chances are you are more interested in the origin of the event rather than the path it took, which is why I have yet to use this.
Static
The Static interceptor is used to insert a single key/value header into each Flume event processed. If more than one key/value is desired, you simply add additional Static interceptors. Unlike the interceptors we've looked at so far, the default behavior is to preserve existing headers with the same key. As always, my recommendation is to always specify what you want and not rely on the defaults.
I do not know why the key and value properties are not required, as the defaults are not terribly useful.
Here is a table summarizing the properties of the Static interceptor:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
static |
|
key |
No |
String |
key |
|
value |
No |
String |
value |
|
preserveExisting |
No |
boolean |
true |
Finally, let's look at an example configuration that inserts two new headers, provided they don't already exist in the event:
agent.sources.s1.interceptors=pos env
agent.sources.s1.interceptors.pos.type=static
agent.sources.s1.interceptors.pos.key=pointOfSale
agent.sources.s1.interceptors.pos.value=US
agent.sources.s1.interceptors.env.type=static
agent.sources.s1.interceptors.env.key=environment
agent.sources.s1.interceptors.env.value=staging
Regular expression filtering
If you want to filter events based on the content of the body, the regular expression filtering interceptor is your friend. Based on a regular expression you provide, it will either filter out the matching events or keep only the matching events. Start by setting the typeinterceptor to regex_filter. The pattern you want to match is specified using a Java-style regular expression syntax. See these javadocs for usage details at http://docs.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html. The pattern string is set in the regexproperty. Be sure to escape backslashes in Java Strings. For instance, the \d+ pattern would need to be written with two backslashes: \\d+. If you wanted to match a backslash, the documentation says to type two backslashes, but each needs to be escaped, resulting in four, that is, \\\\. You will see the use of escaped backslashes throughout this chapter. Finally, you need to tell the interceptor if you want to exclude matching records by setting the excludeEvents property to true. The default (false) indicates that you want to only keep events that match the pattern.
Here is a table summarizing the properties of the regular expression filtering interceptor:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
regex_filter |
|
regex |
No |
String |
.* |
|
excludeEvents |
No |
boolean |
false |
In this example, any events containing the NullPointerException string will be dropped:
agent.sources.s1.interceptors=npe
agent.sources.s1.interceptors.npe.type=regex_filter
agent.sources.s1.interceptors.npe.regex=NullPointerException
agent.sources.s1.interceptors.npe.excludeEvents=true
Regular expression extractor
Sometimes, you'll want to extract bits of your event body into Flume headers so that you can perform routing via Channel Selectors. You can use the regular expression extractor interceptor to perform this function. Start by setting the type interceptor toregex_extractor:
agent.sources.s1.interceptors=e1
agent.sources.s1.interceptors.e1.type=regex_extractor
Like the regular expression filtering interceptor, the regular expression extractor interceptor too uses a Java-style regular expression syntax. In order to extract one or more fields, you start by specifying the regex property with group matching parentheses. Let's assume we are looking for error numbers in our events in the Error: N form, where N is a number:
agent.sources.s1.interceptors=e1
agent.sources.s1.interceptors.e1.type=regex_extractor
agent.sources.s1.interceptors.e1.regex=Error:\\s(\\d+)
As you can see, I put capture parentheses around the number, which may be one or more digit. Now that I've matched my desired pattern, I need to tell Flume what to do with my match. Here, we need to introduce serializers, which provide a pluggable mechanism for how to interpret each match. In this example, I've only got one match, so my space-separated list of serializer names has only one entry:
agent.sources.s1.interceptors=e1
agent.sources.s1.interceptors.e1.type=regex_extractor
agent.sources.s1.interceptors.e1.regex=Error:\\s(\\d+)
agent.sources.s1.interceptors.e1.serializers=ser1
agent.sources.s1.interceptors.e1.serializers.ser1.type=default
agent.sources.s1.interceptors.e1.serializers.ser1.name=error_no
The name property specifies the event key to use, where the value is the matching text from the regular expression. The type of default value (also the default if not specified) is a simple pass-through serializer. For this event body, look at the following:
NullPointerException: A problem occurred. Error: 123. TxnID: 5X2T9E.
The following header would be added to the event:
{ "error_no":"123" }
If I wanted to add the TxnID value as a header, I'd simply add another matching pattern group and serializer:
agent.sources.s1.interceptors=e1
agent.sources.s1.interceptors.e1.type=regex_extractor
agent.sources.s1.interceptors.e1.regex=Error:\\s(\\d+).*TxnID:\\s(\\w+)
agent.sources.s1.interceptors.e1.serializers=ser1 ser2
agent.sources.s1.interceptors.e1.serializers.ser1.type=default
agent.sources.s1.interceptors.e1.serializers.ser1.name=error_no
agent.sources.s1.interceptors.e1.serializers.ser2.type=default
agent.sources.s1.interceptors.e1.serializers.ser2.name=txnid
Then, I would create these headers for the preceding input:
{ "error_no":"123", "txnid":"5x2T9E" }
However, take a look at what would happen if the fields were reversed as follows:
NullPointerException: A problem occurred. TxnID: 5X2T9E. Error: 123.
