Field Guide to Hadoop (2015)
Chapter 3. Serialization
Big data systems spend a great deal of time and resources moving data around. Take, for example, a typical process that looks at logs. That process might collect logs from a few servers, moving those logs to HDFS, perform some sort of analysis to build a handful of reports, then move those reports to some sort of dashboard your users can see. At each step in that process, you’re moving data, in some cases multiple times, between systems, off hard drives and into memory. See Figure 3-1.
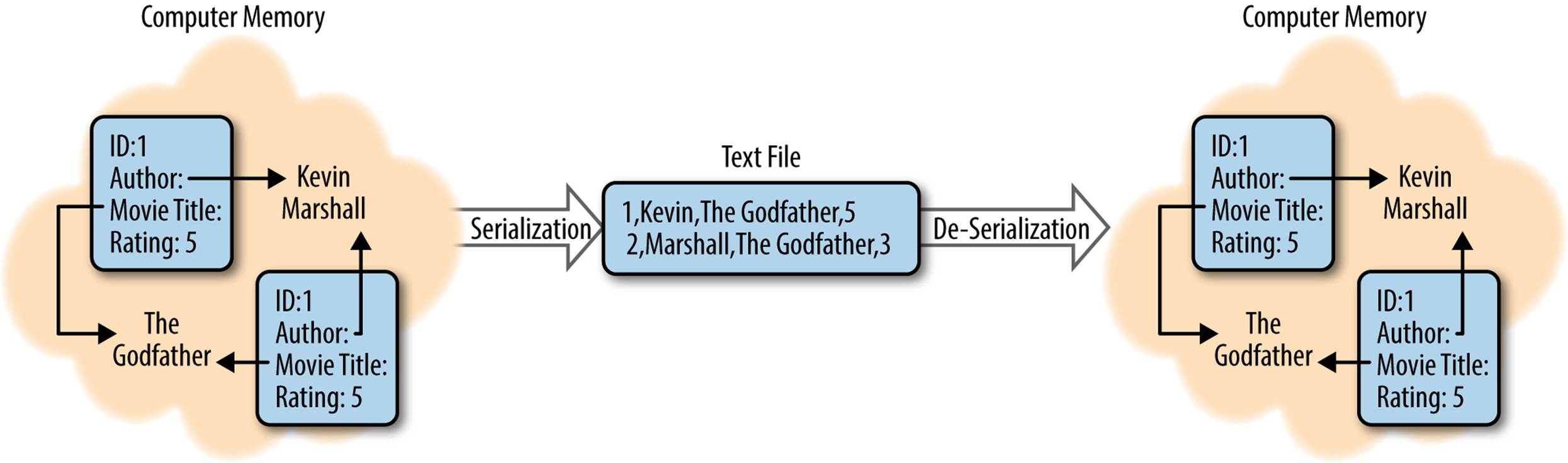
Figure 3-1. Serialization and deserialization of a movie review
When modern computers work with data, it’s often held in all manner of complex formats, full of internal relationships and references. When you want to write this data down, whether to share it or to store it for later, you need to find a way to break down those relationships, explain the references, and build a representation of the data that can be read from start to finish. This process is called serialization.
Similarly, have you ever read a great description of a place or event and found that you could picture it perfectly in your head? This process of reading something that’s been written down (serialized) and rebuilding all the complex references and relationships is known as de-serialization.
There is a wide variety of data serialization tools and frameworks available to help manage what your data looks like as it is moved around. Choosing the right serialization format for each task is a critical aspect of building a system that is scalable, performs well, and can be easily managed. As you’ll see, there are a handful of major considerations to keep in mind when choosing a serialization format, including:
Data size
How much space does your data take up in memory or on disk?
Read/write speed
How long does it take a computer to read/write your data?
Human readability
Can humans make sense out of your serialized data without outside assistance?
Ease of use
How hard is it to write or read data in this format? Do you need to share special files or tools with other folks who want to read your data?
Avro

|
License |
Apache License, Version 2.0 |
|
Activity |
Medium |
|
Purpose |
Data Serialization |
|
Official Page |
http://avro.apache.org |
|
Hadoop Integration |
API Compatible |
Let’s say you have some data and you want to share it with someone else. The first thing you might do is write out the structure of your data, defining things like how many fields there are and what kind of data those fields contain. In technical terms, that definition could be called a schema. You would likely share that schema along with your data, and the folks who are interested in your data might put together a little code to make sure they can read it.
