Expert Oracle Database Architecture, Third Edition (2014)
Chapter 2. Architecture Overview
Oracle is designed to be a very portable database—it is available on every platform of relevance, from Windows to UNIX/Linux to mainframes. However, the physical architecture of Oracle looks different on different operating systems. For example, on a UNIX/Linux operating system, you’ll see Oracle implemented as many different operating system processes, virtually a process per major function. On UNIX/Linux, this is the correct implementation, as it works on a multiprocess foundation. On Windows, however, this architecture would be inappropriate and would not work very well (it would be slow and nonscalable). On the Windows platform, Oracle is implemented as a single process with multiple threads. In the past, on IBM mainframe systems, running OS/390 and z/OS, the Oracle operating system–specific architecture exploits multiple OS/390 address spaces, all operating as a single Oracle instance. Up to 255 address spaces can be configured for a single database instance. Moreover, Oracle works together with OS/390 Workload Manager (WLM) to establish the execution priority of specific Oracle workloads relative to each other and relative to all other work in the OS/390 system. Even though the physical mechanisms used to implement Oracle from platform to platform vary, the architecture is sufficiently generalized that you can get a good understanding of how Oracle works on all platforms.
In this chapter, I present a broad picture of this architecture. We’ll take a look at the Oracle server and define some terms such as database, pluggable database, container database, and instance (terms that always seem to cause confusion). We’ll take a look at what happens when you “connect” to Oracle and, at a high level, how the server manages memory. In the subsequent three chapters, we’ll look in detail at the three major components of the Oracle architecture:
· Chapter 3 covers files. Here we’ll look at the five general categories of files that make up the database: parameter, data, temp, control, and redo log files. We’ll also cover other types of files, including trace, alert, dump (DMP), data pump, and simple flat files. We’ll look at the file area (in Oracle 10g and above) called the Fast Recovery Area, and we’ll also discuss the impact that Automatic Storage Management (ASM) has on file storage.
· Chapter 4 covers the Oracle memory structures referred to as the System Global Area (SGA), Process Global Area (PGA), and User Global Area (UGA). We’ll examine the relationships between these structures, and we’ll also discuss the shared pool, large pool, Java pool, and various other SGA components.
· Chapter 5 covers Oracle’s physical processes or threads. We’ll look at the three different types of processes that will be running on the database: server processes, background processes, and slave processes.
It was hard to decide which of these components to cover first. The processes use the SGA, so discussing the SGA before the processes might not make sense. On the other hand, when discussing the processes and what they do, I’ll need to make references to the SGA. These two components are closely tied: the files are acted on by the processes and won’t make sense without first understanding what the processes do.
What I’ll do, then, is define some terms and give a general overview of what Oracle looks like (if you were to draw it on a whiteboard). There will be two architectures to consider. One is the architecture the Oracle database employed exclusively from version 6 through 11g (referred to now as single tenant in this book) and a new multitenant architecture available with Oracle 12c. You’ll then be ready to get into some of the details.
Defining Database and Instance
There are two terms that, when used in an Oracle context, seem to cause a great deal of confusion: database and instance. In Oracle terminology, the definitions of these terms are as follows:
· Database: A collection of physical operating system files or disks. When using Oracle Automatic Storage Management (ASM) or RAW partitions, the database may not appear as individual, separate files in the operating system, but the definition remains the same. There are three distinct types of databases in Oracle Database 12c.
· A single-tenant database: This is a self-contained set of data files, control files, redo log files, parameter files, and so on, that include all of the Oracle metadata (the definition of ALL_OBJECTS, for example), Oracle data, and Oracle code (such as the code forDBMS_OUTPUT), in addition to all of the application metadata, data, and code. This is the only type of database in releases prior to version 12c.
· A container or root database: This is a self-contained set of data files, control files, redo log files, parameter files, and so on, that only include the Oracle metadata, Oracle data, and Oracle code. There are no application objects or code in these data files—only Oracle-supplied metadata and Oracle-supplied code objects. This database is self-contained in that it can be mounted and opened without any other supporting physical structures.
· A pluggable database: This is a set of data files only. It is not self-contained. A pluggable database needs a container database to be “plugged into” to be opened and accessible. These data files contain only metadata for application objects, application data, and code for those applications. There is no Oracle metadata or any Oracle code in these data files. There are no redo log files, control files, parameter files, and so on—only data files associated with a pluggable database. The pluggable database inherits these other types of files from the container database it is currently plugged into.
· Instance: A set of Oracle background processes or threads and a shared memory area, which is memory that is shared across those threads or processes running on a single computer. This is the place for volatile, nonpersistent stuff, some of which gets flushed to disk. A database instance can exist without any disk storage whatsoever. It might not be the most useful thing in the world, but thinking about it that way definitely helps draw the line between the instance and the database.
The two terms, instance and database, are sometimes used interchangeably, but they embrace very different concepts, especially now in the multitenant architecture. The relationship between them is that a single-tenant or container database (herein referred to simply as database, meaning either a single-tenant or container database; when discussing pluggable databases, pluggable will be explicitly referenced) may be mounted and opened by many instances. An instance may mount and open just a single database at any point in time. In fact, it is true to say that an instance will mount and open, at most, a single database in its entire lifetime! We’ll look at an example of that in a moment.
A pluggable database will be associated with a single container database at a time and is only indirectly associated with an instance; it will share the instance created to mount and open the container database. So, like a container database, a pluggable database can be associated with one or more instances at any point in time. Unlike a single-tenant database, however, an instance may be providing access to many (up to around 250) pluggable databases simultaneously. That is, a single instance may be providing services for many pluggable databases, but only one container or single-tenant database.
Confused even more? Some further explanation should help clear up these concepts.
An instance is simply a set of operating system processes, or a single process with many threads, and some memory. These processes can operate on a single database, which is just a collection of files (data files, temporary files, redo log files, and control files). At any time, an instance will have only one set of files (one container or single-tenant database) associated with it. Multiple pluggable databases, subordinate to the container database, can be open and accessible simultaneously—but will all share the single instance created to open the container database.
In most cases, the opposite is true as well: a container or single-tenant database will have only one instance working on it. However, in the special case of Oracle Real Application Clusters (RAC), an Oracle option that allows it to function on many computers in a clustered environment, we may have many instances simultaneously mounting and opening this one database, which resides on a set of shared physical disks. This gives us access to this single database from many different computers at the same time. Oracle RAC provides for extremely highly available systems and has the potential to architect extremely scalable solutions.
Let’s start by taking a look at a simple example. Let’s say we’ve just installed Oracle 12c version 12.1.0.1 on our UNIX/Linux–based computer. We did a software-only installation. No starter databases, nothing—just the software.
The pwd command shows the current working directory, dbs (on Windows, this would be the database directory) and the ls –l command shows that the directory is empty. There is no init.ora file and no SPFILEs (stored parameter files; these will be discussed in detail inChapter 3).
