ZooKeeper (2013)
Part II. Programming with ZooKeeper
Chapter 5. Dealing with Failure
Life would be so much easier if failures never happened. Of course, without failures, much of the need for ZooKeeper would also go away. To effectively use ZooKeeper it is important to understand the kinds of failures that happen and how to handle them.
There are three main places where failures occur: in the ZooKeeper service itself, the network, and an application process. Recovery depends on finding which one of these is the locus of the failure, but unfortunately, doing so isn’t always easy.
Imagine the simple configuration shown in Figure 5-1. Just two processes make up the application, and three servers make up the ZooKeeper service. The processes will connect to one of the servers at random and so may end up connecting to different servers. The servers use internal protocols to keep the state in sync across clients and present a consistent view to clients.
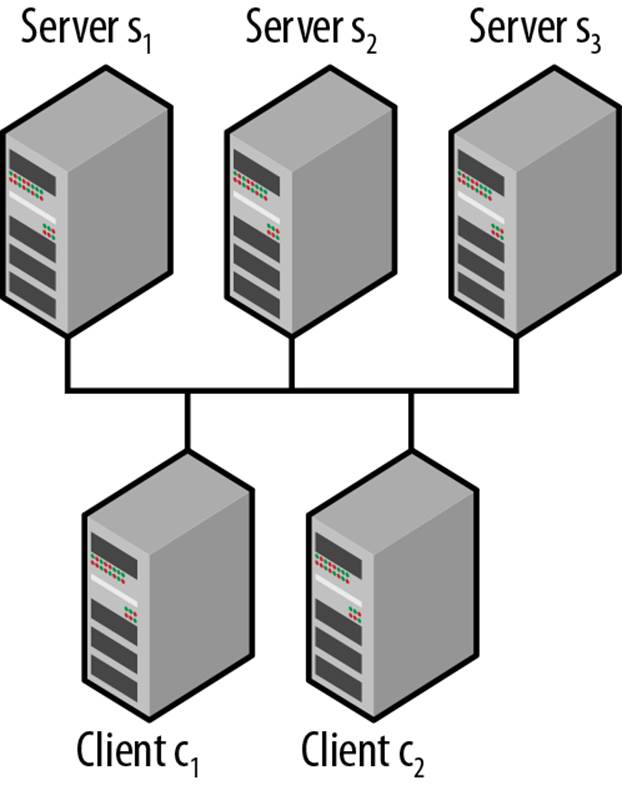
Figure 5-1. Simple distributed application diagram
Figure 5-2 shows some of the failures that can happen in the various components of the system. It’s interesting to examine how an application can distinguish between the different types of failures. For example, if the network is down, how can c1 determine the difference between a network failure and a ZooKeeper service outage? If ZooKeeper s1 is the only server that is down, the other ZooKeeper servers will be online, so if there is no network problem, c1 will be able to connect to one of the other servers. However, if c1 cannot connect to any of the servers, it may be because the service is unavailable (perhaps because a majority of the servers are down) or because there is a network failure.
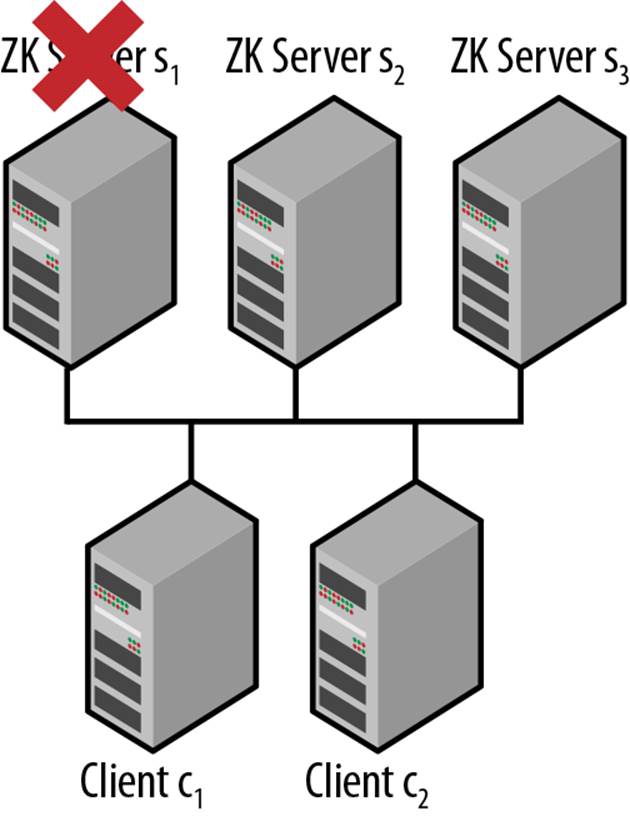
Figure 5-2. Simple distributed application diagram with failures
This example shows that it isn’t always possible to handle failures based on the component in which they occur, so instead ZooKeeper presents its view of the system and developers work within that view.
