MySQL Stored Procedure Programming (2009)
Part III. Using MySQL Stored Programs in Applications
Chapter 15. Using MySQL Stored Programs with Perl
Perl is an open source programming language widely used for system administration tasks, web site development, data manipulation, and reporting. Perl was the brainchild of Larry Wall, who initially developed the language to provide a language for the easy manipulation of text files and the like. Perl rapidly became very popular among the Unix community as a powerful, easy-to-use, general-purpose programming language. During the explosion of the World Wide Web, Perl's ease of use and database connectivity capabilities made it the preferred choice for CGI-based data-driven web sites.
From very early on, Perl was an extensible language and benefited greatly from a wide variety of user-contributed packages allowing it to do everything from handling Unix mail to performing complex statistical analyses. One category of extension showed particularly rapid uptake—extensions that enabled Perl to interact with relational databases, allowing Perl users to manipulate RDBMS data as easily as they could manipulate text files. Initially, these extensions were platform specific—the extension used to access Oracle had little in common with that used to access Sybase, for instance.
Perl's DBI (DataBase Interface) module evolved to provide a common syntax for interacting with relational databases. DBI defines interfaces and utilities common to all databases, while for each specific relational database, we use a DBD (DataBase Driver) module that contains the database-specific implementation of the DBI interface, and may also include database-specific utility routines. The preferred way to use MySQL with Perl is through the DBD::mysql module.
In this chapter we will first provide a general overview of DBD::mysql capabilities and then move on to show how to use DBD::mysql to call MySQL stored programs.
Review of Perl DBD::mysql Basics
Let's start with a review of how to install the DBD::mysql driver, and how to use that driver to perform traditional interactions (i.e., those not using stored programs) with MySQL. These form the building blocks that we can use to work with stored programs. However, if you are already familiar with the Perl DBI, you may wish to skip forward to "Executing Stored Programs with DBD::mysql," later in this chapter.
Installing DBD::mysql
To access MySQL from Perl, you will normally use the DBD::mysql package. DBD::mysql is a Perl package that implements the classes defined by the DBI package that allow Perl to interact with relational databases in a database-independent manner.
The DBI package is probably already included in your Perl distribution. If it is not, you can follow the instructions given in this section.
Tip
Make sure to install the DBI package before installing the DBD::mysql package.
Installing DBD::mysql on Linux or Unix
The easiest way to install DBD::mysql on a Linux/Unix system is to use the CPAN (Comprehensive Perl Archive Network) shell. To invoke the CPAN shell, run the following command from a command line (as root):
[root@guyh3 root]# perl -MCPAN -e 'shell'
This invokes the CPAN command line:
[root@guyh3 root]# perl -MCPAN -e 'shell'
cpan shell -- CPAN exploration and modules installation (v1.61)
ReadLine support enabled
cpan>
You can then type install DBD::mysql to download, build and install the DBD::mysql driver. It's probably best to specify force install, because otherwise the DBD::mysql driver will not install unless it has passed all the built-in tests. Unfortunately, the tests will probably fail if you have a nonstandard database password, so we generally use force install to ensure that the installation succeeds.
The CPAN install session will look something like this:
cpan> force install DBD::mysql
CPAN: Storable loaded ok
Going to read /root/.cpan/Metadata
Database was generated on Wed, 15 Jun 2005 11:57:49 GMT
Running install for module DBD::mysql
Running make for R/RU/RUDY/DBD-mysql-2.9008.tar.gz
CPAN: Digest::MD5 loaded ok
Checksum for /root/.cpan/sources/authors/id/R/RU/RUDY/DBD-mysql-2.9008.tar.gz ok
Scanning cache /root/.cpan/build for sizes
DBD-mysql-2.9008/
DBD-mysql-2.9008/t/
DBD-mysql-2.9008/t/60leaks.t
DBD-mysql-2.9008/t/40listfields.t
DBD-mysql-2.9008/t/10dsnlist.t
*** LOTS of other output ***
Failed 16/18 test scripts, 11.11% okay. 725/732 subtests failed, 0.96% okay.
make: *** [test_dynamic] Error 2
/usr/bin/make test -- NOT OK
Running make install
Installing /usr/lib/perl5/site_perl/5.8.0/i386-linux-thread-multi/auto/DBD/mysql/
mysql.so
Files found in blib/arch: installing files in blib/lib into architecture dependent
library tree
Installing /usr/lib/perl5/site_perl/5.8.0/i386-linux-thread-multi/DBD/mysql.pm
Installing /usr/share/man/man3/DBD::mysql.3pm
Writing /usr/lib/perl5/site_perl/5.8.0/i386-linux-thread-multi/auto/DBD/mysql/.
packlist
Appending installation info to /usr/lib/perl5/5.8.0/i386-linux-thread-multi/
perllocal.pod
/usr/bin/make install -- OK
Installing DBD::mysql on Windows
If you are using Perl on Windows, you probably are using the ActiveState binary distribution (http://www.activestate.com). Activestate Perl includes the Perl Package Manager, which can be used to download binary versions of Perl packages from the ActiveState site. To use PPM you simply type ppm from a Windows command prompt. If you are working through a proxy server, you may need to set appropriate values for HTTP_proxy, HTTP_proxy_user, and HTTP_proxy_pass, as shown below:
C:\>set HTTP_proxy=http://something.proxy.com:8080
C:\>set HTTP_proxy_user=myusername
C:\>set HTTP_proxy_pass=mypassword
C:\>ppm
PPM interactive shell (2.1.6) - type 'help' for available commands.