I would wind up with only a header for txnid. A better way to handle this kind of ordering would be to use multiple interceptors so that the order doesn't matter:
agent.sources.s1.interceptors=e1 e2
agent.sources.s1.interceptors.e1.type=regex_extractor
agent.sources.s1.interceptors.e1.regex=Error:\\s(\\d+)
agent.sources.s1.interceptors.e1.serializers=ser1
agent.sources.s1.interceptors.e1.serializers.ser1.type=default
agent.sources.s1.interceptors.e1.serializers.ser1.name=error_no
agent.sources.s1.interceptors.e2.type=regex_extractor
agent.sources.s1.interceptors.e2.regex=TxnID:\\s(\\w+)
agent.sources.s1.interceptors.e2.serializers=ser1
agent.sources.s1.interceptors.e2.serializers.ser1.type=default
agent.sources.s1.interceptors.e2.serializers.ser1.name=txnid
The only other type of serializer implementation that ships with Flume, other than the pass-through, is to specify the fully qualified class name of org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer. This serializer is used to convert times into milliseconds. You need to specify a pattern property based on org.joda.time.format.DateTimeFormat patterns.
For instance, let's say you were ingesting Apache Web Server access logs, for example:
192.168.1.42 - - [29/Mar/2013:15:27:09 -0600] "GET /index.html HTTP/1.1" 200 1037
The complete regular expression for this might look like this (in the form of a Java String, with backslash and quotes escaped with an extra backslash):
^([\\d.]+) \\S+ \\S+ \\[([\\w:/]+\\s[+\\-]\\d{4})\\] \"(.+?)\" (\\d{3}) (\\d+)
The time pattern matched corresponds to the org.joda.time.format.DateTimeFormat pattern:
yyyy/MMM/dd:HH:mm:ss Z
Take a look at what would happen if we make our configuration something like this:
agent.sources.s1.interceptors=e1
agent.sources.s1.interceptors.e1.type=regex_extractor
agent.sources.s1.interceptors.e1.regex=^([\\d.]+) \\S+ \\S+ \\[([\\w:/]+\\s[+\\-]\\d{4})\\] \"(.+?)\" (\\d{3}) (\\d+)
agent.sources.s1.interceptors.e1.serializers=ip dt url sc bc
agent.sources.s1.interceptors.e1.serializers.ip.name=ip_address
agent.sources.s1.interceptors.e1.serializers.dt.type=org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer
agent.sources.s1.interceptors.e1.serializers.dt.pattern=dd/MMM/yyyy:HH:mm:ss Z
agent.sources.s1.interceptors.e1.serializers.dt.name=timestamp
agent.sources.s1.interceptors.e1.serializers.url.name=http_request
agent.sources.s1.interceptors.e1.serializers.sc.name=status_code
agent.sources.s1.interceptors.e1.serializers.bc.name=bytes_xfered
This would create the following headers for the preceding sample:
{ "ip_address":"192.168.1.42", "timestamp":"1364588829", "http_request":"GET /index.html HTTP/1.1", "status_code":"200", "bytes_xfered":"1037" }
The body content is unaffected. You'll also notice that I didn't specify default for the other type of serializers, as that is the default.
Note
There is no overwrite checking in this interceptor type. For instance, using the timestamp key will overwrite the event's previous time value if there was one.
You can implement your own serializers for this interceptor by implementing the org.apache.flume.interceptor.RegexExtractorInterceptorSerializer interface. However, if your goal is to move data from the body of an event to the header, you'll probably want to implement a custom interceptor so that you can alter the body contents in addition to setting the header value, otherwise the data will be effectively duplicated.
To summarize, let's review the properties for this interceptor:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
regex_extractor |
|
regex |
Yes |
String |
|
|
serializers |
Yes |
Space-separated list of serializer names |
|
|
serializers.NAME.name |
Yes |
String |
|
|
serializers.NAME.type |
No |
Default or FQCN of implementation |
default |
|
serializers.NAME.PROP |
No |
Serializer-specific properties |
Morphline interceptor
As we saw in Chapter 4, Sinks and Sink Processors, a powerful library of transformations backs the MorphlineSolrSink from the KiteSDK project. It should come as no surprise that you can also use these libraries in many places where you'd be forced to write a custom interceptor. Similar in configuration to its sink counterpart, you only need to specify the Morphline configuration file, and optionally, the Morphline unique identifier (if the configuration specifies more than one Morphline). Here is a summary table of the Flume interceptor configuration:
|
Key |
Required |
Type |
Default |
|
type |
Yes |
String |
org.apache.flume.sink.solr.morphline. MorphlineInterceptor$Builder |
|
morphlineFile |
Yes |
String |
|
|
morphlineId |
No |
String |
Picks the first if not specified and an error if not specified; more than one exists. |
Your Flume configuration might look something like this:
agent.sources.s1.interceptors=i1 m1
agent.sources.s1.interceptors.i1.type=timestamp
agent.sources.s1.interceptors.m1.type=org.apache.flume.sink.solr.morphline.MorphlineInterceptor$Builder
agent.sources.s1.interceptors.m1.morphlineFile=/path/to/morph.conf
agent.sources.s1.interceptors.m1.morphlineId=goMorphy
In this example, we have specified the s1 source on the agent named agent, which contains two interceptors, i1 and m1, processed in that order. The first interceptor is a standard interceptor that inserts a timestamp header if none exists. The second will send the event through the Morphline processor specified by the Morphline configuration file corresponding to the goMorphy ID.