[ora12cr1@dellpe dbs]$ pwd
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs
[ora12cr1@dellpe dbs]$ ls -l
total 0
Using the ps (process status) command, we can see all processes being run by the user ora12cr1 (the Oracle software owner in this case). There are no Oracle database processes whatsoever at this point.
[ora12cr1@dellpe dbs]$ ps -aef | grep ora12cr1
root 18392 15416 0 14:31 pts/1 00:00:00 su - ora12cr1
ora12cr1 18401 18392 0 14:31 pts/1 00:00:00 -bash
ora12cr1 18461 18401 0 14:34 pts/1 00:00:00 ps -aef
ora12cr1 18462 18401 0 14:34 pts/1 00:00:00 grep ora12cr1
We then enter the ipcs command, a UNIX/Linux command that is used to show interprocess communication devices, such as shared memory, semaphores, and the like. Currently, there are none in use on this system at all.
[ora12cr1@dellpe dbs]$ ipcs -a
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
------ Message Queues --------
key msqid owner perms used-bytes messages
We then start up SQL*Plus (Oracle’s command-line interface) and connect as sysdba (the account that is allowed to do virtually anything in the database). Initially, assuming you haven’t yet set the environment variable ORACLE_SID, you’ll see the following:
[ora12cr1@dellpe dbs]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.1.0 Production on Mon Sep 2 14:35:52 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
ERROR:
ORA-12162: TNS:net service name is incorrectly specified
This error occurs because the database software has no idea what to try to connect to. When you connect, the Oracle software will look for a TNS connect string (a network connection). If, as in our example, the connect string is not supplied, the Oracle software will look at the environment for a variable named ORACLE_SID (on Windows, it would look also in the registry for the ORACLE_SID variable). The ORACLE_SID is the Oracle “site identifier;” it is sort of a key to gain access to an instance. If we set our ORACLE_SID:
[ora12cr1@dellpe dbs]$ export ORACLE_SID=ora12c
the connection is successful and SQL*Plus reports we are connected to an idle instance:
[ora12cr1@dellpe dbs]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.1.0 Production on Mon Sep 2 14:36:54 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to an idle instance.
SQL>
Our “instance” right now consists solely of the Oracle server process shown in bold in the following output. There is no shared memory allocated yet and no other processes.
SQL> !ps -aef | grep ora12cr1
root 18392 15416 0 14:31 pts/1 00:00:00 su - ora12cr1
ora12cr1 18401 18392 0 14:31 pts/1 00:00:00 -bash
ora12cr1 18474 18473 0 14:36 pts/0 00:00:00 .../dbhome_1/bin/sqlplus as sysdba
ora12cr1 18475 18474 0 14:36 ? 00:00:00 oracleora12c (DESCRIPTION=(LOCAL=YES)
(ADDRESS=(PROTOCOL=beq)))
ora12cr1 18482 18474 0 14:38 pts/0 00:00:00 /bin/bash -c ps -aef | grep ora12cr1
ora12cr1 18483 18482 0 14:38 pts/0 00:00:00 ps -aef
ora12cr1 18484 18482 0 14:38 pts/0 00:00:00 grep ora12cr1
SQL> !ipcs -a
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
------ Message Queues --------
key msqid owner perms used-bytes messages
![]() Note On Windows, Oracle executes as a single process with threads; you won’t see separate processes as on UNIX/Linux. Moreover, the Windows threads will not have the same names as the processes just shown. I am using UNIX/Linux specifically here so we can differentiate the individual processes and “see” them clearly.
Note On Windows, Oracle executes as a single process with threads; you won’t see separate processes as on UNIX/Linux. Moreover, the Windows threads will not have the same names as the processes just shown. I am using UNIX/Linux specifically here so we can differentiate the individual processes and “see” them clearly.
One interesting thing to note from this ps output is the process named oracleora12c. No matter how hard you look on your system, you will not find an executable by that name. The Oracle binary that is executing is really the binary file $ORACLE_HOME/bin/oracle.
![]() Note It is assumed that the environment variable (on UNIX/Linux) or registry setting (on Windows) named ORACLE_HOME has been set and represents the fully qualified path to where the Oracle software is installed.
Note It is assumed that the environment variable (on UNIX/Linux) or registry setting (on Windows) named ORACLE_HOME has been set and represents the fully qualified path to where the Oracle software is installed.
The Oracle developers simply rename the process as it is loaded into memory. The name of the single Oracle process that is running right now (our dedicated server process; more on this later) is oracle$ORACLE_SID. That naming convention makes it very easy to see what processes are associated with which instances and so on. So, let’s try to start the instance now:
SQL> startup
ORA-01078: failure in processing system parameters
LRM-00109: could not open parameter file '/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/
initora12c.ora'
Notice the error about a missing file named initora12c.ora. That file, referred to colloquially as an init.ora file, or more properly as a parameter file, is the sole file that must exist to start up an instance—we need either a parameter file (a simple flat file that I’ll describe in more detail shortly) or a stored parameter file.
We’ll create the parameter file now and put into it the minimal information we need to actually start a database instance. (Normally, we’d specify many more parameters, such as the database block size, control file locations, and so on). By default, this file is located in the$ORACLE_HOME/dbs directory and has the name init${ORACLE_SID}.ora:
[ora12cr1@dellpe dbs]$ cd $ORACLE_HOME/dbs
[ora12cr1@dellpe dbs]$ echo db_name=ora12c > initora12c.ora
[ora12cr1@dellpe dbs]$ cat initora12c.ora
db_name=ora12c
and then, once we get back into SQL*Plus:
[ora12cr1@dellpe dbs]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.1.0 Production on Mon Sep 2 14:42:27 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup nomount
ORACLE instance started.
Total System Global Area 329895936 bytes
Fixed Size 2287960 bytes
Variable Size 272631464 bytes
Database Buffers 50331648 bytes
Redo Buffers 4644864 bytes
We used the nomount option to the startup command since we don’t actually have a database to mount yet (the SQL*Plus documentation includes all of the startup and shutdown options).
![]() Note On Windows, prior to running the startup command, you’ll need to execute a service creation statement using the oradim.exe utility.
Note On Windows, prior to running the startup command, you’ll need to execute a service creation statement using the oradim.exe utility.