PPM> install DBD::mysql
Install package 'DBD-mysql?' (y/N): y
Installing package 'DBD-mysql'...
Bytes transferred: 597532
Installing C:\Perl\site\lib\auto\DBD\mysql\mysql.bs
Installing C:\Perl\site\lib\auto\DBD\mysql\mysql.dll
Installing C:\Perl\site\lib\auto\DBD\mysql\mysql.exp
Installing C:\Perl\site\lib\auto\DBD\mysql\mysql.lib
Installing C:\Perl\html\site\lib\Mysql.html
Installing C:\Perl\html\site\lib\DBD\mysql.html
Installing C:\Perl\html\site\lib\DBD\mysql\INSTALL.html
Installing C:\Perl\html\site\lib\Bundle\DBD\mysql.html
Installing C:\Perl
\site\lib\Mysql.pm
Installing C:\Perl\site\lib\Mysql\Statement.pm
Installing C:\Perl\site\lib\DBD\mysql.pm
Installing C:\Perl\site\lib\DBD\mysql\GetInfo.pm
Installing C:\Perl\site\lib\DBD\mysql\INSTALL.pod
Installing C:\Perl\site\lib\Bundle\DBD\mysql.pm
Writing C:\Perl\site\lib\auto\DBD\mysql\.packlist
Connecting to MySQL
To connect to MySQL from a Perl program, we first need to issue the use DBI clause to load the DBI driver that forms the foundation for the DBD::mysql driver. We then create a database handle using the DBI->connect() method.
The connect method has the following syntax:
Database_handle=DBI->connect(DataSourceName,UserName,PassWord,[Attributes]);
The resulting database handle is used in all subsequent interactions with the database.
The DataSourceName specifies the database details for the connection. The syntax depends on the type of database used, but for MySQL it has the following format:
dbi:mysql:database:host:port
where hostname indicates the hostname or IP address of the machine hosting the MySQL instance, port defines the port on which the MySQL server is listening (3306 by default), and database specifies the database within the server to which the connection is being made.
Attributes defines some optional attributes for the connection; we'll discuss attributes in the next section.
In Example 15-1 we connect to a database prod on the MySQL server on the local machine localhost at port 3306. We connect as root with the password secret.
Example 15-1. Connecting to a MySQL database from Perl
use strict;
use DBI;
my $dbh = DBI->connect( "DBI:mysql:prod:localhost:3306", "root", "secret" );
Connection attributes
DBD:MySQL allows you to specify the following attributes at connection time:
AutoCommit
Determines whether each SQL statement will automatically commit following execution. This is relevant only for transactional databases such as InnoDB.
PrintError
Determines whether MySQL errors will be printed as warnings.
RaiseError
Determines whether MySQL errors will terminate execution.
These attributes are represented as an associative array within the connect() method, and each takes an argument of either 1 (true) or 0 (false). Example 15-2 shows how to set up a connection in which automatic commits are suppressed and in which any errors encountered are reported without terminating execution.
Example 15-2. Setting database handle attributes on connection
my $dbh = DBI->connect( "DBI:mysql:prod:localhost:3306",
"root", "secret", { AutoCommit => 0, PrintError => 1, RaiseError => 0 } )
You can modify any of these database handle attributes during execution, as shown in Example 15-3.
Example 15-3. Enabling autocommit
$dbh->{AutoCommit} = 1; #Enable autocommit
Handling Errors
As shown earlier, we can set up some basic error-handling defaults at connection time that will control whether MySQL errors cause immediate termination of a program. However, we will often want to check the error status of a DBD::mysql call immediately after execution and take appropriate action if the call fails.
Usually, a DBI method will return true if it is successful, or false otherwise, and so we can check that return status to determine whether the call was successful, as shown in Example 15-4. Details about the actual status of execution can be found in the err and errstr properties of the database handle. These properties can be used to determine the root cause of the error or to report the error to the user.
Example 15-4. Checking for errors in a DBI statement
my $dbh = DBI->connect( "DBI:mysql:prod:localhost:3306",
"root", "secret", { AutoCommit => 0, PrintError => 0, RaiseError => 0 } )
|| die "Connection error: ".$DBI::errstr;
Issuing a Simple One-off Statement
The DBI do() method allows us to execute a simple statement that returns no result sets and takes no parameters. Example 15-5 shows the use of the do() method to set the value for a user variable.
