CoffeeScript in Action (2014)
Part 2. Composition
Chapter 8. Metaprogramming
This chapter covers
· Learning about literate CoffeeScript
· Constructing domain-specific languages
· Writing programs that write programs
· Being metacircular: CoffeeScript in CoffeeScript
The term metaprogramming is often used to refer to any programming technique sufficiently complicated that you should think thrice before using it. This chapter is not about writing complicated programs. Metaprogramming is also often used to refer to the use of metaobjects, where you create objects that create objects. This chapter is not about programming metaobjects—you were already working with metaobjects back in chapter 5. So, then, what is this chapter about?
The most succinct description of metaprogramming is programs that write programs. That’s what this chapter is about. More importantly, this chapter is about changing the way you think about your programs and the language you write them in. To begin thinking differently, you’ll start by swapping programs with program explanations through literate CoffeeScript. Next, you’ll explore the creation of miniprogramming languages as domain-specific languages (DSLs). Finally, you’ll look at programs that write programs and at how you can change the language you work in by using the CoffeeScript compiler from inside a CoffeeScript program.
8.1. Literate CoffeeScript
In literate programming, as first explained by Donald Knuth,[1] the visible structure of the program source isn’t the structure of the executable program. Instead, the visible structure of the program is an explanation of the program in another language. Interspersed code snippets make up the executable program. Inspired by the idea of literate programming, the CoffeeScript compiler supports source files where explanation determines the structure of the source code.
1 Donald Knuth is a computer scientist who is sometimes referred to as the father of the analysis of algorithms. His book Literate Programming was published in 1992.
Imagine that Agtron is trying to organize a birthday party for Scruffy. He sends you emails about it, but every time you leave your computer unattended, Scruffy reads your email and finds out what’s going on. As a deterrent to Scruffy reading the emails, Agtron wants a simple disguise for all of his emails so that Scruffy will have difficulty reading them. One simple way to disguise messages is by using a cipher called Rot13.
Rot13 is a simple letter-substitution cipher that replaces a letter with the letter 13 letters after it in the alphabet. The built-in string utility for getting character codes can be used. If the character is in the alphabet up to m, then add 13 to the character code. If the character is after m in the alphabet, then subtract 13 from the character code. Characters can be converted back using the built-in string method. A character is in a specific range regardless of whether it’s uppercase or lowercase. Finally, converting a string is done by converting all the characters and joining the results.
With literate CoffeeScript you use the description of a program, such as a description of Rot13, as the basis for the program itself. To differentiate them from regular CoffeeScript programs, literate CoffeeScript programs are contained in files with a special extension.
8.1.1. The .litcoffee file extension
Source code contained in a file with a .litcoffee extension is considered a literate CoffeeScript program by the compiler. The key difference between a regular CoffeeScript program and a literate CoffeeScript program is that the comments and the program are reversed. Instead of marking comments with #, you leave the comments raw and indent all of the executable code:
|
hello.coffee |
hello.litcoffee |
|
### Log 'Hello world!' to the console ### console.log 'Hello World!' |
Log 'Hello world!' to the console console.log 'Hello World!' |
As a further example, consider a literate CoffeeScript program using an excerpt from W. B. Yeats’s poem “The Wild Swans at Coole”:
W B Yeats
The Wild Swans at Coole
The trees are in their autumn beauty,
trees = [{}, {}]
for tree in trees
tree.inAutumnBeauty = yes
The woodland paths are dry,
paths = [{}, {}, {}]
for path in paths
path.dry = yes
Under the October twilight the water
Mirrors a still sky;
octoberTwilight = {}
stillSky = {}
water =
placeUnder: ->
water.placeUnder octoberTwilight
water.mirrors = stillSky
Upon the brimming water among the stones
Are nine-and-fifty swans.
water.brimming = true
water.stones = [{}, {}, {}, {}]
class Swan
x: 3
for n in [1..59]
water.stones.push new Swan
By writing the explanation first, you are forced to ponder how well the executable program matches the explanation. In other words, writing the explanation first can change how you think about your program.
Is it really literate programming?
Although Donald Knuth’s literate programming inspired literate CoffeeScript, important aspects of Knuth’s description are missing. That shouldn’t discourage you from taking full advantage of it, though.
Literate CoffeeScript files aren’t just for exploring poetry. A description of a program can serve as the starting point for creating a literate-style CoffeeScript program. Back to that Rot13 program then, how do you implement that with literate CoffeeScript?
Take the explanation of Rot13 and put it into a .litcoffee file. Then implement the program by putting indented program source throughout the explanation. The following listing shows a Rot13 program developed in exactly this way.
Listing 8.1. Literate CoffeeScript Rot13


