BDD in Action: Behavior-Driven Development for the whole software lifecycle (2015)
Part 4. Taking BDD Further
Chapter 12. BDD in the build process
This chapter covers
· Executable specifications and the automated build process
· The role of BDD in continuous integration (CI) and continuous delivery
· Using a CI server to publish living documentation
· Using a CI server to speed up your automated acceptance tests
The ultimate aim of BDD is to deliver more valuable software with less waste. But the business value of a new feature isn’t truly realized until it’s deployed into production for users to use. So if you want to deliver business value to users faster, you need to be able to deploy features quickly and efficiently.
Deploying a feature into production is typically a fairly complicated process. You need to build the application from source code and run the automated unit, integration, and acceptance tests. You need to bundle it up into a deployable package. You may do performance tests, code quality checks, and so forth. And you’ll typically deploy it into a test or UAT environment for testers and users to verify before deploying it into production.
User Acceptance Testing (UAT)
UAT is a dedicated environment many organizations use to allow end users to test a new version of an application before it goes into production.
Automation is the key to an efficient deployment process. Any automated steps in this process will be faster and more reliable than the manual equivalents. Indeed, fast deployment relies on minimizing the number and length of manual steps in the build/release cycle.
Manual testing is usually the largest and slowest of these steps, so test automation can have a significant impact on the time required for manual testing. The automated acceptance criteria and living documentation produced by BDD also help build up confidence in the quality of the application, letting testers focus on exploratory testing and spend less time on repetitive scenario-based testing.
In this chapter, we’ll take a closer look at the role BDD plays in the overall build and deployment lifecycle and how it can help streamline the automated delivery process.
12.1. Executable specifications should be part of an automated build
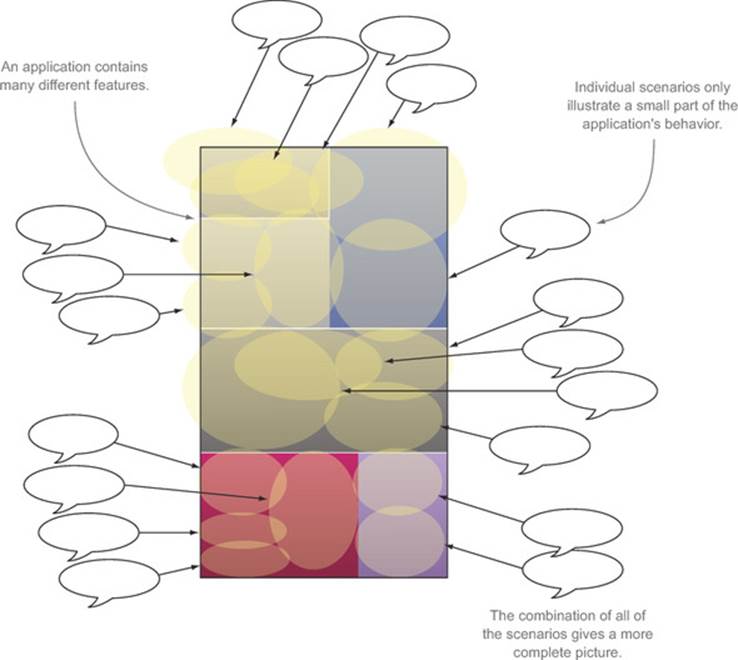
The executable specifications we’ve seen in the previous chapters, both for acceptance criteria and for lower-level technical specifications, aren’t designed to be run by hand on an ad hoc basis. Although it’s certainly convenient to be able to run individual tests from within an IDE, this isn’t their main purpose. Rather, they’re intended to be run automatically, as part of an automated build process. Individual acceptance criteria scenarios give a partial view of an application’s behavior. Only when they’re run together, as a comprehensive suite, can they give a full picture of the current state of the application (see figure 12.1).
Figure 12.1. Only by considering all of the acceptance criteria together can you get a global picture of how the application is expected to behave.
For this reason, executable specifications need to work well in the context of an automated build. Whether they’re implemented as low-level unit tests or end-to-end functional tests, they should respect a certain number of constraints. In particular,
· Each executable specification should be self-sufficient.
· Executable specifications should be stored in version control.
· You should be able to run the executable specifications from the command line, typically using a build script.
Let’s look at these constraints in more detail.
12.1.1. Each specification should be self-sufficient
Some teams try to organize their executable specifications into suites that need to be executed in a precise order. For example, an initial acceptance criterion might describe how to look up an item in an online catalog, a second might then illustrate how to purchase this item, and a third might illustrate requesting a refund of this same item.
This is generally not a good idea. Executable specifications shouldn’t depend on other specifications to prepare test data or to place the system in a particular state. Each specification should be able to run in isolation, and each specification should set up the test environment in the initial state it requires.
This is important for many reasons. If one of the acceptance criteria in a suite fails, the other acceptance criteria that depend on it will also fail, simply because the system isn’t in the initial state they expect. This results in misleading reports that record working features as being broken and makes it harder to troubleshoot real issues.
In addition, when they’re run as part of an automated build, executable specifications won’t necessarily be run in a guaranteed order. Tests may be run in parallel batches, or simultaneously on different machines. Even on a single machine, many test libraries don’t guarantee that tests will be executed in a predetermined order.
For these reasons, executable specifications shouldn’t make any assumptions about which other specifications have (or haven’t) been previously executed; if they need the system to be in a particular state, they should set it up themselves. Doing so results in more flexible and more robust test suites overall.
