MySQL Stored Procedure Programming (2009)
Part III. Using MySQL Stored Programs in Applications
Chapter 14. Using MySQL Stored Programs with Java
PHP is undoubtedly the most popular language used in combination with MySQL to build commercial applications and—in particular—web applications. However, for applications that aspire to possibly greater scalability and standards compliance, Java offers an attractive alternative. The Java JDBC database-independent API provides robust and mature methods for performing all types of database interaction from within the Java environment and includes very strong support for handling stored programs. The J2EE standard provides a way for Java to be used within commercial and open source web or application servers to construct scalable and efficient web applications that can take advantage of MySQL as a database server, and MySQL stored programs as the interface to the database. There are also alternative Java frameworks such as Hibernate and Spring, which can expedite database access without adding all the overhead and complexity of a J2EE solution, and these can leverage stored programs as well.
In this chapter we will commence with a quick review of how you can use Java JDBC to perform interactions with the database not involving stored programs, including the basic prerequisite functions of installing and registering the JDBC driver and obtaining a connection to a MySQL server. We will also explain how to execute basic SQL from the driver and how to handle database errors.
Next, we'll proceed to examine the JDBC syntax for invoking stored programs, including handling input and output parameters and processing multiple result sets.
Finally, we'll look at how stored programs can be utilized within some of the popular Java frameworks, including servlets or Enterprise JavaBeans (EJB) within an application server, from Hibernate, or within the Spring framework.
Review of JDBC Basics
Before examining how we can use stored programs in JDBC , let's look at how JDBC supports database operations that don't include stored programs. These basic operations will serve as the foundation for JDBC that does use stored programs. If you are already familiar with JDBC, you might want to skip forward to "Using Stored Programs in JDBC," later in this chapter.
Installing the Driver and Configuring Your IDE
While the JDBC interface itself is part of native Java , to use JDBC with MySQL we will need to install a MySQL-aware JDBC driver. MySQL provides such a driver, Connector/J, which we can download from http://dev.mysql.com/downloads/connector/j.html. Installation is a simple matter of unpacking the contents of a .zip file or a tar archive to a convenient location on our hard drive.
To allow our Java programs to access the Connector/J archive, we need to add the Connector/J JAR (Java Archive) file to our system's CLASSPATH. For instance, if we unpacked the Connector/J files into a directory called C:\MySQL\ConnectorJ, then our CLASSPATH might look like this:
Set CLASSPATH=C:\MySQL\ConnectorJ\mysql-connector-java-3.1.10-bin.jar;.
Most Java IDEs require that we specify any required libraries in either a general or a project-specific dialog box. For example, in Eclipse, we can open the Properties dialog box for the project, select Java Build Path, click Add External JARs, then add the location of the Connector/J JAR file.Figure 14-1 shows the Eclipse dialog box for adding a required library.
Registering the Driver and Connecting to MySQL
Within our Java program we will normally import the java.sql package so that we don't have to fully qualify our references to JDBC classes, as shown in Example 14-1.
Example 14-1. Importing the java.sql package
package jdbc_example;
import java.sql.*;
Before we can connect to MySQL, we need to initialize the Connector/J driver. This is done with the static Class.forName( ) method, shown in Example 14-2. We can then create a Connection object that represents a specific MySQL connection by usingDriverManager.getConnection( ) with an appropriately formatted URL. This also is shown in Example 14-2 .
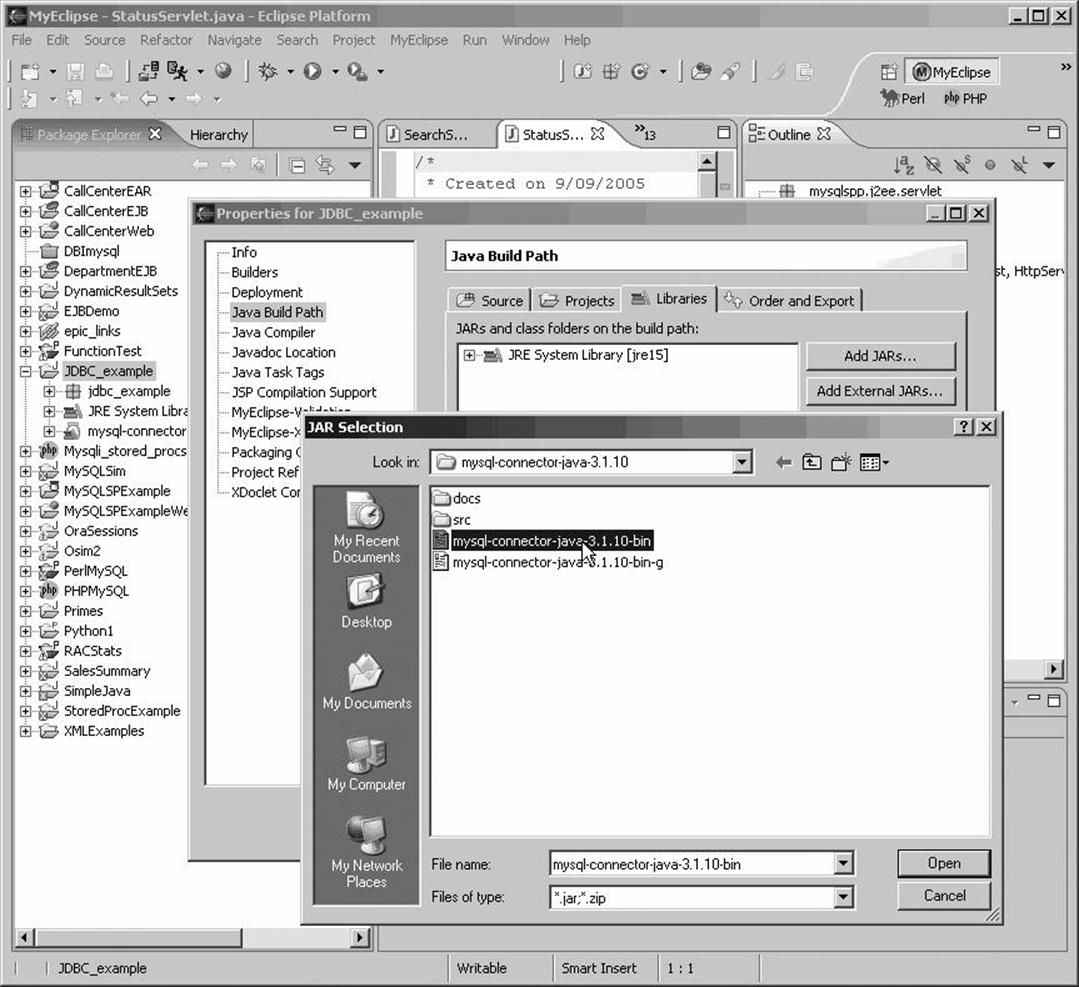
Figure 14-1. Configuring Eclipse for Connector/J
Example 14-2. Connecting to a MySQL instance
Class.forName("com.mysql.jdbc.Driver").newInstance( );
Connection myConnection = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test?user=root&password=secret");
The URL for the getConnection( ) method has the following (simplified) format:
jdbc:mysql://host[:port]/[database][?Name1=Value1][&Name2=Value2]...
The name/value pairs following the ? character typically include user and password together with other optional connection parameters (relating to the use of SSL, timeouts, etc.). You can find a full list of optional connection parameters in the Connector/J documentation athttp://dev.mysql.com/doc/connector/. The following are examples of possible URLs:
jdbc:MySQL://localhost/?user=root
Connect to the MySQL server on the local host at the default port (3306) and connect to root (no password).
jdbc:MySQL://fred:3305/test?user=joe&password=joe1
Connect to the MySQL server on host fred at port number 3305. Connect as joe/joe1 to database test.
Issuing a Non-SELECT Statement
Now that we have created our connection object, we are ready to issue a SQL statement. The simplest way to execute a SQL statement that does not return a result set (such as INSERT, UPDATE, DELETE, or a DDL statement) is to use the createStatement( ) and executeUpdate( )methods of the JDBC Connection interface.
