SQL Server Integration Services Design Patterns, Second Edition (2014)
Chapter 14. Loading the Cloud
It is 2014 and cloud technology is becoming ubiquitous. As more applications are hosted in various cloud service providers, the desire to locate their associated data in the cloud increases. Thanks to forethought and good engineering, Microsoft SQL Server is well-positioned to assist. The user experience when interacting with Microsoft Azure SQL Database (MASD) databases is nearly identical to interacting with local servers or servers on the enterprise network. Make no mistake, this is by design—and it is good design.
In this chapter, we will consider SSIS design patterns used to integrate data in the cloud. These patterns are useful when connecting to any repository that shares cloud technology characteristics. Because interacting with data in the cloud is similar to interacting with data that are more local, the patterns aren’t revolutionary. “So why write a chapter about loading the cloud?” Excellent question.
First, the cloud is here to stay—the djinni will not fit back into the bottle. The more we, as data professionals, learn about using the cloud, the better. Second, the cloud offers interesting challenges to data integration; these are challenges to be addressed and solved by the data integration developer. Loading the cloud isn’t just about interacting with buzz-worthy technology. It is an opportunity to design good architecture.
Interacting with the Cloud
For the purposes of this chapter, the cloud will refer to containers of data or data repositories that
· Reside off-enterprise-premises
· Are hosted by a third party
· Are outside of the physical enterprise domain
I understand these points are subject to debate. I will not debate them here. This definition will likely not survive the years following this writing (2012) and revision (2014). And even now, there is ambiguity and a blurring of lines between what is and is not considered “in the cloud.”
For demonstration, I am using data collected from my local weather station in Farmville, Virginia. The weather data are exposed and available at AndyWeather.com. AndyWeather.com is hosted by a large hosting company that provides remotely-accessible SQL Server database connectivity. As such, the data are stored in the cloud (according to my definition).
I also host weather data using a Microsoft Azure SQL Database: the same data, stored in a different location. “Why?” The simple answer: fault tolerance. Fault tolerance is the same reason DBAs perform database backups and test database restores. The difference between a technician and an engineer—or a developer and an architect—is that a technician builds systems that succeed whereas engineers build systems that don’t fail. It’s about mindset. Technicians get it working and stop there. Engineers consider many ways the system can fail and try to fix these things before they break.
Incremental Loads to Azure SQL Database
An incremental load is one in which only new or updated rows (and sometimes deleted) rows are loaded or changed. Incremental loads can be contrasted with the truncate-and-load pattern, where the existing data in the destination is deleted and all data is reloaded from the source. Sometimes truncate-and-load is most efficient. As data scale—especially at the destination—truncate-and-load performance often suffers. How do you know which will perform best? Test, measure, rinse, and repeat.
One benefit to truncate-and-load is simplicity. It is difficult to mess up a simple mechanism. Incremental loads introduce complexity, and change detection is the first place complexity enters the solution.
Change Detection
Change detection is functionality designed to separate rows that have never been sent from the source (New Rows) to the destination from rows that have been sent. Change detection also separates source rows that exist in the destination into rows that have changed in the source (Changed Rows) and rows that remain unchanged since they were last loaded or updated in the destination (Unchanged Rows). Change detection can also encompass rows that have been deleted from the destination that need to be deleted (or “soft-deleted”) from the source. We will ignore the Deleted Rows use case in this chapter.
We will consider using change detection to determine and discriminate between Unchanged Rows, Changed Rows, and New Rows. The block diagram for an incremental load pattern is shown in Figure 14-1.
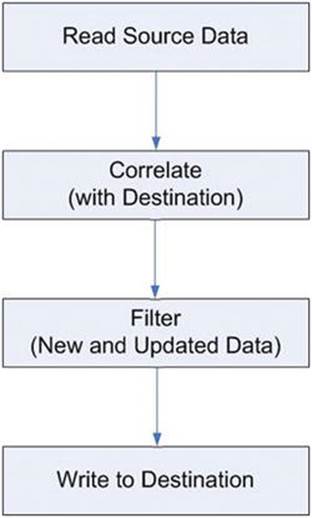
Figure 14-1. Incremental load block diagram
New Rows (Only)
You would think detecting new rows would be simple, regardless of the technology behind the destination database. You would be right. But when loading MASD, there is an economic consideration. As I write this in 2011 (and revise it in 2014), uploads are free. As a data provider, you are charged when your data is consumed. How does this fact impact your incremental load?
Here is where good data integration architecture and design comes in. Part of the job of the data integration architect is to know your data. This goes beyond knowing there is a column in the CleanTemperature table that contains the Average Dew Point for a given hour. Knowing your data means that you understand how and when it changes—or even if it changes. Certain types of data, like weather data, do not get updated after they are captured and recorded.
