Field Guide to Hadoop (2015)
Chapter 4. Management and Monitoring
Building and keeping tabs on a big data architecture can be a daunting task. You’ve got a diverse set of software spread out across many machines that might have dramatically different configurations. How can you tell if part of your system is failing, and how do you bring that component back up after you’ve fixed the problem? How can the different parts of your system communicate with on another so they can do big jobs with many moving parts?
Fortunately, the big data ecosystem provides a variety of tools to ease the burden of managing and monitoring your architecture. We’re going to address three primary categories of these tools:
Node configuration management
These are tools like Puppet or Chef that can help you manage the configuration of your systems. They do things like change operating system parameters and install software.
Resource tracking
While many individual components in your architecture may come with tools to monitor the performance of that specific component, sometimes you need a single dashboard or insight into something that isn’t tied to a specific tool.
Coordination
Many tasks take advantage of a handful of different components of your big data system. Tools like ZooKeeper can help you synchronize all those moving parts to accomplish a single goal.
Ambari

|
License |
Apache License, Version 2.0 |
|
Activity |
High |
|
Purpose |
Provisioning, monitoring, and management of a Hadoop cluster |
|
Official Page |
http://ambari.apache.org |
|
Hadoop Integration |
Fully Integrated |
If you’ve ever tried to install Hadoop from the Apache download, you’ll know that Hadoop is still a bear to install and manage. Recently, Pivotal and Hortonworks, two of the major vendors, agreed to work jointly on Ambari in an attempt to produce a production-ready, easy-to-use, web-based GUI tool based on a RESTful API.
The Ambari documentation at the official page says that it can:
§ Provision and monitor a Hadoop cluster
§ Provide a step-by-step wizard for installing Hadoop services across any number of hosts
§ Provide central management for starting, stopping, and reconfiguring Hadoop services across the entire cluster
§ Provide a dashboard for monitoring health and status of the Hadoop cluster
§ Leverage Ganglia (described here) for metrics collection
§ Leverage Nagios (described here) for system alerting
While installing Hadoop with traditional methods might be a multiday ordeal, Ambari can accomplish this in a few hours with relative ease. Ambari graduated from Incubator status to Top Level Project late in 2013 and should now be ready for production use.
Tutorial Links
There is a silent video that takes you through a cluster build with Ambari.
Here’s a great slideshow tutorial.
Example Code
Ambari is a GUI-based tool, so there’s no way we can present a code example.
HCatalog

|
License |
Apache License, Version 2.0 |
|
Activity |
High |
|
Purpose |
Data abstraction layer |
|
Official Page |
http://hive.apache.org/javadocs/hcat-r0.5.0/index.html |
|
Hadoop Integration |
Fully Integrated |
Suppose you have a set of files that you access with MapReduce, Hive, and Pig. Wouldn’t it be useful if you had a way of accessing them so that you didn’t have to know details of file format and location? You do. HCatalog provides an abstraction layer on many file types in HDFS allowing users of Pig, Hive, and MapReduce to concentrate on reading and writing their data without detailed consideration of what format it is using. This abstraction layer makes the data look very much like relational data (i.e., arranged in tables with rows and columns and a very SQL-like feel). HCatalog is closely associated with Hive because it uses and derives from the Hive metastore, the place that Hive stores its metadata about its tables.
HCatalog has the notion of partitions. A partition is a subset of rows of a table that have some common characteristic. Often, tables are partitioned by a date field. This makes it easy to query and also easy to manage, dropping partitions when they are no longer needed.
If you decide to use HCatalog, you’ll access your data via the HCatalog methods rather than those native to Pig or MapReduce. For example, in Pig, you commonly use PigStorage or TextLoader to read data, whereas when using HCatalog, you would use HCatLoader and HCatStorer.
Tutorial Links
HCatalog is one of the more sparsely documented major projects in the Hadoop ecosystem, but this tutorial from HortonWorks is well done.
Example Code
In Pig without HCatalog, you might load a file using something like:
reviews = load ‘reviews.csv’ using PigStorage(',')
as (reviewer:chararray, title:chararray,rating:int);
Using HCatalog, you might first create a table within Hive
CREATE TABLE movie_reviews
( reviewer STRING, title STRING, rating INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘|’
STORED AS TEXTFILE
and then use it in your Pig statement:
reviews = load ‘movie_reviews’
USING org.apache.hcatalog.pig.HCatLoader(); -
Nagios