The createStatement( ) method creates a reuseable Statement object. The executeUpdate( ) instance method of this Statement object can be used to execute the statement. Example 14-3 shows the use of the createStatement( ) and executeUpdate( ) methods to execute the SET AUTOCOMMIT=0 command.
Example 14-3. Issuing a SQL statement that returns no result set
Statement stmt1 = myConnection.createStatement( );
stmt1.executeUpdate("set autocommit=0");
In general, it's not a good idea to create statements in this way except for one-off SQL statements. For any statement that may be re-executed (perhaps with different parameters), we should use the PreparedStatement interface (see the "Using Prepared Statements" section later in this chapter).
Issuing a SELECT and Retrieving a Result Set
If our statement is a SELECT statement or another MySQL command that returns a result set, we can call the executeQuery( ) method of a Statement object. This creates a ResultSet object through which we can iterate in much the same way as we would iterate through the rows returned by a stored program cursor. This is, however, quite different programmatically from the way in which the java.util.Iterator interface is normally used to iterate through Java collections.
The next( ) method of the ResultSet object allows us to move to the next row in the result set—the very first call to next( ) will move to the first row—while getInt( ), getString( ), and other similar methods allow us to retrieve specific columns from the current row. Columns can be specified by name or by number. Example 14-4 shows us processing a simple query in JDBC.
Example 14-4. Processing a SELECT in JDBC
Statement stmt2 = myConnection.createStatement( );
ResultSet results = stmt2.executeQuery("SELECT department_id, department_name " +
" FROM departments");
while(results.next( ))
{
int departmentID = results.getInt("department_id"); // Get column by name
String departmentName = results.getString(2); // Got column by number
System.out.println(departmentID + ":" + departmentName);
}
results.close( );
As with non-SELECT statements, we should use the PreparedStatement interface rather than Statement if there is a chance that we will re-execute the SQL (potentially with different parameters).
Getting Result Set Metadata
If we don't know the exact structure of the result when we write our code (perhaps the SQL is entered by the end user or dynamically generated by some other module), then we can create a ResultSetMetaData object that contains information about the structure of the ResultSet object.Example 14-5 shows the use of this interface to print a list of column names and data types being returned from a query. Take special note that the first metadata result column has an index of 1 where most Java programmers would assume it to be 0.
Example 14-5. Using the ResultSetMetaData object to get result set structure
Statement stmt3 = myConnection.createStatement( );
ResultSet results2 = stmt2.executeQuery("SELECT *" +
" FROM departments");
ResultSetMetaData meta1 = results2.getMetaData( );
for (int i = 1; i <= meta1.getColumnCount( ); i++)
{
System.out.println("Column " + i + " "
+ meta1.getColumnName(i) + " ("
+ meta1.getColumnTypeName(i) + ")");
}
Using Prepared Statements
Most Java applications—particularly those running in a middle tier such as in a J2EE- compliant application server—re-execute SQL statements many times during the life of a database session. While the "parameters" to the statement, such as WHERE clause arguments, might change, the SQL itself is usually executed many times. Prepared statements are statement objects that are permanently associated with a particular SQL statement. They can be re-executed with new parameters when required. Using a prepared statement results in reduced overhead for the MySQL server, since re-executing an existing statement takes less processing time than executing a new SQL statement.
Note that although the MySQL server supports a feature (since 4.1) called server-side prepared statements , and although the JDBC implementation of prepared statements may leverage the MySQL implementation, the prepared statements we are discussing here are a JDBC feature, and are not specific to any particular RDBMS or version of MySQL.
The PreparedStatement interface extends the Statement interface and therefore inherits methods from that interface. The primary extensions in the PreparedStatement interface relate to specifying parameters prior to execution so that the PreparedStatement instance can be re-executed in a new context.
To create a prepared statement, we use the prepareStatement( ) method of the Connection interface, providing a SQL string as the argument. Any variable portions of the SQL string are represented by the ? character. In Example 14-6 we create a prepared statement that includes a single parameter value representing a specific product identifier.
Example 14-6. Creating a prepared statement
PreparedStatement prepared1 = myConnection.prepareStatement(
"select product_id,product_description,normal_value" +
" from products " +
" where product_id=?");
Before each execution of the prepared statement, we need to provide values for all the parameters of the statement. The PreparedStatement interface provides setInt( ), setString( ), and other similar methods for doing this. Each method takes the parameter number as the first argument and a value of the appropriate data type as the second argument. For instance, in Example 14-7, we set the value of the product identifier that will be provided to the prepared statement defined in Example 14-6 to a value of 12. Take note again that the index of the first parameter is 1 and not—as we might expect—0.
Example 14-7. Setting a parameter value in a prepared statement
prepared1.setInt(1, 12);
Now we can execute the prepared statement using its instance method executeQuery( ) if it is expected to return a result set, or executeUpdate( ) otherwise (see Example 14-8).
Example 14-8. Executing a prepared statement
ResultSet pstmtResults1 = prepared1.executeQuery( );
Example 14-9 shows the prepared statement being declared, the parameter set, and a result set retrieved.
Example 14-9. PreparedStatement example
PreparedStatement prepared1 = myConnection.prepareStatement(
"select product_id,product_description,normal_value" +
" from products " +
" where product_id=?");
prepared1.setInt(1, 12);
ResultSet pstmtResults1 = prepared1.executeQuery( );
while (pstmtResults1.next( ))
{
System.out.println("Product Description: " + pstmtResults1.getString(2));
}
pstmtResults1.close( );
Of course, if we were only going to execute the prepared statement once, this would all be wasted effort. The point is that having created the prepared statement, we can execute it any number of times, feeding different parameters to the prepared statement each time. Example 14-10 illustrates this principle by executing the prepared statement in a loop to print descriptions of the first 10 product IDs.
Example 14-10. Executing a prepared statement repetitively
for (int i = 1; i <= 10; i++)
{
prepared1.setInt(1, i);
pstmtResults1 = prepared1.executeQuery( );
pstmtResults1.next( );
System.out.println("Product ID: " + i +
" Product Description: " + pstmtResults1.getString(2));
}
pstmtResults1.close( );
Handling Transactions
Although we can issue commands such as COMMIT, ROLLBACK, START TRANSACTION, and SET AUTOCOMMIT using the setUpdate( ) method of Statement or PreparedStatement objects, it is probably easier to perform transaction control using the methods provided by theConnection interface.
The Connection interface supports a setAutocommit( ) method, together with commit() and rollback( ) methods, which allow us to disable MySQL autocommit and to perform explicit commit and rollback operations within a connection. So a transaction in JDBC would look like this:
myConnection.setAutoCommit(false);
/* transactional statements go in here */
myConnection.commit( );
Handling Errors
JDBC methods generally throw a SQLException if the SQL that is being issued results in a database error being generated. Classes that contain JDBC statements should therefore either use a throws clause to indicate that such an exception might be raised, or include the JDBC statements within a try/catch block.
Example 14-11 illustrates the first technique; the createDemoTables( ) method will throw a SQLException if a MySQL error occurs. It is up to the caller to catch that exception; otherwise, the unhandled exception might crash the Java program. This technique is recommended for generic or low-level database code that cannot interpret the exception within the context of the application. Pointless catching and re-throwing of exceptions is one of the cardinal sins of Java programming, because it leads to massive stack traces that just obscure what is actually causing the problem.
Example 14-11. Throwing a SQLException
static public void createDemoTables(Connection myConnection)
throws SQLException
{
Statement s1 = connection.createStatement( );
s1.executeUpdate("CREATE TABLE DEMO " +
" (MyInt INT, " +
" MyString VARCHAR(30))");
}
Example 14-12 shows the alternative approach. Here, the JDBC calls are enclosed in a try/catch block that catches the SQLException and reports the error message. Since the exception is caught, the createDemoTables( ) method no longer needs to declare the throws clause. This technique should be used when the catch block is able to adequately deal with the error by logging it or handling it programmatically. The catch block may also re-throw the exception as an application exception that includes valuable context information with regard to what the application was trying to do when the SQL failed.
