MySQL Stored Procedure Programming (2009)
Part IV. Optimizing Stored Programs
Chapter 22. Optimizing Stored Program Code
In this chapter, we look at techniques for optimizing the stored program code itself.
As we have said before, the performance of a typical stored program will primarily depend on the performance of the SQL in that stored program. This is why we have devoted several chapters to showing how to tune MySQL SQL statements.
As with any language, however, it is possible to write inefficient code in the MySQL stored program language itself. So in this chapter, we're going to assume that we have tuned our stored program's SQL statements and are now ready to tune the stored program code.
Before we dig into tuning stored program code we will briefly review the performance characteristics of stored programs and look at the circumstances under which stored programs can improve application performance. For example, under certain circumstances, we can use a stored programin place of SQL statements that are difficult to optimize. Stored programs can also improve the performance of network-intensive operations. However, note that stored programs are not, in general, a good solution when we want to do mathematically intensive computation.
Performance Characteristics of Stored Programs
MySQL stored programs can often add to application functionality and developer efficiency, and there are certainly many cases where the use of a procedural language such as the MySQL stored program language can do things that a nonprocedural language like SQL cannot. There are also a number of reasons why a MySQL stored program approach may offer performance improvements over a traditional SQL approach:
It provides a procedural approach
SQL is a declarative, nonprocedural language: this means that in SQL you don't specify how to retrieve data—you only specify the data that you want to retrieve (or change). It's up to MySQL itself—specifically, the MySQL query optimizer—to determine how to go about identifying the result set.
From time to time, we might have a very good idea about the most efficient way to retrieve the data, but find that the MySQL optimizer chooses another—less efficient—path.
When we think we know how the data should be retrieved but can't get the optimizer to play ball, we can sometimes use MySQL stored programs to force the desired approach.
It reduces client-server traffic
In a traditional SQL-based application, SQL statements and data flow back and forth between the client and the server. This traffic can cause delays even when both the client and the server programs are on the same machine. If the client and server are on different machines, then the overhead is even higher.
We can use MySQL stored programs to eliminate much of this overhead, particularly when we need to execute a series of related SQL statements. A succinct message is sent from the client to the server (the stored program execution request) and a minimal response is sent from the server to the client (perhaps only a return code). Furthermore, we can take advantage of database triggers to automatically execute statements in the database without any network interaction at all.
The resulting reduction in network traffic can significantly enhance performance.
It allows us to divide and conquer complex statements
As SQL statements become more complex, they also get harder and harder to fully optimize, both for the MySQL optimizer and for the programmer. We have all seen (and some of us have written) massive SQL statements with multiple subqueries, UNION operations, and complex joins. Tuning these "monster" SQL statements can be next to impossible for both humans and software optimizers.
It's often a winning strategy to break these massive SQL statements into smaller individual statements and optimize each individually. For instance, subqueries could be run outside of the SQL statement and the results forwarded to subsequent steps as query parameters or through temporary tables.
Having said that, we don't want to give you the impression that we think you should rewrite all of your non-trivial SQL statements in MySQL stored programs. In fact, it is usually the case that if you can express your needs in "straight" SQL, that will be the most efficient approach. And do remember that complex arithmetic computations will usually be slower in a stored program than in an equivalent SQL statement.
How Fast Is the Stored Program Language?
It would be terribly unfair of us to expect the first release of the MySQL stored program language to be blisteringly fast. After all, languages such as Perl and PHP have been the subject of tweaking and optimization for about a decade, while the latest generation of programming languages—.NET and Java—have been the subject of a shorter but more intensive optimization process by some of the biggest software companies in the world. So right from the start, we expected that the MySQL stored program language would lag in comparison with the other languages commonly used in the MySQL world.
Still, we felt it was important to get a sense of the raw performance of the language. So we put together a number of test scripts. First off, we wanted to see how quickly the stored program language could crunch numbers. Stored programs generally do not perform computationally expensive operations, but—given that you sometimes have a choice between various application tiers when performing some computationally intensive task—it's worth knowing if the stored program language is up to the job.
To test basic compute performance, we wrote a stored program that determines the number of prime numbers less than a given input number. (We're sure that some of you will know better algorithms, but remember that the point is to compare languages, not to calculate prime numbers in the most efficient manner possible.) The stored program is shown in Example 22-1.
Example 22-1. Stored program to find prime numbers
CREATE PROCEDURE sp_nprimes(p_num int)
BEGIN
DECLARE i INT;
DECLARE j INT;
DECLARE nprimes INT;
DECLARE isprime INT;
SET i=2;
SET nprimes=0;
main_loop:
WHILE (i<p_num) do
SET isprime=1;
SET j=2;
divisor_loop:
WHILE (j<i) DO
IF (MOD(i,j)=0) THEN
SET isprime=0;
LEAVE divisor_loop;
END IF;
SET j=j+1;
END WHILE ;
IF (isprime=1) THEN
SET nprimes=nprimes+1;
END IF;
SET i=i+1;
END WHILE;
SELECT CONCAT(nprimes,' prime numbers less than ',p_num);
END;
We implemented this algorithm in a variety of languages—C, Java, VB.NET, Perl, PHP, and PL/SQL (the Oracle stored program language). For instance, the Oracle implementation of the procedure is shown in Example 22-2; as you can see, while some of the language constructs differ, the algorithms are identical.