If you have read Tim Mitchell’s description of a typical incremental load pattern in Chapter 11, you will note a Lookup transform configured to connect to the destination and read data. In MASD, you will pay for that data read. There are almost 30,000 rows present in my MASD AndyWeather database. If I load all the rows from my source into a Data Flow task and use a Lookup transform to “join” between my source and MASD, I pay for reading rows that haven’t changed. What’s more, I know they will never change. Since weather data is never updated once recorded, there will simply be no Changed Rows.
Each hour, a few rows of new data are generated for each subject area in the AndyWeather database. If I use a Lookup, I load all 30,000 rows for no good reason—and I pay for the privilege. No thank you.
To limit the amount of data read, and thereby lower the total cost of the solution, I could execute a query that selects a “marker” indicating the latest or last row loaded. For this, I could select the maximum value from a field containing the date and time the table was last loaded; something like Max(LastUpdatedDateTime) or even a data integration lineage or metadata field like Max(LoadDate). I could similarly select another marker such as the Max(ID) from an integer column reliably maintained by a sequence, identity, trigger, or other mechanism. The reliability of the mechanism represents the maximum confidence a data integration architect can place in the value. I will demonstrate building an incremental loader using an identity column maintained on the source data.
Before I do, I wish to point out that Chapter 11 contains a great section on the incremental load design pattern. There is a discussion of another solution I will not touch upon: change data capture. I encourage you to review Chapter 11 before you complete your data integration design.
Building the Cloud Loader
To work through the demonsration that follows, you will need a MASD account and database. Creating the account and database is beyond the scope of this book, but you can learn more at www.windowsazure.com/en-us/home/features/sql-azure. Once MASD is set up and configured, create a database. In this database, create a table named dbo.LoadMetrics using the T-SQL shown in Listing 14-1.
Listing 14-1. Creating the LoadMetrics Table
Create Table dbo.LoadMetrics
(ID int identity(1,1)
Constraint PK_LoadMetrics_ID Primary Key Clustered
,LoadDate datetime
Constraint DF_LoadMetrics_LoadDate Default(GetDate())
,MetricName varchar(25)
,MetricIntValue int)
The LoadMetrics table will hold the last ID loaded for each table in the cloud destination. We will write this row once, and read and update it each load cycle. Accessing this table in this manner is the simplest and least processor-intensive manner in which to acquire the information we seek: the value of the last ID column loaded for a particular table. Why store this value in a table? Why not simply execute a Max(ID) select statement on the data table? Again, MASD charges for reads and not writes. Billing may change—it has in the past. What if we’re billed according to cycles or execution plans? You never know.
While connected to the MASD instance, create a table to hold your data. My data table will hold temperature information collected from my weather station in Farmville, Virginia. The table I use contains temperature- and humidity-related data and is shown in Listing 14-2.
Listing 14-2. Creating the CleanTemperature Table
Create Table dbo.CleanTemperature
(ID int identity(1,1)
Constraint PK_Cleantemperature_ID Primary Key Clustered
,MeasDateTime datetime
,MinT real
,MaxT real
,AvgT real
,MinH smallint
,MaxH smallint
,AvgH smallint
,ComfortZone smallint
,MinDP real
,MaxDP real
,AvgDP real
,MinHI varchar(7)
,MaxHI varchar(7)
,AvgHI varchar(7)
,LoadDate datetime
,LowBatt bit
,SensorID int)
Once the cloud tables have been created, we can begin work on an SSIS loader.
Locally, create a new SSIS solution and project named CloudLoader. Rename the default SSIS package SimpleCloudLoader.dtsx. Add a Sequence container and rename it SEQ Pre-Load Operations. Add an Execute SQL task by placing it into the Sequence container and rename itGet AWCleanTempMaxID From AndyWeather. Set the ResultSet property to Single Row and change the ConnectionType property to ADO.Net. Create the ADO.Net connection manager using information from your MASD account. To acquire the latest ID from the LoadMetrics table, I use the following query.
IF NOT EXISTS
(
Select *
From dbo.LoadMetrics
Where MetricName = 'CleanTempMaxID'
)
BEGIN
INSERT INTO dbo.LoadMetrics (LoadDate, MetricName,MetricIntValue)
VALUES (NULL,'CleanTempMaxID',NULL);
END
Select Coalesce(MetricIntValue, 0) As CleanTempMaxID
From dbo.LoadMetrics
Where MetricName = 'CleanTempMaxID'
On the Result Set page, I store the value in an SSIS variable of an Int32 data type named AWCleanLoadMaxID.