Example 14-12. Catching a SQLException
static public void createDemoTables(Connection connection)
{
try
{
Statement s1 = connection.createStatement( );
s1.executeUpdate("CREATE TABLE DEMO" +
" (MyInt INT," +
" MyString VARCHAR(30))");
}
catch(SQLException exception)
{
System.out.println("Error while creating demo tables: " +
exception.getErrorCode( ) +
" SQLSTATE:" + exception.getSQLState( ));
exception.printStackTrace( );
}
}
The getErrorCode( ) and getMessage( ) methods are typically used to report on the specifics of the database error concerned. However, the SQLException class inherits a lot of useful diagnostic methods from its super classes Exception and Throwable. In particular,printStackTrace( ) will print a stack trace for the exception to standard output, while getStackTrace( ) allows programmatic access to the trace.
Using Stored Programs in JDBC
So far we have mainly reviewed the JDBC calls that can be used with any database and that don't relate in any way to stored program calls. If you have used JDBC with other RDBMS types or with previous versions of MySQL, you probably haven't learned much. Let's move on to processing stored program calls in JDBC (Figure 14-2).
Stored program calls are very similar to standard JDBC calls. A stored program strongly resembles a prepared statement that executes a query, with the following exceptions:
§ A stored program can return more than one result set.
§ A stored procedure can be associated with output—as well as input—parameters. This means that we need a way to retrieve the altered values from any stored procedure parameters that are defined as OUT or INOUT.
In addition to the general sequence of processing involved in creating and executing a prepared statement, when executing a stored program, we may need to retrieve multiple result sets and also—when the stored program execution has completed—retrieve the results of any output variables.
Using the CallableStatement Interface
The CallableStatement interface extends the PreparedStatement interface. It includes all of the methods of the PreparedStatement interface, as well as additional methods specific to stored program calls. You create a CallableStatement with the prepareCall( ) method of a Connection object:
CallableStatement statementName = ConnectionName.prepareCall(sql_text);
The single argument to the prepareCall( ) method contains the MySQL statements required to invoke the stored program. Any parameters are indicated by ? characters. The entire call must be enclosed in braces, "{" and "}", which are the standard JDBC escape sequences for indicating database-independent syntax. So to call the stored procedure sp_test_inout_rs2, which has two parameters, we would use the following syntax:
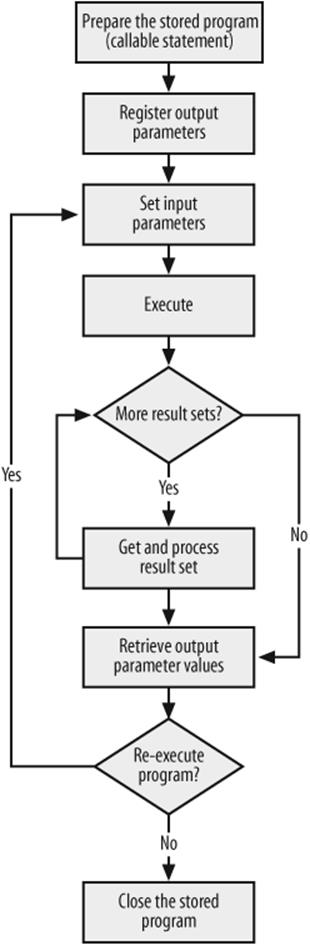
Figure 14-2. JDBC program flow when executing a stored program
CallableStatement callableStmt =
myConnection.prepareCall("{CALL sp_test_inout_rs2(?,?)}");
sp_test_inout_rs2 is a stored procedure that has both an IN and an OUT parameter and that returns two result sets. The stored procedure takes the name of a MySQL schema as an IN argument and returns a list of tables and a list of stored routines owned by that schema. It returns the number of tables in the specified database as an OUT parameter. The text for this stored procedure is shown in Example 14-13.
Example 14-13. Example stored procedure used in Java examples
CREATE PROCEDURE sp_test_inout_rs2(IN in_user VARCHAR(30),OUT table_count INT)
BEGIN
SELECT table_name,table_type
FROM information_schema.tables
WHERE upper(table_schema)=upper(in_user);
SELECT routine_name,routine_type
FROM information_schema.routines
WHERE upper(routine_schema)=upper(in_user);
SELECT COUNT(*)
INTO table_count
FROM information_schema.tables
where upper(table_schema)=upper(in_user);
END ;
Registering OUT Variables
If the stored procedure includes any OUT variables, you need to identify these to JDBC. The registerOutParameter( ) instance method of CallableStatement allows you to identify these parameters. This method has the following syntax:
callableStatementInstance.registerOutParameter(parameter_number,data_type);
Parameters are identified by number, starting with 1 for the first parameter. The data types are those contained in java.sql.Types and include INTEGER, CHAR, NUMERIC, DATE, etc.
In sp_test_inout_rs2, our second parameter is an OUT integer parameter, so we issue the statement to identify the parameter in Example 14-14.
Example 14-14. Registering a stored procedure OUT or INOUT parameter
callableStmt.registerOutParameter(2, Types.INTEGER);
Supplying Input Parameters
No matter how many times we execute our stored procedure, we only have to create the CallableStatement and register output parameters once. However, most executions of a stored procedure will have different input parameters , so the first step in a new execution is to identify the values of those parameters. The syntax for setting input parameter values is the same as that for a PreparedStatement; we use the setInt( ), setFloat( ), setString( ), setDate( ), or other appropriate methods of the PreparedStatement interface to set each value. In our example stored procedure, we have only a single VARCHAR input parameter, so we set its value as shown in Example 14-15.
Example 14-15. Setting the value of an input parameter
callableStmt.setString(1, schemaName);
schemaName is a Java String containing the name of the schema for which we want to retrieve information.
Executing the Procedure
Now we are ready to execute the stored procedure, which we do with the execute( ) instance method shown in Example 14-16.
Example 14-16. Executing a stored procedure
callableStmt.execute( );
The execute( ) method returns a Boolean value, which resolves to true if the stored procedure returns at least one result set. So we could call execute( ) as shown in Example 14-17.
Example 14-17. Executing a stored procedure that might return a result set
boolean hasResults = callableStmt.execute( );
If you know that your stored procedure does not return a result set, you can use the executeUpdate( ) method instead, as shown in Example 14-18.
Example 14-18. Executing a stored procedure that does not return a result set
CallableStatement noResultStmt = connection.prepareCall("{call sp_noresult( )}");
noResultStmt.executeUpdate( );
Retrieving a Result Set
As we noted earlier, the initial execute( ) call will return true only if the stored procedure returns at least one result set. If this is so, or if you know in advance that the stored procedure has a result set, you can retrieve it in the usual fashion. Example 14-19 shows how to retrieve a single result set from a stored procedure call.
Example 14-19. Retrieving a single result set from a stored procedure call
ResultSet rs1 = callableStmt.getResultSet( );
while (rs1.next( ))
System.out.println(rs1.getString("table_name") + " " +
rs1.getString("table_type"));
In this case, we knew the names and types of the columns in our result set. If we did not, we could call the getMetaData( ) method to retrieve the result set structure. ResultSetMetaData is described in the section "Getting Result Set Metadata" earlier in this chapter.
Retrieving Multiple Result Sets
If the stored procedure has more than one result set, you can use the getMoreResults( ) method to move to the next set. If there are no more result sets , getMoreResults( ) will return false. So to get a second result set, we can call getMoreResults( ) and then retrieve the result set. Example 14-20 illustrates this technique.
Example 14-20. Obtaining a second result set from the stored procedure call
if (callableStmt.getMoreResults( ))
{
ResultSet rs2 = callableStmt.getResultSet( );
while (rs2.next( ))
System.out.println(rs2.getString(1) + " " + rs2.getString(2));
rs2.close( );
}
In this example, we used the column numbers rather than column names to retrieve the results. Using column names (rs2.getString("department_id") for instance) leads to more readable code, but when you are processing dynamic result sets, it may be more convenient to refer to the columns by number.
Dynamically Processing Result Sets
It is possible—but very unusual—that we might call a stored program without knowing the number and types of input and output parameters. However, because we often use unbounded SELECT statements within stored programs to generate debugging or other messages, and because it is relatively easy to conditionally create result sets in our stored program code, we may find that we need to execute a stored program without knowing exactly how many result sets will be returned or what the structure of each result set will look like.