Example 15-5. Using do( ) to execute a simple SQL
$dbh->do('set @myvariable=10')||die $DBI::errstr;
Preparing a Statement for Reuse
To execute a statement more than once, or to execute a SQL statement that retrieves a result set, we first need to prepare, and then execute, the statement. Example 15-6 shows the use of prepare() and execute() rather than do() to execute a simple SQL statement.
Example 15-6. Using prepare( ) and execute( )
my $sth=$dbh->prepare('set @myvariable=9')||die $DBI::errstr;
$sth->execute||die $DBI::errstr;
Using Bind Variables
One of the advantages of using prepared statements is that they can be re-executed with altered parameters without having to be redefined each time. Bind variables— also known as substitution variables —are indicated within a SQL statement by ? placeholders. Prior to execution, we call the bind_param() method to set the values of these variables.
In Example 15-7 we prepare a statement and then bind and execute() the statement 10 times in a loop. Each execution inserts unique rows into the appropriate table.
Example 15-7. Using bind_param( ) to set placeholder values
my $sth=$dbh->prepare('INSERT INTO bind_example(col1,col2) VALUES(?,?)')
||die $DBI::errstr;
for (my $i=1; $i<=10;$i++) {
$sth->bind_param(1,$i);
$sth->bind_param(2,'Row# '.$i);
$sth->execute||die $DBI::errstr;
}
$sth->finish;
Alternatively, we can specify the bind variables in the execute method, as shown in Example 15-8.
Example 15-8. Specifying bind values in the execute( ) method
my $sth = $dbh->prepare('INSERT INTO bind_example(col1,col2) VALUES(?,?)')
|| die $DBI::errstr;
for ( my $i = 1 ; $i <= 10 ; $i++ ) {
my $col2_value = 'Row2#' . $i;
$sth->execute( $i, $col2_value ) || die $DBI::errstr;
}
Issuing a Query and Retrieving Results
In line with the core philosophy of Perl —There's More Than One Way To Do It?— Perl DBI and the DBD::mysql driver provide a number of ways to retrieve rows from a query. In Example 15-9, we use the fetchrow_array method, which is probably the most commonly used approach.
Example 15-9. Retrieving rows with fetchrow_array
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
while ( my @row = $sth->fetchrow_array ) {
print $row[0] ."\t". $row[1] . "\n";
}
$sth->finish;
After we have prepared and executed a SQL statement that returns a result set (SELECT, SHOW STATUS, etc.), we can use the fetchrow_array method to retrieve each row into a Perl array. We can then refer to the column values as numbered elements in that array (starting with element 0, of course!).
There's More Than One Way To Do It
Perl DBI offers at least five other ways of retrieving rows from a statement handle, described in the following subsections.
fetchrow_arrayref method
The fetchrow_arrayref method, shown in Example 15-10, is similar in usage to fetchrow_array, and has the advantage of returning a reference to an array, rather than the array itself. This has a small positive impact on performance for each row, since the data is not copied into a new array.
Example 15-10. Retrieving rows with fetchrow_arrayref
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
while ( my $row_ref = $sth->fetchrow_arrayref ) {
print $row_ref->[0]."\t".$row_ref->[1]."\n";
}
$sth->finish;
fetchrow_hashref method
The fetchrow_hashref method, shown in Example 15-11, returns the row as an associative array in which each element of the array is keyed by the column name, rather than the column position. This has the advantage of improving readability, although you have to know the column names that will be returned by the query.
Example 15-11. Retrieving rows with fetchrow_hashref
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
while ( my $hash_ref = $sth->fetchrow_hashref ) {
print $hash_ref->{customer_id} . "\t" .
$hash_ref->{customer_name} . "\n";
}
$sth->finish;
fetchall_arrayref method
The fetchall_arrayref method allows you to retrieve an entire result set in a single operation. For noninteractive applications where the result set can fit into available memory, this can be a very efficient way to retrieve a result set. However, it is not necessarily appropriate for interactive applications where the user may wish to view only the first page of data before looking at the rest (for instance, on a web search page you rarely scroll through the entire list of matching sites). If the result set is too large for available memory, this method may degrade overall system performance as memory is swapped out to disk.
There are two main modes for the fetchall_arrayref method. In the first and simplest case, shown in Example 15-12, no arguments are provided to the method, and the method passes a reference to an array. Each element in the array contains references to an array containing the column values for a particular row.
Example 15-12. Retrieving rows with fetchall_arrayref
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
my $table = $sth->fetchall_arrayref||die $DBI::errstr;
for my $i ( 0 .. $#{$table} ) {
for my $j ( 0 .. $#{ $table->[$i] } ) {
print "$table->[$i][$j]\t";
}
print "\n";
}
Providing {} as the argument to fetchall_arrayref returns the columns as hashes, indexed by column name. In Example 15-13, we repeat our previous query but access our columns as hash references.