Add another Execute SQL task into the Sequence container and rename it Get CleanTempMaxID from the local table. Configure the connection to your source database and table. For me, it’s a local default instance of SQL Server hosting the WeatherData database and thedbo.CleanTemperature table. I use the following T-SQL to extract the current maximum value from the table, configuring a single row result set to push this value into the CleanTempLocalMaxID SSIS variable (Int32 data type).
Select Max(ID) As CleanTempLocalMaxID
From dbo.CleanTemperature
Add a Data Flow task outside the SEQ Pre-Load Operations Sequence container and rename it Load Windows Azure SQL Database. Connect an OnSuccess precedence constraint between the Sequence container and the Data Flow task. Open the Data Flow Task Editor and add an OLE DB source adapter. Connect the OLE DB source adapter to a local source database you wish to load in the cloud and write a query to pull the latest data from the desired table. In my case, I am pulling data from my dbo.CleanTemperature table. To accomplish the load, I use the source query shown in Listing 14-3.
Listing 14-3. WeatherData Source Query
SELECT ID
,MeasDateTime
,MinT
,MaxT
,AvgT
,MinH
,MaxH
,AvgH
,ComfortZone
,MinDP
,MaxDP
,AvgDP
,MinHI
,MaxHI
,AvgHI
,LoadDate
,LowBatt
,SensorID
FROM dbo.CleanTemperature
WHERE ID Between ? And ?
Click the Parameters button and map Parameter0 and Parameter1 to the AWCleanLoadMaxID and CleanTempLocalMaxID variables as shown in Figure 14-2.
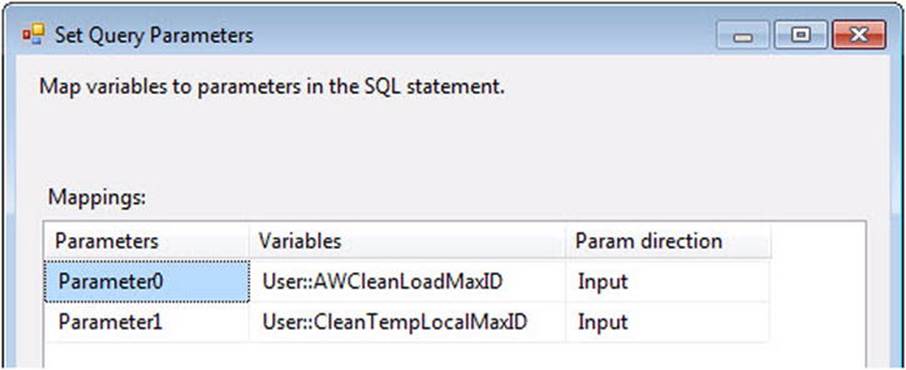
Figure 14-2. Mapping the SQLAzureCleanLoadMaxID variable to Parameter0
The question marks in the source query shown in Listing 14-3 are replaced with the values stored in the respective mapped variables. This query will only return rows where the ID is greater than the value stored in the cloud. Why do we grab the maximum ID from the source table before the load? In a word, latency. In the WeatherData database, the latency is minimal. But think about loading highly active systems—latency can be an issue. For example, suppose several transactions per second are entering the source table and it takes a few seconds to load the destination. If we wait until the load is complete to capture the source table’s Max ID value, that value will likely include data we didn’t load. The technical term for that is “bad.” So we design the package to grab the Max ID value before the load starts and only load rows between the last ID loaded into MASD and the Max ID value captured at the start of the SSIS package. And we never miss a row.
Returning to the demo package, add an ADO.Net destination adapter and rename it Windows Azure SQL Database ADO NET Destination. Connect a data flow path from the OLE DB source adapter to the ADO.Net destination adapter. Why an ADO.Net destination? MASD allows only ADO.Net and ODBC connections—there is no support at the time of this writing for OLE DB connections to MASDs.
Connect a data flow path between the source and destination adapters, edit the destination, and map the columns.
The last step is to update the LoadMetrics table in the MASD database. To accomplish this update, add an Execute SQL task to the control flow and rename it appropriately and descriptively. I named mine Update AndyWeather LoadMetrics Table and configured it to use ADO.Net to connect to my MASD database. My query looks like this one shown in Listing 14-4.
Listing 14-4. Updating the Azure SQL Database LoadMetrics Table
Update dbo.LoadMetrics
Set MetricIntValue = (@MaxID + 1)
, LoadDate = GetDate()
Where MetricName = 'CleanTempMaxID'
Map the value of CleanTempLocalMaxID into the @MaxID parameter on the Parameter Mapping page. And that’s it. This script makes the current maximum ID the minimum ID of the next load.
Conclusion
In this chapter we examined aspects of the architecture and design for loading cloud destinations. We designed a sound solution after weighing the architectural and economic considerations.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.