We therefore need to be familiar with the process of dynamically processing result sets. Example 14-21 implements a method that will execute a stored program passed as a parameter and print out all the result sets generated by that stored program.
Example 14-21. JDBC code to dynamically process multiple result sets
1 private void executeProcedure(Connection connection, String sqlText)
2 throws SQLException {
3
4 CallableStatement cs = connection.prepareCall("{CALL " + sqlText + "}");
5 boolean moreResultSets = cs.execute( );
6 while (moreResultSets) {
7
8 ResultSet rs = cs.getResultSet( );
9 ResultSetMetaData rsmd = rs.getMetaData( );
10
11 StringBuffer buffer = new StringBuffer( );
12 for (int i = 1; i <= rsmd.getColumnCount( ); i++)
13 buffer.append(rsmd.getColumnName(i)).append("\t");
14 System.out.println(buffer.toString( ));
15
16 while (rs.next( )) {
17 buffer.setLength(0);
18 for (int i = 1; i <= rsmd.getColumnCount( ); i++)
19 buffer.append(rs.getString(i)).append("\t");
20 System.out.println(buffer.toString( ));
21 }
22
23 moreResultSets = cs.getMoreResults( );
24 }
25 }
Let's step through Example 14-21:
|
Line(s) |
Explanation |
|
4 |
Create a CallableStatement object that invokes the stored procedure text provided as an argument to the Java procedure. |
|
5 |
Execute the stored procedure. The moreResultSets Boolean value will be true if the stored procedure returns any result sets. |
|
6-24 |
This loop will continue to execute provided that moreResultSets is true. This means that the code within the loop will execute once for each result set returned by the stored procedure. |
|
8-9 |
On line 8 we get a ResultSet object for the current result set, and on line 9 we retrieve the ResultSetMetaData object for that ResultSet. |
|
11-14 |
Print out the column names for the current result set, as retrieved from the ResultSetMetaData object. |
|
16-22 |
Loop through the rows of the current result set. The loop will continue for each row returned by the current result set. |
|
18-21 |
Loop through each column in the current row. The getColumnCount( ) method of the ResultSetMetaData object tells us how many columns we will need to process, and we use getString( ) to retrieve the value. getString( ) will get a string representation of non-string SQL data types such as dates or numeric data. |
|
23 |
Use the getMoreResults( ) method of the CallableStatement object to determine if there are more result sets. If this call returns true, then the CallableStatement will move to the next result set and the while loop defined on line 6 will continue, allowing us to repeat the above process for the next result set. |
Retrieving Output Parameter Values
Once all of the result sets have been retrieved, it is time to retrieve the values of any OUT or INOUT parameters that the procedure may have declared. Remember that in order to do this, we must have used the registerOutParameter( ) method to set the types of these parameters before we executed the stored procedure.
To get the values of output parameters, we use "get" methods (getInt( ), getFloat( ), getString( ), etc.) that are similar to those used to retrieve column values, but instead of applying the methods to the ResultSet object, we apply them to the CallableStatement object. In the case of our sp_test_inout_rs2 stored procedure, which has a single integer OUT parameter (the second parameter), we can simply retrieve the value of the OUT parameter with the code shown in Example 14-22.
Example 14-22. Retrieving the value of an output parameter
System.out.println("Out parameter = " + callableStmt.getInt(2));
Stored Programs and J2EE Applications
While it is certainly possible to use JDBC inside Java to construct client/server applications or even Java applets, the most significant interaction between Java programs and a relational database often occurs with a J2EE application server environment, usually within the context of a J2EE-based web application. This application server could be a commercial J2EE implementation such as WebLogic or WebSphere or—perhaps more typically in combination with MySQL—an open source J2EE server such as Tomcat or JBoss.
Modern J2EE applications follow one of two major patterns with respect to database interaction:
Servlet pattern
In the servlet pattern, JDBC code is included within Java programs running within the application server. These programs are known as servlets . These servlets are free to communicate directly with the database through embedded JDBC code, although many applications will choose to interact with the database through an object-relational mapping interface such as Hibernate.
EJB pattern
In an Enterprise JavaBeans (EJB) based application, access to database objects is abstracted via entity EJB beans. Each entity bean represents either a table or a common multitable entity, and each instance of the entity bean typically represents a row in that table or result set. The EJB pattern contains methods to retrieve, update, delete, and insert rows within this logical table.
A full tutorial on J2EE database programming is beyond the scope of this book (and probably beyond the expertise of its authors). However, in this section we will take a quick look at how you might use stored programs within a J2EE application.
Using Stored Programs Within Java Servlets
In a servlet-based Java web application, Java code in the application or web server controls the generation of dynamic HTML content based on business logic contained within the Java code and through interaction with back-end databases via JDBC. Servlet technology actually predates J2EE (servlets were introduced in Java 1.1), and there is a wide variety of possible servlet implementation patterns.
In this section, we will use a simple servlet to render the output from a stored procedure that contains multiple and unpredictable result sets and that also contains both input and output parameters. The stored procedure generates a selection of MySQL server status information, takes as an input parameter a specific database within the server, and returns as an output parameter the MySQL version identifier. The stored procedure is shown in Example 14-23.
Example 14-23. Stored procedure to return MySQL server status information
CREATE PROCEDURE sp_mysql_info
(in_database VARCHAR(60),
OUT server_version VARCHAR(100))
READS SQL DATA
BEGIN
DECLARE db_count INT;
SELECT @@version
INTO server_version;
SELECT 'Current processes active in server' as table_header;
SHOW full processlist;
SELECT 'Databases in server' as table_header;
show databases;
SELECT 'Configuration variables set in server' as table_header;
SHOW global variables;
SELECT 'Status variables in server' as table_header;
SHOW global status;
/* See if there is a matching database */
SELECT COUNT(*)
INTO db_count
FROM information_schema.schemata s
WHERE schema_name=in_database;
IF (db_count=1) THEN
SELECT CONCAT('Tables in database ',in_database) as table_header;
SELECT table_name
FROM information_schema.tables
WHERE table_schema=in_database;
END IF;
END;
Note that the stored procedure uses a special technique to output "heading" rows for the result sets. When a single row is returned with a column named table_header, that row represents a title or heading for the subsequent result set.
Our example is going to use an HTML page to request the user to enter specific server information, and then use a servlet within the application server to display the output of the stored procedure. The HTML for the input form is very simple and is shown in Example 14-24.
Example 14-24. HTML input form for our servlet example
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<TITLE>MySQL Server status</TITLE>
</head>
<body>
<H2>Enter MySQL Server details</H2>
<FORM name="statusForm" method="post" action="mystatus">
<TABLE>
<TR><TD>Host:</TD><TD> <input type="text" name="mhost"></TD></TR>
<TR><TD>Port:</TD><TD> <input type="text" name="mport"></TD></TR>
<TR><TD>Username:</TD><TD>
<input type="text" name="muser"></TD></TR>
<TR><TD>Password:</TD><TD>
<input type="password" name="mpass"></TD></TR>
<TR><TD>Database:</TD><TD> <input type="text" name="mdb"></TD></TR>
</TABLE>
<INPUT type="submit" value="Submit" />
</FORM>
</body>
</html>
The HTML renders the data entry screen shown in Figure 14-3.
Example 14-25 shows the code for the Java servlet that is invoked when the user clicks the Submit button.