Example 15-13. Using fetchall_arrayref, returning hash references
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
my $table = $sth->fetchall_arrayref({}) || die $DBI::errstr;
foreach my $row (@$table) {
print $row->{customer_id} . "\t" . $row->{customer_name} . "\n";
}
You can also provide array or hash slice references as an argument to fetchall_arrayref to restrict the columns returned.
dump_results method
The dump_results method provides a quick-and-dirty way to print the output of a query. By default, dump_results will output all of the rows from a statement handle to standard output, surrounding the values in quotes, separating with commas, terminating each row with a line feed, and truncating columns (if necessary) to a maximum of 35 bytes per value. These default behaviors can be changed by providing arguments to dump_results:
my $Rowcount=$statement_handle->dump_results(
[column_length],[line separator],[column separator],[file handle]);
Example 15-14 shows dump_results in action.
Example 15-14. Using dump_results to display a result set
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
my $row_count = $sth->dump_results;
$sth->finish;
The output of dump_results is shown in Example 15-15.
Example 15-15. Output from dump_results
'398', 'BELL INDUSTRIES INC.', 'DAHL', 'PHILIPPA'
'2985', 'GEORGIA-PACIFIC CORPORATION', 'OBRIEN', 'DOYLE'
'4776', 'CFC INTERNATIONAL INC', 'KINDRED', 'TOM'
'8756', 'INFODATA SYSTEMS INC', 'WEATHERFORD', 'KRISTIE'
'10746', 'ADTRAN INC.', 'EATON', 'RAYBURN'
bind_col and fetch methods
The final method we're going to look at differs from all the preceeding techniques: instead of the fetch( ) method returning an array or a reference to an array, we associate Perl variables ahead of time to each column that will be returned by the query. We perform this association with thebind_col method. Then we call the fetch method, which automatically deposits the values of the columns concerned into the variables nominated earlier. The Perl variables must be passed by reference (preceded by a \ character), which results in a theoretical performance advantage.
Example 15-16 provides an example of using this technique.
Example 15-16. Using bind_col and fetch( ) to retrieve data from a query
my ( $customer_id, $customer_name );
my $sql =
"SELECT customer_id,customer_name FROM customers WHERE sales_rep_id=1";
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
$sth->bind_col( 1, \$customer_id );
$sth->bind_col( 2, \$customer_name );
while ( $sth->fetch ) {
print join( "\t", ( $customer_id, $customer_name ) ), "\n";
}
Getting Result Set Metadata
We don't necessarily always know the exact structure of the result set that will be returned by a SQL statement: the SQL might have been built up dynamically or even supplied by the user. To allow for this possibility, DBI lets us retrieve details about the result set using attributes of the statement handle. The NUM_OF_FIELDS statement handle attribute returns the number of columns in the result set, while the NAME and TYPE attributes are arrays containing the names and data types of each column.
Example 15-17 shows how we can use these attributes to print out the structure of a result set.
Example 15-17. Retrieving result-set metadata
my $sth = $dbh->prepare($sql) || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
foreach my $colno ( 0 .. $sth->{NUM_OF_FIELDS} - 1 ) {
print "Name= "
. $sth->{NAME}->[$colno]
. "\tType="
. $sth->{TYPE}->[$colno] . "\n";
}
These attributes let us write code that can handle dynamically any result set that might be returned. For instance, the code in Example 15-18 will print the result set returned from a SQL statement contained within the $sql variable, without knowing in advance the structure of the result set that SQL might return.
Example 15-18. Handling a dynamic result set
1 my $sth = $dbh->prepare($sql) || die $DBI::errstr;
2 $sth->execute || die $DBI::errstr;
3
4 # Print a title row
5 print join("\t",@{$sth->{NAME}}),"\n";
6
7 # Print out the values
8 while ( my @row = $sth->fetchrow_array ) {
9 print join("\t",@row),"\n";
10 }
11 $sth->finish;
Let's examine this example line by line:
|
Line(s) |
Explanation |
|
5 |
Print the names of each column in the result set—separated by tab characters—as a header row. |
|
8-10 |
This loop repeats once for each row in the result set. |
|
9 |
Print out a tab-separated list of column values for a particular row. |
Performing Transaction Management
If you're using a transactional storage engine such as InnoDB, you may want to implement transactional logic within your Perl code. While you can do that by issuing the MySQL START TRANSACTION, ROLLBACK , and COMMIT statements with the DBI do() method, DBI provides some native routines that might be more convenient.
The AutoCommit attribute of the connection handle can be set to 0 to disable automatic commits after each statement, while the rollback() and commit() methods of the connection handle can be used to explicitly roll back or commit transactions.
Example 15-19 uses these methods to control transaction logic in a simple Perl script.
Example 15-19. DBI transaction management commands in action
$dbh->{AutoCommit} = 0;
$dbh->do(
"UPDATE account_balance
SET balance=balance-$tfer_amount
WHERE account_id=$from_account"
);
if ($DBI::err) {
print "transaction aborted: ".$DBI::errstr . "\n";
$dbh->rollback;
}
else {
$dbh->do(
"UPDATE account_balance
SET balance=balance+$tfer_amount
WHERE account_id=$to_account"
);
if ($DBI::err) {
print "transaction aborted: ".$DBI::errstr . "\n";
$dbh->rollback;
}
else {
printf("transaction succeeded\n");
$dbh->commit;
}
}
Executing Stored Programs with DBD::mysql
We can use the techniques we've discussed in the previous sections for executing stored programs, although there are some circumstances in which you will need to use some additional techniques—specifically, if you need to retrieve multiple result sets or retrieve the value of an output parameter.