Now we have what I’d call an instance. The background processes needed to actually run a database are all there, including process monitor (pmon), log writer (lgwr), and so on (these processes are covered in detail in Chapter 5). Let’s take a look:
SQL> !ps -aef | grep ora12cr1
root 18392 15416 0 14:31 pts/1 00:00:00 su - ora12cr1
ora12cr1 18401 18392 0 14:31 pts/1 00:00:00 -bash
ora12cr1 18499 18401 0 14:42 pts/1 00:00:00 rlwrap /home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/bin/sqlplus / as sysdba
ora12cr1 18500 18499 0 14:42 pts/0 00:00:00 /home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/bin/sqlplus as sysdba
ora12cr1 18508 1 0 14:43 ? 00:00:00 ora_pmon_ora12c
ora12cr1 18510 1 0 14:43 ? 00:00:00 ora_psp0_ora12c
ora12cr1 18512 1 0 14:43 ? 00:00:00 ora_vktm_ora12c
ora12cr1 18516 1 0 14:43 ? 00:00:00 ora_gen0_ora12c
ora12cr1 18518 1 0 14:43 ? 00:00:00 ora_mman_ora12c
ora12cr1 18522 1 0 14:43 ? 00:00:00 ora_diag_ora12c
ora12cr1 18524 1 0 14:43 ? 00:00:00 ora_dbrm_ora12c
ora12cr1 18526 1 0 14:43 ? 00:00:00 ora_dia0_ora12c
ora12cr1 18528 1 0 14:43 ? 00:00:00 ora_dbw0_ora12c
ora12cr1 18530 1 0 14:43 ? 00:00:00 ora_lgwr_ora12c
ora12cr1 18532 1 0 14:43 ? 00:00:00 ora_ckpt_ora12c
ora12cr1 18534 1 0 14:43 ? 00:00:00 ora_lg00_ora12c
ora12cr1 18536 1 0 14:43 ? 00:00:00 ora_lg01_ora12c
ora12cr1 18538 1 0 14:43 ? 00:00:00 ora_smon_ora12c
ora12cr1 18540 1 0 14:43 ? 00:00:00 ora_reco_ora12c
ora12cr1 18542 1 0 14:43 ? 00:00:00 ora_lreg_ora12c
ora12cr1 18544 1 0 14:43 ? 00:00:00 ora_mmon_ora12c
ora12cr1 18546 1 0 14:43 ? 00:00:00 ora_mmnl_ora12c
ora12cr1 18547 18500 0 14:43 ? 00:00:00 oracleora12c (DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))
ora12cr1 18566 18500 0 14:45 pts/0 00:00:00 /bin/bash -c ps -aef | grep ora12cr1
ora12cr1 18567 18566 0 14:45 pts/0 00:00:00 ps -aef
ora12cr1 18568 18566 0 14:45 pts/0 00:00:00 grep ora12cr1
Additionally, ipcs, for the first time, reports the use of shared memory and semaphores—two important interprocess communication devices on UNIX/Linux:
SQL> !ipcs -a
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x10d1c894 13074435 ora12cr1 660 10485760 38
0x00000000 13107204 ora12cr1 660 322961408 19
------ Semaphore Arrays --------
key semid owner perms nsems
0xfc46e83c 425986 ora12cr1 660 171
0xfc46e83d 458755 ora12cr1 660 171
0xfc46e83e 491524 ora12cr1 660 171
0xfc46e83f 524293 ora12cr1 660 171
0xfc46e840 557062 ora12cr1 660 171
------ Message Queues --------
key msqid owner perms used-bytes messages
Note we have no “database” yet. We have the name of a database (in the parameter file we created), but no actual database. If we try to “mount” this database, it would fail because, quite simply, the database does not yet exist. Let’s create it. I’ve been told that creating an Oracle database involves quite a few steps, but let’s see:
SQL> create database;
Database created.
That is actually all there is to creating a database. In the real world, however, we’d use a slightly more complicated form of the CREATE DATABASE command because we would want to tell Oracle where to put the online redo log files, data files, control files, and so on. But we do now have a fully operational database. We still need to run the $ORACLE_HOME/rdbms/admin/catalog.sql script and other catalog scripts to build the rest of the data dictionary we use every day (the views we use such as ALL_OBJECTS are not yet present in this database), but we have an actual database here. We can use a simple query against some Oracle V$ views, specifically V$DATAFILE, V$LOGFILE, and V$CONTROLFILE, to list the files that make up this database.
SQL> select name from v$datafile;
NAME
-------------------------------------------------------------------------------
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/dbs1ora12c.dbf
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/dbx1ora12c.dbf
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/dbu1ora12c.dbf
SQL> select member from v$logfile;
MEMBER
-------------------------------------------------------------------------------
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/log1ora12c.dbf
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/log2ora12c.dbf
SQL> select name from v$controlfile;
NAME
-------------------------------------------------------------------------------
/home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/dbs/cntrlora12c.dbf
Oracle used defaults to put everything together and created a database as a set of persistent files. If we close this database and try to open it again, we’ll discover that we can’t:
SQL> alter database close;
Database altered.
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-16196: database has been previously opened and closed
An instance can mount and open, at most, one database—a single-tenant or container database—in its lifetime. Remember, the instance consists simply of the processes and shared memory. This is still up and running. All we did was close the database—that is, the physical files. We must discard this instance (shutdown) and create a new one (startup) to open this or any other database.
To recap:
· An instance is a set of background processes and shared memory.
· A (single-tenant or container) database is a self-contained collection of data stored on disk.
· An instance can mount and open only a single database, ever. As we’ll see later, it may provide access to many pluggable databases and “open” and “close” them multiple times; however, it will only ever open a single self-contained database.
· A database may be mounted and opened by one or more instances (using RAC) and the number of instances mounting a single database can fluctuate over time.
As noted earlier, in most cases there’s a one-to-one relationship between an instance and a database. This is probably why the confusion surrounding the terms arises. In most peoples’ experiences, a database is an instance, and an instance is a database.
In many test environments, however, this is not the case. On my disk, I might have five separate databases. On the test machine, at any point in time there is only one instance of Oracle running, but the database it is accessing may be different from day to day or hour to hour, depending on my needs. By simply having many different parameter files, I can mount and open any one of these databases. Here, I have one instance at a time but many databases, only one of which is accessible at any time.
So now when people talk about an instance, you’ll know they mean the processes and memory of Oracle. When they mention the database, they are talking about the physical files that hold the data. A database may be accessible from many instances, but an instance will provide access to exactly one database (single-tenant or container database) at a time.
The SGA and Background Processes
You’re probably ready now for an abstract picture of what an Oracle instance and database look like, so take a look at Figure 2-1.
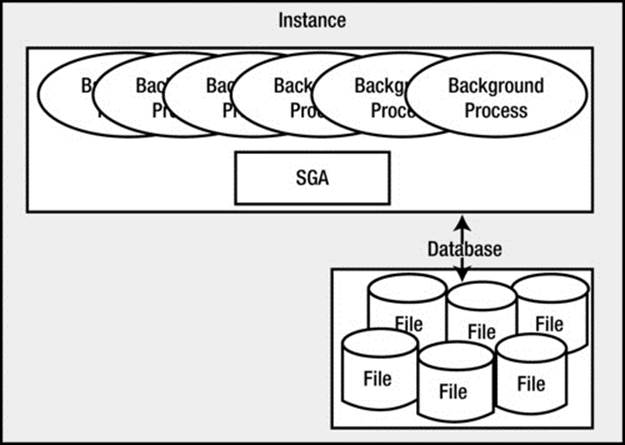
Figure 2-1. Oracle instance and database
Figure 2-1 shows an Oracle instance and database in their simplest form. Oracle has a large chunk of memory called the SGA that it uses, for example, to do the following:
· Maintain many internal data structures that all processes need access to.