Avro is a system that automates much of that work. You provide it with a schema, and it builds the code you need to read and write data. Because Avro was designed from the start to work with Hadoop and big data, it goes to great lengths to store your data as efficiently as possible.
There are two unique behaviors that differentiate Avro from many other serialization systems such as Thrift and Protocol Buffers (protobuf; described here):
Runtime assembled
Avro does not require special serialization code to be generated and shared beforehand. This simplifies the process of deploying applications that span multiple platforms, but comes at a cost to performance. In some cases, you can work around this and generate the code beforehand, but you’ll need to regenerate and reshare the code every time you change the format of your data.
Schema-driven
Each data transfer consists of two parts: a schema describing the format of the data and the data itself. Because the format of the data is defined in the schema, each item does not need to be tagged. This allows for a dramatic reduction in the overhead associated with transferring many complex objects, but can actually increase the overhead involved with transferring a small number of large but simple objects.
Tutorial Links
The official Avro documentation page is a great place to get started and provides “getting started” guides for both Java and Python. If you’re more interested in diving straight into integrating Avro with MapReduce, you can’t go wrong with the avro-mr-sample project on GitHub.
Example Code
Avro supports two general models:
§ A traditional serialization model where a developer authors a schema, runs a compiler to create models based on that schema, and then uses those models in their application
§ A runtime model where Avro builds records based on a schema file provided at runtime
In our example, we’ll use the runtime model because this is one of the most interesting differentiators for Avro.
We start out by defining a schema in a file that we’ll call review.avsc:
{"namespace": "example.elephant",
"type": "record",
"name": "Review",
"fields": [
{"name": "reviewer", "type": "string"},
{"name": "movieTitle", "type": "string"},
{"name": "rating", "type": "int"}
]
}
Now we can create an object based on this schema and write it out to disk:
//Bind the schema
Schema schema = new Parser().parse(new File("review.avsc"));
//Build a record
GenericRecord review = new GenericData.Record(schema);
review.put("reviewer", "Kevin");
review.put("movieTitle", "Dune");
review.put("rating", 10);
// Serialize our review to disk
File file = new File("review.avro");
DatumWriter<GenericRecord> datumWriter =
new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter =
new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, file);
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.close();
We can also deserialize that file we just created to populate a review object:
//Bind the schema
Schema schema = new Parser().parse(new File("review.avsc"));
File file = new File("review.avro");
DatumReader<GenericRecord> datumReader =
new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader =
new DataFileReader<GenericRecord>(file, datumReader);
GenericRecord review = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
review = dataFileReader.next(review);
}
JSON

|
License |
http://www.json.org/license.html |
|
Activity |
Medium |
|
Purpose |
Data description and transfer |
|
Official Page |
http://www.json.org |
|
Hadoop Integration |
No Integration |
As JSON is not part of Hadoop, you may wonder why it’s included here. Increasingly, JSON is becoming common in Hadoop because it implements a key-value view of the world. JSON is an acronym for Java Script Object Notation, and is a convenient way to describe, serialize, and transfer data. It’s easy to learn and understand, and is easily parsable, self-describing, and hierarchical. In addition, JSON syntax is fairly simple. Data is represented by name-value pairs and is comma separated. Objects are enclosed by curly brackets, and arrays are enclosed by square brackets.
JSON is often compared to XML because both are used in data description and data transfer. While you’ll find XML is perhaps a richer and more extensible method of serializing and describing data, you may also find that it is more difficult to read and parse. The Hadoop community seems to favor JSON rather than XML. That said, many of the configuration files in the Hadoop infrastructure are written in XML, so a basic knowledge of XML is still required to maintain a Hadoop cluster.
Tutorial Links
JSON has become one of the most widely adopted standards for sharing data. As a result, there’s a wealth of information available on the Internet, including this w3schools article.
Example Code
Our movie review data can easily be expressed in JSON.
