How to Use Objects: Code and Concepts (2016)
Part I: Language Usage
Chapter 1. Basic Usage of Objects
To learn a natural language properly, one goes abroad to live among native speakers for some time. One learns their idioms, their preferences in choosing words, and the general feeling for the flow of the language. But even so, when composing texts afterward, one turns to thesauri for alternative formulations and to usage dictionaries to acquire a desirable style.
This first part of the book will take you on a tour among Java natives, or at least their written culture in the form of the Eclipse IDE’s code base. We will study common idioms and usages of the language constructs, so as to learn from the experts in the field. At the same time, the categorization of usages gives us a vocabulary for talking about our daily programming tasks, about the purposes of objects, classes, methods, and fields, and about the alternatives we have encountered and the decisions we have made. In short, it helps teams to code more efficiently and to communicate more efficiently.
Like any usage dictionary, the presentation here assumes that you are in general familiar with the language; thus we will discuss the meaning of language constructs only very briefly. Furthermore, the chapter focuses on the technical aspects of usage. Advanced design considerations must necessarily build on technical experience and are discussed in Chapters 11 and 12. However, we give forward pointers to related content throughout, and encourage you to jump ahead if you find a topic particularly interesting. Finally, we discuss the Eclipse IDE’s tool support for the usages, because effective developers don’t write code, they have the code generated by Eclipse. Here, we encourage you to try the tools out immediately, just to get the feel for what Eclipse can do for you.
1.1 The Core: Objects as Small and Active Entities
Because programming languages are designed to offer relatively few, but powerful elements that can be combined in a flexible way, it is not the language, but rather the programmer’s attitude and mindset that determines the shape of the source code. As the well-known saying goes, “A real![]() 210 programmer can write FORTRAN programs in any language.”
210 programmer can write FORTRAN programs in any language.”
To get a head start in object-oriented programming, we will first formulate a few principles that set this approach apart from other programming paradigms. From a development perspective, these principles can also be read as goals: If your objects fit the scheme, you have got the design right. Because the principles apply in many later situations, we keep the discussion brief here and give forward references instead.
It’s the objects that matter, not the classes.
Learning a language, of course, requires mastering its grammar and meaning, so introductory textbooks on Java naturally focus on these subjects. Now it is, however, time to move on: The important point is to understand how objects behave at runtime, how they interact, and how they provide![]() 1.4.12
1.4.12 ![]() 1.3.8
1.3.8 ![]() 1.4.8.4 services to each other. Classes are not as flexible as objects; they are merely development-time blueprints and a technical necessity for creating objects.
1.4.8.4 services to each other. Classes are not as flexible as objects; they are merely development-time blueprints and a technical necessity for creating objects.![]() 85 Learn to think in terms of objects!
85 Learn to think in terms of objects!
![]() Indeed, not all object-oriented languages have classes. Only in class-based languages, such as Java, C++, C#, and Smalltalk, is each object an instance of a class fixed at creation time. In contrast, in object-based languages, such as JavaScript/ECMAScript, objects are lightweight containers for methods and fields. Methods can even be changed for individual objects.
Indeed, not all object-oriented languages have classes. Only in class-based languages, such as Java, C++, C#, and Smalltalk, is each object an instance of a class fixed at creation time. In contrast, in object-based languages, such as JavaScript/ECMAScript, objects are lightweight containers for methods and fields. Methods can even be changed for individual objects.
We start our overview of the characteristics of objects by considering how entire applications can be built from them in the end:
An application is a network of collaborating objects.
![]() 11The idea of many small objects solving the application’s task together is
11The idea of many small objects solving the application’s task together is![]() 32,264,263 perhaps the central notion of object-oriented programming. While in procedural programming a few hundred modules are burdened with providing the functionality, in object-oriented applications a few hundred thousand objects can share and distribute the load. While classical systems feature
32,264,263 perhaps the central notion of object-oriented programming. While in procedural programming a few hundred modules are burdened with providing the functionality, in object-oriented applications a few hundred thousand objects can share and distribute the load. While classical systems feature![]() 11.1 hierarchical module dependencies, objects form networks, usually with cycles: No technical restrictions must impede their collaboration on the task at hand.
11.1 hierarchical module dependencies, objects form networks, usually with cycles: No technical restrictions must impede their collaboration on the task at hand.
Objects are lightweight, active, black-box entities.
![]() 11.2When many objects solve a task together, each object can focus on a small aspect and can therefore remain small and understandable: It contains just the code and information relating to that aspect. To achieve a
11.2When many objects solve a task together, each object can focus on a small aspect and can therefore remain small and understandable: It contains just the code and information relating to that aspect. To achieve a![]() 1.8.2
1.8.2 ![]() 2.2
2.2 ![]() 1.8.6 clear code structure, it is helpful to assume that you can afford as many helper objects as you like. For instance, Eclipse’s SourceViewer, which is the basis for almost all editors, holds around 20 objects that contribute different aspects to the overall component (and around 50 more are inherited). Indeed, without that additional structure, theSourceViewer would
1.8.6 clear code structure, it is helpful to assume that you can afford as many helper objects as you like. For instance, Eclipse’s SourceViewer, which is the basis for almost all editors, holds around 20 objects that contribute different aspects to the overall component (and around 50 more are inherited). Indeed, without that additional structure, theSourceViewer would![]() 1.4.13 become quite unmanageable. Finally, objects are handled by reference—that is, passing objects around means copying pointers, which are mere machine words.
1.4.13 become quite unmanageable. Finally, objects are handled by reference—that is, passing objects around means copying pointers, which are mere machine words.
Objects are also active. While modules and data structures in classical software engineering primarily have things done to them by other modules,![]() 72,205 objects are best perceived as doing things. For example, a Button does not simply paint a clickable area on the screen; it also shows visual feedback on
72,205 objects are best perceived as doing things. For example, a Button does not simply paint a clickable area on the screen; it also shows visual feedback on![]() 7.8 mouse movements and notifies registered objects when the user clicks the
7.8 mouse movements and notifies registered objects when the user clicks the![]() 7.1
7.1 ![]() 2.1 button.
2.1 button.
Finally, objects are “black-box” items. Although they usually contain some extensive machinery necessary for performing their task, there is a conceptual box around the object that other objects do not penetrate. Fig. 1.1 gives the graphical intuition of how black-box objects should collaborate. Object B employs several helper objects, of which C implements some functionality that A requires. Since B is a black box, A should not make assumptions about its internal structure and cannot call on C directly.![]() 2.2.3
2.2.3 ![]() 11.5.1
11.5.1 ![]() 12.1.4 Instead, A sends B a message m; that is, it calls its method m. Unknown to A, m now calls on C. Black-box objects do not publish their internal structure.
12.1.4 Instead, A sends B a message m; that is, it calls its method m. Unknown to A, m now calls on C. Black-box objects do not publish their internal structure.
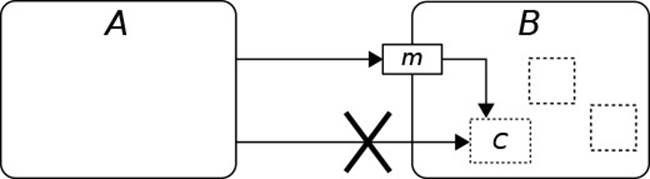
Figure 1.1 Collaboration Between Self-Contained Objects
![]() Being “black-box” means more than just declaring data structures and helpers as private or protected. Preventing others from accessing an object’s fields and internal
Being “black-box” means more than just declaring data structures and helpers as private or protected. Preventing others from accessing an object’s fields and internal![]() 1.4.5
1.4.5 ![]() 1.4.8.2 methods at the language level is only the first step and really just a technical tool. This practice is called encapsulation, from the idea that the language enables you to establish
1.4.8.2 methods at the language level is only the first step and really just a technical tool. This practice is called encapsulation, from the idea that the language enables you to establish![]() 216(§7.4) an impenetrable capsule around the object. Beyond that, the concept of information hiding
216(§7.4) an impenetrable capsule around the object. Beyond that, the concept of information hiding![]() 11.5.1
11.5.1 ![]() 205 addresses creating “black-box” objects at the design level. What is hidden here is
205 addresses creating “black-box” objects at the design level. What is hidden here is![]() 216(§7.6) information about an object, which encompasses much more than just the definition of its technical internals. It may comprise its strategies for solving particular problems, its specific sequence of interactions with other objects, its choice in ordering the values in some list, and many more details. In general, information hiding is about hiding design decisions, with the intention of possibly revising these decisions in the future. In this book, Parts I–III deal mainly with encapsulation. Information hiding is discussed as a design concept in Part IV.
216(§7.6) information about an object, which encompasses much more than just the definition of its technical internals. It may comprise its strategies for solving particular problems, its specific sequence of interactions with other objects, its choice in ordering the values in some list, and many more details. In general, information hiding is about hiding design decisions, with the intention of possibly revising these decisions in the future. In this book, Parts I–III deal mainly with encapsulation. Information hiding is discussed as a design concept in Part IV.
Creating black-box objects demands a special mental attitude, and skill, from developers:
Think of objects from the outside.
Developers adore the nifty code and data structures that they use to solve a problem. In a team, however, it is essential to learn to speak about an object from the perspective of the other team members, who merely wish to use the object quickly and effectively. Consider a combo box, of classCCombo on the screen. It enables the user to select one item from a given list in a nice pop-up window. Providing this simple functionality requires 1200 lines of code, using 12 fields with rather complex interdependencies.
![]() 4
4 ![]() 6For a smooth development process, professionals must learn to describe
6For a smooth development process, professionals must learn to describe![]() 10 their objects’ behavior—their reactions to method invocations—in general terms, yet precisely enough for other objects to rely on the behavior. Their implementation is treated as a private, hidden internal, and is
10 their objects’ behavior—their reactions to method invocations—in general terms, yet precisely enough for other objects to rely on the behavior. Their implementation is treated as a private, hidden internal, and is![]() 11.2 encapsulated behind a public interface. You know that you have succeeded when you can describe your object in 1–2 brief sentences to your fellow team members.
11.2 encapsulated behind a public interface. You know that you have succeeded when you can describe your object in 1–2 brief sentences to your fellow team members.
Objects are team players, not lone wolves.
To emphasize the point of collaboration: Objects can focus on their own tasks only if they don’t hesitate to delegate related tasks that other objects![]() 1.4.1
1.4.1 ![]() 109 can perform better. Toward that goal, it also helps to imagine that objects communicate by sending messages to each other. A “method call” comes with many technical aspects, such as parameter passing and stack frames, that deflect the thoughts from the best design. It’s better to see this process as one object notifying another object, usually that it wants something done. Note also how the idea of objects working together requires lean public interfaces: Delegating tasks works well only if the other object states succinctly and precisely what it can do—that is, which tasks it can perform well.
109 can perform better. Toward that goal, it also helps to imagine that objects communicate by sending messages to each other. A “method call” comes with many technical aspects, such as parameter passing and stack frames, that deflect the thoughts from the best design. It’s better to see this process as one object notifying another object, usually that it wants something done. Note also how the idea of objects working together requires lean public interfaces: Delegating tasks works well only if the other object states succinctly and precisely what it can do—that is, which tasks it can perform well.
Objects have an identity.
Objects are commonly used to represent specific things. Domain objects stand for things that the customers mention in their requirements; other objects may manage printers, displays, or robot arms. An object is therefore more than a place in memory to store data—its unique identity carries a meaning by itself, since the object is implicitly associated with things![]() 1.8.4
1.8.4 ![]() 1.4.13 outside the software world. Except in the case of value objects, one cannot simply exchange one object for another, even if they happen to store the same data in their fields.
1.4.13 outside the software world. Except in the case of value objects, one cannot simply exchange one object for another, even if they happen to store the same data in their fields.
Note that this arrangement stands in contrast to classical data structures. Like objects, they reside in the program’s heap space. But, for instance, one hash map is interchangeable with another as long as both store the same key/value associations. The actual addresses of the hash map’s parts are irrelevant.
Objects have state.
Objects store data in their fields and—apart from a few special cases—that![]() 1.8.4 data changes over time. As we have just seen, objects frequently relate closely to the real world or our concepts about the world. The world is, however, stateful itself: When you write on a piece of paper, the paper is modified. When you type into an editor, you expect that the document is modified correspondingly. Unlike the real world, its software counterpart can support undo, by reversing modifications to the objects’ state. Furthermore,
1.8.4 data changes over time. As we have just seen, objects frequently relate closely to the real world or our concepts about the world. The world is, however, stateful itself: When you write on a piece of paper, the paper is modified. When you type into an editor, you expect that the document is modified correspondingly. Unlike the real world, its software counterpart can support undo, by reversing modifications to the objects’ state. Furthermore,![]() 9.5 the computer hardware is stateful by design, and objects at some point need to match that environment to work efficiently.
9.5 the computer hardware is stateful by design, and objects at some point need to match that environment to work efficiently.
Objects have a defined life cycle.
Java makes it easy to work with objects: Just create them and keep a reference to them as long as they are required; afterwards, the garbage![]() 133 collector reclaims them to reuse the memory.
133 collector reclaims them to reuse the memory.
