Functional Thinking (2014)
Chapter 6. Advance
If the primary paradigm that your language supports is objects, it’s easy to start thinking about solutions to every problem in those terms. However, most modern languages are multiparadigm, meaning that they support object, metaobject, functional, and other paradigms. Learning to use different paradigms for suitable problems is part of the evolution toward being a better developer.
Design Patterns in Functional Languages
Some contingents in the functional world claim that the concept of the design pattern is flawed and isn’t needed in functional programming. A case can be made for that view under a narrow definition of pattern—but that’s an argument more about semantics than use. The concept of a design pattern—a named, cataloged solution to a common problem—is alive and well. However, patterns sometimes take different guises under different paradigms. Because the building blocks and approaches to problems are different in the functional world, some of the traditional Gang of Four patterns disappear, while others preserve the problem but solve it radically differently.
In the functional programming world, traditional design patterns generally manifest in one of three ways:
§ The pattern is absorbed by the language.
§ The pattern solution still exists in the functional paradigm, but the implementation details differ.
§ The solution is implemented using capabilities other languages or paradigms lack. (For example, many solutions that use metaprogramming are clean and elegant—and they’re not possible in Java.)
I’ll investigate these three cases in turn.
Function-Level Reuse
Composition—in the form of passed parameters plus first-class functions—appears frequently in functional programming libraries as a reuse mechanism. Functional languages achieve reuse at a coarser-grained level than object-oriented languages, extracting common machinery with parameterized behavior. Object-oriented systems consist of objects that communicate by sending messages to (or, more specifically, executing methods on) other objects. Figure 6-1 represents an object-oriented system.
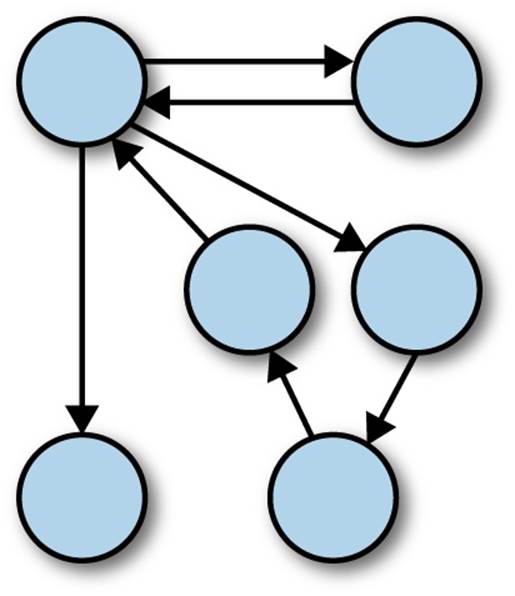
Figure 6-1. Reuse in an object-oriented system
When you discover a useful collection of classes and their corresponding messages, you extract that graph of classes for reuse, as shown in Figure 6-2.
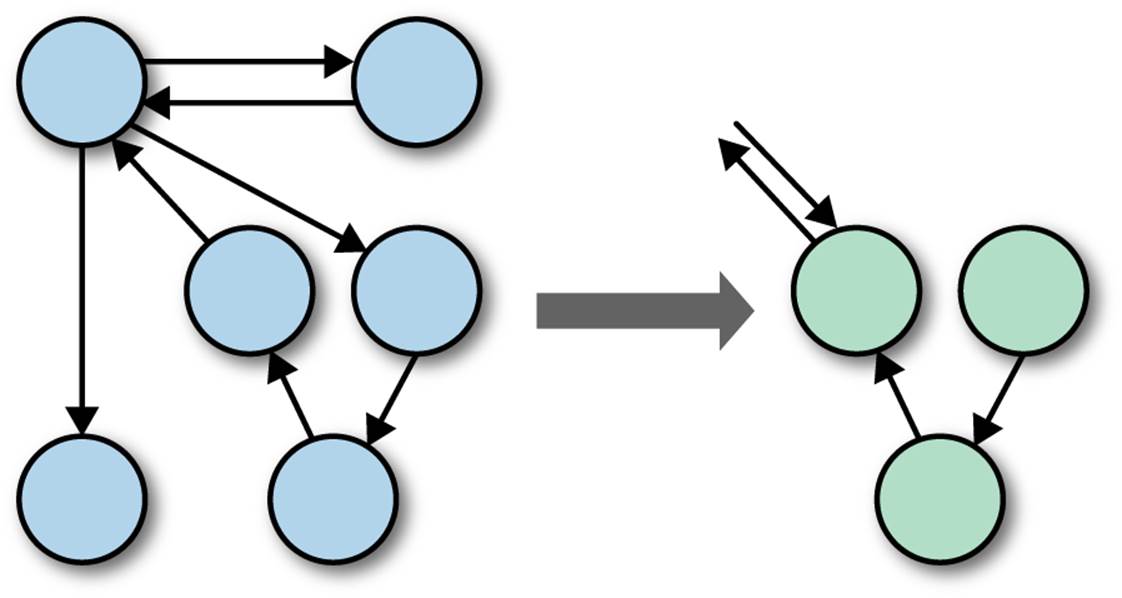
Figure 6-2. Extracting useful parts of the graph
Not surprisingly, one of most popular books in the software-engineering world is Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1994), a catalog of exactly the type of extraction shown in Figure 6-2. Reuse via patterns is so pervasive that numerous other books also catalog (and provide distinct names for) such extractions. The design-patterns movement has been a tremendous boon to the software development world because it supplies nomenclature and exemplars. But, fundamentally, reuse via design patterns is fine-grained: one solution (the Flyweight Pattern, for example) is orthogonal to another (the Memento Pattern). Each of the problems solved by design patterns is highly specific, which makes patterns useful because you can often find a pattern that matches your current problem—but narrowly useful because it is so specific to the problem.