|
License |
GNU General Public License |
|
Activity |
High |
|
Purpose |
IT infrastructure monitoring |
|
Official Page |
http://www.nagios.org |
|
Hadoop Integration |
No Integration |
As anyone who has ever been responsible for a networked computer system knows, keeping track of what’s happening in such a network is of critical importance. You need to know when things go wrong by being alerted rather than manually polling. You would like to have automated restart of failed components. You would like a tool that presents a graphical interface so you can quickly see what’s happening in the environment. Nagios is such a tool. Like many products in the open source world, there is a version that you can freely download, and expanded versions that are licensed at a cost.
The open source core product has many useful features. It provides monitoring of servers, switches, OS, and application through a web-based interface. More important, it provides quick detection of outages and problems and can alert your operations staff via email or text message. There are provisions for automatic restart.
Importantly, Nagios can be embedded into other systems, including Ambari (described here).
Tutorial Links
The Nagios main site has a live demo system.
There are a score of others, including this page on Debian Help and this one on TuxRadar.
Puppet

|
License |
Apache License, Version 2.0 |
|
Activity |
High |
|
Purpose |
Node Management |
|
Official Page |
https://puppetlabs.com |
|
Hadoop Integration |
API Compatible |
Puppet is a popular system for managing the configuration of large numbers of machines. It uses a “declarative” syntax, which means you describe the configuration of your machines and Puppet takes care of figuring out the steps necessary to achieve that configuration. For example, you will describe a configuration that has certain programs installed and Puppet will take care of figuring out how to determine if those programs are installed and how to install them if they are not yet installed.
Puppet configurations are written in terms of resources, manifests, and modules. A resource is the most basic unit of configuration and represents the state of a specific thing. For example, a resource might state that a specific file should exist and that everyone should be able to view its contents, but only the system administrator should be able to alter its contents.
The next level of configuration is a manifest. A manifest is a group of related resources. For example, a manifest may say that installing your application requires both a specific version of a RedHat Package Manager (RPM) to be installed, and that a configuration directory be created.
A module is a logical group of related, but separate, manifests. For example, a module for our application might contain one manifest that installs our application, another manifest that configures our application to work with an HBase instance (described here), and a third module that configures our application to send logs to a specific location.
Tutorial Links
Puppet Labs provides a variety of resources for those getting started.
Example Code
Puppet manifests are written in Ruby and follow typical Ruby syntax rules.
Our example manifest to install our application and ensure the configuration directory exists would look like this:
# 'test_application.pp'
class test_application {
package { 'test_application':
ensure => installed
}
file { 'test_application_conf':
path => '/etc/test_application/conf',
ensure => directory,
require => Package['test_application']
}
}
Chef

|
License |
Apache License, Version 2.0 |
|
Activity |
High |
|
Purpose |
Node Management |
|
Official Page |
https://www.getchef.com |
|
Hadoop Integration |
API Compatible |
Chef is designed to ease the burden of managing the configuration of your infrastructure. It follows an “imperative” syntax that is familiar to many software developers, allowing them to write software configuration the same we they write software code.
Chef configurations are written as resources, recipes, and cookbooks. A resource is the most basic unit of configuration and describes how to configure a specific thing. For example, a resource might tell Chef to create a specific directory and to make sure that everyone is able to view its contents, but that the contents can only be altered by the system administrator.
The next level of configuration is a recipe. A recipe is a group of related resources. For example, a recipe may say that installing your application takes two steps: first you must install a specific package, and then you must create a configuration directory.
A cookbook is a logical group of related, but separate, recipes. For example, a module for our application might contain one recipe that installs our application, another recipe that configures our application to work with an HBase instance (described here), and a third recipe that configures our application to work with an Accumulo instance (described here). All three of these manifests relate to installing and configuring our application, but we need to be be able to control which of these manifests is actually run without being required to run them all.
Tutorial
Opscode provides a variety of resources for getting started on its wiki page.
Example Code
Chef recipes are written in Ruby and follow typical Ruby syntax rules.
Our example manifest to install our application and ensure the configuration directory exists would look like this:
# 'default.rb'
package "test_application" do
action :install
end
directory "/etc/test_application/conf" do
action :create
end
ZooKeeper

