Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2 (2014)
4. Functional Overview of YARN Components
YARN relies on three main components for all of its functionality. The first component is the ResourceManager (RM), which is the arbitrator of all cluster resources. It has two parts: a pluggable scheduler and an ApplicationManager that manages user jobs on the cluster. The second component is the per-node NodeManager (NM), which manages users’ jobs and workflow on a given node. The central ResourceManager and the collection of NodeManagers create the unified computational infrastructure of the cluster. The third component is the ApplicationMaster, a user job life-cycle manager. The ApplicationMaster is where the user application resides. Together, these three components provide a very scalable, flexible, and efficient environment to run virtually any type of large-scale data processing jobs.
Architecture Overview
The central ResourceManager runs as a standalone daemon on a dedicated machine and acts as the central authority for allocating resources to the various competing applications in the cluster. The ResourceManager has a central and global view of all cluster resources and, therefore, can provide fairness, capacity, and locality across all users. Depending on the application demand, scheduling priorities, and resource availability, the ResourceManager dynamically allocates resource containers to applications to run on particular nodes. A container is a logical bundle of resources (e.g., memory, cores) bound to a particular cluster node. To enforce and track such assignments, the ResourceManager interacts with a special system daemon running on each node called the NodeManager. Communications between the ResourceManager and NodeManagers are heartbeat based for scalability. NodeManagers are responsible for local monitoring of resource availability, fault reporting, and container life-cycle management (e.g., starting and killing jobs). The ResourceManager depends on the NodeManagers for its “global view” of the cluster.
User applications are submitted to the ResourceManager via a public protocol and go through an admission control phase during which security credentials are validated and various operational and administrative checks are performed. Those applications that are accepted pass to the scheduler and are allowed to run. Once the scheduler has enough resources to satisfy the request, the application is moved from an accepted state to a running state. Aside from internal bookkeeping, this process involves allocating a container for the ApplicationMaster and spawning it on a node in the cluster. Often called “container 0,” the ApplicationMaster does not get any additional resources at this point and must request and release additional containers.
The ApplicationMaster is the “master” user job that manages all life-cycle aspects, including dynamically increasing and decreasing resources consumption (i.e., containers), managing the flow of execution (e.g., in case of MapReduce jobs, running reducers against the output of maps), handling faults and computation skew, and performing other local optimizations. The ApplicationMaster is designed to run arbitrary user code that can be written in any programming language, as all communication with the ResourceManager and NodeManager is encoded using extensible network protocols (i.e., Google Protocol Buffers, http://code.google.com/p/protobuf/).
YARN makes few assumptions about the ApplicationMaster, although in practice it expects most jobs will use a higher-level programming framework. By delegating all these functions to ApplicationMasters, YARN’s architecture gains a great deal of scalability, programming model flexibility, and improved user agility. For example, upgrading and testing a new MapReduce framework can be done independently of other running MapReduce frameworks.
Typically, an ApplicationMaster will need to harness the processing power of multiple servers to complete a job. To achieve this, the ApplicationMaster issues resource requests to the ResourceManager. The form of these requests includes specification of locality preferences (e.g., to accommodate HDFS use) and properties of the containers. The ResourceManager will attempt to satisfy the resource requests coming from each application according to availability and scheduling policies. When a resource is scheduled on behalf of an ApplicationMaster, the ResourceManager generates a lease for the resource, which is acquired by a subsequent ApplicationMaster heartbeat. A token-based security mechanism guarantees its authenticity when the ApplicationMaster presents the container lease to the NodeManager. In MapReduce, the code running in the container can be a map or a reduce task. Commonly, running containers will communicate with the ApplicationMaster through an application-specific protocol to report status and health information and to receive framework-specific commands. In this way, YARN provides a basic infrastructure for monitoring and life-cycle management of containers, while application-specific semantics are managed independently by each framework. This design is in sharp contrast to the original Hadoop version 1 design, in which scheduling was designed and integrated around managing only MapReduce tasks.
Figure 4.1 illustrates the relationship between the application and YARN components. The YARN components appear as the large outer boxes (ResourceManager and NodeManagers), and the two applications appear as smaller boxes (Containers), one dark and one light. Each application uses a different ApplicationMaster; the darker client is running a Message Passing Interface (MPI) application and the lighter client is running a MapReduce application.