For example, here’s the original data:
Kevin,Dune,10
Marshall,Dune,1
Kevin,Casablanca,5
Bob,Blazing Saddles,9
And here’s the JSON-formatted data (the reviews are described as a collection called movieReviews, which consists of an array of a collection of name-value pairs—one for the name of the reviewer, one for the name of the move, and one for the rating):
{
"movieReviews": [
{ "reviewer":"Kevin", "movie":"Dune", "rating","10" },
{ "reviewer":"Marshall", "movie":"Dune", "rating","1" },
{ "reviewer":"Kevin", "movie":"Casablanca", "rating","5" },
{ "reviewer":"Bob", "movie":"Blazing Saddles", "rating","9" }
]
}
Protocol Buffers (protobuf)
![]()
|
License |
BSD Simplified |
|
Activity |
Medium |
|
Purpose |
Data Serialization |
|
Official Page |
https://developers.google.com/protocol-buffers |
|
Hadoop Integration |
API Compatible |
One common theme you’ll see expressed throughout this book is the trade-off between flexibility and performance. Sometimes you want to easily share data with other folks and you’re willing to take a hit in performance to make sure that data is easy to consume. There will be other occasions where you need to maximize your performance and find that you’re willing to trade away flexibility in order to get it—on those occasions, you’re going to want to take a look at Protocol Buffers.
The primary reason for this trade-off is that Protocol Buffers is compile-time assembled. This means you need to define the precise structure for your data when you build your application, a stark contrast to Avro’s runtime assembly, which allows you to define the structure of your data while the application is running, or JSON’s even more flexible, schema-less design. The upside of compile-time assembly is the code that actually serializes and deserializes your data is likely to be more optimized, and you do not need to pay the cost of building that code while your application is running.
Protocol Buffers is intended to be fast, simple, and small. As a result, it has less support for programming languages and complex data types than other serialization frameworks such as Thrift.
Tutorial Links
Google provides excellent tutorials for a variety of languages in the official project documentation.
Example Code
Unlike Avro (described here), which supports runtime schema binding, protobuf must be integrated into your development and build process. You begin by defining a model in a .proto file. For example:
message Review {
required string reviewer = 1;
required string movieTitle = 2;
required int32 rating = 3;
}
You then run a protobuf compiler for your specific development language (e.g., Java) to generate code based on your model definition.
The mechanism for working with the objects generated by the protobuf compiler changes slightly from language to language. In Java, we use a builder to create a new, writeable object:
Review.Builder reviewBuilder = Review.newBuilder();
reviewBuilder.setReviewer("Kevin");
reviewBuilder.setMovieTitle("Dune");
reviewBuilder.setRating(10);
Review review = reviewBuilder.build();
This review object can then be written to any sort of output stream:
FileOutputStream output = new FileOutputStream("review.dat");
review.writeTo(output);
Repopulating objects from previously serialized data is done in a similar fashion:
FileInputStream input = new FileInputStream("review.dat");
review.parseFrom(input);
Parquet

|
License |
Apache License, Version 2.0 |
|
Activity |
Medium |
|
Purpose |
File Format |
|
Official Page |
http://parquet.io |
|
Hadoop Integration |
API Compatible |
One of the most compelling ideas behind an open ecosystem of tools, such as Hadoop, is the ability to choose the right tool for each specific job. For example, you have a choice between tools like distcp (described here) or Flume (described here) for moving your data into your cluster; Java MapReduce or Pig for building big data processing jobs; Puppet (described here) or Chef (described here) for managing your cluster; and so on. This choice differs from many traditional platforms that offer a single tool for each job and provides flexibility at the cost of complexity.
Parquet is one choice among many for managing the way your data is stored. It is a columnar data storage format, which means it performs very well with data that is structured and has a fair amount of repetition. On the other hand, the Parquet format is fairly complex and does not perform as well in cases where you want to retrieve entire records of data at a time.
Tutorial Links
The GitHub page for the Parquet format project is a great place to start if you’re interested in learning a bit more about how the technology works. If, on the other hand, you’d like to dive straight into examples, move over to the GitHub page for the parquet m/r project.
Example Code
The Parquet file format is supported by many of the standard Hadoop tools, including Hive (described here) and Pig (described here). Using the Parquet data format is typically as easy as adding a couple lines to your CREATE TABLE command or changing a few words in your Pig script.
For example, to change our Hive example to use Parquet instead of the delimited textfile format, we simply refer to Parquet when we create the table:
CREATE EXTERNAL TABLE movie_reviews
( reviewer STRING, title STRING, rating INT)
ROW FORMAT SERDE 'parquet.hive.serde.ParquetHiveSerDe'
STORED
INPUTFORMAT "parquet.hive.DeprecatedParquetInputFormat"
OUTPUTFORMAT "parquet.hive.DeprecatedParquetOutputFormat"
LOCATION '/data/reviews';
We can similarly modify our Pig example to load a review file that is stored in the Parquet format instead of CSV:
reviews = load ‘reviews.pqt’ using parquet.pig.ParquetLoader
as (reviewer:chararray, title:chararray, rating:int);
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.