· Cache data from disk; buffer redo data before writing it to disk.
· Hold parsed SQL plans.
· And so on.
Oracle has a set of processes that are “attached” to this SGA, and the mechanism by which they attach differs by operating system. In a UNIX/Linux environment, the processes will physically attach to a large shared memory segment, a chunk of memory allocated in the OS that may be accessed by many processes concurrently (generally using shmget() and shmat()).
Under Windows, these processes simply use the C call, malloc() to allocate the memory, since they are really threads in one big process and hence share the same virtual memory space.
Oracle also has a set of files that the database processes or threads read and write (and Oracle processes are the only ones allowed to read or write these files). In a single-tenant architecture, these files hold all of our table data, indexes, temporary space, redo logs, PL/SQL code, and so on. In a multitenant architecture, the container database will hold all of the Oracle-related metadata, data, and code; our application data will be separately contained in a pluggable database, which we have yet to create. The database we created earlier is a single-tenant database by default; it does not have pluggable databases enabled. The self-contained set of files includes data files that contain both the Oracle data, as well as the application data.
If you were to start up Oracle on a UNIX/Linux–based system and execute a ps command, you’d see that many physical processes are running, with various names. You saw an example of that earlier when you observed the pmon, smon, and other processes. I cover these processes inChapter 5, so just be aware for now that they are commonly referred to as the Oracle background processes. They are persistent processes that make up the instance, and you’ll see them from the time you start the instance until you shut it down.
It is interesting to note that these are processes, not individual programs. There is only one Oracle binary executable on UNIX/Linux; it has many “personalities,” depending on what it was told to do when it starts up. The same binary executable that was run to start ora_pmon_ora12cwas also used to start the process ora_ckpt_ora12c. There is only one binary executable program, named simply oracle. It is just executed many times with different names.
On Windows, using the pstat tool (part of the Windows XP Resource Kit; search for “pstat download” using your favorite search engine if you don’t have it), we’ll find only one process, oracle.exe. Again, on Windows there is only one binary executable (oracle.exe). Within this process, we’ll find many threads representing the Oracle background processes.
Using pstat (or any of a number of tools, such as tasklist, which comes with many Windows versions), we can see these processes:
C:\WINDOWS> pstat
Pstat version 0.3: memory: 523760 kb uptime: 0 1:37:54.375
PageFile: \??\C:\pagefile.sys
Current Size: 678912 kb Total Used: 228316 kb Peak Used 605488 kb
Memory: 523760K Avail: 224492K TotalWs: 276932K InRam Kernel: 872K P:20540K
Commit: 418468K/ 372204K Limit:1169048K Peak:1187396K Pool N:10620K P:24588K
User Time Kernel Time Ws Faults Commit Pri Hnd Thd Pid Name
56860 2348193 File Cache
0:00:00.000 1:02:23.109 28 0 0 0 0 1 0 Idle Process
0:00:00.000 0:01:50.812 32 4385 28 8 694 52 4 System
0:00:00.015 0:00:00.109 60 224 172 11 19 3 332 smss.exe
0:00:33.234 0:00:32.046 2144 33467 1980 13 396 14 556 csrss.exe
0:00:00.343 0:00:01.750 3684 6811 7792 13 578 20 580 winlogon.exe
0:00:00.078 0:00:01.734 1948 3022 1680 9 275 16 624 services.exe
0:00:00.218 0:00:03.515 1896 5958 3932 9 363 25 636 lsass.exe
0:00:00.015 0:00:00.078 80 804 592 8 25 1 812 vmacthlp.exe
0:00:00.093 0:00:00.359 1416 2765 3016 8 195 17 828 svchost.exe
0:00:00.062 0:00:00.453 1340 3566 1764 8 244 10 896 svchost.exe
0:00:00.828 0:01:16.593 9632 36387 11708 8 1206 59 1024 svchost.exe
0:00:00.046 0:00:00.640 1020 2315 1300 8 81 6 1100 svchost.exe
0:00:00.015 0:00:00.234 736 2330 1492 8 165 11 1272 svchost.exe
0:00:00.015 0:00:00.218 128 1959 3788 8 117 10 1440 spoolsv.exe
0:00:01.312 0:00:19.828 13636 35525 14732 8 575 19 1952 explorer.exe
0:00:00.250 0:00:00.937 956 1705 856 8 29 1 228 VMwareTray.exe
0:00:00.812 0:00:04.562 1044 4619 3800 8 165 4 240 VMwareUser.exe
0:00:00.015 0:00:00.156 88 1049 1192 8 88 4 396 svchost.exe
0:00:00.109 0:00:04.640 744 1229 2432 8 81 3 460 cvpnd.exe
0:00:02.015 0:00:12.078 1476 17578 1904 13 139 3 600 VMwareService.exe
0:00:00.031 0:00:00.093 124 1004 1172 8 105 6 192 alg.exe
0:00:00.062 0:00:00.937 2648 13977 22656 8 101 3 720 TNSLSNR.EXE
0:04:00.359 0:02:57.734 164844 2009785 279168 8 550 29 1928 oracle.exe
0:00:00.093 0:00:00.437 6736 2316 2720 8 141 6 1224 msiexec.exe
0:00:00.015 0:00:00.031 2668 701 1992 8 34 1 804 cmd.exe
0:00:00.015 0:00:00.000 964 235 336 8 11 1 2856 pstat.exe
Here we can see there are 29 threads (Thd in the display) contained in the single Oracle process. These threads represent what were processes on UNIX/Linux—they are the pmon, arch, lgwr, and so on. They each represent a separate bit of the Oracle process. Paging down through thepstat report, we can see more details about each thread:
pid:788 pri: 8 Hnd: 550 Pf:2009785 Ws: 164844K oracle.exe
tid pri Ctx Swtch StrtAddr User Time Kernel Time State
498 9 651 7C810705 0:00:00.000 0:00:00.203 Wait:Executive
164 8 91 7C8106F9 0:00:00.000 0:00:00.000 Wait:UserRequest
...
a68 8 42 7C8106F9 0:00:00.000 0:00:00.031 Wait:UserRequest
We can’t see the thread “names” like we could on UNIX/Linux (ora_pmon_ora12c and so on), but we can see the thread IDs (Tid), priorities (Pri), and other operating system accounting information about them.
Connecting to Oracle
In this section, we’ll take a look at the mechanics behind the two most common ways to have requests serviced by an Oracle server: dedicated server and shared server connections. We’ll see what happens on the client and the server in order to establish connections, so we can log in and actually do work in the database. Lastly, we’ll take a brief look at how to establish TCP/IP connections; TCP/IP is the primary networking protocol used to connect over the network to Oracle. And we’ll look at how the listener process on our server, which is responsible for establishing the physical connection to the server, works differently in the cases of dedicated and shared server connections.