Example 22-2. Oracle implementation of the prime number procedure
PROCEDURE N_PRIMES
( p_num NUMBER)
IS
i INT;
j INT;
nprimes INT;
isprime INT;
BEGIN
i:=2;
nprimes:=0;
<<main_loop>>
WHILE (i<p_num) LOOP
isprime:=1;
j:=2;
<<divisor_loop>>
WHILE (j<i) LOOP
IF (MOD(i,j)=0) THEN
isprime:=0;
EXIT divisor_loop;
END IF;
j:=j+1;
END LOOP ;
IF (isprime=1) THEN
nprimes:=nprimes+1;
END IF;
i:=i+1;
END LOOP;
dbms_output.put_line(nprimes||' prime numbers less than '||p_num);
END;
We executed each program multiple times to seek the number of prime numbers less than 8000. The results are shown in Figure 22-1. We ran these tests on the same machine and did our best to minimize any interference from other running programs and, in every other way, to keep the playing field level. Nevertheless, for this computationally intensive trial, MySQL performed poorly compared with other languages—twice as slow as an Oracle stored procedure, five times slower than PHP or Perl, and dozens of times slower than Java, .NET, or C. Remember that Oracle in particular has been optimizing its stored procedure language for over a decade now; in comparison with the initial releases of PL/SQL, the MySQL stored program language is a speed demon!
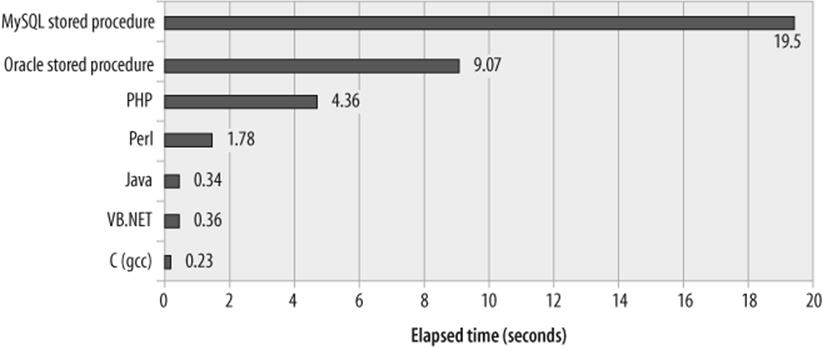
Figure 22-1. Finding prime numbers in various languages
We are confident that the MySQL stored program language will become more efficient in future releases, but for now we recommend that you avoid using this language for mathematically intensive operations.
Tip
The MySQL stored program language is relatively slow when it comes to performing arithmetic calculations. Avoid using stored programs to perform number crunching.
Reducing Network Traffic with Stored Programs
If the previous section left you feeling less than enthusiastic about stored program performance, this section should cheer you right up. Although stored programs aren't particularly zippy when it comes to number crunching, you don't normally write stored programs that simply perform math—stored programs almost always process data from the database. In these circumstances, the difference between stored program and (for instance) Java performance is usually minimal—unless network overhead is a big factor. When a program is required to process large numbers of rows from the database, a stored program can substantially outperform programs written in client languages, because it does not have to wait for rows to be transferred across the network—the stored program runs inside the database.
Consider the stored program shown in Example 22-3; this stored program retrieves all sales rows for the past five months and generates some statistical measurements (mean and standard deviation) against those rows.
Example 22-3. Stored program to generate statistics
CREATE PROCEDURE sales_summary( )
READS SQL DATA
BEGIN
DECLARE SumSales FLOAT DEFAULT 0;
DECLARE SumSquares FLOAT DEFAULT 0;
DECLARE NValues INT DEFAULT 0;
DECLARE SaleValue FLOAT DEFAULT 0;
DECLARE Mean FLOAT;
DECLARE StdDev FLOAT;
DECLARE last_sale INT DEFAULT 0;
DECLARE sale_csr CURSOR FOR
SELECT sale_value FROM SALES s
WHERE sale_date >date_sub(curdate( ),INTERVAL 6 MONTH);
DECLARE CONTINUE HANDLER FOR NOT FOUND SET last_sale=1;
OPEN sale_csr;
sale_loop: LOOP
FETCH sale_csr INTO SaleValue;
IF last_sale=1 THEN LEAVE sale_loop; END IF;
SET NValues=NValues+1;
SET SumSales=SumSales+SaleValue;
SET SumSquares=SumSquares+POWER(SaleValue,2);
END LOOP sale_loop;
CLOSE sale_csr;
SET StdDev = SQRT((SumSquares - (POWER(SumSales,2) / NValues)) / NValues);
SET Mean = SumSales / NValues;
SELECT CONCAT('Mean=',Mean,' StdDev=',StdDev);
END
Example 22-4 shows the same logic implemented in a Java program.
Example 22-4. Java program to generate sales statistics
import java.sql.*;
import java.math.*;
public class SalesSummary {
public static void main(String[] args)
throws ClassNotFoundException, InstantiationException,
IllegalAccessException {
String Username=args[0];
String Password=args[1];
String Hostname=args[2];
String Database=args[3];
String Port=args[4];
float SumSales,SumSquares,SaleValue,StdDev,Mean;
int NValues=0;
SumSales=SumSquares=0;
try
{
Class.forName("com.mysql.jdbc.Driver").newInstance( );
String ConnString=
"jdbc:mysql://"+Hostname+":"+Port+
"/"+Database+"?user="+Username+"&password="+Password;
Connection MyConnect = DriverManager.getConnection(ConnString);
String sql="select sale_value from SALES s" +
" where sale_date >date_sub(curdate( ),interval 6 month)";
Statement s1=MyConnect.createStatement( );
ResultSet rs1=s1.executeQuery(sql);
while (rs1.next( ))
{
SaleValue = rs1.getFloat(1);
NValues = NValues + 1;
SumSales = SumSales + SaleValue;
SumSquares = SumSquares + SaleValue*SaleValue;
}
rs1.close( );
Mean=SumSales/NValues;
StdDev = (float) Math.sqrt(((SumSquares -
((SumSales*SumSales) / NValues)) / NValues));
System.out.println("Mean="+Mean+" StdDev="+StdDev+" N="+NValues);
}
catch(SQLException Ex) {
System.out.println(Ex.getErrorCode()+" "+Ex.getMessage( ));
Ex.printStackTrace( );}
}
}
As we saw earlier in this chapter, Java is much, much faster than the MySQL stored program language when it comes to performing calculations. Therefore, we expect that the Java program would be faster in this case as well. In fact, when we run the Java program on the same host as the relevant MySQL server, the Java program is faster—though not by much: the Java program completed in about 22 seconds while the stored program took about 26 seconds (see Figure 22-2). Although Java is faster than the stored program when it comes to performing the arithmetic calculations needed, the bulk of the time is spent retrieving rows from the database, and so the difference is not very noticeable.
