CoffeeScript in Action (2014)
Part 2. Composition
Chapter 9. Composing the asynchronous
This chapter covers
· The limits of processing data synchronously
· How an event loop works and why you need to think asynchronously
· Events as data and data as events
· Event emitters and how to compose event streams
Remember imperative programs? They’re a bit like the list of chores that Scruffy’s mum used to leave him:
· Clean your room
· Take out the trash
· Do your homework
· No games until you finish your chores!
Scruffy could do the chores in any order, but he couldn’t play until the chores were finished. If everything is synchronous, then games just go after chores:
chores()
games()
You’ve learned about things that are asynchronous. If Scruffy pays Agtron to do his chores, then he can start his games immediately. Unfortunately, if Agtron never finishes the chores, then Scruffy is in big trouble. You learned that the solution to this in CoffeeScript is to use a callback:
chores games
This is the equivalent of Scruffy asking Agtron to tell him when the chores are done so that he can start playing games. It’s also the programming model used in almost all CoffeeScript programs.
Asynchronous programming changes the way that programs are structured. Further, not only are all programs in CoffeeScript asynchronous, but they also run on a single event loop. This presents unique challenges when you’re writing programs.
In this chapter you’ll start by processing some data synchronously and see how far you can get before a synchronous approach breaks down. Then you’ll see how to write programs using an asynchronous approach and learn how to manage the challenges that asynchronous programming presents.
9.1. Data processing
All programs need to deal with data: reading data in, processing (usually), and writing data out. Although the most common way to read, process, and write is synchronously, the synchronous approach quickly breaks down in a CoffeeScript program due to the nature of the event loop. In this section you’ll find out exactly why it breaks down and what you can do about it.
Imagine Agtron and Scruffy are organizing the World Volcano Mogul Skiing Championship. You’re working with them to display the names of competitors, one per second, on electronic billboards placed strategically across the volcano tops. The names must be displayed in alphabetical order, but they’re supplied in random order in a file called competitors with each line containing one competitor in the format Competitor number: Last name, First name:
0212: Turnbill, Geralyn
0055: Spielvogel, Cierra
0072: Renyer, Connie
0011: Engholm, Ciara
0088: Gitting, Estrella
The entire file contains 1,500 names. To sort the names, you’ll first need to read the file into an array. Suppose you’re using Node.js to do this, and that, without knowing any better, you’re doing it synchronously. What happens?
9.1.1. Reading
It’s possible to read a file synchronously in Node.js and then convert the response to an array:
fs = require 'fs'
raw = fs.readFileSync 'competitors', 'utf-8'
competitors = raw.split /\n/
But the standard approach is to read the file asynchronously and pass in a callback that’s invoked when the file is read:
readFile = (file, callback) ->
fs.readFile file, 'utf-8', (error, response) ->
throw error if error
callback response
Reading files asynchronously is the standard approach because doing things synchronously can have disastrous consequences, as you’ll soon see.
A function to get an array of the competitors asynchronously invokes the readFile function with another callback function that converts the response to an array:

This function can be invoked with a callback that prints the resulting array:
readFileAsArray 'competitors', (result) ->
console.log result
# ['0212: Turnbill, Geralyn'
# '0055: Spielvogel, Cierra'
# '0072: Renyer, Connie'
# '0011: Engholm, Ciara'
# '0088: Gitting, Estrella']
The asynchronous version might seem a bit inside out. So why bother doing things asynchronously? To appreciate this technique, try processing the data from the file.
9.1.2. Sorting
Array::prototype has a built-in sort method. When invoked with no arguments, the array is sorted in lexicographical order—like a dictionary:
[4,3,4,7,6].sort()
# [3,4,4,6,7]
['aardvark', 'zebra', 'porcupine'].sort()
# ['aardvark', 'porcupine', 'zebra']
Suppose you have the array of competitors assigned to a competitors variable:
competitors.sort()
# ['0011: Engholm, Ciara',
# '0055: Spielvogel, Cierra',
# '0072: Renyer, Connie',
# '0088: Gitting, Estrella',
# '0212: Turnbill, Geralyn']
You don’t just want the competitors sorted lexicographically, though; you want them sorted lexicographically by their last name.
Array::sort is destructive
Note that sort is destructive. The original array is sorted in place and returned:
sortedCompetitors = competitors.sort()
sortedCompetitors is competitors
# true
Being destructive means that the built-in sort isn’t well suited to function composition (discussed in chapter 6).
Sort comparator
To sort the competitors by last name, you first need a function that can compare competitors on their last name. This function takes two competitor names, determines their last names, and returns -1 if the first competitor should come first or 1 if the second competitor should come first:

When you invoke sort with compareOnLastName, the array is sorted, ordering the elements:
competitors.sort compareOnLastName
# ["0011: Engholm, Ciara"
# "0088: Gitting, Estrella"
# "0072: Renyer, Connie"
# "0455: Spielvogel, Cierra"
# "0212: Turnbill, Geralyn"]
This sorting is synchronous. There’s no callback—no way to say “go off and sort this array and let me know when it’s done.” It works, though, and a program that reads the competitors file, sorts the competitors on last name, and serves the sorted array wrapped in JSON ready to be used for the billboards is provided in the following listing.
Listing 9.1. Displaying names sorted on a field inefficiently


Running the application with the competitors file containing 1,500 competitors serves the resulting JSON at http://localhost:8888/:
> coffee listing.91.coffee competitors.txt
Loading data
Starting server on port 8888
Data loaded
If you visit this page in a web browser, you’ll see that the performance is fine. Nothing to worry about; the array is being sorted synchronously but it’s not hurting the program—not yet anyway. It’s tempting early on to assume that you only need to think asynchronous when reading things like files and network resources, but you soon find out that this is wrong. Read on.
9.1.3. Performance
Imagine now that Scruffy informs you there are not 1,500 competitors as anticipated but actually 150,000 competitors. He also says that he’s using the program you wrote, and it takes a long time to sort the 150,000 competitors. The application freezes for several seconds each time it loads data. You need to figure out what’s going on.
Timing programs
A crude but effective way to get a simple measurement of the time it takes for part of a program to execute is by using the built-in Date objects. To evaluate the time difference between two Date objects, you use subtraction:

With this, you can change the loadData function from listing 9.1 to show how long it takes to load data:
loadData = ->
start = new Date()
console.log 'Loading and processing data'
sortedCompetitorsFromFile fileName, (data) ->
elapsed = new Date() - start
console.log "Data loaded in #{elapsed/1000} seconds"
server data
It takes less than one-tenth of a second for 1,500 competitors, but for 150,000 competitors it takes 35 seconds! This is not simply due to sorting. Look how long it takes to sort an array of 150,000 numbers:

The built-in Array::sort can sort 150,000 random numbers in milliseconds, not seconds like your competitor sorting. The slow sorting is caused by the comparison function. Why? Because the compareOnLastName function is slow. When the array is sorted, every item might need to be compared to every other item! That’s more comparisons than you want to see written down, quite apart from the effect it has on the performance of your program. To avoid this problem, your first thought is to optimize the sorting to be fast enough.
9.1.4. Decorate, sort, undecorate
It’s always faster to do nothing than to do something. Consider what the something is that happens inside the compareOnLastName function:

Two last names are extracted for each comparison, which is expensive and unnecessary because the last name only needs to be determined once for each competitor. That can be done before any sorting occurs. A technique known as decorate-sort-undecorate, which uses this idea, is demonstrated here.
Listing 9.2. Decorate-sort-undecorate