Dedicated Server
Figure 2-1 and the following ps output present a picture of what an Oracle database named ora12cr1 might look like immediately after starting.
[tkyte@dellpe]$ ps -aef | grep _$ORACLE_SID
ora12cr1 19607 1 0 15:16 ? 00:00:00 ora_pmon_ora12cr1
ora12cr1 19609 1 0 15:16 ? 00:00:00 ora_psp0_ora12cr1
ora12cr1 19611 1 0 15:16 ? 00:00:00 ora_vktm_ora12cr1
ora12cr1 19615 1 0 15:16 ? 00:00:00 ora_gen0_ora12cr1
ora12cr1 19617 1 1 15:16 ? 00:00:00 ora_mman_ora12cr1
ora12cr1 19621 1 0 15:16 ? 00:00:00 ora_diag_ora12cr1
ora12cr1 19623 1 0 15:16 ? 00:00:00 ora_dbrm_ora12cr1
ora12cr1 19625 1 0 15:16 ? 00:00:00 ora_dia0_ora12cr1
ora12cr1 19627 1 0 15:16 ? 00:00:00 ora_dbw0_ora12cr1
ora12cr1 19629 1 0 15:16 ? 00:00:00 ora_lgwr_ora12cr1
ora12cr1 19631 1 0 15:16 ? 00:00:00 ora_ckpt_ora12cr1
ora12cr1 19633 1 0 15:16 ? 00:00:00 ora_lg00_ora12cr1
ora12cr1 19635 1 0 15:16 ? 00:00:00 ora_lg01_ora12cr1
ora12cr1 19637 1 0 15:16 ? 00:00:00 ora_smon_ora12cr1
ora12cr1 19639 1 0 15:16 ? 00:00:00 ora_reco_ora12cr1
ora12cr1 19641 1 0 15:16 ? 00:00:00 ora_lreg_ora12cr1
ora12cr1 19643 1 1 15:16 ? 00:00:00 ora_mmon_ora12cr1
ora12cr1 19645 1 0 15:16 ? 00:00:00 ora_mmnl_ora12cr1
ora12cr1 19647 1 0 15:16 ? 00:00:00 ora_d000_ora12cr1
ora12cr1 19649 1 0 15:16 ? 00:00:00 ora_s000_ora12cr1
ora12cr1 19661 1 0 15:16 ? 00:00:00 ora_tmon_ora12cr1
ora12cr1 19663 1 0 15:16 ? 00:00:00 ora_tt00_ora12cr1
ora12cr1 19665 1 0 15:16 ? 00:00:00 ora_smco_ora12cr1
ora12cr1 19667 1 0 15:16 ? 00:00:00 ora_fbda_ora12cr1
ora12cr1 19671 1 0 15:16 ? 00:00:00 ora_aqpc_ora12cr1
ora12cr1 19675 1 0 15:16 ? 00:00:00 ora_cjq0_ora12cr1
ora12cr1 19705 1 0 15:16 ? 00:00:00 ora_w000_ora12cr1
ora12cr1 19708 1 0 15:16 ? 00:00:00 ora_qm02_ora12cr1
ora12cr1 19710 1 0 15:16 ? 00:00:00 ora_qm03_ora12cr1
ora12cr1 19712 1 0 15:16 ? 00:00:00 ora_q002_ora12cr1
ora12cr1 19714 1 0 15:16 ? 00:00:00 ora_q003_ora12cr1
tkyte 19720 15416 0 15:16 pts/1 00:00:00 grep _ora12cr1
If we were now to log into this database using a dedicated server, we would see a new process (or a thread on some other operating systems) get created just to service us:
OPS$TKYTE@ORA12CR1> !ps -aef | grep $ORACLE_SID
ora12cr1 19607 1 0 15:16 ? 00:00:00 ora_pmon_ora12cr1
ora12cr1 19609 1 0 15:16 ? 00:00:00 ora_psp0_ora12cr1
ora12cr1 19611 1 0 15:16 ? 00:00:00 ora_vktm_ora12cr1
ora12cr1 19615 1 0 15:16 ? 00:00:00 ora_gen0_ora12cr1
ora12cr1 19617 1 0 15:16 ? 00:00:00 ora_mman_ora12cr1
ora12cr1 19621 1 0 15:16 ? 00:00:00 ora_diag_ora12cr1
ora12cr1 19623 1 0 15:16 ? 00:00:00 ora_dbrm_ora12cr1
ora12cr1 19625 1 0 15:16 ? 00:00:00 ora_dia0_ora12cr1
ora12cr1 19627 1 0 15:16 ? 00:00:00 ora_dbw0_ora12cr1
ora12cr1 19629 1 0 15:16 ? 00:00:00 ora_lgwr_ora12cr1
ora12cr1 19631 1 0 15:16 ? 00:00:00 ora_ckpt_ora12cr1
ora12cr1 19633 1 0 15:16 ? 00:00:00 ora_lg00_ora12cr1
ora12cr1 19635 1 0 15:16 ? 00:00:00 ora_lg01_ora12cr1
ora12cr1 19637 1 0 15:16 ? 00:00:00 ora_smon_ora12cr1
ora12cr1 19639 1 0 15:16 ? 00:00:00 ora_reco_ora12cr1
ora12cr1 19641 1 0 15:16 ? 00:00:00 ora_lreg_ora12cr1
ora12cr1 19643 1 0 15:16 ? 00:00:00 ora_mmon_ora12cr1
ora12cr1 19645 1 0 15:16 ? 00:00:00 ora_mmnl_ora12cr1
ora12cr1 19647 1 0 15:16 ? 00:00:00 ora_d000_ora12cr1
ora12cr1 19649 1 0 15:16 ? 00:00:00 ora_s000_ora12cr1
ora12cr1 19661 1 0 15:16 ? 00:00:00 ora_tmon_ora12cr1
ora12cr1 19663 1 0 15:16 ? 00:00:00 ora_tt00_ora12cr1
ora12cr1 19665 1 0 15:16 ? 00:00:00 ora_smco_ora12cr1
ora12cr1 19667 1 0 15:16 ? 00:00:00 ora_fbda_ora12cr1
ora12cr1 19671 1 0 15:16 ? 00:00:00 ora_aqpc_ora12cr1
ora12cr1 19675 1 0 15:16 ? 00:00:00 ora_cjq0_ora12cr1
ora12cr1 19705 1 0 15:16 ? 00:00:00 ora_w000_ora12cr1
ora12cr1 19708 1 0 15:16 ? 00:00:00 ora_qm02_ora12cr1
ora12cr1 19712 1 0 15:16 ? 00:00:00 ora_q002_ora12cr1
ora12cr1 19714 1 0 15:16 ? 00:00:00 ora_q003_ora12cr1
tkyte 19732 19731 0 15:17 pts/0 00:00:00 /home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/
bin/sqlplus
ora12cr1 19733 19732 0 15:17 ? 00:00:00 oracleora12cr1 (DESCRIPTION=(LOCAL=YES)
(ADDRESS=(PROTOCOL=beq)))
tkyte 19744 19742 0 15:18 pts/0 00:00:00 grep ora12cr1
Now you can see that there is a new process, oracleora12cr1, created as our dedicated server process. When we log out, the extra thread/process will go away.