A literate CoffeeScript file is also valid syntax for Markdown. This means that any text formatter that understands Markdown (there are many libraries for generating HTML that understand Markdown) can turn your program into a nicely formatted document.
If you prefer tests (discussed in chapter 10) and self-documenting code over comments, then you might not find the style of literate CoffeeScript to suit your taste for many programs. But even if literate CoffeeScript isn’t to your taste, you still share the motivation to write programs that are well explained. That motivation also drives the invention of domain-specific languages.
8.2. Domain-specific languages
CoffeeScript is a general-purpose programming language. It may be better suited to some tasks than to others, but the intention is that it can be used to solve any programming problem. In contrast, the intention of a DSL is to solve a particular type of problem.
This goes hand in hand with the idea that you should describe your program how you like and then worry about the implementation later. The way you like to describe your program may be a natural language such as English, a general-purpose programming language like CoffeeScript, or a more focused DSL designed to solve specific problems.
In this section you’ll learn the difference between internal and external DSLs; different techniques for creating internal DSLs using object literals, fluent interfaces, and functions; and finally how to approach the construction of an internal DSL.
8.2.1. External DSLs
Imagine for a minute that CSS doesn’t exist. How would you use CoffeeScript to style elements in a simple HTML document?
<html>
<p>
It is <strong>very</strong> important that you understand this...
</p>
Making text contained in a <strong> element bold and red could be done by directly manipulating those properties:
strongElements = document.getElementsByTagName 'strong'
for strongElement in StrongElements
strongElement.fontWeight = 'bold'
strongElement.color = 'red'
That would quickly get tedious. You could create a better syntax out of that, perhaps by declaring style rules with objects and then using those objects to style the elements:
strongStyle:
fontWeight: 'bold'
color: 'red'
strongElements = document.getElementsByTagName 'strong'
for strongElement in StrongElements
for styleName, styleValue of strongStyle
strongElement[styleName] = styleValue
With the object syntax, you very quickly arrive at syntax very similar to CSS. The limited vocabulary and small number of features make CSS a DSL. Although CSS is an entire language (an external DSL), a mini-language with a limited vocabulary is often useful in other contexts where an entire standalone language would be too time-consuming to implement. For those cases, you can create internal DSLs.
8.2.2. Internal DSLs
One well-known example of utilizing a DSL is the popular jQuery framework. Instead of directly using the APIs designed for DOM manipulation, jQuery provides a DSL that simplifies things. Another common use of an internal DSL is in a testing framework. For example, suppose you want to test if an array contains a particular item. Using only the assert module for Node.js works, but you might not find it expressive enough:

How about testing that a string contains another string?
assert 'fundamental'.indexOf('fun') >= 0
That works too. But all your tests are phrased in terms of the assertion library, which might not be very comprehensible to you when writing or reading tests. Testing frameworks often hide these things behind a convenient DSL that makes sense in a testing domain:
expect('fundamental').to.contain 'fun'
This is a minor shift, and for this example it’s actually more verbose. So why do it? It makes life easier for users. The more control you have over the language, the more power you have to create with it.
The most common approach to creating DSLs in CoffeeScript comes from JavaScript, and that’s to use a fluent interface. You don’t have to use a fluent interface, though, because CoffeeScript syntax is sparse.
8.2.3. Object literals
With very little in the way of syntax, CoffeeScript object literals are a useful tool for creating internal DSLs. Imagine Agtron standing next to your desk, coffee in hand. “There’s a law,” he states, “known as Zawinski’s law, that ‘Every program attempts to expand until it can read mail.’” If you’ll eventually need to write a program that deals with email, you might as well get some practice now.
Consider the format of the exchange between a client and a server using the Simple Mail Transfer Protocol (SMTP). In the following example, client requests are in bold and server responses are in regular-weight font:

You might implement your SMTP library by emulating the protocol:
class Smtp
constructor: ->
connect: (host, port=25) ->
send: (message, callback) ->
Would you expect users to adopt this interface?
smtp = new Smtp
smtp.connect 'coffeescriptinaction.com'
smtp.send 'MAIL FROM: scruffy@coffeescriptinaction.com', (response) ->
if response.contains 'OK'
smtp.send 'RCPT TO: agtron@coffeescriptinaction.com', (response) ->
What’s the problem with that? For one thing, it looks worse than the raw SMTP. The users of your API don’t even care how SMTP works or indeed whether their email is delivered using SMTP at all. Worse, you’re forcing users to either flatten your API calls themselves or live in nested callback hell. Not good, but what can you do instead?
Have some empathy and approach the problem as a user. How should it look? How do you want to define and send an email?
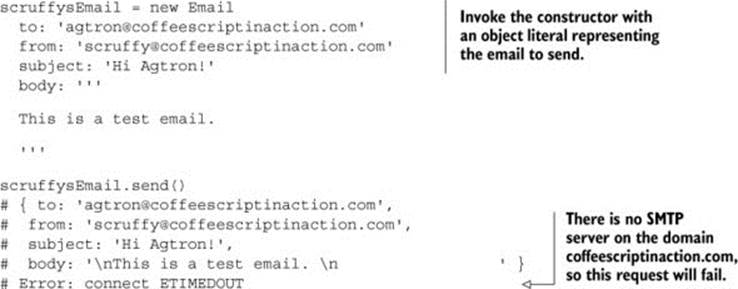
scruffysEmail = new Email
to: ''
from: ''
body: '''
'''
scruffysEmail.send()
This is simpler. Notice how any mention of SMTP is absent? A user doesn’t care about how SMTP works; they just want to send an email. It’s up to the mail library to determine how to connect to SMTP. Instead of copying the format of the protocol, copy the format that makes sense to people who use your library. Write the program in the language of the user.
The next listing shows this technique in action. This listing requires a dependency called simplesmtp, so if you intend to run it directly, you should first install the dependency:
> npm install simplesmtp
Once the dependency is installed, you can run the listing.
Listing 8.2. An object literal–based DSL for email (email.coffee)