The decorate function invoked with an array of strings containing competitor names returns an object with a sortOn property. This property contains the string used to compare the competitor to other competitors:
lastName = (s) -> s.split(/\s+/g)[1].replace /,/, ''
sortRule = (name) -> lastName name
decorate = (array) ->
{original: item, sortOn: sortRule item} for item in array
decorate ['0011: Engholm, Ciara']
# [{original: '0011: Engholm, Ciara', sortOn: 'Engholm'}]
The undecorate function does the reverse. It takes an object created by decorate and returns the original string:
undecorate = (array) ->
item.original for item in array
undecorate [{original: '0011: Engholm, Ciara', sortOn: 'Engholm'}]
# ['0011: Engholm, Ciara']
Now you can sort the array much faster. An example comparison between the performance with and without decorate-sort-decorate appears in table 9.1. Although actual results will vary significantly across different environments and computers, the decorate-sort-undecorate version is always substantially faster because it does less work.
Table 9.1. Performance improvement of decorate-sort-undecorate
|
Number of entries |
Decorate-sort-undecorate |
Original version |
|
500 |
0.003 seconds |
1.575 seconds |
|
3,000 |
0.024 seconds |
4.866 seconds |
|
150,000 |
0.116 seconds |
18.138 seconds |
Decorate-sort-undecorate is a useful technique. Eliminating repeated computation of the same thing makes the array sorting perform fast enough to be acceptable without making the program freeze for a long time. It’s just barely avoiding the problem, but sometimes avoiding the problem is exactly the right approach.
You can’t always avoid the problem, though. CoffeeScript programs run on an event loop, and an event loop does only one thing at a time.
9.2. Event loops
CoffeeScript programs, whether on Node.js or in a web browser, are executed on a single-threaded event loop where only one thing ever happens at a time. If you try to make something happen (like evaluating a CoffeeScript expression) while something else is happening, then the new thing will have to wait until the first thing is finished. To keep your CoffeeScript program from locking up, you need to adopt particular asynchronous programming techniques that are suited to a single-threaded event loop. In this section you’ll learn how to do that.
Imagine that your billboard code was so successful that Joe from Million Corporation phones you to say he wants to use it for the Intergalactic Volcano Mogul Skiing Championships. He says there are approximately 1.5 million names. A decorate-sort-undecorate version of the application with these 1.5 million names makes your program unresponsive:
Loading and processing data
Starting server on port 8888
Data loaded in 5.482 seconds
Agtron happens to be walking past (his timing is impeccable). He looks at what you’re doing, smiles, and asks if he can show you something. He shows you what’s happening while your program is sorting all those competitors by adding a setInterval intended to log to the console once per second:
start = new Date()
setInterval ->
console.log "Clock tick after #{(new Date()-start)/1000} seconds"
, 1000
You expect to see a clock tick each second, but that’s not what happens:
Loading and processing data
Starting server on port 8888
Data loaded in 4.636 seconds
Clock tick at 4.643 seconds
Clock tick at 4.643 seconds
The program does only one thing at a time. If it spends 5 seconds sorting an array, then nothing else happens during those 5 seconds—the event loop experiences a blackout. Then, once the event loop is free, you see two events that have been waiting to be handled occur immediately one after the other.
9.2.1. Events and blackouts
When something happens that the event loop needs to handle, then the event loop receives an event. For example, when you evaluated the setInterval call with a function and a delay of 1,000 milliseconds, you were requesting that an event occur on the event loop in 1,000 milliseconds and for the function you supplied to be invoked as the handler for the event:
setInterval ->
console.log "Clock tick after #{(new Date()-start)/1000} seconds"
, 1000
Similarly, when you request a file to be read asynchronously, you’re asking the file to be read outside of the event loop and for an event to be triggered on the event loop once the file has been read. Again, the function you supply is the handler that will be invoked when the event occurs:
fs.readFile 'myFile.txt', (err, data) ->
console.log 'invoked as the handler when the event occurs'
Because an asynchronous file read occurs outside of the event loop, the time it takes for the response to come back doesn’t affect the event loop. Other events can be handled and other computations can be done until the response comes back. In figure 9.1 you can see other events being handled as they arrive on the event loop while asynchronous requests are requested and the results are awaited.
Figure 9.1. Asynchronous I/O doesn’t block the event loop.
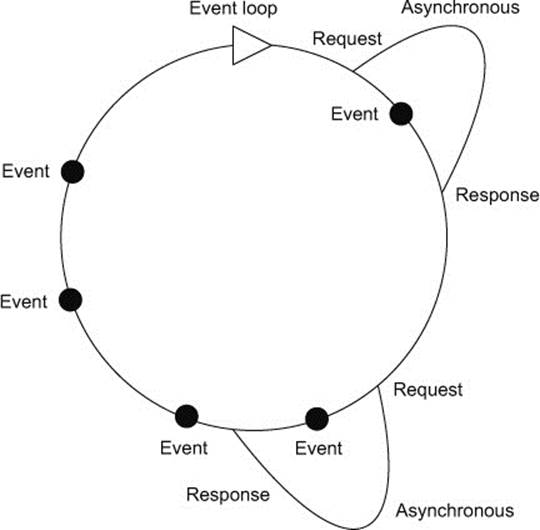
An event loop like the one in figure 9.1 is in good shape because nothing is blocking it. If it takes 2 seconds to get a response for a request back from a web service somewhere on the other side of the world, that doesn’t matter because it’s happening asynchronously. The program will carry on doing other things until the response comes back, at which point the response is added to the event queue and processed at the next available time.
What does an event loop in poor shape look like? Well, if a program spends a lot of time processing something synchronously, such as sorting a list of a million or more competitors, the event loop will be blocked for a long time and the program will experience a blackout while it waits for the synchronous operation to complete before doing anything else. That’s exactly what happens if you try to read a massive file synchronously,
dataForMyMassiveFile = fs.readFileSync 'myMassiveFile.mpg'
or when you try to synchronously sort a million competitors by their last name. In figure 9.2 you see an event loop in a poor state with a synchronous, blocking operation on the event loop. Notice how nothing else happens during the synchronous block and how two events that have had to wait for it to complete are handled shortly after.
Figure 9.2. Blocking the event loop stops the world.
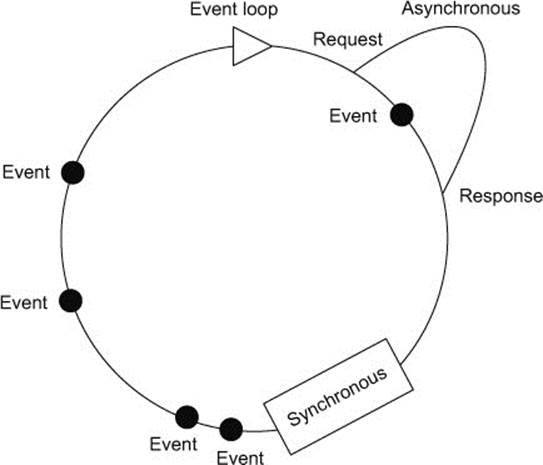
The event loop is the wrong place to do heavy processing. You can get away with sorting 15,000 competitors if you do it efficiently and infrequently, but you won’t get away with sorting millions of competitors. A program on the event loop must respond quickly to incoming events. If it spends all the time processing things, that defeats the purpose. Besides, some things aren’t just large—they’re infinite.
9.2.2. Infinite time
How do you deal with a data source that never ends? Think about how you kept track of the most popular pages on a website in chapter 3. You didn’t try to load all of the data; after all, that would be impossible because the data never finishes. Trying to load it all at once is effectively the same as doing this:
loop 0
Not desirable. In figure 9.3 you can see Agtron and Scruffy play out what might happen if Agtron ran on an event loop.
Figure 9.3. Don’t block the event loop—unless you like to wait.