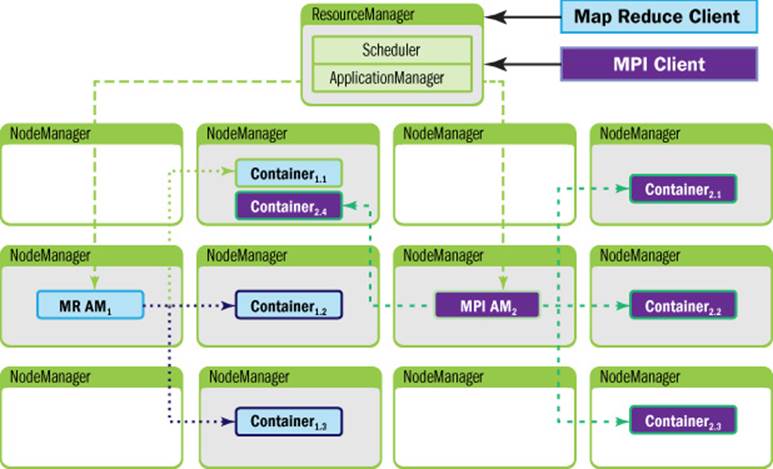
Figure 4.1 YARN architecture with two clients (MapReduce and MPI). The client MPI AM2 is running an MPI application and the client MR AM1 is running a MapReduce application.
ResourceManager
As previously described, the ResourceManager is the master that arbitrates all the available cluster resources, thereby helping manage the distributed applications running on the YARN system. It works together with the per-node NodeManagers and the per-application ApplicationMasters.
In YARN, the ResourceManager is primarily limited to scheduling—that is, it allocates available resources in the system among the competing applications but does not concern itself with per-application state management. The scheduler handles only an overall resource profile for each application, ignoring local optimizations and internal application flow. In fact, YARN completely departs from the static assignment of map and reduce slots because it treats the cluster as a resource pool. Because of this clear separation of responsibilities coupled with the modularity described previously, the ResourceManager is able to address the important design requirements of scalability and support for alternative programming paradigms.
In contrast to many other workflow schedulers, the ResourceManager also has the ability to symmetrically request back resources from a running application. This situation typically happens when cluster resources become scarce and the scheduler decides to reclaim some (but not all) of the resources that were given to an application.
In YARN, ResourceRequests can be strict or negotiable. This feature provides ApplicationMasters with a great deal of flexibility on how to fulfill the reclamation requests—for example, by picking containers to reclaim that are less crucial for the computation, by checkpointing the state of a task, or by migrating the computation to other running containers. Overall, this scheme allows applications to preserve work, in contrast to platforms that kill containers to satisfy resource constraints. If the application is noncollaborative, the ResourceManager can, after waiting a certain amount of time, obtain the needed resources by instructing the NodeManagers to forcibly terminate containers.
ResourceManager failures remain significant events affecting cluster availability. As of this writing, the ResourceManager will restart running ApplicationMasters as it recovers its state. If the framework supports restart capabilities—and most will for routine fault tolerance—the platform will automatically restore users’ pipelines.
In contrast to the Hadoop 1.0 JobTracker, it is important to mention the tasks for which the ResourceManager is not responsible. Other than tracking application execution flow and task fault tolerance, the ResourceManager will not provide access to the application status (servlet; now part of the ApplicationMaster) or track previously executed jobs, a responsibility that is now delegated to the JobHistoryService (a daemon running on a separated node). This is consistent with the view that the ResourceManager should handle only live resource scheduling, and helps YARN central components scale better than Hadoop 1.0 JobTracker.
YARN Scheduling Components
YARN has a pluggable scheduling component. Depending on the use case and user needs, administrators may select either a simple FIFO (first in, first out), capacity, or fair share scheduler. The scheduler class is set in yarn-default.xml. Information about the currently running scheduler can be found by opening the ResourceManager web UI and selecting the Scheduler option under the Cluster menu on the left (e.g., http://your_cluster:8088/cluster/scheduler). The various scheduler options are described briefly in this section.
FIFO Scheduler
The original scheduling algorithm that was integrated within the Hadoop version 1 JobTracker was called the FIFO scheduler, meaning “first in, first out.” The FIFO scheduler is basically a simple “first come, first served” scheduler in which the JobTracker pulls jobs from a work queue, oldest job first. Typically, FIFO schedules have no sense of job priority or scope. The FIFO schedule is practical for small workloads, but is feature-poor and can cause issues when large shared clusters are used.