|
License |
Apache License, Version 2.0 |
|
Activity |
Medium |
|
Purpose |
Coordination |
|
Official Page |
https://zookeeper.apache.org |
|
Hadoop Integration |
API Compatible |
Hadoop and HDFS are effective tools for distributing work across many machines, but sometimes you need to quickly share little bits of information between a number of simultaneously running processes. ZooKeeper is built for exactly this sort of need: it’s an effective mechanism for storing and sharing small amounts of state and configuration data across many machines.
For example, let’s say you have a job that takes information from a large number of small files, transforms that data, and puts the information into a database.
You could store the information in a file on a fileshare or in HDFS, but accessing that information from many machines can be very slow and attempting to update the information can be difficult due to synchronization issues.
A slightly better approach would be to move the connection information into a MapReduce job configuration file. Even then, you would need to update a file for every analytic every time the database moves. Also, there would be no straightforward way to update the connection information if the database needs to be moved while you have an analytic running.
Better still, storing the connection information in ZooKeeper allows your analytics to quickly access the information while also providing a simple mechanism for updates.
ZooKeeper is not intended to fill the space of HBase (described here) or any other big data key-value store. In fact, there are protections built into ZooKeeper to ensure that folks do not attempt to use it as a large data store. ZooKeeper is, however, just right when all you want to do is share a little bit of information across your environment.
Tutorial Links
The official getting started guide is a great place to get your feet wet with ZooKeeper.
Example Code
In this example, we’re going to start by opening the ZooKeeper command-line interface:
$ zookeeper-client
Now we’ll create a key-value pair. In this case, the key is /movie_reviews/database and the value is the IP address of a database we’ll use for our movie reviews:
[zk: localhost:3000(CONNECTED) 0] create /movie_reviews ''
Created /movie_reviews
[zk: localhost:3000(CONNECTED) 1] create /movie_reviews/database
'10.2.1.1'
Created /movie_reviews/database
Now we’ll retrieve the value for our key. Notice that we get back two important pieces of data—the actual value of 10.2.1.1 and the version of the value:
[zk: localhost:3000(CONNECTED) 2] get /movie_reviews/database
'10.2.1.1'
<metadata>
dataVersion = 0
<metadata>
Imagine the original server hosting our database has crashed and we need to point all the different processes that use that database to our failover. We’ll update the value associated with our key to point to the IP address of our failover:
[zk: localhost:3000(CONNECTED) 0] set /movie_reviews/database
'10.2.1.2'
<metadata>
dataVersion = 1
<metadata>
Now let’s get the key one last time. Notice that we retrieve the new IP address and the version has incremented to indicate that the value has changed:
[zk: localhost:3000(CONNECTED) 1] get /movie_reviews/database
'10.2.1.2'
<metadata>
dataVersion = 1
<metadata>
Oozie
![]()
|
License |
Apache License, Version 2.0 |
|
Activity |
High |
|
Purpose |
A workflow scheduler to manage complex multipart Hadoop jobs |
|
Official Page |
https://oozie.apache.org |
|
Hadoop Integration |
Fully Integrated |
You may be able to complete some of your data analytic tasks with a single MapReduce, Pig, or Hive job that reads its data from the Hadoop Distributed File System (HDFS, described here), computes its output and stores it in HDFS, but some tasks will be more complicated. For example, you may have a job that requires that two or three other jobs finish, and each of these require that data is loaded into HDFS from some external source. And you may want to run this job on a periodic basis. Of course, you could orchestrate this manually or by some clever scripting, but there is an easier way.
That way is Oozie, Hadoop’s workflow scheduler. It’s a bit complicated at first, but has some useful power to start, stop, suspend, and restart jobs, and control the workflow so that no task within the complete job runs before the tasks and objects it requires are ready. Oozie puts its actions (jobs and tasks) in a directed acyclic graph (DAG) that describe what actions depend upon previous actions completing successfully. This is defined in a large XML file (actually hPDL, Hadoop Process Definition Language). The file is too large to display here for any nontrivial example, but the tutorials and Oozie site have examples.
What is a DAG? A graph is a collection of nodes and arcs. Nodes represent states or objects. Arcs connect the nodes. If an arc has an arrow at either end, then that arc is directed and the direction of the arrow indicates the direction. In Oozie, the nodes are the actions, such as to run a job, fork, fail, or end. The arcs show which actions flow into others. It’s directed to show the ordering of the actions and decision or controls—that is, what nodes must run jobs or whether events precede or follow (e.g., a file object must be present before a Pig script is run). Acyclic means that in traversing the graph, once you leave a node, you cannot get back there. That would be a cycle. An implication of this is that Oozie cannot be used to iterate through a set of nodes until a condition is met (i.e., there are no while loops). There is more information about graphs in “Giraph”.
Figure 4-1 is a graphic example of an Oozie flow in which a Hive job requires the output of both a Pig job and a MapReduce job, both of which require external files to be present.
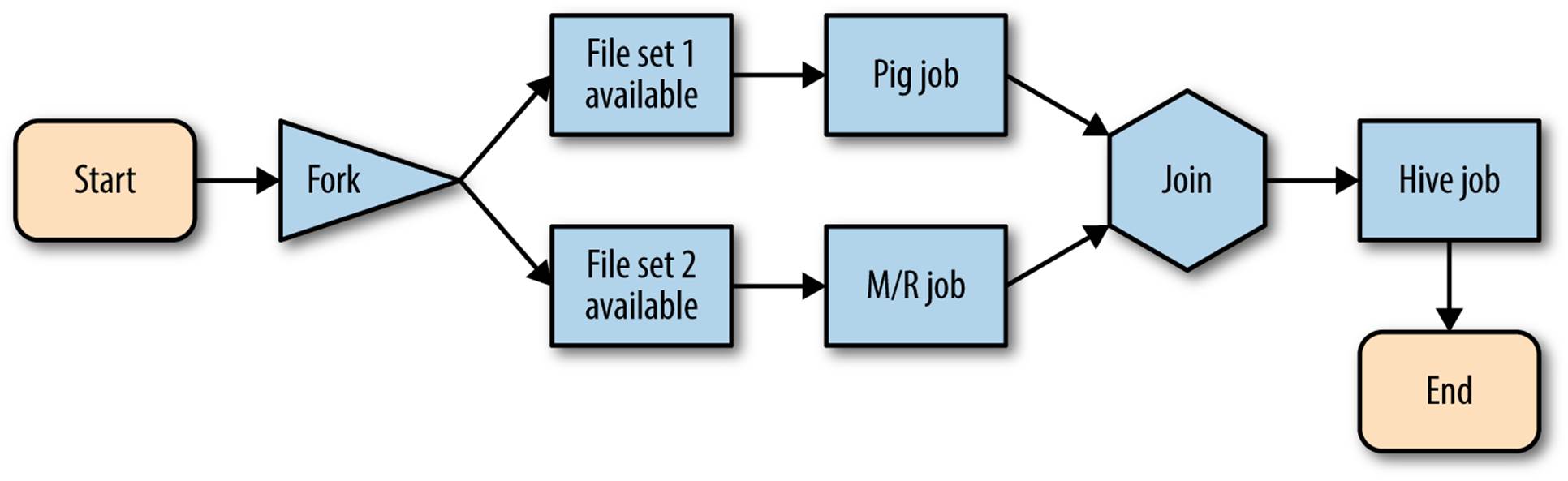
Figure 4-1. Graph representation of Oozie job flow
The Oozie installation comes with a GUI console for job monitoring, but it requires the use of Ext JS, a JavaScript framework for building desktop apps that comes with both open source and commercial versions.
Recently there has been some use of Hue as a more general Hadoop monitoring tool. Hue is open source, distributed under the Apache License, Version 2.0 and is primarly associated with the Cloudera Hadoop Distribution.
Tutorial Links
There are a handful of interesting Oozie presentations, including this one by IBM’s big data team and this academic presentation.
Example Code
The actual example files are too large to easily fit here. For more information, refer to the official user resources page, which contains cookbooks for a variety of languages.
Ganglia