Functional programmers also want reusable code, but they use different building blocks. Rather than try to create well-known relationships (coupling) between structures, functional programming tries to extract coarse-grained reuse mechanisms—based in part on category theory, a branch of mathematics that defines relationships (morphism) between types of objects. Most applications do things with lists of elements, so a functional approach is to build reuse mechanisms around the idea of lists plus contextualized, portable code. Functional languages rely on first-class functions (functions that can appear anywhere any other language construct can appear) as parameters and return values. Figure 6-3 illustrates this concept.
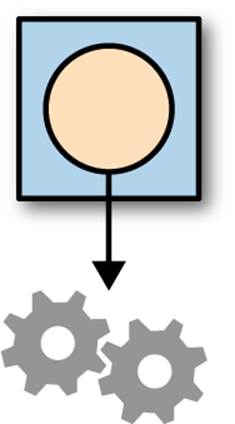
Figure 6-3. Reuse via coarse-grained mechanisms plus portable code
In Figure 6-3, the gear box represents abstractions that deal generically with some fundamental data structure, and the yellow box represents portable code, encapsulating data inside it.
The functional approach to filtering lists illustrated in Example 2-12 is common across functional programming languages and libraries. Using the ability to pass code as a parameter (as to the filter() method) illustrates thinking about code reuse in a different way. If you come from a traditional design-patterns–driven object-oriented world, you are likely more accustomed to building classes and methods to solve problems.
However, functional languages allow you to cede some scaffolding and boilerplate with the same conceptual result. For example, the Command design pattern isn’t needed in a language with closures. Ultimately, that design pattern only exists to address language deficiencies, such as the inability to pass behavior without wrapping it in a (generally) useless skeleton class. Of course, the Command design pattern also supports other useful behavior, such as undo, but it is predominantly used as a way to pass executable chunks of code to methods.
Another common pattern that loses most of its boilerplate code is the Template Method design pattern, introduced in Chapter 3.
Template Method
First-class functions make the Template Method design pattern simpler to implement, because they remove potentially unnecessary structure. Template Method defines the skeleton of an algorithm in a method, deferring some steps to subclasses and forcing them to define those steps without changing the algorithm’s structure. A typical implementation of the Template Method appears in Example 6-1, in Groovy.
Example 6-1. “Standard” Template Method implementation
package templates;
abstractclassCustomer {
def plan
def Customer() {
plan = []
}
defabstract checkCredit()
defabstract checkInventory()
defabstract ship()
def process() {
checkCredit()
checkInventory()
ship()
}
}
In Example 6-1, the process() method relies on checkCredit(), checkInventory(), and ship(), whose definitions must be supplied by subclasses because they are abstract methods.
Because first-class functions can act as any other data structure, I can redefine the code in Example 6-1 using code blocks, as shown in Example 6-2.