To understand objects, it is often useful to consider the things that happen to an object during its existence more explicitly. The term life cycle captures this idea: An object is allocated, then initialized by the constructor![]() 1.6.1 or by ordinary methods taking its role; then, its methods get called from the
1.6.1 or by ordinary methods taking its role; then, its methods get called from the![]() 1.6.2 outside to trigger certain desired reactions; and finally, the object becomes
1.6.2 outside to trigger certain desired reactions; and finally, the object becomes![]() 1.4.1 obsolete and gets destroyed.
1.4.1 obsolete and gets destroyed.
From the object’s point of view, these events are represented by calls to specific methods: It is notified about its creation and initialization, then![]() 12.3.3.4 the various operations, and finally its own upcoming destruction. These notifications serve to give the object the opportunity to react properly—for instance, by freeing allocated resources before it gets destroyed.
12.3.3.4 the various operations, and finally its own upcoming destruction. These notifications serve to give the object the opportunity to react properly—for instance, by freeing allocated resources before it gets destroyed.
Don’t worry too much about efficiency.
Developers coming to Java often wonder whether it will be efficient enough. Unlike in C or C++, it is simply very difficult to estimate the actual runtime cost of their code. Their preoccupation with efficiency then sometimes leads them to trade object-oriented design for perceived improvements in efficiency. As Donald Knuth puts it, “Premature optimization is the root of![]() 140
140 ![]() 44(Item 55) all evil.”
44(Item 55) all evil.”
Efficiency of code is, indeed, a dangerous goal: When it is stressed![]() 258 too much, developers are likely to spend much effort on complex special-purpose data structures and algorithms. With the computing power now available on most devices, the trade-off between expensive developer time and cheap execution time is rapidly moving toward optimizing development and maintenance.
258 too much, developers are likely to spend much effort on complex special-purpose data structures and algorithms. With the computing power now available on most devices, the trade-off between expensive developer time and cheap execution time is rapidly moving toward optimizing development and maintenance.
![]() The trade-off might be obvious at the present time. But it is interesting that it has been valid from the infancy of modern computing. One of the seminal papers
The trade-off might be obvious at the present time. But it is interesting that it has been valid from the infancy of modern computing. One of the seminal papers![]() 236(p.125) on good software organization states, “The designer should realize the adverse effect on maintenance and debugging that may result from striving just for minimum execution time and/or memory. He should also remember that programmer cost is, or is rapidly becoming, the major cost of a programming system and that much of the maintenance will be in the future when the trend will be even more prominent.”
236(p.125) on good software organization states, “The designer should realize the adverse effect on maintenance and debugging that may result from striving just for minimum execution time and/or memory. He should also remember that programmer cost is, or is rapidly becoming, the major cost of a programming system and that much of the maintenance will be in the future when the trend will be even more prominent.”
Code optimization therefore requires a strong justification, ideally by demonstrating the bottlenecks using a profiler. Without such a tool, a good![]() 115 guide is Amdahl’s law, which briefly says: “Make the common case fast.” The overall system performance improves only when we optimize code that runs frequently and that takes up a high portion of the system runtime anyway. Usually, this is the case in inner loops that are processing large amounts of data or performing nontrivial computations in each iteration. Symmetrically, it is not worth optimizing methods that run infrequently and usually work on very little data. As a case in point, consider the choice of linear data structures in ListenerList and AbstractListViewer in the Eclipse code base.
115 guide is Amdahl’s law, which briefly says: “Make the common case fast.” The overall system performance improves only when we optimize code that runs frequently and that takes up a high portion of the system runtime anyway. Usually, this is the case in inner loops that are processing large amounts of data or performing nontrivial computations in each iteration. Symmetrically, it is not worth optimizing methods that run infrequently and usually work on very little data. As a case in point, consider the choice of linear data structures in ListenerList and AbstractListViewer in the Eclipse code base.
![]() A profiler may actually be instrumental in finding the bottleneck at all. Because object-oriented code works with lots of small methods rather than long and deeply nested loops, the time may be spent in unexpected places like auxiliary hashCode() or equals() methods. The author once found that his program analysis tool written in C++ spent around 30% of its runtime in the string copy constructor invoked for passing an argument to a central, small method. Using a const& parameter eliminated the problem.
A profiler may actually be instrumental in finding the bottleneck at all. Because object-oriented code works with lots of small methods rather than long and deeply nested loops, the time may be spent in unexpected places like auxiliary hashCode() or equals() methods. The author once found that his program analysis tool written in C++ spent around 30% of its runtime in the string copy constructor invoked for passing an argument to a central, small method. Using a const& parameter eliminated the problem.
Furthermore, efficiency is not the same as program speed perceived by the user, and this speed can often be improved without using sophisticated![]() 50(§C.1)
50(§C.1) ![]() 174 data structures. For applications with user interfaces, it is usually sufficient
174 data structures. For applications with user interfaces, it is usually sufficient![]() 9.4.3 to reduce the screen space to be redrawn and to move more complex tasks
9.4.3 to reduce the screen space to be redrawn and to move more complex tasks![]() 7.10 to background threads, or even to just switch to the “busy” mouse cursor.
7.10 to background threads, or even to just switch to the “busy” mouse cursor.![]() 8
8 ![]() 148 Multithreading can help to exploit the available CPU power. As these approaches suggest, optimization of perceived program speed is not so much about data structures and algorithms, but about good software organization. Moreover, this kind of optimization actually clarifies the structure, rather than making it more complex. The software will become more—not less—maintainable.
148 Multithreading can help to exploit the available CPU power. As these approaches suggest, optimization of perceived program speed is not so much about data structures and algorithms, but about good software organization. Moreover, this kind of optimization actually clarifies the structure, rather than making it more complex. The software will become more—not less—maintainable.
Finally, the concept of encapsulation ensures that you will not lose too much by starting with simple data structures and algorithms, as long as you keep their choice hidden inside objects. Once a profiler identifies a bottleneck, the necessary changes will usually be confined to single classes.
In summary, there is rarely a need for real optimization. You can design your code based on this assumption:
Objects are small and method calls are cheap.
You should not hesitate to introduce extra methods if they better document![]() 1.4.6 your overall approach and to introduce new objects (even temporary ones to be returned from methods) if they help to structure your solution.
1.4.6 your overall approach and to introduce new objects (even temporary ones to be returned from methods) if they help to structure your solution.![]() 133
133 ![]() 199
199
![]() A particular concern of many C/C++ developers is the garbage collector. The HotSpot JVM’s collector offers many state-of-the-art collectors, among them a generational garbage collector. It acts on the assumption that “many objects die young”—that
A particular concern of many C/C++ developers is the garbage collector. The HotSpot JVM’s collector offers many state-of-the-art collectors, among them a generational garbage collector. It acts on the assumption that “many objects die young”—that![]() 133 is, the program uses them only temporarily. The garbage collector keeps a small heap in which objects are created initially, and that heap is cleaned up frequently. Since the heap is small, this approach is very cheap. Only objects that survive a few collections are moved to larger heap areas that are cleaned less frequently, and with more effort.
133 is, the program uses them only temporarily. The garbage collector keeps a small heap in which objects are created initially, and that heap is cleaned up frequently. Since the heap is small, this approach is very cheap. Only objects that survive a few collections are moved to larger heap areas that are cleaned less frequently, and with more effort.
1.2 Developing with Objects
Software development is more than just designing and typing code. It means working with and working on code that already exists or that is being written. Being a professional developer, then, is measured not only by the final outcome, but also by the process by which one arrives there.
1.2.1 Effective Code Editing in Eclipse
Programming is, or should be, a rather creative activity in the quest for solutions to given problems. Typing and formatting code, in contrast, is a mere chore, which easily distracts you from the solution. The goal is this:
Don’t type your Java code—let Eclipse generate it for you.
While going through the language constructs in detail, we will point out the related Eclipse tool support. Here, we give a first, brief overview. To avoid lengthy and redundant enumerations along the menu structure, we give a motivational choice and encourage you to try the tools whenever you code.
1.2.1.1 Continuous Code Improvements
Two tools are so useful that developers usually invoke them intermittently, without special provocation: code formatting and organization of imports.
Tool: Format Code
Press Ctrl-Shift-F (for Source/Format) in the Java editor to format the current source file according to the defined code conventions.
![]() 241Code conventions define rules for formatting—in particular, for line breaks and indentation—that make it simpler for developers to share source code: If all source of a project is laid out consistently, developers get used to the style and are not distracted by irrelevant detail. With Eclipse, obeying code conventions is simple and there is no excuse for ill-formatted code. In the Preferences/Java/Code Style/Formatter, you can even fine-tune the conventions used to fit your requirements.
241Code conventions define rules for formatting—in particular, for line breaks and indentation—that make it simpler for developers to share source code: If all source of a project is laid out consistently, developers get used to the style and are not distracted by irrelevant detail. With Eclipse, obeying code conventions is simple and there is no excuse for ill-formatted code. In the Preferences/Java/Code Style/Formatter, you can even fine-tune the conventions used to fit your requirements.
![]() You can also change these settings from a project’s Properties dialog, which writes them to the .settings folder within the project. As a result, they will be checked into version control systems with the code and will be shared in the team. Alternatively, you can export and import the workspace-wide formatting settings.
You can also change these settings from a project’s Properties dialog, which writes them to the .settings folder within the project. As a result, they will be checked into version control systems with the code and will be shared in the team. Alternatively, you can export and import the workspace-wide formatting settings.
![]() Formatting does not work for source code with syntax errors. If Ctrl-Shift-F does not react, fix any remaining errors first.
Formatting does not work for source code with syntax errors. If Ctrl-Shift-F does not react, fix any remaining errors first.
Java requires import declarations to access classes or static methods from other packages. Of course, these are not meant to be written by hand:
Tool: Organize Imports
Press Ctrl-Shift-O (Source/Organize Imports) to remove unused imports and add imports for unresolved names. If there are ambiguities, Eclipse will show a selection dialog to resolve them.
![]() Since the compiler by default issues warnings about unused imports, Eclipse can even invoke the tool whenever a file is saved (see Preferences/Java/Editor/Save Actions).
Since the compiler by default issues warnings about unused imports, Eclipse can even invoke the tool whenever a file is saved (see Preferences/Java/Editor/Save Actions).
1.2.1.2 Navigation
In real-world projects, it is necessary to keep an overview of large code bases. When learning APIs and new frameworks, you also need to see related code quickly. It is worthwhile to get used to the keyboard shortcuts.
The Navigation menu offers a huge selection of available tools. Here are some appetizers: F3 jumps to the declaration of the name under the cursor; pressing Shift and hovering with the mouse over an identifier shows the definition in a pop-up (enable in Preferences/Java/Editor/Hovers);F2 shows the JavaDoc. With Ctrl-Shift-T you can quickly select a class, interface, or enum to jump to; Ctrl-Shift-R jumps to general resources.
There are also many special-purpose views, which are placed beside the editor: F4 shows the position of a class in the type hierarchy; that view’s context menu then lets you move through the hierarchy by focusing on different classes. The outline reflects the structure of the current class,and a double-click jumps to the element; you can even rearrange elements by drag-and-drop. With Ctrl-Alt-H, you can navigate through the call hierarchy view to understand the collaboration between methods across classes. A second access path to such views is found in the Show in ...menu, which you reach in the Java editor by Alt-Shift-W. This menu will save you a lot of manual tree navigation in the package explorer.
To move within a class, invoke the quick outline with Ctrl-O, then type the beginning of the target method’s or field’s name. To also see declarations in the super-types, press Ctrl-O again.
1.2.1.3 Quick-Fix
Quick-Fix (Ctrl-1) was historically intended to fix simple errors. More recently, it has developed into a standard access path to powerful tools for code generation and modification. Very often, it is simpler to deliberately write wrong or incomplete code and then use Quick-Fix to create the intended version. We can give here only a few examples, and encourage you to invoke the tool frequently to build a mental model of what it can do for you.
First, Quick-Fix still fixes simple errors. It adds required imports, changes typos in names, and rearranges arguments of method calls to resolve type errors. When you call a nonexistent method, it creates the method for you. When you write an abstract method, it proposes to make the class abstract for you; when the method has a body, Quick-Fix can remove it. When your class implements an interface, but does not have the methods, Quick-Fix adds them. When you call a method that expects an interface, it offers to add an implements clause to the argument object or to add a cast. When you assign to a local variable of the wrong type, or call a method with a wrong parameter, it can change the target type, or the source type, to achieve a match.
The real power of these fixes comes from using combinations. For instance, if you want this to receive notifications about changes in a text![]() 7.1 field on the screen, just type txt.addModifyListener(this). Quick-Fix first adds the required implements clause, then creates the required method declarations for you.
7.1 field on the screen, just type txt.addModifyListener(this). Quick-Fix first adds the required implements clause, then creates the required method declarations for you.
Quick-Fix is also good at generating and modifying code. Sometimes, while the code may compile, it may not be what you had in mind. When you have written an expression, Quick-Fix can place the result in a new variable declaration. It will even extract the subexpression under the cursor to a new variable. When you declare a variable and initialize it on the next line, Quick-Fix can join the variable declaration when the cursor is in the variable name on either line. In if and while statements, Quick-Fix can add and remove curly braces in single-statementthen/else blocks and the loop body, respectively.
![]() Linked positions are shown as boxes in generated code when the generation involves choices or ambiguities. Using tab, you can navigate between the linked positions and then choose the desired version from the appearing pop-up menus.
Linked positions are shown as boxes in generated code when the generation involves choices or ambiguities. Using tab, you can navigate between the linked positions and then choose the desired version from the appearing pop-up menus.