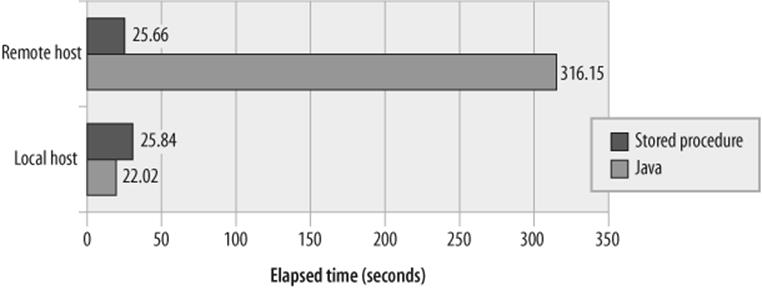
Figure 22-2. Java versus stored program performance across the network
However, when we invoke each program from a remote host across a network with relatively high latency, we see that while the stored program execution time stays the same, the Java program takes much longer to execute (increasing from 22 seconds to 5 minutes). The Java program has to fetch each row from the database across the network, and these network round-trips dominate the overall execution time. The lesson is clear: if your program causes a large amount of network traffic, such as those that fetch or change a large number of rows across the network, a stored program can outperform a program written in a client language such as Java or PHP.
Tip
Stored programs do not incur the network overhead of languages such as PHP or Java. If network overhead is an issue, then using a stored program can be an effective optimization.
Stored Programs as an Alternative to Expensive SQL
Sometimes we can use a stored program to perform query or DML operations that perform badly in standard SQL. This usually happens when the "pure" SQL statement becomes overly complex because of limitations in the SQL syntax or when the MySQL optimizer isn't able to come up with a sensible plan for your SQL query. In this section we offer two scenarios in which a stored program can be expected to outperform a SQL statement that executes the same logical steps.
Avoid Self-Joins with Procedural Logic
One situation in which a stored program might offer a better solution is where you are forced to construct a query that joins a table to itself in order to filter for the required rows. For instance, in Example 22-5, we issue a SQL statement that retrieves the most valuable order for each customer over the past few months.
Example 22-5. Finding the maximum sale for each customer
SELECT s.customer_id,s.product_id,s.quantity, s.sale_value
FROM sales s, (SELECT customer_id,max(sale_value) max_sale_value
FROM sales
GROUP BY customer_id) t
WHERE t.customer_id=s.customer_id
AND t.max_sale_value=s.sale_value
AND s.sale_date>date_sub(currdate( ),interval 6 month);
This is an expensive SQL statement, partially because we first need to create a temporary table to hold the customer ID and maximum sale value and then join that back to the sales table to find the full details for each of those rows.
MySQL doesn't provide SQL syntax that would allow us to return this data without an expensive self-join. However, we can use a stored program to retrieve the data in a single pass through the sales table. Example 22-6 shows a stored program that stores maximum sales for each customer into a temporary table (max_sales_by_customer) from which we can later select the results.
Example 22-6. Stored program to return maximum sales for each customer over the last 6 months
1 CREATE PROCEDURE sp_max_sale_by_cust( )
2 MODIFIES SQL DATA
3 BEGIN
4 DECLARE last_sale INT DEFAULT 0;
5 DECLARE l_last_customer_id INT DEFAULT -1;
6 DECLARE l_customer_id INT;
7 DECLARE l_product_id INT;
8 DECLARE l_quantity INT;
9 DECLARE l_sale_value DECIMAL(8,2);
10 DECLARE counter INT DEFAULT 0;
11
12 DECLARE sales_csr CURSOR FOR
13 SELECT customer_id,product_id,quantity, sale_value
14 FROM sales
15 WHERE sale_date>date_sub(currdate( ),interval 6 month)
16 ORDER BY customer_id,sale_value DESC;
17
18 DECLARE CONTINUE HANDLER FOR NOT FOUND SET last_sale=1;
19
20 OPEN sales_csr;
21 sales_loop: LOOP
22 FETCH sales_csr INTO l_customer_id,l_product_id,l_quantity,l_sale_value;
23 IF (last_sale=1) THEN
24 LEAVE sales_loop;
25 END IF;
26
27 IF l_customer_id <> l_last_customer_id THEN
28 /* This is a new customer so first row will be max sale*/
29 INSERT INTO max_sales_by_customer
30 (customer_id,product_id,quantity,sale_value)
31 VALUES(l_customer_id,l_product_id,l_quantity,l_sale_value);
32 END IF;
33
34 SET l_last_customer_id=l_customer_id;
35
36 END LOOP;
37
38 END;
Let's look at the most significant lines in this program:
|
Line(s) |
Explanation |
|
12 |
Declare a cursor that will return sales for the past 6 months ordered by customer_id and then by descending sale_value. |
|
27-32 |
Check to see whether we have encountered a new customer_id. The first row for any given customer will be the maximum sale for that customer, so we insert that row into a temporary table (line 30). |
The stored program is significantly faster than the standard SQL solution. Figure 22-3 shows the elapsed time for the two solutions.
