CoffeeScript in Action (2014)
Part 3. Applications
Chapter 13. ECMAScript and the future of CoffeeScript
This chapter covers
· CoffeeScript and the future of JavaScript
· Features in ECMAScript 5 you can use today
· Upcoming features in ECMAScript 6
· Source maps for debugging
Whatever your opinion of JavaScript (and regardless of whether learning CoffeeScript has changed it), you should count on it being around for a long time—long enough, at least, that it will probably outlast your career as a programmer. For that reason it’s important to look at what the future holds for JavaScript and how it will affect CoffeeScript.
In this chapter you’ll look at the evolving relationship between CoffeeScript and JavaScript and why your understanding of CoffeeScript applies not only to JavaScript today but also to the JavaScript of tomorrow. You’ll see how JavaScript versions relate to different editions of the ECMAScript specification that documents the evolving JavaScript standard. Lastly, this chapter discusses one of the most important tool-related aspects of the JavaScript ecosystem: how to debug CoffeeScript programs with source maps. Before looking at the future, though, where are you now?
13.1. CoffeeScript in the context of JavaScript
When talking about language versions, it’s important to first have a broad overview. Table 13.1 shows a timeline of major versions of the ECMAScript specification.
Table 13.1. An ECMAScript timeline
|
Edition |
Date published |
Examples of new features |
|
1 |
June 1997 |
|
|
2 |
June 1998 |
|
|
3 |
December 1999 |
Regular expressions Improved string handling Exception handling |
|
4 |
Abandoned |
|
|
5 |
December 2009 |
Strict mode Native JSON support New object methods Property descriptors |
|
6 |
In progress |
Rest and spread parameters Template strings Default parameters Destructuring assignment Function syntax Classes |
The fifth and sixth editions of the ECMAScript specification are most relevant to CoffeeScript. Some of the features introduced by these editions are instantly recognizable from CoffeeScript, others are vaguely familiar, and some are brand new. All of them are explored in this chapter.
JavaScript, ECMAScript? Which is it?
ECMAScript is the name of the language standardized by the ECMA-262 specification by Ecma International. JavaScript is a dialect of ECMAScript (and a trademark of Oracle Corporation), but it’s the name used by almost everybody when referring to the language. In this chapter, ECMAScript is used when referring to the ECMA-262 specification.
13.1.1. A better JavaScript through CoffeeScript
JavaScript is the host for CoffeeScript. The word host conjures up images of human parasites like worms and bedbugs. In the case of CoffeeScript, though, JavaScript benefits from the relationship. One of the ways that JavaScript benefits is by taking some of the features in CoffeeScript and adding them to future versions of JavaScript.
Imagine you’re working with Scruffy on a library to automatically fetch form values and synchronize them with a server. In this listing you can see the initial program that Scruffy has called Formulaic.
Listing 13.1. Formulaic form bindings
class Formulaic
constructor: (@root, @selector, @http) ->
@subscribers = []
@fields = @extractFields()
@startPolling()
extractFields: ->
element = @root.querySelector @selector
fields = element.getElementsByTagName 'input'
extracted = {}
for field in fields
extracted[field.name] = field.value
extracted
startPolling: ->
diff = =>
for own key, value of @extractFields()
if @fields[key] isnt value
@fields[key] = value
@notify()
setInterval diff, 100
subscribe: (subscriber) ->
@subscribers.push subscriber
notify: ->
subscriber() for subscriber in @subscribers
How do you use the Formulaic class from listing 13.1? Consider the following HTML document:
<!doctype html>
<html>
<form id='contact-details'>
<input type='text' name='first-name'>
<input type='text' name='last-name'>
<input type='text' name='email'>
You new a Formulaic instance by passing the document and the selector for the form:
new Formulaic document, '#contact-details'
Agtron tells you that extending and improving Formulaic will require you to learn some ECMAScript 5 and some ECMAScript 6 features. Sounds good! Time to get started.
13.1.2. Future JavaScript features that CoffeeScript has today
Some of the features coming in future versions of ECMAScript are already present in CoffeeScript in one form or another. This means that even if the names of these features sound only vaguely familiar, you already know and use rest and spread parameters, template strings, default parameters, and destructuring assignment. Because you already know them, it’s best to get them out of the way before moving on to the interesting stuff.
rest and spread
The rest and spread operators proposed for ECMAScript 6 work the same way as the ones you’re familiar with in CoffeeScript (aside from some syntactical differences). Here’s the CoffeeScript syntax you’re familiar with:
rest = (a, b, r...) -> r
rest 1,2,3,4,5,6,7
# [3,4,5,6,7]
spread = [1,2,3,4,5,6,7]
rest spread
# [3,4,5,6,7]
In JavaScript with ECMAScript 6 it looks similar, but the ellipsis goes on the front of the variable name:

The ECMAScript 6 specification also has string interpolation.