1.2.1.4 Auto-Completion
Auto-Complete (Ctrl-Space) in many editors means finding extensions to the name under the cursor. In Eclipse, it means guessing what you were probably about to write. As with Quick-Fix, it is useful to invoke the tool very often to learn about its possibilities.
In its basic capacity, Auto-Complete will propose extensions to type, method, and field names. It will also add import declarations as necessary. Using CamelCase notation often simplifies the input. To get, for instance, IFileEditorInput, just auto-complete IFEI; since there is only one completion, it expands immediately. When looking for method names, Auto-Complete uses the type of the invocation target. But it does even more: If the current position is guarded by an instanceof test, it offers the methods of the specialized type and adds the required cast.
![]() Under Preferences/Java/Editor/Content Assist, you can include or exclude names that are not actually available at the current point. In exploratory programming, at the beginning of projects, or with new libraries, it is often useful to get all proposals, even if they result in a compilation error; you can always quick-fix that error later on.
Under Preferences/Java/Editor/Content Assist, you can include or exclude names that are not actually available at the current point. In exploratory programming, at the beginning of projects, or with new libraries, it is often useful to get all proposals, even if they result in a compilation error; you can always quick-fix that error later on.
![]()
![]() 12.3.3
12.3.3 ![]() A.1.2When working with plugins, it is often useful to auto-complete even types from plugins that are not not yet referenced by the current project. To enable this, open the Plug-ins view, select all entries, and choose Add to Java Search from the context menu. You can later use Quick-Fix to add the missing dependencies.
A.1.2When working with plugins, it is often useful to auto-complete even types from plugins that are not not yet referenced by the current project. To enable this, open the Plug-ins view, select all entries, and choose Add to Java Search from the context menu. You can later use Quick-Fix to add the missing dependencies.
Auto-Complete also includes many code templates. Expanding the class name, for example, yields a default constructor. At the class level, a method name from the superclass creates an overriding method; completing get or set offers getters and setters for fields; static_finalcompletes to a constant definition. Expanding toarray calls the toArray() method of a collection in the context; you can choose which one through linked positions.
1.2.1.5 Surround With
Developing code is often an explorative process: You write down part of a larger computation and only later realize that it should actually be guarded by an if, or must run in a different thread altogether, so that it must be![]() 148 packaged into a Runnable object. The tool Surround With(Alt-Shift-Z) offers a choice of handy modifications that often need to be applied as an afterthought in daily work.
148 packaged into a Runnable object. The tool Surround With(Alt-Shift-Z) offers a choice of handy modifications that often need to be applied as an afterthought in daily work.
1.2.1.6 The Source Menu
An obvious place to look for code generation patterns is the Source menu. We have saved it for last because many of its tools are also available more easily through Auto-Complete or Quick-Fix. Yet, this menu often offers more comprehensive support. For instance, you can generate getters and setters for several fields, or override several methods at once. In practice, you will soon get a feel for whether the extra effort in going through the menu and a dialog offers any advantages over invoking the tool through other access paths. It is also worthwhile to get used to keyboard shortcuts to the menu items. For instance, Alt-S R is handy for generating getters and setters for fields; Alt-Shift-S shows a pop-up version of the menu over the editor.
1.2.2 Refactoring: Incremental Design Improvements
In the early days of computing, it was commonly thought that a software![]() 54 project should progress in a linear fashion: Gather the requirements from the users, lay down the system architecture, then the design, then specify the single classes and their methods, and finally implement and test them. This was called the waterfall model. Unfortunately, the waterfall has washed away many a software project.
54 project should progress in a linear fashion: Gather the requirements from the users, lay down the system architecture, then the design, then specify the single classes and their methods, and finally implement and test them. This was called the waterfall model. Unfortunately, the waterfall has washed away many a software project.
Later software processes acknowledge that one learns during development by including cycles that allow going back to earlier project phases.![]() 233 Agile software development then established truly iterative development,
233 Agile software development then established truly iterative development,![]() 28 and demanded a focus on the code, rather than on plans and documents. The challenge is, of course, that the design will change when the code already exists.
28 and demanded a focus on the code, rather than on plans and documents. The challenge is, of course, that the design will change when the code already exists.
At a smaller scale, every developer knows that coding an object yields new insights on how the object should best be designed. After having written out the solution, one simply understands more of the solution’s structure.
Expect to adapt objects to new design insights.
When you find that a new base class is a good place for shared functionality,![]() 3.1.3 introduce it. When you find that your colleague’s tangled method can
3.1.3 introduce it. When you find that your colleague’s tangled method can![]() 1.4.5
1.4.5 ![]() 1.4.6 be perceived as a few high-level processing steps, introduce them. When you think of a better name for some variable, change it. A slogan in the
1.4.6 be perceived as a few high-level processing steps, introduce them. When you think of a better name for some variable, change it. A slogan in the![]() 1.2.3 community nowadays is “Leave the campground cleaner than you found it.”
1.2.3 community nowadays is “Leave the campground cleaner than you found it.”![]() 172
172
Of course, it won’t do to anarchically change the design every few days. There must be some discipline to avoid breaking other classes and delaying the project’s progress.![]() 92
92
Refactoring means improving the design without changing functionality.
Refactoring applies to existing, working, running, productive code. To avoid![]() 5.4.8 accidental breakage, the overall code base should be well tested. However, you can also write tests just to capture the current functionality of a specific object, and then go ahead and refactor it.
5.4.8 accidental breakage, the overall code base should be well tested. However, you can also write tests just to capture the current functionality of a specific object, and then go ahead and refactor it.
Refactoring is a transaction that takes a running application to a running application.
Writing tests for “obvious” modifications such as changing names seems, of course, so cumbersome that no one would do it. More generally, many frequent refactorings are syntactic in nature, and there is little danger of accidents. Eclipse provides a broad and stable tool support for refactorings, which we will introduce throughout this chapter, together with the constructs that they apply to.
Learn to use the Eclipse refactoring tools.
The Eclipse tools for reliable refactorings are accessible through a common menu, very often through the context menu:
Tool: Eclipse Refactoring Tools
In most circumstances, select the element to be modified and press Alt-Shift-T to invoke the refactoring context menu.
One word of warning is in order: Cleaning up the structure often yields opportunities to add new functionality “while you’re looking at the class anyway.” Indeed, refactorings are often applied precisely because new functionality will not fit the existing structure. However, you should not yield to temptation. First, apply the planned sequence of refactorings and restore the old system behavior. Then, commit the changes to your versioning system. Only at that point should you change the functionality.
Don’t introduce new functionality during refactoring.
This rule is often used to argue that refactoring is a wasted effort: The point is not to change the functionality, but then functionality is what the customer pays for. This argument is short-sighted, because it neglects the internal cost of implementing the requested functionality:
Refactoring makes developers more productive.
Refactoring is usually essential to achieve a project’s goals with less effort and sometimes to achieve them at all. Refactoring changes the software structure so that new functionality will fit in more easily. It can separate special logic from general mechanisms and can enable reuse of the general parts. It makes the code more readable and more understandable. As a result, it reduces the time spent on debugging and on digging into the code written by other team members. During maintenance—and maintenance is the most cost-intensive part of the software life cycle—developers will find their way around the code more easily and will make the necessary adaptations with more confidence and in less time. In the end, refactoring is not a matter of taste in software design, but rather translates into direct gains in the cost of software production.
1.2.3 The Crucial Role of Naming
Whenever we code, we choose names: for variables, fields, methods, classes, packages, and so on. These names are for the human readers: for your fellow team members, for the later maintenance developers, and for yourself if you happen to come back to the code a few months later. Carefully chosen names can convey meaning and intention, while poorly chosen names may mislead and confuse readers and make them spend more time trying to decipher the code than necessary. The literature contains many guidelines and hints![]() 55
55 ![]() 172(Ch.17, N) on naming. Here, we give a general overview to encourage you to consider
172(Ch.17, N) on naming. Here, we give a general overview to encourage you to consider![]() 263(p.67, p.69, p.88ff) naming a central activity in software development.
263(p.67, p.69, p.88ff) naming a central activity in software development.
Think of names as documentation.
Most developers dislike documentation, because it takes away time from coding, gets outdated quickly, and is not read anyway. Not writing documentation means, however, that others will have to understand the code. Luckily, there is a simple way out: All language elements, from classes to local variables, have names that you can use to express your intention in![]() 11.2.1 writing the code. Knowing your intention will help future readers to grasp the working of the code. This gain in productivity motivates a simple guideline:
11.2.1 writing the code. Knowing your intention will help future readers to grasp the working of the code. This gain in productivity motivates a simple guideline:
Invest time in finding the most appropriate names.
Suppose you are writing a data processing tool that deals with table-like structures, similar to relational database systems. You will have objects representing single data records. Without much thought, you could call these “data items”—but then, that’s not very specific, since “item” has a rather fuzzy meaning. When focusing on the table structure, you might prefer “data row” or simply “row.” In the context of databases, however, you might speak of a “record.” Try out different variants, drawing on established names and your experience. You may also employ a thesaurus for inspiration![]() 141 about closely related words.
141 about closely related words.
As with any choice, you may find that the name that was best at one point later turns out to be unsuitable. For instance, when writing a loop that traverses a string, you may have introduced an index pos for the current position. As you proceed, you discover several further “positions”: the first occurrence of some character, the end of some substring, and so on. To make the code more readable, you should change pos into curPos or even searchPosition, to describe the content more precisely. Fortunately:
There is no excuse for keeping bad names.
Changing names is so common that Eclipse provides extensive support for this operation. For novices, it may be daunting to go through the![]() 1.2.2 Refactoring menu, but that place was chosen merely to emphasize that renaming is a proper structural code modification that does not alter the meaning of the code.
1.2.2 Refactoring menu, but that place was chosen merely to emphasize that renaming is a proper structural code modification that does not alter the meaning of the code.
Tool: Renaming
Place the cursor over any name in the editor, or select an element in the package explorer. Then press Alt-Shift-R or use the Refactoring/Rename menu (Alt-Shift-T).
One important exception to changing bad names immediately is, of course, in the public interface of your software: If you offer functionality to others, your clients’ code will be broken. As an extreme example, there is the case![]() 61 of the function SHStripMneumonic in the Windows API—once it was published, there was simply no way to correct the name to SHStripMnemonic.
61 of the function SHStripMneumonic in the Windows API—once it was published, there was simply no way to correct the name to SHStripMnemonic.
A general guideline for choosing good names derives from the fact that humans tend to jump to conclusions:
Use similar names for similar things, and different names for different things.
When humans see a ScreenManager and a Display in the system, they will assume that someone was sloppy and the former actually manages the latter. If this is the case, rename ScreenManager to DisplayManager; otherwise, choose a completely different name, such asWindowLayoutManager (if that is its task). To make the point very clear, let’s look at an example![]() 214 where the rule has been disobeyed. The developer guide of Eclipse’s Graphical Editing Framework (GEF) states somewhat awkwardly:
214 where the rule has been disobeyed. The developer guide of Eclipse’s Graphical Editing Framework (GEF) states somewhat awkwardly:
The “source” and “target” nodes should not be confused with “source” and “target” feedback. For feedback, “source” simply means show the feedback for the connection, while “target” means highlight the mouse target.
Since names serve communication purposes, they often crop up in discussions among the team. For this situation, it is important to obey a simple rule:
Make names pronouncable.
This strategy also implies that abbreviations should in general be avoided, unless they have an obvious expansion, which can then be pronounced. Note that auto-completion invalidates the excuse that abbreviations reduce the![]() 1.2.1.4 typing effort. In fact, use of CamelCase often makes it easier to enter the longer, pronouncable name.
1.2.1.4 typing effort. In fact, use of CamelCase often makes it easier to enter the longer, pronouncable name.
The goal of communication also implies that names should conjure up associations in the reader’s mind.
Use names to refer to well-known concepts.
For instance, if a name includes the term “cache,” then the reader will immediately be aware that it contains temporary data that is kept for efficiency reasons, but is really derived from some other data.
If a concept is very general, you should qualify it further through composite names. For instance, the associations of a “hash map” are clear. The more specific class IdentityHashMap then turns out to associate values to objects based on object identity, instead of its equals andhashCode methods. However, the reference to well-known concepts is not unproblematic,![]() 1.4.13 since it depends on the intended group of readers. Therefore:
1.4.13 since it depends on the intended group of readers. Therefore:
Choose names to fit the context.
Names are often linked to the project, team, and and part of the system. At a basic level, coding conventions may dictate, for example, that fields are prefixed by f. Look at, for instance, JavaTextTools and other classes from the Eclipse Java tooling for examples. Default implementations of interfaces![]() 3.1.4 are often suffixed with Adapter, such as in SWT’s MouseAdapter. Further, patterns come with naming conventions. For example, observer interfaces
3.1.4 are often suffixed with Adapter, such as in SWT’s MouseAdapter. Further, patterns come with naming conventions. For example, observer interfaces![]() 2.1 in Java usually have the suffix Listener. Similarly, in the Eclipse platform the update method from the pattern is called refresh. Examples are seen in JFace’s Viewer class and the EditPart from the Graphical
2.1 in Java usually have the suffix Listener. Similarly, in the Eclipse platform the update method from the pattern is called refresh. Examples are seen in JFace’s Viewer class and the EditPart from the Graphical![]() 9.3.1
9.3.1 ![]() 214 Editing Framework. Finally, the layer of the object is important: Domain objects have domain names, such as BankAccount, while technical objects have technical names, such as LabelProvider.