Capacity Scheduler
The Capacity scheduler is another pluggable scheduler for YARN that allows for multiple groups to securely share a large Hadoop cluster. Developed by the original Hadoop team at Yahoo!, the Capacity scheduler has successfully been running many of the largest Hadoop clusters.
To use the Capacity scheduler, an administrator configures one or more queues with a predetermined fraction of the total slot (or processor) capacity. This assignment guarantees a minimum amount of resources for each queue. Administrators can configure soft limits and optional hard limits on the capacity allocated to each queue. Each queue has strict ACLs (Access Control Lists) that control which users can submit applications to individual queues. Also, safeguards are in place to ensure that users cannot view or modify applications from other users.
The Capacity scheduler permits sharing a cluster while giving each user or group certain minimum capacity guarantees. These minimums are not given away in the absence of demand. Excess capacity is given to the most starved queues, as assessed by a measure of running or used capacity divided by the queue capacity. Thus, the fullest queues as defined by their initial minimum capacity guarantee get the most needed resources. Idle capacity can be assigned and provides elasticity for the users in a cost-effective manner.
Queue definitions and properties such as capacity and ACLs can be changed, at run time, by administrators in a secure manner to minimize disruption to users. Administrators can add additional queues at run time, but queues cannot be deleted at run time. In addition, administrators can stop queues at run time to ensure that while existing applications run to completion, no new applications can be submitted.
The Capacity scheduler currently supports memory-intensive applications, where an application can optionally specify higher memory resource requirements than the default. Using information from the NodeManagers, the Capacity scheduler can then place containers on the best-suited nodes.
The Capacity scheduler works best when the workloads are well known, which helps in assigning the minimum capacity. For this scheduler to work most effectively, each queue should be assigned a minimal capacity that is less than the maximal expected workload. Within each queue, multiple applications are scheduled using hierarchical FIFO queues similar to the approach used with the stand-alone FIFO scheduler. Capacity Scheduler is covered in more detail in Chapter 8, “Capacity Scheduler in YARN.”
Fair Scheduler
The Fair scheduler is a third pluggable scheduler for Hadoop that provides another way to share large clusters. Fair scheduling is a method of assigning resources to applications such that all applications get, on average, an equal share of resources over time.
Note
In Hadoop version 1, the Fair scheduler uses the term “pool” to refer to a queue. Starting with the YARN Fair scheduler, the term “queue” will be used instead of “pool.” To provide backward compatibility with the original Fair scheduler, “queue” elements can be named as “pool” elements.
In the Fair scheduler model, every application belongs to a queue. YARN containers are given to the queue with the least amount of allocated resources. Within the queue, the application that has the fewest resources is assigned the container. By default, all users share a single queue, called “default.” If an application specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to configure the Fair scheduler to assign queues based on the user name included with the request. The Fair scheduler supports a number of features such as weights on queues (heavier queues get more containers), minimum shares, maximum shares, and FIFO policy within queues, but the basic idea is to share the resources as uniformly as possible.
Under the Fair scheduler, when a single application is running, that application may request the entire cluster (if needed). If additional applications are submitted, resources that are free are assigned “fairly” to the new applications so that each application gets roughly the same amount of resources. The Fair scheduler also applies the notion of preemption, whereby containers can be requested back from the ApplicationMaster. Depending on the configuration and application design, preemption and subsequent assignment can be either friendly or forceful.
In addition to providing fair sharing, the Fair scheduler allows guaranteed minimum shares to be assigned to queues, which is useful for ensuring that certain users, groups, or production applications always get sufficient resources. When a queue contains waiting applications, it gets at least its minimum share; in contrast, when the queue does not need its full guaranteed share, the excess is split between other running applications. To avoid a single user flooding the clusters with hundreds of jobs, the Fair scheduler can limit the number of running applications per user and per queue through the configurations file. Using this limit, user applications will wait in the queue until previously submitted jobs finish.