Example 6-2. Template Method with first-class functions
package templates;
classCustomerBlocks {
def plan, checkCredit, checkInventory, ship
def CustomerBlocks() {
plan = []
}
def process() {
checkCredit()
checkInventory()
ship()
}
}
In Example 6-2, the steps in the algorithm are merely properties of the class, assignable like any other property. This is an example in which the language feature mostly absorbs the implementation details. It’s still useful to talk about this pattern as a solution (deferring steps to subsequent handlers) to a problem, but the implementation is simpler.
The two solutions aren’t equivalent. In the “traditional” Template Method shown in Example 6-1, the abstract class requires subclasses to implement the dependent methods. Of course, the subclass might just create an empty method body, but the abstract-method definition forms a kind of documentation, reminding subclassers to take it into account. On the other hand, the rigidity of method declarations might not be suitable in situations in which more flexibility is required. For example, I could create a version of my Customer class that accepts any list of methods for processing.
Deep support for features such as code blocks makes languages developer-friendly. Consider the case in which you want to allow subclassers to skip some of the steps. Groovy has a special protected access operator (?.) that ensures that the object isn’t null before invoking a method on it. Consider the process() definition in Example 6-3.
Example 6-3. Adding protection to code-block invocation
def process() {
checkCredit?.call()
checkInventory?.call()
ship?.call()
}
In Example 6-3, whoever implements the functions assigned to the checkCredit, checkInventory, and ship properties can choose which of them to leave blank. Syntactic sugar like the ?. operator allows developers to cede repetitive, obfuscating code such as a long series of if blocks to the language, replacing boilerplate code with expressiveness. Although there is nothing particularly functional about the ?. operator, it serves as a good example of ceding busywork to the runtime.
The availability of higher-order functions allows you to avoid unnecessary boilerplate code in the most common uses of classic design patterns such as Command and Template.
Strategy
A popular design pattern simplified by first-class functions is the Strategy pattern. Strategy defines a family of algorithms, encapsulating each one and making them interchangeable. It lets the algorithm vary independently from clients that use it. First-class functions make it simple to build and manipulate strategies.
A traditional implementation of the Strategy design pattern, for calculating the products of numbers, appears in Example 6-4.
Example 6-4. Using the Strategy design pattern for products of two numbers
interfaceCalc {
def product(n, m)
}
classCalcMultimplements Calc {
def product(n, m) { n * m }
}
classCalcAddsimplements Calc {
def product(n, m) {
def result = 0
n.times {
result += m
}
result
}
}
In Example 6-4, I define an interface for the product of two numbers. I implement the interface with two different concrete classes (strategies): one using multiplication and the other using addition. To test these strategies, I create a test case, shown in Example 6-5.
Example 6-5. Testing product strategies
classStrategyTest {
def listOfStrategies = [new CalcMult(), new CalcAdds()]
@Test
publicvoid product_verifier() {
listOfStrategies.each { s ->
assertEquals(10, s.product(5, 2))
}
}
As expected in Example 6-5, both strategies return the same value. Using code blocks as first-class functions, I can reduce much of the ceremony from the previous example. Consider the case of exponentiation strategies, shown in Example 6-6.
Example 6-6. Testing exponentiation with less ceremony
@Test
publicvoid exp_verifier() {
def listOfExp = [
{i, j -> Math.pow(i, j)},
{i, j ->
def result = i
(j-1).times { result *= i }
result
}]
listOfExp.each { e ->
assertEquals(32, e(2, 5))
assertEquals(100, e(10, 2))
assertEquals(1000, e(10, 3))
}
}
In Example 6-6, I define two strategies for exponentiation directly inline, using Groovy code blocks, trading formality for convenience. The traditional approach forces name and structure around each strategy, which is sometimes desirable. However, note that I have the option to add more stringent safeguards to the code in Example 6-6, whereas I can’t easily bypass the restrictions imposed by the more traditional approach—which is more of a dynamic-versus-static argument than a functional-programming-versus-design-patterns one.
The Flyweight Design Pattern and Memoization
The Flyweight pattern is an optimization technique that uses sharing to support a large number of fine-grained object references. You keep a pool of objects available, creating references into the pool for particular views.
Flyweight uses the idea of a canonical object—a single representative object that represents all other objects of that type. For example, if you have a particular consumer product, a canonical version of the product represents all products of that type.
In an application, instead of creating a list of products for each user, you create one list of canonical products, and each user has a reference into that list for his product.
Consider the classes in Example 6-7, which model computer types.