If we examine Figure 5-2 from the perspective of c2, we see that a network failure that lasts long enough will cause the session between c1 and ZooKeeper to expire. Thus, even though c1 is actually still alive, ZooKeeper will declare c1 to be dead because c1 cannot connect to any server. If c1is watching ephemeral znodes from c1, it will be informed of the death of c1. So c2 will know for sure that c1 is dead because ZooKeeper will have told it so, even though in this scenario c1 is still alive.
In this scenario, c1 cannot talk to the ZooKeeper service. It knows it is alive, but it cannot be sure whether or not ZooKeeper has declared it dead, so it must assume the worst. If c1 takes an action that a dead process should not take (changing external resources, for example), it can corrupt the system. If c1 is ever able to reconnect with ZooKeeper and finds out that its session is no longer active, it needs to make sure to stay consistent with the rest of the system and terminate or execute restart logic to appear as a new instance of the process.
SECOND-GUESSING ZOOKEEPER
It may be tempting to second-guess ZooKeeper. It has been done before. Unfortunately, the uncertainty problem is fundamental, as we pointed out in the introduction to this chapter. The second-guesser may indeed guess correctly when ZooKeeper is wrong, but she may also guess incorrectly when ZooKeeper is right. System design is simpler and failures are easier to understand and diagnose if ZooKeeper is the designated source of truth.
Rather than trying to determine causes of failures, ZooKeeper exposes two classes of failures: recoverable and unrecoverable. Recoverable failures are transient and should be considered relatively normal—things happen. Brief network hiccups and server failures can cause these kinds of failures. Developers should write their code so that their applications keep running in spite of these failures.
Unrecoverable failures are much more problematic. These kinds of failures cause the ZooKeeper handle to become inoperable. The easiest and most common way to deal with this kind of failure is to exit the application. Examples of causes of this class of failure are session timeouts, network outages for longer than the session timeout, and authentication failures.
Recoverable Failures
ZooKeeper presents a consistent state to all of the client processes that are using it. When a client gets a response from ZooKeeper, the client can be confident that the response will be consistent with all other responses that it or any other client receives. There are times when a ZooKeeper client library loses its connection with the ZooKeeper service and can no longer provide information that it can guarantee to be consistent. When a ZooKeeper client library finds itself in this situation, it uses the Disconnected event and the ConnectionLossException to express its lack of knowledge about the state of the system.
Of course, the ZooKeeper client library vigorously tries to extricate itself from this situation. It will continuously try to reconnect to another ZooKeeper server until it is finally able to reestablish the session. Once the session is reestablished, ZooKeeper will generate a SyncConnected event and start processing requests. ZooKeeper will also reregister any watches that were previously registered and generate watch events for any changes that happened during the disconnection.
A typical cause of Disconnected events and ConnectionLossExceptions is a ZooKeeper server failure. Figure 5-3 shows an example of such a failure. In this example a client is connected to server s2, which is one of two active ZooKeeper servers. When s2 fails, the client’s Watcherobjects will get a Disconnected event and any pending requests will return with a ConnectionLossException. The ZooKeeper service itself is fine because a majority of servers are still active, and the client will quickly reestablish its session with a new server.