Template strings
In CoffeeScript you use string interpolation to insert values into strings without having to manually concatenate them:
word = 'interpolation'
"Just like string #{word}"
# Just like string interpolation
What’s the alternative in JavaScript today? Concatenating strings with the + operator:
"Just like string " + word
Imagine trying to create an HTML template with concatenation instead of interpolation:
"""
<html>
<title>#{title}</title>
<body>
<h1>#{ heading}</h1>
#{content}
"""
ECMAScript 6 will have template strings that provide the string interpolation you know and love, but with different syntax:

Template strings are multiline (like heredocs) and will support custom substitution functions. In CoffeeScript the back tick ` is already used to put raw JavaScript in your CoffeeScript programs, so the JavaScript template string syntax won’t work in CoffeeScript.
Arrow function syntax
JavaScript syntax benefits from CoffeeScript. One inspiration that JavaScript will take from CoffeeScript is arrows instead of the function keyword. The ECMAScript 6 standard does not specify the single-arrow function but it does have the fat arrow:
![]()
You would be forgiven for mistaking that for CoffeeScript. That’s because it was inspired by CoffeeScript syntax—the relationship between CoffeeScript and ECMAScript is symbiotic.
That’s it for the familiar things. How about all the unfamiliar features that you need to know about to stay in the game? To begin with, what’s in ECMAScript 5 that a CoffeeScripter needs to find out about?
13.2. ECMAScript 5
Released in December 2009, the primary focus for the changes in ECMAScript 5 was to improve robustness for the language and, as a result, for runtimes and programs. The key features to be aware of are native JSON support, strict mode, property descriptors, and changes to the Objectobject. The best way to learn them is to try them, which means your runtime needs to support them.
13.2.1. Runtime support
It’s easy to play with the ECMAScript 5 features discussed in this section; simply fire up the CoffeeScript REPL. All of these features are supported in the V8 JavaScript engine that powers Node.js, your REPL, and all of your server-side CoffeeScript programs. Unfortunately, the same does not hold true for all of your browser-based programs. Some browsers don’t support all of these features, so if you need to support those browsers, you have to either avoid those features or use a polyfill (as discussed in chapter 11) where possible.
Polyfills
If you find yourself stuck writing programs for a browser that doesn’t support the ECMAScript 5 feature that you want, you will need to polyfill. Sometimes you need to polyfill things you might think are essential, such as JSON.
The ECMAScript features supported by a particular browser depend on which version of which JavaScript runtime it uses. When writing programs, however, it’s usually browser versions that are discussed. So that’s what we’ll discuss now. Table 13.2 shows which versions of major browsers support the ECMAScript 5 features that are discussed in this section.
Table 13.2. Support for ECMAScript 5 in some popular browsers
|
Feature |
IE8 |
IE9 |
IE10 |
FF 4+ |
Sf 6+ |
Ch 7+ |
|
Object.create |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Object property descriptors |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
New array methods (e.g., map) |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Strict mode |
No |
No |
Yes[*] |
Yes |
Yes |
Yes |
|
Native JSON |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
IE = Internet Explorer; FF = Firefox; Sf = Safari; Ch = Chrome |
||||||
* = Known bugs in implementation
When you target a browser older than the ones in table 13.2 (Internet Explorer 7, Safari 5, or Firefox 3.5, for example), there’s a good chance that it won’t support the ECMAScript 5 features you want to use. In that case, it’s best to consult the documentation for that browser.
So, what are these features and, more importantly, how will they be useful for your programs (such as Formulaic)?
13.2.2. Object.create
You know that Object.create produces a new object with an existing object as the prototype. What you might not know is that Object.create also has a second parameter, an object of property names and descriptors:
homer =
'first-name': 'Homer'
'last-name': 'Simpson'
homerTwo = Object.create homer,
clone:
value: true
writable: false
'middle-name':
value: 'Clone'
writable: false
homerTwo.clone
# true
If your CoffeeScript program is running in an environment without a native Object .create, then objects won’t support property descriptors and any polyfill for Object.create won’t have the second parameter.
13.2.3. JSON
ECMAScript 5 introduced the global JSON object and the JSON.stringify and JSON .parse methods. What do they do, and why can’t you just use JSON directly in your programs? After all, valid JSON is a valid JavaScript object.
Consider the Formulaic program. So far it’s not particularly useful because it doesn’t send the form information anywhere. How do you implement a sync method in Formulaic that communicates with an external server? The sync method should post all of the form data to a specific URL by invoking the http.post method:
sync: ->
throw new Error 'No transport' unless @http? and @url?
data = extractFields
@http.post @url, JSON.stringify(@)
What does invoking JSON.stringify do? It turns an object into a string.
stringify
To turn an object into a valid JSON string, use JSON.stringify:
fred = {firstName: 'Fred', lastName: 'Flintstone'}
JSON.stringify fred
# '{"firstName":"Fred","lastName":"Flintstone"}'
However, when you use JSON.stringify on a Formulaic instance you’re really only interested in the field values, but you get much more:
{
"root":{
"location":{},
"contact-form":{
"0":{},
"1":{},
}
},
"selector":".contact-form",
"subscribers":[],
"fields":{
"search":""
}
}
Worse, some other objects will not JSON.stringify at all. For example, try it on the REPL with the global object:
JSON.stringify @
# TypeError: Converting circular structure to JSON
What can you do? Formulaic is your class, so surely you can tell it how to turn itself into JSON? Indeed, you can. Even better, you can tell JSON.stringify about it.