12.1.2. Executable specifications should be stored under version control
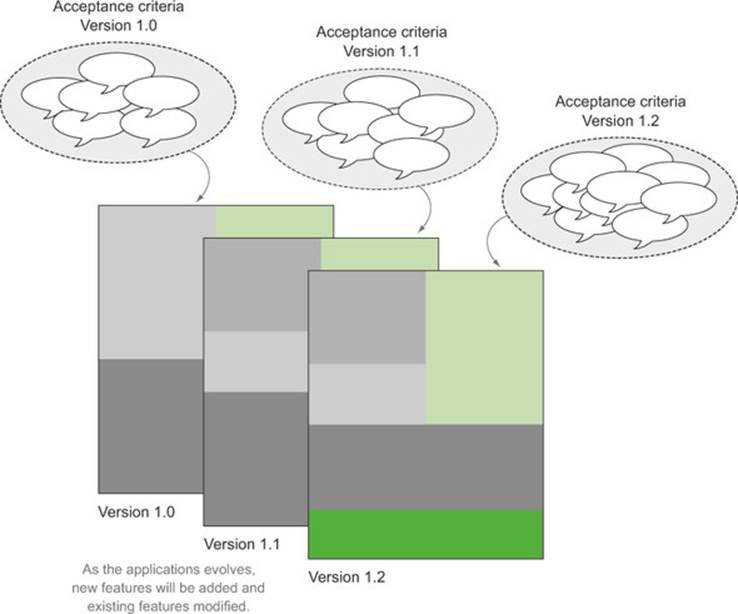
A given set of automated acceptance criteria is designed to run against a specific version of an application. If a new feature is added to the application, there must be a new version of the acceptance criteria that illustrates this feature. If developers are working simultaneously on different versions (or different branches) of the application code base, there should be matching different versions of the acceptance criteria (see figure 12.2).
Figure 12.2. Acceptance criteria evolve alongside the application.
In addition, the automated build process needs to be able to run the right set of executable specifications for a given version of the application, whether it’s the latest build of the source code, a specific release candidate build, or a bug fix for a previous release.
Some tools let you store acceptance criteria scenarios away from the source code, in a separate database or managed in a separate application. The motivation behind these tools is to make it easier for non-developers to access (and take ownership of) the acceptance criteria scenarios. However, this approach poses a number of problems. For one thing, it makes the acceptance criteria much harder to associate with a particular version of the application, which in turn makes the acceptance criteria harder to integrate into a robust automated build system.
In addition, this approach can also encourage business analysts or other less technical team members to create scenarios in isolation. When developers come to implement these scenarios, they inevitably need to “tweak” them to make them easier to automate, so the automated scenarios end up being slightly different from the ones the business analysts originally proposed. This whole workflow breaks down the collaboration aspect of BDD that’s so essential to its success.
For these reasons, it’s important to store your executable specifications in version control. In fact, automated acceptance criteria should be considered a form of source code and stored in the same source code repository as your application code.
12.1.3. You should be able to run the executable specifications from the command line
You also need to be able to execute your acceptance criteria from the command line, typically using a build script. Graphical interfaces are convenient, but build automation needs scripting. And build automation is at the heart of the continuous integration and delivery strategies we’ll discuss in the rest of this chapter.
There are many build-scripting tools, and your choice will typically depend on the nature of your project. In the Java world, you might use Maven, Gradle, or Ant. For a JavaScript-based project, you could use Grunt or Gulp. In .NET, it might be MSBuild or NAnt, and so on. In many cases, you could also launch the tests directly with the tool you’re using (for example, using Cucumber with Ruby), although build scripts often give you more control over the execution environment.
All of the tools we’ve discussed in this book can be executed on the command line, or from within a build script, but many organizations still use more heavyweight test automation tools that integrate poorly with command-line execution and build automation. Without this capability, it becomes very hard to integrate the automated acceptance criteria into the automated build process, which in turn makes continuous integration and continuous delivery strategies very hard to implement.
12.2. Continuous integration speeds up the feedback cycle
One of the most important principles underlying agile and lean software development practices is feedback. Fast feedback loops are essential to reducing wasted effort and delivering valuable features efficiently. Being informed of an issue is the first step in resolving it. Delay represents risk: the faster you know about a potential problem, the better position you’re in to adjust your actions accordingly. Even positive feedback is useful; when you can confirm that a particular strategy or problem solution is successful, you can build on this for subsequent work.
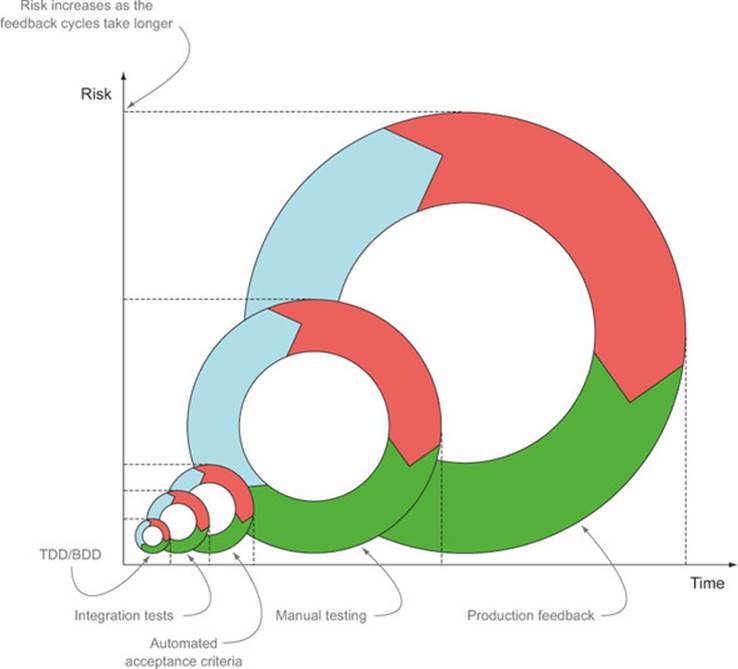
TDD or low-level BDD, for example, provides feedback within seconds or minutes, whereas automated acceptance tests, which typically take longer to run, can provide feedback within minutes or tens of minutes. In a project that relies entirely on manual testing, developers might need to wait for days, weeks, or even months to get this same feedback (see figure 12.3).
Figure 12.3. All forms of tests provide feedback, but the longer a test takes to provide feedback, the higher the risk.
The principal goal of continuous integration (CI) is to provide fast feedback on the state of the build process. A CI server is an application that continually monitors a project’s source code repository for changes. Whenever a change is committed to version control, the CI server kicks off a build to compile and test this version of the application. This ensures that all of the automated tests are run against each new version of the code base. If anything goes wrong, the team is immediately notified. In teams that practice CI well, the status of the build is taken very seriously, and if a build breaks, the developer responsible will immediately stop work and fix the problem.