The YARN Fair scheduler allows containers to request variable amounts of memory and schedules based on those requirements. Support for other resource specifications, such as type of CPU, is under development. To prevent multiple smaller memory applications from starving a single large memory application, a “reserved container” has been introduced. If an application is given a container that it cannot use immediately due to a shortage of memory, it can reserve that container, and no other application can use it until the container is released. The reserved container will wait until other local containers are released and then use this additional capacity (i.e., extra RAM) to complete the job. One reserved container is allowed per node, and each node may have only one reserved container. The total reserved memory amount is reported in the ResourceManager UI. A larger number means that it may take longer for new jobs to get space.
A new feature in the YARN Fair scheduler is support for hierarchical queues. Queues may now be nested inside other queues, with each queue splitting the resources allotted to it among its subqueues in a fair scheduling fashion. One use of hierarchical queues is to represent organizational boundaries and hierarchies. For example, Marketing and Engineering departments may now arrange a queue structure to reflect their own organization. A queue can also be divided into subqueues by job characteristics, such as short, medium, and long run times.
The Fair scheduler works best when there is a lot of variability between queues. Unlike with the Capacity scheduler, all jobs make progress rather than proceeding in a FIFO fashion in their respective queues.
Containers
At the fundamental level, a container is a collection of physical resources such as RAM, CPU cores, and disks on a single node. There can be multiple containers on a single node (or a single large one). Every node in the system is considered to be composed of multiple containers of minimum size of memory (e.g., 512 MB or 1 GB) and CPU. The ApplicationMaster can request any container so as to occupy a multiple of the minimum size.
A container thus represents a resource (memory, CPU) on a single node in a given cluster. A container is supervised by the NodeManager and scheduled by the ResourceManager.
Each application starts out as an ApplicationMaster, which is itself a container (often referred to as container 0). Once started, the ApplicationMaster must negotiate with the ResourceManager for more containers. Container requests (and releases) can take place in a dynamic fashion at run time. For instance, a MapReduce job may request a certain amount of mapper containers; as they finish their tasks, it may release them and request more reducer containers to be started.
NodeManager
The NodeManager is YARN’s per-node “worker” agent, taking care of the individual compute nodes in a Hadoop cluster. Its duties include keeping up-to-date with the ResourceManager, overseeing application containers’ life-cycle management, monitoring resource usage (memory, CPU) of individual containers, tracking node health, log management, and auxiliary services that may be exploited by different YARN applications.
On start-up, the NodeManager registers with the ResourceManager; it then sends heartbeats with its status and waits for instructions. Its primary goal is to manage application containers assigned to it by the ResourceManager.
YARN containers are described by a container launch context (CLC). This record includes a map of environment variables, dependencies stored in remotely accessible storage, security tokens, payloads for NodeManager services, and the command necessary to create the process. After validating the authenticity of the container lease, the NodeManager configures the environment for the container, including initializing its monitoring subsystem with the resource constraints’ specified application. The NodeManager also kills containers as directed by the ResourceManager.
ApplicationMaster
The ApplicationMaster is the process that coordinates an application’s execution in the cluster. Each application has its own unique ApplicationMaster, which is tasked with negotiating resources (containers) from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks. In the YARN design, Map-Reduce is just one application framework; this design permits building and deploying distributed applications using other frameworks. For example, YARN ships with a Distributed-Shell application that allows a shell script to be run on multiple nodes on the YARN cluster.
Once the ApplicationMaster is started (as a container), it will periodically send heartbeats to the ResourceManager to affirm its health and to update the record of its resource demands. After building a model of its requirements, the ApplicationMaster encodes its preferences and constraints in a heartbeat message to the ResourceManager. In response to subsequent heartbeats, the ApplicationMaster will receive a lease on containers bound to an allocation of resources at a particular node in the cluster. Depending on the containers it receives from the ResourceManager, the ApplicationMaster may update its execution plan to accommodate the excess or lack of resources. Container allocation/deallocation can take place in a dynamic fashion as the application progresses.
YARN Resource Model
In earlier Hadoop versions, each node in the cluster was statically assigned the capability of running a predefined number of map slots and a predefined number of reduce slots. The slots could not be shared between maps and reduces. This static allocation of slots wasn’t optimal because slot requirements vary during the MapReduce application life cycle. Typically, there is a demand for map slots when the job starts, as opposed to the need for reduce slots toward the end of the job.