214 Editing Framework. Finally, the layer of the object is important: Domain objects have domain names, such as BankAccount, while technical objects have technical names, such as LabelProvider.
Sometimes, it can help to merge several views:
Choose compound names to indicate different aspects.
For instance, a BankAccountLabelProvider clearly is a technical object that implements a LabelProvider for domain-level BankAccounts.
One distinction to be obeyed painstakingly is that between the external![]() 4.1
4.1 ![]() 1.1 and internal views of an object: The public methods’ names must not refer to internal implementation decisions.
1.1 and internal views of an object: The public methods’ names must not refer to internal implementation decisions.
Public names must be understandable without knowing the internals.
You can see whether you have got the naming right if you have achieved a simple overall goal:
Choose names such that the source code tells its own story.
Code telling a story is easy to recognize. Suppose you read through a longish piece of code that calls some methods, accesses a few fields, and stores temporary results in local variables. At the same time, you have a good sense of what is going on, because the names establish conceptual links![]() 141 between the various steps and data items: This is code that tells a story. Make it a habit to look through code that you have just finished and to
141 between the various steps and data items: This is code that tells a story. Make it a habit to look through code that you have just finished and to![]() 1.4.5 rearrange and rename until you are satisfied with the story.
1.4.5 rearrange and rename until you are satisfied with the story.
Developers are a close-knit community, and one that is partly held together by common jokes, puns, and folklore. Nevertheless, we hope that you are by now convinced that names are too important to sacrifice them to short-lived merriment:
Don’t joke with names.
Here is an example.1 At some point, someone found it funny to use a Hebrew token name for the namespace separator :: in PHP. Unfortunately, this “internal” choice later turned up in error messages to the user, confusing everyone not in the know:
parse error, unexpected T_PAAMAYIM_NEKUDOTAYIM
1. http://php.net/manual/en/keyword.paamayim-nekudotayim.php
Such occurrences are so common that there are collections of rules to avoid them.2 Names referring to the author’s favorite movie, pseudo-random words such as starship, and “temporary” names with my and foo in them are known to have made it into releases.
2. See, for example, http://thc.org/root/phun/unmaintain.html and http://c2.com/cgi/wiki?BadVariableNames
1.3 Fields
An object’s fields are usually at the core of operations: They store the information that the object works on, the knowledge from which it computes![]() 1.1
1.1 ![]() 4.1 answers to method calls, and the basis on which it makes decisions. From the larger perspective of the overall system, however, this core of an object is a private, hidden detail. Consequently, other objects must not make any assumptions about which fields exist and what they contain.
4.1 answers to method calls, and the basis on which it makes decisions. From the larger perspective of the overall system, however, this core of an object is a private, hidden detail. Consequently, other objects must not make any assumptions about which fields exist and what they contain.
An object’s fields are its private property.
The seminal object-oriented language Smalltalk takes this goal very seriously:![]() 109 Only the object itself can access its fields (including those inherited from its superclass); field access across objects is impossible. In Java, access
109 Only the object itself can access its fields (including those inherited from its superclass); field access across objects is impossible. In Java, access![]() 232 rights follow the philosophy of “participating in the implementation”: An object
232 rights follow the philosophy of “participating in the implementation”: An object![]() 111 can access private fields of other instances of its own class, protected fields can be accessed from all subclasses and classes in the same package, and default visible fields (without modifiers) are shared within the package. public fields are even open to the world in general.
111 can access private fields of other instances of its own class, protected fields can be accessed from all subclasses and classes in the same package, and default visible fields (without modifiers) are shared within the package. public fields are even open to the world in general.
While all fields, technically speaking, store data, general usage differentiates between various intentions and interpretations associated with that data. Anticipating these intentions often helps in understanding the fields of a concrete object and their implied interdependencies. Before we start, one general remark should be noted:
An object’s fields last for its lifetime.
Fields are initialized when the object is created by the constructor. Afterward,![]() 1.6.1 they retain their meaning until the object is picked up by the garbage collector. At each point in time, you should be able to say what each field
1.6.1 they retain their meaning until the object is picked up by the garbage collector. At each point in time, you should be able to say what each field![]() 4.1 contains and how it relates to the other fields. In consequence, you should refrain from “reusing” fields for different kinds of data, even if the type fits. It is far better to invest in a second field. Also, you should avoid having fields that are valid only temporarily, and prefer to introduce helper objects.
4.1 contains and how it relates to the other fields. In consequence, you should refrain from “reusing” fields for different kinds of data, even if the type fits. It is far better to invest in a second field. Also, you should avoid having fields that are valid only temporarily, and prefer to introduce helper objects.![]() 1.8.6
1.8.6
1.3.1 Data Structures
At the most basic level, objects use fields to maintain and structure their data. For instance, the GapTextStore lies at the heart of text management in the Eclipse source editors. It maintains a possibly large text efficiently in a flat array and still provides (mostly) constant time manipulations for frequent operations, such as typing a single character.
Figure 1.2 depicts the meaning of the following fields:
org.eclipse.jface.text.GapTextStore
private char[] fContent;
private int fGapStart;
private int fGapEnd;

Figure 1.2 The GapTextStore Data Structure
The fContent is the flat storage area. The gap between fGapStart and fGapEnd is unused; the remainder stores the actual text in two chunks. Text modifications are performed easily at fGapStart: New characters go into the gap and deletions move the gap start backward. To modify other positions, the object moves the gap within the buffer, by copying around the (usually few) characters between the gap and the new start. The array is resized only in the rare event that the gap becomes empty or too large.
![]() 72 This is a typical data structure, like the ones often found in textbooks. In such a structure, primitive data types are combined to represent some abstract value with operations, here a text with the usual modifications. It is also typical in that the object’s interface is very simple and hides
72 This is a typical data structure, like the ones often found in textbooks. In such a structure, primitive data types are combined to represent some abstract value with operations, here a text with the usual modifications. It is also typical in that the object’s interface is very simple and hides![]() 4.1 the intricate case distinctions about moving and resizing the gap—that is, clients merely invoke the following method to remove length characters at offset and insert the string text instead.
4.1 the intricate case distinctions about moving and resizing the gap—that is, clients merely invoke the following method to remove length characters at offset and insert the string text instead.
org.eclipse.jface.text.GapTextStore
public void replace(int offset, int length, String text)
Data structures can also be built from objects, rather than primitive types.![]() 72 For instance, the JDK’s HashMap uses singly linked lists of Entry objects to represent buckets for collision resolution. As in the case of primitive types, the HashMap contains all the logic for maintaining the data structure in the following fields. Entry objects have only basic getter-like methods and serve as passive containers of information, rather than as active objects.
72 For instance, the JDK’s HashMap uses singly linked lists of Entry objects to represent buckets for collision resolution. As in the case of primitive types, the HashMap contains all the logic for maintaining the data structure in the following fields. Entry objects have only basic getter-like methods and serve as passive containers of information, rather than as active objects.
java.util.HashMap
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
![]() The transient modifier states that the field is not serialized to disk in the default manner. Instead, Java’s serialization mechanism invokes writeObject and read Object from HashMap.
The transient modifier states that the field is not serialized to disk in the default manner. Instead, Java’s serialization mechanism invokes writeObject and read Object from HashMap.
The final modifier states that the field must not be altered after it has been initialized in the constructor. The compiler also tracks whether the field is, in fact, initialized.
Data structures are frequently constructed from larger and more powerful building blocks, in particular from the collections framework. For instance,![]() 9.3.2 the JFace AbstractListViewer displays lists of data items. It maintains these items in a general list, rather than an array, because that facilitates operations:
9.3.2 the JFace AbstractListViewer displays lists of data items. It maintains these items in a general list, rather than an array, because that facilitates operations:
org.eclipse.jface.viewers.AbstractListViewer
private java.util.List listMap = new ArrayList();
The common theme of these examples is that the main object contains all the logic and code necessary to maintain the data structure fields. Even if those fields technically do contain objects, they are only passive information holders and do not contribute any functionality on their own—they perform menial housekeeping tasks, at best.
Don’t implement tasks partially in data structure objects.
Mentally classifying fields as “data structures” helps to clearly separate concerns, and you know that the contained objects are uninteresting when it comes to maintenance and debugging. At the same time, the work is clearly divided—or rather not divided in that the host object takes it on completely. If you do want helper objects to contribute, do so properly and![]() 1.3.2
1.3.2 ![]() 1.8.2
1.8.2 ![]() 1.8.5 give them self-contained tasks of their own.
1.8.5 give them self-contained tasks of their own.
1.3.2 Collaborators
Objects are team players: When some other object already has the data and![]() 1.1 logic for performing some task, they are happy to delegate that task. One can also say that the objects collaborate. Very often, an object stores its
1.1 logic for performing some task, they are happy to delegate that task. One can also say that the objects collaborate. Very often, an object stores its![]() 11.1 collaborators in its fields, because it refers to them frequently throughout its lifetime. In contrast to data structures, an object entrusts collaborators with some part of its own specific responsibilities.
11.1 collaborators in its fields, because it refers to them frequently throughout its lifetime. In contrast to data structures, an object entrusts collaborators with some part of its own specific responsibilities.
The Eclipse platform’s JobManager provides a good example. Its purpose is to schedule and track all background Jobs, such as compiling Java![]() 7.10 files. This task is rather complex, since it has to account for priorities and dependencies between jobs. The manager therefore delegates some decisions to JobQueue objects held in three fields, for different groups of jobs. The method JobQueue.enqeue(), with its helpers, then takes care of priorities and resource dependencies.
7.10 files. This task is rather complex, since it has to account for priorities and dependencies between jobs. The manager therefore delegates some decisions to JobQueue objects held in three fields, for different groups of jobs. The method JobQueue.enqeue(), with its helpers, then takes care of priorities and resource dependencies.
org.eclipse.core.internal.jobs.JobManager
private final JobQueue sleeping;
private final JobQueue waiting;
final JobQueue waitingThreadJobs;
In contrast, the management of the currently running jobs is a core task of the JobManager itself, and the necessary logic belongs to that class. The bookkeeping is therefore performed in mere data structures, rather than![]() 1.3.1 self-contained objects. The JobManager is responsible for keeping up the expected relationships between the two sets—we will later see that these
1.3.1 self-contained objects. The JobManager is responsible for keeping up the expected relationships between the two sets—we will later see that these![]() 4.1 relationships become part of its class invariant.
4.1 relationships become part of its class invariant.
org.eclipse.core.internal.jobs.JobManager
private final HashSet running;
private final HashSet yielding;
![]() 2.2All of these examples incorporate the notion of ownership: The JobManager holds the sole references to the collaborators, the manager creates them,
2.2All of these examples incorporate the notion of ownership: The JobManager holds the sole references to the collaborators, the manager creates them,![]() 1.1 and their life cycle ends with that of the manager.
1.1 and their life cycle ends with that of the manager.
Collaboration is, however, not restricted to that setting; indeed, true![]() 1.1 networks of collaborating objects can be built only by sharing collaborators.
1.1 networks of collaborating objects can be built only by sharing collaborators.![]() 12.3.3.4 As an extreme example, the Eclipse IDE’s UI is composed from different editors and views, both of which are special workbench parts. Each such part holds a reference to the context, called a site, where it appears:
12.3.3.4 As an extreme example, the Eclipse IDE’s UI is composed from different editors and views, both of which are special workbench parts. Each such part holds a reference to the context, called a site, where it appears:
org.eclipse.ui.part.WorkbenchPart
private IWorkbenchPartSite partSite;
Through that site, views and editors can change the title on their tabs, and even access the overall workbench infrastructure, to observe changes, open and close parts, and perform other tasks.
1.3.3 Properties
![]() 1.1In general, objects treat their fields as a private matter that is no one else’s concern. In this manner, they are free to change the internal data format if it turns out that the current choice is inadequate. However, sometimes
1.1In general, objects treat their fields as a private matter that is no one else’s concern. In this manner, they are free to change the internal data format if it turns out that the current choice is inadequate. However, sometimes![]() 1.8.3 the task of some object is precisely to hold on to some information, and its clients can and must know about it. Such fields are called properties, and the object offers getters and setters for their properties—that is, methods named get
1.8.3 the task of some object is precisely to hold on to some information, and its clients can and must know about it. Such fields are called properties, and the object offers getters and setters for their properties—that is, methods named get ![]() property name
property name![]() and set
and set ![]() property name
property name![]() , respectively. For Boolean properties, the getter is named is
, respectively. For Boolean properties, the getter is named is ![]() property name
property name![]() . These methods are also collectively called accessors.
. These methods are also collectively called accessors.
![]() 9.3.4For instance, a JFace Action encapsulates a piece of functionality that can be put into menus, toolbars, and other UI components. It naturally has a text, icon, tool tip text, and other elements, so these fields are directly accessible by setters and getters. For more examples, just search for method declarations named set* inside Eclipse.
9.3.4For instance, a JFace Action encapsulates a piece of functionality that can be put into menus, toolbars, and other UI components. It naturally has a text, icon, tool tip text, and other elements, so these fields are directly accessible by setters and getters. For more examples, just search for method declarations named set* inside Eclipse.