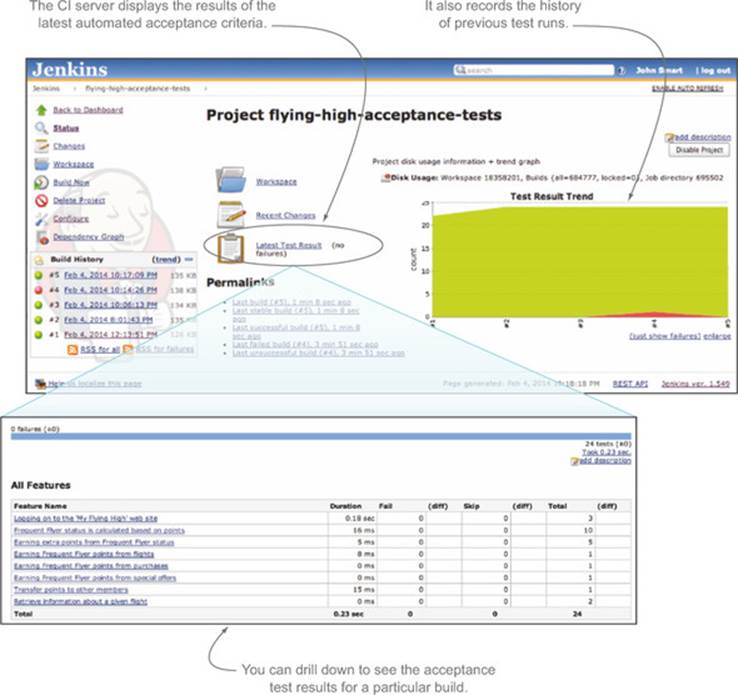
Figure 12.4 illustrates the results of a set of automated acceptance criteria run under Cucumber, as displayed on Jenkins, a popular open source CI server (http://jenkins-ci.org/).
Figure 12.4. Automated acceptance criteria are typically run on a CI server, such as Jenkins.
CI relies heavily on good automated testing: without automated testing, a CI server is little better than an automated compilation checker. But with reliable and comprehensive automated tests, the team can use the CI build results to evaluate the current state of the application. If every feature has a meaningful set of automated unit and acceptance tests, then the automated test reports will give a meaningful picture of the current state of the application.
For teams practicing BDD, a CI server also acts as a platform for automatically building and publishing living documentation. The full set of automated acceptance criteria is executed for each change made to the application. Issues are raised quickly, but even when all goes well, the living documentation generated from the acceptance criteria is updated and published for each change to the application. This provides much faster feedback for business analysts, testers, and even business stakeholders about the current state of the application. They don’t have to wait for the developers to announce that a new feature has been delivered, or demonstrate how it works; they can look at the latest version of the living documentation and see for themselves.
12.3. Continuous delivery: any build is a potential release
Continuous delivery takes CI a step further. For a team that practices continuous delivery, any build is a potential release. To be deemed “release-ready,” a particular version of an application must successfully pass through a number of quality gateways—unit tests, integration tests, acceptance tests, performance tests, code quality metrics, and so on. In continuous delivery, an executable version of the application is built and packaged very early on in the build process, and this same packaged version is passed through each of the quality gateways. This approach streamlines the process, because the application doesn’t need to be rebuilt at each stage. If it successfully passes all of the gateways, it can be deployed to production if and when the business decides to do so.
An example of a build pipeline is illustrated in figure 12.5. Here, an initial build compiles the application and runs unit and integration tests. If these pass, a binary version of the application is prepared: this is the release candidate for this version. The release candidate is passed to subsequent build jobs, each of which acts as a quality gateway. In the pipeline illustrated here, the quality gateways are the automated acceptance criteria and the performance tests. If the release candidate passes both of these gateways successfully, it can be deployed to the User Acceptance Testing (UAT) environment. Deployment to UAT and production is triggered manually—the process is still automated, but the team decides when the latest release candidate should be deployed.
Figure 12.5. A simple build pipeline
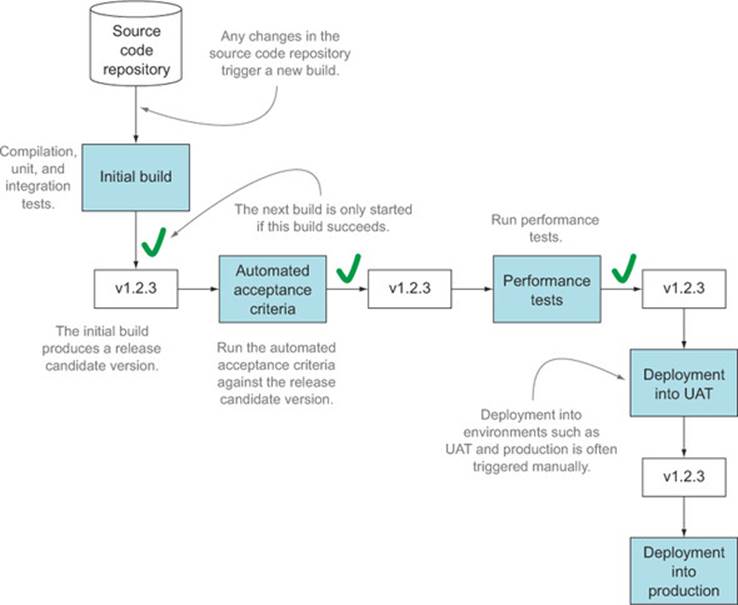
In a more traditional release process, when the code is deemed ready, a special “release build” will produce a release candidate version of the application. This release candidate version will need to pass through a similar set of quality gateways before it can be released into production, but it will generally be rebuilt from source code at each stage.
In both cases, the build pipeline is typically made up of a series of quality gateways, which run different sorts of tests and checks. Common examples of quality gateways include
· A simple, fast build that compiles and runs the unit and integration tests (in that order). This is designed to provide feedback to developers. Using BDD naming styles makes it easier to troubleshoot problems when they do occur.
· A longer-running build job that runs the automated acceptance criteria. This build job also produces and publishes the living documentation.