Using the library provided by listing 8.2 doesn’t require the user to know SMTP:
Apart from object literals, what other ways are there to create a DSL in CoffeeScript?
8.2.4. Fluent interfaces
Object literal syntax works well for DSLs in CoffeeScript but not so well in JavaScript because with all the braces ({}) and semicolons (;), JSON tends not to feel very much like a language. This means that object literal DSLs are clunky in JavaScript, so if your CoffeeScript library will be used from inside a JavaScript program (quite likely), you should consider a different approach to your DSL by using a fluent interface (as discussed in chapter 7):
scruffysEmail = new Email
scruffysEmail
.to('agtron@coffeescriptinaction.com')
.from('scruffy@coffeescriptinaction.com')
.body '''
Hi Agtron!
'''
scruffysEmail.send (response) ->
console.log response
An implementation of this fluent-style DSL appears in the following listing.
Listing 8.3. A fluent interface–based DSL for email


Finally, CoffeeScript syntax supports a third way to create nice-looking DSLs.
8.2.5. Function passing
The option of omitting parentheses from function calls means that a DSL can be created in CoffeeScript using function composition only (discussed in chapter 6). This has the benefit of allowing a natural-looking DSL made entirely from function names. For example, consider a sendfunction that accepts another function as the parameter:
send = (next) ->
http.send next()
email = ->
The syntax is appealing:
send email (body 'Hi Agtron') to 'agtron@coffeescriptinaction.com'
Unfortunately, a DSL that uses function composition only is generally limited to a single line because of significant indentation. To get multiple lines, you might have to resort to using parentheses and line-continuing backslashes:
send email \
(body 'Hi Agtron!')\
(to 'agtron@coffeescriptinaction.com')
That makes DSLs based purely on the techniques of function composition a bit clunky in CoffeeScript. That said, there are other ways to use functions for DSLs more effectively, one of which you’ll see in the examples that follow.
8.2.6. Constructing a DSL
The lack of syntactic noise in CoffeeScript has meant that people attracted to the notion of writing DSLs have flocked to the language. Here are some examples of domains for which DSLs have been created in CoffeeScript and an accompanying syntax example that’s easily implemented in CoffeeScript. Implementing handlers for HTTP requests has been omitted here simply because you have, by now, seen it so many times that it would be rather uninteresting.
HTML
There are three basic ways that programmers deal with HTML from inside their own languages: templates, hooks, and language DSLs that allow them to compose HTML entirely inside their program. One way to compose HTML inside CoffeeScript is with a small DSL:
loggedIn = -> true
doctype 5
html ->
body ->
ul class: 'info', ->
li -> 'Logged in' if loggedIn()
Here’s the HTML generated by this CoffeeScript DSL (with newlines and indentation added for readability):
<!DOCTYPE html>
<html>
<body>
<ul class='info'>
<li>Logged in</li>
The nice thing about this approach to HTML is that you have the full power of CoffeeScript in your HTML. In the next listing you can see a basic implementation of this HTML DSL that supports a subset of HTML elements.
Listing 8.4. A basic DSL for HTML

The implementation in listing 8.4 supports only a very small subset of elements. But it does demonstrate how well the CoffeeScript syntax can be formed to match your needs. A similar approach can be applied to CSS.
CSS
CSS has traditionally adhered to the principle of least power. Unfortunately, over time least power has turned into insufficient power for many people. The most common approach to tackling the problem has been writing CSS preprocessors such as Less and Sass. CoffeeScript is also a preprocessor, so at a basic level, Sass is to CSS as CoffeeScript is to JavaScript.
An alternative approach to a preprocessor is to embed a DSL in CoffeeScript:

The output from this DSL is corresponding CSS:
ul {
font-weight: bold;
}
.x {
font-size: 2em;
}
The need to quote CSS selectors by putting them in strings makes the CoffeeScript DSL more awkward than raw CSS. In the following listing you can see an implementation of a small DSL for CSS.
Listing 8.5. A basic DSL for CSS