Figure 14-3. Data entry form for our servlet example
Example 14-25. Servlet code that invokes our stored procedure
1 public class StatusServlet extends HttpServlet
2 {
3 public void doPost(HttpServletRequest request, HttpServletResponse response)
4 throws ServletException, IOException
5 {
6 String hostname = request.getParameter("mhost");
7 String port = request.getParameter("mport");
8 String username = request.getParameter("muser");
9 String password = request.getParameter("mpass");
10 String database = request.getParameter("mdb");
11 StringBuffer html = new StringBuffer( );
12
13 response.setContentType("text/html");
14 PrintWriter out = response.getWriter( );
15
16 try {
17 Class.forName("com.mysql.jdbc.Driver").newInstance( );
18 String connString = "jdbc:mysql://" + hostname + ":" + port + "/" +
19 database + "?user=" + username + "&password=" + password;
20 Connection connection = DriverManager.getConnection(connString);
21
22 CallableStatement myproc =
23 connection.prepareCall("{CALL sp_mysql_info(?,?)}");
24 myproc.registerOutParameter(2, Types.VARCHAR);
25 myproc.setString(1, database);
26
27 boolean moreResultSets = myproc.execute( );
28 while (moreResultSets) {
29 ResultSet rs = myproc.getResultSet( );
30 ResultSetMetaData rsmd = rs.getMetaData( );
31 if (rsmd.getColumnName(1).equals("table_header")) {
32 rs.next( );
33 html.append("<h2>").append(rs.getString(1))
34 .append("</h2>");
35 } else {
36 makeTable(rs, rsmd, html);
37 }
38 moreResultSets = myproc.getMoreResults( );
39 }
40 String version = myproc.getString(2);
41
42 out.println("<HTML><HEAD><TITLE>MySQL Server status</TITLE></HEAD>");
43 out.println("<H1>MySQL Server status and statistics</H1>");
44 out.println("<b>Server:</b>\t" + hostname + "<br>");
45 out.println("<b>Port:</b>\t" + port + "<br>");
46 out.println("<b>Version:</b>:\t" + version + "<br>");
47 out.println(html.toString( ));
48 out.println("</HTML>");
49 } catch (SQLException e) {
50 out.println(e.getErrorCode() + " " + e.getMessage( ));
51 e.printStackTrace(out);
52 } catch (InstantiationException e) {
53 e.printStackTrace(out);
54 } catch (IllegalAccessException e) {
55 e.printStackTrace(out);
56 } catch (ClassNotFoundException e) {
57 e.printStackTrace(out);
58 } finally {
59 out.flush( );
60 out.close( );
61 }
62 }
63
64 private void makeTable(ResultSet rs, ResultSetMetaData rsmd, StringBuffer html)
65 throws SQLException
66 {
67 html.append("<table border=\"1\"><tr>");
68
69 for (int i = 1; i <= rsmd.getColumnCount( ); i++)
70 html.append("<td bgcolor=\"silver\">").append(rsmd.getColumnName(i))
71 .append("</td>");
72 html.append("</tr>");
73
74 while (rs.next( )) {
75 html.append("<tr>");
76 for (int i = 1; i <= rsmd.getColumnCount( ); i++)
77 html.append("<td>").append(rs.getString(i)).append("</td>");
78 html.append("</tr>\n");
79 }
80
81 html.append("</table>\n");
82 }
83 }
Let's examine this servlet code:
|
Line(s) |
Explanation |
|
6-10 |
Retrieve the server connection details as entered by the user on the calling HTML form. |
|
11 |
Create a StringBuffer object for building the HTML text to avoid churning lots of throwaway String objects. |
|
13 and 14 |
Initialize an output stream to return HTML output. |
|
17-20 |
Create a connection to the MySQL server using the connection details supplied by the user. |
|
22-25 |
Prepare the stored procedure shown in Example 14-23. On line 24 we register our output parameter, and on line 25 we supply the input parameter—the name of a database within the server—provided by the user in the HTML form. |
|
27 |
Execute the stored procedure. |
|
28-39 |
This loop executes once for each result set returned by the stored procedure. |
|
29 and 30 |
Retrieve a result set and—on line 30—a ResultSetMetaData object for that result set. |
|
31-37 |
If the first column in the result set is called "table_header", then the result set represents a heading row for a subsequent result set, so we create an HTML header tag. Otherwise, we pass the result set to the makeTable( ) method, which returns an HTML table formatted from the result set (see below for a description of the makeTable( ) method). |
|
37 |
Call the getMoreResults( ) method to see if there are further result sets. If there are, then moreResultSets will be set to true and the loop will continue. Otherwise, it will be set to false and the loop will terminate. |
|
40 |
Now that all result sets have been processed, retrieve the value of the output parameter, which contains the MySQL version string. |
|
42-48 |
Write our formatted HTML report to the print stream. |
|
49-57 |
Catch any exceptions and print a stack trace to the print stream. |
|
58-61 |
Whether there is an exception or not, we must flush and close the print stream to send our output back to the calling session. |
|
64-82 |
Define the private makeTable( ) method that takes ResultSet and ResultSetMetaData objects and appends an HTML table representation of that result set to the specified StringBuffer. |
|
69-72 |
Loop through the column names for the result set and format HTML to create the heading row for the table. |
|
74-79 |
Loop through the rows returned by the result set and—in lines 76-77—append the columns in each row. We generate HTML to create an HTML table cell for each row returned in the result set. |
Figure 14-4 shows the output generated by the servlet and stored procedure.
Using Stored Programs from EJB
Enterprise JavaBeans (EJB) is a feature of the J2EE specification that provides for distributed server-side Java components intended for enterprise systems development. Entity EJBs provide a way to represent persistent data—usually data from an RDBMS—in the EJB component model.
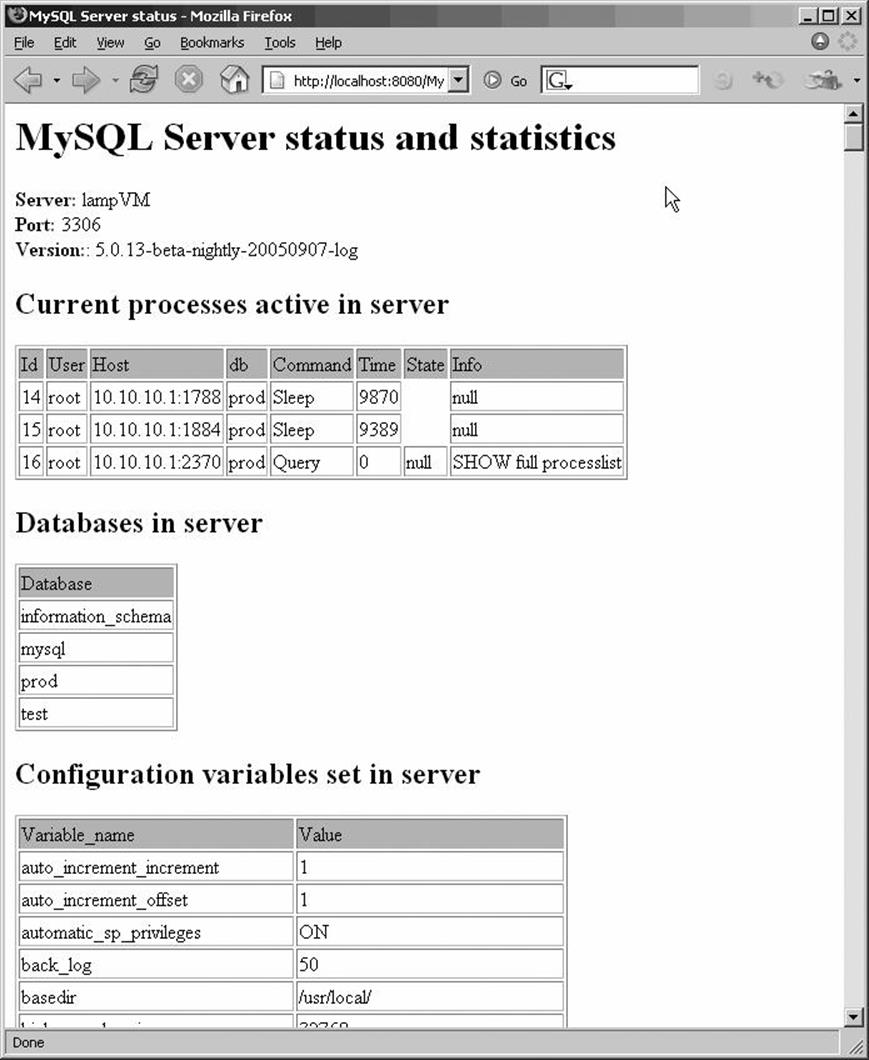
Figure 14-4. Output from our stored procedure/servlet example
In most J2EE applications, EJBs represent a mapping of relational data to Java objects. In a very simple case, an EJB may represent a database table, and each instance of the EJB might represent a row in that table. However, the relationships between EJBs and relational tables can be as complex as the developer chooses, and an EJB may represent a complex business object that is represented across many database tables.