· A build job that verifies code quality metrics such as code coverage or coding standards.
· Build jobs that verify performance or other nonfunctional requirements (discussed in section 9.4).
Many modern CI servers now support build pipelines to various degrees. Figure 12.6 illustrates the build pipeline illustrated in figure 12.5 running on a Jenkins server using the Build Pipeline plugin (https://wiki.jenkins-ci.org/display/JENKINS/Build+Pipeline+Plugin).
Figure 12.6. A build pipeline implemented using Jenkins
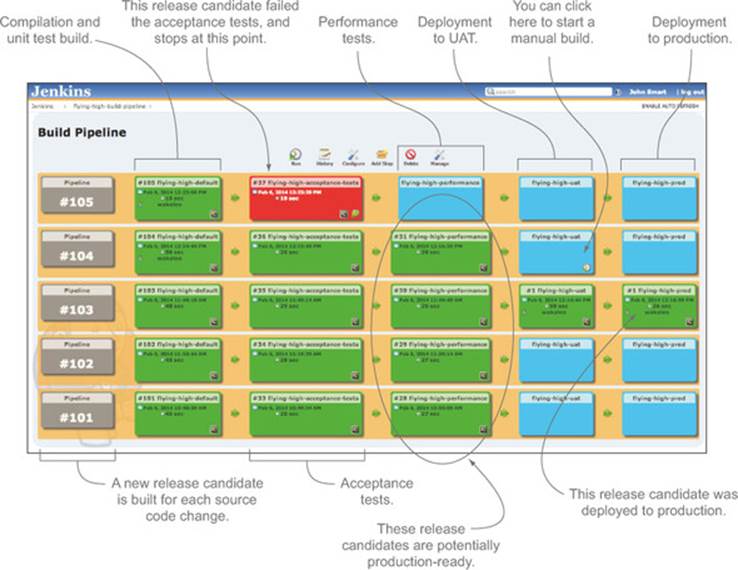
Teams practicing BDD are in a good position to implement continuous delivery strategies. Continuous delivery relies on an extremely high level of confidence in the automated test suite: if you can’t trust the automated tests to verify your application, you need to introduce a manual testing step, or possibly several manual testing steps, into the pipeline. Many organizations do indeed have manual testing steps, but the number and length of these steps has a significant impact on the time it takes a given release candidate to get into production. The more confidence the team has in the automated tests, the less time needs to be spent on these manual testing stages.
This is one of the reasons that BDD practitioners place such a strong emphasis on communication and readability when writing automated acceptance scenarios. Testers need to be able to understand what the automated acceptance tests are verifying, and to trust that they’re testing these aspects of the application effectively. Otherwise, they’ll effectively duplicate the verification work done by the automated tests, which wastes time, slows down the deployment pipeline, and diverts testers from doing more value-added testing such as exploratory testing.
But this trust can’t be blind—testers need to be able to see both what scenarios the automated acceptance criteria are testing and how they’re testing these scenarios. The key to this trust is effective living documentation. In the next section, you’ll see how CI can help make this living documentation easily accessible to testers and other team members.
12.4. Continuous integration used to deploy living documentation
You learned about the benefits of living documentation in chapter 11. But living documentation isn’t useful if it’s not up to date, or if you need to produce a new version manually whenever you need to consult it. Effective living documentation needs to be generated automatically for each new version as part of the CI build. And it needs to be easy to access, so that anyone who needs to see the latest version can do so with minimal effort.
Let’s look at a couple of ways that BDD teams make living documentation available.
12.4.1. Publishing living documentation on the build server
This simplest way to publish up-to-date living documentation is to store it directly on the CI build server. Almost all of the BDD tools we’ve discussed in this book produce HTML reports, and most CI servers let you store HTML reports produced as part of a build. Some CI servers, such as Jenkins, also provide dedicated plugins for BDD tools, such as Cucumber and Thucydides, that let you publish the reports on the CI server website more easily (see figure 12.7).
Figure 12.7. The Thucydides Jenkins plugin makes it easy to access the latest Thucydides reports.
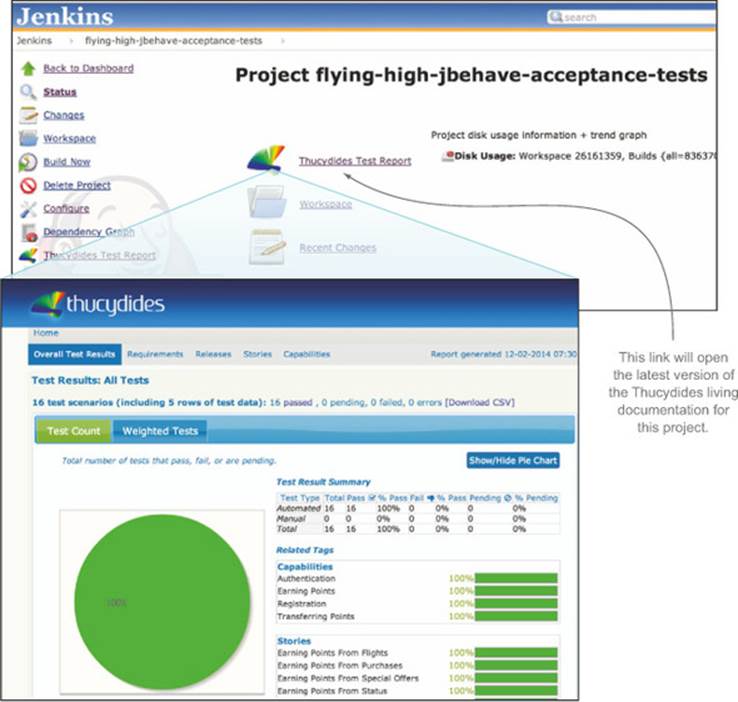
This approach is easy to set up and is relatively low maintenance. But accessing the living documentation on a CI server isn’t always as easy as it should be, particularly for team members or users not familiar with using a CI build server.
Some CI servers, such as Jenkins, do make it easy to use a fixed URL that will always access the latest successful build for a project, or, for example, the latest set of Thucydides reports. But another way to make access simpler is to use a dedicated web server for the living documentation.