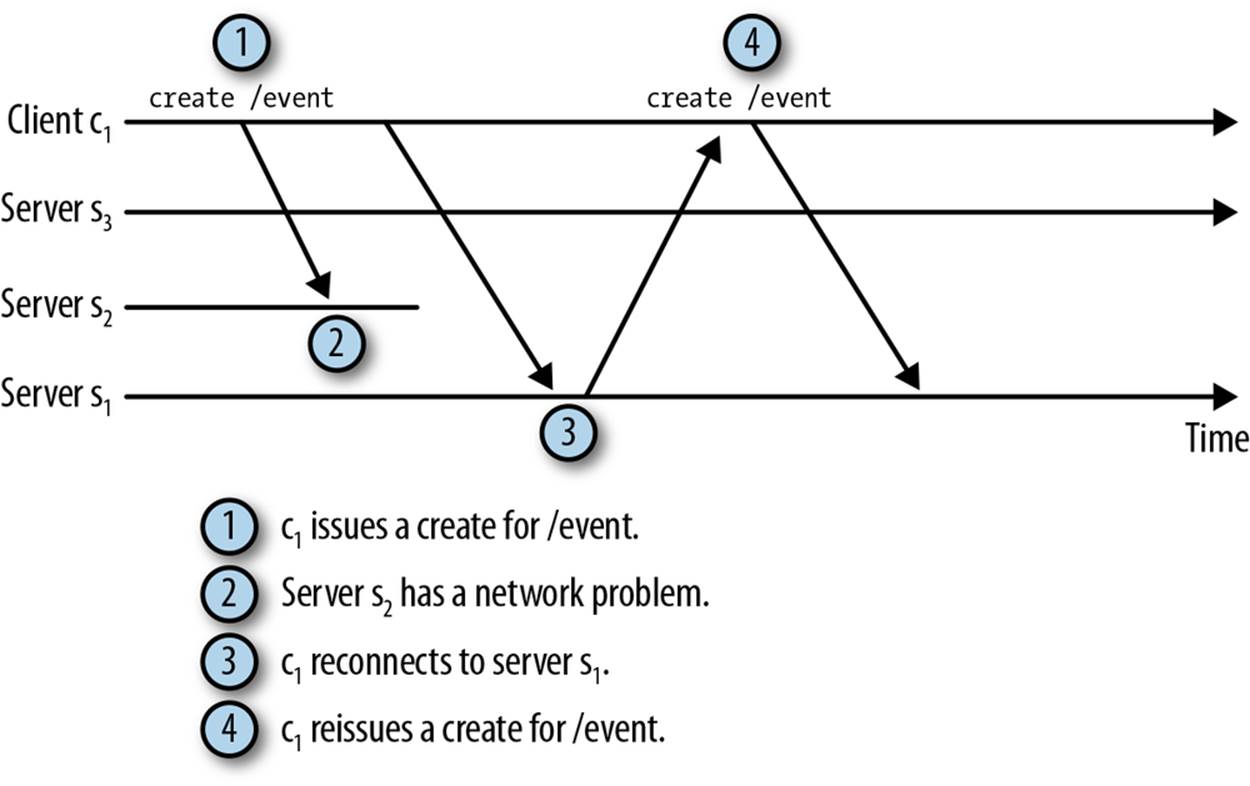
Figure 5-3. Connection loss example
If the client doesn’t have any pending requests, all this will take place with very little disruption to the client. Apart from a Disconnected event followed by a SyncConnected event, the client will not notice the change. If there are pending requests, however, the connection loss is much more disruptive.
If the client has a pending request outstanding, such as a create request that it just submitted, when the connection loss happens the client will get a ConnectionLossException for synchronous requests and a CONNECTIONLOSS return code for asynchronous requests. However, the client will not be able to tell from these exceptions or return codes whether or not the requests were processed. As we have seen, handling the connection loss complicates the code because the application code must figure out whether the requests actually completed. One very bad way of dealing with the complication of handling connection loss is to code for the simple case, then shut everything down and restart if a ConnectionLossException or CONNECTIONLOSS return code is received. Although this makes the code simpler, it turns what should be a minor disruption into a major system event.
To see why, let’s look at a system that is composed of 90 client processes connected to a ZooKeeper cluster of three servers. If the application is written using this simple but bad style and one of the ZooKeeper servers fails, 30 client processes will shut down and restart their sessions with ZooKeeper. To make matters worse, the session shutdown happens when the client processes are not connected to ZooKeeper, so their sessions will not get explicitly shut down and ZooKeeper will have to detect the failures based on the session timeouts. The end result is that a third of the application processes restart, and the restarts may be delayed because the new processes must wait for the locks held by the old sessions to expire. On the other hand, if the application is written to correctly handle connection loss, such scenarios will cause very little system disruption.
Developers must keep in mind that while a process is disconnected, it cannot receive updates from ZooKeeper. Though this may sound obvious, an important state change that a process may miss is the death of its session. Figure 5-4 shows an example of such a scenario. Client c1, which happens to be a leader, loses its connection at time t1, but it doesn’t find out that it has been declared dead until time t4. In the meantime, its session expires at time t2, and at time t3 another process becomes the leader. From time t2 to time t4 the old leader does not know that it has been declared dead and another leader has taken control.