Tool: Generating Getters and Setters
Since properties are so common, Eclipse offers extensive tool support for their specification. The obvious choice is Source/Generate Getters and Setters (Alt-S R or Alt-Shift-S R). You can also auto-complete get and set in the class body, possibly with a prefix of the property name. When the cursor is on the field name, you can choose Encapsulate Field from the refactoring menu (Alt-Shift-T), or just invoke Quick-Fix (Ctrl-1). The latter two tools will also make the field private if it was public before.
![]() Don’t generate getters and setters lightly, simply because Eclipse supports it. Always remember that an object’s data is conceptually private. Only fields that happen to fit the object’s public description are properties and should have accessor methods.
Don’t generate getters and setters lightly, simply because Eclipse supports it. Always remember that an object’s data is conceptually private. Only fields that happen to fit the object’s public description are properties and should have accessor methods.
![]() Beware that the generated getters return objects stored in fields by reference, so that clients can modify these internal data structures by calling the objects’ methods. This slip happens often with basic structures such as ArrayLists or HashMaps, and Eclipse does not recognize it. You must either return copies or wrap the objects by Collections.unmodifiableList() or similar methods. Similarly, when clients pass objects to setters, they may have retained a reference, with the same problematic results.
Beware that the generated getters return objects stored in fields by reference, so that clients can modify these internal data structures by calling the objects’ methods. This slip happens often with basic structures such as ArrayLists or HashMaps, and Eclipse does not recognize it. You must either return copies or wrap the objects by Collections.unmodifiableList() or similar methods. Similarly, when clients pass objects to setters, they may have retained a reference, with the same problematic results.
Sometimes, the stored information is so obvious and elementary that the fields themselves can be public. For instance, SWT decides that a![]() 7.1 Rectangle obviously has a position and a size, so making the fields x, y, width, and height public is hardly giving away any secrets. Besides, the simplicity of the class and the data makes it improbable that it will ever be changed.
7.1 Rectangle obviously has a position and a size, so making the fields x, y, width, and height public is hardly giving away any secrets. Besides, the simplicity of the class and the data makes it improbable that it will ever be changed.
Even more rarely, efficiency requirements may dictate public fields. For instance, Positions represents points in a text document. Of course, these must be updated upon each and every text modification, even when only a single character is typed. To enableDefaultPositionUpdater to perform these frequent updates quickly, the position’s fields are public (following Amdahl’s law).![]() 1.1
1.1
It is also worth noting that sometimes properties are not backed by physical fields within the object itself. For instance, the accessors of SWT widgets often delegate to a native implementation object that actually appears![]() 7.1 on the screen. In turn, a Label’s foreground color, a Textfield’s content, and many more properties are stored only at the native C layer. Conceptually, this does not change their status as properties, and tools such as the WindowBuilder do rely on the established naming conventions.
7.1 on the screen. In turn, a Label’s foreground color, a Textfield’s content, and many more properties are stored only at the native C layer. Conceptually, this does not change their status as properties, and tools such as the WindowBuilder do rely on the established naming conventions.![]() 7.2
7.2
Finally, the JavaBeans specification defines further support. When bound properties![]() 202 are changed, beans will send notifications to PropertyChange Listeners according to the OBSERVER pattern. For constrained properties,
202 are changed, beans will send notifications to PropertyChange Listeners according to the OBSERVER pattern. For constrained properties,![]() 2.1 observers can even forbid invalid changes.
2.1 observers can even forbid invalid changes.
1.3.4 Flags and Configuration
Properties usually contain the data that an object works with, or that characterize its state. Sometimes, they do more: The value of the property influences the object’s behavior and in particular the decisions that the![]() 1.1 object makes. Knowing that the property has more influence than mere passive data is essential for understanding and using it correctly.
1.1 object makes. Knowing that the property has more influence than mere passive data is essential for understanding and using it correctly.
As a typical example, consider an URLConnection for accessing a web server, usually over HTTP. Before it is opened, the connection can be configured to enable sending data, by timeout intervals, and in many other ways. All of these choices are not passed on as data, but influence the connection’s behavior.
java.net.URLConnection
protected boolean doOutput = false;
private int connectTimeout;
private int readTimeout;
Boolean configuration properties are called flags. Very often, they are stored in bit masks to save space. In the following snippet from SWT’s text field, the READ_ONLY bit is first cleared, then perhaps reset if necessary. The style bit field here is shared through the built-in Widgethierarchy.
org.eclipse.swt.widgets.Text
public void setEditable(boolean editable) {
style &= ~SWT.READ_ONLY;
if (!editable)
style |= SWT.READ_ONLY;
}
Beyond elementary types, configuration properties may also contain objects. An object is given a special collaborator, with the intention of defining or modifying its behavior by specifying the desired collaboration. For instance,![]() 7.5 all Composite widgets on the screen must somehow arrange the contained child elements. However, there are huge differences: While toolbars create visual rows of their children, forms often place them in a tabular arrangement. A composite’s behavior can therefore be configured by a Layout, which computes the children’s positions on behalf of the composite widget. The predefined choices such as RowLayout, GridLayout, and StackLayout cover the most common scenarios.
7.5 all Composite widgets on the screen must somehow arrange the contained child elements. However, there are huge differences: While toolbars create visual rows of their children, forms often place them in a tabular arrangement. A composite’s behavior can therefore be configured by a Layout, which computes the children’s positions on behalf of the composite widget. The predefined choices such as RowLayout, GridLayout, and StackLayout cover the most common scenarios.
Configuration by objects in this way is an application of the STRATEGY![]() 12.3
12.3 ![]() 100 pattern:
100 pattern:
Pattern: Strategy
Encapsulate algorithms (i.e., solutions to a given problem) with a common interface so that clients can use them interchangeably.
1. Identify the common aspects of the various solutions and define an interface (or abstract base class) Strategy capturing the access paths and expected behavior.
2. Define ConcreteStrategy objects that implement Strategy.
3. Optional: Rethink your definitions and refactor to enable clients to provide their own concrete strategies.
After you have performed these steps, objects can be parameterized by a strategy by simply storing that strategy in a property.
A second use of the STRATEGY pattern is to encapsulate algorithms![]() 1.8.6 as objects, without the goal of abstracting over families of algorithms. In this case, the complexities of the algorithm can be hidden behind a small, readable interface. If the family of algorithms is not to be extensible, the
1.8.6 as objects, without the goal of abstracting over families of algorithms. In this case, the complexities of the algorithm can be hidden behind a small, readable interface. If the family of algorithms is not to be extensible, the![]() 3.1.6 pattern might degenerate to a reified case distinction.
3.1.6 pattern might degenerate to a reified case distinction.
1.3.5 Abstract State
An object’s state consists, in principle, of the current data stored in its fields. Very often, it is useful to abstract over the individual fields and their![]() 10 data structures, and to assign a small number of named states instead. For example, a button on the screen is “idle,” “pressed,” or “armed” (meaning releasing the button now will trigger its action); a combo box has a selection list that is either opened or closed. These summary descriptions of the object’s state enable clients to understand the object’s behavior in general terms. For instance, the documentation may state, “The button sends a released notification if it is in the armed state and the user releases the mouse button.”
10 data structures, and to assign a small number of named states instead. For example, a button on the screen is “idle,” “pressed,” or “armed” (meaning releasing the button now will trigger its action); a combo box has a selection list that is either opened or closed. These summary descriptions of the object’s state enable clients to understand the object’s behavior in general terms. For instance, the documentation may state, “The button sends a released notification if it is in the armed state and the user releases the mouse button.”
Sometimes, the abstract state is reflected in the object’s fields. While![]() 10.3 direct enumerations are rare, combinations of Boolean flags that determine the state are quite common. For instance, a ButtonModel in the Graphical
10.3 direct enumerations are rare, combinations of Boolean flags that determine the state are quite common. For instance, a ButtonModel in the Graphical![]() 214 Editing Framework has a bit field state for that purpose (shown slightly
214 Editing Framework has a bit field state for that purpose (shown slightly![]() 1.3.4 simplified here):
1.3.4 simplified here):
org.eclipse.draw2d.ButtonModel
protected static final int ARMED_FLAG = 1;
protected static final int PRESSED_FLAG = 2;
protected static final int ENABLED_FLAG = 16;
private int state = ENABLED_FLAG;
A second, very instructive example is found in Socket, whose state fields reflect the sophisticated state model of TCP network connections.![]() 237
237
While it is not mandatory to make the abstract state explicit in the concrete state, it often leads to code that tells its own story. For instance,![]() 1.2.3 the setPressed() method of ButtonModel is called whenever the user presses or releases the mouse button. The previously given documentation is then directly expressed in the method’s control flow, especially in lines 5–6 (value is the new pressed/non-pressed state).
1.2.3 the setPressed() method of ButtonModel is called whenever the user presses or releases the mouse button. The previously given documentation is then directly expressed in the method’s control flow, especially in lines 5–6 (value is the new pressed/non-pressed state).
org.eclipse.draw2d.ButtonModel.setPressed
1 setFlag(PRESSED_FLAG, value);
2 if (value)
3 firePressed();
4 else {
5 if (isArmed())
6 fireReleased();
7 else
8 fireCanceled();
9 }
1.3.6 Caches
Designing networks of objects sometimes involves a dilemma between a natural structure that reflects the specification and problem domain directly,![]() 1.1 and the necessity to make frequently called methods really fast. This dilemma is best resolved by choosing the natural structure and method implementations to ensure correctness, and by making the methods store previously computed results in index data structures, such as HashMaps.
1.1 and the necessity to make frequently called methods really fast. This dilemma is best resolved by choosing the natural structure and method implementations to ensure correctness, and by making the methods store previously computed results in index data structures, such as HashMaps.
Caches hold derived data that could, in principle, be recomputed at any time.
A typical example is found in the Eclipse JDT’s Java compiler. The compiler must track super-type relationships between defined classes and interfaces, and the natural structure is simple: Just store the types from the source code directly (a ReferenceBinding is an object representing a resolved type, either from the source or from a library):
org.eclipse.jdt.internal.compiler.lookup.SourceTypeBinding
public ReferenceBinding superclass;
public ReferenceBinding[] superInterfaces;
For any assignment c=d, the compiler will determine the types C and D of c and d, respectively. It must then decide whether a D object is valid for a C variable. This question clearly shows the dilemma mentioned previously: It is central for the correctness of the compiler, and should be implemented along the language specification by just searching through the superclass and superInterfaces. At the same time, it must be answered very often![]() 1.1 and very fast.
1.1 and very fast.
Caching comes to the rescue: A ReferenceBinding implements the specification directly in a private method isCompatibleWith0. The method implements a linear search through the super-types and is potentially expensive. The public method isCompatibleWith therefore wraps calls by consulting a cache. The following code is slightly simplified. Line 1 looks up the previous result, which can be either true, false, or null. If the result is known (i.e., result is not null) then that result is returned (lines 2–3). Otherwise, the linear method is called. However, there is a snag: The search could end up in an infinite recursion if the type hierarchy contains a cycle. This is resolved by placing false into the cache and letting each recursion step go through the public method—a cycle ends in returning false immediately in line 3; at the same time, the recursion itself can take advantage of the cache. If despite this check the call in line 7 returns true, then no cycle can be present, so the result is updated to true (line 8). With this setup, the answer to the subtyping query is computed only once for any pair of types.
org.eclipse.jdt.internal.compiler.lookup.ReferenceBinding.isCompatialbleWith
1 result = this.compatibleCache.get(otherType);
2 if (result != null) {
3 return result == Boolean.TRUE;
4 }
5 // break possible cycles
6 this.compatibleCache.put(otherType, Boolean.FALSE);
7 if (isCompatibleWith0(otherType, captureScope)) {
8 this.compatibleCache.put(otherType, Boolean.TRUE);
9 return true;
10 }
Caches are also a prime example of encapsulation, which is often motivated![]() 1.1
1.1 ![]() 4.1
4.1 ![]() 11.5.1 precisely by the fact that the object is free to exchange its internal data structures for more efficient versions. Callers of isCompatibleWith are not aware of the cache, apart from perhaps noting the superb performance. The presence or absence of the cache does not change the object’s observable behavior.
11.5.1 precisely by the fact that the object is free to exchange its internal data structures for more efficient versions. Callers of isCompatibleWith are not aware of the cache, apart from perhaps noting the superb performance. The presence or absence of the cache does not change the object’s observable behavior.
![]() One liability of caches is that they must be kept up-to-date. They contain information
One liability of caches is that they must be kept up-to-date. They contain information![]() 6.1.5 derived from possibly large object structures, and any change of these structures must be immediately reflected in the cache. The OBSERVER pattern offers a general approach
6.1.5 derived from possibly large object structures, and any change of these structures must be immediately reflected in the cache. The OBSERVER pattern offers a general approach![]() 2.1 to this consistency problem. However, you should be aware of the trade-off between the complexity of such a synchronization mechanism and the gain in efficiency obtained by caching. The question of optimizations cannot be evaded by caches.
2.1 to this consistency problem. However, you should be aware of the trade-off between the complexity of such a synchronization mechanism and the gain in efficiency obtained by caching. The question of optimizations cannot be evaded by caches.![]() 1.1
1.1
![]() Caches are effective only if the same answer is demanded several times. In other contexts, this behavior is also called locality of reference. In the case of a cache miss, the ordinary computation needs to be carried out anyway, while the overhead of maintaining the cache is added on top. In the case of the compiler, it is probable that a medium-sized code base, for instance during the recompilation of a project or package, will perform the same type conversion several times.