Converting to JSON
If an object has a toJSON method, then JSON.stringify will invoke it and use it as the value to stringify:
class Formulaic
toJSON: -> "message": "Determine your own JSON representation"
formulaic = new Formulaic
JSON.stringify formulaic
# '{"message":"Determine your own JSON representation"}'
That takes care of sending the form information to the server. How about getting the form back? Suppose the server responds to a POST with updated JSON for the object:
sync: ->
throw new Error 'No transport' unless @http? and @url?
@http.post @url, JSON.stringify(@extractFields()), (response) ->
@fields = JSON.parse response
What does invoking JSON.parse do?
parse
The JSON.parse method converts a string of JSON to an object. If you need to polyfill JSON.parse, you can do it dangerously with an eval:
JSON.parse ?= (json) ->
eval json
barney = JSON.parse '{"firstName":"Barney","lastName":"Rubble"}'"
barney.lastName
# "Rubble"
Be warned: eval is evil. When you eval code, it can do anything, so you should never eval code you don’t trust. The ECMAScript 5 specification adds a native JSON.parse over eval (for safety reasons) and over other techniques for parsing JSON (for performance reasons).
The native JSON support is the most immediately applicable solution for Formulaic. How does Formulaic send form data back to the server and what format does it use? In the next listing you see an extended version of Formulaic that uses native JSON support.
Listing 13.2. Formulaic with server sync
class Formulaic
constructor: (@root, @selector, @http) ->
@subscribers = []
@fields = @extractFields()
@startPolling()
extractFields: ->
element = @root.querySelector @selector
fields = element.getElementsByTagName 'input'
extracted = {}
for field in fields
extracted[field.name] = field.value
extracted
update: =>
for own key, value of @extractFields()
if @fields[key] isnt value
@fields[key] = value
@notify()
startPolling: ->
setInterval @update, 100
subscribe: (subscriber) ->
@subscribers.push subscriber
notify: ->
subscriber() for subscriber in @subscribers
sync: ->
throw new Error 'No transport' unless @http? and @url?
@http.post @url, JSON.stringify(@extractFields()), (response) ->
@fields = JSON.parse response
exports.Formulaic = Formulaic
The Formulaic program in listing 13.2 is far from finished. For one thing, it fetches data from the server but doesn’t actually put any changes it receives back into the visible form that the user edits. To do that, you need some new features of the Object object.
13.2.4. Property descriptors
The new problem Agtron has given you and Scruffy is to improve Formulaic so that a change from the server is reflected in the form. This means that a change to the object representing the form needs to trigger an update in the form:
form = new Formulaic document, '#contact-details'
form.fields['first-name'] = 'Tyrone'
You could get Formulaic to poll the field properties. You could, but you don’t have to. Why? Well, until now you’ve treated all object properties as having just a name and a value:

With ECMAScript 5, though, properties don’t have just names and values; they also have descriptors. The property descriptors are value, get, set, configurable, enumerable, and writable. The get and set descriptors are commonly known as getters and setters.
Getters and setters
Consider the 'first-name' property of form.fields. Until now, when a property value is changed, that’s the full extent of it, and you’d better like it. With a set property descriptor, though, you can create a property and define what happens when a new value is assigned to it! One way to do that is with Object.defineProperty:
Object.defineProperty form.fields, 'first-name',
set: (newValue) => @root.getElementsByName('first-name')[0].value = newValue
For Formulaic, a get property descriptor means you don’t need to poll the form fields for changes. Instead, you can define a function that gets the latest value from the form field any time the object property is accessed:
Object.defineProperty form.fields, 'first-name',
set: (newValue) => @updateView 'first-name', newValue
get: => @updateField 'first-name'
In the following listing you see a new version of Formulaic using getters and setters.
Listing 13.3. Using getters and setters


Now what? Agtron wants to know what happens when the form is considered complete and should no longer be changed. How will you stop the Formulaic instance from being modified?
Preventing changes
Suppose now that the form also contains a unique identifier for a user. This user ID should never change. Unfortunately, regular object properties can be changed by anybody who has a reference to the object.
With property descriptors, you can create properties that can’t be changed:
class User
user = Object.create User.prototype,
id:
value: 'u58440329'
enumerable: true
writable: false
configurable: false
name:
value: 'Robert'
Due to the writable descriptor being false, attempts to change this property have no effect:
user.id = '0'
user.id
# u58440329
Also, due to the enumerable descriptor being false, the property doesn’t appear in a comprehension:
property for property of user
# [ 'name' ]
Finally, due to the configurable descriptor being false, the property can’t be made writable or enumerable again:
Object.defineProperty user, id, writable: true
# Cannot redefine property: id
Using Object.defineProperty gets tedious when you need to add or change multiple properties, but some other methods new to the Object object make it easier.