Example 6-7. Simple classes modeling types of computers
classComputer {
def type
def cpu
def memory
def hardDrive
def cd
}
classDesktopextends Computer {
def driveBays
def fanWattage
def videoCard
}
classLaptopextends Computer {
def usbPorts
def dockingBay
}
classAssignedComputer {
def computerType
def userId
public AssignedComputer(computerType, userId) {
this.computerType = computerType
this.userId = userId
}
}
In these classes, let’s say it’s inefficient to create a new Computer instance for each user, assuming that all the computers have the same specifications. An AssignedComputer associates a computer with a user.
A common way to make this code more efficient combines the Factory and Flyweight patterns. Consider the singleton factory for generating canonical computer types, shown in Example 6-8.
Example 6-8. Singleton factory for flyweight computer instances
classCompFactory {
def types = [:]
staticdef instance;
private ComputerFactory() {
def laptop = new Laptop()
def tower = new Desktop()
types.put("MacBookPro6_2", laptop)
types.put("SunTower", tower)
}
staticdef getInstance() {
if (instance == null)
instance = new CompFactory()
instance
}
def ofType(computer) {
types[computer]
}
}
The ComputerFactory class builds a cache of possible computer types, then delivers the proper instance via its ofType() method. This is a traditional singleton factory as you would write it in Java.
However, Singleton is a design pattern as well, and it serves as another good example of a pattern ceded to the runtime. Consider the simplified ComputerFactory, which uses the @Singleton annotation provided by Groovy, shown in Example 6-9.
Example 6-9. Simplified singleton factory
@Singleton classComputerFactory {
def types = [:]
private ComputerFactory() {
def laptop = new Laptop()
def tower = new Desktop()
types.put("MacBookPro6_2", laptop)
types.put("SunTower", tower)
}
def ofType(computer) {
types[computer]
}
}
To test that the factory returns canonical instances, I write a unit test, shown in Example 6-10.
Example 6-10. Testing canonical types
@Test
publicvoid comp_factory() {
def bob = new AssignedComputer(
CompFactory.instance.ofType("MacBookPro6_2"), "Bob")
def steve = new AssignedComputer(
CompFactory.instance.ofType("MacBookPro6_2"), "Steve")
assertTrue(bob.computerType == steve.computerType)
}
Saving common information across instances is a good idea, and it’s an idea that I want to preserve as I cross into functional programming. However, the implementation details are quite different. This is an example of preserving the semantics of a pattern while changing (preferably, simplifying) the implementation.
As I covered in Chapter 4, a memoized function allows the runtime to cache the values for you. Consider the functions defined in Example 6-11.
Example 6-11. Memoization of flyweights
def computerOf = {type ->
def of = [MacBookPro6_2: new Laptop(), SunTower: new Desktop()]
return of[type]
}
def computerOfType = computerOf.memoize()
In Example 6-11, the canonical types are defined within the computerOf function. To create a memoized instance of the function, I simply call the memoize() method.
Example 6-12 shows a unit test comparing the invocation of the two approaches.
Example 6-12. Comparing approaches
@Test
publicvoid flyweight_computers() {
def bob = new AssignedComputer(
ComputerFactory.instance.ofType("MacBookPro6_2"), "Bob")
def steve = new AssignedComputer(
ComputerFactory.instance.ofType("MacBookPro6_2"), "Steve")
assertTrue(bob.computerType == steve.computerType)
def sally = new AssignedComputer(
computerOfType("MacBookPro6_2"), "Sally")
def betty = new AssignedComputer(
computerOfType("MacBookPro6_2"), "Betty")
assertTrue sally.computerType == betty.computerType
}
The result is the same, but notice the huge difference in implementation details. For the “traditional” design pattern, I created a new class to act as a factory, implementing two methods. For the functional version, I implemented a single method, then returned a memoized version. Offloading details such as caching to the runtime means fewer opportunities for handwritten implementations to fail. In this case, I preserved the semantics of the Flyweight pattern but with a very simple implementation.
Factory and Currying
In the context of design patterns, currying acts as a factory for functions. A common feature in functional programming languages is first-class (or higher-order) functions, which allow functions to act as any other data structure. Thanks to this feature, I can easily create functions that return other functions based on some criterion, which is the essence of a factory. For example, if you have a general function that adds two numbers, you can use currying as a factory to create a function that always adds one to its parameter—an incrementer, as shown in Example 6-13, implemented in Groovy.