The resource allocation model in YARN addresses the inefficiencies of static allocations by providing for greater flexibility. As described previously, resources are requested in the form of containers, where each container has a number of nonstatic attributes. YARN currently has attribute support for memory and CPU. The generalized attribute model can also support things like bandwidth or GPUs. In the future resource management model, only a minimum and a maximum for each attribute are defined, and ApplicationManagers can request containers with attribute values as multiples of the minimum.
Client Resource Request
A YARN application starts with a client resource request. Figure 4.2 illustrates the initial step in which a client communicates with the ApplicationManager component of the ResourceManager to initiate this process. The client must first notify the ResourceManager that it wants to submit an application. The ResourceManager responds with an ApplicationID and information about the capabilities of the cluster that will aid the client in requesting resources. This process is shown in Steps 1 and 2 in Figure 4.2.
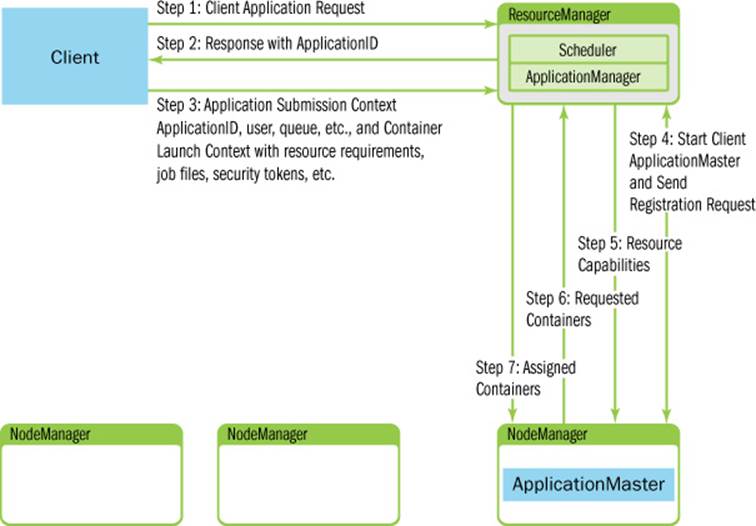
Figure 4.2 Example client resource request to ResourceManager
ApplicationMaster Container Allocation
Next the client responds with a “Application Submission Context” in Step 3. The Application Submission context contains the ApplicationID, user, queue, and other information needed to start the ApplicationMaster. In addition a “Container Launch Context” (CLC) is sent to the ResourceManager. The CLC provides resource requirements (memory/CPU), job files, security tokens, and other information needed to launch an ApplicationMaster on a node. Once the application has been submitted, the client can also request that the ResourceManager kill the application or provide status reports about the application.
When the ResourceManager receives the application submission context from a client, it schedules an available container for the ApplicationMaster. This container is often called “container 0” because it is the ApplicationMaster, which must request additional containers. If there are no applicable containers, the request must wait. If a suitable container can be found, then the ResourceManager contacts the appropriate NodeManager and starts the ApplicationMaster (Step 4 in Figure 4.2). As part of this step, the ApplicationMaster RPC port and tracking URL for monitoring the application’s status will be established.
In response to the registration request, the ResourceManager will send information about the minimum and maximum capabilities of the cluster (Step 5 in Figure 4.2). At this point the ApplicationMaster must decide how to use the capabilities that are currently available. Unlike some resource schedulers in which clients request hard limits, YARN allows applications to adapt (if possible) to the current cluster environment.
Based on the available capabilities reported from the ResourceManager, the ApplicationMaster will request a number of containers (Step 6 in Figure 4.2). This request can be very specific, including containers with multiples of the resource minimum values (e.g., extra memory). The ResourceManager will respond, as best as possible based on scheduling policies, to this request with container resources that are assigned to the ApplicationMaster (Step 7 in Figure 4.2).
As a job progresses, heartbeat and progress information is sent from the ApplicationMaster to the ResourceManager (shown in Figure 4.3). Within these heartbeats, it is possible for the ApplicationMaster to request and release containers. When the job finishes, the ApplicationMaster sends a Finish message to the ResourceManager and exits.