Freezing, sealing, and preventing extensions
To make working with multiple descriptors at the same time easier, some other methods have been added. First, with Object.freeze you can stop any properties on form.fields from being modified. Suppose your form contains a user object; to stop it from being modified, you freeze it:
user =
name: 'Robert'
Object.freeze user
Now none of the properties are writable or configurable and no new properties can be added:
user.name = 'Janet'
user.name
# 'Robert'
user.address = '10 Elephant Parade'
user.address?
# false
Object.defineProperty user, 'phone', value: '555 4312'
# Cannot define property:phone, object is not extensible.
That’s all well and good. How do they apply to Formulaic?
13.2.5. Putting it together
To answer Agtron’s question of locking the form when it’s complete, Scruffy wants to change Formulaic to use Object.freeze so that all of the fields on an instance can be frozen:
form = new Formulaic, '#form'
Object.freeze form
form.fields.user.id = 'u2344999'
form.fields.user.id
# 'u2344999'
It’s not working! Why not? Because freezing an object is shallow—it only freezes the properties and doesn’t work recursively to freeze properties of objects that are properties. You must either be careful to freeze the object containing the actual properties you want to be frozen (as you’ll see in listing 13.4) or recursively freeze everything in the object to achieve a deep freeze. A typical implementation of a deep freeze follows:
deepFreeze = (o) ->
Object.freeze o
for own propKey of o
prop = o[propKey]
if typeof prop != 'object' || Object.isFrozen prop
continue
deepFreeze prop
Freezing doesn’t follow the prototype chain
Although a frozen object is itself immutable, other objects on its prototype chain may not be. If you’re creating mixins or constant objects and you really want them to be isolated, use null as the prototype first and then freeze the object.
That’s enough time in the deep freeze; what about the other methods, Object.seal and Object.preventExtensions? They’re similar to Object.freeze, but they’re less restrictive about what can be changed in the object afterward. In table 13.3 you can see the different levels of restriction that these methods place on the objects they’re invoked with.
Table 13.3. How seal, freeze, and preventExtensions affect an object
|
Property action |
||||
|
Method |
Add |
Delete |
Edit value |
Edit descriptor |
|
freeze |
No |
No |
No |
No |
|
seal |
No |
No |
Yes |
No |
|
preventExtensions |
No |
Yes |
Yes |
Yes |
You can test whether an object is frozen, sealed, or has had extensions prevented by using Object.isFrozen, Object.isSealed, and Object.isExtensible, respectively.
There’s a problem when you try to freeze the form.fields property of a Formulaic instance because the properties on that are all getters and setters—the values are stored somewhere else and the Formulaic instance is only acting as a proxy for the fields. A solution to this appears in the next listing.
Listing 13.4. Formulaic with disabled fields


The final part of ECMAScript 5 that you need to know about is strict mode. Notice that both listings 13.3 and 13.4 included something called "use strict" in them. What does it do and why might you want to include it?
13.2.6. Strict mode
When most of your JavaScript programs are written in CoffeeScript, it can be easy to forget JavaScript’s problems. CoffeeScript protects you from some JavaScript follies, so the "use strict" pragma added in ECMAScript 5 doesn’t appear in your programs often. But it’s still important to understand how it relates to CoffeeScript.
Strict mode forbids some things in JavaScript that are dangerous; if you use them, you’ll get an error. For example, with strict mode, using an undeclared global variable in JavaScript will cause a ReferenceError:

Of course, implicit variable declaration in CoffeeScript means that you won’t see this error in CoffeeScript programs.
As you can see in the previous example, to enable strict mode you add the pragma "use strict" to some scope in your program. Any violations of strict mode inside that scope will cause an error.
The CoffeeScript compiler won’t compile your program into something that breaks strict mode, but it won’t complain if you break strict mode yourself. So when you run the following compiled program, the runtime will throw a syntax error:
"use strict"
failsStrict =
duplicateKey: 1
"duplicateKey": 2
There’s nothing to stop you from adding the "use strict" pragma to your CoffeeScript program if you want to ensure that your programs adhere to strict mode.
That’s enough for ECMAScript 5. It’s time to look into the future a little bit and see what ECMAScript 6 has in store for you.
13.3. ECMAScript 6
Important
The ECMAScript 6 specification is still a work in progress. Any of the features discussed here may change before they’re finalized.
ECMAScript 6 is more ambitious than ECMAScript 5. In fact, at the time of writing, it’s still at least a year from being finalized and probably years from being widely supported. Still, these things have a habit of changing while you aren’t looking, so it’s best to keep aware of the changes that are coming. Besides, some of them can already be used.
There are some specific features you can expect in ECMAScript 6 that have current or future relevance to CoffeeScript, and they’re covered in this section: modules, const, let, sets, maps, proxies, comprehensions, iterators, and generators.