To execute a simple, one-off stored procedure that returns no result sets, we can simply invoke it with the do() method of the database handle, as shown in Example 15-20.
Example 15-20. Executing a very simple stored procedure
my $sql = 'call simple_stored_proc( )';
$dbh->do($sql)||die $DBI::errstr;
Stored procedures that return only a single result set can be treated in the same manner as simple SELECT statements. Example 15-21 shows a stored procedure that returns just one result set.
Example 15-21. Simple stored procedure with a result set
CREATE PROCEDURE department_list( )
SELECT department_name,location from departments;
Example 15-22 shows how we would retrieve that result set in Perl. The approach is exactly the same as the one we would use for a SELECT statement or other SQL that returns a result set.
Example 15-22. Fetching a single result set from a stored procedure
my $sth = $dbh->prepare('call department_list( )') || die $DBI::errstr;
$sth->execute || die $DBI::errstr;
while ( my @row = $sth->fetchrow_array ) {
print join("\t",@row),"\n";
}
$sth->finish;
Input parameters can be treated in the same way as placeholders in standard SQL. Input parameters are indicated in the prepare statement as ? characters, and the values are set using the bind_param method.
Example 15-23 shows a simple stored procedure that accepts an input parameter.
Example 15-23. Simple stored procedure with an input parameter
CREATE PROCEDURE customer_list(in_sales_rep_id INTEGER)
SELECT customer_id,customer_name
FROM customers
WHERE sales_rep_id=in_sales_rep_id;
In Example 15-24 we use bind_param to set that value before executing the stored procedure and retrieving the result set. The example executes the stored procedure nine times, supplying 1-9 for the sales_rep_id parameter.
Example 15-24. Specifying an input parameter
my $sth = $dbh->prepare('call customer_list(?)') || die $DBI::errstr;
for ( my $sales_rep_id = 1 ; $sales_rep_id < 10 ; $sales_rep_id++ ) {
print "Customers for sales rep id = " . $sales_rep_id;
$sth->execute($sales_rep_id) || die $DBI::errstr;
while ( my @row = $sth->fetchrow_array ) {
print join( "\t", @row ), "\n";
}
}
$sth->finish;
Handling Multiple Result Sets
Since stored procedures may return multiple result sets , DBI provides a method—more_results—to move to the next result set in a series. The DBD::mysql driver implementation of this method was still experimental at the time of writing (it is available in developer releases 3.0002.4 and above). We'll keep you updated on the status of DBD::mysql at this book's web site (see the Preface for details).
Example 15-25 shows a simple stored procedure that returns two result sets.
Example 15-25. Stored procedure with two result sets
CREATE PROCEDURE sp_rep_report(in_sales_rep_id int)
BEGIN
SELECT employee_id,surname,firstname
FROM employees
WHERE employee_id=in_sales_rep_id;
SELECT customer_id,customer_name
FROM customers
WHERE sales_rep_id=in_sales_rep_id;
END
Because we know in advance the number and structure of the result sets returned by the stored procedure, it is relatively simple to process the results. In Example 15-26, we simply retrieve the first result set as usual, call more_results, and then process the next result set.
Example 15-26. Fetching two result sets from a stored procedure
my $sth = $dbh->prepare("CALL sp_rep_report(?)") || die $DBI::errstr;
$sth->execute($sales_rep_id) || die $DBI::errstr;
# first result set: employee_id,surname,firstname
print 'Employee_id' . "\t" . 'Surname' . "\t" . 'Firstname' . "\n";
while ( my $row = $sth->fetchrow_hashref ) {
print $row->{employee_id} . "\t" .
$row->{surname} . "\t" .
$row->{firstname} . "\n";
}
$sth->more_results;
# second result set: customer_id,customer_name
print 'Customer_id' . "\t" . 'Customer Name' . "\n";
while ( my $row = $sth->fetchrow_hashref ) {
print $row->{customer_id} . "\t" . $row->{customer_name} . "\n";
}
$sth->finish;
Handling Dynamic Result Sets
A stored program can return a variable number of result sets, and the structure and number of those result sets can be unpredictable. To process the output of such stored programs, we need to combine the more_results method with the DBI attributes that contain result set metadata; these were outlined in the earlier section "Getting Result Set Metadata." The more_results method returns false if there are no further result sets, so we can continue to call more_results until all of the result sets have been processed. Example 15-27 illustrates this technique.