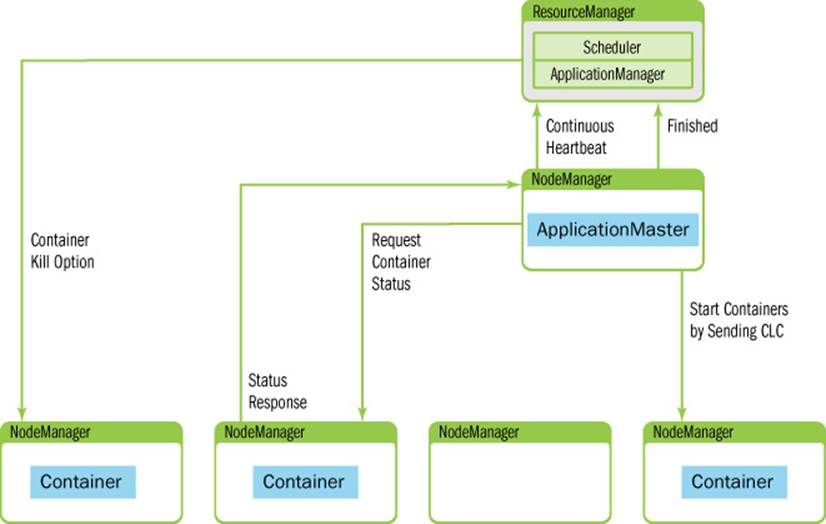
Figure 4.3 ApplicationMaster NodeManager interaction.
ApplicationMaster–Container Manager Communication
At this point, the ResourceManager has handed off control of assigned NodeManagers to the ApplicationMaster. The ApplicationMaster will independently contact its assigned node managers and provide them with a Container Launch Context that includes environment variables, dependencies located in remote storage, security tokens, and commands needed to start the actual process (refer to Figure 4.3). When the container starts, all data files, executables, and necessary dependencies are copied to local storage on the node. Dependencies can potentially be shared between containers running the application.
Once all containers have started, their status can be checked by the ApplicationMaster. The ResourceManager is absent from the application progress and is free to schedule and monitor other resources. The ResourceManager can direct the NodeManagers to kill containers. Expected kill events can happen when the ApplicationMaster informs the ResourceManager of its completion, or the ResourceManager needs nodes for another applications, or the container has exceeded its limits. When a container is killed, the NodeManager cleans up the local working directory. When a job is finished, the ApplicationMaster informs the ResourceManager that the job completed successfully. The ResourceManager then informs the NodeManager to aggregate logs and clean up container-specific files. The NodeManagers are also instructed to kill any remaining containers (including the ApplicationMaster) if they have not already exited.
Managing Application Dependencies
In YARN, applications perform their work by running containers that map to processes on the underlying operating system. Containers have dependencies on files for execution, and these files are either required at start-up or may be needed one or more times during application execution. For example, to launch a simple Java program as a container, we need a collection of classes and/or a file and potentially more jar files as dependencies. Instead of forcing every application to either access (mostly for reading) these files remotely every time or manage the files themselves, YARN gives the applications the ability to localize these files.
When starting a container, an ApplicationMaster can specify all the files that a container will require and, therefore, that should be localized. Once these files are specified, YARN takes care of the localization and hides all the complications involved in securely copying, managing, and later deleting these files.
In the remainder of this section, we’ll explain the basic concepts underlying this functionality.
LocalResources Definitions
We will begin with some definitions that will aid in the discussion of application dependencies.
![]() Localization: The process of copying or downloading remote resources onto the local file system. Instead of always accessing a resource remotely, that resource is copied to the local machine, so it can then be accessed locally from that point of time.
Localization: The process of copying or downloading remote resources onto the local file system. Instead of always accessing a resource remotely, that resource is copied to the local machine, so it can then be accessed locally from that point of time.
![]() LocalResource: The file or library required to run a container. The NodeManager is responsible for localizing the resource prior to launching the container. For each LocalResource, applications can specify the following:
LocalResource: The file or library required to run a container. The NodeManager is responsible for localizing the resource prior to launching the container. For each LocalResource, applications can specify the following:
![]() URL: A remote location from where a LocalResource must be downloaded.
URL: A remote location from where a LocalResource must be downloaded.
![]() Size: The size in bytes of the LocalResource.
Size: The size in bytes of the LocalResource.
![]() TimeStamp: The last modification of the resource on the remote file system before container start.
TimeStamp: The last modification of the resource on the remote file system before container start.
![]() LocalResourceType: A specific type of a resource localized by the NodeManager—FILE, ARCHIVE, or PATTERN.
LocalResourceType: A specific type of a resource localized by the NodeManager—FILE, ARCHIVE, or PATTERN.