To try these features from the CoffeeScript REPL, you’ll need two things. First, you’ll need a recent version of Node.js. To see which version you have, pass --version to Node.js.
> node --version
The features described in this section require the version to be 0.10.24 or newer. If you have an older version, you should upgrade your version of Node.js.
The second thing you’ll need to do to try the new features on the CoffeeScript REPL is to pass arguments to Node.js when you start the CoffeeScript REPL telling it to enable the new features. When invoking the CoffeeScript REPL, these options are passed individually as flags. For example, to enable proxies you set the harmony-proxy flag:
> coffee -i --nodejs --harmony-proxies
What if you want to use all of the new features? Well, Harmony was the name given early on to a large set of features that were intended for the next version of the ECMAScript specification. You can enable all of these Harmony features in CoffeeScript/node.js/V8 with a single harmonyflag:
> coffee -i --nodejs --harmony
To try the CoffeeScript code snippets for the features in this section, you should invoke the REPL with harmony enabled.
The first feature worth mentioning—in part because it’s a point of contention—is the module system.
13.3.1. Modules
JavaScript wasn’t designed with a module system, so when people needed modules for client-side programs they invented their own. Now there are many different module systems, so almost everybody is a traveler in a foreign country—carrying their module adapters everywhere they go so they can plug things in.
Until ECMAScript 6 standardizes modules, you’ll need to use some other module system. One approach, outlined in chapter 12, is to use the Node.js module syntax for both server and client modules and compile them out for the client (where they aren’t supported) using a build step.
In the long term, JavaScript needs a standardized module system for the sake of interoperability. The module system that’s proposed for ECMAScript 6 is similar to the Node.js module system. But the keyword module is already used by Node.js to refer to the current module, so something will have to change:
![]()
Then elsewhere you import...from:
![]()
Your CoffeeScript program has a compilation step, so regardless of the module system your CoffeeScript program uses today, the JavaScript that it generates can use a different module system tomorrow. Because the module system is one of the most likely areas that can still change, it’s easier to move on to more defined areas such as const and let.
13.3.2. const and let
The variable-scoping rules catch out many programmers new to JavaScript. One of the reasons for this is that it has a syntax similar to C and Java but very different scoping rules. In order to provide some of the naming rules that people expect to find in JavaScript, two new keywords, constand let, are being added in ECMAScript 6. You’ll notice that you almost use their semantics already.
const
Many CoffeeScript programs have a few variables that are written in uppercase:
ONE_SECOND = 1000
setInterval ->
rocket.forward()
, ONE_SECOND
Why name this variable in uppercase? In JavaScript it’s really just tradition handed down from programming languages with a C heritage. It’s meant to indicate that the value shouldn’t be changed. The problem is that it can be changed:
ONE_SECOND = 0
Suppose your program needs to get some information about the environment it’s running in, such as whether it’s in production or development mode:
MODE = 'development'
Because the MODE variable can be changed by any other part of the program, there’s some potential for your program to break:
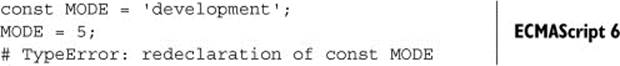
Everything is immutable?
If you take a functional approach to your CoffeeScript programs, then you might already treat most (if not all) of your variables as being constant. If you’re brave, then you modify the compilation of your CoffeeScript programs to turn all of your var declarations into const declarations.
The keyword const is a reserved word in the CoffeeScript compiler, but as of CoffeeScript 1.6 const itself is not supported.
Let
Variables in CoffeeScript are always function scoped. What if you don’t want a name to be scoped to a function? Consider a trivial example with a comprehension inside a function:

Comprehensions in CoffeeScript have side effects. The names used are variables and so they use the same scoping rules and implicit declaration as any other variables in CoffeeScript. The ECMAScript 6 let expression is designed for names that should only apply to a block of code, just like the comprehension shown previously:

If you don’t like comprehensions to have side effects, you can see how that could be useful. How can you use it in CoffeeScript? Well, the brevity and flexibility of CoffeeScript’s syntax mean that you can approximate let with a simple do -> form:
number = 5
do (number=0) -> number for number in numbers
Function parameters always shadow, so there’s no way to assign a value to the number variable. This means you can rewrite the earlier example so that the comprehension doesn’t clobber the outer variable:
number = 4
double = do (number=0) ->
(numbers) -> number * 2 for number in numbers
double [3,4,5,6]
number
# 4
CoffeeScript favors simplicity. Sometimes when you think you need a specific new feature, there’s an easy way to achieve the result you want without it. It’s possible to write entire CoffeeScript programs that use only parameters and never use variables.
Remember, const and let are reserved words in the CoffeeScript compiler, so you can’t use them. How about something you can use? How about some more objects?
13.3.3. Sets, Maps, and WeakMaps
Objects are useful as key-value pairs, but they’re not dedicated for use as key-value stores. This can lead to problems such as properties on the prototype chain being included in comprehensions unless the own keyword is used. ECMAScript 6 specifies several dedicated APIs better optimized for some cases where you’d otherwise use a plain object. These are Set, Map, and WeakMap.