This brings us to the next iteration of our diagram. If we were to connect to Oracle in its most commonly used configuration, we would see something like Figure 2-2.
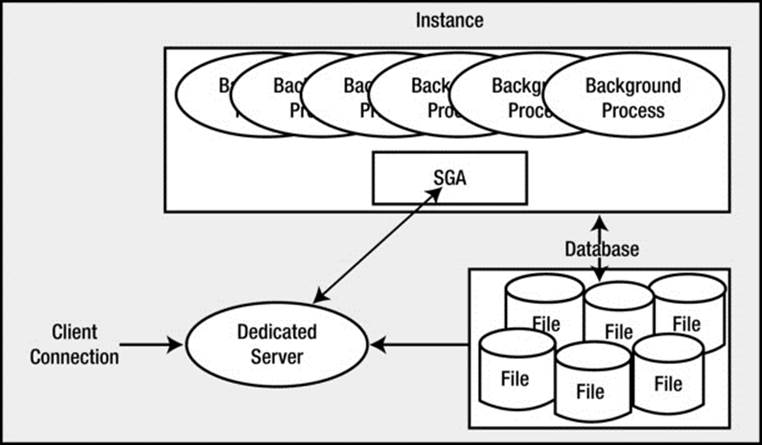
Figure 2-2. Typical dedicated server configuration
As noted, typically Oracle will create a new process for me when I log in. This is commonly referred to as the dedicated server configuration, since a server process will be dedicated to me for the life of my session. For each session, a new dedicated server will appear in a one-to-one mapping. This dedicated server process is not (by definition) part of the instance. My client process (whatever program is trying to connect to the database) will be in direct communication with this dedicated server over some networking conduit, such as a TCP/IP socket. It is this server process that will receive my SQL and execute it for me. It will read data files if necessary, and it will look in the database’s cache for my data. It will perform my update statements. It will run my PL/SQL code. Its only goal is to respond to the SQL calls I submit to it.
Shared Server
Oracle can also accept connections in a manner called shared server, in which you wouldn’t see an additional thread created or a new UNIX/Linux process appear for each user connection.
![]() Note In Version 7.x and 8.x of Oracle, shared server was known as multithreaded server or MTS. That legacy name is not in use anymore.
Note In Version 7.x and 8.x of Oracle, shared server was known as multithreaded server or MTS. That legacy name is not in use anymore.
In a shared server, Oracle uses a pool of shared processes for a large community of users. Shared servers are simply a connection pooling mechanism. Instead of having 10,000 dedicated servers (that’s a lot of processes or threads) for 10,000 database sessions, a shared server lets us have a small percentage of these processes or threads, which are (as the name implies) shared by all sessions. This allows Oracle to connect many more users to the instance than would otherwise be possible. Our machine might crumble under the load of managing 10,000 processes, but managing 100 or 1,000 processes is doable. In shared server mode, the shared processes are generally started up with the database and appear in the ps list.
A big difference between shared and dedicated server connections is that the client process connected to the database never talks directly to a shared server, as it would to a dedicated server. It can’t talk to a shared server because that process is, in fact, shared. In order to share these processes, we need another mechanism through which to “talk.” Oracle employs a process (or set of processes) called a dispatcher for this purpose. The client process will talk to a dispatcher process over the network. The dispatcher process will put the client’s request into the request queue in the SGA (one of the many things the SGA is used for). The first shared server that is not busy will pick up this request and process it (e.g., the request could be UPDATE T SET X = X+5 WHERE Y = 2). Upon completion of this command, the shared server will place the response in the invoking dispatcher’s response queue. The dispatcher process monitors this queue and, upon seeing a result, will transmit it to the client. Conceptually, the flow of a shared server request looks like Figure 2-3.
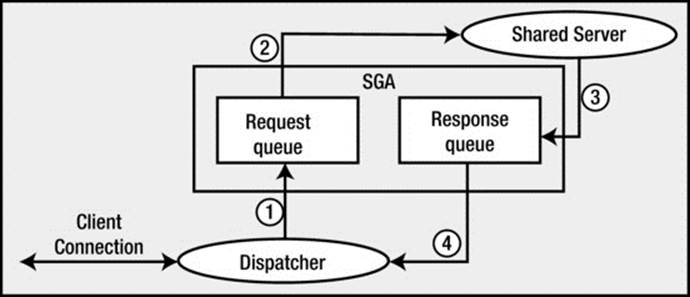
Figure 2-3. Steps in a shared server request
As shown in Figure 2-3, the client connection will send a request to the dispatcher. The dispatcher will first place this request onto the request queue in the SGA (1). The first available shared server will dequeue this request (2) and process it. When the shared server completes, the response (return codes, data, and so on) is placed into the response queue (3), subsequently picked up by the dispatcher (4), and transmitted back to the client.
As far as the developer is concerned, there is conceptually no difference between a shared server connection and a dedicated server connection. Architecturally they are quite different, but that’s not apparent to an application.
Now that you understand what dedicated server and shared server connections are, you may have the following questions:
· How do I get connected in the first place?
· What would start this dedicated server?
· How might I get in touch with a dispatcher?
The answers depend on your specific platform, but the sections that follow outline the process in general terms.
Mechanics of Connecting over TCP/IP
We’ll investigate the most common networking case: a network-based connection request over TCP/IP. In this case, the client is situated on one machine and the server resides on another, with the two connected on a TCP/IP network. It all starts with the client. The client makes a request using the Oracle client software (a set of provided application program interfaces, or APIs) to connect to a database. For example, the client issues the following:
[tkyte@dellpe ~]$ sqlplus scott/tiger@ora12cr1
SQL*Plus: Release 12.1.0.1.0 Production on Mon Sep 2 15:25:06 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Last Successful login time: Mon Sep 02 2013 13:44:49 -04:00
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
SCOTT@ORA12CR1>
![]() Note The string ora12cr1 used here is unique to my configuration. I have a tnsnames.ora entry (more on that next) named ora12cr1. It is a TNS connect string that points to an existing, installed and configured Oracle 12c Release 1 instance on my network. You will be using your own TNS connect strings, unique to your installation.
Note The string ora12cr1 used here is unique to my configuration. I have a tnsnames.ora entry (more on that next) named ora12cr1. It is a TNS connect string that points to an existing, installed and configured Oracle 12c Release 1 instance on my network. You will be using your own TNS connect strings, unique to your installation.