Each EJB includes various methods that allow the application to interact with the underlying data. Some of these methods are listed in Table 14-1.
Table 14-1. Some of the methods of an entity EJB
|
Method or method type |
Description |
|
ejbFind find_type |
Various "finder" methods allow the application to find a particular instance of an EJB (perhaps a specific row in a table). There will always be at least an ejbFindByPrimaryKey() method. |
|
ejbCreate |
Creates a new instance of an entity bean. This is roughly equivalent to inserting a row into the database. |
|
ejbStore |
Applies the in-memory contents of the entity bean to the database. It usually involves one or more UPDATE statements. |
|
ejbRemove |
Permanently removes an instance of an entity bean—usually associated with deleting one or more database rows. |
|
ejbLoad |
Loads a particular instance of an EJB. This is equivalent to reading a certain table row into memory. |
Entity EJBs in a J2EE application are responsible for representing all persistent data in the application, where persistent means that the data will continue to exist when the current thread, process, or application ceases to run. There are two styles of persistence management in entity EJBs:
Bean-Managed Persistence (BMP)
In this mode, the interaction with the underlying data source is controlled by code that is contained within the EJB. In most cases, this means that the programmer includes JDBC code within the bean to query and update the underlying tables, or uses an abstraction layer such as Hibernate or Spring to generate the JDBC calls.
Container-Managed Persistence (CMP)
In this mode, the interaction with the underlying data source is controlled by the EJB container itself. The container generates SQL to retrieve and maintain data based on deployment data that defines the relationship between the data represented by the entity bean and the data held in the relational database.
In CMP, the SQL is issued by the EJB container itself and is not under developer control. Consequently it is not really feasible to use stored programs in conjunction with a CMP EJB. It's fair to say that CMP is the recommended method of implementing entity bean persistence, since it reduces the effort involved in implementing the bean and since (somewhat surprisingly) CMP implementations can outperform BMP implementations. Most J2EE experts recommend using BMP only when there is a very complex relationship between beans and the underlying tables or when some special SQL coding is required for performance or security reasons.
Note also that the J2EE specification does not forbid accessing the database from session beans, and the programmer is free to implement JDBC within a session bean framework in order to retrieve and maintain persistent data. In this model, JDBC calls would be embedded in the session bean much as we embedded JDBC within a Java servlet in the "Using Stored Programs Within Java Servlets" section earlier in this chapter.
However, in the case in which our database logic is contained in a BMP-based entity bean, we can certainly use a stored program implementation if we choose.
For instance, Example 14-26 shows a typical EJB method that we might use to locate an EJB representing a particular customer using the customer's phone number. The bean method accepts the phone number and returns the primary key of the relevant customer (the customer_id). Thiscustomer_id would later be used by the ejbLoad() method to load the relevant bean.
Example 14-26. EJB method to find a customer by phone number
public int ejbFindByPhoneNo(String phoneNo) throws FinderException
{
try {
Connection connection = getConnection( );
PreparedStatement statement = connection.prepareStatement
("SELECT customer_id FROM customers WHERE phoneno=?");
statement.setString(1, phoneNo);
ResultSet resultSet = statement.executeQuery( );
if (!resultSet.next( ))
{
statement.close( );
connection.close( );
throw new FinderException("Could not find: " + phoneNo);
}
statement.close( );
connection.close( );
return resultSet.getInt(1);
}
catch(SQLException e) {
throw new EJBException ("Could not find: " + phoneNo, e);
}
}
The SQL within a BMP entity bean can be implemented as a stored program. Example 14-27 shows such a finder method. The finder method calls the stored procedure GetCustomerIdByPhoneno, which returns a customer_id that matches a particular customer name.
Example 14-27. EJB finder method that uses a stored procedure
public int ejbFindByPhoneNoSP(String phoneNo) throws FinderException
{
try {
Connection connection = getConnection( );
String sqlText = "{call getcustomeridbyphoneno(?,?,?)}";
CallableStatement custStmt = connection.prepareCall(sqlText);
custStmt.registerOutParameter(2, Types.INTEGER);
custStmt.registerOutParameter(3, Types.INTEGER);
custStmt.setString(1, phoneNo);
custStmt.execute( );
if (custStmt.getInt(3) == 1) // Not Found indicator
throw new FinderException("Could not find: " + phoneNo);
return custStmt.getInt(2);
}
catch(SQLException e) {
throw new EJBException("Could not find: " + phoneNo, e);
}
}
Using Stored Procedures with Hibernate
J2EE provides entity EJBs as a mechanism for mapping Java objects to database tables. In CMP the J2EE system itself generates the SQL necessary to create the EJBs from the database and to update the database to reflect changes made to the EJBs. The generic term for a framework that synchronizes program objects with relational database data in this manner is an Object-Relational Mapping (ORM) framework .
J2EE and the EJB model have its supporters as well as its detractors, but almost everyone agrees that it is mainly suitable for large-scale distributed applications. To get the benefits of ORM for non-J2EE applications, programmers typically adopt an alternative ORM framework, the most popular of which is Hibernate (http://www.hibernate.org).
Database stored programs and ORM are not necessarily a perfect fit. Gavin King— the creator of Hibernate—was quoted as saying:
Stored procedures are essentially a nonrelational view of a relational database ... my view, currently, is that the goal of an object-relational mapping tool should be to map between tables and objects, not between objects and "some other stuff."[*]
It's true that programmers who are building applications that make widespread use of stored procedures will get less benefit from Hibernate than those working with native SQL; in particular, Hibernate cannot auto-generate stored procedure calls, so the programmer needs to configure Hibernate with every stored procedure call that might be required.
However, demand for stored procedures in Hibernate has remained high, and their use is now fully supported. This support allows Hibernate to be used with legacy applications that rely on stored procedures and also allows new applications to take advantage of both Hibernate and stored procedures where appropriate.
In this section we will provide a brief overview of using Hibernate with MySQL stored procedures. We're going to assume you have some basic familiarity with Hibernate—if you are new to Hibernate, you will find a review of Chapter 2 ("Introduction to Hibernate") of the Hibernate Reference Documentation helpful. Our examples in this section are based on the Event class described in that chapter.
Hibernate Support for MySQL Stored Procedures
For every supported RDBMS, Hibernate includes a Dialect definition that defines the capabilities and configurations that the RDBMS supports. At the time of writing, the Hibernate (3.1rc3) MySQLDialect definition did not include a reference to stored procedures and, consequently, Hibernate would generate the following error when configured to use a MySQL stored procedure:
[java] Hibernate: { call getEvent(?) }
[java] Exception in thread "main" java.lang.UnsupportedOperationException: org.
hibernate.dialect.MySQLDialect does not support
resultsets via stored procedures.
Modifying the Hibernate MySQLDialect.java file to reflect MySQL 5.0's ability to execute stored procedures is relatively simple, and we have submitted a modified version of this file to the Hibernate team for inclusion in an upcoming release of Hibernate (JIRA key HHH-1244, scheduled for 3.1 production). You can also obtain this file from this book's web site, where we will also include information about the current status of Hibernate support for MySQL stored procedures.
Using a Stored Procedure to Load an Object
The load( ) method of the Hibernate session object allows you to create a Hibernate object using the Hibernate mappings. Under the hood, Hibernate will generate a SELECT statement to extract the appropriate data from the database. Example 14-28 shows us creating and loading anEvent object for the event #1.
Example 14-28. Loading a Hibernate object in a Java application
Long id = new Long(1);
Event event = (Event) session.load(Event.class, id);
We can load the Event object using a stored procedure. A simple stored procedure to retrieve details for a specific event is shown in Example 14-29.
Example 14-29. Stored procedure to load an Event object
CREATE PROCEDURE getEvent (in_event_id INTEGER)
BEGIN
SELECT event_id, title, event_date
FROM events
WHERE event_id = in_event_id;
END;
To use this stored procedure, we need to create a definition for it in the mapping document and add a loader entry to the class definition. Example 14-30 shows the changes we made to the mapping document (Events.hbm.xml) to enable our stored procedure loader.