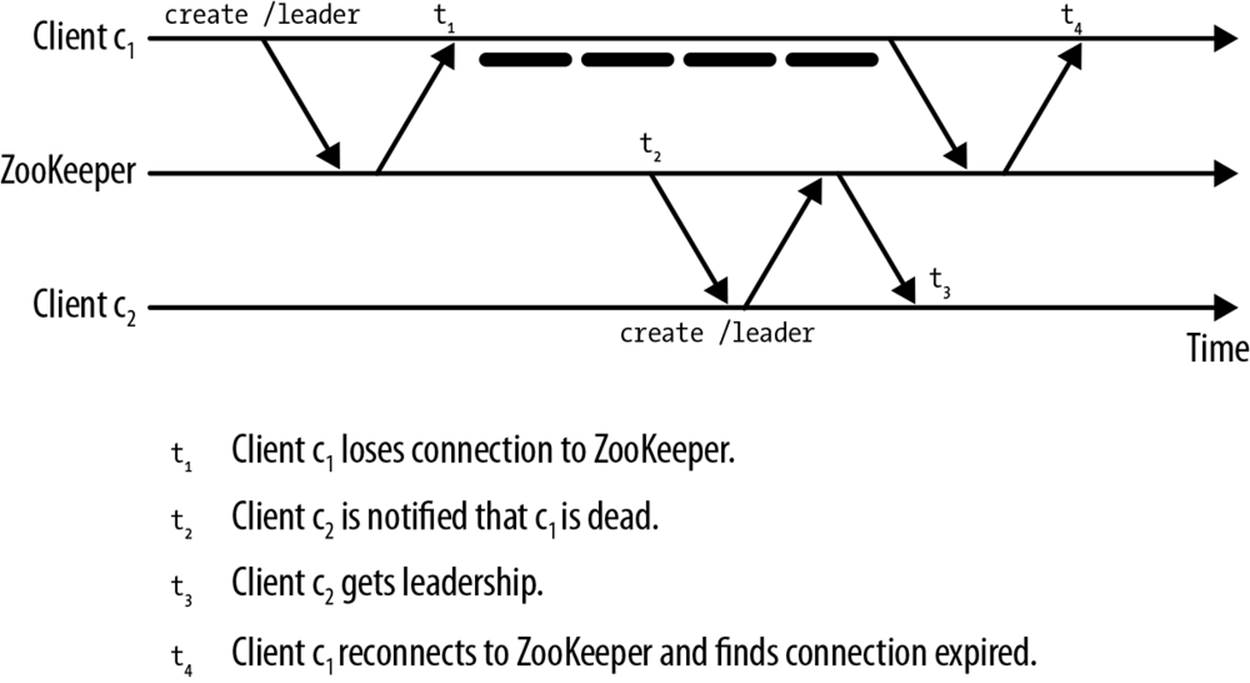
Figure 5-4. Revenge of the living dead
If the developer is not careful, the old leader will continue to act as a leader and may take actions that conflict with those of the new leader. For this reason, when a process receives a Disconnected event, the process should suspend actions taken as a leader until it reconnects. Normally this reconnect happens very quickly.
If the client is disconnected for an extended period of time, the process may choose to close the session. Of course, if the client is disconnected, closing the session will not make ZooKeeper close sooner. The ZooKeeper service still waits for the session expiration time to pass before declaring the session expired.
RIDICULOUSLY LONG DELAY TO EXPIRE
When disconnects do happen, the common case should be a very quick reconnect to another server, but an extended network outage may introduce a long delay before a client can reconnect to the ZooKeeper service. Some developers wonder why the ZooKeeper client library doesn’t simply decide at some point (perhaps twice the session timeout) that enough is enough and kill the session itself.
There are two answers to this. First, ZooKeeper leaves this kind of policy decision up to the developer. Developers can easily implement such a policy by closing the handle themselves. Second, when a ZooKeeper ensemble goes down, time freezes. Thus, when the ensemble is brought back up, session timeouts are restarted. If processes using ZooKeeper hang in there, they may find out that the long timeout was due to an extended ensemble failure that has recovered and pick right up where they left off without any additional startup delay.
The Exists Watch and the Disconnected Event
To make session disconnection and reestablishment a little more seamless, the ZooKeeper client library will reestablish any existing watches on the new server. When the client library connects to a ZooKeeper server, it will send the list of outstanding watches and the last zxid (the last state timestamp) it has seen. The server will go through the watches and check the modification timestamps of the znodes that correspond to them. If any watched znodes have a modification timestamp later than the last zxid seen, the server will trigger the watch.