Here, the client is the program SQL*Plus, scott/tiger is the username and password, and ora12cr1 is a TNS service name. TNS stands for Transparent Network Substrate and is “foundation” software built into the Oracle client that handles remote connections, allowing for peer-to-peer communication. The TNS connection string tells the Oracle software how to connect to the remote database. Generally, the client software running on your machine will read a file called tnsnames.ora. This is a plain-text configuration file commonly found in the$ORACLE_HOME/network/admin directory ($ORACLE_HOME represents the full path to your Oracle installation directory). It will have entries that look like this:
SCOTT@ORA12CR1> !cat $ORACLE_HOME/network/admin/tnsnames.ora
# tnsnames.ora Network Configuration File: /home/ora12cr1/app/ora12cr1/product/12.1.0/dbhome_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
ORA12CR1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = somehost.somewhere.com)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora12cr1)
)
)
This configuration information allows the Oracle client software to map the TNS connection string we used, ora12cr1, into something useful—namely, a hostname, a port on that host on which a listener process will accept connections, the service name of the database on the host to which we wish to connect, and so on. A service name represents groups of applications with common attributes, service level thresholds, and priorities. The number of instances offering the service is transparent to the application, and each database instance may register with the listener as willing to provide many services. So, services are mapped to physical database instances and allow the DBA to associate certain thresholds and priorities with them.
This string, ora12cr1, could have been resolved in other ways. For example, it could have been resolved using a naming service provided by the Lightweight Directory Access Protocol (LDAP) server, similar in purpose to DNS for hostname resolution. However, use of thetnsnames.ora file is common in most small to medium installations (as measured by the number of hosts that need to connect to the database) where the number of copies of such a configuration file is manageable.
EASY CONNECT
The easy connect method allows you to connect to a remote database without the need of a tnsnames.ora file (or other methods of resolving the location of the database). If you know the name of the host, server, port, and service name, you can directly enter those on the command line. The syntax is as follows:
sqlplus username@[//]host[:port][/service_name][:server][/instance_name]
For example, assuming the host name is hesta, the port is 1521, and the service name is ora12cr1, then you can connect as follows:
$ sqlplus user/pass@hesta:1521/ora12cr1
The easy connect method is handy for situations in which you’re troubleshooting connectivity issues or when you don’t have a tnsnames.ora file available (or other ways to resolve the remote connection).
Now that the client software knows where to connect to, it will open a TCP/IP socket connection to the server with the hostname somehost.somewhere.com on port 1521 (this is the default listener port, and can be configured to run on other ports). If the DBA for our server has installed and configured Oracle Net, and has the listener listening on port 1521 for connection requests, this connection may be accepted. In a network environment, we will be running a process called the TNS listener on our server. This listener process is what will get us physically connected to our database. When it receives the inbound connection request, it inspects the request and, using its own configuration files, either rejects the request (because there is no such service, for example, or perhaps our IP address has been disallowed connections to this host) or accepts it and goes about getting us connected.
If we are making a dedicated server connection, the listener process will create a dedicated server for us. On UNIX/Linux, this is achieved via fork() and exec() system calls (the only way to create a new process after initialization in UNIX/Linux is via fork()). The new dedicated server process inherits the connection established by the listener, and we are now physically connected to the database. On Windows, the listener process requests the database process to create a new thread for a connection. Once this thread is created, the client is “redirected“ to it, and we are physically connected. Diagrammatically in UNIX/Linux, it would look as shown in Figure 2-4.
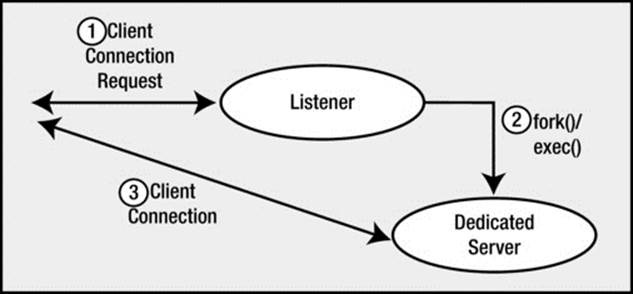
Figure 2-4. The listener process and dedicated server connections
However, the listener will behave differently if we are making a shared server connection request. This listener process knows the dispatcher(s) we have running in the instance. As connection requests are received, the listener will choose a dispatcher process from the pool of available dispatchers. The listener will either send back to the client the connection information describing how the client can connect to the dispatcher process or, if possible, hand off the connection to the dispatcher process (this is OS-and database version–dependent, but the net effect is the same). When the listener sends back the connection information, it is done because the listener is running on a well-known hostname and port on that host, but the dispatchers also accept connections on randomly assigned ports on that server. The listener is made aware of these random port assignments by the dispatcher and will pick a dispatcher for us. The client then disconnects from the listener and connects directly to the dispatcher. We now have a physical connection to the database. Figure 2-5 illustrates this process.
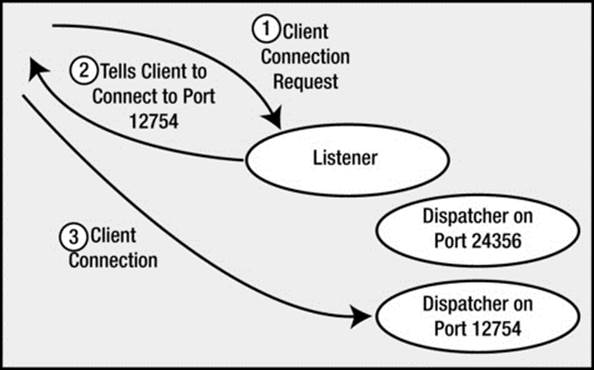
Figure 2-5. The listener process and shared server connections
Pluggable Databases
Starting with Oracle Database 12c, a new approach to the concept of a “database” was introduced. So far in this chapter, we have concentrated on the single-tenant or container databases and their association with instances (a database may have one or more instances; an instance will mount and open, at most, a single database). We are now ready to look at the concept of a pluggable database—what it is and how it operates. Pluggable databases in the multitenant architecture are non-self-contained sets of data files that consist purely of application data and metadata. There is no Oracle-specific data/metadata in them; that information is in the container database that they are currently associated with. A pluggable database—in order to be used, to be queried—must be associated with a container database. That container database will only have Oracle data and metadata in it—just the information Oracle needs to “run.” The pluggable databases have the “rest” of the database metadata and data.
So, for example, the container database would have the definition of the “SYS” user (the metadata for the SYS user) and the compiled code and source code for objects like DBMS_OUTPUT and UTL_FILE. A pluggable database, on the other hand, would have the definition of an application schema like SCOTT, all of the metadata describing the tables in the SCOTT schema, all of the PL/SQL source code for the SCOTT schema, all of the GRANTS granted to the SCOTT schema, and so on. In short, a pluggable database has everything that describes a set of application schemas—the metadata for the accounts, the metadata for the tables in those accounts, and the actual data for those tables. A pluggable database is self-contained with respect to the application accounts it contains, but it needs a container database to be “opened” and queried. Therefore, you can say that a pluggable database is not “self-contained,” it needs something else in order to be opened and used.