12.4.2. Publishing living documentation to a dedicated web server
Some teams choose to publish living documentation to a dedicated web server. Any web server will do, because the reports are just static HTML. This way, team members don’t need to log on to the build server or find the right build job; they can access the documentation simply and directly.
This approach requires a little more initial configuration to deploy the reports, but most CI servers let you deploy files to a remote server easily enough. For example, Jenkins has several plugins that make it easy to deploy files across FTP, SFTP, and so on.
It can be useful to store previous versions of the living documentation for future reference. A common strategy is to publish the latest living documentation on a dedicated web server, and to store older versions on the build server.
12.5. Faster automated acceptance criteria
As you’ve seen, automated acceptance criteria are an excellent way to provide rich and meaningful feedback about the state of a project. And compared to manual tests, automated acceptance criteria are certainly fast. But in terms of build automation, automated acceptance tests (along with performance tests and load tests) are often among the slowest of the automated tests you’re likely to run. The value of feedback is proportional to the speed with which you receive it, so faster feedback is always preferable.
When automated acceptance tests take too long to run, the whole development and release process suffers. A full release process that takes 15 to 30 minutes, for example, provides reasonably fast feedback for developers and makes it easier to streamline the release process and get new features or bug fixes deployed as quickly as they’re implemented. But if your full test suite takes three hours to run, developers will often have to wait until the following day to get feedback about their changes, and same-day releases of changes and bug fixes becomes much harder.
In this section, we’ll look at a few ways you can speed up your automated acceptance tests, and as a result speed up your delivery process.
12.5.1. Running parallel acceptance tests within your automated build
One way to speed up tests is to configure the acceptance criteria to run in parallel directly within the automated build. Modern machines with multicore processors have plenty of processing power that can be harnessed to accelerate your test suite. Exactly how you do this varies greatly depending on what BDD toolset you’re using, and different tools have different levels of support for parallel processing.
If you’re implementing your automated acceptance criteria using JBehave and Thucydides with Maven, for example, you can use the parallel execution capabilities that come with the Maven JUnit test runner Surefire (http://maven.apache.org/surefire/maven-surefire-plugin/) used to execute the JBehave scenarios. In figure 12.8, you can see a typical project structure using JBehave and Thucydides.
Figure 12.8. A Thucydides/JBehave project with a test suite for each feature (.story) file
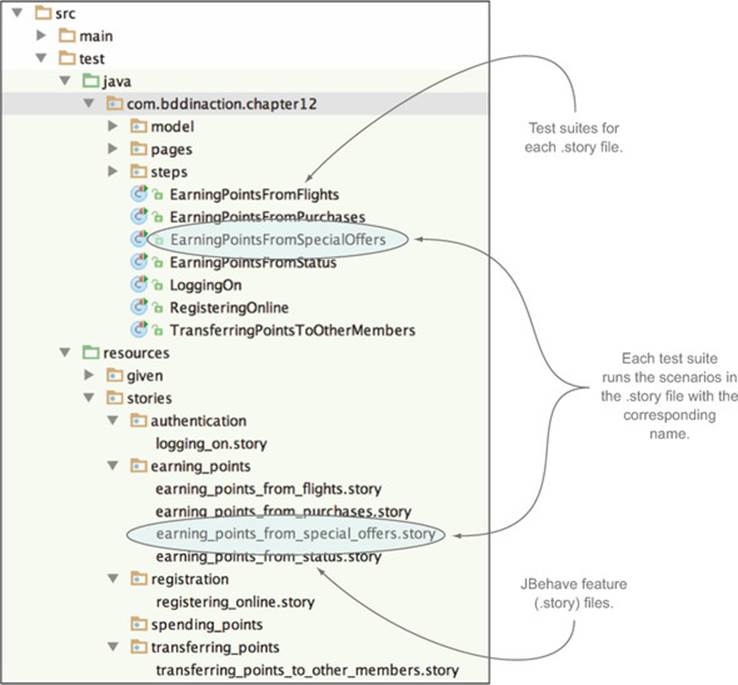
In this example, each feature file has its own test suite class. The following is an example of the test suite class for the earning_points_from_flights.story file:

For larger projects, you might have a test suite class per higher-level feature or capability, with the stories being organized into folders accordingly. For example, the following test suite class would run all of the stories in the earning_points directory:

In both cases, you’re running the tests through JUnit.
One way you can configure the automated build to run these tests in separate parallel threads is to use the <forkCount> option, as shown here:

This runs each test class in a separate JVM process. You can also use JUnit’s built-in <parallel> option, but this runs all of the tests in parallel threads within a single JVM process, which is less robust and better suited to running unit tests in parallel.
The <forkCount> option will also work fine with the Maven Failsafe plugin, a popular alternative Maven plugin used for integration testing.[1]
1 See “Fork Options and Parallel Test Execution” on Apache’s “Maven Failsafe Plugin” page: http://maven.apache .org/surefire/maven-failsafe-plugin/examples/fork-options-and-parallel-execution.html.
Similar approaches can work with any tool that uses a JUnit-based test runner, though with some caveats. If you’re using Cucumber-JVM, you can configure Cucumber-JVM test suites similar to the Thucydides test runners shown previously to run a subset of the Cucumber feature files. For example, the following class will run all of the feature files with the @earning_points tag:

Similarly, the following class will only run features related to Authentication:
@RunWith(Cucumber.class)
@Cucumber.Options(tags = {"@authentication"},
format = {"json:target/cucumber/authentication.json"})
public class Authentication {}
Note how each of these test suites writes the test results to a different file. This ensures that the test results can be produced independently, but it means you’ll need to merge the results from all of these JSON files after the tests have finished. If you’re using a CI tool with Cucumber integration, such as Jenkins or Bamboo, this can be easily done directly from within the CI build job itself.
Not all BDD tools offer this level of support for parallel testing, and even when this is the case, parallel testing on a single machine won’t scale beyond a certain point. For example, if you’re running web tests, running too many browser sessions simultaneously on a single machine can slow down the machine and cause tests to fail due to browser crashes or memory limitations. For large projects, a more scalable approach is to run parallel builds on more than one machine.