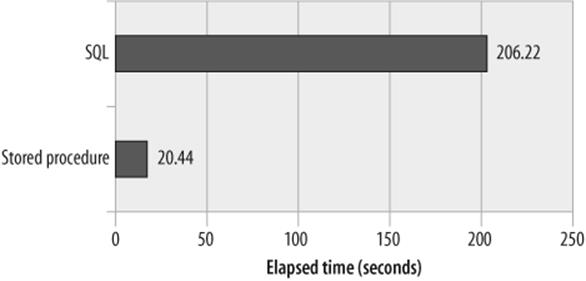
Figure 22-3. Using a stored program to optimize a complex self-join
Optimize Correlated Updates
A correlated update is an UPDATE statement that contains a correlated subquery in the SET clause and/or WHERE clause. Correlated updates are often good candidates for optimization through procedural execution. In Example 22-7 we have an UPDATE statement that updates all customers who are also employees, and assigns the employee's manager as their sales representative.
Example 22-7. Correlated UPDATE statement
UPDATE customers c
SET sales_rep_id =
(SELECT manager_id
FROM employees
WHERE surname = c.contact_surname
AND firstname = c.contact_firstname
AND date_of_birth = c.date_of_birth)
WHERE (contact_surname,
contact_firstname,
date_of_birth) IN
(SELECT surname, firstname, date_of_birth
FROM employees and );
Note that the UPDATE statement needs to access the employees table twice: once to identify customers who are employees and again to find the manager's identifier for those employees.
Example 22-8 offers a stored program that provides an alternative to the correlated update. The stored program identifies those customers who are also employees using a cursor. For each of the customers retrieved by the cursor, an UPDATE is issued.
Example 22-8. Stored program alternative to the correlated update
CREATE PROCEDURE sp_correlated_update( )
MODIFIES SQL DATA
BEGIN
DECLARE last_customer INT DEFAULT 0;
DECLARE l_customer_id INT ;
DECLARE l_manager_id INT;
DECLARE cust_csr CURSOR FOR
select c.customer_id,e.manager_id
from customers c,
employees e
where e.surname=c.contact_surname
and e.firstname=c.contact_firstname
and e.date_of_birth=c.date_of_birth;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET last_customer=1;
OPEN cust_csr;
cust_loop: LOOP
FETCH cust_csr INTO l_customer_id,l_manager_id;
IF (last_customer=1) THEN
LEAVE cust_loop;
END IF;
UPDATE customers
SET sales_rep_id=l_manager_id
WHERE customer_id=l_customer_id;
END LOOP;
END;
Because the stored program does not have to do two separate accesses of the customers table, it is significantly faster than the standard SQL. Figure 22-4 compares the performance of the two approaches.
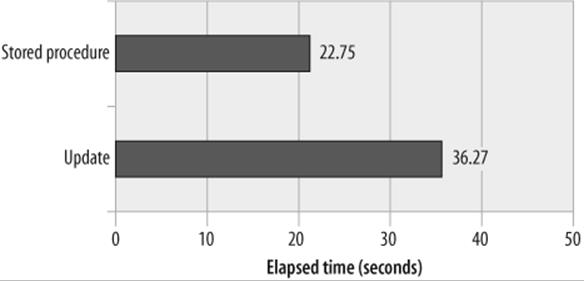
Figure 22-4. Performance of a correlated update and stored program alternative
Optimizing Loops
In the remainder of this chapter we will look at techniques for the optimization of stored program code that does not involve SQL statements, starting with the optimization of loops .
Because the statements executed within a loop can be executed many times, optimizing loop processing is a basic step when optimizing the performance of a program written in any language. The MySQL stored program language is no exception.
Move Unnecessary Statements Out of a Loop
The first principle of optimizing a loop is to move calculations out of the loop that don't belong inside the loop (these are known as loop-invariant statements , since they do not vary with each execution of the loop body). Although such a step might seem obvious, it's surprising how often a program will perform calculations over and over within a loop that could have been performed just once before the start of loop execution.
For instance, consider the stored program in Example 22-9. This loop is actually fairly inefficient, but at first glance it's not easy to spot where the problem is. Fundamentally, the problem with this stored program is that it calculates the square root of the i variable for every value of the jvariable. Although there are only 1,000 different values of i, the stored program calculates this square root five million times.
Example 22-9. A poorly constructed loop
WHILE (i<=1000) DO
SET j=1;
WHILE (j<=5000) DO
SET rooti=sqrt(i);
SET rootj=sqrt(j);
SET sumroot=sumroot+rooti+rootj;
SET j=j+1;
END WHILE;
SET i=i+1;
END WHILE;
By moving the calculation of the square root of i outside of the loop—as shown in Example 22-10—we substantially reduce the overhead of this loop.
Example 22-10. Moving unnecessary calculations out of a loop
WHILE (i<=1000) DO
SET rooti=sqrt(i);
SET j=1;
WHILE (j<=5000) DO
SET rootj=sqrt(j);
SET sumroot=sumroot+rootj+rooti;
SET j=j+1;
END WHILE;
SET i=i+1;
END WHILE;
Figure 22-5 shows the performance improvements achieved from moving the calculation of the square root of the i variable outside of the inner loop.
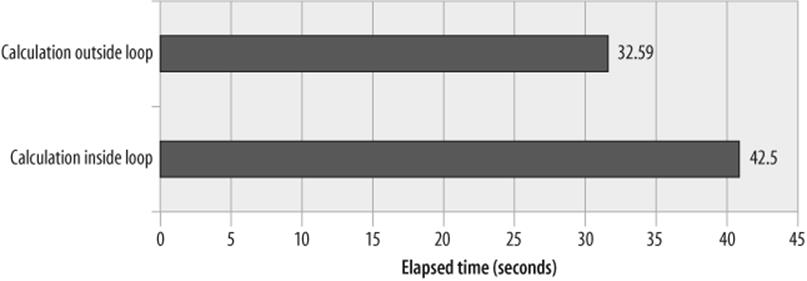
Figure 22-5. Performance improvements gained from removing unnecessary calculations within a loop
Tip
Ensure that all statements within a loop truly belong within the loop. Move any loop-invariant statements outside of the loop.