Example 15-27. Dynamically processing multiple result sets
1 sub execute_procedure( ) {
2 my ( $dbh, $stored_procedure_call ) = @_;
3 my $sth = $dbh->prepare($stored_procedure_call)
4 || die $DBI::err . ": " . $DBI::errstr;
5 $sth->execute || die DBI::err . ": " . $DBI::errstr;
6 my $result_set_no = 0;
7
8 do {
9 print "\n", ( '=' x 20 ) . " Result Set # ",
10 ++$result_set_no . ( '=' x 20 ), "\n\n";
11
12 print join( "\t", @{ $sth->{NAME} } ),"\n", ( '-' x 54 ), "\n";
13
14 while ( my @row = $sth->fetchrow_array( ) ) {
15 print join( "\t", @row ), "\n";
16 }
17 }until ( !$sth->more_results );
18 }
Let's step through this code:
|
Lines |
Explanation |
|
1–7 |
Here we define our subroutine, and have it extract a database connection handle ($dbh) and stored procedure call from the parameters passed to the procedure. The stored procedure call is prepared and executed (lines 3–5). |
|
8–17 |
Specify an until loop that will execute until more_results returns false. This loop will execute at least once. |
|
9 and 10 |
This statement prints a "divider" line to separate each result set returned by the stored procedure. |
|
12 |
Print out the column names for the current result set. |
|
14–16 |
Loop through the rows in the current result set by calling fetchrow_array to retrieve rows until all rows have been processed. |
|
15 |
Print the column values for the current row and print each column value. |
|
17 |
Call more_results to move to the next result set. If more_results returns false, then there are no more result sets to be retrieved and the loop will terminate. |
Handling Output Variables
A stored procedure may contain OUT or INOUT parameters that can return individual scalar values from the stored procedure call. The DBI specification provides the bind_param_inout method for retrieving the values of such parameters. Unfortunately, this method is not implemented in the DBD::mysql driver as we write this—we'll keep you posted on the status of this method for MySQL at the book's web site.
Luckily, we don't need the bind_param_inout method to retrieve the value of an output parameter. We can pass in a user variable (see Chapter 3) to receive the output parameter value, and then select the value of that variable in a subsequent SELECT. Example 15-28 shows an example of this technique as an alternative to using bind_param_inout.
Example 15-28. Retrieving an output parameter without the bind_param_inout method
my $sql =
'call sp_rep_customer_count(1,@customer_count)'; #watch out for the "@"!
my $sth = $dbh->prepare($sql);
$sth->execute( ) || die $DBI::errstr;
$sth->finish;
# Now get the output variable
my @result = $dbh->selectrow_array('SELECT @customer_count')
|| die $DBI::errstr;
print "customer_count=", $result[0], "\n";
Watch out when creating strings that include user variables in Perl. By default, the @ symbol indicates a Perl array and—if the @ appears in a double-quoted string—Perl will attempt to replace the apparent array with a Perl value. So you should always include these types of strings in single quotes or escape the user variable reference by preceding the @ symbol with "\" (e.g., SELECT \@user_var).
Also, remember that if the stored program includes any result sets, you must process all of these result sets before attempting to retrieve the values of an output parameter.
A Complete Example
In this section we'll put all of the techniques we have described so far into an example procedure that implements a simple web-based MySQL server status display. The example will prompt the user for MySQL server details and return selected status information about that server. The information will be provided by a single stored program that returns multiple result sets and includes both input and output parameters.
The stored procedure is shown in Example 15-29. The stored procedure returns, as result sets, the output of various SHOW statements and—if a valid database name is provided as an input parameter—details about objects in that particular database. The server version is returned as an output parameter.
Example 15-29. Stored procedure that generates an employee report
CREATE PROCEDURE sp_mysql_info
(in_database VARCHAR(60),
OUT server_version VARCHAR(100))
READS SQL DATA
BEGIN
DECLARE db_count INT;
SELECT @@version
INTO server_version;
SELECT 'Current processes active in server' as table_header;
SHOW full processlist;
SELECT 'Databases in server' as table_header;
SHOW databases;
SELECT 'Configuration variables set in server' as table_header;
SHOW global variables;
SELECT 'Status variables in server' as table_header;
SHOW global status;
/* See if there is a matching database */
SELECT COUNT(*)
INTO db_count
FROM information_schema.schemata s
WHERE schema_name=in_database;
IF (db_count=1) THEN
SELECT CONCAT('Tables in database ',in_database) as table_header;
SELECT table_name
FROM information_schema.tables
WHERE table_schema=in_database;
END IF;
END;
To help us generate a well-formatted report, the stored procedure outputs a header row for each of the result sets it returns. This header row is issued as a single-row, single-column result set in which the column name is table_header.
Our Perl example is contained in Example 15-30. This is a Perl CGI script, designed to be run from the "CGI bin" directory of a web server such as Apache or Microsoft IIS. The program generates HTML to prompt for user input, connects to MySQL, runs the stored procedure, and generates the HTML to output the results.