Set
A Set is just an ordered list of unique elements—a bit like a shopping list. Try it on a harmony-enabled REPL; use coffee -i --nodejs –harmony:
shopping = new Set()
shopping.has 'eggs'
# false
shopping.add 'milk'
shopping.has 'milk'
# true
shopping.delete 'milk'
shopping.has 'milk'
# false
On to the Map; how does it differ? Well, in the analogy format you remember from high school English tests, Set is to Array as Map is to Object.
Map
A Map is dedicated to storing key-value pairs. Aren’t objects already good at that? Yes, but a Map allows any value (not just a string) to be used as a key:
map = new Map
harold = name: 'Harold'
map.set harold, age: 50
map.get harold
# {age: 50}
Be mindful that when you use an object as a key, only the actual object can be used to get from a Map instance, not just any old object that looks the same:
map.get {name: 'Harold'}
# undefined
Unfortunately, a Map can be a problem because it can eat memory. Sounds dangerous—what does it mean?
WeakMap
In addition to Map there’s also a WeakMap. A WeakMap is a Map that is not enumerable. The reason it’s not enumerable is so that objects referenced by it can be garbage collected if the only reference to the object is in the WeakMap instance itself:
stackOfPapers =
paperOnGladiators:
text:
"Gladiators, it seems, were fat."
papersMap = new WeakMap
papersMap.add stackOfPapers.paperOnGladiators
delete stackOfPapers.paperOnGladiators
When that’s implemented using a WeakMap, then deleting the paperOnGladiators from the stackOfPapers allows it to be garbage collected. But if it were implemented using a regular Map, then deleting the object wouldn’t make it available for garbage collection because the Map has a strong reference to the deleted paper. You can see how a Map could lead to object hoarding and a massive amount of uncollected garbage in some instances.
These features may not be setting your hair on fire. They’re very useful for solving some specific problems, but they don’t really expand your universe as a programmer. That’s about to change, because it’s time to explore proxies.
13.3.4. Proxies
With proxies you can give revocable access to an object. How is that useful? Imagine you’re a superhero. What happens when the bad guys take you to their secret hideout? They blindfold you so that you don’t know how to get there. In other words, they take you to the hideout without giving you any reference to it:
class SecretHideout
hideout = new SecretHideout()
proxy = new Proxy hideout, {}
Just as you can’t lead the police to a hideout you can’t find, there’s no way you can touch a proxied object because your reference is to the proxy, not the original object:
proxy.policeAssault = true
hideout.policeAssault #false
More importantly, a proxy can capture any call to the object behind the proxy by defining a handler object that defines a get and set for any property accessed on the proxy. In the case of Formulaic, a form can be placed behind a proxy handler. The handler must have get and set methods that specify what happens when a property on the proxied object is accessed or modified:
form = document.getElementById '#the-form'
handler =
get: -> 'property access intercepted by proxy'
set: -> 'property modify intercepted by proxy'
proxiedForm = new Proxy form, handler
proxiedForm.name
# 'property access intercepted by proxy'
proxiedForm.phone = '555 9988'
# 'property modify intercepted by proxy'
This is useful for Formulaic. The existing implementation extracts all of the fields and creates an intermediate representation of the form. With ECMAScript 6, instead of this intermediate representation your program can use a proxy. In listing 13.5 you can see Proxy and Map used to create a new version of Formulaic. In order for this program to work, it will need to execute in a runtime that supports proxies. For that reason, this listing throws an error if proxies are not supported.
Listing 13.5. Formulaic using Proxy
throw new Error 'Proxy required' unless Proxy?
class Formulaic
constructor: (@root, @selector, @http, @url) ->
@source = @root.querySelector @selector
@handler =
get: (target, property) ->
target[property]?.value
set: (target, property, value) =>
if @valid property then @sync()
@fields = new Proxy @source, @handler
valid: (property) ->
property isnt ''
addField: (field, value) ->
throw new Error "Can't append to DOM" unless @source.appendChild?
newField = @root.createElement 'input'
newField.value = value
@source.appendChild newField
sync: ->
throw new Error 'No HTTP specified' unless @http? and @url?
@http.post @url, JSON.stringify(@source), (response) => #B
for field, fieldResponse of JSON.parse response
if field of @source
@source[field].value = fieldResponse.value
else
@addField field, fieldResponse.value
The advantage of a Proxy approach is that it provides a way to unify an interface:
form = new Formulaic document, '#form', http, 'http://agtron.co/formulaic/1'
form.fields.login = 'scruffy1234'
You only change properties on an instance of the Formulaic class, but the underlying implementation can be communicating with the server and updating the view for you. In fact, the proxy can do anything in response to a get or set. Listing 13.5 shows one other use for proxies, by validating the field value to ensure empty strings are not used.
The fun doesn’t stop at proxies, though. Another exciting feature proposed for ECMAScript 6 is the addition of iterators, generators, and the concept of yield, which combine to finally give comprehensions real power.