This logic works perfectly for every ZooKeeper operation except exists. The exists operation is different from all other operations because it can set a watch on a znode that does not exist. If we look closely at the watch registration logic in the previous paragraph, we see that there is a corner case in which we can miss a watch event.
Figure 5-5 illustrates the corner case that causes us to miss the creation event of a watched znode. In this example, the client is watching for the creation of /event. However, just as the /event is created by another client, the watching client loses its connection to ZooKeeper. During this time the other client deletes /event, so when the watching client reconnects to ZooKeeper and reregisters its watch, the ZooKeeper server no longer has the /event znode. Thus, when it processes the registered watches and sees the watch for /event, and sees that there is no node called/event, it simply reregisters the watch, causing the client to miss the creation event for /event. Because of this corner case, you should try to avoid watching for the creation event of a znode. If you do watch for a creation event it should be for a long-lived znode; otherwise, this corner case can bite you.
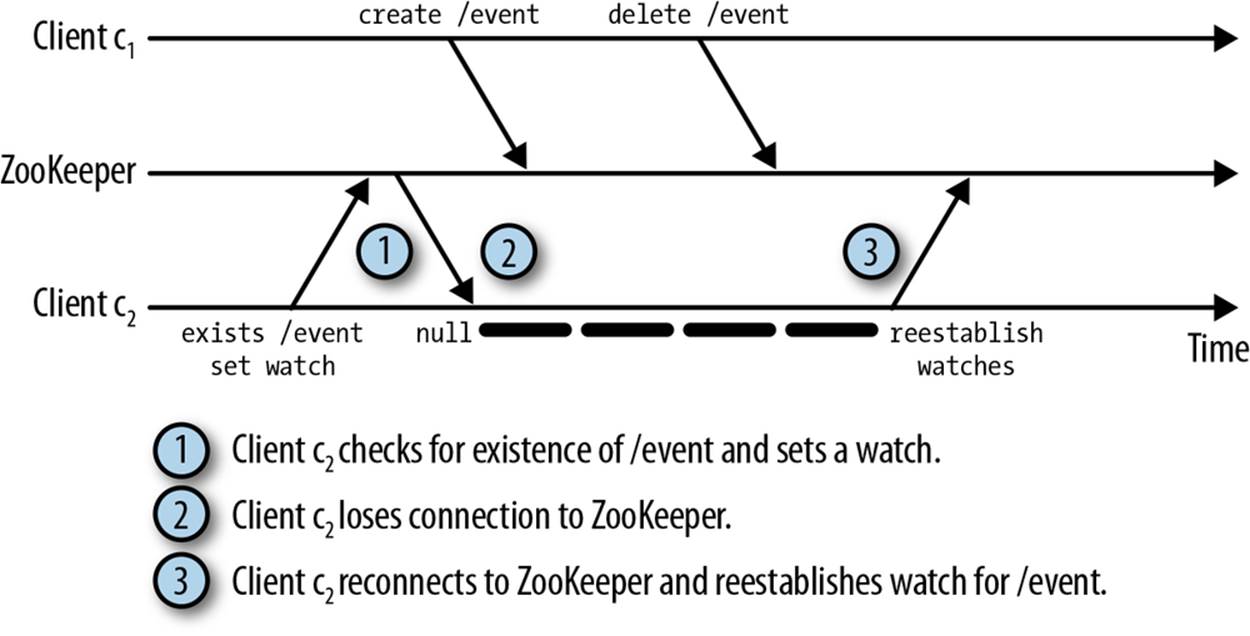
Figure 5-5. Notification corner case
HAZARDS OF AUTOMATIC DISCONNECT HANDLING
There are ZooKeeper wrapper libraries that will automatically handle connection loss failures for you by simply reissuing commands. In some cases this is perfectly acceptable, but other cases may result in errors. For example, if the znode /leader is used to establish leadership and your process issues a create for /leader that results in a connection loss, a blind retry of thecreate will cause the second create to fail because /leader already exists, so the process will assume that another process has leadership. Of course, you can recognize and handle this situation if you are aware of this case and understand how the wrapper library works. Some libraries are much more sophisticated, so if you do use one of these libraries, it is good to have an understanding of ZooKeeper and a strong understanding of the guarantee that the library is providing you.
Unrecoverable Failures
Occasionally, such bad things happen that a session cannot be recovered and must be closed. The most common reason for this is that the session expires. Another reason is that an authenticated session can no longer authenticate itself to the server. In both cases, ZooKeeper throws away the session state.
The clearest example of this lost state is the ephemeral znodes that get deleted when a session is closed. Internally, ZooKeeper keeps a less visible state that is also discarded when a session is closed.