Example 14-30. Defining the loader stored procedure in the Hibernate mapping document
1 <hibernate-mapping>
2 <class name="Event" table="EVENTS">
3 <id name="id" column="EVENT_ID">
4 <generator class="increment" />
5 </id>
6 <property name="title" />
7 <property name="date" type="timestamp" column="EVENT_DATE" />
8
9 <loader query-ref="getEventSP"></loader>
10 </class>
11
12 <sql-query name="getEventSP" callable="true">
13 <return alias="event" class="Event">
14 <return-property name="id" column="EVENT_ID" />
15 <return-property name="title" column="TITLE" />
16 <return-property name="date" column="EVENT_DATE" />
17 </return>
18 { call getEvent(?) }
19 </sql-query>
Let's look at the important parts of this document:
|
Line(s) |
Explanation |
|
9 |
The mapping tag loader defines the SQL that will be used when the data for a class is first loaded. query-ref refers to a named query defined elsewhere in the mapping—in this case getEventSP. |
|
12-19 |
The sql-query section defines a named SQL query that can be used elsewhere in the mapping or from Java code. |
|
12 |
The name property allows you to provide a meaningful name for the SQL query. The callable property—if set to true— indicates that the SQL query should be executed as a JDBC CallableStatement—i.e., it is a stored procedure or function. |
|
13-17 |
The return section provides details about the result set that will be returned by the sql-query section. |
|
13 |
The alias property provides an alias that can be used to prefix column names in the SQL and is not of much interest for a callable SQL. The class property indicates that the SQL will return properties relating to the specified class (in this case the Event class). |
|
18 |
The SQL code that is executed by this sql-query. For a callable SQL, this should be in the same format used in the prepareCall( ) method of the Connection interface, as described earlier in this chapter. |
Once we rebuild our application, all subsequent load( ) calls will use the getEvent( ) stored procedure to retrieve event data from the database.
Hibernate Queries
It is typical for an application to generate lists of matching objects by issuing Hibernate queries . For instance, to create a List object that includes all events, we might include the code shown in Example 14-31 in our application.
Example 14-31. Simple Hibernate query to retrieve all objects
List result = session.createQuery("from Event").list( );
We could retrieve all Events objects raised since yesterday with the Hibernate query shown in Example 14-32.
Example 14-32. Hibernate query with WHERE clause
List result =
session.createQuery("from Event as e where e.date > ?")
.setDate(0, yesterday).list( );
Let's implement the query expressed in Example 14-32 through a stored procedure call. A stored procedure to return events raised after a specified date is shown in Example 14-33.
Example 14-33. Stored procedure to support a Hibernate query
CREATE PROCEDURE getRecentEvents(in_event_date DATETIME)
BEGIN
SELECT event_id AS EVENT_ID, title AS EVENT_TITLE, event_date AS EVENT_DATE
FROM events
WHERE event_date > in_event_date;
END;
As in the previous example, we need to add a definition for the stored procedure call to the mapping file. Example 14-34 shows the mapping for our new stored procedure.
Example 14-34. Mapping for our query stored procedure
<sql-query name="getRecentEventsSP" callable="true">
<return alias="event" class="Event">
<return-property name="id" column="EVENT_ID" />
<return-property name="title" column="EVENT_TITLE" />
<return-property name="date" column="EVENT_DATE" />
</return>
{ call getRecentEvents(?) }
</sql-query>
Now we can use that named query in our Java code. Instead of using the createQuery( ) method, we use the getNamedQuery( ) method, supplying the name we have given our stored procedure call in the mapping file and supplying any necessary parameters. Example 14-35 shows the technique.
Example 14-35. Using a stored procedure to execute a Hibernate query in Java code
List result = session.getNamedQuery("getRecentEventsSP")
.setDate(0,yesterday).list( );
Using Stored Procedures for Persistence
By default, Hibernate constructs and issues INSERT, UPDATE, and DELETE statements, as appropriate, to persist the contents of Java objects in the database. However, we can configure Hibernate to use stored procedure calls instead.
For a stored procedure to be used with Hibernate it must accept the same parameters—in the same order—as the SQL that Hibernate would generate by default. For instance, in the case of a stored procedure to replace an INSERT statement, the stored procedure will have to provide parameters representing every column in Hibernate's INSERT statement, and these parameters must appear in the same order as the columns appear in that INSERT statement. The easiest way of determining this sequence is to log the SQL generated by Hibernate before converting it to a stored procedure call.
For UPDATE and DELETE, the stored procedure must return the number of rows affected by the operation as either a function return value or as the first parameter (which will, of course, need to be an OUT parameter).
Warning
The Hibernate documentation implies that a stored function should be used to implement UPDATE and DELETE functionality and that the stored function should return the number of rows affected. Unfortunately, Hibernate treats stored function return values in a way that works for SQL Server but not for MySQL, so for now it is necessary to implement the UPDATE or DELETE through a stored procedure.
Example 14-36 shows stored procedures designed to replace the Hibernate-generated DML statements to maintain Event objects. Note that in the case of the updateEvent and deleteEvent procedures, the first parameter is an OUT parameter that returns the number of rows affected by the DML operation. This parameter is neither required nor permitted for the createEvent procedure.
Example 14-36. Stored procedure to implement a Hibernate update operation
CREATE PROCEDURE updateEvent
(OUT row_count INTEGER, in_event_date DATETIME,
in_title VARCHAR(60), in_event_id INTEGER)
BEGIN
UPDATE events
SET title = in_title, event_date = in_event_date
WHERE event_id = in_event_id;
SET row_count = ROW_COUNT( );
END $$
CREATE PROCEDURE deleteEvent(OUT row_count INTEGER, in_event_id INTEGER)
BEGIN
DELETE FROM events
WHERE event_id = in_event_id;
SET row_count = ROW_COUNT( );
END$$
CREATE PROCEDURE createEvent
( InEventDate DATE, InEventTitle VARCHAR(60), InEventId INT )
BEGIN
INSERT INTO events (event_date, title, event_id)
VALUES(InEventDate, CONCAT(InEventId, InEventTitle), InEventId);
END$$
To ensure that Hibernate uses these stored procedures in place of its self-generated SQL, we need to add entries in the mapping document to associate the specific operation with the stored procedure call. Example 14-37 shows the entries we added to the Event class definition (inEvent.hbm.xml) to enable the stored procedures.
Example 14-37. Configuring Hibernate to use stored procedures for UPDATE, INSERT, and DELETE
<sql-insert callable="true">{call createEvent (?, ?, ?)}</sql-insert>
<sql-update callable="true">{call updateEvent(?,?,?,?)}</sql-update>
<sql-delete callable="true">{call deleteEvent(?,?)}</sql-delete>
Once we rebuild our application, Hibernate will use these stored procedure calls in place of the INSERT, UPDATE, or DELETE SQL statements that it would normally generate.
We have now completely converted the Event mapping to use stored procedures. Hibernate will now use MySQL stored procedures exclusively when querying, loading or modifying objects of the Event class.
[*] http://www.theserverside.com/talks/videos/GavinKing/interview.tss?bandwidth=dsl
Using Stored Procedures with Spring
Spring (http://www.springframework.org) is a popular, lightweight framework for the development of Java applications. Spring offers many facilities that support the development of Java applications, including support for Model-View-Controller design, POJO (Plain Old Java Objects) , integration with J2EE objects, Aspect Oriented Programming, integration with other complementary frameworks such as Hibernate, and abstraction layers for transaction management and database access. Spring aims to deliver on many of the promises of the J2EE framework, but in a less invasive and more productive manner.
Spring's JDBC abstraction layer eliminates much of the repetitive coding normally associated with even simple SQL queries. The abstraction layer includes a StoredProcedure class that can be used to incorporate stored procedure calls into a Spring application. In this section we will provide a brief overview of how to access a MySQL stored procedure from within a Spring application.
Example 14-38 shows the stored procedure we are going to use in our Spring example. It accepts a single input parameter—the department_id—and returns two result sets. The first result set contains a list of employees in that department, and the second contains a list of customers associated with the department. The stored procedure includes an OUT parameter that returns the total value of all sales associated with the department.