Example 15-30. Perl CGI program to display server status information
1 #!/usr/bin/perl
2 use CGI qw(:standard);
3 use HTML::Table;
4 use DBI;
5 use strict;
6 if ( !param( ) ) {
7 my $form_tbl = new HTML::Table( );
8 $form_tbl->addRow( "Hostname:", textfield( 'hostname', 'localhost' ) );
9 $form_tbl->addRow( "Username:", textfield( 'username', 'root' ) );
10 $form_tbl->addRow( "Password:", password_field('password') );
11 $form_tbl->addRow( "Database:", textfield('database') );
12 $form_tbl->addRow( "Port:", textfield( 'port', 3306 ) );
13 print header, start_html('MySQL Server Status'),
14 h1('Enter MySQL Server details'), start_form, $form_tbl->getTable,
15 submit,end_form, hr;
16 }
17 else {
18 my $hostname = param('hostname');
19 my $username = param('username');
20 my $password = param('password');
21 my $db = param('database');
22 my $port = param('port');
23 my @html_body;
24
25 my $dbh = DBI->connect( "DBI:mysql:$db:$hostname:$port",
26 "$username", "$password", { PrintError => 0 } );
27 if (DBI::err) {
28 print header, start_html("Error"), $DBI::errstr;
29 }
30 else {
31 my $sth = $dbh->prepare('call sp_mysql_info(?,@server_version)')
32 || die $DBI::err . ": " . $DBI::errstr;
33 $sth->bind_param( 1, $db );
34 $sth->execute || die DBI::err . ": " . $DBI::errstr;
35 do {
36 if ($sth->{NAME}->[0] eq "table_header" ) {
37 my @row = $sth->fetchrow_array( );
38 push( @html_body, h2( $row[0] ), p );
39 }
40 else {
41 my $table = new HTML::Table( );
42 $table->setBorder(1);
43 foreach my $colno ( 0 .. $sth->{NUM_OF_FIELDS} ) {
44 $table->setCell( 1, $colno + 1, $sth->{NAME}->[$colno] );
45 $table->setCellBGColor( 1, $colno + 1, "silver" );
46 }
47 my $rowno = 1;
48 while ( my @row = $sth->fetchrow_array( ) ) {
49 $rowno++;
50 foreach my $colno ( 0 .. $#row ) {
51 $table->setCell( $rowno, $colno + 1, $row[$colno] );
52 }
53 }
54 push( @html_body, $table->getTable );
55 }
56 } until ( !$sth->more_results );
57
58 $sth = $dbh->prepare('SELECT @server_version') || die $DBI::errstr;
59 $sth->execute( ) || die $DBI::errstr;
60 my @row = $sth->fetchrow_array( );
61 my $mysql_version = $row[0];
62
63 print header, start_html('MySQL Server Status'),
64 h1('MySQL Server Status');
65 print "<b>Server: </b>", $hostname, br, "<b>Port: </b>", $port, br,
66 "<b>Database:</b>", $db, br "<b>Version:</b>", $mysql_version, br;
67 for my $html (@html_body) {
68 print $html;
69 }
70 print end_html;
71 }
72 }
Let's step through this example:
|
Line(s) |
Explanation |
|
1–4 |
Define the path to the Perl executable—necessary for CGI programs— and import the Perl packages we are going to use. These packages include the Perl CGI module that assists with HTML formatting, the HTML::Table package to assist us with our HTML tables, and— of course—the DBI package to allow database connectivity. |
|
6–16 |
Create the HTML input form as shown in Figure 15-1. Lines 7–12 create an HTML table that contains our input fields, while lines 13–15 print titles and other HTML. All HTML is generated by the CGI package. |
|
17–72 |
Executed once the user clicks the Submit button on our HTML form. |
|
18–22 |
Retrieve the values the user entered on the input form and assign them to Perl variables. |
|
25–29 |
Using the inputs provided by the user, establish a connection to the MySQL database. |
|
31–34 |
Prepare the stored procedure call, bind the database name provided by the user as the first parameter, and execute the stored procedure. |
|
35–56 |
Execute once for each result set returned by the stored procedure. |
|
36–39 |
If the result set contains a column called table_header, then the result set is treated as a title heading for a subsequent result set, and so we generate an H2 heading row. All HTML output is added to the @html_body array to be printed once we have retrieved all result sets and the value for the output variable. |
|
41–46 |
If the result set does not represent a heading, then we initialize an HTML table to display the results. Here we create the heading row for the HTML table. Lines 43–46 loop through the column names in the result set and create a corresponding HTML table heading. |
|
48–53 |
Loop through the rows in the result set and generate HTML table rows. The loop commencing on line 48 iterates through each row, and the loop commencing on line 50 iterates through each column in each row. Line 51 sets the value for a specific row/column combination. |
|
54 |
Add the HTML for our table to the @html_body array. |
|
56 |
The until clause controls the execution of the loop that commenced on line 35. While the more_results call returns true, indicating that there are more result sets, the loop will continue to execute. |
|
58–61 |
Now that all result sets have been processed, we can retrieve the value of the output parameter. When we prepared the stored procedure on line 31, we provided a user variable—'@server_version'—to receive the value of the output parameter. Now we issue a SELECT statement to get the value of that variable. |
|
63–66 |
Having retrieved all the result sets and having retrieved the output parameter, we can generate the HTML output. These lines print the heading and server details (including the server version). |
|
67–69 |
Output the HTML that we have accumulated into the @html_body array during our program execution. This includes header rows and HTML tables constructed in our main loop. |
|
70 |
This completes our HTML output and our Perl example. |
This Perl program first generates the HTML input form, as shown in Figure 15-1.