13.3.5. Comprehensions, iterators, and generators
Comprehensions, iterators, and generators in ECMAScript 6 will be familiar to Python programmers. Why do they matter? Event streams. You’ll remember (from chapter 9) that composing programs with event streams is problematic. To improve these programs, you developed a fluent interface for asynchronous streams of events that abstracted away some of the complexity, giving you a cleaner programming model to work with. The combination of comprehensions, iterators, and generators can provide the same power at a different syntactic level.
First, though, you need to see how JavaScript is getting comprehensions very much like the ones you already know in CoffeeScript.
Comprehensions
ECMAScript 6 has array comprehensions similar to those you’re familiar with in CoffeeScript:

The only syntactic difference from CoffeeScript is some brackets and parentheses:
double (n) ->
n * 2
numbers = [2,3,5,4,2]
doubled = double number for number in numbers
Array comprehensions are nice, but they’re certainly no earth-shattering new feature. You might have noticed that in CoffeeScript too; the comprehensions are nice, but they’re fairly limited. That changes once iterators and generators are introduced; comprehensions become very powerful.
Consider some keyboard-handling code for a computer game. When the user presses the up-arrow, down-arrow, left-arrow, left-arrow, and down-arrow keys, then the data your program ultimately receives is an array (just like in chapter 9):
[UP, DOWN, LEFT, LEFT, DOWN]
Unfortunately, there’s a catch with this array—you don’t have it yet. When the game starts, you haven’t received any events, so you can’t use a comprehension on it because a comprehension works on values—not on values you’ll get later.
What if you could use a comprehension for these keyboard commands? What if comprehensions worked with arrays that you don’t have yet? With iterators and generators they do!
Iterators
So, what’s an iterator? Think of it as an object with a next method:

To use this iterator in ECMAScript 6, you need to declare it as an iterator property on the prototype of your object. In CoffeeScript, that means putting it in the class declaration:
class KeyboardEvents
iterator: keyCommandIterator
You iterate over an instance of KeyboardEvents with an ECMAScript 6 comprehension:

Now the potential for comprehensions starts to become apparent, but if you have a sweet tooth, it might not seem like very much sugar yet. Just making comprehensions work with objects that have a next method isn’t enough. That’s good, because it doesn’t end there. Comprehensions in ECMAScript 6 will also work with a new sort of function: a generator.
Generators
Comprehensions with objects and iterators work, but they’re a bit cumbersome. Suppose you don’t have a keyboard event object and a dedicated iterator. Instead, you just have a function that produces a value:
UP = 1
DOWN = -1
keyboardEvents = ->
if Math.floor Math.random()*10 > 5
UP
else
DOWN
Wouldn’t it be nice if there were some way to express a function that could work like an iterator on an object? You’d need some special syntax for a function that could give control back to the invoking function without being finished. There’s such a thing proposed for ECMAScript 6 called agenerator function. Instead of being evaluated and returning a value, a generator function yields values.
In order to support this new feature, ECMAScript 6 had to add new syntax to indicate that a function is a generator:

CoffeeScript will need to add new syntax to support the yield keyword for generators. One option is the starred arrow ->*:
keyboardEventGenerator = ->*
while true
if Math.floor Math.random()*10 > 5
yield UP
else
yield DOWN
At the time of writing, the actual syntax hasn’t been decided and CoffeeScript doesn’t currently support generators. Both the ECMAScript 6 specification and the CoffeeScript syntax to deal with it are still evolving.
A generator is like a function, but instead of just being evaluated, it can suspend execution and resume later. Being able to yield in the middle of a function means that the generator and the function that uses it work together. With regular functions, a function invocation always completes before the calling function resumes. In contrast, with generators, the calling function gets control back many times. That’s why generator functions are sometimes known as co-routines in languages where the equivalents of functions are known as routines.
Will these generators be useful in CoffeeScript? Absolutely. They’ll be useful in all those places where you’ve either ended up with event-emitter spaghetti code or have created your own abstraction to deal with them. Generators and comprehensions will give you more syntactic flexibility.
Language features in JavaScript are nice, but in the ever-expanding JavaScript universe, new languages are being invented almost daily. The rising popularity of compile-to-JavaScript languages (like CoffeeScript) means that runtimes need to find better ways to support them. One of the ways that JavaScript runtimes are starting to do this is with source maps.
13.4. Source maps for debugging
Debugging CoffeeScript by looking at the compiled JavaScript is difficult. An error in a running JavaScript program is easy to understand if the program was written in JavaScript but not so easy if the program was transpiled from another language such as CoffeeScript. So how do you use a debugger on a CoffeeScript program?
13.4.1. Why source maps?
You don’t really need the debugger to work, right? When you develop everything by writing a test first (see chapter 11), and your code doesn’t work, you can change a test or write a new test to see what’s happening. There’s some degree of truth in that, but it’s not practical. Even if you tend not to use it much, one day you’ll need the debugger and you don’t want to be presented with the compiled JavaScript version of your program.