Example 6-13. Currying as a function factory
def adder = { x, y -> x + y}
def incrementer = adder.curry(1)
println "increment 7: ${incrementer(7)}"
In Example 6-13, I curry the first parameter as 1, returning a function that accepts a single parameter. In essence, I have created a function factory.
I would like to return to an example from an earlier chapter on recursive filtering in Scala, shown in Example 6-14.
Example 6-14. Recursive filtering in Scala
objectCurryTestextendsApp {
def filter(xs:List[Int], p:Int => Boolean):List[Int] =
if (xs.isEmpty) xs
elseif (p(xs.head)) xs.head :: filter(xs.tail, p)
else filter(xs.tail, p)
def dividesBy(n:Int)(x:Int) = ((x % n) == 0) // ![]()
val nums =List(1, 2, 3, 4, 5, 6, 7, 8)
println(filter(nums, dividesBy(2))) // ![]()
println(filter(nums, dividesBy(3)))
}
![]()
A function is defined to be curried.
![]()
filter expects as parameters a collection (nums) and a function that accepts a single parameter (the curried dividesBy() function).
What’s interesting in Example 6-14 from a patterns standpoint is the “casual” use of currying in the dividesBy() method. Notice that dividesBy() accepts two parameters and returns true or false based on whether the second parameter divides evenly into the first. However, when this method is called as part of the invocation of the filter() method, it is called with only one parameter—the result of which is a curried function that is then used as the predicate within the filter() method.
This example illustrates the first two of the ways that patterns manifest in functional programming, as I listed them at the start of this section. First, currying is built into the language or runtime, so the concept of a function factory is ingrained and doesn’t require extra structure. Second, it illustrates my point about different implementations. Using currying as in Example 6-14 would likely never occur to typical Java programmers, who have never really had portable code and certainly never thought about constructing specific functions from more general ones. In fact, chances are that most imperative developers wouldn’t think of using a design pattern here, because creating a specific dividesBy() method from a general one seems like a small problem, whereas design patterns—relying mostly on structure to solve problems and therefore requiring a lot of overhead to implement—seem like solutions to large problems. Using currying as it was intended doesn’t justify the formality of a special name other than the one it already has.
NOTE
Use currying to construct specific functions from general ones.
Structural Versus Functional Reuse
Recall the quote from Chapter 1:
OO makes code understandable by encapsulating moving parts. FP makes code understandable by minimizing moving parts.
— Michael Feathers
Working in a particular abstraction every day causes it to seep gradually into your brain, influencing the way you solve problems. In this section, I tackle code reuse via refactoring and the attendant abstraction impact.
One of the goals of object orientation is to make encapsulating and working with state easier. Thus, its abstractions tend toward using state to solve common problems, implying the use of multiple classes and interactions—what Michael Feathers calls “moving parts.”
Functional programming tries to minimize moving parts by composing parts together rather than coupling structures together. This is a subtle concept that’s hard to see for developers whose primary experience is with object-oriented languages.
Code Reuse Via Structure
The imperative (and especially) object-oriented programming style uses structure and messaging as building blocks. To reuse object-oriented code, you extract the target code into another class, then use inheritance to access it.
To illustrate code reuse and its implications, I return to a version of the now-familiar number classifier to illustrate code structure and style.
You could also write code that uses a positive integer’s factors to determine if it is a prime number (defined as an integer greater than 1 whose only factors are 1 and the number itself). Because both of these problems rely on a number’s factors, they are good candidates for refactoring (no pun intended) and thus for illustrating styles of code reuse.
Example 6-15 shows the number classifier written in an imperative style.
Example 6-15. Imperative number classifier
publicclassClassifierAlpha {
privateint number;
public ClassifierAlpha(int number) {
this.number = number;
}
publicboolean isFactor(int potential_factor) {
return number % potential_factor == 0;
}
public Set<Integer> factors() {
HashSet<Integer> factors = new HashSet<>();
for (int i = 1; i <= sqrt(number); i++)
if (isFactor(i)) {
factors.add(i);
factors.add(number / i);
}
return factors;
}
staticpublicint sum(Set<Integer> factors) {
Iterator it = factors.iterator();
int sum = 0;
while (it.hasNext())
sum += (Integer) it.next();
return sum;
}
publicboolean isPerfect() {
return sum(factors()) - number == number;
}
publicboolean isAbundant() {
return sum(factors()) - number > number;
}
publicboolean isDeficient() {
return sum(factors()) - number < number;
}
}
I discuss the derivation of this code in Chapter 2, so I won’t repeat it now. Its purpose here is to illustrate code reuse. That leads me to the similar code in Example 6-16, which determines prime numbers.