Events processed as an interceptor must only output one event for every input event. If you need to output multiple records from a single Flume event, you must do this in the MorphlineSolrSink. With interceptors, it is strictly one event in and one event out.
The first command will most likely be the readLine command (or readBlob, readCSV, and so on) to convert the event into a Morphline Record. From there, you run any other Morphline commands you like with the final Record at the end of the Morphline chain being converted back into a Flume event. We know from Chapter 4, Sinks and Sink Processors, that the _attachment_body special Record key should be byte[] (the same as the event's body). This means that the last command needs to do the conversion (such astoByteArray or writeAvroToByteArray). All other Record keys are converted to String values and set as headers with the same keys.
Note
Take a look at the reference guide for a complete list of Morphline commands, their properties and usage information at http://kitesdk.org/docs/current/kite-morphlines/morphlinesReferenceGuide.html
The Morphline configuration file syntax has already been discussed in detail in the Morphline configuration file section in Chapter 4, Sinks and Sink Processors.
Custom interceptors
If there is one piece of custom code you will add to your Flume implementation, it will most likely be a custom interceptor. As mentioned earlier, you implement the org.apache.flume.interceptor.Interceptor interface and the associatedorg.apache.flume.interceptor.Interceptor.Builder interface.
Let's say I needed to URLCode my event body. The code would look something like this:
public class URLDecode implements Interceptor {
public void initialize() {}
public Event intercept(Event event) {
try {
byte[] decoded = URLDecoder.decode(new String(event.getBody()), "UTF-8").getBytes("UTF-8");
event.setBody(decoded);
} catch UnsupportedEncodingException e) {
// Shouldn't happen. Fall through to unaltered event.
}
return event;
}
public List<Event> intercept(List<Event> events) {
for (Event event:events) {
intercept(event);
}
return events;
}
public void close() {}
public static class Builder implements Interceptor.Builder {
public Interceptor build() {
return new URLDecode();
}
public void configure(Context context) {}
}
}
Then, to configure my new interceptor, use the fully qualified class name for the Builder class as the type:
agent.sources.s1.interceptors=i1
agent.sources.s1.interceptors.i1.type=com.example.URLDecoder$Builder
For more examples of how to pass and validate properties, look at any of the existing interceptor implementations in the Flume source code.
Keep in mind that any heavy processing in your custom interceptor can affect the overall throughput, so be mindful of object churn or computationally intensive processing in your implementations.
The plugins directory
Custom code (sources, interceptors, and so on) can always be installed alongside the Flume core classes in the $FLUME_HOME/lib directory. You could also specify additional paths for CLASSPATH on startup by way of the flume-env.sh shell script (which is often sourced at startup time when using a packaged distribution of Flume). Starting with Flume 1.4, there is now a command-line option to specify a directory that contains the custom code. By default, if not specified, the $FLUME_HOME/plugins.d directory is used, but you can override this using the --plugins-path command-line parameter.
Within this directory, each piece of custom code is separated into a subdirectory whose name is of your choosing—pick something easy for you to keep track of things. In this directory, you can include up to three subdirectories: lib, libext, and native.
The lib directory should contain the JAR file for your custom component. Any dependencies it uses should be added to the libext subdirectory. Both of these paths are added to the Java CLASSPATH variable at startup.
Tip
The Flume documentation implies that this directory separation by component allows for conflicting Java libraries to coexist. In truth, this is not possible unless the underlying implementation makes use of different class loaders within the JVM. In this case, the Flume startup code simply appends all of these paths to the startup CLASSPATH variable, so the order in which the subdirectories are processed will determine the precedence. You cannot even be guaranteed that the subdirectories will be processed in a lexicographic order, as the underlying bash shell for loop can give no such guarantees. In practice, you should always try and avoid conflicting dependencies. Code that depends too much on ordering tends to be buggy, especially if your classpath reorders itself from server installation to server installation.
The third directory, native, is where you put any native libraries associated with your custom component. This path, if it exists, gets added to LD_LIBRARY_PATH at startup so that the JVM can locate these native components.
So, if I had three custom components, my directory structure might look something like this:
$FLUME_HOME/plugins.d/base64-enc/lib/base64interceptor.jar
$FLUME_HOME/plugins.d/base64-enc/libext/base64-2.0.0.jar
$FLUME_HOME/plugins.d/base64-enc/native/libFoo.so
$FLUME_HOME/plugins.d/uuencode/lib/uuEncodingInterceptor.jar
$FLUME_HOME/plugins.d/my-avro-serializer/myAvroSerializer.jar
$FLUME_HOME/plugins.d/my-avro-serializer/native/libAvro.so
Keep in mind that all these paths get mashed together at startup, so conflicting versions of libraries should be avoided. This structure is an organization mechanism for ease of deployment for humans. Personally, I have not used it yet, as I use Chef (or Puppet) to install custom components on my Flume agents directly into $FLUME_HOME/lib, but if you prefer to use this mechanism, it is available.