An unrecoverable failure happens when the client fails to provide proper credentials to authenticate the session, or when it reconnects to an expired session after a Disconnected event. The client library does not determine that a session has failed on its own—as we saw in Figure 5-4, the old client did not figure out that it was disconnected until time t4, long after it was declared dead by the rest of the system.
The easiest way to deal with unrecoverable failures is to terminate the process and restart. This allows the process to come back up and reinitialize its state with a new session. If the process is going to keep running, it must clear out any internal application process state associated with the old session and reinitialize with a new one.
HAZARDS OF AUTOMATIC RECOVERY FROM UNRECOVERABLE FAILURES
It is tempting to automatically recover from unrecoverable failures by simply re-creating a new ZooKeeper handle under the covers. In fact, that is exactly what early ZooKeeper implementations did, but early users noted that this caused problems. A process that thought it was a leader could lose its session, but before it could notify its other management threads that it was no longer the leader, these threads were manipulating data using the new handle that should be accessed only by a leader. By making a one-to-one correspondence between a handle and a session, ZooKeeper now avoids this problem. There may be cases where automatic recovery is fine, especially in cases where a client is only reading data, but it is important that clients making changes to ZooKeeper data keep in mind the hazards of automatic recovery from session failures.
Leader Election and External Resources
ZooKeeper presents a consistent view of the system to all of its clients. As long as clients do all their interactions through ZooKeeper (as our examples have done), ZooKeeper will keep everything in sync. However, interactions with external devices will not be fully protected by ZooKeeper. A particularly problematic illustration of this lack of protection, and one that has often been observed in real settings, happens with overloaded host machines.
When the host machine on which a client process runs gets overloaded, it will start swapping, thrashing, or otherwise cause large delays in processes as they compete for overcommitted host resources. This affects the timeliness of interactions with ZooKeeper. On the one hand, ZooKeeper will not be able to send heartbeats in a timely manner to ZooKeeper servers, causing ZooKeeper to time out the session. On the other hand, scheduling of local threads on the host machine can cause unpredictable scheduling: an application thread may believe a session is active and a master lock is held even though the ZooKeeper thread will signal that the session has timed out when the thread has a chance to run.
Figure 5-6 shows a problematic issue with this timeline. In this example, the application uses ZooKeeper to ensure that only one master at a time has exclusive access to an external resource. This is a common method of centralizing management of the resource to ensure consistency. At the start of the timeline, Client c1 is the master and has exclusive access to the external resource. Events proceed as follows:
1. At t1, c1 becomes unresponsive due to overload and stops communicating with ZooKeeper. It has queued up changes to the external resource but has not yet received the CPU cycles to send them.
2. At t2, ZooKeeper declares c1’s session with ZooKeeper dead. At this time it also deletes all ephemeral nodes associated with c1’s sessions, including the ephemeral node that it created to become the master.
3. At t3, c2 becomes the master.
4. At t4, c2 changes the state of the external resource.
5. At t5, c1’s overload subsides and it sends its queued changes to the external resource.
6. At t6, c1 is able to reconnect to ZooKeeper, finds out that its session has expired, and relinquishes mastership. Unfortunately, the damage has been done: at time t5, changes were made to the external resource, resulting in corruption.