Use LEAVE or CONTINUE to Avoid Needless Processing
Just as it is important to remove all unnecessary processing from a loop, it is equally important to leave the loop when you are finished. Again, this seems obvious, but it is easy to write a fully functional loop that performs unnecessary iterations. When you look at your code, it's not always that obvious that the loop is inefficient.
Consider the loop shown in Example 22-11: this is a variation on the loop used in Example 22-1 to count prime numbers. This loop is functionally correct, but inefficient. On line 2 we cycle through all numbers less than the given number looking for divisors. If we find a divisor (line 4), we know that the number is not a prime number. However, in Example 22-11, we continue to check each number even though we have already found the first divisor. This is unnecessary, since once we find even a single divisor, we know that the number is not prime—there is no need to look for further divisors.
Example 22-11. Loop that iterates unnecessarily
1 divisor_loop:
2 WHILE (j<i) do /* Look for a divisor */
3
4 IF (MOD(i,j)=0) THEN
5 SET isprime=0; /* This number is not prime*/
6 END IF;
7 SET j=j+1;
8 END WHILE ;
Example 22-12 shows the same loop, but with a LEAVE statement added that terminates the loop once a divisor is found.
Example 22-12. Loop with a LEAVE statement to avoid unnecessary iterations
divisor_loop:
WHILE (j<i) do /* Look for a divisor */
IF (MOD(i,j)=0) THEN
SET isprime=0; /* This number is not prime*/
LEAVE divisor_loop; /* No need to keep checking*/
END IF;
SET j=j+1;
END WHILE ;
Although the LEAVE statement terminates the loop and reduces the elapsed time for the stored procedure, it may decrease readability of the code because the loop now has two sections that determine if the loop continues—the WHILE clause condition and the LEAVE statement. Constructing a loop with multiple exit points makes the code harder to understand and maintain.
It would be equally valid in this case to modify the WHILE clause so that the loop ceases its repetitions once it has determined that the number is not a prime, as shown in Example 22-13.
Example 22-13. Modifying the WHILE condition to avoid unnecessary iterations
divisor_loop:
WHILE (j<i AND isprime=1) do /* Look for a divisor */
IF (MOD(i,j)=0) then
SET isprime=0; /* This number is not prime*/
END IF;
SET j=j+1;
END WHILE ;
Figure 22-6 shows the improvements gained in our prime number search when we add the LEAVE statement or modify the WHILE clause. Modifying the WHILE clause leads to a comparable performance increase without reducing the readability of the loop.
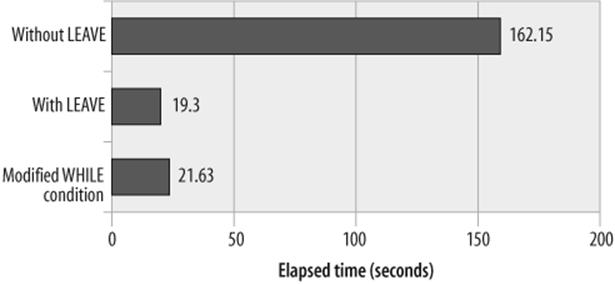
Figure 22-6. Effect of using LEAVE or modifying WHILE clause to avoid unnecessary iterations
Tip
Make sure that your loops terminate when all of the work has been done, either by ensuring that the loop continuation expression is comprehensive or—if necessary—by using a LEAVE statement to terminate when appropriate.
IF and CASE Statements
Another category of statement that is highly amenable to code optimization is the conditional statement category—IF and CASE statements. This is especially true if these statements are called repetitively within a loop. The essence of optimizing conditional statements like IF and CASE is to reduce the number of comparisons that are performed. You can do this by:
§ Testing for the more likely matches earlier in the IF or CASE statement
§ Stopping the comparison process as early as possible
Test for the Most Likely Conditions First
When constructing IF and CASE statements, try to minimize the number of comparisons that these statements are likely to make by testing for the most likely scenarios first. For instance, consider the IF statement shown in Example 22-14. This statement maintains counts of various percentages. Assuming that the input data is evenly distributed, the first IF condition (percentage>95) will match about once in every 20 executions. On the other hand, the final condition will match in three out of four executions. So this means that for 75% of the cases, all four comparisons will need to be evaluated.
Example 22-14. Poorly constructed IF statement
IF (percentage>95) THEN
SET Above95=Above95+1;
ELSEIF (percentage >=90) THEN
SET Range90to95=Range90to95+1;
ELSEIF (percentage >=75) THEN
SET Range75to89=Range75to89+1;
ELSE
SET LessThan75=LessThan75+1;
END IF;
Example 22-15 shows a more efficiently formed IF statement. In this variation, the first condition will evaluate as true in the majority of executions and no further comparisons will be necessary.
Example 22-15. Optimized IF statement
IF (percentage<75) THEN
SET LessThan75=LessThan75+1;
ELSEIF (percentage >=75 AND percentage<90) THEN
SET Range75to89=Range75to89+1;
ELSEIF (percentage >=90 and percentage <=95) THEN
SET Range90to95=Range90to95+1;
ELSE
SET Above95=Above95+1;
END IF;
Figure 22-7 shows the performance improvement gained by reordering the IF statement so that the most commonly satisfied condition is evaluated first.