12.5.2. Running parallel tests on multiple machines
Today, hardware is cheap and virtual machines are easy to set up. Many organizations configure their testing infrastructure so that they can devote a battery of physical and virtual machines to testing when they need to run an intensive set of tests, and then release them once the tests are finished. Continuous integration servers like Jenkins, Bamboo, and TeamCity make it easy to dispatch build jobs across several machines to better distribute the load.
You can use this distributed capability to speed up your automated acceptance criteria. This approach is illustrated in figure 12.9. The acceptance criteria ![]() need to be divided into groups that can be distributed across different build jobs, possibly on different machines
need to be divided into groups that can be distributed across different build jobs, possibly on different machines ![]() .
.
Figure 12.9. Automated acceptance criteria can be run faster by splitting them into groups that are run on different machines.
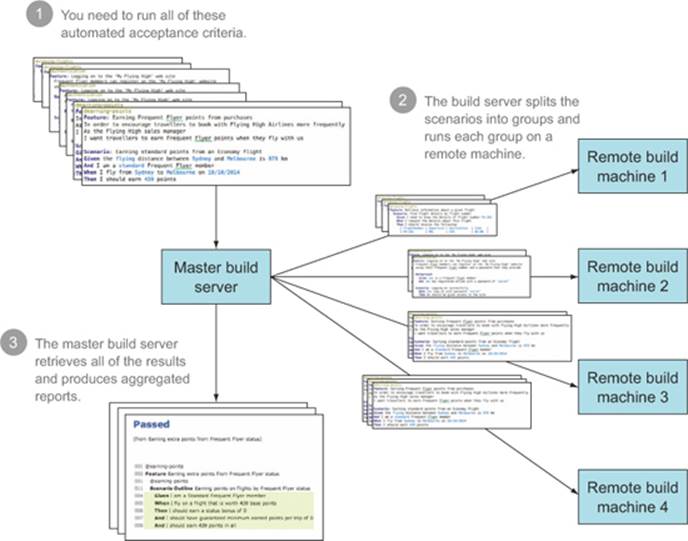
Different teams use different strategies to group acceptance criteria in this way. Tags and directory structures are both popular options. If you’re using Cucumber, you can take an approach similar to the one you saw with the JBehave/Thucydides project in section 12.5.1, with a test-runner class to run the scenarios for a given tag or tags:
@Cucumber.Options(tags = {"@earning_points"},
format = {"json:target/cucumber/earning_points.json"})
public class EarningPoints {}
In this configuration, each parallel build job would be configured to run a different test runner, typically by passing a system property from the command line. Using Maven, for example, you could run something like this:
mvn test –Dtest=EarningPoints
Using JBehave, you’d typically use the metafilter system property directly:
mvn test –Dmetafilter=+earning_points
Virtually any modern CI tool will let you run build jobs in parallel like this, although the functionality (and even the vocabulary used) varies from tool to tool. In Bamboo, for example, you’d set up a build plan to deploy your application. This build plan would be made up of a number of stages: compilation and unit tests, integration tests, automated acceptance criteria, performance tests, and so forth. Within the automated acceptance criteria stage, you can run several jobs in parallel, with each job running a subset of the acceptance criteria.
If you’re using Jenkins, you can use a multi-configuration project type for a more centralized approach. Multi-configuration projects let you run a build job multiple times with different parameters, either on the main build server or across a number of remote machines. The multi-configuration build job lets you define a list of parameter values to be passed to the automated build script, and it runs a separate build job for each parameter value. These build jobs are run in parallel, either on the master build server or on remote build machines.
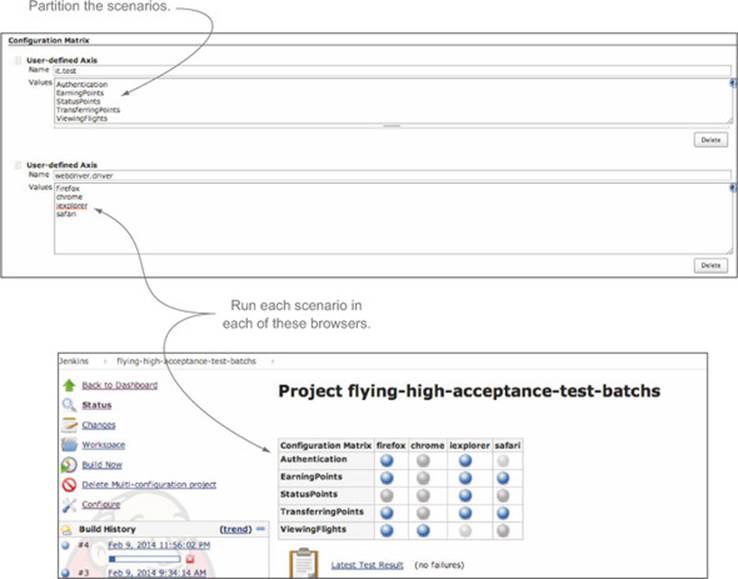
Multi-configuration build jobs work well for automated acceptance criteria. For example, rather than having a separate build job for each tag you want to execute, you could use a multi-configuration build job and provide a set of values for the test or metafilter parameter. To do this, you’d first create a multi-configuration build job in Jenkins and add a User-Defined Axis in the Configuration Matrix section (see figure 12.10).
Figure 12.10. A Jenkins multi-configuration build job lets you run several variations of a build job in parallel and then aggregate the results.