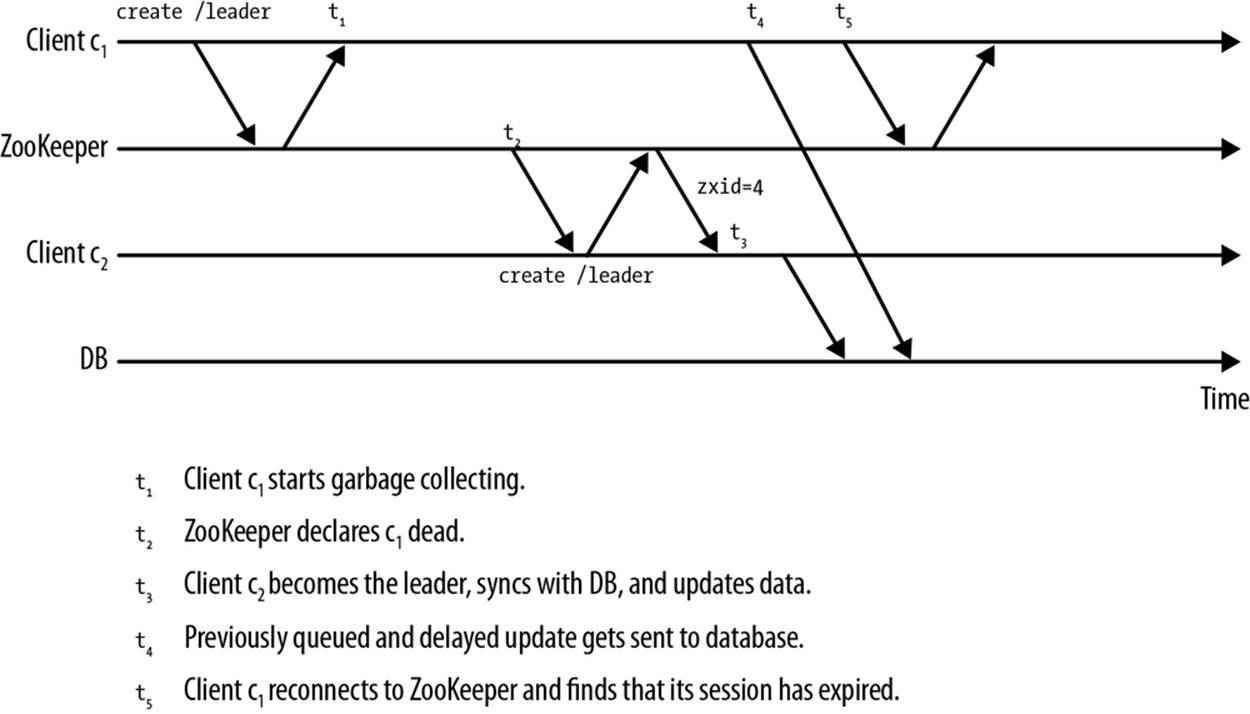
Figure 5-6. Coordinating external resources
Apache HBase, one of the early adopters of ZooKeeper, ran into this problem in the field. HBase has region servers that manage regions of a database table. The data is stored on a distributed file system, HDFS, and a region server has exclusive access to the files that correspond to its region.HBase ensures that only one region server is active at a time for a particular region by using leader election through ZooKeeper.
The region server is written in Java and has a large memory footprint. When available memory starts getting low, Java starts periodically running garbage collection to find memory no longer in use and free it for future allocations. Unfortunately, when collecting lots of memory, a long stop-the-world garbage collection cycle will occasionally run, pausing the process for extended periods of time. The HBase community found that sometimes this stop-the-world time period would be tens of seconds, which would cause ZooKeeper to consider the region server as dead. When the garbage collection finished and the region server continued processing, sometimes the first thing it would do would be to make changes to the distributed file system. This would end up corrupting data being managed by the new region server that had replaced the region server that had been given up for dead.
Similar problems can also result because of clock drift. In the HBase situation, time froze due to system overload. Sometimes with clock drift, time will slow down or even go backward, giving the client the impression that it is still safely within the timeout period and therefore still has mastership, even though its session has already expired with ZooKeeper.
There are a couple of approaches to addressing this problem. One approach is to make sure that you don’t run into overload and clock drift situations. Careful monitoring of system load can help detect possibly problematic situations, well-designed multithreaded applications can avoid inducing overloads, and clock synchronization programs can keep system clocks in sync.
Another approach is to extend the coordination data provided by ZooKeeper to the external devices, using a technique called fencing. This is used often in distributed systems to ensure exclusive access to a resource.
We will show an example of implementing simple fencing using a fencing token. As long as a client holds the most recent token, it can access the resource.
When we create a leader znode, we get back a Stat structure. One of the members of that structure is the czxid, which is the zxid that created the znode. The zxid is a unique, monotonically increasing sequence number. We can use the czxid as a fencing token.
When we make a request to the external resource, or when we connect to the external resource, we also supply the fencing token. If the external resource has received a request or connection with a higher fencing token, our request or connection will be rejected. This means that once a new master connects to an external resource and starts managing it, if an old master tries to do anything with the external resource, its requests will fail; it will be fenced off. Fencing has the nice benefit that it will work reliably even in the presence of system overload or clock drift.
Figure 5-7 shows how this technique solves the scenario of Figure 5-6. When c1 becomes the leader at time t1, the creation zxid of the /leader znode is 3 (in reality, the zxid would be a much larger number). It supplies the creation zxid as the fencing token to connect with the database. Later, when c1 becomes unresponsive due to overload, ZooKeeper declares c1 as failed and c2 becomes the new leader at time t2. c2 uses 4 as its fencing token because the /leader znode it created has a creation zxid of 4. At time t3, c2 starts making requests to the database using its fencing token. Now when c1’s request arrives at the database at time t4, it is rejected because its fencing token (3) is lower than the highest-seen fencing token (4), thus avoiding corruption.