Example 6-16. Imperative prime number finder
publicclassPrimeAlpha {
privateint number;
public PrimeAlpha(int number) {
this.number = number;
}
publicboolean isPrime() {
Set<Integer> primeSet = new HashSet<Integer>() {{
add(1); add(number);}};
return number > 1 &&
factors().equals(primeSet);
}
publicboolean isFactor(int potential_factor) {
return number % potential_factor == 0;
}
public Set<Integer> factors() {
HashSet<Integer> factors = new HashSet<>();
for (int i = 1; i <= sqrt(number); i++)
if (isFactor(i)) {
factors.add(i);
factors.add(number / i);
}
return factors;
}
}
A few items of note appear in Example 6-16. The first is the slightly odd initialization code in the isPrime() method. This is an example of an instance initializer, a construction quirk in Java that allows me to create instances outside the constructor by placing code blocks within the class but outside any method declarations.
The other items of interest in Example 6-16 are the isFactor() and factors() methods. Notice that they are identical to their counterparts in the ClassifierAlpha class (in Example 6-15). This is the natural outcome of implementing two solutions independently and realizing that you have virtually the same functionality.
Refactoring to eliminate duplication
The solution to this type of duplication is to refactor the code into a single Factors class, which appears in Example 6-17.
Example 6-17. Refactored common code
publicclassFactorsBeta {
protectedint number;
public FactorsBeta(int number) {
this.number = number;
}
publicboolean isFactor(int potential_factor) {
return number % potential_factor == 0;
}
public Set<Integer> getFactors() {
HashSet<Integer> factors = new HashSet<>();
for (int i = 1; i <= sqrt(number); i++)
if (isFactor(i)) {
factors.add(i);
factors.add(number / i);
}
return factors;
}
}
The code in Example 6-17 is the result of using Extract Superclass refactoring in your IDE of choice. Notice that because both of the extracted methods use the number member variable, it is dragged into the superclass. While performing this refactoring, the IDE asked me how I would like to handle access (accessor pair, protected scope, etc.). I chose protected scope, which adds number to the class and creates a constructor to set its value.
Once I’ve isolated and removed the duplicated code, both the number classifier and the prime number tester are much simpler. Example 6-18 shows the refactored number classifier.
Example 6-18. Refactored, simplified classifier
publicclassClassifierBetaextends FactorsBeta {
public ClassifierBeta(int number) {
super(number);
}
publicint sum() {
Iterator it = getFactors().iterator();
int sum = 0;
while (it.hasNext())
sum += (Integer) it.next();
return sum;
}
publicboolean isPerfect() {
return sum() - number == number;
}
publicboolean isAbundant() {
return sum() - number > number;
}
publicboolean isDeficient() {
return sum() - number < number;
}
}
Example 6-19 shows the refactored prime number tester.
Example 6-19. Refactored, simplified prime number tester
publicclassPrimeBetaextends FactorsBeta {
public PrimeBeta(int number) {
super(number);
}
publicboolean isPrime() {
Set<Integer> primeSet = new HashSet<Integer>() {{
add(1); add(number);}};
return getFactors().equals(primeSet);
}
}
Regardless of which access option you choose for the number member when refactoring, you must deal with a network of classes when you think about this problem. Often this is a good thing, because it allows you to isolate parts of the problem, but it also has downstream consequences when you make changes to the parent class.
This is an example of code reuse via coupling: tying together two elements (in this case, classes) via the shared state of the number field and the getFactors() method from the superclass. In other words, this works by using the built-in coupling rules in the language. Object orientation defines coupled interaction styles (how you access member variables via inheritance, for example), so you have predefined rules about how things are coupled—which is good, because you can reason about behavior in a consistent way. Don’t misunderstand me: I’m not suggesting that using inheritance is a bad idea. Rather, I’m suggesting that it is overused in object-oriented languages in lieu of alternative abstractions that have better characteristics.
Code reuse via composition
In Chapter 2, I presented a functional version of the number classifier in Java, shown in Example 6-20.