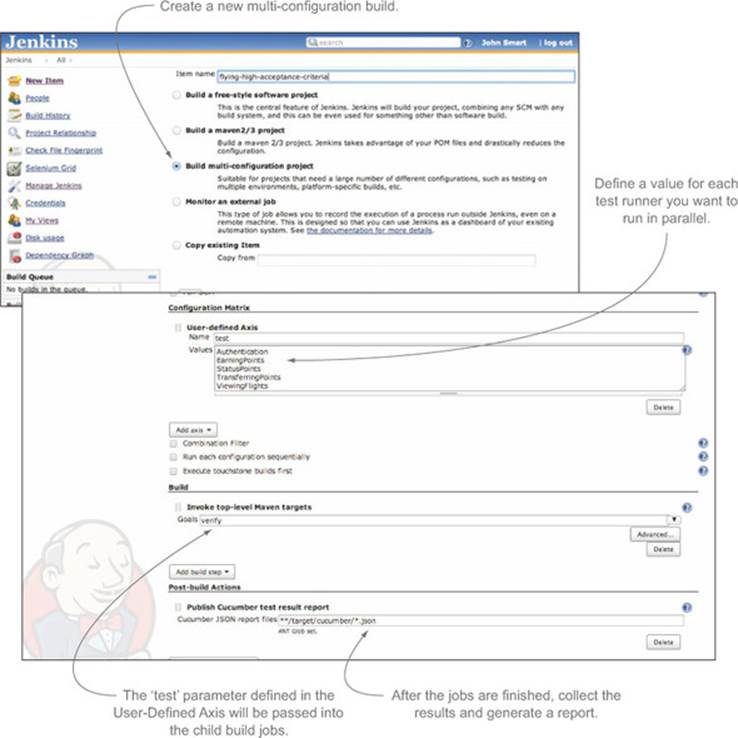
When Jenkins runs this multi-configuration build, it’ll start a build job for each value you place in the User-Defined Axis field, passing in the values you define in the user-defined axis as system properties. So in the example in figure 12.10, it will start five child jobs respectively running the following commands:
mvn test –Dtest=Authentication
mvn test –Dtest=EarningPoints
mvn test –Dtest=StatusPoints
mvn test –Dtest=TransferringPoints
mvn test –Dtest=ViewingFlights
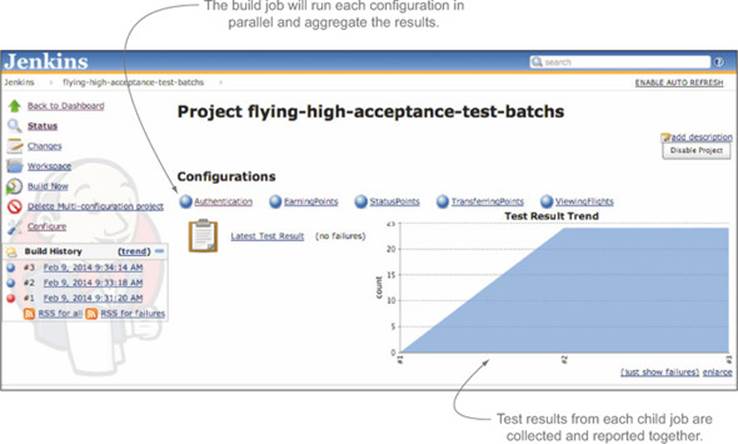
The results of each of these child jobs are shown in the overall build job status page (see figure 12.11).
Figure 12.11. The results of each child job are displayed on the main job page.
Multi-configuration builds are an excellent way to speed up automated acceptance criteria, and they’re very easy to scale, though they’re a Jenkins-specific feature. In the next section we’ll look at another approach to this problem that will work on any build server.
12.5.3. Running parallel web tests using Selenium Grid
If you’re running web tests using WebDriver (see chapter 8), another strategy you can use is to set up a Selenium Grid server (http://docs.seleniumhq.org/projects/grid/). Selenium Grid lets you set up remote machines that you can use to farm out automated web tests. Teams often use Selenium Grid to run web tests on different browsers, devices, and operating systems, or to distribute the load in large automated web testing suites. You can use Selenium Grid to run tests on browsers on Windows, Linux, and OS X, and even on mobile devices running Android and iOS.
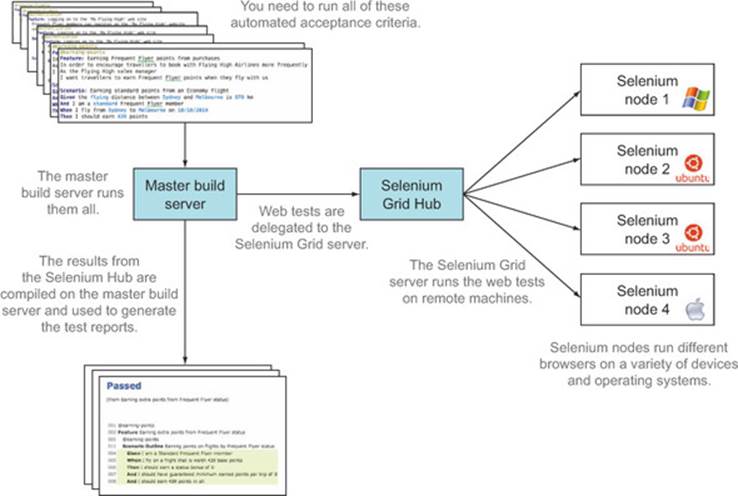
Unlike the CI-based approach we looked at earlier, the tests are often executed on a single machine (typically the build server). But when the web tests are executed, they won’t open a browser locally; instead, they’ll delegate to the Selenium Grid server, which will open and control a browser on a remote machine (see figure 12.12). You can configure any browser supported by the operating system on the node machine, including PhantomJS.
Figure 12.12. Selenium Grid lets you run WebDriver-based tests on a number of remote machines.
Note that although Selenium Grid does make it easy to run web tests on different operating systems and browsers, it won’t in itself run the web tests in parallel. For this to happen, you still need to configure the tests to run in parallel, such as by using the strategy discussed in section 12.5.1.
A Selenium Grid server is easy to set up.[2] The first thing you’ll need is a machine to act as your Selenium Grid Hub. Choose one with a decent amount of memory and CPU power—although this machine doesn’t run the browsers itself, WebDriver tests are memory-hungry, and if the server doesn’t have enough resources, the tests will fail unexpectedly.
2 See the Selenium Grid2 wiki for detailed instructions: https://code.google.com/p/selenium/wiki/Grid2.
The Selenium Hub binary comes as part of the Selenium Server JAR file that you download from the Selenium site (http://docs.seleniumhq.org/download/). To start it, you execute the JAR file with the -role hub option, as shown here:
java -jar selenium-server-standalone-2.39.0.jar -port 4444 -role hub
This will run the Selenium Hub on port 4444.