![]() Pattern: The pattern that should be used to extract entries from the archive (used only when the type is PATTERN).
Pattern: The pattern that should be used to extract entries from the archive (used only when the type is PATTERN).
![]() LocalResourceVisibility: The specific visibility of a resource localized by the NodeManager. The visibility can be either PUBLIC, PRIVATE, or APPLICATION.
LocalResourceVisibility: The specific visibility of a resource localized by the NodeManager. The visibility can be either PUBLIC, PRIVATE, or APPLICATION.
A container can request and use any kind of files for localization, provided they are used as read-only by the containers. Typical examples of LocalResources include the following:
![]() Libraries required for starting the container, such as a jar file.
Libraries required for starting the container, such as a jar file.
![]() Configuration files required to configure the container once started (e.g., remote service URLs, application default configurations).
Configuration files required to configure the container once started (e.g., remote service URLs, application default configurations).
![]() A static dictionary file.
A static dictionary file.
The following are some examples of bad candidates for LocalResources:
![]() Shared files that external components may potentially update in the future and for which current containers wish to track these changes.
Shared files that external components may potentially update in the future and for which current containers wish to track these changes.
![]() Files that applications themselves directly want to update.
Files that applications themselves directly want to update.
![]() Files through which an application plans to share the updated information with external services.
Files through which an application plans to share the updated information with external services.
![]() LocalCache: The NodeManager maintains and manages several local caches of all the files downloaded. The resources are uniquely identified based on the remote URL originally used while copying that file.
LocalCache: The NodeManager maintains and manages several local caches of all the files downloaded. The resources are uniquely identified based on the remote URL originally used while copying that file.
LocalResource Timestamps
As mentioned earlier, NodeManager tracks the last-modification timestamp of each LocalResource before a container starts. Before downloading them, the NodeManager checks that the files haven’t changed in the interim. This check ensures a consistent view at the LocalResources—an application can use the very same file contents all the time it runs without worrying about data corruption issues due to concurrent writers to the same file.
Once the file is copied from its remote location to one of the NodeManager’s local disks, it loses any connection to the original file other than the URL (used while copying). Any future modifications to the remote file are not tracked; hence, if an external system has to update the remote resource, it should be done via versioning. YARN will cause containers that depend on modified remote resources to fail, in an effort to prevent inconsistencies.
Note that the ApplicationMaster specifies the resource timestamps to a NodeManager while starting any container on that node. Similarly, for the container running the ApplicationMaster itself, the client must populate the timestamps for all the resources that ApplicationMaster needs.
In case of a MapReduce application, the MapReduce JobClient determines the modification timestamps of the resources needed by the MapReduce ApplicationMaster. The ApplicationMaster itself then sets the timestamps for the resources needed by the MapReduce tasks.
LocalResource Types
Each LocalResource can be of one of the following types:
![]() FILE: A regular file, either textual or binary.
FILE: A regular file, either textual or binary.
![]() ARCHIVE: An archive, which is automatically unarchived by the NodeManager. As of now, NodeManager recognizes jar, tar, tar.gz, and .zip files.
ARCHIVE: An archive, which is automatically unarchived by the NodeManager. As of now, NodeManager recognizes jar, tar, tar.gz, and .zip files.
![]() PATTERN: A hybrid of ARCHIVE and FILE types. The original file is retained, and at the same time (only) part of the file is unarchived on the local file system during localization. Both the original file and the extracted files are put in the same directory. Which contents have to be extracted from the ARCHIVE and which shouldn’t be are determined by the pattern field in the LocalResource specification. Currently, only jar files are supported under PATTERN type; all others are treated as a regular ARCHIVE.
PATTERN: A hybrid of ARCHIVE and FILE types. The original file is retained, and at the same time (only) part of the file is unarchived on the local file system during localization. Both the original file and the extracted files are put in the same directory. Which contents have to be extracted from the ARCHIVE and which shouldn’t be are determined by the pattern field in the LocalResource specification. Currently, only jar files are supported under PATTERN type; all others are treated as a regular ARCHIVE.
LocalResource Visibilities
LocalResources can be of three types depending on their specified LocalResource-Visibility—that is, depending on how visible/accessible they are on the original storage/file system.