Imagine a browser-based program you wrote—a program, any program, it doesn’t matter which one. Imagine now that you wrote this program in a file called (ingeniously) program.coffee. What do you see if the program throws an exception? You see text something like so:
Reference Error: x is not defined -- program.js 23
This is telling you that your program has thrown a reference error in line 23 of program.js. That’s nice, except that you didn’t write any program.js because you wrote your program in CoffeeScript! So what’s the problem?
The problem is not that CoffeeScript is compiled. There are many compiled languages with good debuggers. The problem is that the JavaScript runtime has no knowledge of your original CoffeeScript source, so it has no way to show you where the problem is in your original source. That changes with source maps. Source maps allow the CoffeeScript compiler to tell the JavaScript runtime how source lines in the JavaScript correspond to source lines in the original CoffeeScript source.
13.4.2. Getting started with source maps
To try CoffeeScript with source maps, you’ll need both a runtime that supports them and a CoffeeScript compiler that can create a source map. Right now, that means a CoffeeScript compiler version greater than 1.6 and a recent version of your web browser that supports source maps.[1]Before long, source maps will be supported by more runtimes.
1 Consult the documentation for your browser to determine if it supports source maps and how you can enable them.
To understand what they do, here’s a trivial program you can whet your source-maps appetite on:

Suppose the program is contained in a file called sourcemaps.coffee. You’re familiar with the standard way to compile:
> coffee sourcemaps.coffee
To generate a corresponding map file, you pass the -m or --map flag:
> coffee --map sourcemaps.coffee
The source map won’t make much sense because it’s not intended to be human readable. It’s a JSON file containing information that the runtime can use to map from the compiled JavaScript program to your original CoffeeScript source:
{
"version":3,
"file":" sourcemaps.coffee",
"sources":[
"sourcemaps.coffee"
],
"names":[],
"mappings":"AAAC;;;EAAA,MAAA,GAAS,SAAA,CAAA,KAAA,CAAA;;;MAAW,2BAAqB,aAArB,
aAAA,CAAA,KAAA,CAAA;QAAa,OAAQ;oBAArB,IAAA,CAAA,CAAA,CAAO;;;;;EAC3B,OAAO,IAAP,CAAY,MAAA,CAAO,CAAA;AAAA,IAAC,CAAD;AAAA,IAAG,CAAH;AAAA,IAAK,CAAL;
AAAA,IAAO,CAAP;AAAA,EAAA,CAAP,CAAZ;EACA,KAAA,CAAM,GAAA,CAAI,KAAJ,CAAU,
mBAAV,CAAN"
}
To use the source map, the runtime needs to be told where to find it. To tell the runtime where to find the source map, either put a comment in the compiled JavaScript or set an X-SourceMap header if the file is served over HTTP. You add a comment to the file like this:
echo '\n//@ sourceMappingURL=sourcemaps.js.map' >> sourcemaps.js
Now, consider that 'Using source maps' error that your program throws—how does it appear? When you run the program in an environment that doesn’t understand source maps, you’ll see the error reported in the compiled JavaScript file:
Uncaught Error: Using source maps
double -- sourcemap.js:5
That’s not very useful. An exception in compiled JavaScript when you’re writing your program in CoffeeScript is difficult to comprehend. In contrast, with source maps you’ll see the error reported in your original CoffeeScript program:
Uncaught Error: Using source maps
double -- sourcemaps.coffee:2
It gets better. Not only will you see errors on appropriate lines, but you’ll also be able to harness the full power of your favorite IDE on your CoffeeScript program. Stepping through and setting breakpoints will be done in your CoffeeScript source, and not in the generated JavaScript.
Enabling source maps in your browser
As with most configuration options, each browser will have a slightly different way of enabling source maps. As an example, Chrome 27 allows you to enable source maps via a check box in the settings for the developer tools. Consult the documentation for the relevant version of the browser (or other runtime) you’re using for details on how to enable source maps.
It’s still early days for source maps, so you’ll need to consult the documentation for your individual runtime to get them working. If you like to use the debugger, you can already see that it’s a useful tool.
The future will include JavaScript, but it’s not all JavaScript. Every day there are more languages that compile to JavaScript. Source maps go just that little bit further to opening up the JavaScript language to embrace them.
13.5. Summary
In this chapter you looked at the language ecosystem around CoffeeScript. Specifically, you saw how CoffeeScript not only benefits from advancements in the ECMA-Script specification but also contributes to them. Your deeper understanding of both current and future language features will ultimately make you a better CoffeeScript programmer.
As a CoffeeScript programmer, you also need tools like source maps. Support for those is emerging rapidly on runtimes, so by starting today you’ll be prepared for tomorrow (which will arrive sooner than you think). Regardless of whether you’re ultimately writing JavaScript, CoffeeScript, or a mixture of both, you’ll be better off for learning what the future holds. After all, learning and using are, to borrow a phrase from Scruffy’s high school English teacher, inexorably intertwined.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.