Before you can use this hub for any tests, you need to register some Selenium node machines to run the tests. From the machine you want to run the actual tests on, you start up the Selenium Server with the -role node option, typically along with other options related to what browsers are installed on the node and the maximum number of each browser to open simultaneously on the node. For example, if the Selenium Hub is running on selenium.acme.org, you could set up a Linux node running up to four instances of Firefox and Chrome like this:

There are many other options available, which are documented on the Selenium Grid website. For more complex configurations, you can also place the configuration options in a JSON file.
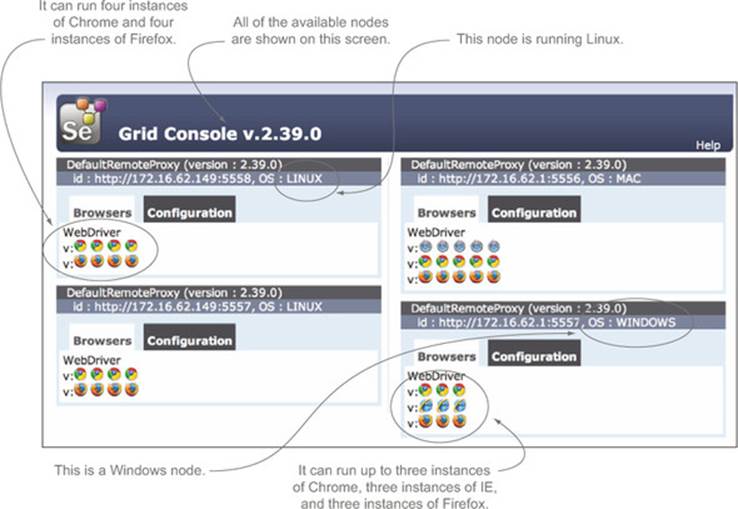
Once you’ve registered a few hubs, you can monitor them on the Selenium Hub console page, as illustrated in figure 12.13.
Figure 12.13. The Selenium Grid console page shows all the available Selenium nodes, what OS they’re running, and which browser instances they’re hosting.
When the nodes are running, you can start dispatching your tests to the Selenium Hub instead of running them locally. If you’re dealing with native Selenium, you’ll need to use a RemoteWebDriver to connect to the Selenium Hub. In Java, for example, you might do something like this:

The DesiredCapabilites object ![]() is used to provide a description of the environment you’d like to run this test in. These parameters are used to send the web test to the most appropriate Selenium node machine. Then you create a RemoteWebDriver instance using these preferences and the URL of the Selenium Hub, and use this WebDriver instance to run your tests.
is used to provide a description of the environment you’d like to run this test in. These parameters are used to send the web test to the most appropriate Selenium node machine. Then you create a RemoteWebDriver instance using these preferences and the URL of the Selenium Hub, and use this WebDriver instance to run your tests.
If you’re using Thucydides, you just need to provide the webdriver.remote.url system property, and Thucydides will run all of the scenarios on the Selenium Hub automatically.
If you provide undemanding desired driver capabilities (for example, you might just be interested in running your tests on Firefox), then Selenium Grid will transparently dispatch your web tests to as many compatible Selenium node machines as possible. This, combined with the parallel testing strategies we saw earlier, is a simple and effective way to scale your tests.
If you have more involved web-testing requirements (for example, you may need to test on a number of specific browsers), then Selenium Grid combined with the Jenkins multi-configuration build job (see figure 12.10) that you saw earlier is a great fit. But this time you’d use two User-Defined Axis fields: one for the test sets you want to execute, and another for the browsers you want to use. The resulting build job will run each test under every browser (see figure 12.14).
Figure 12.14. Multi-configuration build jobs work well with Selenium Grid.
All of the strategies we’ve discussed here require a little organization and planning to set up efficiently. But when done well, they can lead to significantly faster and more scalable automated acceptance criteria, which in turn leads to a faster build and release process.
12.6. Summary
In this chapter you learned about the role of BDD in the build and deployment process:
· Your executable specifications need to be part of an automated build process.
· Automated executable specifications can be run on a CI server to provide faster and more reliable feedback than could be achieved with manual testing alone.
· Automated executable specifications are an essential part of any CI process.
· CI can also be used to ensure that a project’s living documentation is always up to date and easily available.
· You can speed up automated acceptance criteria by running them in parallel, either on a single machine or across several machines.
· Selenium Grid is a specialized tool that makes it easy to run WebDriver-based tests in parallel on multiple machines.
If you’ve made it this far, congratulations! We’ve covered a lot of material in this book, going right across the spectrum from requirements discovery to automated tests and living documentation. I’ll try to distill all that we’ve discussed into a few short paragraphs.
12.7. Final words
BDD is based on a few simple principles, many of which are closely aligned with broader Agile principles:
· Describe behavior, don’t specify solutions.
· Discover the behavior that will deliver real business value.
· Use conversations and examples to explore what a system should do.
Conversation and collaboration is key. As Liz Keogh is fond of saying, “Having conversations is more important than capturing conversations is more important than automating conversations.” In the first part of this book, you learned a number of techniques and approaches that can help facilitate these conversations and capture useful examples in an unambiguous form.
But automation has huge value too. Once you’re satisfied that you’ve understood a requirement sufficiently, automation is where the rubber meets the road and the examples turn into executable specifications. At the high-level requirements level, you learned how to express examples in a form that can be easily automated with tools like Cucumber and JBehave, and how to automate them in a clean, robust, and sustainable way. In chapter 10 you saw how writing executable specifications at the unit-testing level really is a no-brainer. And automation is the cornerstone of the continuous integration and delivery strategies we looked at in this chapter.
One of the outcomes of both high-level and low-level executable specifications is up-to-date requirements documentation that can be viewed by the whole team at any time. This is what we call living documentation, and it’s what we looked at in chapter 11.
At the end of the day, BDD is about streamlining the whole development process and delivering value. And it’s much more a mindset than a particular toolset. With that in mind, adopt and adapt the practices you find valuable within your organization. I hope you’ll find as much success with it as I have!
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.