Example 6-20. More functional version of number classifier
importjava.util.Collection;
importjava.util.Collections;
importjava.util.HashSet;
importjava.util.Set;
publicclassNumberClassifier {
publicstaticboolean isFactor(finalint candidate, finalint number) { ![]()
return number % candidate == 0;
}
publicstatic Set<Integer> factors(finalint number) { ![]()
Set<Integer> factors = new HashSet<>();
factors.add(1);
factors.add(number);
for (int i = 2; i < number; i++)
if (isFactor(i, number))
factors.add(i);
return factors;
}
publicstaticint aliquotSum(final Collection<Integer> factors) {
int sum = 0;
int targetNumber = Collections.max(factors);
for (int n : factors) { ![]()
sum += n;
}
return sum - targetNumber;
}
publicstaticboolean isPerfect(finalint number) {
return aliquotSum(factors(number)) == number;
}
![]()
publicstaticboolean isAbundant(finalint number) {
return aliquotSum(factors(number)) > number;
}
publicstaticboolean isDeficient(finalint number) {
return aliquotSum(factors(number)) < number;
}
}
![]()
All methods must accept number as a parameter—no internal state exists to hold it.
![]()
All methods are public static because they are pure functions, thus generically useful outside the number classification realm.
![]()
Note the use of the most general reasonable parameter, aiding reuse at the function level.
![]()
No caching is present, making this version inefficient for repeating classifications.
I also have a functional version (using pure functions and no shared state) of the Example 6-16, whose isPrime() method appears in Example 6-21. The rest of its code is identical to the same-named methods in Example 6-20.
Example 6-21. Functional version of prime number tester
publicclassFPrime {
publicstaticboolean isPrime(int number) {
Set<Integer> factors = Factors.of(number);
return number > 1 &&
factors.size() == 2 &&
factors.contains(1) &&
factors.contains(number);
}
}
Just as I did with the imperative versions, I extract the duplicated code into its own Factors class, changing the name of the factors() method to of() for readability, as shown in Example 6-22.
Example 6-22. The functional refactored Factors class
publicclassFactors {
staticpublicboolean isFactor(int number, int potential_factor) {
return number % potential_factor == 0;
}
staticpublic Set<Integer> of(int number) {
HashSet<Integer> factors = new HashSet<>();
for (int i = 1; i <= sqrt(number); i++)
if (isFactor(number, i)) {
factors.add(i);
factors.add(number / i);
}
return factors;
}
}
Because all the state in the functional version is passed as parameters, no shared state comes along with the extraction. Once I have extracted this class, I can refactor both the functional classifier and prime number tester to use it. Example 6-23 shows the refactored number classifier.
Example 6-23. Refactored number classifier
publicclassFClassifier {
publicstaticint sumOfFactors(int number) {
Iterator<Integer> it = Factors.of(number).iterator();
int sum = 0;
while (it.hasNext())
sum += it.next();
return sum;
}
publicstaticboolean isPerfect(int number) {
return sumOfFactors(number) - number == number;
}
publicstaticboolean isAbundant(int number) {
return sumOfFactors(number) - number > number;
}
publicstaticboolean isDeficient(int number) {
return sumOfFactors(number) - number < number;
}
}
Note that I didn’t use any special libraries or languages to make the second version more functional. Rather, I did it by using composition rather than coupling for code reuse. Both Examples 6-22 and 6-23 use the Factors class, but its use is entirely contained within individual methods.
The distinction between coupling and composition is subtle but important. In a simple example such as this, you can see the skeleton of the code structure showing through. However, when you end up refactoring a large code base, coupling pops up everywhere because that’s one of the reuse mechanisms in object-oriented languages. The difficulty of understanding exuberantly coupled structures has harmed reuse in object-oriented languages, limiting effective reuse to well-defined technical domains such as object-relational mapping and widget libraries. The same level of reuse has eluded us when we write less obviously structured object-oriented code (such as the code you write in business applications).
I could have improved the imperative version by noticing that the IDE is offering to create coupling between the parent and child via a protected member. Rather than introduce coupling, I should use composition instead. Thinking as a more functional programmer means thinking differently about all aspects of coding. Code reuse is an obvious development goal, and imperative abstractions tend to solve that problem differently from the way that functional programmers solve it.
At the beginning of this section, I delineated the ways that design patterns intersect with function programming. First, they can be absorbed by the language or runtime. I showed examples of this using the Factory, Strategy, Singleton, and Template Method patterns. Second, patterns can preserve their semantics but have completely different implementations; I showed an example of the Flyweight pattern using classes versus using memoization. Third, functional languages and runtimes can have wholly different features, allowing them to solve problems in completely different ways.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.