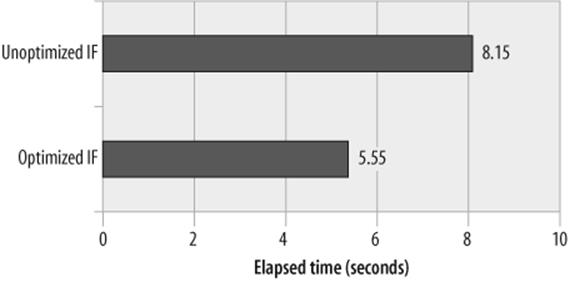
Figure 22-7. Effect of optimizing an IF statement by reordering comparisons
Tip
If an IF statement is to be executed repeatedly, placing the most commonly satisfied condition earlier in the IF structure may optimize performance.
Avoid Unnecessary Comparisons
Sometimes an IF or CASE statement will be constructed that has some kind of common condition in each comparison clause. For instance, in Example 22-16, each of the expressions in the IF statement includes an employee_status='U' condition. Even if the employee_status is not equal to "U", each of these comparisons will need to be evaluated—adding some processing overhead.
Example 22-16. IF statement with common condition in each expression
IF (employee_status='U' AND employee_salary>150000) THEN
SET categoryA=categoryA+1;
ELSEIF (employee_status='U' AND employee_salary>100000) THEN
SET categoryB=categoryB+1;
ELSEIF (employee_status='U' AND employee_salary<50000) THEN
SET categoryC=categoryC+1;
ELSEIF (employee_status='U') THEN
SET categoryD=categoryD+1;
END IF;
Example 22-17 shows a more optimized IF structure. In this example, the employee_status is checked first and then—only if employee_status='U'—are the additional comparisons are evaluated. Figure 22-8 demonstrates the optimization.
Example 22-17. Nested IF statement to avoid redundant comparisons
IF (employee_status='U') THEN
IF (employee_salary>150000) THEN
SET categoryA=categoryA+1;
ELSEIF (employee_salary>100000) THEN
SET categoryB=categoryB+1;
ELSEIF (employee_salary<50000) THEN
SET categoryC=categoryC+1;
ELSE
SET categoryD=categoryD+1;
END IF;
END IF;
To be honest, under most circumstances, tuning IF statements will not greatly improve the performance of your code. The overhead of SQL processing will usually dominate overall execution time. Consequently, we suggest that when it comes to conditional statements, you should prioritize writing readable and maintainable code. If a particular IF statement becomes a bottleneck, then you should consider a rewrite that will improve performance even at the expense of maintainability.
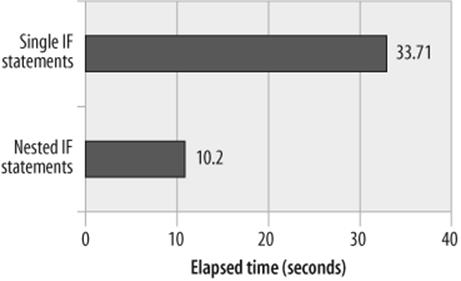
Figure 22-8. Effect of nesting an IF statement to eliminate redundant comparisons
Tip
If your IF or CASE statement contains compound expressions with redundant comparisons, consider nesting multiple IF or CASE statements to avoid redundant processing.
CASE Versus IF
We wondered if there was any performance difference between a CASE statement and an equivalent IF statement. We thought that CASE might be more optimal for comparing a variable against a range of set values, so we speculated that this statement:
CASE customer_code
WHEN 1 THEN
SET process_flag=7;
WHEN 2 THEN
SET process_flag=9;
WHEN 3 THEN
SET process_flag=2;
ELSE
SET process_flag=0;
END CASE;
might be more efficient than the equivalent IF statement:
IF customer_code= 1 THEN
SET process_flag=7;
ELSEIF customer_code= 2 THEN
SET process_flag=9;
ELSEIF customer_code=3 THEN
SET process_flag=2;
ELSE
SET process_flag=0;
END IF;
In fact, the opposite turned out to be true. The IF statement is roughly 15% faster than the equivalent CASE statement—presumably this is the result of a more efficient internal algorithm for IF in the MySQL code.
As noted earlier, we advise you to structure your stored program's statements primarily for readability and maintainability, since it is almost always the elapsed time of SQL statements that dominates performance. However, if performance is critical, you may want to make a habit of using IFstatements rather than CASE statements in your code.
Recursion
A recursive routine is one that invokes itself. Recursive routines often offer elegant solutions to complex programming problems, but they also tend to consume large amounts of memory. They are also likely to be less efficient and less scalable than implementations based on iterative execution.
Most recursive algorithms can be reformulated using nonrecursive techniques involving iteration. Where possible, we should give preference to the more efficient iterative algorithm.
For example, in Example 22-18, the stored procedure uses recursion to calculate the Nth element of the Fibonacci sequence, in which each element in the sequence is the sum of the previous two numbers.
Example 22-18. Recursive implementation of the Fibonacci algorithm
CREATE PROCEDURE rec_fib(n INT,OUT out_fib INT)
BEGIN
DECLARE n_1 INT;
DECLARE n_2 INT;
IF (n=0) THEN
SET out_fib=0;
ELSEIF (n=1) then
SET out_fib=1;
ELSE
CALL rec_fib(n-1,n_1);
CALL rec_fib(n-2,n_2);
SET out_fib=(n_1 + n_2);
END IF;
END
Example 22-19 shows a nonrecursive implementation that returns the Nth element of the Fibonacci sequence.