Tiering flows
In Chapter 1, Overview and Architecture, we talked about tiering your data flows. There are several reasons for you to want to do this. You may want to limit the number of Flume agents that directly connect to your Hadoop cluster, to limit the number of parallel requests. You may also lack sufficient disk space on your application servers to store a significant amount of data while you are performing maintenance on your Hadoop cluster. Whatever your reason or use case, the most common mechanism to chain Flume agents is to use the Avro source/sink pair.
The Avro source/sink
We covered Avro a bit in Chapter 4, Sinks and Sink Processors, when we discussed how to use it as an on-disk serialization format for files stored in HDFS. Here, we'll put it to use in communication between Flume agents. A typical configuration might look something like this:
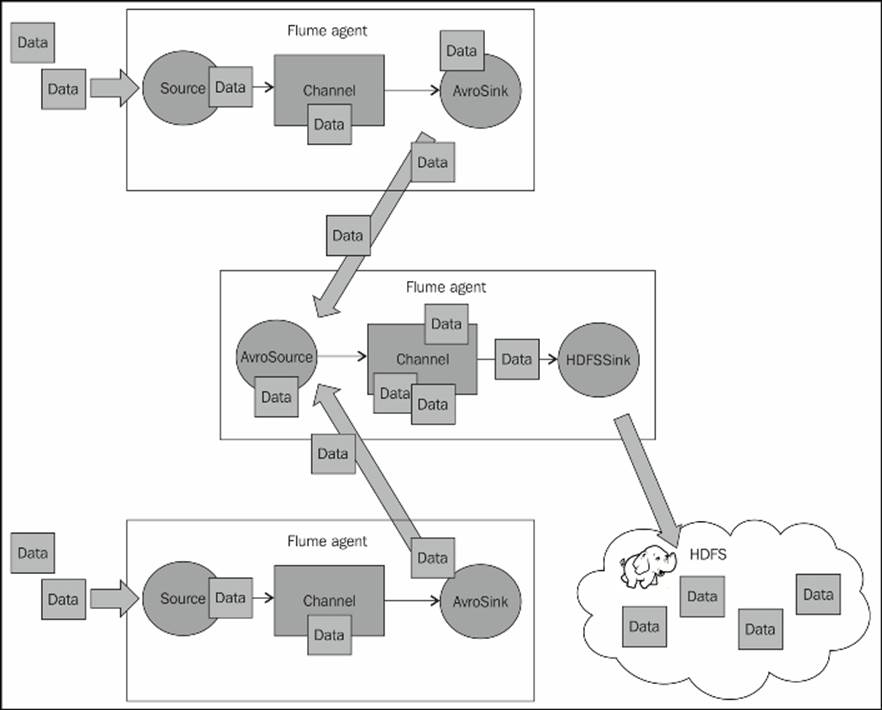
To use the Avro source, you specify the type property with a value of avro. You need to provide a bind address and port number to listen on:
collector.sources=av1
collector.sources.av1.type=avro
collector.sources.av1.bind=0.0.0.0
collector.sources.av1.port=42424
collector.sources.av1.channels=ch1
collector.channels=ch1
collector.channels.ch1.type=memory
collector.sinks=k1
collector.sinks.k1.type=hdfs
collector.sinks.k1.channel=ch1
collector.sinks.k1.hdfs.path=/path/in/hdfs
Here, we have configured the agent in the middle that listens on port 42424, uses a memory channel, and writes to HDFS. I've used the memory channel for brevity in this example configuration. Also note that I've given this agent a different name, collector, just to avoid confusion.
The agents on the top and bottom sides feeding the collector tier might have a configuration similar to this. I have left the sources off this configuration for brevity:
client.channels=ch1
client.channels.ch1.type=memory
client.sinks=k1
client.sinks.k1.type=avro
client.sinks.k1.channel=ch1
client.sinks.k1.hostname=collector.example.com
client.sinks.k1.port=42424
The hostname, collector.example.com, has nothing to do with the agent name on this machine; it is the hostname (or you can use an IP) of the target machine with the receiving Avro source. This configuration, named client, would be applied to both agents on the top and bottom sides, assuming both had similar source configurations.
As I don't like single points of failure, I would configure two collector agents with the preceding configuration and instead, set each client agent to round robin between the two, using a sink group. Again, I've left off the sources for brevity:
client.channels=ch1
client.channels.ch1.type=memory
client.sinks=k1 k2
client.sinks.k1.type=avro
client.sinks.k1.channel=ch1
client.sinks.k1.hostname=collectorA.example.com
client.sinks.k1.port=42424
client.sinks.k2.type=avro
client.sinks.k2.channel=ch1
client.sinks.k2.hostname=collectorB.example.com
client.sinks.k2.port=42424
client.sinkgroups=g1
client.sinkgroups.g1=k1 k2
client.sinkgroups.g1.processor.type=load_balance
client.sinkgroups.g1.processor.selector=round_robin
client.sinkgroups.g1.processor.backoff=true
There are four additional properties associated with the Avro sink that you may need to adjust from their sensible defaults.