Caches are effective only if the same answer is demanded several times. In other contexts, this behavior is also called locality of reference. In the case of a cache miss, the ordinary computation needs to be carried out anyway, while the overhead of maintaining the cache is added on top. In the case of the compiler, it is probable that a medium-sized code base, for instance during the recompilation of a project or package, will perform the same type conversion several times.
![]() For long-lived caches, you must start to worry about the cache outgrowing the original data structure, simply because more and more answers keep accumulating. The central insight is that cache entries can be recomputed at any time, so you are free to discard some if the cache gets too large. This strategy is implemented by the JDT’s
For long-lived caches, you must start to worry about the cache outgrowing the original data structure, simply because more and more answers keep accumulating. The central insight is that cache entries can be recomputed at any time, so you are free to discard some if the cache gets too large. This strategy is implemented by the JDT’s![]() 99 JavaModelCache, which uses several ElementCaches to associate heavyweight information objects with lightweight IJavaElement handles. Sometimes, a more elegant solution is
99 JavaModelCache, which uses several ElementCaches to associate heavyweight information objects with lightweight IJavaElement handles. Sometimes, a more elegant solution is![]() 50 to leverage the garbage collector’s support for weak references: A WeakHashMap keeps an
50 to leverage the garbage collector’s support for weak references: A WeakHashMap keeps an![]() 133 entry only as long as its key is referenced from somewhere else.
133 entry only as long as its key is referenced from somewhere else.
1.3.7 Data Shared Between Methods
A central goal in coding methods is to keep the individual methods short![]() 1.4.5 and readable, by introducing separate methods for contained processing steps. Unfortunately, passing the required data can lead to long parameter lists, which likewise should be avoided. The obvious solution is to keep the data required by several methods in the object’s fields.
1.4.5 and readable, by introducing separate methods for contained processing steps. Unfortunately, passing the required data can lead to long parameter lists, which likewise should be avoided. The obvious solution is to keep the data required by several methods in the object’s fields.
![]() 1.3.4
1.3.4 ![]() 1.8.6 This approach applies in particular when complex algorithms are represented by objects according to the STRATEGY pattern. Examples can be found in the FastJavaPartitionScanner, which maintains the basic structure of Java source code within editors, or in Zest’s graph layout algorithms, such as SpringLayoutAlgorithm, but also in simple utilities such as the JDK’s StringTokenizer.
1.8.6 This approach applies in particular when complex algorithms are represented by objects according to the STRATEGY pattern. Examples can be found in the FastJavaPartitionScanner, which maintains the basic structure of Java source code within editors, or in Zest’s graph layout algorithms, such as SpringLayoutAlgorithm, but also in simple utilities such as the JDK’s StringTokenizer.
When coding methods and their submethods, you often find out too late that you have forgotten to pass a local variable as a parameter. When you expect that the data will be needed in several methods anyway, Eclipse makes it simple to keep it in a field directly:
Tool: Convert local Variable to Field
Go to the local variable declaration in the Java editor. From the Refactoring menu (Alt-Shift-T), select Convert local variable to field. Alternatively, you can use Quick-Fix (Ctrl-1) on the variable declaration.
This tool is particularly useful when the local variable contains an intermediate![]() 7.1 node in a larger data structure. For instance, when building a widget tree for display, you cannot always anticipate all the UI widgets that will need to be accessed in event listeners. Luckily, the problem is remedied by a quick keyboard shortcut.
7.1 node in a larger data structure. For instance, when building a widget tree for display, you cannot always anticipate all the UI widgets that will need to be accessed in event listeners. Luckily, the problem is remedied by a quick keyboard shortcut.
![]() Avoid introducing fields that contain valid data only temporarily; it can be rather tricky to ensure that all accesses will actually find valid data. If you find that you have several temporary fields, try to extract them to a separate class, together with the methods that use them. Very often, you will find that you are actually applying the STRATEGY pattern and are encapsulating an algorithm in an object.
Avoid introducing fields that contain valid data only temporarily; it can be rather tricky to ensure that all accesses will actually find valid data. If you find that you have several temporary fields, try to extract them to a separate class, together with the methods that use them. Very often, you will find that you are actually applying the STRATEGY pattern and are encapsulating an algorithm in an object.
1.3.8 Static Fields
The first rule about static fields is a simple one: Don’t use them.
Reserve static fields for special situations.
![]() 1.1Static fields go against the grain of object-oriented programming: They are associated with classes, not objects, and classes should be an irrelevant, merely technical necessity. While you can reuse functionality in objects by creating just another instance, you cannot clone classes. That is, a class exists once per JVM.3 When you find that you are using static fields very often, you should probably rather be writing in C (and even good C programmers shun global variables). However:
1.1Static fields go against the grain of object-oriented programming: They are associated with classes, not objects, and classes should be an irrelevant, merely technical necessity. While you can reuse functionality in objects by creating just another instance, you cannot clone classes. That is, a class exists once per JVM.3 When you find that you are using static fields very often, you should probably rather be writing in C (and even good C programmers shun global variables). However:
3. Technically, this is not quite true: A class is unique only within a class loader, and different class loaders may well load the same class several times, which leads to separate sets of its static fields coexisting at runtime. You should never try to exploit this feature, though.
Do use constants.
Fields declared as static final are constants, meaning named values. They are not associated with classes at runtime, the compiler usually inlines them, and they disappear from the binaries altogether. Whenever you find in the code a stray literal value that has some meaning by itself, consider introducing a constant instead.
Tool: Extract Constant
From the Refactoring menu (Alt-Shift-T), choose Extract constant.
It is sometimes inevitable to have global data for logical reasons. That is, when running Eclipse, there is only one Platform on which the application runs, one ResourcesPlugin that manages the disk state, and one JobManager that synchronizes background jobs. In such cases, you can apply![]() 7.10 the SINGLETON pattern. It ensures at least that clients keep working with objects and the implementation itself can also refer to a proper object.
7.10 the SINGLETON pattern. It ensures at least that clients keep working with objects and the implementation itself can also refer to a proper object.![]() 100
100
Pattern: Singleton
If for logical reasons a particular class can have only one instance, then ensure that only one instance can ever be created and make it accessible globally.
To implement the pattern, maintain a static instance (line 2) with a global getter (line 4) and make the sole constructor private (line 3) to disable the creation of further instances. Lazy creation (line 6) can increase efficiency, since very often singletons are rather comprehensive classes.
1 public class Singleton {
2 private static Singleton instance;
3 private Singleton() {}
4 public static Singleton getInstance() {
5 if (instance == null)
6 instance = new Singleton();
7 return instance;
8 }
9 }
![]() Be very conscientious about the logical justification of single instances. Singletons may appear an easy way out if you have forgotten to pass around some required
Be very conscientious about the logical justification of single instances. Singletons may appear an easy way out if you have forgotten to pass around some required![]() 226 object and need just any instance quickly. Don’t yield to that temptation: You lose the benefits of object-oriented programming, because your object’s fields are essentially global variables.
226 object and need just any instance quickly. Don’t yield to that temptation: You lose the benefits of object-oriented programming, because your object’s fields are essentially global variables.
![]()
![]() 163As a special implication, singletons make testing harder, because it is not possible to change the type of created object. Tests have to work with exactly the same
163As a special implication, singletons make testing harder, because it is not possible to change the type of created object. Tests have to work with exactly the same![]() 5.3.2.1 object as the production scenario. It is not possible to provide mock objects in creating
5.3.2.1 object as the production scenario. It is not possible to provide mock objects in creating![]() 5.3.2 a simplified fixture, so that its unit tests no longer run in the minimal possible context.
5.3.2 a simplified fixture, so that its unit tests no longer run in the minimal possible context.
![]()
![]() 8.1Be careful with SINGLETONS in multithreaded applications: When two threads invoke getInstance() simultaneously, it must be guaranteed that only a single instance is created. You can, for example, make the getInstance method synchronized, which uses the class’s built-in lock. Beyond that, the singleton object itself must, of course, be thread-safe. If you feel you need a global object in a multithreaded environment, you
8.1Be careful with SINGLETONS in multithreaded applications: When two threads invoke getInstance() simultaneously, it must be guaranteed that only a single instance is created. You can, for example, make the getInstance method synchronized, which uses the class’s built-in lock. Beyond that, the singleton object itself must, of course, be thread-safe. If you feel you need a global object in a multithreaded environment, you![]() 148 can also consider using thread-local variables, which are supported in the Java library by class ThreadLocal.
148 can also consider using thread-local variables, which are supported in the Java library by class ThreadLocal.
1.4 Methods
If objects are to be active, collaborating entities, it is their methods that must make them active and that enable them to collaborate. In other words, simply invoking a method on an object is sufficient to induce the object to perform actions, compute results, or make decisions. Understanding methods is therefore key to understanding objects. We will also discuss many![]() 100 design patterns already in this section, because their intention is best motivated and explained from the behavior of the occurring methods.
100 design patterns already in this section, because their intention is best motivated and explained from the behavior of the occurring methods.
1.4.1 An Object-Oriented View on Methods
In most presentations of object-oriented programming, methods are linked tightly with classes. You will know the approach: Classes define methods, the classes get instantiated, and one can invoke the defined methods on the instances.
public class BaseClass {
public int op(int x) {
return 2 * x;
}
}
BaseClass obj = new BaseClass();
System.out.println(obj.op(18));
Object-oriented programming is then characterized by polymorphism: One can define derived classes (or subclasses), and override the methods introduced in the base class (or superclass).
public class DerivedClass extends BaseClass {
public int op(int x) {
return x + 24;
}
}
The term polymorphism captures the fact that an object appears to have several “shapes.” An object of the derived class can be used wherever the base class is expected. The object appears to have acquired a new shape. The transition from shape DerivedClass to shape BaseClass is explicit in the call to method work() shown next. Technically speaking, we must distinguish between the static type of a variable or field, as declared in the source code, and the dynamic type, which is the class instantiated at runtime to create the contained object. Under the typing rules of Java, the dynamic type is always a subtype of the static type (where subtyping is reflexive, meaning it includes the case of the types being the same).
public void workWithObjects() {
DerivedClass obj = new DerivedClass();
work(obj);
}
public void work(BaseClass obj) {
System.out.println(obj.op(18));
}
We will not go into the details—you already know this material by heart.
To acquire a truly object-oriented coding style, it is, however, best to start out from a radically simple point of view:
Methods belong to the object, not to the class.
The language Smalltalk makes this view explicit: One does not “invoke” a![]() 123,109 method at all, but rather sends a message to the object and the object itself decides which method it will execute in response. The object-based language JavaScript takes an even more literal approach and says that
123,109 method at all, but rather sends a message to the object and the object itself decides which method it will execute in response. The object-based language JavaScript takes an even more literal approach and says that![]() 85 “methods” are merely functions stored in an object’s fields. In Java, the previously described simplification has the virtue of deliberately blurring the technical details of inheritance hierarchies: No matter how the method ended up in the object, the important thing is that it exists and can be invoked.
85 “methods” are merely functions stored in an object’s fields. In Java, the previously described simplification has the virtue of deliberately blurring the technical details of inheritance hierarchies: No matter how the method ended up in the object, the important thing is that it exists and can be invoked.![]() 111
111
![]() You will appreciate the simplicity of the formulation if you follow the details in the Java Language Specification. The core is in §15.12.4.4, which defines the dynamic method lookup
You will appreciate the simplicity of the formulation if you follow the details in the Java Language Specification. The core is in §15.12.4.4, which defines the dynamic method lookup![]() 239 procedure in method invocations, or more precisely virtual method invocations. Dynamic method lookup involves both the runtime class R of the target object and the compile-time type X of the object reference used to invoke the method m. It searches classes S, starting with R and traversing the hierarchy upward, until the central case applies: “If [ ... ] the declaration in Soverrides (§8.4.8.1) X.m, then the method declared in S is the method to be invoked [ ... ].” Not only does this definition involve the interaction of several concepts, but it also gives only a procedural description of the lookup through a linear search in the inheritance hierarchy. If you think through these steps for every single method call, you will never get any coding done.
239 procedure in method invocations, or more precisely virtual method invocations. Dynamic method lookup involves both the runtime class R of the target object and the compile-time type X of the object reference used to invoke the method m. It searches classes S, starting with R and traversing the hierarchy upward, until the central case applies: “If [ ... ] the declaration in Soverrides (§8.4.8.1) X.m, then the method declared in S is the method to be invoked [ ... ].” Not only does this definition involve the interaction of several concepts, but it also gives only a procedural description of the lookup through a linear search in the inheritance hierarchy. If you think through these steps for every single method call, you will never get any coding done.
For practical purposes, the following understanding is sufficient:
When a class declares a method, then this method will be stored into all of its instances.
Furthermore, a class inherits all methods declared in its superclass that it does not declare itself.
This formulation has the advantage that the runtime behavior remains simple: To find the invoked method, just look what has ended up in the object. The usual Java terminology is just a more detailed version:
• ![]() 111(§8.4.2)A method’s signature consists of its name and parameter types.
111(§8.4.2)A method’s signature consists of its name and parameter types.
• If a superclass happens to have declared a method with the same signature, then that method is said to be overridden.
• If a superclass or interface happens to have declared only an abstract method with the same signature, then that method is said to be implemented.