The solution when you have a source of data that doesn’t end (like a list of names that keeps getting new names added to it) is to treat it as a source of events. This is what event emitters are used for.
9.3. Event emitters
Website traffic is data that comes from users. Users are an excellent place to start looking at event emitters. Imagine that you’re building a browser-based version of the 1972 classic Atari game Pong, as shown in figure 9.4. In this game the users control the movement of the paddles up and down on the screen to hit the ball back and forth across the screen.
Figure 9.4. In your version of Pong, the user controls the paddle with the keyboard.
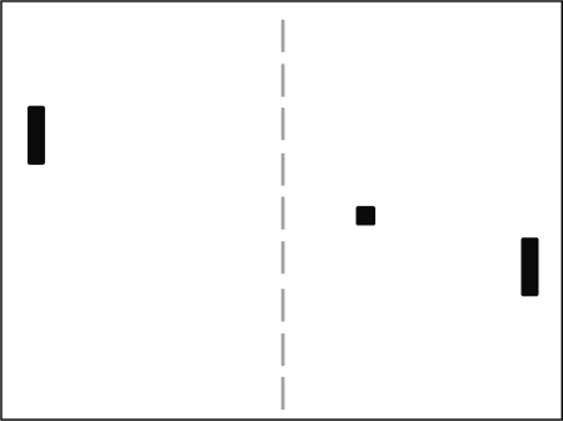
User data doesn’t stop until the game stops, so it’s effectively infinite. How is it processed?
9.3.1. User events
Anything that’s done asynchronously on the event loop (like reading a file) causes an event to be triggered when it’s done. There’s another important type of event that you don’t request (not directly anyway) but that you definitely want to listen to and handle. That type of event is the user event.
How do you handle user events in a CoffeeScript program? By attaching a handler to them. For example, start by attaching an event handler for keydown events:

What does this have to do with reading data? Consider this sequence of keydown events that occurred during a game of Pong:
UP, DOWN, DOWN, DOWN, UP, DOWN, UP, UP, UP
It’s an array. It’s just that at the start of the game you don’t have any of the data, and at the end of the game you have all the data. You don’t wait until all the keydown event data arrives before doing anything—that wouldn’t make for a very fun game. You process data as it arrives. The same can apply to any source of data; it can be treated as a source of events.
9.3.2. Data as events
If you treat a data source as a source of events, you can read and process parts of it asynchronously as each part arrives. Remember that blocking the event loop causes other events to queue up, as happened when your program spent almost 5 seconds waiting for some data to be loaded and processed:
Loading and processing data
Starting server on port 8888
Data loaded in 4.636 seconds
Clock tick at 4.643 seconds
Clock tick at 4.643 seconds
What does the data actually look like, though? Compare it to the keydown data from the game of Pong:
# competitor data
["0011: Engholm, Ciara", "0088: Gitting, Estrella", "0072: Renyer, Connie"]
# keypress data
[UP, DOWN, DOWN, DOWN, UP, DOWN, UP, UP, UP]
They’re both arrays. So, if a source of events (an event emitter) can produce an array, then you can use one to produce the competitor data. What does it look like if the source of the competitor data is an event emitter? Consider a function that takes a callback as a parameter that it invokes once per second with the value 'A competitor'. New data is produced and passed to the callback asynchronously:
ONE_SECOND = 1000
start = new Date()
competitorEmitter = (callback) ->
setInterval ->
callback 'A competitor'
, ONE_SECOND
receiver = (data) ->
now = new Date()
elapsed = now - start
console.log "#{data} received after #{elapsed/ONE_SECOND} seconds"
competitorEmitter receiver
# A competitor received after 0.995 seconds
# A competitor received after 1.995 seconds
# A competitor received after 2.995 seconds
# A competitor received after 3.995 seconds
This can also be wrapped up into a DataEmitter class:

This event emitter is a fake, but it helps to show what an event emitter does. In Node.js there’s an EventEmitter class in the core events module.
9.3.3. Using event emitters in Node.js
The EventEmitter in the core Node.js events module is a JavaScript class that you can extend in your own CoffeeScript program:
{EventEmitter} = require 'events'
class CompetitorEmitter extends EventEmitter
If the CompetitorEmitter is going to emit competitors as it reads them, then it doesn’t make sense for it to load the entire competitors source file in one go. Instead, it should open the source file as a stream using createReadStream from the Node.js core fs module:
fs = require 'fs'
sourceStream = fs.createReadStream 'competitors.txt'
The createReadStream method returns a Stream, which extends EventEmitter. It allows a file to be read in chunks instead of waiting to load the whole file.
The following listing contains a CompetitorsEmitter that reads the competitors file and emits arrays of competitors while the file is being read.
Listing 9.3. Sort competitors from stream