The first is the batch-size property, which defaults to 100. In heavy loads, you may see better throughput by setting this higher, for example:
client.sinks.k1.batch-size=1024
The next two properties control network connection timeouts. The connect-timeout property, which defaults to 20 seconds (specified in milliseconds), is the amount of time required to establish a connection with an Avro source (receiver). The related request-timeoutproperty, which also defaults to 20 seconds (specified in milliseconds), is the amount of time for a sent message to be acknowledged. If I wanted to increase these values to 1 minute, I could add these additional properties:
client.sinks.k1.connect-timeout=60000
client.sinks.k1.request-timeout=60000
Finally, the reset-connection-interval property can be set to force connections to reestablish themselves after some time period. This can be useful when your sink is connecting through a VIP (Virtual IP Address) or hardware load balancer to keep things balanced, as services offered behind the VIP may change over time due to failures or changes in capacity. By default, the connections will not be reset except in cases of failure. If you wanted to change this so that the connections reset themselves every hour, for example, you can specify this by setting this property with the number of seconds, as follows:
client.sinks.k1.reset-connection-interval=3600
Compressing Avro
Communication between the Avro source and sink can be compressed by setting the compression-type property to deflate. On the Avro sink, you can additionally, set the compression-level property to a number between 1 and 9, with the default being 6. Typically, there are diminishing returns at higher compression levels, but testing may prove a nondefault value that works better for you. Clearly, you need to weigh the additional CPU costs against the overhead to perform a higher level of compression. Typically, the default is fine.
Compressed communications are especially important when you are dealing with high latency networks, such as sending data between two data centers. Another common use case for compression is where you are charged for the bandwidth consumed, such as most public cloud services. In these cases, you will probably choose to spend CPU cycles, compressing and decompressing your flow rather than sending highly compressible data uncompressed.
Tip
It is very important that if you set the compression-type property in a source/sink pair, you set this property at both ends. Otherwise, a sink could be sending data the source can't consume.
Continuing the preceding example, to add compression, you would add these additional property fields on both agents:
collector.sources.av1.compression-type=deflate
client.sinks.k1.compression-type=deflate
client.sinks.k1.compression-level=7
client.sinks.k2.compression-type=deflate
client.sinks.k2.compression-level=7
SSL Avro flows
Sometimes, communication is of a sensitive nature or may traverse untrusted network paths. You can encrypt your communications between an Avro sink and an Avro source by setting the ssl property to true. Additionally, you will need to pass SSL certificate information to the source (the receiver) and optionally, the sink (the sender).
I won't claim to be an expert in SSL and SSL certificates, but the general idea is that a certificate can either be self-signed or signed by a trusted third party such as VeriSign (called a certificate authority or CA). Generally, because of the cost associated with getting a verified certificate, people only do this for web browser certificates a customer might see in a web browser. Some organizations will have an internal CA who can sign certificates. For the purpose of this example, we'll be using self-signed certificates. This basically means that we'll generate a certificate but not have it signed by any authority. For this, we'll use the keytool utility that comes with all Java installations (the reference can be found at http://docs.oracle.com/javase/7/docs/technotes/tools/solaris/keytool.html). Here, I create a Java Key Store (JKS) file that contains a 2048 bit key. When prompted for a password, I'll use the password string. Make sure you use a real password in your nontest environments:
% keytool -genkey -alias flumey -keyalg RSA -keystore keystore.jks -keysize 2048
Enter keystore password: password
Re-enter new password: password
What is your first and last name?
[Unknown]: Steve Hoffman
What is the name of your organizational unit?
[Unknown]: Operations
What is the name of your organization?
[Unknown]: Me, Myself and I
What is the name of your City or Locality?
[Unknown]: Chicago
What is the name of your State or Province?
[Unknown]: Illinois
What is the two-letter country code for this unit?
[Unknown]: US
Is CN=Steve Hoffman, OU=Operations, O="Me, Myself and I", L=Chicago, ST=Illinois, C=US correct?
[no]: yes
Enter key password for <flumey>
(RETURN if same as keystore password):
I can verify the contents of the JKS by running the list subcommand:
% keytool -list -keystore keystore.jks
Enter keystore password: password
Keystore type: JKS
Keystore provider: SUN
Your keystore contains 1 entry
flumey, Nov 11, 2014, PrivateKeyEntry, Certificate fingerprint (SHA1): 5C:BC:3C:7F:7A:E7:77:EB:B5:54:FA:E2:8B:DD:D3:66:36:86:DE:E4
Now that I have a key in my keystore file, I can set the additional properties on the receiving source:
collector.sources.av1.ssl=true
collector.sources.av1.keystore=/path/to/keystore.jks
collector.sources.av1.keystore-password=password
As I am using a self-signed certificate, the sink won't be sure that communications can be trusted, so I have two options. The first is to tell it to just trust all certificates. Clearly, you would only do this on a private network that has some reasonable assurances about its security. To ignore the dubious origin of my certificate, I can set the trust-all-certs property to true as follows:
client.sinks.k1.ssl=true
client.sinks.k1.trust-all-certs=true
If you didn't set this, you'd see something like this in the logs:
org.apache.flume.EventDeliveryException: Failed to send events
...
Caused by: javax.net.ssl.SSLHandshakeException: General SSLEngine problem
...
Caused by: sun.security.validator.ValidatorException: No trusted certificate found
...
For communications over the public Internet or in multitenant cloud environments, more care should be taken. In this case, you can provide a truststore to the sink. A truststore is similar to a keystore, except that it contains certificate authorities you are telling Flume can be trusted. For well-known certificate authorities, such as VeriSign and others, you don't need to specify a truststore, as their identities are already included in your Java distribution (at least for the major ones). You will need to have your certificate signed by a certificate authority and then add the signed certificate file to the source's keystore file. You will also need to include the signing CA's certificate in the keystore so that the certificate chain can be fully resolved.