Method overriding replaces an inherited method with a new, completely independent![]() 3.1.1 version. Again, however, the important point is not the process, but the result:
3.1.1 version. Again, however, the important point is not the process, but the result:
Callers are not aware of the replacement of a method by overriding.
![]()
![]() 111(§15.12.4.4) The technically minded reader may find it helpful to know that this is what actually
111(§15.12.4.4) The technically minded reader may find it helpful to know that this is what actually![]() 3,19,239 happens internally: The JVM keeps a method dispatch table per class, which has a slot for every method declared in the hierarchy. Each slot contains a code pointer to the currently valid method; overriding replaces the code pointer. To invoke a method, the JVM merely looks up the table from the object, then the code from the table. C++ uses the term virtual table for the same concept.
3,19,239 happens internally: The JVM keeps a method dispatch table per class, which has a slot for every method declared in the hierarchy. Each slot contains a code pointer to the currently valid method; overriding replaces the code pointer. To invoke a method, the JVM merely looks up the table from the object, then the code from the table. C++ uses the term virtual table for the same concept.
Tool: Override Method
To override one or more methods, choose Source/Override or Implement Methods (Alt-S V) and follow the steps in the dialog. For single methods, you can also type the name of an inherited method in a derived class, auto-complete it, and choose Override Method.
A second, more advanced tool takes care of slips in methods’ signatures. It is often the case that you want to add new parameters—for instance, if a generalized implementation of a method requires more information, or if design changes require further collaborations and passing along further objects.
Tool: Change Signature
To modify a method’s signature consistently throughout the code base, place the cursor in the method’s header, or its name at a call site, and use Alt-Shift-C (or Alt-Shift-T and the refactoring menu).
Finally, let us look at a special aspect of methods:
Use methods to enforce encapsulation.
Since the fields containing an object’s state are its private concern, methods![]() 1.3
1.3 ![]() 1.1 are the only way of accessing the object at all. At the same time, the methods’ definition determines whether the fields really remain private. We have seen some pitfalls when passing and returning internal objects
1.1 are the only way of accessing the object at all. At the same time, the methods’ definition determines whether the fields really remain private. We have seen some pitfalls when passing and returning internal objects![]() 1.3.3 by reference, which enables clients to modify these internals. As a positive example, think back to the GapTextStore: Its public methods present a
1.3.3 by reference, which enables clients to modify these internals. As a positive example, think back to the GapTextStore: Its public methods present a![]() 1.3.1 consistently simple view of a “stored text document” and never mention any aspects of its internal organization. You should always strive to write methods that do not allow the client even to guess at what goes on inside the object.
1.3.1 consistently simple view of a “stored text document” and never mention any aspects of its internal organization. You should always strive to write methods that do not allow the client even to guess at what goes on inside the object.
1.4.2 Method Overloading
It remains to introduce briefly a second language feature concerning methods: overloading. Overloading is completely orthogonal, or complementary, to the question of overriding: The two can be used in isolation or can be combined arbitrarily.
Compared to overriding, overloading is very simple and happens completely at compile-time. If an object contains two methods with the same name, but different signatures, then the method is said to be overloaded. For a method call, the compiler resolves the overloading by choosing the![]() 111(§15.12.2) “closest match” based on the types of the arguments. A method call in the created class file does not contain just the method’s name, but its entire signature. Consequently, there is no longer any ambiguity and no need for runtime choice. The usage of overloading is simple:
111(§15.12.2) “closest match” based on the types of the arguments. A method call in the created class file does not contain just the method’s name, but its entire signature. Consequently, there is no longer any ambiguity and no need for runtime choice. The usage of overloading is simple:
Overloading expresses a close logical relation between methods.
For instance, the Eclipse API for working with resources in the workspace offers two methods for obtaining a file from a surrounding folder:
org.eclipse.core.resources.IFolder
public IFile getFile(String name);
public IFile getFile(IPath path);
Indeed, the two methods are so closely related that the results of the following calls are the same (by equals(), since resource objects are handles):
IFile resultByString = folder.getFile("b/c");
IFile resultByPath =
folder.getFile(Path.fromPortableString("b/c"));
A special form of overloading is convenience methods, to be discussed![]() 1.4.4 shortly. They represent simplified versions of very general methods.
1.4.4 shortly. They represent simplified versions of very general methods.
![]() You should take the logical connection implied by overloading seriously: The reader expects that basically the same thing will happen in all variants of the method.
You should take the logical connection implied by overloading seriously: The reader expects that basically the same thing will happen in all variants of the method.![]() 1.1
1.1 ![]() 1.2.3
1.2.3 ![]() 1.4.3 Think from the callers’ perspective and aim at keeping their code readable. When in doubt, add some suffix to the name to disambiguate it.
1.4.3 Think from the callers’ perspective and aim at keeping their code readable. When in doubt, add some suffix to the name to disambiguate it.
![]() Overloading and overriding interact at one special point: Overriding takes place only if two methods have the same signature. Up to Java 1.4, a common source of errors was that a method seemed to override an inherited one, but introduced a small variation in the parameters, so that the old method remained in place. The @Override annotation reduces that risk, since the compiler can at least check that some method has been overridden.
Overloading and overriding interact at one special point: Overriding takes place only if two methods have the same signature. Up to Java 1.4, a common source of errors was that a method seemed to override an inherited one, but introduced a small variation in the parameters, so that the old method remained in place. The @Override annotation reduces that risk, since the compiler can at least check that some method has been overridden.
1.4.3 Service Provider
The first and most fundamental approach to using methods is to consider![]() 1.1 them as services offered by the object to the outside world. Other objects can collaborate by invoking these methods, and can make use of the object’s functionality instead of reimplementing it. Foremost, services are offered as public methods, because these are accessible to any other object in the system.
1.1 them as services offered by the object to the outside world. Other objects can collaborate by invoking these methods, and can make use of the object’s functionality instead of reimplementing it. Foremost, services are offered as public methods, because these are accessible to any other object in the system.
As a simple example, an IFile object in the Eclipse platform offers the following method to write data to disk. The data is given as an Input Stream, from which the bytes are read. Additional parameters specify whether changes not yet noticed by Eclipse should be ignored and whether a history entry for undo should be created. In the background, the object performs the disk updates, changes the internal resource data structures, and sends out change notifications—a complex service provided to the client object for free.
org.eclipse.core.resources.IFile.setContents
void setContents(InputStream source, boolean force,
boolean keepHistory, IProgressMonitor monitor)
Further typical examples are found in the class GC from SWT, which enables![]() 7.8 drawing on the screen. They demonstrate the idea of “services” very well, because simple calls by the client require complex interactions with the operating system in the background. For example, just passing a position and a string to drawString() will take care of all font issues, such as rasterization and measuring.
7.8 drawing on the screen. They demonstrate the idea of “services” very well, because simple calls by the client require complex interactions with the operating system in the background. For example, just passing a position and a string to drawString() will take care of all font issues, such as rasterization and measuring.
When writing service provider methods, the fundamental guideline is:
Always think of methods from the clients’ perspective.
A service method will be written once, but will potentially be used in many places throughout the code base. It is therefore essential to keep its use simple, even if this leads to a more complex implementation. Simplicity can often be gauged by a few basic questions: How many parameters must be provided? Is their meaning clear? Can the method’s effect be described![]() 4.1 in 1–2 sentences? Are there complex side conditions on the use? It is also
4.1 in 1–2 sentences? Are there complex side conditions on the use? It is also![]() 5.4.3 very helpful to write out a few use scenarios, possibly in the form of unit tests, to get a feeling for what the client code will look like, whether the code “tells its own story.”
5.4.3 very helpful to write out a few use scenarios, possibly in the form of unit tests, to get a feeling for what the client code will look like, whether the code “tells its own story.”![]() 1.2.3
1.2.3
Designing service methods always involves decisions. For example, consider again GapTextStore, which handles text documents for editors![]() 1.3.1 throughout Eclipse. Its core functionality is provided by a method replace (pos,len,txt), which performs the obvious text replacement. The Swing counterpart GapContent, in contrast, offers two separate methods insert String() and remove(). Both alternatives are certainly viable. While Swing’s choice may be more natural from an application perspective, SWT’s choice is more uniform from a technical point of view and also leads to further uniformity in other objects. For instance, undo/redo can be implemented
1.3.1 throughout Eclipse. Its core functionality is provided by a method replace (pos,len,txt), which performs the obvious text replacement. The Swing counterpart GapContent, in contrast, offers two separate methods insert String() and remove(). Both alternatives are certainly viable. While Swing’s choice may be more natural from an application perspective, SWT’s choice is more uniform from a technical point of view and also leads to further uniformity in other objects. For instance, undo/redo can be implemented![]() 9.5 in a single command class, instead of two. In any case, the crucial consideration is the expected use of the methods, not their implementation.
9.5 in a single command class, instead of two. In any case, the crucial consideration is the expected use of the methods, not their implementation.
Certainly, not all public methods perform complex services. Sometimes, the services are extremely simple, such as accessing a property field. It is![]() 1.3.3
1.3.3 ![]() 1.3.4 nevertheless necessary to consider such methods as full service providers. In particular, you should ask yourself—again—whether these methods should actually be public. Furthermore, they may require new functionality along
1.3.4 nevertheless necessary to consider such methods as full service providers. In particular, you should ask yourself—again—whether these methods should actually be public. Furthermore, they may require new functionality along![]() 2.1 the way—for instance, they may notify observers about the change, or may maintain internal consistency conditions with other fields.
2.1 the way—for instance, they may notify observers about the change, or may maintain internal consistency conditions with other fields.
So far, we have looked at public methods, which are offered to the overall system. Objects usually also provide services for more restricted![]() 3.1.2 audiences. Services to subclasses are usually given by protected methods and require special care in calls, since the caller must understand more of
3.1.2 audiences. Services to subclasses are usually given by protected methods and require special care in calls, since the caller must understand more of![]() 9.3.2 the object’s implementation. For instance, an AbstractListViewer maps linear data structures into lists or combo boxes on the screen. Internally, it keeps a mapping between data items and screen texts. The mapping is considered an implementation detail in general, but subclasses can still access it through methods like indexForItem(). Similarly, objects in a
9.3.2 the object’s implementation. For instance, an AbstractListViewer maps linear data structures into lists or combo boxes on the screen. Internally, it keeps a mapping between data items and screen texts. The mapping is considered an implementation detail in general, but subclasses can still access it through methods like indexForItem(). Similarly, objects in a![]() 1.7 package sometimes collaborate closely, and their services to each other are presented as default visible methods.
1.7 package sometimes collaborate closely, and their services to each other are presented as default visible methods.
1.4.4 Convenience Method
Sometimes a service method is so general that calls become rather complex. When restricting the generality is not an option, it may be useful to provide convenience methods, which are sufficient for the most frequent applications and which internally delegate to the general method.
For instance, a tree widget on the screen can be told to expand the topmost levels of the displayed data structure through the following method expandToLevel. Really, this delegates to a more general method that expands below a given node:
org.eclipse.jface.viewers.AbstractTreeViewer
public void expandToLevel(int level) {
expandToLevel(getRoot(), level);
}
Similarly, a Document manages a text document with positions, which are markers that move according to modifications. The following convenience method allows simple clients to forget that there are actually several different categories of positions:
org.eclipse.jface.text.AbstractDocument
public void addPosition(Position position)
throws BadLocationException {
addPosition(DEFAULT_CATEGORY, position);
}
Whether to introduce convenience methods is, however, a decision not to be taken lightly. Having too many clutters up the API that users of the class![]() 7 have to learn. Worse, the semantics may become unclear. In swt.Control, for example, the general setBounds(rect) makes the widget cover a rectangular screen area; unexpectedly, setLocation() not only moves the widget, but also re-sizes it to width and height 0 (which is not stated in the documentation). It may also become unclear which method is the real implementation, so that it becomes hard to change the behavior by overriding.
7 have to learn. Worse, the semantics may become unclear. In swt.Control, for example, the general setBounds(rect) makes the widget cover a rectangular screen area; unexpectedly, setLocation() not only moves the widget, but also re-sizes it to width and height 0 (which is not stated in the documentation). It may also become unclear which method is the real implementation, so that it becomes hard to change the behavior by overriding.![]() 3.1.7 For instance, Figures in the Graphical Editing Framework have methods
3.1.7 For instance, Figures in the Graphical Editing Framework have methods![]() 214 setBounds() and setLocation(); code inspection reveals that the latter is a convenience method for the former. However, from the documentation alone, the first might also call setLocation() and setSize().
214 setBounds() and setLocation(); code inspection reveals that the latter is a convenience method for the former. However, from the documentation alone, the first might also call setLocation() and setSize().
![]() To clarify which one is the core method and to avoid confusion in overriding, you can make the convenience method final (in the example from Figure, null means “no layout constraint” and -1 means “at the end”):
To clarify which one is the core method and to avoid confusion in overriding, you can make the convenience method final (in the example from Figure, null means “no layout constraint” and -1 means “at the end”):
public final void add(IFigure figure) {
add(figure, null, -1);
}
Convenience methods should not be introduced for a particular client’s convenience, but rather created only if they are useful as an additional interface. Their design is subject to the same considerations as that of general service methods.
1.4.5 Processing Step
The services of an object are rarely so simplistic that their implementation fits into the service provider method itself. Methods that span several screen pages are a maintenance nightmare, as they are write-only code. Realistically, once you get the test cases running, you will be only too happy to free your mind from the burden and move on to the next task. Then you have to keep hoping that the code will never be touched again.