When the user clicks the Submit button, the CGI Perl script generates output, as shown in Figure 15-2.
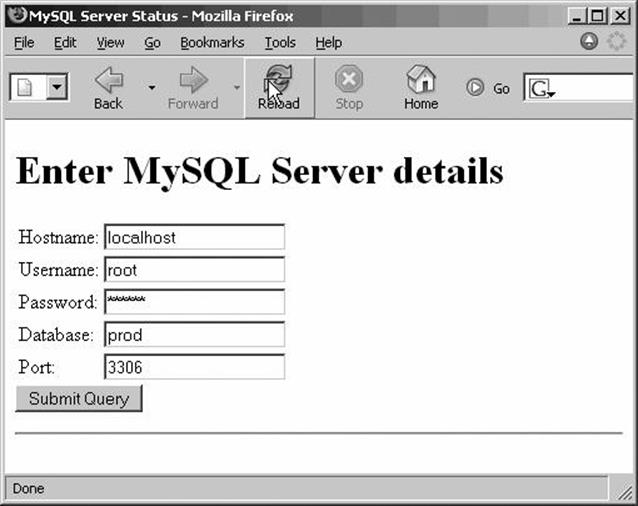
Figure 15-1. Input form for our example
Conclusion
In this chapter we reviewed the Perl DBD::mysql package, which allows Perl to connect to MySQL databases. We also showed how to use DBD::mysql to interact with MySQL stored procedures. Perl provides all of the mechanisms necessary for stored procedure processing, although some of these mechanisms were experimental as we wrote this chapter. We'll keep you updated with the status of these extensions at this book's web site.
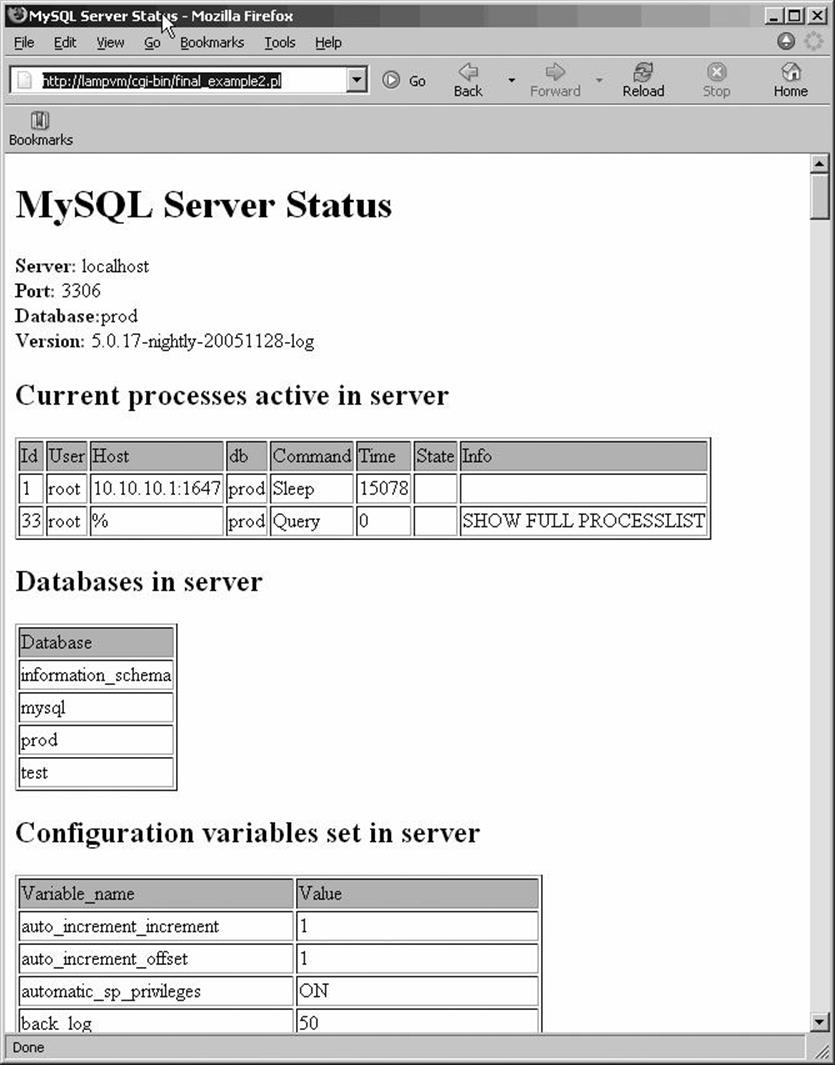
Figure 15-2. Output from our CGI example
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.