Example 22-19. Nonrecursive implementation of the Fibonacci sequence
CREATE PROCEDURE nonrec_fib(n INT,OUT out_fib INT)
BEGIN
DECLARE m INT default 0;
DECLARE k INT DEFAULT 1;
DECLARE i INT;
DECLARE tmp INT;
SET m=0;
SET k=1;
SET i=1;
WHILE (i<=n) DO
SET tmp=m+k;
SET m=k;
SET k=tmp;
SET i=i+1;
END WHILE;
SET out_fib=m;
END
Figure 22-9 compares the relative performance of the recursive and nonrecursive implementations. Not only is the recursive algorithm less efficient for almost any given input value, it also degrades rapidly as the number of recursions increases (which is, in turn, dependent on which element of the Fibonacci sequence is requested). As well as being inherently a less efficient algorithm, each recursion requires MySQL to create the context for a new stored program (or function) invocation. As a result, recursive algorithms tend to waste memory as well as being slower than their iterative alternatives.
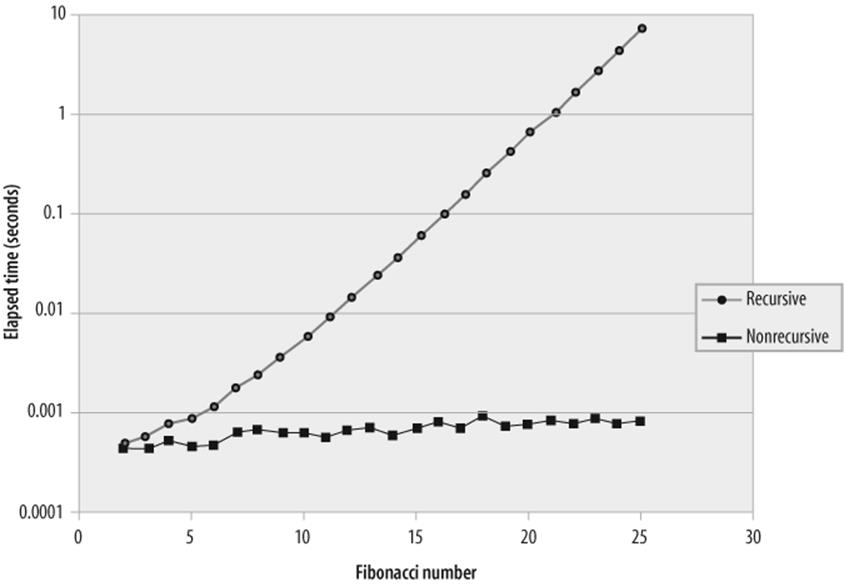
Figure 22-9. Performance of recursive and nonrecursive calculations of Fibonacci numbers (note logarithmic scale)
The maximum recursion depth—the number of times a procedure can call itself—is controlled by the MySQL configuration parameter max_sp_recursion_depth. The default value of 0 disables all recursive procedures. A procedure that attempts to recurse beyond the value ofmax_sp_recursion_depth will encounter a runtime error:
mysql> CALL rec_fib(10,@x);
ERROR 1456 (HY000): Recursive limit 0 (as set by the max_sp_recursion_depth variable)
was exceeded for routine rec_fib
Recursion in stored functions is not allowed. An attempt to recurse in a function will always generate a runtime error:
mysql> SELECT rec_fib(10);
ERROR 1424 (HY000): Recursive stored functions and triggers are not allowed.
Tip
Recursive solutions rarely perform as efficiently as their nonrecursive alternatives.
Cursors
When you need to retrieve only a single row from a SELECT statement, using the INTO clause is far easier than declaring, opening, fetching from, and closing a cursor. But does the INTO clause generate some additional work for MySQL or could the INTO clause be more efficient than a cursor? In other words, which of the two stored programs shown in Example 22-20 is more efficient?
Example 22-20. Two equivalent stored programs, one using INTO and the other using a cursor
CREATE PROCEDURE using_into
( p_customer_id INT,OUT p_customer_name VARCHAR(30))
READS SQL DATA
BEGIN
SELECT customer_name
INTO p_customer_name
FROM customers
WHERE customer_id=p_customer_id;
END;
CREATE PROCEDURE using_cursor
(p_customer_id INT,OUT p_customer_name VARCHAR(30))
READS SQL DATA
BEGIN
DECLARE cust_csr CURSOR FOR
SELECT customer_name
FROM customers
WHERE customer_id=p_customer_id;
OPEN cust_csr;
FETCH cust_csr INTO p_customer_name;
CLOSE cust_csr;
END;
Certainly, it is simpler to code an INTO statement than to code DECLARE, OPEN, FETCH, and CLOSE statements, and we will probably only bother to do this—when we know that the SQL returns only one row—if there is a specific performance advantage. As it turns out, there is actually a slight performance penalty for using an explicit cursor. Figure 22-10 shows the relative performance of each of the stored programs in Example 22-20—over 11,000 executions, the INTO-based stored program was approximately 15% faster than the stored program that used an explicit cursor.
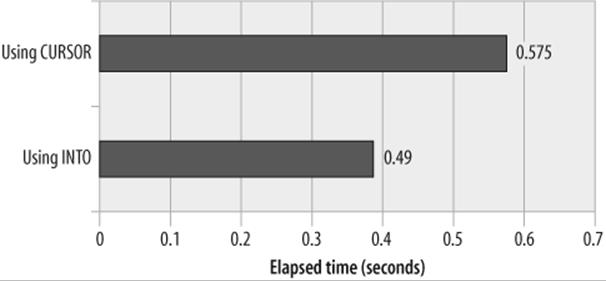
Figure 22-10. Relative performance of INTO versus CURSOR fetch
Tip
If you know that a SQL statement will return only one row, then a SELECT ... INTO statement will be slightly faster than declaring, opening, and fetching from a cursor.