A pluggable database is not directly opened by an instance, but rather an Oracle instance must be started and a container database mounted and opened by that instance. Once the container instance is up and running, and the container database is opened, that container database may open as many as 250 separate pluggable databases. Each of these pluggable databases acts as if it were a “stand-alone” database. That is, they appear to be self-contained, stand-alone “single tenant” databases. But they all share the same container database and container instance.
The main goals of the pluggable database, the multitenant architecture, are twofold:
· To measurably reduce the amount of resources it takes to host many databases—many applications—on a single host.
· To reduce the maintenance work performed by the DBA to manage many databases—many applications—on a single host.
Reduced Resource Utilization
As you’ve already seen, when you start an Oracle instance, there are many processes associated with it. In Chapter 5 you’ll be introduced to each of them and see what they do; but as you can see, each instance is supported by some 20 to 40 processes. If you attempted to start up 50 single-tenant databases—where each database has an instance associated with it, or its own instance—you would have upward of 1,000 processes just to get the databases started! That is extremely taxing on the operating system, both to create that many processes and then to manage them.
Additionally, each instance would have its own SGA. Chapter 4 will cover what is in the SGA, but suffice it to say, there is a lot of duplication. Each SGA would have a cached copy of DBMS_OUTPUT in its shared pool, and each SGA would have a redo log buffer and many other duplicative data structures.
With pluggable databases, you can have the separation of application metadata, users, data, code, and so on, but avoid the redundant instances. That is, you can have a single instance with a single container database (the Oracle metadata, code, and data) that provides access to as many as 250 pluggable databases, each hosting a separate application. Instead of 1,000 processes to start up 50 separate application databases, you can have 51 databases (one container and 50 application databases) sharing the same 20 to 40 processes. That’s a massive reduction in server resource utilization. Additionally, they all share a common SGA, allowing the repetitive parts of the 50 separate SGAs that would normally have to be shared. In general, the size of the single SGA you would allocate for these 50 application databases will be smaller than the sum of the 50 separate SGAs you would have to allocate otherwise.
Reduced Maintenance
If a DBA were tasked with managing 50 separate databases using the single-tenant architecture, she would have 50 databases to backup, monitor, manage, patch, upgrade, and so on. Each database would be managed independent from every other database. In the multitenant architecture, there is a single “database” she would need to backup, monitor, manage, patch, upgrade and so on. For example, the act of patching an Oracle database involves updating the Oracle executables (updating the instance) and updating the Oracle metadata—the Oracle data dictionary. When a DBA patches a database, she does not touch any of the underlying application metadata, schemas, data, code, and so on—she only touches the Oracle instance and the Oracle metadata, data, and code.
Under the multitenant architecture, each of the 50 pluggable databases containing the application data share a common instance; hence when the DBA patches the instance, all 50 pluggable databases are patched instance wise. Likewise, when the DBA patches the container database, the self-contained set of files that hold the Oracle metadata, code, and data, all 50 pluggable databases inherit those updates. They share that Oracle metadata, code, and data. So the act of patching a single container database would, in fact, patch all of the underlying pluggable databases.
If that is not desirable (patching all 50 at once), an alternative approach can be applied. Instead of patching the existing container database, the DBA can just create a new container database that is patched. So now there are two Oracle instances with two container databases: one at version X and the other at version Y. In order to patch a pluggable database, the DBA “unplugs” it from the container database to which it is currently attached. Unplugging creates an XML manifest file that describes the files belonging to that pluggable database. Then, the DBA “plugs” that pluggable data into the new container database. The act of unplugging a pluggable database is very lightweight and fast—all that needs to be done is to create the XML manifest file. The act of plugging in a database is likewise lightweight and fast—the XML manifest file is read, the files associated with the pluggable database are registered with the container database, and the pluggable database can be used again. The pluggable database is patched or upgraded simply by plugging it into a container database that is patched. The DBA has one container database to manage, patch, upgrade, and so on. The pluggable databases just inherit that work.
How Is a Pluggable Database Different?
From the perspective of a developer, a pluggable database is no different from a single-tenant database. The application connects to the database in exactly the same way it would connect to a single-tenant database in earlier releases. The earlier examples of creating connections, using shared servers, and using dedicated servers all still apply. The differences lie in the underlying architecture—that of a single instance for many pluggable databases, and the resulting reduced resource utilization on the server and the ease of management for the DBA.
From a DBA perspective, there are many changes in the way a database is administered—positive changes. For example, if a DBA configured a container database for RAC, every pluggable database under that container would be RAC enabled. The same with Data Guard, RMAN backups, and so on. The DBA has one instance to configure and work with, instead of one instance per application as in the past.
Summary
This completes our overview of the Oracle architecture. In this chapter, we defined the terms instance, database, and pluggable database, and saw how to connect to the database through either a dedicated server connection or a shared server connection. Figure 2-6 sums up the material covered in the chapter and shows the interaction between a client using a shared server connection and a client using a dedicated server connection. It also shows that an Oracle instance may use both connection types simultaneously. (In fact, an Oracle database always supports dedicated server connections—even when configured for shared server.)
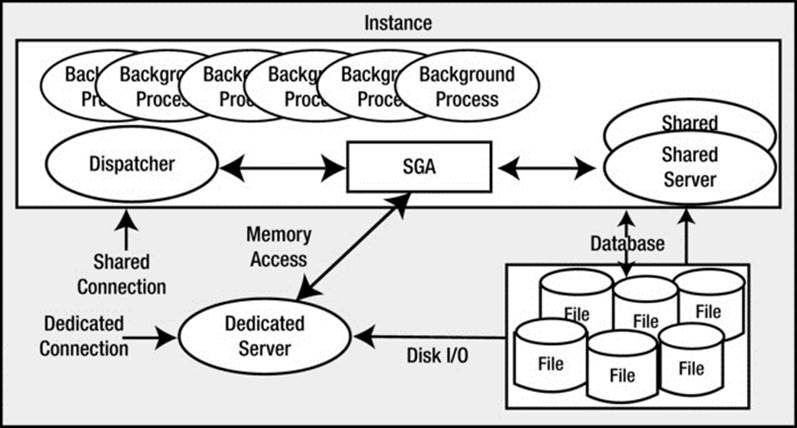
Figure 2-6. Connection overview
Now you’re ready to take a more in-depth look at the files that comprise the database and the processes behind the server—what they do and how they interact with each other. You’re also ready to look inside the SGA to see what it contains and what its purpose is. You’ll start in the next chapter by looking at the types of files Oracle uses to manage the data, and the role of each file type.