The final novel DSL you will look at is an SQL DSL in CoffeeScript.
SQL
With CoffeeScript’s liberal syntax, it’s tempting to attempt an SQL DSL that looks just like regular SQL by endlessly chaining functions:
SELECT '*' FROM 'users' WHERE 'name LIKE "%scruffy%"'
But SQL syntax is a little more complicated than you might think, and when you mix that with CoffeeScript’s significant indentation, it can get ugly. The simplest way to implement an SQL DSL in CoffeeScript is to use the object literal style:
query
SELECT: '*'
FROM: 'users'
WHERE: 'name LIKE "%scruffy%"'
Remember, property values can be evaluated at runtime. This can be powerful, but it might make your DSL too permissive:
query
SELECT: '*'
FROM: 'users'
WHERE: "name LIKE '%#{session.user.name}%'"
What if session.user.name contains something that should never appear in an SQL query? Correct handling of SQL connections, databases, and queries is complicated. When you create a DSL, be careful that what you create is appropriate to the domain.
Writing internal DSLs not only means bending the language to fit your needs but also means writing programs that target the needs of users, instead of focusing on implementation details that users don’t care about. What could be better than a program that’s easy to write? A program that you don’t have to write at all! How do you achieve this? Instead of writing programs all the time, you write programs that write other programs. There’s one program you already use that does this for you—it’s called the CoffeeScript compiler.
8.3. How the compiler works
The CoffeeScript compiler is written in CoffeeScript. The first CoffeeScript compiler was written in Ruby, but since version 0.5 the compiler has been implemented in CoffeeScript. That’s right, CoffeeScript is compiled using CoffeeScript, something you should spend some time to ponder, as Scruffy does in figure 8.1. The diagram that Scruffy is holding in figure 8.1 is called a Tombstone Diagram (or T-Diagram). If you’re interested in exploring compilers outside of this chapter, then you’ll likely come across more of them.
Figure 8.1. The CoffeeScript compiler is written in CoffeeScript.

Creating the initial compiler for a new language in an existing language and then using the new language to create another compiler that can compile the new language (and the compiler itself!) is known as bootstrapping a compiler. You need to know this about the CoffeeScript compiler because you’re about to make some changes to it.
Imagine that one night you’re drinking a coffee and relaxing with Scruffy and Agtron. Scruffy jokes that he’d like the function syntax for CoffeeScript to look like lambda calculus:

Scruffy laments that if only he had real macros in CoffeeScript, he could do what he likes. Agtron pauses, looks at Scruffy, and remarks, “Why don’t you just modify CoffeeScript? You could call your custom extension ScruffyCoffee.”
Use the source
The annotated source code for CoffeeScript is available online. Because CoffeeScript is written in CoffeeScript, you will, by now, be able to read it comfortably:
http://coffeescript.org/documentation/docs/coffee-script.html
To navigate to other parts of the documented source, use the Jump To link at the top right of the online CoffeeScript documentation pages.
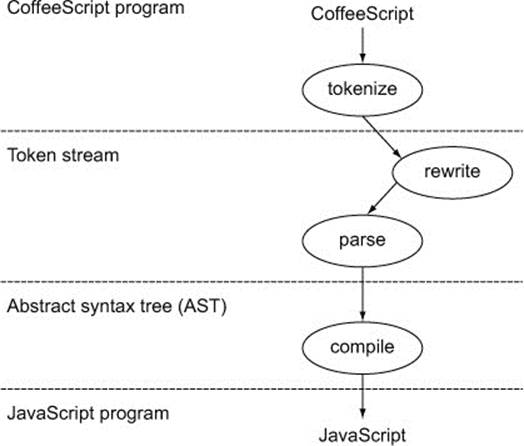
In order to make changes to the CoffeeScript compiler, you first need to understand what it does. As with many things in CoffeeScript, you can understand much of this by experimentation on the REPL. At a high level, the CoffeeScript compiler understands the CoffeeScript you provide it by first splitting it into tokens, performing some rewrites on those tokens, and then creating an abstract syntax tree that’s a representation of your CoffeeScript program. Figure 8.2 demonstrates the high-level steps that the CoffeeScript 1.6 compiler takes.
Figure 8.2. The internal CoffeeScript compilation process
To get a basic grasp of this process for CoffeeScript, consider the simple part of the CoffeeScript syntax that Scruffy wants to change: function syntax. The basic expression that you’ll examine in the CoffeeScript compiler is the identity function assigned to a variable I:
I = (x) -> x
The first thing the compiler must do is convert this string (input stream) to tokens.
Compiler versions
The CoffeeScript compiler version described here is CoffeeScript 1.6.2, so depending on the version of the compiler you have, the results you get when inspecting the compiler may be different (particularly regarding the things that get rewritten). But the general structure of the compiler will be the same, regardless of the version you’re using.
8.3.1. Tokenizing
During compilation, the first step is to use a lexer to covert the input into an array of tokens known as the token stream. Consider the tokens that the identity function assignment expression produces:

The lexer has generated tokens that represent the string of CoffeeScript code it was invoked with. Here’s a visual representation of how the tokens are broken down:

When tokenizing, it’s common for a compiler to ignore some things like comments and specific characters by not generating any tokens for them. Here, whitespace in the middle of the line has been ignored. In addition to skipping characters, the CoffeeScript compiler also modifies the token stream by adding tokens. Notice that the INDENT and OUTDENT tokens don’t correspond to any indentation in the original source string. The rewriter has added these tokens.
8.3.2. Rewriting
The myriad of syntax options in CoffeeScript means that tokenizing and building an abstract syntax tree for everything is a complicated task. Because some of the syntax is mostly convenience, CoffeeScript also has a rewriter that will modify the token stream. The rewriting done by the compiler is described here.
Implicit indentation
One of the things that you’ve just seen is that the rewriter adds implicit indentation. For example, when you write a function inline, the rewriter assumes that you meant it with indentation:
I = (x) -> x
The [INDENT] in the token stream is placed before the function body:
I = (x) ->[INDENT]x
Notice that indentation doesn’t require a newline. Of course, in practice you always think of indentation as being accompanied by a preceding newline because that’s the only way you can write it.
Newlines
The rewriter also removes some leading and mid-expression newlines:
a = 1
b = 2
Any important newline, such as one that indicates the end of an expression (a terminator) is preserved:

Further rewrites are performed for braces and parentheses.
Braces and parentheses
In most places, parentheses and braces are optional. This is convenient but can leave room for some ambiguity. The simplest way for the compiler to deal with these issues is with the rewriter:
I = (x) -> x
I 2
These common cases where parentheses are implicit and should be added are easy to see:

But more complicated examples can be difficult to discern. How do you tokenize this doozy?
f ->
a
.g b, ->
c
.h a
Probably you don’t tokenize it because you avoid writing code like that. Although you have the option to avoid writing ambiguous code, the compiler doesn’t have the same luxury. It must reliably accommodate the different styles, edge cases, and incidentally complex syntax of many programmers. Thus, the full rewriter for braces and parentheses is complicated. Finally, postfix conditionals need some special treatment by the rewriter.
Postfix
A postfix conditional such as play 'football' unless injured is convenient syntactic sugar but it poses a problem for the compiler, because it reads backwards. To deal with this, the CoffeeScript compiler tags postfix conditionals:

Why does the CoffeeScript compiler do all this rewriting? Because rewriting simplifies the next compilation step.
8.3.3. The abstract syntax tree
Once the compiler has a token stream, it’s ready to use it to create an abstract syntax tree (AST). Whereas the token stream represents the syntax of the program, the AST represents the meaning of the program in terms of the rules of the CoffeeScript grammar. Going back to the simple function expression for which Scruffy wants to provide an alternative syntax, what does the AST for that look like? To get the AST you invoke coffee.nodes with either a string of CoffeeScript or a CoffeeScript token stream:
coffee = require 'coffee-script'
expression = 'I = (x) -> x'
tokens = coffee.tokens expression
coffee.nodes tokens
# { expressions:
# [ { variable: [Object],
# value: [Object],
# context: undefined,
# param: undefined,
# subpattern: undefined } ] }
The default string representation of an object on the REPL lacks some details important for understanding what’s going on here. By using JSON.stringify and formatting the result, you can better see the AST:
console.log JSON.stringify coffee.nodes, null, 2
Now you see the AST object for the I = (x) -> x expression:
{
"expressions": [
{
"variable": {
"base": {
"value": "I"
},
"properties": []
},
"value": {
"params": [
{
"name": {
"value": "x"
}
}
],
"body": {
"expressions": [
{
"base": {
"value": "x"
},
"properties": []
}
]
},
"bound": false
}
}
]
}
Figure 8.3 contains a graphical representation of this AST. It demonstrates a remarkable uniformity and can give new insight into the nature of some expressions. For example, a function is a value with params and a body.
Figure 8.3. An example abstract syntax tree
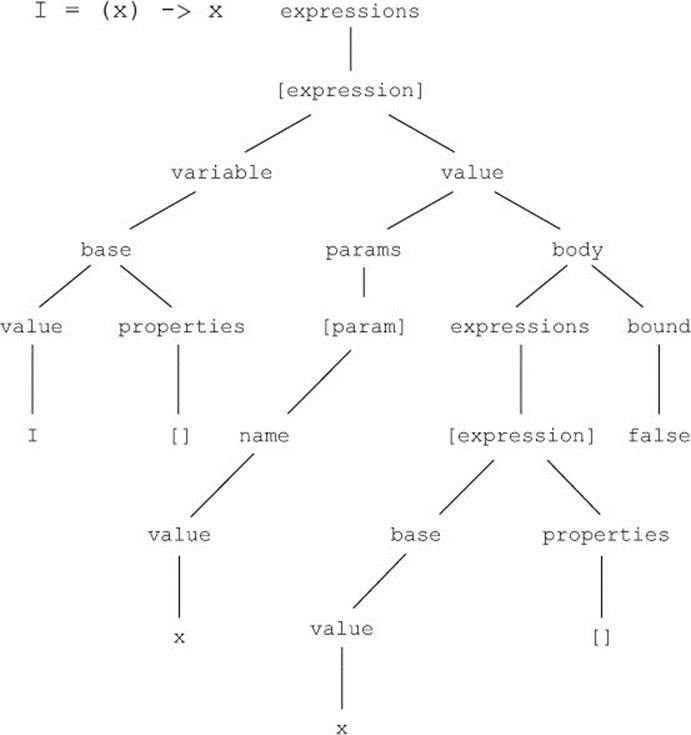
Now that you understand the tokens that are generated from your source code and the AST that’s generated from the tokens, you’re equipped to modify either (or both) of them to dynamically modify CoffeeScript source inside your CoffeeScript program. What does this mean? It means you can shape your program source to better match your ideas.
8.4. Bending code to your ideas
To really create a language you need to be able to modify the syntax. Although the internal DSL-making potential of CoffeeScript means you can create mini-languages for some tasks, you’re still fundamentally constrained to what CoffeeScript syntax accepts.
In order to stretch the language itself, you need to be able to modify it. For a compiled language like CoffeeScript, that means you need to intercept the compiler somehow. To do this you can either work with the compiler at the token or AST stage, or you can place something before or after the compiler. The easiest (though not the most sensible) way to do this is to just preprocess source code using eval.
8.4.1. Can you just eval?
JavaScript has an eval function that takes a string of JavaScript code and executes it in the running program. The string of code is evaluated as if you had written it directly into the program. For example, var declarations will go into the current scope. Try it on the Node JavaScript REPL:
node> eval('var x = 2');
node> x
node> # 2
The use of eval is considered dangerous because the code is executed with the privileges of the caller. This means that anything you eval can do anything that can be done at the point the eval was invoked. The eval function is dangerous, but it’s certainly interesting.
The CoffeeScript compiler also has an eval method that compiles and evaluates a string of program code. The difference with the eval provided by the CoffeeScript compiler (apart from the fact that it evaluates CoffeeScript) is that by default it sandboxes the code that it evaluates by running it in a separate context. The evaluation of the eval call is the evaluation of the code contained in the string:
coffee = require 'coffee-script'
coffee.eval '2'
# 2
evaluation = coffee.eval '2 + 4'
# 6
evaluation
# 6
But any variables in the evaled string are only defined in the sandbox:
coffee.eval '''
x = 1
y = 2
x + y'''
# 3
x
# Reference Error: x is not defined
y
# Reference Error: y is not defined
Still, the CoffeeScript eval allows you to execute arbitrary snippets of CoffeeScript code at runtime. Further, because it’s a string that you pass to the eval function, you can generate that string any way you like:
coffee = require 'coffee-script'
x = 42
y = coffee.eval "#{x} + 3"
y
# 45
This suggests an easy way to get Scruffy’s syntax. Use a regular expression to replace his expression with an equivalent function:
coffee = require 'coffee-script'
scruffyCode = '''
I = λx.x
'''
coffeeCode = scruffyCode.replace /λ([a-zA-Z]+)[.]([a-zA-Z]+)/g, '($1) -> $2'
identity = coffee.eval coffeeCode
identity 2
#2
hello = identity (name) -> "Hello #{name}"
# [Function]
hello 'Scruffy'
# 'Hello Scruffy'
In the listing that follows, you can see a tiny command-line CoffeeScript program that can execute a .scruffycoffee file using this technique. A .scruffycoffee file is simply a CoffeeScript program that also supports Scruffy’s desired λ syntax.
Listing 8.6. ScruffyCoffee with eval and regular expressions

Imagine the possibilities when you can evaluate arbitrary snippets of code. Now, stop imagining the possibilities and consider instead your responsibility to write comprehensible programs. Still, the presence of eval means you can metaprogram to your heart’s content with just a bit of string interpolation. Apart from the dangers, CoffeeScript isn’t very well suited for this.
The regular expression and eval solution aren’t really workable, and the program in listing 8.6 is very limited due to the simplicity of the regular expression. As you try to make the regular expression more complete, you’ll realize that you’re essentially just poorly reimplementing the CoffeeScript tokenizer for no good reason. Instead, you’ll be better off modifying the token stream or the AST.
8.4.2. Rewriting the token stream
A slightly less quick-and-dirty way to metaprogram (compared to evaluating strings) is to directly modify the token stream before the AST is generated. By doing that, you’re adding your own rewriter to the compilation process. Remember Scruffy’s desired syntax?
I = λx.x
How is it tokenized now?