Here is a typical example of how to get it right. Opening a new window on the screen seems simple enough: The client just calls open() on![]() 9.3.2 a Window object. The implementation shows the complexity: The window object negotiates with the operating system for resources, makes sure that
9.3.2 a Window object. The implementation shows the complexity: The window object negotiates with the operating system for resources, makes sure that![]() 7.1 the result fits on the screen, shows the window, and finally dispatches all
7.1 the result fits on the screen, shows the window, and finally dispatches all![]() 7.10.1 events to the new window, if desired.
7.10.1 events to the new window, if desired.
org.eclipse.jface.window.Window
1 public int open() {
2 create();
3 constrainShellSize();
4 shell.open();
5 if (block) {
6 runEventLoop(shell);
7 }
8 return returnCode;
9 }
This code shows good structuring; you can grasp the essence of the solution without knowing any of the details.
Use methods to break up the implementation into meaningful steps.
The steps are usually part of the object’s implementation. That is, they are internal and therefore declared private or protected. Making them private clarifies their auxiliary status and there are no further difficulties. Making processing steps protected, in contrast, needs some reflection:![]() 1.4.8
1.4.8 ![]() 3.1.2 Can subclasses reuse the steps for their own purposes? Then the methods become part of the subclass interface, which needs extensive consideration
3.1.2 Can subclasses reuse the steps for their own purposes? Then the methods become part of the subclass interface, which needs extensive consideration![]() 1.4.11 in itself. Or do you want subclasses to influence the behavior, by extension
1.4.11 in itself. Or do you want subclasses to influence the behavior, by extension![]() 1.4.9 or according to the TEMPLATEMETHOD pattern? All of those questions will be discussed in due course. For now, it is sufficient to summarize:
1.4.9 or according to the TEMPLATEMETHOD pattern? All of those questions will be discussed in due course. For now, it is sufficient to summarize:
Take care not to expose internal processing steps inadvertently.
![]() Sometimes breaking up a method into smaller steps does not work out, because it requires complex parameter passing or temporary fields. In such cases, it is useful to
Sometimes breaking up a method into smaller steps does not work out, because it requires complex parameter passing or temporary fields. In such cases, it is useful to![]() 1.4.8.3
1.4.8.3 ![]() 1.8.6
1.8.6 ![]() 27 factor out the method into a separate object according to the METHOD OBJECT pattern.
27 factor out the method into a separate object according to the METHOD OBJECT pattern.
A more fundamental question is how to identify useful processing steps in the first place. The simplest approach is to allow yourself some wishful thinking: While coding some functionality that you know to be complex, just look out for bits that you know to be solvable, even if that resolution requires some further effort. Choose a descriptive name and just write down a call that you would think sensible, even though you know that the method does not yet exist.
Tool: Create Method from Call
Place the cursor on the closing parenthesis and activate Quick-Fix (Ctrl-1). Eclipse will create a method below the current one that fits the call. Use Tab to jump to the linked positions at which Eclipse has made choices—for example, of parameter types and names—to amend those choices quickly.
The problem with wishful thinking is that it requires experience. In other words, you can think of useful steps only if you recognize a familiar pattern—that is, if you have coded something similar before. Making the right wishes can be surprisingly hard.
A complementary approach is to recognize processing steps after the fact, either in existing code or while you are coding. Eclipse’s extensive tool support in this area testifies to the practical importance of this strategy.
Tool: Extract Method
Select statements or a (sub)expression in the Java editor, then invoke the Refactoring/Extract method (by Alt-Shift-M, or through Alt-Shift-T). A pop-up dialog enables you to customize the result.
![]() Eclipse is really amazingly intelligent: If it detects that some statement has a side effect on a local variable, it passes the current value as a parameter and returns the variable’s new value from the method.
Eclipse is really amazingly intelligent: If it detects that some statement has a side effect on a local variable, it passes the current value as a parameter and returns the variable’s new value from the method.
Tools, especially powerful tools, always need to be applied with care and consideration. Suppose that in the context of a spreadsheet application,![]() 9.4 you were to write a method that gets the cell content of a particular cell, ensuring that the cell exists. The row and column are given in 1-based, user-oriented notation. You may come up with the following code (cells is a HashMap):
9.4 you were to write a method that gets the cell content of a particular cell, ensuring that the cell exists. The row and column are given in 1-based, user-oriented notation. You may come up with the following code (cells is a HashMap):
methods.refactoring.ExtractExampleCells00
1 public String getCellContent(int userRow, int userCol) {
2 Cell c = cells.get(new CellRef(userRow - 1, userCol - 1));
3 if (c != null) {
4 c = new Cell();
5 cells.put( new CellRef(userRow - 1, userCol - 1), c);
6 }
7 return c.content;
8 }
When you extract lines 2–6, you get a method getOrCreateCell with a tangle of functionality: It shifts indices to internal notation, adds cells as required, and so on. Very often, you have to clean up the code before extracting methods, and in many cases, a second tool comes to the rescue.
Tool: Extract Variable
Select an expression and bind its result to a local variable by Alt-Shift-L (or refactor with Alt-Shift-T; or Quick-Fix with Ctrl-1). Variable extraction can also replace multiple occurrences of an expression simultaneously.
![]() To select an expression for extraction, it is sufficient to place the cursor onto a character that belongs to none of its subexpressions, such as the operator in a binary expression.
To select an expression for extraction, it is sufficient to place the cursor onto a character that belongs to none of its subexpressions, such as the operator in a binary expression.
For instance, if you want to capture only the on-the-fly creation of new cells, you would extract the CellRef objects into a variable and would end up with this code:
methods.refactoring.ExtractExampleCells01
public String getCellContent( int userRow, int userCol) {
CellRef key = new CellRef(userRow - 1, userCol - 1);
Cell c = getOrCreateCell(key);
return c.content;
}
If you like this better, you can immediate inline the parameter, and the variable c as well.
Tool: Inline Variable
Select a variable declaration or a variable reference and press Alt-Shift-I (or Alt-Shift-T for the menu).
This leaves you with the following neat code:
methods.refactoring.ExtractExampleCells02
public String getCellContent(int userRow, int userCol) {
return getOrCreateCell(
new CellRef(userRow - 1, userCol - 1)).content;
}
Looking at this code, you might see another piece of useful functionality lurking inside, and obtain the following final version. Note also how introducing![]() 1.2.3 an additional method makes the code “tell its own story.”
1.2.3 an additional method makes the code “tell its own story.”
methods.refactoring.ExtractExampleCells03
public String getCellContent(int userRow, int userCol) {
return getOrCreateCell(convertExternalCoordinates(userRow,
userCol)).content;
}
This example demonstrates a general guideline:
Plan method refactorings carefully and judge the result by readability.
Nevertheless, you will note that modifying code with the Eclipse tools is fundamentally different from writing code. The code is no longer a stiff, unmodifiable, fixed mass of statements, but becomes malleable, so you can easily mold or massage it into new shapes at the expense of a few keyboard short-cuts. Also, an undo will revert all modifications simultaneously, which leaves you free to experiment until you are satisfied with the result.
Despite the ease of code editing and experimentation, the original goal for introducing methods as processing steps remains valid:
Identify processing steps from the meaning and context of the code.
Methods, even internal helper methods, are never merely technical. Always be aware that methods structure your solution and shape the way that you, and later your team, will think about the solved problem.
Going one step beyond, this thought touches on the old debate about whether code should be written bottom-up, from the smaller steps to the larger, or top-down, by wishful thinking, from the general strategy to the details. In practice, the question arises very rarely, because both require experience with similar problems solved. When solving new problems, your first concern is to find and understand any solution. In the words of Tim Budd:![]() 55(§2.3)
55(§2.3)
[ ... ] design might be said to progress from the known to the unknown.
In the extreme, this might actually lead to bottom-up code development, if you are working in an area that you are very familiar with. If you know that a particular bit of functionality will come in useful, you should not hesitate to write it down as a building block for the later development.
Write down what you clearly understand is necessary.
In summary, Eclipse’s powerful tool support enables you to start coding,![]() 92 perhaps along test cases to be solved, and later restructure the code to
92 perhaps along test cases to be solved, and later restructure the code to![]() 5.2 facilitate maintenance. We close the discussion on methods as processing steps with one final guideline, which holds regardless of the way by which you have arrived at your code:
5.2 facilitate maintenance. We close the discussion on methods as processing steps with one final guideline, which holds regardless of the way by which you have arrived at your code:
Don’t forget to clean up your code once you have understood the solution.
1.4.6 Explanatory Methods
Method names are extremely powerful documentation. In the declaration,![]() 1.2.3 they head the method body and leave the reader with an anticipation, an expectation of what that code will probably achieve. At the same time, the method name appears at the call sites. There, it gives a summary of a particular computation that needs to be performed. Methods can therefore be used as named pieces of code.
1.2.3 they head the method body and leave the reader with an anticipation, an expectation of what that code will probably achieve. At the same time, the method name appears at the call sites. There, it gives a summary of a particular computation that needs to be performed. Methods can therefore be used as named pieces of code.
Use method calls to express and document your overall solution strategy.
This advice is actually at the heart of agile software development. This![]() 28
28 ![]() 172 approach encourages you to cut down on wasted work. For instance, rather than writing documentation that no one reads or updates, it is more sensible to put an extra effort into creating good code structure to make the code self-documenting. Having short methods with descriptive names is a first, fundamental step.
172 approach encourages you to cut down on wasted work. For instance, rather than writing documentation that no one reads or updates, it is more sensible to put an extra effort into creating good code structure to make the code self-documenting. Having short methods with descriptive names is a first, fundamental step.
When tempted to write an inline comment, introduce a method instead.
To see what can be achieved, consider the following excerpt from the Gap TextStore.![]() 1.3.1 To prepare for an insertion, it can just move the gap, or else it must reallocate the backing array because of insufficient space. The core of the method exhibits that choice, and also the contained parallelism, beautifully:
1.3.1 To prepare for an insertion, it can just move the gap, or else it must reallocate the backing array because of insufficient space. The core of the method exhibits that choice, and also the contained parallelism, beautifully:
org.eclipse.jface.text.GapTextStore.adjustGap
if (reuseArray)
newGapEnd = moveGap(offset, remove, oldGapSize, newGapSize,
newGapStart);
else
newGapEnd = reallocate(offset, remove, oldGapSize, newGapSize,
newGapStart);
Introducing explanatory methods also does not require deep thought![]() 12 or weighing of alternatives. The goal is not reusability or extensibility, but merely a place to put an expressive name. Making the methods private ensures that no one learns about their existence and that you remain free to restructure your code if you happen to find a better solution later on. Don’t hesitate to extract methods with the tools Extract Method and Extract Variable for the purpose: Having a good, explanatory name is better than having no name at all. And in case you ever follow a dead-end street, there is always a simple solution:
12 or weighing of alternatives. The goal is not reusability or extensibility, but merely a place to put an expressive name. Making the methods private ensures that no one learns about their existence and that you remain free to restructure your code if you happen to find a better solution later on. Don’t hesitate to extract methods with the tools Extract Method and Extract Variable for the purpose: Having a good, explanatory name is better than having no name at all. And in case you ever follow a dead-end street, there is always a simple solution:
Tool: Inline Method
Place the cursor on a method name and press Alt-Shift-I to inline the method’s body (or use Alt-Shift-T for the Refactoring menu).
1.4.7 Events and Callbacks
Very often methods defined by an object are not services or functionality offered to others, but rather points where the object accepts notifications![]() 2.1 from others. Observers are interested in state changes of other objects;
2.1 from others. Observers are interested in state changes of other objects;![]() 2.3.2 visitors are called back for each node encountered in a hierarchical data
2.3.2 visitors are called back for each node encountered in a hierarchical data![]() 7.3 structure. In the context of frameworks, inversion of control dictates that the framework decides when to run which application code. Callback methods
7.3 structure. In the context of frameworks, inversion of control dictates that the framework decides when to run which application code. Callback methods![]() 3.2.6 are usually defined in interfaces and are then implemented in different objects. Examples can be found in the corresponding sections.
3.2.6 are usually defined in interfaces and are then implemented in different objects. Examples can be found in the corresponding sections.
Technically, there is nothing special about a callback: The method gets called and the object executes the code to update its state and carry![]() 7.11 out suitable operations. Conceptually, however, callback methods cannot
7.11 out suitable operations. Conceptually, however, callback methods cannot![]() 1.1
1.1 ![]() 1.4.3 be understood from the caller’s perspective, but only from the object’s perspective—that is, the object alone determines the suitable reaction to the method call. Furthermore:
1.4.3 be understood from the caller’s perspective, but only from the object’s perspective—that is, the object alone determines the suitable reaction to the method call. Furthermore:
Understanding callbacks requires understanding the framework’s mechanisms.
You also need complementary knowledge about the framework’s mechanisms![]() 1.4.9
1.4.9 ![]() 3.1.2 to understand when and why the method will be called. The method achieves its purpose only because the environment makes guarantees about the circumstances under which it will call the method. For instance, the JFace viewers display application data on the screen. They use content
3.1.2 to understand when and why the method will be called. The method achieves its purpose only because the environment makes guarantees about the circumstances under which it will call the method. For instance, the JFace viewers display application data on the screen. They use content