Trigger Overhead
Every database trigger is associated with a specific DML operation (INSERT, UPDATE, or DELETE) on a specific table—the trigger code will execute whenever that DML operation occurs on that table. Furthermore, all MySQL 5.0 triggers are of the FOR EACH ROW type, which means that the trigger code will execute once for each row affected by the DML operation. Given that a single DML operation might potentially affect thousands of rows, should we be concerned that our triggers might have a negative effect on DML performance? Absolutely!
For all of the reasons outlined previously, triggers can significantly increase the amount of time taken to execute DML operations and can have a detrimental effect on overall application performance if trigger overhead is not carefully managed.
The overhead of a trigger itself is significant, though not unmanageable. For instance, consider the trigger shown in Example 22-21; this trivial trigger serves no purpose, but it allows us to measure the overhead of a trigger that does virtually nothing.
Example 22-21. "Trivial" trigger
CREATE TRIGGER sales_bi_trg
BEFORE INSERT
ON sales
FOR EACH ROW
SET @x=NEW.sale_value;
When we implemented this trivial trigger, the time taken to insert 100,000 sales rows increased from 8.84 seconds to 12.9 seconds—an increase of about 45%. So even the simplest of triggers adds a significant—though bearable—overhead.
But what about a complex trigger? In Chapter 11, we created a set of triggers to maintain a sales summary table. One of the triggers we created is the BEFORE INSERT trigger, shown in Example 22-22.
Example 22-22. A more complex trigger
CREATE TRIGGER sales_bi_trg
BEFORE INSERT ON sales
FOR EACH ROW
BEGIN
DECLARE row_count INTEGER;
SELECT COUNT(*)
INTO row_count
FROM customer_sales_totals
WHERE customer_id=NEW.customer_id;
IF row_count > 0 THEN
UPDATE customer_sales_totals
SET sale_value=sale_value+NEW.sale_value
WHERE customer_id=NEW.customer_id;
ELSE
INSERT INTO customer_sales_totals
(customer_id,sale_value)
VALUES(NEW.customer_id,NEW.sale_value);
END IF;
END
This trigger checks to see if there is an existing row for the customer in the summary table and, if there is, updates that row; otherwise, it adds a new row. Since we are performing a single additional update or insert for every row inserted, we do expect an increase in our INSERT overhead. However, we might not expect that the time taken to insert 10,000 rows increases from 0.722 second to 64.36 seconds—almost 100 times more!
The problem with our trigger is obvious on reflection. The SQL that checks for a matching row is not supported by an index, so for every row inserted into sales, we are performing a full scan of customer_sales_totals. This is not a huge table, but these scans are performed for every row inserted, so the overhead adds up rapidly. Furthermore, the UPDATE statement is also not supported by an index, so a second scan of the customer_sales_totals table is performed to support the UPDATE.
The solution is to create an index on customer_sales_totals.customer_id, as shown in Example 22-23.
Example 22-23. Index to support our trigger
CREATE UNIQUE INDEX customer_sales_totals_cust_id
ON customer_sales_totals(customer_id)
Once the index is created, the performance improves: time to insert 10,000 rows is reduced to about 4.26 seconds, which—although much slower than the performance we achieved without a trigger—is certainly more acceptable than 64 seconds. Performance variations are shown in Figure 22-11.
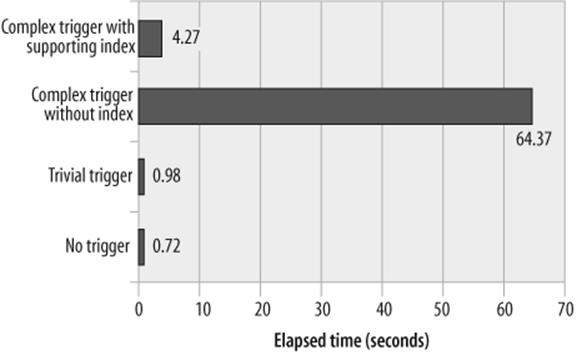
Figure 22-11. Trigger performance variations
The lesson here is this: since the trigger code will execute once for every row affected by a DML statement, the trigger can easily become the most significant factor in DML performance. Code inside the trigger body needs to be as lightweight as possible and—in particular—any SQL statements in the trigger should be supported by indexes whenever possible.
Conclusion
In this chapter we looked at the particular performance characteristics of stored programs and offered advice about when to use stored program logic in place of "straight" SQL and how to optimize the algorithms we write in the MySQL stored program language.
As we have emphasized repeatedly, the performance of most stored programs will depend primarily on the performance of the SQL statements found within the stored program. Before optimizing stored program statements, make sure that all of the SQL statements are fully optimized.
The MySQL stored program language is currently slower than most alternative procedural languages—such as Java and PHP—when it comes to number crunching. In general, we are better off implementing computationally expensive code in one of these other languages.
Stored programs can, however, really shine from a performance standpoint when a relatively small output is calculated from a large number of database rows. This is because other languages must transfer these rows across the network, while stored program execution occurs inside the database, minimizing network traffic.
Sometimes stored programs can also be used as an alternative to hard-to-optimize SQL. This will typically be true when the SQL language forces we to repetitively fetch the same data, or when the SQL logic is enormously complex and we need to "divide and conquer." However, a stored program solution will typically take more programming investment than a SQL equivalent, so we must be sure that we are obtaining the improvements we expect.
The optimization of stored program code follows the same general principles that are true for other languages. In particular:
§ Optimize loop processing: ensure that no unnecessary statements occur within a loop; exit the loop as soon as you are logically able to do so.
§ Reduce the number of comparisons by testing for the most likely match first, and nest IF or CASE statements when necessary to eliminate unnecessary comparisons.
§ Avoid recursive procedures.
Because MySQL triggers execute once for each row affected by a DML statement, the effect of any unoptimized statements in a trigger will be magnified during bulk DML operations. Trigger code needs to be very carefully optimized—expensive SQL statements have no place in triggers.