PUBLIC
All the LocalResources (remote URLs) that are marked PUBLIC are accessible for containers of any user. Typically PUBLIC resources are those that can be accessed by anyone on the remote file system and, following the same ACLs, are copied into a public LocalCache. If in the future a container belonging to this or any other application (of this or any user) requests the same LocalResource, it is served from the LocalCache and, therefore, not copied or downloaded again if it hasn’t been evicted from the LocalCache by then. All files in the public cache will be owned by “yarn-user” (the user that NodeManager runs as) with world-readable permissions, so that they can be shared by containers from all users whose containers are running on that node.
PRIVATE
LocalResources that are marked PRIVATE are shared among all applications of the same user on the node. These LocalResources are copied into the specific user’s (the user who started the container—that is, the application submitter) private cache. These files are accessible to all the containers belonging to different applications, but all started by the same user. These files on the local file system are owned by the user and are not accessible by any other user. Similar to the public LocalCache, even for the application submitters, there aren’t any write permissions; the user cannot modify these files once localized. This feature is intended to avoid accidental write operations to these files by one container that might potentially harm other containers. All containers expect each LocalResource to be in the same state as originally specified (mirroring the original timestamp and/or version number).
APPLICATION
All the resources that are marked as having the APPLICATION scope are shared only among containers of the same application on the node. They are copied into the application-specific LocalCache that is owned by the user who started the container (application submitter). All of these files are owned by the user with read-only permissions.
Specifying LocalResource Visibilities
The ApplicationMaster specifies the visibility of a LocalResource to a NodeManager while starting the container; the NodeManager itself doesn’t make any decisions or classify resources. Similarly, for the container running the ApplicationMaster itself, the client has to specify visibilities for all the resources that the ApplicationMaster needs.
In case of a MapReduce application, the MapReduce JobClient decides the resource type which the corresponding ApplicationMaster then forwards to a NodeManager.
Lifetime of LocalResources
As mentioned previously, different types of LocalResources have different life cycles:
![]() PUBLIC LocalResources are not deleted once the container or application finishes, but rather are deleted only when there is pressure on each local directory for disk capacity. The threshold for local files is dictated by the configuration property__yarn.nodemanager.localizer.cache.target-size-mb__, as described later in this section.
PUBLIC LocalResources are not deleted once the container or application finishes, but rather are deleted only when there is pressure on each local directory for disk capacity. The threshold for local files is dictated by the configuration property__yarn.nodemanager.localizer.cache.target-size-mb__, as described later in this section.
![]() PRIVATE LocalResources follow the same life cycle as PUBLIC resources.
PRIVATE LocalResources follow the same life cycle as PUBLIC resources.
![]() APPLICATION-scoped LocalResources are deleted immediately after the application finishes.
APPLICATION-scoped LocalResources are deleted immediately after the application finishes.
For any given application, we may have multiple ApplicationAttempts, and each attempt may start zero or more containers on a given NodeManager. When the first container belonging to an ApplicationAttempt starts, NodeManager localizes files for that application as requested in the container’s launch context. If future containers request more such resources, then all of them will be localized. If one ApplicationAttempt finishes or fails and another is started, ResourceLocalizationService doesn’t do anything with respect to the previously localized resources. However, when the application finishes, the ResourceManager communicates that information to NodeManagers which in turn clear the application LocalCache. In summary, APPLICATION LocalResources are truly application scoped and not ApplicationAttempt scoped.
Wrap-up
The three main yarn components work together to deliver a new level of functionality to Apache Hadoop. The ResourceManager acts as a pure scheduler controlling the use of cluster resources in the form of resource containers (e.g., CPUs, memory). User applications are under the control of an application-specific ApplicationMaster (itself a container) that must negotiate the use of additional containers with the ResourceManager at run time. Once the ApplicationMaster has been given resources, it works with the per-node NodeManagers to start and monitor containers on the cluster nodes. Containers are flexible and can be released and requested as the application progresses.
To ensure best utilization of the cluster, administrators have three scheduling options: FIFO, capacity, and fair share. These schedulers are used by the ResourceManager to best match the user needs with the available cluster resources.
LocalResources are new and are a very useful feature that application writers can exploit to declare their start-up and run-time dependencies.
In this new YARN environment, MapReduce does not hold a special place in the workflow because it is “just an application framework” directed by an ApplicationMaster. Other frameworks are available or under development for use in the YARN environment.