Your rewriter will need to see the λ symbol and know that it needs to rewrite the rest of the expression to a function:

In the next listing you can see a new implementation of ScruffyCoffee that uses a custom rewriter instead of a nasty-looking regular expression.
Listing 8.7. Custom rewriter
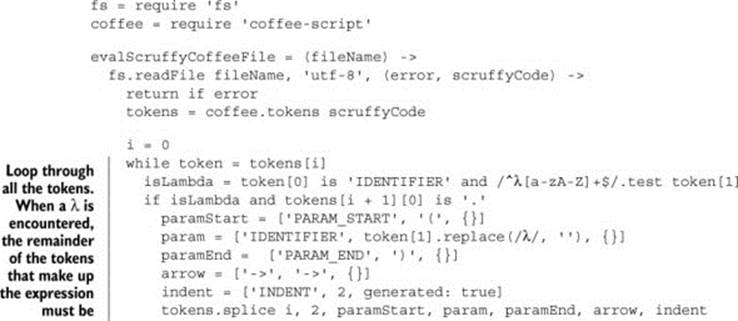
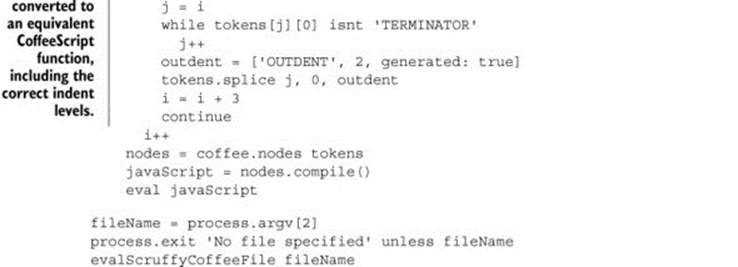
Messing around with the token stream is difficult, potentially dangerous, and overall not a whole lot of fun. Luckily, there’s a more structured representation of your CoffeeScript program that you can manipulate—the AST.
8.4.3. Using the abstract syntax tree
The next option available to you for implementing Scruffy’s lambda syntax is to modify the abstract syntax tree in place before generating JavaScript. The AST is excellent for analyzing source code.
Modifying programs
Imagine it’s opposites day and you want addition to replace subtraction (and vice versa) in your CoffeeScript program. How can you swap them? By manipulating the AST! First, use the compiler to generate an AST for the expression 2 + 1:
coffee = require 'coffee-script'
nodes = coffee.nodes '2 + 1'
The node for this addition expression has an operator and first and last properties representing the left and right sides of the operator, respectively:
addition = nodes.expressions[0]
addition.operator
# '+'
addition.first.base.value
# '2'
addition.second.base.value
# '1'
When you compile these nodes you get the JavaScript you expect:
nodes.compile bare: true
# 'return 2 + 1;'
Now, if you change a node, you’ll change the compiled output:
addition.operator = '-'
nodes.compile bare: true
# 'return 2 - 1'
Great! You know how to manipulate the AST, but what can you actually do with that?
Generating code
Imagine you’re working in a team and they don’t write tests. In the following listing you can see a basic implementation of using the AST to generate files that contain tests for class methods. This same technique could be used dynamically to look at code coverage.
Listing 8.8. Generating method tests via the AST
fs = require 'fs'
coffee = require 'coffee-script'
capitalizeFirstLetter = (string) ->
string.replace /^(.)/, (character) -> character.toUpperCase()
generateTestMethod = (name) ->
"test#{capitalizeFirstLetter name}: -> assert false"
walkAst = (node) ->
generated = "assert = require 'assert'"
if node.body?.classBody
className = node.variable.base.value
methodTests = for expression in node.body.expressions
if expression.base?.properties
methodTestBodies = for objectProperties in expression.base.properties
if objectProperties.value.body?
generateTestMethod objectProperties.variable.base.value
methodTestBodies.join '\n\n '
methodTestsAsText = methodTests.join('').replace /^\n/, ''
generated += """
\n
class Test#{className}
#{methodTestsAsText}
test = new Test#{className}
for methodName of Test#{className}::
test[methodName]()
"""
expressions = node.expressions || []
if expressions.length isnt 0
for expression in node.expressions
generated = walkAst expression
generated
generateTestStubs = (source) ->
nodes = coffee.nodes source
walkAst nodes
generateTestFile = (fileName, callback) ->
fs.readFile fileName, 'utf-8', (err, source) ->
if err then callback 'No such file'
testFileName = fileName.replace '.coffee', '_test.coffee'
generatedTests = generateTestStubs source
fs.writeFile "#{testFileName}", generatedTests, callback 'Done'
fileName = process.argv[2]
unless fileName
console.log 'No file specified'
process.exit()
generateTestFile fileName, (report) ->
console.log report
Listing 8.8 works on a file containing a class. Consider a file called elephant.coffee containing a class declaration:
class Elephant
walk: ->
'Walking now'
forget: ->
'I never forget'
When listing 8.8 is invoked with elephant.coffee, it generates a corresponding test class:
> coffee 8.8.coffee elephant.coffee
> # Generated elephant_test.coffee
The generated test file contains test stubs for all of the methods on the class:
assert = require 'assert'
class TestElephant
testWalk: -> assert false
testForget: -> assert false
test = new TestElephant
for methodName of TestElephant::
test[methodName]()
The AST is an excellent source of information about a program. Using the AST and a corresponding grammar is how the CoffeeScript compiler generates your JavaScript program. What’s a grammar? Agtron is glad you asked. The grammar is the definition for the semantic structure of the language. The grammar determines how the parser interprets the token stream. All 1.x versions of the CoffeeScript compiler use the Jison parser-generator (http://jison.org), so that’s a good place to start. If you want a new language, you should probably start from a clean slate. At heart, CoffeeScript is just JavaScript.
8.4.4. It’s just JavaScript
Amid all the excitement of modifying the CoffeeScript compiler to support whatever syntax takes your fancy on a given day, it’s easy to lose sight of the wider ecosystem. You see, it’s important that your CoffeeScript programs are still just JavaScript. Sure, JavaScript is increasingly becoming a compilation target for a wide range of different languages, but the power of CoffeeScript lies in only doing cleanups and being a small step from JavaScript for those people who want minimal syntax and can live with significant indentation.
Thus, Scruffy’s syntax using the λ character is probably not something you’d do in practice. But support for the upcoming JavaScript let syntax (discussed in chapter 13) is something that you might want to add:
let x = 3
console.log x
# 3
console.log x
# ReferenceError: x is not defined
Listing 8.9 shows Scruffy’s implementation of ScruffyCoffee that supports let by using a rewriter. This listing is invoked with an input file containing a let expression:
if true
let x = 2, y = 2
console.log 'let expression'
console.log 'wraps block in closure'
The generated JavaScript uses a function closure to approximate a let:
var ok;
ok = require('assert').ok;
if (true) {
(function(x, y) {
console.log('let expression');
return console.log('wraps block in closure');
})(2, 2);
}
ok(typeof x === "undefined" || x === null);
ok(typeof y === "undefined" || y === null);
Scruffy achieved the function closure by rewriting the token stream so that the let expression is replaced with a do that has the let variables as parameters. Any code at the same level of indentation as the let is then scoped inside the let:
do (x = 2, y = 2) ->
console.log 'let expression'
console.log 'wraps block in closure'
Scruffy’s implementation of let is limited. It supports only one let per block and it must be the first line. Also, because let is a word reserved by the CoffeeScript compiler, Scruffy had to rewrite the raw source before passing it to the tokenizer.
Listing 8.9. Scruffy’s let implementation using a custom rewriter
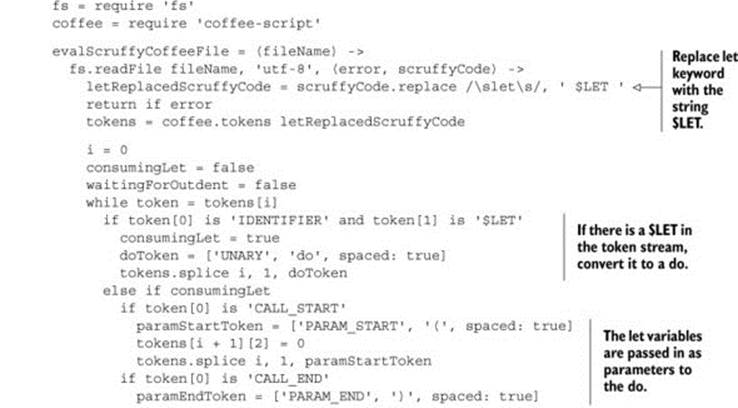