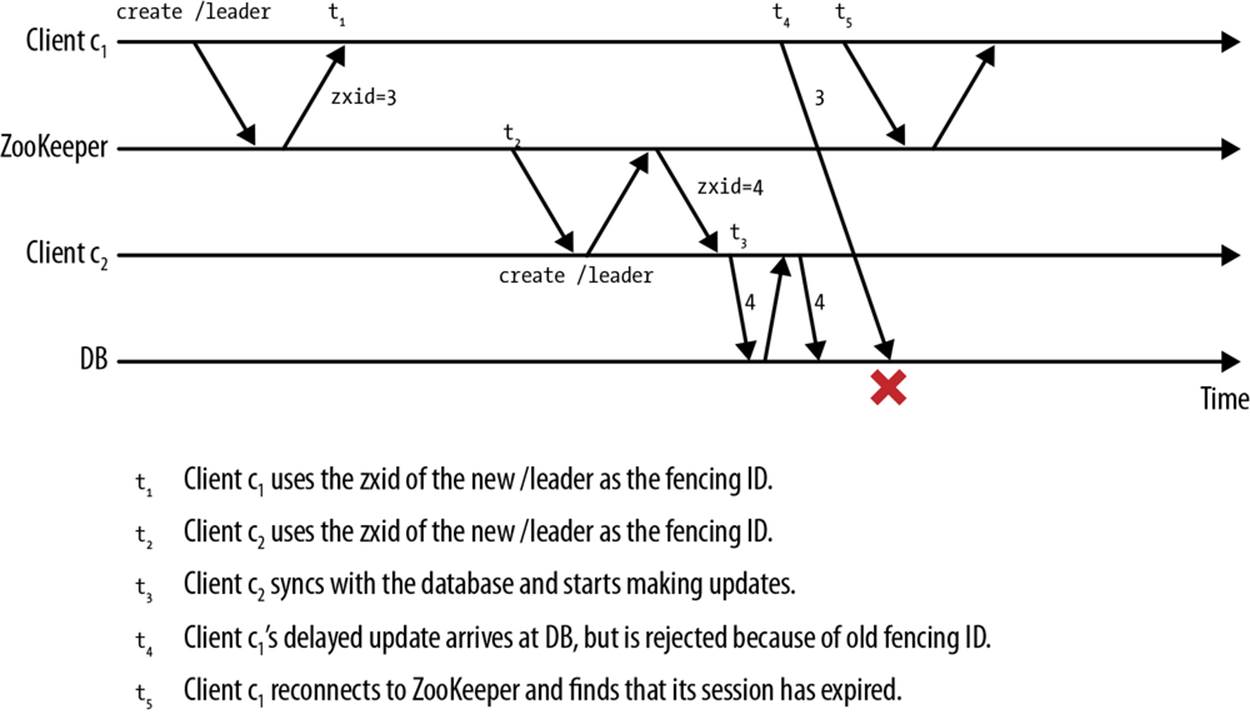
Figure 5-7. Fencing with ZooKeeper
Unfortunately, this fencing scheme requires changes to the protocol between the client and the resource. There must be room in the protocol to add the zxid, and the external resource needs a persistent store to track the latest zxid received.
Some external resources, such as some file servers, provide locking to partially address this problem of fencing. Unfortunately, such locking also has limitations. A leader that has been swapped out and declared dead by ZooKeeper may still hold a valid lock and therefore prevent a newly elected leader from acquiring the lock it needs to make progress. In such cases, it may be more practical to use the resource lock to determine leadership and have the leader create the /leader znode for informational purposes.
Takeaway Messages
Failures are a fact of life in any distributed system. ZooKeeper doesn’t make the failures go away, but it does provide a framework to handle them. To handle failures effectively, developers that use ZooKeeper need to react to the state change events and failure codes and exceptions thrown by ZooKeeper. Unfortunately, not all failures are handled in the same way in all cases. Developers must consider that there are times in the disconnected state, or when dealing with disconnected exceptions, that the process does not know what is happening in the rest of the system or even whether its own pending requests have executed. During periods of disconnection, processes cannot assume that the rest of the system still believes they are running, and even though the ZooKeeper client library will reconnect with ZooKeeper servers and reestablish watches, the process must still validate the results of any pending requests that may or may not have executed.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.