When the program in listing 9.3 is executed, the events generated by setInterval aren’t forced to wait long for the event loop. Note that for this program to run, you’ll need a competitors.15000.txt file in the same format as the previous competitors files:
> coffee 9.3.coffee
There are 1468 competitors
There are 2937 competitors
There are 4406 competitors
Tick at 0.121
...
Now that the data is being loaded as a stream and sorted as it arrives, the processing is broken up into multiple blocks. This means that the event loop isn’t blocked for a long, continuous time. Instead, the event loop is blocked for multiple smaller chunks of time, as shown in figure 9.5 and by comparison to figure 9.3.
Figure 9.5. Don’t wait forever. Treat input as a series of events and process it as it arrives.
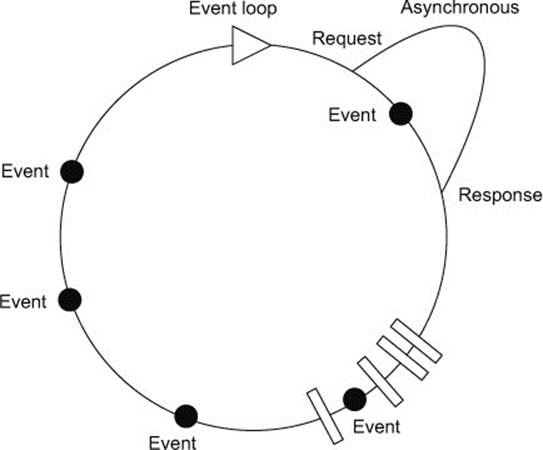
There’s only one event loop, and the event loop is the wrong place to do data processing. It’s reasonable to do some processing to generate responses to events, but anything that you expect will take time should be done offline or handled outside of the event loop.
Where should data processing be done?
If your application needs to process something that you know will take a long time, then it simply has to be done outside the event loop. Send the processing somewhere else (to another program) with a callback so that it can be done asynchronously, with your program being notified when it’s done.
How does the solution in listing 9.4 perform with a list of 1.5 million names? It doesn’t block the event loop for 5 seconds, but it does take minutes to complete (try to execute it and go make yourself a coffee while you wait). Despite the slow performance, by treating the data source as an event emitter you’re able to process the entire list without blocking the event loop. The same approach works in reverse—just as data can be treated as events, so can events be treated as data.
9.3.4. Events as data
Suppose now that the competitor data also contains the fastest time for each competitor on a particular ski run:
0212: Turnbill, Geralyn, '12:13'
0055: Spielvogel, Cierra, '11:55'
0072: Renyer, Connie, '11:33'
0011: Engholm, Ciara, '14:10'
You receive a call from Joe, who says that he wants to display only competitors who have a best time faster than 12:00. It’s tempting to modify the existing code to add the condition:
for item in chunk
insertAt = 0
if scoreBetterThan item, '12:00'
toInsert = { original: item, sortOn: lastName(item) }
for competitor in @competitors
if toInsert.lastName > competitor.lastName
insertAt++
@competitors.splice insertAt, 0, toInsert
Wait a minute! What happens when Joe asks you to show only competitors with names starting with J or those with competitor numbers starting with 02? Remember that the data is really an array. It’s being loaded asynchronously, but it’s still an array. If it were an array of data, you wouldn’t write a big for loop with a bunch of conditionals. Instead, you’d use array methods such as filter. What would that look like?

If the data is really an array, then that’s how you’d like to process it. The problem is that you don’t actually have the array—not yet anyway. Think about it, though; you don’t need to process any of the data until the values are needed somewhere else in the program. The manipulations that will be done on the data when it’s actually needed can be defined up front, before any of the data is available. Treating a series of asynchronous events as an array is an abstraction—one that makes it easier to compose events in familiar ways.
9.4. Event composition
In this section you’ll see how to hide the plumbing of an event emitter to make it easier to compose events. This starts by learning to be lazy.
9.4.1. Lazy data handling
The data that you have now and the data that you’ll have as the result of a series of events isn’t as different as you might think. In a sense, the difference is that an array is an expression of the value:
['Geralyn Turnbull', 'Connie Renyer']
Whereas the data that you don’t have yet is like a function that returns the data:
-> ['Geralyn Turnbull', 'Connie Renyer']
The first expression is the data itself; the second returns the data when invoked. This makes a good starting place on the road to composing asynchronous events.
Imagine that you need to do more with the list of names than just display them; imagine that you want to put them into a phone book like the one from chapter 4:
phoneNumbers = [
{ name: 'hannibal', number: '555-5551', relationship: 'friend' }
{ name: 'darth', number: '555-5552', relationship: 'colleague' }
{ name: 'hal_9000', number: 'disconnected', relationship: 'friend' }
{ name: 'freddy', number: '555-5554', relationship: 'friend' }
{ name: 'T-800', number: '555-5555', relationship: 'colleague' }
]
To get an array containing only friends, you either use a comprehension with a when clause or the Array::filter method. In this case, use filter:
relationshipIs = (relationship) ->
(item) -> item.relationship is relationship
phoneNumbers
.filter(relationshipIs 'friend')
Suppose, though, that you don’t have the data but a function that returns the data:
getPhoneNumbers = -> phoneNumbers
You’ll remember writing fluent interfaces in chapter 7. Here goes another one; suppose you call it withResultOf:
withResultOf(getPhoneNumbers)
.filter(relationshipIs 'friend')
The withResultOf function will need to return an object that has a filter method:
withResultOf = (fn) ->
filter: ->
At some point in the program, you’ll need the actual data itself. Call this method that returns the data evaluate:

By now, this is a familiar pattern: some imperative code hidden behind a largely functional interface:
withResultOf(getPhoneNumbers)
.filter(relationshipIs 'friend')
.evaluate()
# [
# { name: 'hannibal', number: '555-5551', relationship: 'friend' },
# { name: 'hal_9000', number: 'disconnected', relationship: 'friend' },
# { name: 'freddy', number: '555-5554', relationship: 'friend' }
# ]
But you don’t have to evaluate it immediately. You might want to call it later or pass it to another function. This is lazy because the computation is defined early, but the evaluation occurs only when evaluate is invoked. This is very different from just determining the computation later on.
Just like a function, this event stream filter is now first-class. For example, one of your work colleagues wants to sync live with your business contacts. You can easily send him a filtered event stream:
withResultOf(getPhoneNumbers)
.filter(relationshipIs 'business')
When he wants to use it, he evaluates it and gets the values up to now, filtered:
suppliedContacts.evaluate()
That technique works for data streams or functions that actually return the values. But when you look at your event-driven program, the functions don’t return the values at all; they invoke a callback with the return value:
fs.readFile, 'filename', callback
So, how can you extend withResultOf to work for asynchronous functions that invoke callbacks?
9.4.2. Lazy event handling
Consider again the data for the phone book. This time it’s not returned by a function but instead passed as an argument to a callback:
phonebookData = (callback) ->
callback [
{ name: 'hannibal', number: '555-5551', relationship: 'friend' }
{ name: 'darth', number: '555-5552', relationship: 'colleague' }
{ name: 'hal_9000', number: 'disconnected', relationship: 'friend' }
{ name: 'freddy', number: '555-5554', relationship: 'friend' }
{ name: 'T-800', number: '555-5555', relationship: 'colleague' }
]
If the phone book is an event emitter, then it’s still callback-driven, except that the callback is called repeatedly as new data arrives:
phonebook.on 'data', callback
The sequence of values produced by an event emitter is an array; you just don’t have all of the values yet. Think of the array of keyboard commands that were produced during the running game of Pong—it was also produced by an event emitter (a user):
[ UP, DOWN, DOWN, DOWN, UP, DOWN, UP, UP, UP ]
An event emitter generating the phone book doesn’t change what the data looks like. Instead of letting the source of the data dictate how you use it, decide on the interface you want first, and then figure out how to make it work.
9.4.3. Composing event streams
Suppose the phone book information is arriving asynchronously, with each subsequent chunk arriving as it becomes available. The source of the data is an event emitter named phonebookEmitter that may or may not stop producing more events. Now suppose that you want to filter the phone book to just friends. The interface that you want is one that matches what you use for an array:
phonebook = \
withEvents(phonebookEmitter)
.filter(relationship 'friend')
You start by trying this on a different source of events so that you can control what’s happening. Create your own event emitter that emits numbers:
{EventEmitter} = require 'events'
even = (number) -> number%2 is 0
emitter = new EventEmitter
evenNumberEvents = withEvents(emitter, 'number').filter(even)
emitter.emit 'number', 2
emitter.emit 'number', 5
When evaluate is invoked, you expect to get an array containing only the even numbers:
evenNumberEvents.evaluate()
# [2]
If more events occur, then invoking evaluate again will show the even numbers up to that point:
emitter.emit 'number', 4
emitter.emit 'number', 3
evenNumberEvents.evaluate()
# [2,4]
The expression for the filtered events is like a function expression:
withEvents(emitter, 'number').filter(even)
It can be passed around inside a program without being evaluated. So how do you implement it? In the next listing you see a working phone book application with filtering capabilities. Note that this listing reads a file called phone_numbers.csv that looks like this:
hannibal,555-5551,friend
darth,555-5552,colleague
hal_9000,disconnected,friend
freddy,555-5554,friend
T-800,555-5555,colleague
dolly,555-3322,associate
This phone_numbers.csv file is included with the book’s downloadable content.
Listing 9.4. Phone book with data loaded from event stream
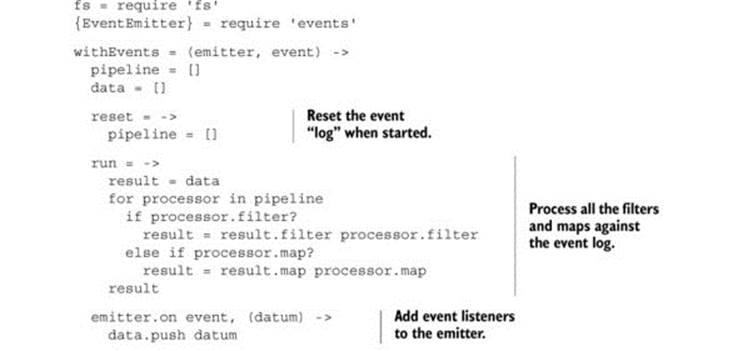