As before, modifying the token stream is possible, but it can be risky and is definitely not for the faint of heart. Scruffy achieved his implementation of let by rewriting source before tokenization and by rewriting the token stream, but it would also be possible to manipulate the AST instead of using a token rewriter. It’s your language, so for your circumstances it might make sense to completely change the syntax. You own the language.
8.5. Summary
Writing programs that write programs is what metaprogramming is all about. In this chapter you saw how literate CoffeeScript works and how it can change the way you think about program source. You then saw how to adapt existing CoffeeScript syntax and create domain-specific languages that provide a closer fit than plain CoffeeScript for certain types of problems. Finally, you saw how to modify CoffeeScript itself from inside a CoffeeScript program.
While learning what works in CoffeeScript, you also saw that CoffeeScript isn’t a Lisp. The CoffeeScript compiler is written in CoffeeScript, but it doesn’t have a meta-circular evaluator, and the eval function is mostly a distraction. Another way that CoffeeScript is not a Lisp is that it doesn’t have macros. That said, there are moves to implement hygienic macros in JavaScript. If you’re interested in that, then you should check out the sweet.js project (sweetjs.org). It’s also possible to create macros for CoffeeScript, but that’s a lesson for another day.
In the next chapter you’ll look at how the existing CoffeeScript syntax and semantics work in asynchronous environments.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.