Once you have added the key, signed certificate, and signing CA's certificate to the source, you need to configure the sink (the sender) to trust these authorities so that it will pass the validation step during the SSL handshake. To specify the truststore, set thetruststore and truststore-password properties as follows:
client.sinks.k1.ssl=true
client.sinks.k1.truststore=/path/to/truststore.jks
client.sinks.k1.truststore-password=password
Chances are there is somebody in your organization responsible for obtaining the third-party certificates or someone who can issue an organizational CA-signed-certificate to you, so I'm not going to go into details about how to create your own certificate authority. There is plenty of information on the Internet if you choose to take this route. Remember that certificates have an expiration date (usually, a year), so you'll need to repeat this process every year or communications will abruptly stop when certificates or certificate authorities expire.
The Thrift source/sink
Another source/sink pair you can use to tier your data flows is based on Thrift (http://thrift.apache.org/). Unlike Avro data, which is self-documenting, Thrift uses an external schema, which can be compiled into just about every programming language on the planet. The configuration is almost identical to the Avro example already covered. The preceding collector configuration that uses Thrift would now look something like this:
collector.sources=th1
collector.sources.th1.type=thrift
collector.sources.th1.bind=0.0.0.0
collector.sources.th1.port=42324
collector.sources.th1.channels=ch1
collector.channels=ch1
collector.channels.ch1.type=memory
collector.sinks=k1
collector.sinks.k1.type=hdfs
collector.sinks.k1.channel=ch1
collector.sinks.k1.hdfs.path=/path/in/hdfs
There is one additional property that sets the maximum worker threads in the underlying thread pool. If unset, a value of zero is assumed, which makes the thread pool unbounded, so you should probably set this in your production configurations. Testing should provide you with a reasonable upper limit for your environment. To set the thread pool size to 10, for example, you would add the threads property:
collector.source.th1.threads=10
The "client" agents would use the corresponding Thrift sink as follows:
client.channels=ch1
client.channels.ch1.type=memory
client.sinks=k1
client.sinks.k1.type=thrift
client.sinks.k1.channel=ch1
client.sinks.k1.hostname=collector.example.com
client.sinks.k1.port=42324
Like its Avro counterpart, there are additional settings for the batch size, connection timeouts, and connection reset intervals that you may want to adjust based on your testing results. Refer to the The Avro source/sink section earlier in this chapter for details.
Using command-line Avro
The Avro source can also be used in conjunction with one of the command-line options you may have noticed back in Chapter 2, A Quick Start Guide to Flume. Rather than running flume-ng with the agent parameter, you can pass the avro-client parameter to send one or more files to an Avro source. These are the options specific to avro-client from the help text:
avro-client options:
--dirname <dir> directory to stream to avro source
--host,-H <host> hostname to which events will be sent (required)
--port,-p <port> port of the avro source (required)
--filename,-F <file> text file to stream to avro source [default: std input]
--headerFile,-R <file> headerFile containing headers as key/value pairs on each new line
--help,-h display help text
This variation is very useful for testing, resending data manually due to errors, or importing older data stored elsewhere.
Just like an Avro sink, you have to specify the hostname and port you will be sending data to. You can send a single file with the --filename option or all the files in a directory with the --dirname option. If you specify neither of these, stdin will be used. Here is how you might send a file named foo.log to the Flume agent we previously configured:
$ ./flume-ng avro-client --filename foo.log --host collector.example.com --port 42424
Each line of the input will be converted into a single Flume event.
Optionally, you can specify a file containing key/value pairs to set Flume header values. The file uses Java property file syntax. Suppose I had a file named headers.properties containing:
pointOfSale=US
environment=staging
Then, including the --headerFile option would set these two headers on every event created:
$ ./flume-ng avro-client --filename foo.log --headerFile headers.properties --host collector.example.com --port 42424
The Log4J appender
As we discussed in Chapter 5, Sources and Channel Selectors, there are issues that may arise from using a filesystem file as a source. One way to avoid this problem is to use the Flume Log4J Appender in your Java application(s). Under the hood, it uses the same Avro communication that the Avro sink uses, so you need only configure it to send data to an Avro source.
The Appender has two properties, which are shown here in XML:
<appender name="FLUME" class="org.apache.flume.clients.log4jappender.Log4jAppender">
<param name="Hostname" value="collector.example.com"/>
<param name="Port" value="42424"/>
</appender>
The format of the body will be dictated by the Appender's configured layout (not shown). The log4j fields that get mapped to Flume headers are summarized in this table:
|
Flume header key |
Log4J logging event field |
|
flume.client.log4j.logger.name |
event.getLoggerName() |
|
flume.client.log4j.log.level |
event.getLevel() as a number. See org.apache.log4j.Level for mappings. |
|
flume.client.log4j.timestamp |
event.getTimeStamp() |
|
flume.client.log4j.message.encoding |
N/A—always UTF8 |
|
flume.client.log4j.logger.other |
Will only see this if there was a problem mapping one of the above fields, so normally, this won't be present. |
Refer to http://logging.apache.org/log4j/1.2/ for more details on using Log4J.