The same technique works for other sources of events. Using the withEvents function, you can map and filter user events, such as keyboard interaction.
9.4.4. Client side
It’s time to look at that game of Pong again, because the same technique that worked for a data stream works for user input data. The paddles in a game of Pong are moved up and down the screen based on keyboard presses performed by the players. Suppose the game of Pong will run in a browser and that the HTML structure is as follows:
<!DOCTYPE html>
<html dir="ltr" lang="en-US">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Pong</title>
</head>
<body>
<div id="pong"></div>
</body>
<script src="9.5.js"></script>
</html>
Attaching a handler to keyboard events means that the data supplied by the keyboard (the key presses) is received:
document.on 'keypress', (event) ->
console.log 'The keyboard was pressed'
Sure, you could write an entire program inside the keypress handler, but that will eventually lead to event handler spaghetti. In the next listing you see the paddle-controlling code for Pong implemented by treating the key presses as a stream of event data. Compile this listing and use it with the sample HTML shown previously to experiment.
Listing 9.5. Controlling paddles in a web browser


There are other ways to structure this (perhaps without a paddle class), but it’s important to see how the program is broken up into small composable units even though it’s handling multiple users. Regardless of the source of events, this technique helps you to manage event streams. With first-class functions and a terse syntax for both functions and objects, CoffeeScript makes it possible to write readable code.
9.4.5. Multiple event sources
That works for a single source of events, but what happens when you have multiple sources of events? Suppose you have two sources of data:
source1 = [13,14,15]
source2 = [23,24,25]
For arrays, to zip them means to create a new array by interleaving the two arrays together, like a zipper:
zip = (a, b) ->
zipped = []
while a.length or b.length
do ->
fromA = a.pop()
fromB = b.pop()
if fromB then zipped.push fromB
if fromB then zipped.push fromA
zipped.reverse()
zip source1, source2
# [13,23,14,24,15,25]
Streams of events, when treated as arrays, can be zipped together in the same way. With two event streams where the source order doesn’t matter, zipping them together as they arrive is done in the same way as two arrays are zipped together.
9.5. Summary
In this chapter you started by processing data synchronously and quickly learned how you are guaranteed that heavy processing, no matter how well optimized, will eventually break your program if you try to do it all synchronously on the event loop. That wasn’t the end of the story, though, and you later learned that large or infinite data could be handled effectively as event streams.
You also learned that changing the way you looked at events and treating them as streams made them easier to compose. Because all CoffeeScript programs run on an event loop with callbacks and event handlers, if you repeatedly add more and more event handlers and scatter related program code in unrelated parts of a program, you’ll quickly find your program to be incomprehensible. By thinking of event emitters as sources of data, you can apply familiar techniques such as mapping and filtering to help make them more manageable.
When writing all of this code, how do you know it does what it’s supposed to do? In the next chapter you’ll learn about test-driven development and how to ensure your CoffeeScript programs are well tested.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.