|
License |
BSD |
|
Activity |
Medium |
|
Purpose |
Monitoring |
|
Official Page |
http://ganglia.sourceforge.net |
|
Hadoop Integration |
API Compatible |
Ganglia is a distributed monitoring system specifically designed to work with clusters and grids consisting of many machines. It allows you to quickly visualize how your systems are being used and can be a useful tool for keeping track of the general welfare of your cluster. Ganglia is best used to understand how your system is behaving at a very broad but very shallow level. Folks who are looking to debug or optimize specific analytics would be better served to look at other tools that are geared toward providing much deeper information at a much narrower scope, such as White Elephant.
By default, Ganglia is capable of providing information about much of the inner workings of your system right out of the box. This includes a number of data points describing such things as how much of your total computing capability is being used, how much data is moving through your network, and how your persistent storage is being utilized. Users with additional needs can also extend Ganglia to capture and display more information, such as application-specific metrics, through the use of plug-ins. Hadoop is packaged with a set of plug-ins for reporting information about HDFS and MapReduce to Ganglia (see the Ganglia Metrics project for more information).
Ganglia is being used in the Ambari project (described here).
Tutorial Links
Ganglia has a widely distributed support network spanning mailing lists, GitHub defect tracking, wiki pages, and more. An excellent starting off point for folks looking to get their first Ganglia installation working is the Ganglia wiki page.
Example Code
Configuring a Ganglia instance is beyond the scope of this book, as is even the most basic of distributed system monitoring and diagnostic processes. Interested readers are encouraged to look at the Ganglia instance monitoring the Wikimedia (Wikipedia) cluster to see Ganglia in action.