You will need to include the flume-ng-sdk JAR in the classpath of your Java application at runtime to use Flume's Log4J Appender.
Keep in mind that if there is a problem sending data to the Avro source, the appender will throw an exception and the log message will be dropped, as there is no place to put it. Keeping it in memory could quickly overload your JVM heap, which is usually considered worse than dropping the data record.
The Log4J load-balancing appender
I'm sure you noticed that the preceding Log4j Appender only has a single hostname/port in its configuration. If you wanted to spread the load across multiple collector agents, either for additional capacity or for fault tolerance, you can use theLoadBalancingLog4jAppender. This appender has a single required property named Hosts, which is a space-separated list of hostnames and port numbers separated by a colon, as follows:
<appender name="FLUME" class="org.apache.flume.clients.log4jappender.LoadBalancingLog4jAppender">
<param name="Hosts" value="server1:42424 server2:42424"/>
</appender>
There is an optional property, Selector, which specifies the method that you want to load balance. Valid values are RANDOM and ROUND_ROBIN. If not specified, the default is ROUND_ROBIN. You can implement your own selector, but that is outside the scope of this book. If you are interested, go have a look at the well-documented source code for the LoadBalancingLog4jAppender class.
Finally, there is another optional property to override the maximum time for exponential back off when a server cannot be contacted. Initially, if a server cannot be contacted, 1 second will need to pass before that server is tried again. Each time the server is unavailable, the retry time doubles, up to a default maximum of 30 seconds. If we wanted to increase this maximum to 2 minutes, we can specify a MaxBackoff property in milliseconds as follows:
<appender name="FLUME" class="org.apache.flume.clients.log4jappender.LoadBalancingLog4jAppender">
<param name="Hosts" value="server1:42424 server2:42424"/>
<param name="Selector" value="RANDOM"/>
<param name="MaxBackoff" value="120000"/>
</appender>
In this example, we have also overridden the default round_robin selector to use a random selection.
The embedded agent
If you are writing a Java program that creates data, you may choose to send the data directly as structured data using a special mode of Flume called the Embedded Agent. It is basically a simple single source/single channel Flume agent that you run inside your JVM.
There are benefits and drawbacks to this approach. On the positive side, you don't need to monitor an additional process on your servers to relay data. The embedded channel also allows for the data producer to continue executing its code immediately after queuing the event to the channel. The SinkRunner thread handles taking events from the channel and sending them to the configured sinks. Even if you didn't use embedded Flume to perform this handoff from the calling thread, you would most likely use some kind of synchronized queue (such as BlockingQueue) to isolate the sending of the data from the main execution thread. Using Embedded Flume provides the same functionality without having to worry whether you've written your multithreaded code correctly.
The major drawback to embedding Flume in your application is added memory pressure on your JVM's garbage collector. If you are using an in-memory channel, any unsent events are held in the heap and get in the way of cheap garbage collection by way of short-lived objects. However, this is why you set a channel size: to keep the maximum memory footprint to a known quantity. Furthermore, any configuration changes will require an application restart, which can be problematic if your overall system doesn't have sufficient redundancy built in to tolerate restarts.
Configuration and startup
Assuming you are not dissuaded (and you shouldn't be), you will first need to include the flume-ng-embedded-agent library (and dependencies) into your Java project. Depending on what build system you are using (Maven, Ivy, Gradle, and so on), the exact format will differ, so I'll just show you the Maven configuration here. You can look up the alternative formats at http://mvnrepository.com/:
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-embedded-agent</artifactId>
<version>1.5.2</version>
</dependency>
Start by creating an EmbeddedAgent object in your Java code by calling the constructor (and passing a string name—used only in error messages):
EmbeddedAgent toHadoop = new EmbeddedAgent("myData");
Next, you have to set properties for the channel, sinks, and sink processor via the configure() method, as shown in this example. Most of this configuration should look very familiar to you at this point:
Map<String,String> config = new HashMap<String, String>;
config.put("channel.type","memory");
config.put("channel.capacity", "75");
config.put("sinks", "s1 s2");
config.put("sink.s1.type", "avro");
config.put("sink.s1.hostname", "foo.example.com");
config.put("sink.s1.port", "12345");
config.put("sink.s1.compression-type", "deflate");
config.put("sink.s2.type", "avro");
config.put("sink.s2.hostname", "bar.example.com");
config.put("sink.s2.port", "12345");
config.put("sink.s2.compression-type", "deflate");
config.put("processor.type", "failover");
config.put("processor.priority.s1", "10");
config.put("processor.priority.s2", "20");
toHadoop.configure(config);
Here, we define a memory channel with a capacity of 75 events along with two Avro sinks in an active/standby configuration (first, to foo.example.com, and if that fails, to bar.example.com) using Avro serialization with compression. Refer to Chapter 3, Channels, for specific settings for memory- or file-backed channel properties.
The sink processor only comes into play if you have more than one sink defined in your sinks property. Unlike the optional sink groups options covered in Chapter 4, Sinks and Sink Processors, you need to specify a sink list, even if it is just one. Clearly, there is no behavior difference between failover and load balance when there is only once sink. Refer to each specific sink's properties in Chapter 4, Sinks and Sink Processors, for specific configuration parameters.