Example 14-38. Stored procedure for use with our Spring example
CREATE PROCEDURE sp_department_report
(in_dept_id INTEGER, OUT sales_total DECIMAL(8,2))
BEGIN
SELECT employee_id, surname, firstname, address1, address2, salary
FROM employees
WHERE department_id = in_dept_id;
SELECT customer_id, customer_name, address1, address2, zipcode
FROM customers
WHERE sales_rep_id IN
(SELECT employee_id FROM employees
WHERE department_id = in_dept_id);
SELECT SUM(sale_value)
INTO sales_total
FROM sales
WHERE customer_id IN
(SELECT customer_id
FROM customers
WHERE sales_rep_id IN
(SELECT employee_id
FROM employees
WHERE department_id = in_dept_id));
END
The natural way to represent the customer and employee rows returned by the stored procedure is to create customer and employee Java classes. Example 14-39 shows part of the class that would represent employees. We created a similar class for customers.
Example 14-39. Java class to represent employees
public class Employee
{
private long id;
private String surname;
private String firstName;
private String address1;
private String address2;
private double salary;
public Employee(long id, String surname, String firstName,
String address1, String address2, double salary)
{
this.id = id;
this.surname = surname;
this.firstName = firstName;
this.address1 = address1;
this.address2 = address2;
this.salary = salary;
}
public String toString( ) {
return "Employee : " + employeeId + " " + surname;
}
public String getSurname( ) {
return surname;
}
public String getFirstName( ) {
return firstName;
}
/* Other getters and setters would go here */
}
To represent the stored procedure, we create a new class that extends the Spring StoredProcedure class, as shown in Example 14-40.
Example 14-40. Class to represent a stored procedure in Spring
1 private class MyStoredProcedure extends StoredProcedure
2 {
3 public MyStoredProcedure(DataSource ds)
4 {
5 setDataSource(ds);
6 setSql("sp_department_report");
7
8 declareParameter(new SqlReturnResultSet("Employees",
9 new RowMapper( ) {
10 public Object mapRow(ResultSet rs, int rowNum)
11 throws SQLException {
12 Employee e = new Employee(
13 rs.getInt("employee_id"),
14 rs.getString("surname"),
15 rs.getString("firstname"),
16 rs.getString("address1"),
17 rs.getString("address2"),
18 rs.getDouble("salary"));
19 return e;
20 }
21 }));
22
23 declareParameter(new SqlReturnResultSet("Customers",
24 new RowMapper( ) {
25 public Object mapRow(ResultSet rs, int rowNum)
26 throws SQLException {
27 Customer c = new Customer(
28 rs.getInt("customer_id"),
29 rs.getString("customer_name"),
30 rs.getString("address1"),
31 rs.getString("address2"),
32 rs.getString("zipcode"));
33 return c;
34 }
35 }));
36
37 declareParameter(new SqlParameter("department_id", Types.INTEGER));
38
39 declareParameter(new SqlOutParameter("sales_total", Types.DOUBLE));
40
41 compile( );
42 }
43
44 }
Let's look at the significant lines of this class:
|
Line(s) |
Explanation |
|
3 |
The constructor method for the class. It takes a single argument that represents the MySQL server connection. |
|
5 |
Set the data source that was provided as an argument. |
|
6 |
Set the SQL associated with the stored procedure. The SQL should contain only the stored procedure name —parentheses, the CALL statement, and parameter placeholders are neither required nor allowed. |
|
8–39 |
The declareParameter( ) method invocations define input and output parameters and also any result sets returned by the stored procedure. |
|
8–21 |
Specify the definition of the first—employee list—result set. The SqlReturnResultSet class represents a result set. |
|
9 |
Create an implementation of the RowMapper interface that will map the result set rows. |
|
10 |
The mapRow( ) method processes a single row in a result set. It returns an object that represents the row. |
|
12–18 |
Create an Employee object to hold a single employee row from the result set. We create the Employee object using the default constructor with the values of the current row as arguments. We use the normal JDBC syntax to retrieve each column from the row and assign it to the appropriate constructor argument. |
|
19 |
Return the new Employee object to the RowMapper, which will add it to the Map being constructed for the current result set. |
|
23–35 |
Repeat the process for the second result set, which is used to create a Map of customer objects. |
|
37 |
Define our single input parameter—department_id—using the SqlParameter method. |
|
39 |
Define our single output parameter—sales_total—using the SqlOutParameter method. |
Now that we have created a class that knows how to process the inputs and outputs of our stored procedure, we are ready to use the stored procedure within our Java code. The StoredProcedure class takes, as its argument, a Map that includes all of the required parameters to the stored procedure call. The class returns a Map that contains all of the result sets and output parameters. Example 14-41 shows us using the StoredProcedure class in our Java code.
Example 14-41. Using a Spring stored procedure class
1 MyStoredProcedure msp = new MyStoredProcedure(datasource);
2 Map inParameters = new HashMap( );
3 inParameters.put("department_id", new Integer(department_id));
4 Map results = msp.execute(inParameters);
5
6 List employees = (List) results.get("Employees");
7 System.out.println("Employees of department " + department_id);
8 for (int i = 0; i < employees.size( ); i++) {
9 Employee e = (Employee) employees.get(i);
10 System.out.println(e.getEmployeeId( ) + "\t" +
11 e.getFirstname() + "\t" + e.getSurname( ));
12 }
13
14 List customers = (List) results.get("Customers");
15 System.out.println("Customers of department " + department_id);
16 for (int i = 0; i < customers.size( ); i++) {
17 Customer c = (Customer) customers.get(i);
18 System.out.println(c.getCustomerId() + "\t" + c.getCustomerName( ));
19 }
20
21 Double salesTotal = (Double) results.get("sales_total");
22 System.out.println("Total sales for the department " +
23 department_id + "=" + salesTotal);
Here is an explanation of this code:
|
Line(s) |
Explaination |
|
1 |
Create a new instance of our MyStoredProcedure class, passing an existing DriverManagerDataSource object (datasource) to represent the MySQL connection. |
|
2 |
Create a HashMap that will hold the procedure's input parameters. |
|
3 |
Add name-value pairs to the HashMap for each input parameter. In this case, we have only a single parameter—department_id. |
|
4 |
Use the execute( ) method of the StoredProcedure object to execute the stored procedure. We pass in the Map containing input parameters, and we retrieve a new Map containing all the outputs of the stored procedure call. |
|
6 |
Use the get( ) method of the Map to retrieve a List that represents the rows in the first result set (employees). |
|
8 |
Iterate through each element in the List. This is equivalent to moving through each row in the result set. |
|
9 |
Cast each list entry to an Employee object representing the current row in the result set. |
|
10 |
Use the methods we created for the Employee class to extract and display the details for the current employee. |
|
14-19 |
Process the second result set (customers) in the same way as for the employees result set. |
|
21-23 |
Retrieve and display the value of the single OUT parameter (sales_total). |
Conclusion
In this chapter we looked at how to use MySQL stored programs from within Java programs. Java programs access relational databases through the JDBC interfaces supported by the MySQL Connector/J driver.
We first reviewed the fundamentals of using JDBC to process basic SQL—queries, updates, inserts, deletes, DDL, and utility statements. We showed how to use the PreparedStatement interface to execute SQL statements that are repeatedly executed, possibly with variable query parameters or DML inputs. Finally, we looked at JDBC structures for implementing transaction and error handling.
JDBC fully supports stored programs through the CallableStatement interface. Callable statements support multiple result sets, and they support IN, OUT, and INOUT parameters. The ResultSetMetaData interface can be used to determine the structure of result sets returned by stored programs if this is not known in advance.
Stored programs are suitable for use in J2EE applications, and stored procedures can be invoked from within J2EE application servers such as JBoss, WebLogic, and WebSphere. We can use stored programs in J2EE applications wherever we might embed standard SQL calls—from servlets, session EJBs, or Bean Managed Persistence (BMP) EJBs. However, stored programs cannot easily be leveraged from within Container Managed Persistence (CMP) EJBs.
We can use stored procedures in ORM frameworks such as Hibernate, although doing so involves more work than letting Hibernate generate its own native SQL. The Spring framework also provides full support for MySQL stored procedures.
As with other application development environments, the use of stored programs from within Java code offers a number of advantages, including encapsulation of complex transaction logic, abstraction of the underlying schema, and potential performance improvements from reduction in network round trips.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.