Finally, before you start using this agent, you need to call the start() method to instantiate everything based on your properties and start all the background processing threads as follows:
toHadoop.start();
The class is now ready to start receiving and forwarding data.
You'll want to keep a reference to this object around for cleanup later, as well as to pass it to other objects that will be sending data as the underlying channel provides thread safety. Personally, I use Spring Framework's dependency injection to configure and pass references at startup rather than doing it programmatically, as I've shown in this example. Refer to the Spring website for more information (http://spring.io/), as proper use of Spring is a whole book unto itself, and it is not the only dependency injection framework available to you.
Sending data
Data can be sent either as single events or in batches. Batches can sometimes be more efficient in high volume data streams.
To send a single event, just call the put() method, as shown in this example:
Event e = EventBuilder.withBody("Hello Hadoop", Charset.forName("UTF8");
toHadoop.put(e);
Here, I'm using one of many methods available on the org.apache.flume.event.EventBuilder class. Here is a complete list of methods you can use to construct events with this helper class:
EventBuilder.withBody(byte[] body, Map<String, String> headers);
EventBuilder.withBody(byte[] body);
EventBuilder.withBody(String body, Charset charset, Map<String, String> headers);
EventBuilder.withBody(String body, Charset charset);
In order to send several events in one batch, you can call the putAll() method with a list of events, as shown in this example, which also includes a time header:
Map<String,String> headers = new HashMap<String,String>;
headers.put("timestamp",Long.toString(System.currentTimeMillis());
List<Event> events = new ArrayList<Event>;
events.add(EventBuilder.withBody("First".getBytes("UTF-8"), headers);
events.add(EventBuilder.withBody("Second".getBytes("UTF-8"), headers);
toHadoop.putAll(events);
As interceptors are not supported, you will need to add any headers you want to add to the events programmatically in Java before you call put() or putAll().
Shutdown
Finally, as there are background threads waiting for data to arrive on your embedded channel which are most likely holding persistent connections to configured destinations, when it is time to shut down your application, you'll want to have Flume do its cleanup as well. You simply call the stop() method on the configured Embedded Agent as follows:
toHadoop.stop();
Routing
The routing of data to different destinations based on content should be fairly straightforward now that you've been introduced to all the various mechanisms in Flume.
The first step is to get the data you want to switch on into a Flume header by means of a source-side interceptor if the header isn't already available. The second step is to use a Multiplexing Channel Selector on that header value to switch the data to an alternate channel.
For instance, let's say you wanted to capture all exceptions to HDFS. In this configuration, you can see events coming in on the s1 source via avro on port 42424. The event is tested to see whether the body contains the text Exception. If it does, it creates anexception header key (with the value of Exception). This header is used to switch these events to channel c1, and ultimately, HDFS. If the event didn't match the pattern, it would not have the exception header and would get passed to the c2 channel via the default selector where it would be forwarded via Avro serialization to port 12345 on server foo.example.com:
agent.sources=s1
agent.sources.s1.type=avro
agent.sources.s1.bind=0.0.0.0
agent.sources.s1.port=42424
agent.sources.s1.interceptors=i1
agent.sources.s1.interceptors.i1.type=regex_extractor
agent.sources.s1.interceptors.i1.regex=(Exception)
agent.sources.s1.interceptors.i1.serializers=ex
agent.sources.s1.intercetpros.i1.serializers.ex.name=exception
agent.sources.s1.selector.type=multiplexing
agent.sources.s1.selector.header=exception
agent.sources.s1.selector.mapping.Exception=c1
agent.sources.s1.selector.default=c2
agent.channels=c1 c2
agent.channels.c1.type=memory
agent.channels.c2.type=memory
agent.sinks=k1 k2
agent.sinks.k1.type=hdfs
agent.sinks.k1.channel=c1
agent.sinks.k1.hdfs.path=/logs/exceptions/%y/%M/%d/%H
agent.sinks.k2.type=avro
agent.sinks.k2.channel=c2
agent.sinks.k2.hostname=foo.example.com
agent.sinks.k2.port=12345
Summary
In this chapter, we covered various interceptors shipped with Flume, including:
· Timestamp: These are used to add a timestamp header, possibly overwriting an existing one.
· Host: This is used to add the Flume agent hostname or IP as a header in the event.
· Static: This is used to add static String headers.
· Regular expression filtering: This is used to include or exclude events based on a matched regular expression.
· Regular expression extractor: This is used to create headers from matched regular expressions. It's useful for routing with Channel Selectors.
· Morphline: This is used to delegate transformation to a Morphline command chain.
· Custom: This is used to create any custom transformations you need that you can't find elsewhere.
We also covered tiering data flows using the Avro source and sink. Optional compression and SSL with Avro flows were covered as well. Finally, Thrift sources and sinks were briefly covered, as some environments may already have Thrift data flows to integrate with.
Next, we introduced two Log4J Appenders, a single path and a load-balancing version, for direct integration with Java applications.
The Embedded Flume Agent was covered for those wishing to directly integrate basic Flume functionality into their Java applications.
Finally, we gave you an example of using interceptors in conjunction with a Channel Selector to provide routing decision logic.
In the next chapter, we will dive into an example to stitch together everything we have covered so far.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.